【综述】视频无监督域自适应(VUDA)的小综述
【综述】视频无监督域自适应(VUDA)的小综述

一篇小综述,大家看个乐子就好,参考文献来自于一篇综述性论文
完整PPT已经上传资源:https://download.csdn.net/download/weixin_46570668/87848901?spm=1001.2014.3001.5503

链接:https://arxiv.org/abs/2211.10412
这次基于三篇有代表性的文章来讲解
- X. Song, S. Zhao, J. Yang, H. Yue, P. Xu, R. Hu, and H. Chai, “Spatio-temporal contrastive domain adaptation for action recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 9787–9795.
- Y. Xu, J. Yang, H. Cao, Z. Chen, Q. Li, and K. Mao, “Partial video domain adaptation with partial adversarial temporal attentive network,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9332–9341.
- L. Yang, Y. Huang, Y. Sugano, and Y. Sato, “Interact before align: Leveraging cross-modal knowledge for domain adaptive action recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 14 722–14 732.
VUDA提出背景
由于训练的公开视频数据集(源视频域)和真实视频(目标视频域)之间的域差异,训练的基于现有数据集的视频模型在直接部署到真实世界的应用程序时,会有显著的性能下降。此外,由于视频注释的成本较高,使用无标记的视频进行训练更加实用。为了统一解决视频高标注成本以及性能下降的问题,引入了视频无监督域自适应(VUDA),通过减轻视频域偏移,提高视频模型的通用性和可移植性,从标记源域适应到无标记目标域。
虽然具有深度学习的UDA通过处理领域转移大大提高了模型的通用性和可移植性,但之前对视觉应用的研究通常集中在图像数据上。同时,通过传统的视频特征提取器获得的视频表示主要来自于空间特征。然而,视频不仅包含空间特征,而且还包含时间特征以及其他模式的特征,如光流和音频特征,所有这些特性都会发生域偏移。
VUDA方法类别
随后,人们提出了各种VUDA方法来处理视频任务的域偏移问题。一般来说,可以分为五类:
- 基于对抗的方法,特征生成器与额外的域鉴别器以对抗的方式联合训练,如果域鉴别器不能区分它们是来自源域还是目标域,则获得域不变特征;
- 基于差异的方法,其中显式地计算了源域和目标域之间的差异,而目标域与源域通过应用度量学习方法,优化基于度量的目标;
- 基于语义的方法,利用领域不变特征获得一定的语义约束,如互信息,聚类,对比学习;
- 复合方法,域不变的特征是通过优化不同目标的组合(即基于差异、对抗和语义);
- 基于重构的方法,其中领域不变特征由使用重构的目标数据训练的编码器提取。
以上这五种方法还可根据输入模态的类别,继续细分。
Closed-set VUDA
现有的工作通常会对一般场景应用某些约束或假设,以形成可以更好地处理的场景。最常见的场景是闭集VUDA(closed-set VUDA)场景,它设置了以下约束和假设:
- 只有1个视频源域,只有1个目标域。
- 源域视频𝑫_𝒔和源模型𝑮_𝑺 (. ;𝜽_𝑺)是可访问的。
- 源域视频和目标域视频共享相同的标签空间(即𝒀_𝒔 = 𝒀_𝑻和| 𝑪_𝒔 | = | 𝑪_𝑻 |)。
- 源域视频和目标域视频共享相同的模型(即𝑮_𝑺 (. ;𝜽_𝑺) = 𝑮_𝑻 ( .;𝜽_𝑻) )。
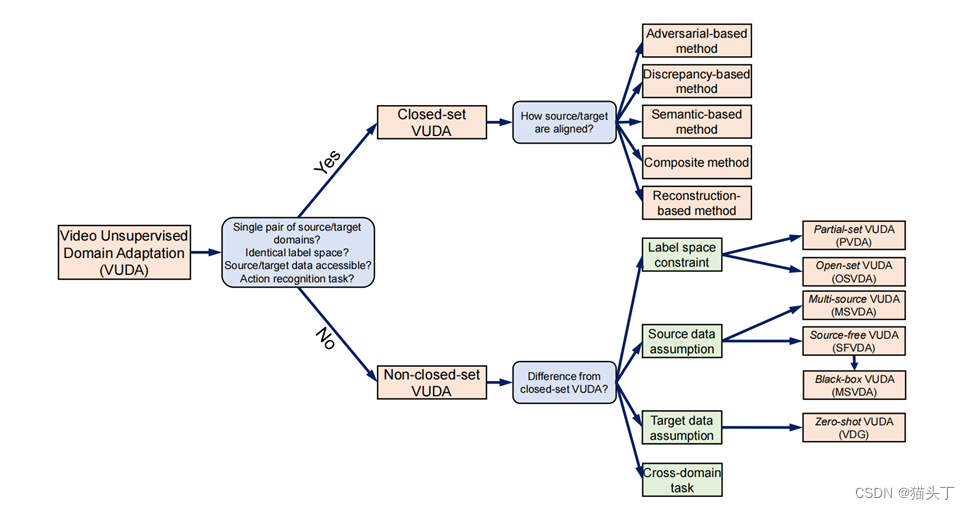
接下来,我们会分别从闭集VUDA相关工作和非闭集VUDA相关工作中选三篇比较有代表性的工作来讲,包括两篇闭集VUDA任务,分别使用基于对抗的方法和基于语义的方法,和一篇非闭集VUDA任务,即部分视频域自适应。
跨模态交互式对齐(CIA)Interact before align: Leveraging cross-modal knowledge for domain adaptive action recognition(CVPR 2022)
让我们来看第一篇文章吧!
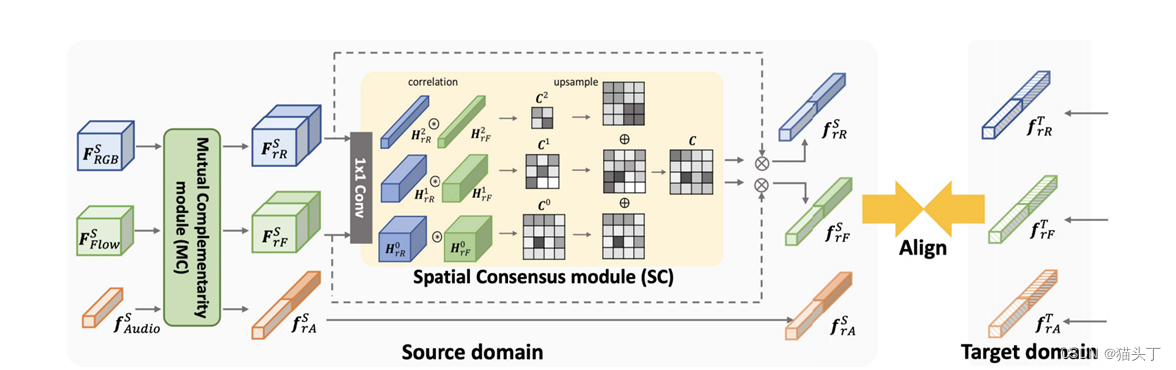
跨模态交互式对齐(CIA)将RGB、光流和音频模态对齐。CIA通过相互互补(MC)模块,不同的模态在跨源域和目标域对齐之前,通过从其他模式中吸收可转移的知识来增强了每个模态的可转移性。

背景
由于不同的特征,每个模态的可转移性(即特征跨域的不变性)是不同的和互补的。例如,对于目标域上的一个动作“洗杯”,由于水的声音在各个域上是相似的,所以音频模式更容易转移来确定动作的动词“清洗”。同时,RGB可以很好地识别目标域上的 “杯子”。如果这两种模式可以相互作用,交换它们独特的域可转移知识,它们都可以增强其可转移性,最终准确地确定动作“洗杯”。
以前的大多数工作利用多模态信息,通过单独对齐每个模态或通过跨模态自我监督学习表示。我们发现首先使用跨模态相互作用可以更有效地完成跨域对齐。跨模态知识交互允许其他模态基于跨模态互补性而补充缺失的可转移信息。
创新
我们提出了一种新的模型来增强多模态特征的域自适应动作识别。据我们所知,这是第一个考虑跨模态交互以增加特征跨域的可转移性的工作。
首先我们来看一下模型的整体结构,如下图所示,在源域S和目标域T中,对于RGB、光流和音频的每种模式,我们首先使用backbone将输入编码为帧级特征𝐹_𝑅𝐺𝐵^𝑆、 𝐹_𝐹𝑙𝑜𝑤^𝑆 、 𝐹_𝐴𝑢𝑑𝑖𝑜^𝑆 、 𝐹_𝑅𝐺𝐵^𝑇 、 𝐹_𝐹𝑙𝑜𝑤^𝑇 和𝐹_𝐴𝑢𝑑𝑖𝑜^𝑇 。然后,我们使用两个模块,即相互互补模块(MC)和空间共识模块(SC),分别允许特征交互来利用跨模态互补和跨模态共识。MC模块利用跨模态的互补性,使一个模态从其他模态接收可转移的语义知识,利用两个门控功能,SC模块强调可转移的空间区域。最后,我们对SC输出采用对抗性特征对齐,以最小化源域和目标域之间的差异。
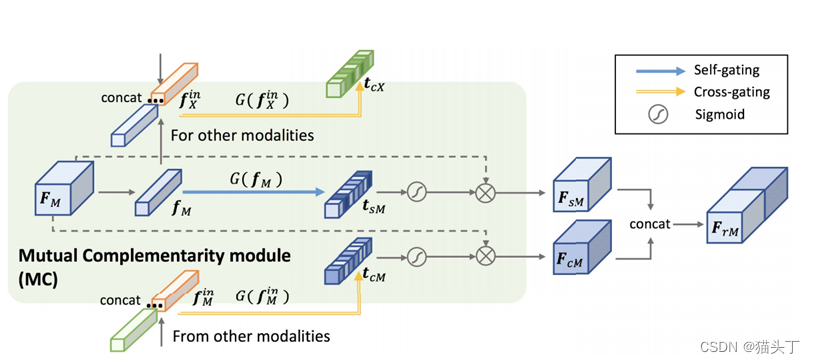
The Mutual Complementarity (MC) module
𝐹_𝑐𝑀代表了由其他模态的可转移知识细化的模态M的特征。首先将全局平均池应用于其他模式的特征,并将它们连接起来,获得其中的跨模态知识表示𝑓_𝑀𝑖𝑛。在𝑓_𝑀𝑖𝑛中,我们总结了域可转移的知识,并通过交叉门控函数重新评估了模态M的语义可转移性:
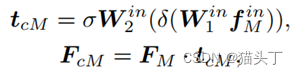
其中𝑊_1^𝑖𝑛 , 𝑊_2^𝑖𝑛为权值矩阵,σ和δ分别表示sigmond激活和ReLU激活。这里的𝑇_𝑐𝑀是利用跨模态知识对模态M的语义可转移性的重新评估,然后利用总结后的知识重新加权𝐹_𝑀的通道。
当从其他模态接收互补知识时,模态M保持自身独特的信息和模态特征也很重要。因此,除了交叉门控外,我们还使用了一个自我门控操作来对模态M进行自我重新评估:
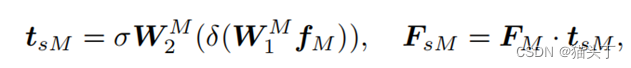
最后,我们将𝐹_𝑠𝑀和𝐹_𝑐𝑀这两个细化特征串联融合,得到了模态M的可转移性细化特征:
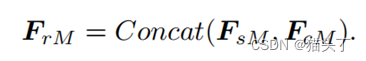
The Spatial Consensus (SC) module
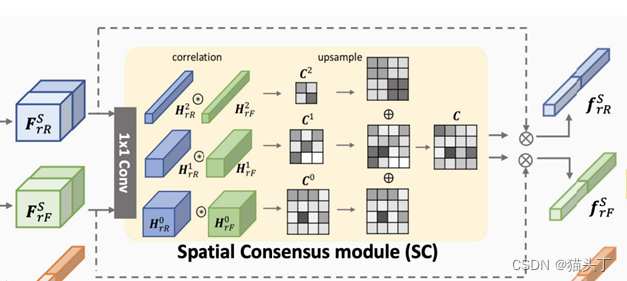
由于特征𝐹_𝑟𝑅𝑆和𝐹_𝑟𝐹𝑆编码不同的信息,首先将这些特征映射到相同的潜在空间,然后,我们计算特征相似度来衡量两种模式是否关于空间可转移性共享相同的观点。对于每个位置,只有当两种模态都发现该位置是可转移的时,特征相似性才会很高。
由于不同样本的可转移区域大小不同,我们计算了不同尺度下的特征图的相关性:特征𝐻_𝑟𝑅和𝐻_𝑟𝐹首先被降采样2k次,得到两组特征图{𝐻_𝑟𝑅^0 , 𝐻_𝑟𝑅^1 ,… 𝐻_𝑟𝑅^𝑘 ,}和{𝐻_𝑟𝐹^0 , 𝐻_𝑟𝐹^1 ,… 𝐻_𝑟𝐹^𝑘 ,}。对于每个尺度k,我们计算每个空间位置(i,j)上的Pearson相关系数为:
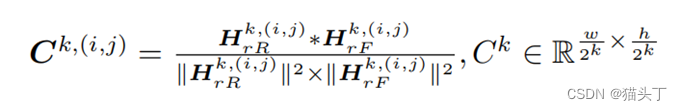
我们分别对𝑓_𝑟𝑅 、 𝑓_𝑟𝐹和𝑓_𝑟𝐴应用对抗性域对齐。将基于两层MLP的鉴别器表示为D,该鉴别器的损失可以写为:
其中,𝑓_𝑀表示{𝑓_𝑟𝑅 、 𝑓_𝑟𝐹 、 𝑓_𝑟𝐴}中的特征之一。
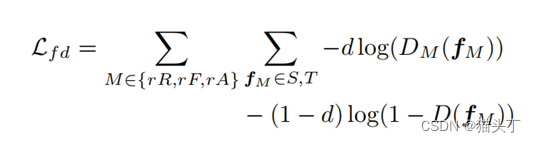
将帧级特征进行平均,形成视频级特征𝑣_𝑟𝑅 、 𝑣_𝑟𝐹和𝑣_𝑟𝐴 ,并将它们融合为𝑣_𝑚𝑚 。对视频级特征𝑣_𝑟𝑅 、 𝑣_𝑟𝐹和𝑣_𝑟𝐴也进行了域对齐,并将其损失记为𝑙_𝑣𝑑 。
在源域上,我们将标准的分类损失应用于融合的视频级特征𝑣_𝑚𝑚 其中, 𝐺_𝑀表示对应特征的动作分类器。
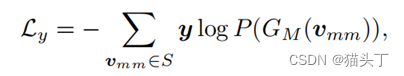
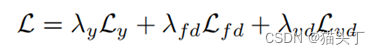
时空对比域自适应(STCDA)Spatio-temporal contrastive domain adaptation for action recognition(CVPR2021)
一种典型的基于语义的方法是时空对比域自适应(STCDA),STCDA通过基于视频的对比对齐(VCA)使类内源域和目标特征的距离最小,使类间源域和目标特征的距离最大化。通过对标记的源视频特征进行聚类,得到目标视频的标签。

Spatio-temporal Contrastive Learning
在clip级上,正样本是另一模态中的对应帧或相同模态中具有正确时间顺序的视频聚合,负样本是错误的时间顺序或错误的姿态帧。同样,在video级上,正样本是在另一种模态中对应的视频,而负样本是至少有一个负剪辑的聚合样本。
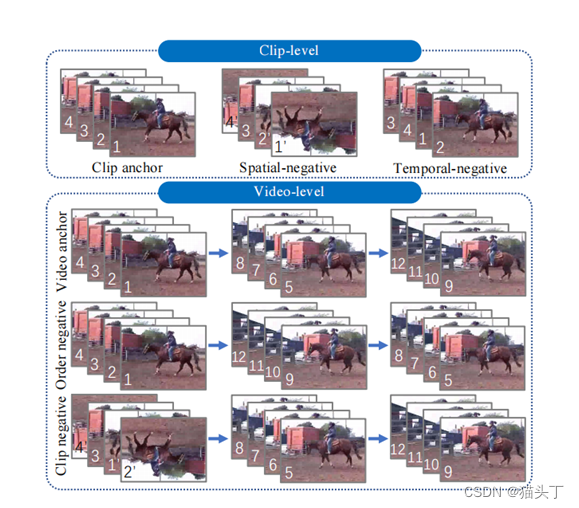
clip级和video级的时空对比损失分别定义如下:
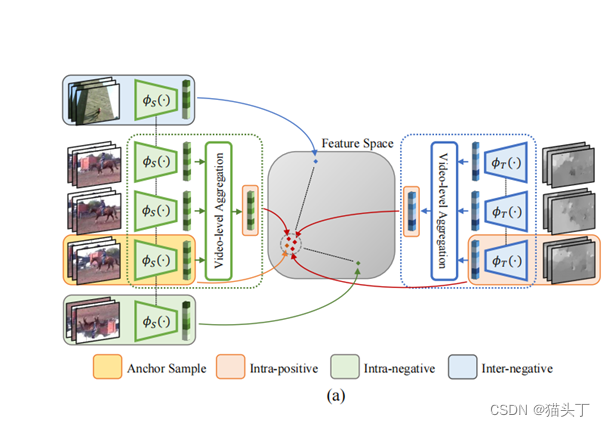
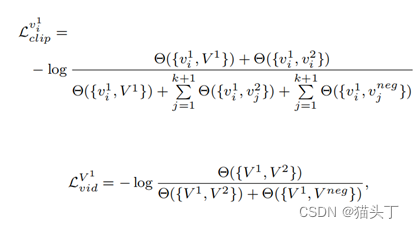
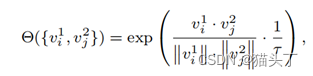
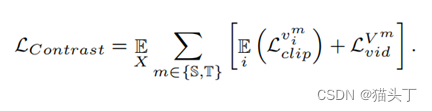
Video-based Contrastive Domain Alignment
我们提出了一种视频级分类感知距离度量,即基于视频的对比对齐(VCA),将源数据和目标数据映射到统一的特征空间,并测量源数据的类标签和目标数据伪标签的特征距离。该操作的目的是在clip/video样本的特征空间中,分离来自不同类别的表示,压缩来自同一类别的特征。
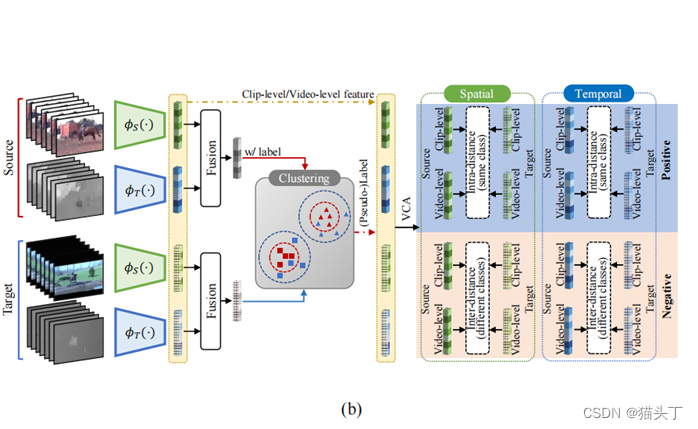
根据预测的伪标签,视频级域差异的距离计算定义如下:
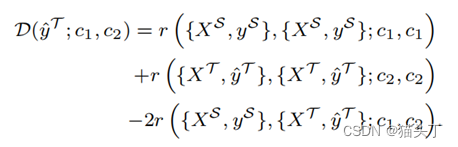
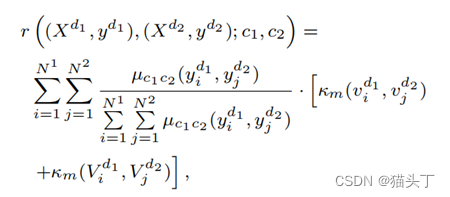
基于视频的对比对齐(VCA)目标如下
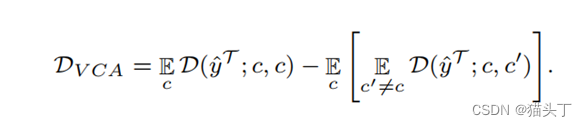

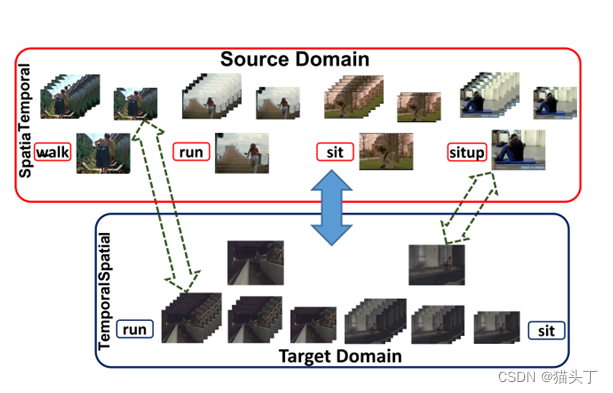
非闭集VUDA
上述的VUDA方法都是建立在几个约束和假设之上的。在过去的几年里,有各种各样的研究寻找不同的约束和假设,这样VUDA方法可以更适用于现实世界的场景,可以大致分为:
- ***具有不同标签空间约束的方法;***可以合理地假设,大规模的公共视频数据集可以包含小规模的目标数据集的类别。这种场景被定义为部分视频域自适应(PVDA)。
- ***具有不同源数据假设的方法;***源数据有可能从多个数据集收集。这个VUDA场景被定义为多源视频域自适应(MSVDA)。
- ***具有不同目标数据假设的方法;***闭集VUDA假设目标域数据是容易获得的。更实际的做法是假设在适应过程中目标域是不可见的(即目标域的数据不可用),定义为zero shot VUDA,或视频域泛化(VDG)。
- ***具有不同跨域任务的方法。***对于上述所有的工作,VUDA方法都是为跨域动作识别任务而设计的。除了动作识别外,对其他跨域视频任务还有多种研究,如跨域时间动作分割。
部分对抗时间注意网络(PATAN)Partial video domain adaptation with partial adversarial temporal attentive network(ICCV 2021)
**部分对抗时间注意网络(PATAN)**提出通过过滤目标域外标签来解决PVDA,以减轻负偏移。首先,PATAN构造了时间特征,通过局部时间特征的注意组合来更多关注对类过滤过程的贡献更大的局部时间特征。其次,PATAN利用时间特征进行仅源类过滤,以缓解空间特征错误分类的影响。

使当前对一般无监督域适应有效的方法无法在局部域适应取得较好表现得一个重要原因就是域外标签会对适应过程产生副作用,具体表现为使目标域中的数据对齐到源域中为标签为域外标签的数据,造成负适应(negative transfer)。在视频局部域适应中,这种负适应可能由时序特征造成。
例如:由于在两个域中“走”与“跑”的视频都是从摄像头近端向远端移动的场景,故而直觉上来说他们的时序信息(时序特征)很可能会比较相似。这就进一步导致在目标域中的关于“跑”的视频通过对齐到源域中的“走”的视频引发负适应。
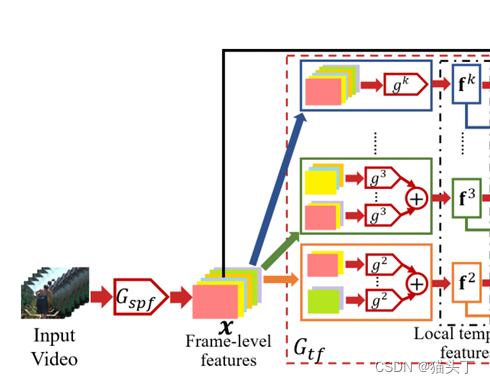
解决视频局部域适应问题的一个关键在于从视频中获取相对高效而又鲁棒的时序特征,因此提出使用时序关系网络(Temporal Relation Network TRN)作为特征提取器。TRN 提取的全局时序特征是由局部时序特征结合而来,而其局部时序特征是通过组合不同帧从而得到不同的帧间关系获得,如下图所示。
Vi的时间特征是由多个局部时间特征的组合构建的,每个特征都建立在r个时间有序采样帧的片段上,其中r∈[2,k]。在形式上,一个局部时间特征𝑓_𝑖^𝑟被定义为:
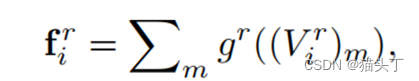
索引a和b可能不是连续的。通过函数𝑔𝑟融合时间有序的帧级特征,计算出𝑓_𝑖𝑟的局部时间特征
我们认为所要关注的即是对目标域外过滤起到更加关键作用的局部时序特征。这些局部时序特征之所以能对目标域外标签进行有效过滤是因为他们能较好的区分自己是否属于目标域标签亦或是目标域外标签。
故而这些局部特征的分类预测应该是较为确定的,根据这个我们设计了一个标签注意力机制(label attention),通过计算每个局部特征的分类预测置信度(预测熵值的负数)来对局部特征赋予权重,即标签注意力。
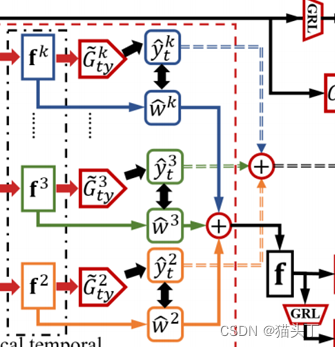
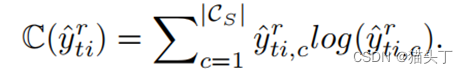
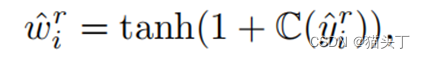
构建最后的全局时序特征是将所有的局部时序特征加权求和得到
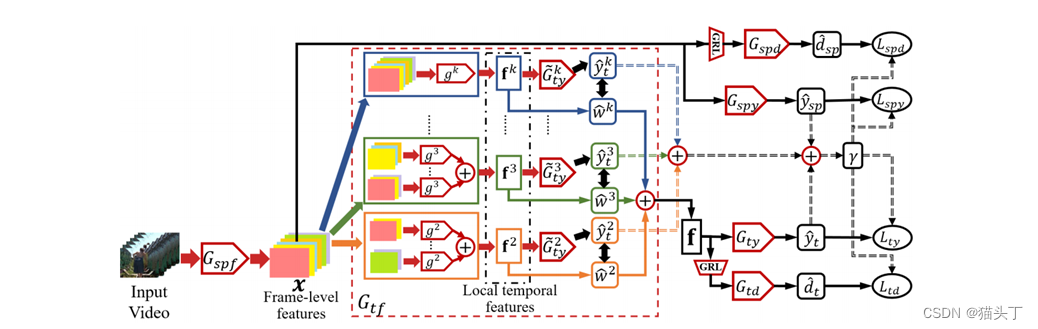
PATAN的总体优化目标表述为
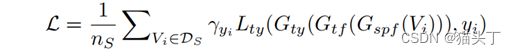
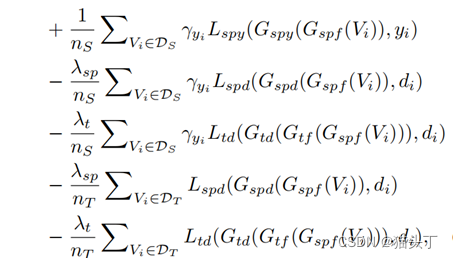
VUDA挑战
- 利用多模态信息
- 探索多种应用场景下的VUDA
- 更有效的VUDA自监督方法
相关文章:
【综述】视频无监督域自适应(VUDA)的小综述
【综述】视频无监督域自适应(VUDA)的小综述 一篇小综述,大家看个乐子就好,参考文献来自于一篇综述性论文 完整PPT已经上传资源:https://download.csdn.net/download/weixin_46570668/87848901?spm1001.2014.3001.550…...

《深入理解计算机系统(CSAPP)》第9章虚拟内存 - 学习笔记
写在前面的话:此系列文章为笔者学习CSAPP时的个人笔记,分享出来与大家学习交流,目录大体与《深入理解计算机系统》书本一致。因是初次预习时写的笔记,在复习回看时发现部分内容存在一些小问题,因时间紧张来不及再次整理…...

信息论与编码 SCUEC DDDD 期末复习
1.证明熵的可加性 2.假设一帧视频图像可以认为是由3*10的五次方个像素组成(每像素均独立变化),如果每个像素可取128个不同的等概率亮度表示。请计算出每帧图像含多少信息量?若有一口述者在约12000个汉字的字汇中选400个字来口述此…...
windows安装python开发环境
最近因工作需要,要学习一下python,所以先安装一下python的开发环境,比较简单 下载和安装Python 首先,在浏览器中打开Python的官方网站(https://www.python.org/downloads/) 然后,从该网站下载与你的操…...

java idea常用的快捷方式
文章目录 java idea常用的快捷方式快速复制选多行改变代码格式化 快速代码编辑psvmsout5.forarr.for快速死循环快速补全代码当方法还没创建的时候抽取具有一定功能的代码变成方法 java idea常用的快捷方式 快速复制 c t r l d \color{red}{ctrld} ctrld 选多行改变 A l t 鼠…...

lwIP 开发指南
目录 lwIP 初探TCP/IP 协议栈是什么TCP/IP 协议栈架构TCP/IP 协议栈的封包和拆包 lwIP 简介lwIP 源码下载lwIP 文件说明 MAC 内核简介PHY 芯片介绍YT8512C 简介LAN8720A 简介 以太网接入MCU 方案软件TCP/IP 协议栈以太网接入方案硬件TCP/IP 协议栈以太网接入方案 lwIP 无操作系…...

RabbitMQ消息属性详解
content-type属性 如同各种标准化的HTTP规范,content-type传输消息体的MIME类型。例如,如果你的应用程序正在发送JSON序列化的数据值,那么将content-type属性设置为application/json将允许尚待开发的消费者应用程序在收到消息时检查消息类型…...

shader 混合模式
在所有着色器执行完毕,所有纹理都被应用,所有像素准备被呈现到屏幕之后,使用Blend命令来操作这些像素进行混合。 3.2 blend的语法 BlendOff:关闭blend混合(默认值) BlendSrcFactor DstFactor :配置并启动混…...

【大数据工具】Hive 安装
Hive 环境搭建与基本使用 Hive 安装包下载地址:https://dlcdn.apache.org/hive/ 注:安装 Hive 前要先安装好 MySQL 1. MySQL 安装 MySQL 安装包下载地址:https://dev.mysql.com/downloads/mysql/archives/community/MySQL%20::%20Downloa…...

Android9.0 iptables用INetd实现app某个时间段禁止上网的功能实现
1.前言 在9.0的系统rom定制化开发中,在system中netd网络这块的产品需要中,会要求设置app某个时间段禁止上网的功能,liunx中iptables命令也是比较重要的,接下来就来在INetd这块实现app某个时间段禁止上网的的相关功能,就是在系统中只能允许某个app某个时间段禁止上网,就是…...

webpack.config.js基础配置(五大核心属性)
在上一节webpack零基础入门中我们在安装完webpack 和 webpack-cli依赖之后,直接通过npx webpack ./src/main.js --modedevelopment的方式对src下的js文件进行了打包。 其中的 ./src/main.js: 指定 Webpack 从 main.js 文件开始打包,不但会打包 main.js&a…...
【2023 B卷|200分】)
【华为OD机试】阿里巴巴找黄金宝箱(IV)【2023 B卷|200分】
【华为OD机试】-真题 !!点这里!! 【华为OD机试】真题考点分类 !!点这里 !! 题目描述 一贫如洗的樵夫阿里巴巴在去砍柴的路上,无意中发现了强盗集团的藏宝地, 藏宝地有编号从0-N的箱子,每个箱子上面有一个数字,箱子排列成一个环, 编号最大的箱子的下一个是编号为0的箱…...

Qt6 C++基础入门2 文件结构与信号和槽
目录 标准文件结构widget.hwidget.cppmain.cpppro 文件 信号与槽自定义信号connect 的两种方式 标准文件结构 widget.h widget 对象的头文件 一般会直接在头文件导入所有后续在 cpp 文件内用到的类,所以 include 基本都会写在这里 // 头文件标志起始 #ifndef WID…...
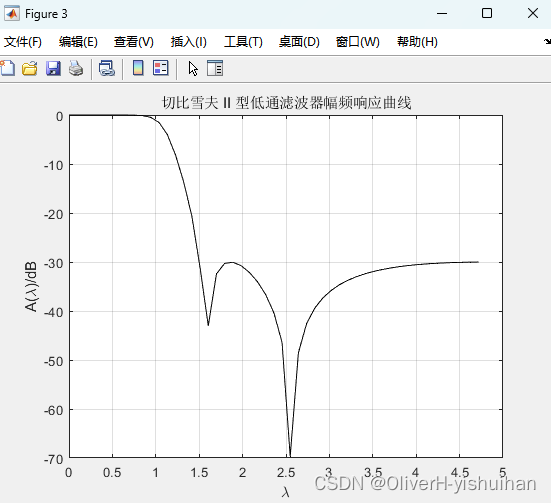
常用模拟低通滤波器的设计——契比雪夫II型滤波器
常用模拟低通滤波器的设计——契比雪夫II型滤波器 切比雪夫 II 型滤波器的振幅平方函数为: 式中,为有效带通截止频率, 是与通带波纹有关的参量, 大,波纹大,; 为 N 阶契比雪夫多项式。 在 Matl…...

SSM 如何使用 Redis 实现缓存?
SSM 如何使用 Redis 实现缓存? Redis 是一个高性能的非关系型数据库,它支持多种数据结构和多种操作,可以用于缓存、队列、计数器等场景。在 SSM(Spring Spring MVC MyBatis)开发中,Redis 可以用来实现数…...

uin-app如何获取微信昵称和头像的博客
在很多应用中都会使用到微信登录功能,这样可以方便用户快速地完成注册、登录等操作。本文将介绍如何通过uin-app获取微信用户的昵称和头像信息。 第一步:准备开发环境 首先,需要下载并安装QQ精简版开发工具(uin-app)…...

第六十七天学习记录:对陈正冲编著《C 语言深度解剖》中关于变量命名规则的学习
最近开始在阅读陈正冲编著的《C 语言深度解剖》,还没读到十分之一就感觉收获颇多。其中印象比较深刻的是其中的变量的命名规则。 里面提到的不允许使用拼音正是我有时候会犯的错。 因为在以往的工作中,偶尔会遇到时间紧迫的情况。 而对于新增加的变量不知…...

matlab 计算点云的线性指数
目录 一、算法原理二、代码实现三、结果展示一、算法原理 选取当前点 p i ( x , y , z ) p_{i}(x,y,z) p<...
SpringBoot集成ElasticSearch
文章目录 前言一、ElasticSearch本地环境搭建二、SpringBoot整合ElasticSearch1.pom中引入ES依赖2.application.yaml配置elasticsearch3.ElasticSearchClientConnect连接ES客户端工具类4.ElasticSearchResult封装响应结果5.Person实体类6.Person实体类7.ElasticsearchControlle…...

分治入门+例题
目录 🥇2.3.2 合并排序 🥇2.3.3 快速排序 🌼P1010 [NOIP1998 普及组] 幂次方 🌳总结 形象点,分治正如“凡治众如治寡,分数是也”,管理少数几个人,即可统领全军 本质ÿ…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...