机器学习——特征工程
对于机器学习特征工程的知识,你是怎样理解“特征”
在机器学习中,特征(Feature)是指从原始数据中提取出来的、用于训练和测试机器学习模型的各种属性、变量或特点。特征可以是任何类型的数据,例如数字、文本、图像、音频等等。
特征工程是机器学习中非常重要的一个环节,指的是从原始数据中选择、提取、转换和创建特征的过程。好的特征可以提高模型的准确性和泛化能力,而不良的特征则可能导致模型的错误或不稳定。
在进行特征工程时,通常需要考虑以下几个方面:
特征的重要性:要选择与目标变量相关性高、影响力大的特征。可以使用相关系数、信息增益、方差分析等方法进行评估。
特征的类型:不同类型的特征需要采用不同的处理方式,例如数值型特征可以进行标准化、归一化等操作,而类别型特征则需要进行编码。
特征的处理:特征可能存在缺失值、异常值、重复值等问题,需要进行清洗、填充、转换等操作。
特征的创造:有时候,原始数据中并没有我们需要的特征,需要根据业务需求进行特征的创造,例如从日期中提取出月份、从地理位置中提取出经纬度等。
对于机器学习特征工程的知识,给定场景和问题,你如何设计特征?(特征工程方法论)
在机器学习特征工程的实践中,如何设计特征取决于具体的场景和问题。
下面是一些特征工程方法论的参考:
理解数据背景和业务需求:在设计特征前,需要对数据的背景和业务需求进行深入了解,了解数据中的信息是否有足够的可用性以及如何影响模型的预测结果。
特征选择和提取:从原始数据中选取出最具有预测力的特征。可以使用统计方法、相关性分析、特征重要性分析、L1正则化等方法进行特征选择和提取。
特征编码:将类别型变量编码为数字变量,以便算法能够使用。编码方法包括独热编码、二进制编码、标签编码等。
特征缩放:将特征进行缩放,使得所有特征的数值范围在相似的区间内。常见的缩放方法包括标准化、最小-最大缩放等。
特征交叉:将不同的特征进行组合,以便捕捉特征之间的交互效应。可以使用多项式特征、交叉特征等方法进行特征交叉。
特征变换:通过对特征进行变换,可以发现数据的更深层次的规律。常见的变换包括对数变换、指数变换、正弦变换等。
特征创造:有时候,原始数据中并没有我们需要的特征,需要根据业务需求进行特征的创造。例如,对时间序列数据进行滚动窗口计算,提取出统计特征等。
时间序列数据——滚动窗口计算
在时间序列分析中,滚动窗口计算是一种常用的数据处理方式,它可以将原始时间序列数据按照滑动窗口的方式进行分割,并在每个窗口内进行一些统计计算。
具体来说,滚动窗口计算就是将时间序列数据划分成大小相等的固定窗口,然后在每个窗口内进行一些统计计算,比如计算窗口内数据的均值、标准差、最大值、最小值等等。窗口可以根据具体需求来设置,可以是固定大小的窗口,也可以是根据数据波动情况自适应调整大小的窗口。
滚动窗口计算在时间序列分析中非常常用,可以用来寻找数据中的规律和周期性变化,也可以用来进行数据预处理,提取特征等。比如在预测股票价格时,可以使用滚动窗口计算来提取历史股票价格的统计特征,然后将这些特征作为输入用于预测未来的股票价格。
介绍一下编码方法中独热编码、二进制编码、标签编码、序号编码
在机器学习中,特征通常需要被编码成数值型的形式,以便于机器学习算法的处理。常见的编码方法有独热编码、二进制编码和标签编码。
编码方法的选择应该根据具体问题的特点和机器学习模型的需求进行,不能盲目追求维度的降低,因为特征的编码方法可能会影响机器学习模型的性能。
独热编码(One-Hot Encoding):将离散型特征的每一个取值都编码成一个独立的向量,向量的维度等于特征取值的个数。在向量中,只有特征取值对应的位置是1,其他位置都是0。适合的数据类型是无序的类别型数据,如颜色、性别等。这种编码方法可以有效地处理离散型特征,但是当离散型特征的取值过多时,会导致编码后的向量维度变得非常高,进而造成稀疏性问题。
二进制编码(Binary Encoding):将离散型特征的每一个取值都映射成一个整数,然后将整数用二进制进行编码。这种编码方法可以有效地处理离散型特征,相较于独热编码,可以减少向量的维度,但是仍然存在维度过高的问题。
标签编码(Label Encoding):将离散型特征的每一个取值都映射成一个整数。这种编码方法只适用于具有大小关系的离散型特征,对于没有大小关系的离散型特征,使用标签编码会引入无关的大小关系。
序号编码(Ordinal Encoding)是将类别型数据映射为整数的编码方式。将每个类别与一个整数一一对应,从1开始逐一递增,直到最后一个类别编码完毕。适合的数据类型是有序的类别型数据,如评级、温度等级等。
开发特征时候做如何做数据探索,怎样选择有用的特征?
在开发特征时,数据探索是一个非常重要的步骤,可以帮助我们更好地了解数据,选择有用的特征。下面是一些数据探索和特征选择的方法:
可视化探索数据。通过绘制直方图、散点图、箱线图等可视化图表,观察数据分布、异常值等情况,发现数据中的规律、趋势和异常情况。
相关性分析。计算特征之间的相关性系数,例如皮尔逊相关系数、斯皮尔曼相关系数等,判断特征之间的相关性程度,可以帮助选择具有较高相关性的特征。
特征重要性评估。使用机器学习算法或统计方法,计算每个特征的重要性得分,例如决策树中的信息增益、随机森林中的特征重要性评估等。
特征选择算法。使用特征选择算法来自动选择最具有代表性和区分度的特征,例如Lasso、Ridge、ElasticNet等正则化算法,或者基于遗传算法、贪心算法、递归特征消除等的特征选择算法。
领域知识。通过对领域知识的理解和分析,可以选择与目标变量相关的特征,增加模型的准确性和可解释性。
在特征选择完成后,还需要对选定的特征进行验证,包括特征的统计学分布、特征之间的相关性、特征与目标变量的相关性等方面进行验证,以确保选定的特征具有可靠性和鲁棒性。
对于机器学习特征工程的知识,你是如何做数据清洗的?举例说明
数据清洗是特征工程的重要步骤,它包括识别、处理和纠正数据中存在的错误、缺失、异常值和重复项等问题,以提高数据质量和模型性能。
以下是我通常进行数据清洗的步骤:
去除重复数据:查找并删除重复的数据行,以避免重复数据对模型的影响。
处理缺失数据:对于缺失值,可以使用插值法(如均值、中位数、众数填充)、删除缺失值的行或使用高级方法(如矩阵分解、随机森林填充)进行处理。
处理异常数据:查找并处理数据中的异常值,如使用平均值、中位数、截断方法进行处理。
处理错误数据:查找并处理数据中的错误值,如使用规则检查、模型校验或与数据来源方联系等方法进行处理。
特征选择:根据实际情况,选择对模型有用的特征,如去除冗余特征、选择相关性高的特征或使用PCA等方法进行降维。
数据变换:对数据进行变换,如对连续型特征进行分箱、对类别型特征进行编码、对时间序列数据进行滚动窗口计算等方法进行处理。
举例来说,如果我们要开发一个房价预测模型,首先需要对数据进行清洗。在数据清洗的过程中,我们需要处理一些缺失值、异常值和错误值,如通过填充平均值或中位数的方法处理缺失值、使用平均值或截断法处理异常值等。然后我们可以对房屋属性进行特征选择,如选择房屋面积、卧室数量、卫生间数量、车库数量等特征,并对类别型特征进行编码(如独热编码)或二进制编码等。最后,我们可以使用这些特征构建预测模型,以预测房价。
对于机器学习特征工程的知识,如何发现数据中的异常值,你是如何处理?缺失值如何处理?
发现异常值和处理缺失值都是数据清洗的一部分,是特征工程中非常重要的环节。
- 异常值的处理:
异常值是指与大部分样本明显不同的观测值,可能是由于录入错误、数据采集问题、测量误差等因素导致。对于异常值,可以通过以下方法进行处理:
- 删除异常值:可以通过设置阈值或使用统计学方法来识别和删除异常值。
- 替换异常值:将异常值替换为合理的值,例如使用均值、中位数、众数等代替异常值。
- 将异常值作为一种特殊情况处理:对于某些场景下,异常值可能包含有用的信息,可以将其作为一种特殊情况来处理。
- 缺失值的处理:
缺失值是指数据集中某些观测值未被采集或记录下来的情况。处理缺失值可以采用以下方法:
- 删除带有缺失值的样本:如果缺失值数量较少,可以考虑删除带有缺失值的样本。
- 插值法:插值法是通过已有的观测值推断出缺失值,比较常见的插值方法包括线性插值、多项式插值、样条插值等。
- 特殊值填充:对于某些特殊情况,可以将缺失值填充为特殊值,例如 0、-1、999 等。
- 模型预测:可以使用已有的数据构建模型来预测缺失值,例如回归模型、分类模型等。
对于机器学习特征工程的知识,对于数值类型数据,你会怎样处理?为什么要做归一化?归一化有哪些方法?离散化有哪些方法,离散化和归一化有哪些优缺点?
对于数值型数据,一般需要进行归一化处理。归一化的目的是将数据统一到同一数量级,避免不同变量因为单位不同造成的影响。具体来说,归一化能够加速梯度下降求解速度,提高算法的精度和效率。
常见的归一化方法包括:
最大-最小归一化(Min-Max Scaling):将数据缩放到[0,1]的范围内。具体计算方法是将原始数据减去最小值后除以最大值与最小值之差。
z-score归一化:将数据归一化为标准正态分布,即均值为0,方差为1的分布。具体计算方法是将原始数据减去均值后除以标准差。
离散化是将连续型数据划分成离散型数据的过程。离散化可以降低数据噪声的影响,减小模型复杂度,同时还可以提高模型的可解释性。常见的离散化方法包括:
等宽离散化:将数据划分为等宽的区间,不适合数据分布不均匀的情况。
等频离散化:将数据划分为等频的区间,可以处理数据分布不均匀的情况。
K-means离散化:使用k-means算法将数据聚成k个簇,簇中心即为离散化后的值。
离散化的优点是能够去除异常值和噪声,提高模型鲁棒性,同时还能够减小计算复杂度。但是,离散化会损失一部分信息,可能会影响模型的精度。
归一化的优点是将数据统一到同一数量级,可以加快算法的收敛速度,提高算法的精度和效率。但是,归一化会改变原始数据的分布特征,有可能会影响模型的准确性。因此,在进行特征工程时,需要根据具体的问题和数据分布情况来选择是否进行离散化和归一化,并选择适合的方法进行处理。
等宽离散化是一种常用的离散化方法, 它将连续的数值型数据划分成等宽的区间, 每个区间内的数据被映射为该区间的标签或类别。 这种方法对于数据分布比较均匀的情况效果较好。下面以一个简单的例子说明等宽离散化的过程:假设我们有一组连续的数值型数据,如下所示:[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]现在我们将这些数据进行等宽离散化,假设我们希望将其分成4个区间,则每个区间的宽度为:(10-1)/4 = 2.25按照这个宽度进行划分,得到的4个区间分别为:[1, 3.25), [3.25, 5.5), [5.5, 7.75), [7.75, 10]最终将原始数据映射到对应的区间中,得到的离散化后的数据如下所示:[1-3.25) => 0 [1-3.25) => 0 [3.25-5.5) => 1 [3.25-5.5) => 1[5.5-7.75) => 2 [5.5-7.75) => 2 [7.75-10] => 3 [7.75-10] => 3这样,我们就将原始的连续数值型数据离散化为了4个等宽的区间。
CTR类特征是什么, 你是如何处理CTR类特征?
CTR(Click-Through Rate)类特征指的是用户点击某个广告的概率。在CTR预估问题中,CTR类特征是非常重要的一类特征,对于点击率预估等任务有着至关重要的作用。
在处理CTR类特征时,常见的处理方法有以下几种:
特征离散化:将连续型的CTR特征离散化成若干个桶,可以将连续变量转化为离散变量,并减少特征空间的维度。等宽离散化、等频离散化、基于决策树的离散化是常见的方法。
统计特征:使用历史数据统计用户的行为特征,例如历史点击率、曝光率、点击次数等特征,可以反映用户的行为习惯,有助于提高模型的表现。
特征交叉:将CTR类特征和其他类别的特征进行交叉,例如广告类别、用户属性等特征,可以构建新的特征。
嵌入式特征选择:嵌入式方法通过在模型训练过程中同时学习特征的权重和模型的参数,自动完成特征选择和模型训练。常见的方法包括L1正则化、Elastic Net、树模型中的特征重要性等。
以广告CTR预估为例,假设我们有用户年龄、性别、历史点击率等特征,我们可以使用以上方法来处理CTR类特征。例如,可以使用等频离散化将历史点击率分成5个桶,然后再将历史点击率和年龄、性别等特征进行交叉,构建新的特征,最后使用嵌入式方法进行特征选择和模型训练。
相关文章:

机器学习——特征工程
对于机器学习特征工程的知识,你是怎样理解“特征” 在机器学习中,特征(Feature)是指从原始数据中提取出来的、用于训练和测试机器学习模型的各种属性、变量或特点。特征可以是任何类型的数据,例如数字、文本、图像、音…...

ubuntu安装搜狗输入法,图文详解+踩坑解决
搜狗输入法已支持Ubuntu16.04、18.04、19.10、20.04、20.10,本教程系统是基于ubuntu18.04 一、添加中文语言支持 系统设置—>区域和语言—>管理已安装的语言—>在“语言”tab下—>点击“添加或删除语言”。 弹出“已安装语言”窗口,勾选中文…...

docker 数据持久化
目录 一、将本地目录直接映射到容器里(运行成容器时候进行映射) 二、数据卷模式 1、创建数据卷 2、查看数据卷列表,有哪些数据卷 3、查看某个数据卷 4、容器目录挂载到数据卷 5、数据卷的优势:多个容器共享一个数据卷 默认…...

Pytest运行指定的case,这个方法真的很高效……
Pytest运行指定的case 在测试工作中,当我们写了较多的cases时,如果每次都要全部运行一遍,无疑是很浪费时间的,而且效率低下。 但是有一种方法可以帮助你快速地运行指定的测试用例,提高测试效率,那就是使用…...

操作系统复习2.3.4-进程同步问题
生产者-消费者 系统中有一组生产者进程和一组消费者进程 两者共享一个初始为空,大小为n的缓冲区 缓冲区没满,生产者才能放入 缓冲区没空,消费者才能取出 互斥地访问缓冲区 互斥要在同步之后,不然会导致想要同步,但由…...
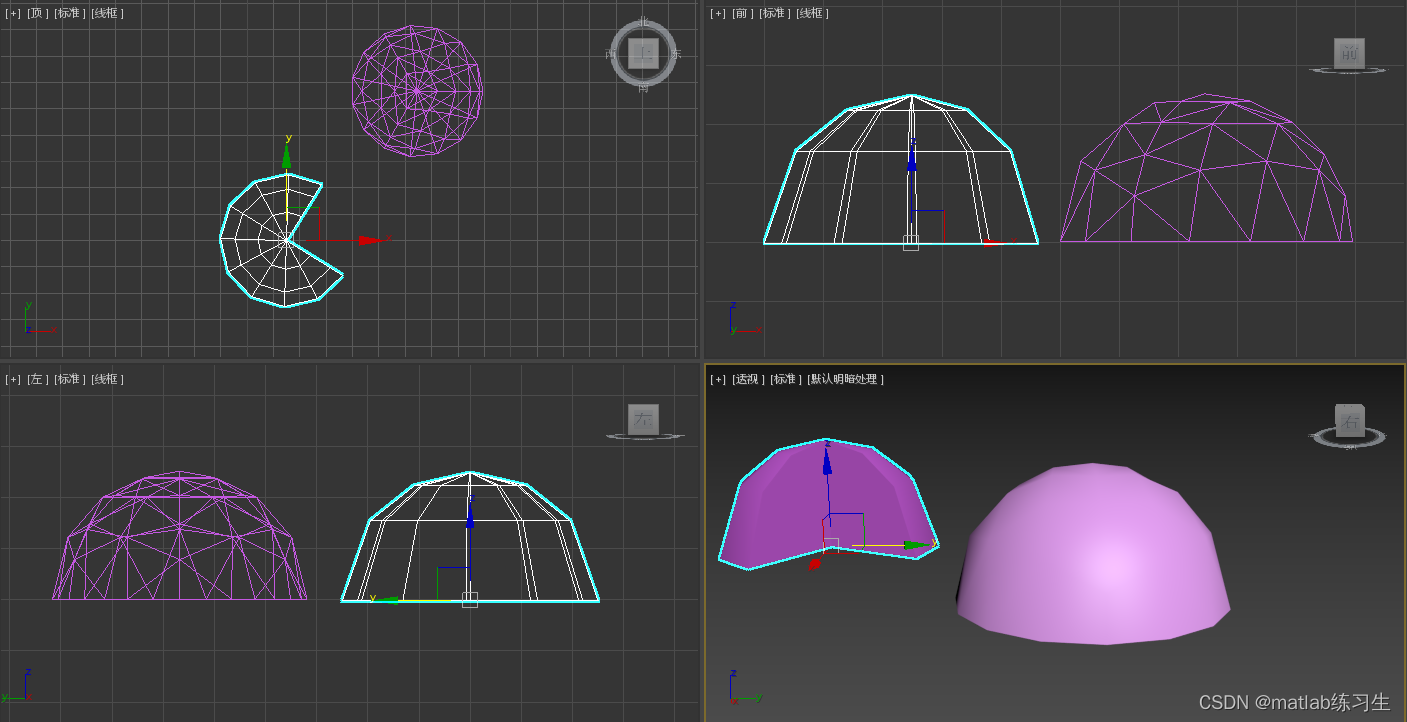
3ds MAX 基本体建模,长方体、圆柱体和球体
3ds MAX基本页面如下: 生成新的几何体在右侧: 选择生成的对象类型即可,以下为例子: 1、长方体建模 选择建立的对象类型为长方形 在 任意一个窗口绘制,鼠标滑动 这里选择左上角的俯视图 松开鼠标后,可以…...

搭建个人博客
个人网站用处有很多,可以写博客来记录学习过程中的各种事,不管是新知识还是踩坑记录,写完就丢在网站上,方便日后复习,也可以共享给他人,让其他人避免踩雷。 当然也不仅限于技术性的文章,生活中有…...
)
JavaScript进阶(下)
# JavaScript 进阶 - 第3天笔记 > 了解构造函数原型对象的语法特征,掌握 JavaScript 中面向对象编程的实现方式,基于面向对象编程思想实现 DOM 操作的封装。 - 了解面向对象编程的一般特征 - 掌握基于构造函数原型对象的逻辑封装 - 掌握基于原型对…...
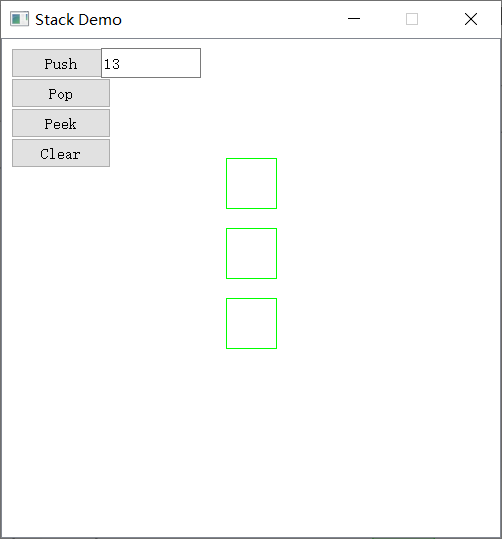
基于PyQt5的图形化界面开发——堆栈动画演示
目录 0. 前言1. 了解堆栈2.代码实现3. 演示效果其他PyQt5文章 0. 前言 本文使用 PyQt5制作图形化界面演示数据结构中的堆栈操作 操作系统:Windows10 专业版 开发环境:Pycahrm Comunity 2022.3 Python解释器版本:Python3.8 第三方库&…...

2023 年第三届长三角高校数学建模竞赛赛题浅析
为了更好地让大家本次长三角比赛选题,我将对本次比赛的题目进行简要浅析。数模模型通常分为优化、预测、评价三类,而本次数学题目就正好对应着A、B、C分别为优化、预测、评价。整体难度不大,主要难点在于A题的优化以及B、C的数据收集。稍后&a…...

sqlite3免费加密开源项目sqlcipher简单使用
一、概述 使用sqlite3的免费版本是不支持加密的。为了能使用上加密sqlite3,有一个免费的开源项目sqlcipher提供了免费和付费的加密sqlite功能。我们当然选择免费的版本啦。 官方网站: https://www.zetetic.net/sqlcipher/open-source/ 文档目录&#…...

SOLIDWORKS PDM Professional中的Add-ins
实现COM接口IEdmAddIn5的DLLs:IEdmAddIn5 Interface - 2019 - SOLIDWORKS API Help。通过“Add-in特性”对话框添加到文件库中:Administrate Add-ins Dialog Box - 2019 - SOLIDWORKS API Help通知SOLIDWORKS PDM Professional 用户操作: 将Add-in添加到…...

干货 | 郭晓雷:数智安全监管机制研究与思考
作者:郭晓雷本文约4300字,建议阅读8分钟 本文报告的主要内容关于数据安全,从学术或者技术的角度,更多地认为人工智能是数据处理的新技术,其应用会产生更加丰富的数据处理活动场景。 郭晓雷:今天报告的主要内…...
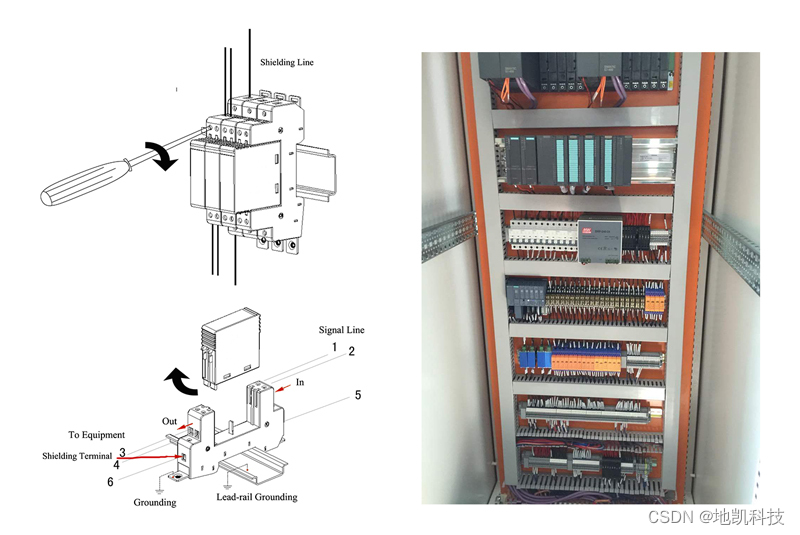
感应雷电浪涌的防线,SPD浪涌保护器
SPD - Surge Protective Device SPD 是防止雷击导致故障的避雷器,代表浪涌保护设备。一般指浪涌保护器,浪涌保护器,也叫防雷器,是一种为各种电子设备、仪器仪表、通讯线路提供安全防护的电子装置。 IEC/ EN61643-11 (…...
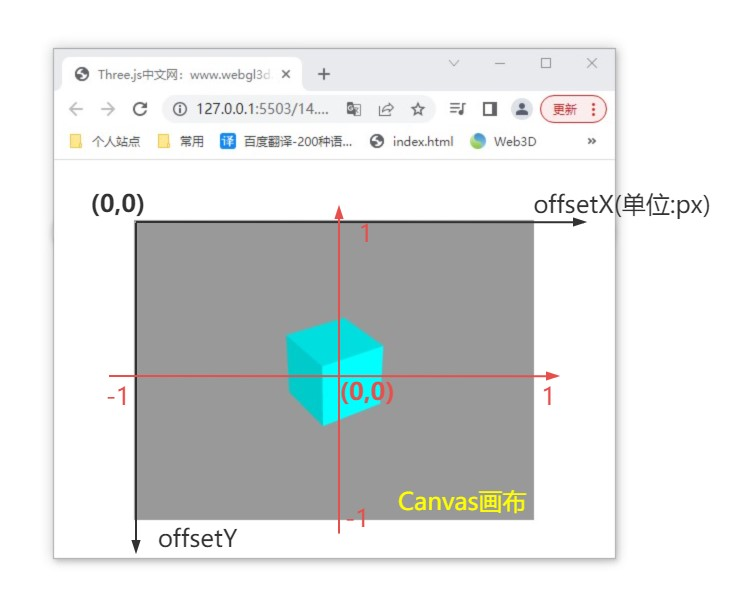
ThreeJS教程:屏幕坐标转标准设备坐标
推荐:将 NSDT场景编辑器 加入你的3D工具链 3D工具集: NSDT简石数字孪生 屏幕坐标转标准设备坐标 在讲解下节课鼠标点击选中模型之前,先给大家讲解下坐标系的问题。 获取鼠标事件坐标 先来了解一些,普通的web前端相关知识。 鼠…...

[elasticsearch 实现插入查询小demo ]
目录 前言: 。以下是Java语言实现Elasticsearch数据插入和批量插入的示例代码: 我们需要定义一个ElasticsearchUtil类来封装Elasticsearch操作。在本示例中,我们实现了以下方法: 下面是一个Java代码示例,演示了如何使用Elast…...
因为计算机中丢失VCRUNTIME140怎么办?为什么会丢失VCRUNTIME140.dll
vcruntime140.dll是一个Windows动态链接库,其主要功能是为C/C编译的程序提供运行时支持。这个库在Microsoft Visual Studio 2015中被引入,其名称中的“140”代表版本号。在我们打开运行软件或者游戏程序的时候,电脑提示因为计算机中丢失VCRUN…...

【满分】【华为OD机试真题2023B卷 JAVAJS】数字游戏
华为OD2023(B卷)机试题库全覆盖,刷题指南点这里 数字游戏 时间限制:1s 空间限制:256MB 限定语言:不限 题目描述: 小明玩一个游戏。系统发1+n张牌,每张牌上有一个整数。第一张给小明,后n张按照发牌顺序排成连续的一行。需要小明判断,后n张牌中,是否存在连续的若干张…...

NLP常用的三种中文分词工具对比
本文将对三种中文分词工具进行使用尝试,这三种工具分别为:哈工大的LTP,结巴分词以及北大的pkuseg。 1、准备 首先我们先准备好环境,即需要安装三个模块: pyltpjiebapkusegLTP的分词模型文件cws.model 在用户字典中…...
Visual C++ 6.0环境开发PACS影像系统的技术指标和精准算法
一、技术指标 •图像文件格式:DCM、JPG、BMP、TIF等 •可支持显示属性设置:24/32位真彩;256位色(黑白) •可支持监视器分辨率:1024﹡768;1280﹡1024;1600&…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...
五子棋测试用例
一.项目背景 1.1 项目简介 传统棋类文化的推广 五子棋是一种古老的棋类游戏,有着深厚的文化底蕴。通过将五子棋制作成网页游戏,可以让更多的人了解和接触到这一传统棋类文化。无论是国内还是国外的玩家,都可以通过网页五子棋感受到东方棋类…...
macOS 终端智能代理检测
🧠 终端智能代理检测:自动判断是否需要设置代理访问 GitHub 在开发中,使用 GitHub 是非常常见的需求。但有时候我们会发现某些命令失败、插件无法更新,例如: fatal: unable to access https://github.com/ohmyzsh/oh…...

车载诊断架构 --- ZEVonUDS(J1979-3)简介第一篇
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从,不跟风。把自己的精力全部用在自己。一是去掉多余,凡事找规律,基础是诚信;二是…...