推荐系统算法详解
文章目录
- 基于人口统计学的推荐算法
- 用户画像
- 基于内容的推荐算法
- 相似度计算
- 基于内容推荐系统的高层次结构
- 特征工程
- 数值型特征处理
- 类别特征处理
- 时间型特征处理
- 统计型特征处理
- 推荐系统常见反馈数据
- 基于UGC的推荐
- TF-IDF
- TF-IDF算法示例
- 1. 引入依赖
- 2. 定义数据和预处理
- 3. 进行词数统计
- 4. 计算词频TF
- 5. 计算逆文档频率idf
- 6. 计算TF-IDF
- 基于协同过滤的推荐算法
- 基于近邻的推荐
- 基于协同过滤的推荐优缺点
- 基于模型的协同过滤思想
- 隐语义模型(LFM)
- LFM降维方法——矩阵因子分解
- LFM进一步理解
- 矩阵因子分解
- 模型求解——损失函数
- 模型求解算法——ALS
- 梯度下降算法
- 代码实现
- 1. 引入依赖
- 2. 定义数据
- 3. 算法实现
- 4. 测试
常用推荐算法分类:
- 基于人口统计学的推荐与用户画像
- 基于内容的推荐和特征工程
- 基于协同过滤的推荐
基于人口统计学的推荐算法
- 基于人口统计学的推荐机制(Demographic-based Recommendation)是一种最易实现的推荐算法,它只是简单的根据系统用户的基本信息发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户
- 对于没有明确含义的用户信息(比如登录时间、地域等上下文信息),也可以通过聚类等手段,给用户打上分类标签。
- 对于特定标签的用户,又可以根据预设的规则(知识)或者模型,推荐出对应的物品
- 用户信息化的过程一般又称为用户画像(User Profile)
用户画像
- 用户画像(User Profile)就是企业通过收集与分析消费者社会属性、生活习惯、消费行为等主要信息的数据之后,完美地抽象出一个用户的商业全貌作为企业应用大数据技术的基本方式
- 用户画像为企业提供了足够的信息基础,能够帮助企业快速找到精准用户群体以及用户需求等更为广泛的反馈信息
- 作为大数据的根基,它完美地抽象出一个用户的信息全貌,为进一步精准、快速地分析用户行为习惯、消费习惯等重要信息,提供了足够的数据基础

基于内容的推荐算法

- Content-bashed Recommendation(CB)根据推荐物品或内容的元数据,发现物品的相关性,再基于用户过去的喜好记录,为用户推荐相似的物品。
- 通过抽取物品内在或者外在的特征值,实现相似度计算。
- 比如一个电影,有导演、演员、用户标签UGC、用户评论、时长、风格等等,都可以算是特征。、
- 将用户(user)个人信息的特征(基于喜好记录或是预设兴趣标签),和物品(item)的特征相匹配,就能得到用户对物品感兴趣的程度
- 在一些电影、音乐、图书的社交网络有很成功的应用,有些网站还请专业人员对物品进行基因编码/打标签(PGC)
- 对于物品的特征提取——打标签(tag)
- 专家标签(PGC)
- 用户自定义标签(UGC)
- 降维分析数据,提取隐语义标签(LFM)
- 对于文本信息的特征提取——关键字
- 分词、语义处理和情感分析(NLP)
- 潜在语义分析(LSA)
相似度计算

基于内容推荐系统的高层次结构

特征工程

- 特征(feature):数据中抽取出来的对结果预测有用的信息。
- 特征的个数就是数据的观测维度
- 特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程
- 特征工程一般包括特征清洗(采样、清洗异常样本),特征处理,特征选择。
- 特征按照不同的数据类型分类,有不同的特征处理方法:
- 数值型
- 类别型
- 时间型
- 统计型
数值型特征处理

- 归一化:


- 离散化:



类别特征处理
- 类别型特征本身没有大小关系,需要将它们编码为数字,它但们之间不能有预先设定的大小关系,因此既要做到公平,又要区分它们,那么直接开辟多个空间
- One-Hot编码/哑变量
- One-Hot编码/哑变量所做的就是将类别型数据平行地展开,也就是说,经过One-Hot编码/哑变量后,这个特征的空间会膨胀


时间型特征处理
时间特征既可以看做连续值,又可以看作离散值
- 连续值
- 持续时间(网页浏览时长)
- 间隔时间(上次购买/点击离现在的时间间隔)
- 离散值
- 一天中哪个时段
- 一周中的星期几
- 一年中的哪个月/星期
- 工作日/周末
统计型特征处理
- 加减平均:商品价格高于平均价格多少,用户在某个品类下消费超过多少。
- 分位线:商品属于售出商品价格的分位线处。
- 次序性:商品处于热门商品第几位。
- 比例类:电商中商品的好/中/差评比例。
推荐系统常见反馈数据

基于UGC的推荐

基于UGC简单推荐的问题:

TF-IDF


- TF-IDF对基于UGC推荐的改进:

TF-IDF算法示例
1. 引入依赖
import numpy as np
import pandas as pd
2. 定义数据和预处理
docA = "The cat sat on my bed"
docB = "The dog sat on my knees"bowA = docA.split(" ")
bowB = docB.split(" ")
bowA# 构建词库
wordSet = set(bowA).union(set(bowB))
wordSet
{'The', 'bed', 'cat', 'dog', 'knees', 'my', 'on', 'sat'}
3. 进行词数统计
# 用统计字典来保存词出现的次数
wordDictA = dict.fromkeys( wordSet, 0 )
wordDictB = dict.fromkeys( wordSet, 0 )# 遍历文档,统计词数
for word in bowA:wordDictA[word] += 1
for word in bowB:wordDictB[word] += 1pd.DataFrame([wordDictA, wordDictB])

4. 计算词频TF
def computeTF( wordDict, bow ):# 用一个字典对象记录tf,把所有的词对应在bow文档里的tf都算出来tfDict = {}nbowCount = len(bow)for word, count in wordDict.items():tfDict[word] = count / nbowCountreturn tfDicttfA = computeTF( wordDictA, bowA )
tfB = computeTF( wordDictB, bowB )
tfA
{'my': 0.16666666666666666,'on': 0.16666666666666666,'knees': 0.0,'dog': 0.0,'The': 0.16666666666666666,'sat': 0.16666666666666666,'cat': 0.16666666666666666,'bed': 0.16666666666666666}
5. 计算逆文档频率idf
def computeIDF( wordDictList ):# 用一个字典对象保存idf结果,每个词作为key,初始值为0idfDict = dict.fromkeys(wordDictList[0], 0)N = len(wordDictList)import mathfor wordDict in wordDictList:# 遍历字典中的每个词汇,统计Nifor word, count in wordDict.items():if count > 0:# 先把Ni增加1,存入到idfDictidfDict[word] += 1# 已经得到所有词汇i对应的Ni,现在根据公式把它替换成为idf值for word, ni in idfDict.items():idfDict[word] = math.log10( (N+1)/(ni+1) )return idfDictidfs = computeIDF( [wordDictA, wordDictB] )
idfs
{'cat': 0.17609125905568124,'on': 0.0,'sat': 0.0,'knees': 0.17609125905568124,'bed': 0.17609125905568124,'The': 0.0,'my': 0.0,'dog': 0.17609125905568124}
6. 计算TF-IDF
def computeTFIDF( tf, idfs ):tfidf = {}for word, tfval in tf.items():tfidf[word] = tfval * idfs[word]return tfidftfidfA = computeTFIDF( tfA, idfs )
tfidfB = computeTFIDF( tfB, idfs )pd.DataFrame( [tfidfA, tfidfB] )

基于协同过滤的推荐算法

-
基于内容(Content based,CB)主要利用的是用户评价过的物品的内容特征,而CF方法还可以利用其他用户评分过得物品内容
-
CF可以解决CB的一些局限:
- 物品内容不完全或者难以获得时,依然可以通过其他用户的反馈给出推荐
- CF基于用户之间物品的评价质量,避免了CB仅依赖内容可能造成的对物品质量的判断干扰
- CF推荐不受内容限制,只要其他类型用户给出了对不同的物品的兴趣,CF就可以给用户推荐出内容差异很大的物品(但有某种内在联系)
-
分为两类:基于近邻和基于模型
基于近邻的推荐

- 基于用户:

- 基于用户的协同过滤(User-CF):

- 基于物品:

- 基于物品的协同过滤(Item-CF):

- User-CF与Item-CF比较:

基于协同过滤的推荐优缺点
- 基于协同过滤的推荐机制的优点:
- 它不需要对物品或者用户进行严格的建模,而且不要求对物品特征的描述是机器可理解的,所以这种方式也是领域无关的
- 这种方法算出来的推荐是开放的,可以共用他人的经验,很好的支持用户发现潜在的兴趣偏好
- 存在的问题:
- 方法的核心是基于历史数据,所以对新物品和新用户都有“冷启动”的问题
- 推荐的效果依赖于用户历史偏好数据的多少和准确性
- 在大部分的实现中,用户历史偏好使用稀释矩阵进行存储的,而稀疏矩阵上的计算有些明显的问题,包括可能少部分人的错误偏好会对推荐的准确度有很大的影响等等
- 对一些特殊品味的用户不能给予很好的推荐
基于模型的协同过滤思想
-
基本思想:
- 用户具有一定的特征,决定着他的偏好选择;
- 物品具有一定的特征,影响着用户是否选择它;
- 用户之所以选某一个商品,是因为用户特征与物品特征相匹配;
-
基于这种思想,模型的建立相当于从行为数据总提取特征,给用户和物品同时打上“标签”;这和基于人口统计学的用户标签、基于内容方法的物品标签本质是一样的,都是特征提取和匹配
-
有显性特征时(比如用户标签,物品分类标签)我们可以直接匹配做出推荐;没有时,可以根据已有的偏好数据,去发掘出隐藏的特征,这需要用到隐语义模型(LFM)
-
基于模型的协同过滤推荐,就是基于样本的用户偏好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测新物品的得分,计算推荐
-
基于近邻的推荐和基于模型的推荐
- 基于近邻的推荐是在预测时直接使用已有的用户偏好数据,通过近邻数据来预测对新物品的偏好(类似分类)
- 而基于模型的方法,是要使用这些皮那好数据来训练模型,找到内在规律,再用模型来做预测(类似回归)
-
训练模型时,可以基于标签内容来提取物品特征,也可以让模型去发掘物品的潜在特征;这样的模型被称为隐语义模型(Latent Factor Model, LFM)
隐语义模型(LFM)
- 用隐语义模型来进行协同过滤的目标
- 揭示隐藏的特征,这些特征能够解释为什么给出对应的预测评分
- 这类特征可能是无法直接用语言解释描述的,事实上我们并不需要知道,类似“玄学“
- 通过矩阵分解进行降维分析
- 协同过滤算法非常依赖历史数据,而一般的推荐系统中,偏好数据又往往是稀疏的;这就需要对原始数据做降维处理
- 分解之后的矩阵,就代表了用户和物品的隐藏特征
- 隐语义模型的实例
- 基于概率的隐语义分析(pLSA )
- 隐式迪利克雷分布模型(LDA )
- 矩阵因子分解模型(基于奇异值分解的模型,SVD )
LFM降维方法——矩阵因子分解


LFM进一步理解
- 我们可以认为,用户之所以给电影打出这样的分数,是有内在原因的,我们可以挖掘出影响用户打分的隐藏因素,进而根据未评分电影与这些隐藏因素的关联度,决定此未评分电影的预测评分
- 应该有一些隐藏的因素,影响用户的打分,比如电影:演员、题材、年代…甚至不一定是人直接可以理解的隐藏因子
- 找到隐藏因子,可以对user和item进行关联(找到是由于什么使得user喜欢/不喜欢此item,什么会决定user喜欢/不喜欢此item),就可以推测用户是否会喜欢某一部未看完的电影

矩阵因子分解



模型求解——损失函数

模型求解算法——ALS





梯度下降算法

代码实现
1. 引入依赖
import numpy as np
import pandas as pd
2. 定义数据
# 评分矩阵R,6个用户对5个物品的评分
R = np.array([[4,0,2,0,1],[0,2,3,0,0],[1,0,2,4,0],[5,0,0,3,1],[0,0,1,5,1],[0,3,2,4,1],])
3. 算法实现
"""
@输入参数:
R:M*N 的评分矩阵
K:隐特征向量维度
max_iter: 最大迭代次数
alpha:步长
lamda:正则化系数@输出:
分解之后的 P,Q
P:初始化用户特征矩阵M*K
Q:初始化物品特征矩阵N*K
"""# 给定超参数K = 2 # 隐特征向量维度
max_iter = 5000 # 最大迭代次数
alpha = 0.0002 # 迭代步长
lamda = 0.004 # 正则化系数# 核心算法
def LFM_grad_desc( R, K=2, max_iter=1000, alpha=0.0001, lamda=0.002 ):# 基本维度参数定义M = len(R) # 行数N = len(R[0]) # 列数# P,Q初始值,随机生成 -> 随机梯度下降 P = np.random.rand(M, K) # 随机生成一个M*K的矩阵Q = np.random.rand(N, K) # 随机生成一个N*K的矩阵Q = Q.T # 将Q矩阵转置# 开始迭代for step in range(max_iter):# 对所有的用户u、物品i做遍历,对应的特征向量Pu、Qi梯度下降for u in range(M):for i in range(N):# 对于每一个大于0的评分,求出预测评分误差if R[u][i] > 0:eui = np.dot( P[u,:], Q[:,i] ) - R[u][i] # 算出误差# 代入公式,按照梯度下降算法更新当前的Pu、Qifor k in range(K):P[u][k] = P[u][k] - alpha * ( 2 * eui * Q[k][i] + 2 * lamda * P[u][k] )Q[k][i] = Q[k][i] - alpha * ( 2 * eui * P[u][k] + 2 * lamda * Q[k][i] )# u、i遍历完成,所有特征向量更新完成,可以得到P、Q,可以计算预测评分矩阵predR = np.dot( P, Q )# 计算当前损失函数cost = 0for u in range(M):for i in range(N):if R[u][i] > 0:cost += ( np.dot( P[u,:], Q[:,i] ) - R[u][i] ) ** 2# 加上正则化项for k in range(K):cost += lamda * ( P[u][k] ** 2 + Q[k][i] ** 2 )if cost < 0.0001:breakreturn P, Q.T, cost
4. 测试
P, Q, cost = LFM_grad_desc(R, K, max_iter, alpha, lamda)print(P)
print(Q)
print(cost)predR = P.dot(Q.T)print(R)
predR
[[ 1.42191162 1.03351644][ 1.72249312 0.62970942][ 1.65325684 -0.13902681][ 0.40523191 1.72699454][ 1.073343 1.77336266][ 1.46799251 0.7221439 ]]
[[ 0.89568365 2.63697244][ 1.24396992 0.68943122][ 1.41289734 -0.069854 ][ 2.3704516 1.24042426][ 0.34949845 0.46040278]]
2.305292572214812
[[4 0 2 0 1][0 2 3 0 0][1 0 2 4 0][5 0 0 3 1][0 0 1 5 1][0 3 2 4 1]]
array([[3.99893737, 2.4813538 , 1.9368199 , 4.65257155, 0.97278975],[3.20333531, 2.57687096, 2.38971822, 4.8641934 , 0.89192864],[1.11418525, 1.96075235, 2.34559377, 3.74651308, 0.51380237],[4.91699659, 1.69474026, 0.4519136 , 3.10278854, 0.93674101],[5.63768424, 2.55781799, 1.39264699, 4.74402969, 1.19159281],[3.21913046, 2.32400708, 2.02367808, 4.37557001, 0.84553816]])
相关文章:
推荐系统算法详解
文章目录 基于人口统计学的推荐算法用户画像 基于内容的推荐算法相似度计算基于内容推荐系统的高层次结构特征工程数值型特征处理类别特征处理时间型特征处理统计型特征处理 推荐系统常见反馈数据基于UGC的推荐TF-IDFTF-IDF算法示例1. 引入依赖2. 定义数据和预处理3. 进行词数统…...
企业网站架构部署与优化之LAMP
LAMP LAMP概述1、各组件的主要作用2、各组件安装顺序 编译安装Apache http服务编译安装MySQL服务编译安装PHP解析环境安装论坛 LAMP概述 LAMP架构是目前成熟的企业网站应用模式之一,指的是协同工作的一整套系统和相关软件,能够提供静态和动态Web站点服务…...
攻防世界安卓逆向练习
文章目录 一.easy-so1. jadx分析程序逻辑2. ida查看so文件3. 解题脚本: 二.ezjni1. 程序逻辑分析2. 解题脚本: 三.easyjava1. 主函数逻辑2. getIndex函数3. getChar函数4.解题脚本 四.APK逆向1.程序逻辑分析2.解题脚本3.动态调试 Android2.0app3 一.easy-so 1. jadx分析程序逻…...
)
自然语言处理从入门到应用——自然语言处理的语言模型(Language Model,LM)
分类目录:《自然语言处理从入门到应用》总目录 语言模型(Language Model,LM)(也称统计语言模型)是描述自然语言概率分布的模型,是一个非常基础和重要的自然语言处理任务。利用语言模型ÿ…...
【MySql】InnoDB一棵B+树可以存放多少行数据?
文章目录 背景一、怎么得到InnoDB主键索引B树的高度?二、小结三、最后回顾一道面试题总结参考资料 背景 InnoDB一棵B树可以存放多少行数据?这个问题的简单回答是:约2千万。为什么是这么多呢?因为这是可以算出来的,要搞…...
【综述】视频无监督域自适应(VUDA)的小综述
【综述】视频无监督域自适应(VUDA)的小综述 一篇小综述,大家看个乐子就好,参考文献来自于一篇综述性论文 完整PPT已经上传资源:https://download.csdn.net/download/weixin_46570668/87848901?spm1001.2014.3001.550…...

《深入理解计算机系统(CSAPP)》第9章虚拟内存 - 学习笔记
写在前面的话:此系列文章为笔者学习CSAPP时的个人笔记,分享出来与大家学习交流,目录大体与《深入理解计算机系统》书本一致。因是初次预习时写的笔记,在复习回看时发现部分内容存在一些小问题,因时间紧张来不及再次整理…...

信息论与编码 SCUEC DDDD 期末复习
1.证明熵的可加性 2.假设一帧视频图像可以认为是由3*10的五次方个像素组成(每像素均独立变化),如果每个像素可取128个不同的等概率亮度表示。请计算出每帧图像含多少信息量?若有一口述者在约12000个汉字的字汇中选400个字来口述此…...
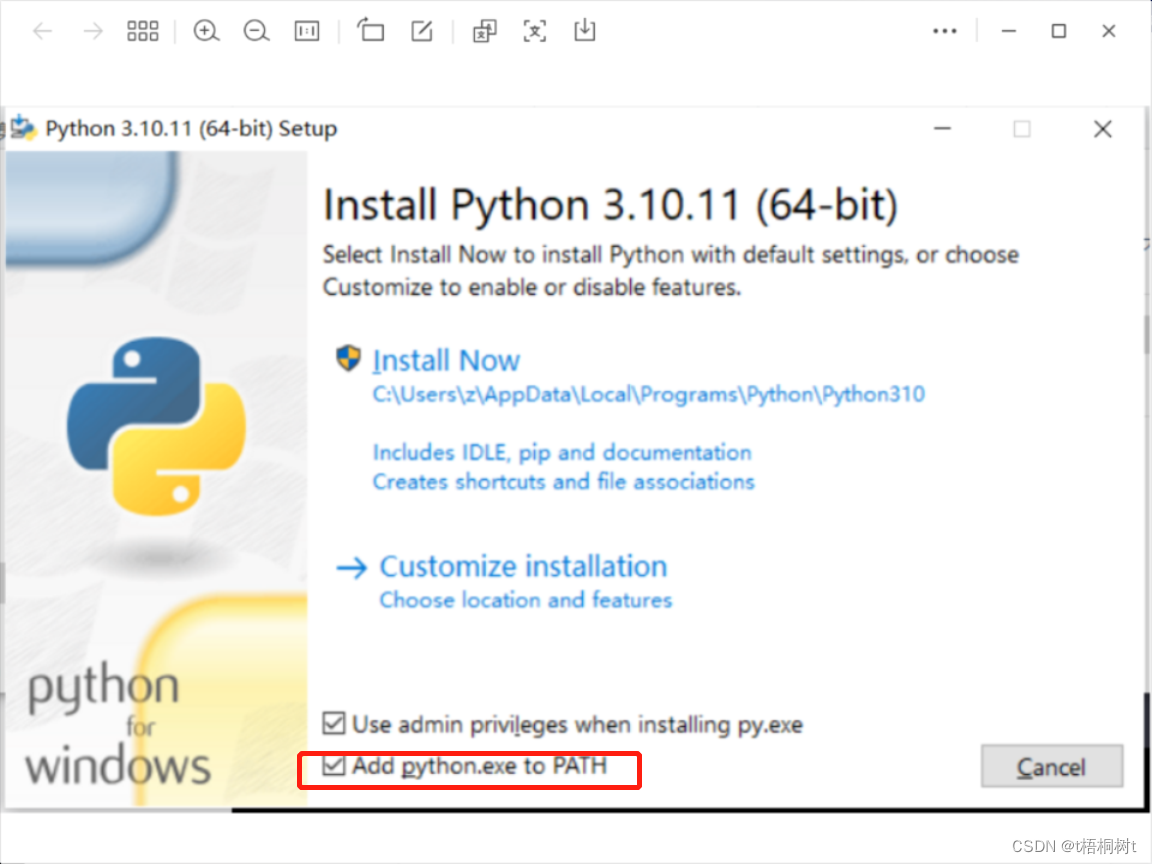
windows安装python开发环境
最近因工作需要,要学习一下python,所以先安装一下python的开发环境,比较简单 下载和安装Python 首先,在浏览器中打开Python的官方网站(https://www.python.org/downloads/) 然后,从该网站下载与你的操…...

java idea常用的快捷方式
文章目录 java idea常用的快捷方式快速复制选多行改变代码格式化 快速代码编辑psvmsout5.forarr.for快速死循环快速补全代码当方法还没创建的时候抽取具有一定功能的代码变成方法 java idea常用的快捷方式 快速复制 c t r l d \color{red}{ctrld} ctrld 选多行改变 A l t 鼠…...

lwIP 开发指南
目录 lwIP 初探TCP/IP 协议栈是什么TCP/IP 协议栈架构TCP/IP 协议栈的封包和拆包 lwIP 简介lwIP 源码下载lwIP 文件说明 MAC 内核简介PHY 芯片介绍YT8512C 简介LAN8720A 简介 以太网接入MCU 方案软件TCP/IP 协议栈以太网接入方案硬件TCP/IP 协议栈以太网接入方案 lwIP 无操作系…...

RabbitMQ消息属性详解
content-type属性 如同各种标准化的HTTP规范,content-type传输消息体的MIME类型。例如,如果你的应用程序正在发送JSON序列化的数据值,那么将content-type属性设置为application/json将允许尚待开发的消费者应用程序在收到消息时检查消息类型…...

shader 混合模式
在所有着色器执行完毕,所有纹理都被应用,所有像素准备被呈现到屏幕之后,使用Blend命令来操作这些像素进行混合。 3.2 blend的语法 BlendOff:关闭blend混合(默认值) BlendSrcFactor DstFactor :配置并启动混…...

【大数据工具】Hive 安装
Hive 环境搭建与基本使用 Hive 安装包下载地址:https://dlcdn.apache.org/hive/ 注:安装 Hive 前要先安装好 MySQL 1. MySQL 安装 MySQL 安装包下载地址:https://dev.mysql.com/downloads/mysql/archives/community/MySQL%20::%20Downloa…...

Android9.0 iptables用INetd实现app某个时间段禁止上网的功能实现
1.前言 在9.0的系统rom定制化开发中,在system中netd网络这块的产品需要中,会要求设置app某个时间段禁止上网的功能,liunx中iptables命令也是比较重要的,接下来就来在INetd这块实现app某个时间段禁止上网的的相关功能,就是在系统中只能允许某个app某个时间段禁止上网,就是…...

webpack.config.js基础配置(五大核心属性)
在上一节webpack零基础入门中我们在安装完webpack 和 webpack-cli依赖之后,直接通过npx webpack ./src/main.js --modedevelopment的方式对src下的js文件进行了打包。 其中的 ./src/main.js: 指定 Webpack 从 main.js 文件开始打包,不但会打包 main.js&a…...
【2023 B卷|200分】)
【华为OD机试】阿里巴巴找黄金宝箱(IV)【2023 B卷|200分】
【华为OD机试】-真题 !!点这里!! 【华为OD机试】真题考点分类 !!点这里 !! 题目描述 一贫如洗的樵夫阿里巴巴在去砍柴的路上,无意中发现了强盗集团的藏宝地, 藏宝地有编号从0-N的箱子,每个箱子上面有一个数字,箱子排列成一个环, 编号最大的箱子的下一个是编号为0的箱…...

Qt6 C++基础入门2 文件结构与信号和槽
目录 标准文件结构widget.hwidget.cppmain.cpppro 文件 信号与槽自定义信号connect 的两种方式 标准文件结构 widget.h widget 对象的头文件 一般会直接在头文件导入所有后续在 cpp 文件内用到的类,所以 include 基本都会写在这里 // 头文件标志起始 #ifndef WID…...
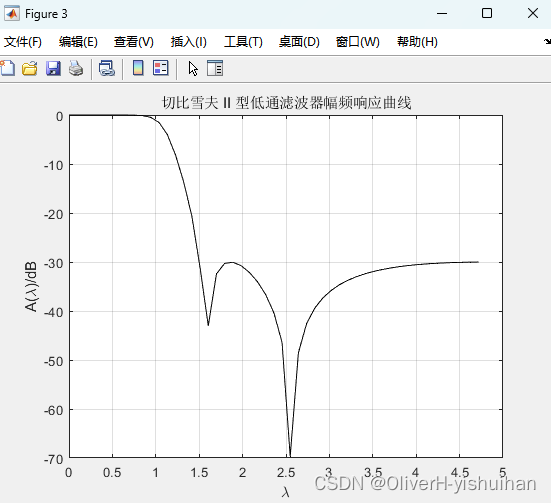
常用模拟低通滤波器的设计——契比雪夫II型滤波器
常用模拟低通滤波器的设计——契比雪夫II型滤波器 切比雪夫 II 型滤波器的振幅平方函数为: 式中,为有效带通截止频率, 是与通带波纹有关的参量, 大,波纹大,; 为 N 阶契比雪夫多项式。 在 Matl…...

SSM 如何使用 Redis 实现缓存?
SSM 如何使用 Redis 实现缓存? Redis 是一个高性能的非关系型数据库,它支持多种数据结构和多种操作,可以用于缓存、队列、计数器等场景。在 SSM(Spring Spring MVC MyBatis)开发中,Redis 可以用来实现数…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...