solr教程
一:安装配置
下载完成之后,解压solr文件,解压tomcat
1.1 在tomcat安装solr,并且建立solrCore
- 把solr5.5目录下的server/solr-webapp/webapp 重命名为solr,并且放置到tomcat/webapp的目录下。
- 打开tomcat/webapp/solr/WEB-INF/web.xml
- 新建一个文件夹,不要中文目录,用来做solrHome,也就是solrCore的实例存放位置
- 在tomcat/webapp/solr/WEB-INF/web.xml中配置solr的地址
-
-
在tomcat/webapp/solr/WEB-INF/文件夹中,建立classes目录
- 把solr5.5/server/resource/log4j.properties 复制到上一步建立的classes目录中
- 把solr5.5/server/lib/ext/目录下的所有jar文件复制到tomcat/webapp/solr/WEB-INF/lib/中,这是一些日志用的jar包,不然启动报错。
- 这个时候,可以输入http://127.0.0.1:8080/solr/admin.html来访问到solr的控制界面了。
- 接下来就是创建solrCore。
- 目前solrHome目录是空的,我们创建一个空文件夹core1,这个就是我们的一个实例,然后把solr5.5/server/solr/configsets/sample_techproducts_configs/conf/ 这个文件复制到solrHome/core1中。
- 把solr5.5/server/solr/solr.xml复制到solrHome目录下。
- 在solr的管理控制台界面,添加一个core1
-
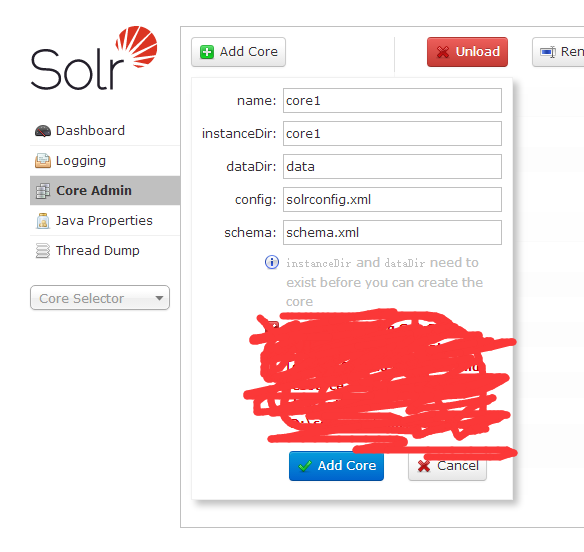
- 这下就创建成功了一个实例core1,yge 请注意我打码的部分,需要先执行第11步操作,否则的话,会无法创建solr core,也就是会有错误信息,这是solr的一个bug,但是至今没有修复。
1.2 安装ik中文分词器
- 准备好ik分词器的jar包,可以自己编译,也可以下载我生成的。然后把它复制到tomcat/webapp/solr/WEB-INF/lib里面。(千万不要复制到tomcat/lib中,这样会找不到lucene的类)
- 打开solrHome/core1/conf/managed-schema文件,在最下方,追加如下配置
-

<fieldType name="text_ik" class="solr.TextField"><analyzer type="index" useSmart="false"class="org.wltea.analyzer.lucene.IKAnalyzer" /><analyzer type="query" useSmart="true"class="org.wltea.analyzer.lucene.IKAnalyzer" /></fieldType>

- 启动tomcat,即可看到text_ik分词
-
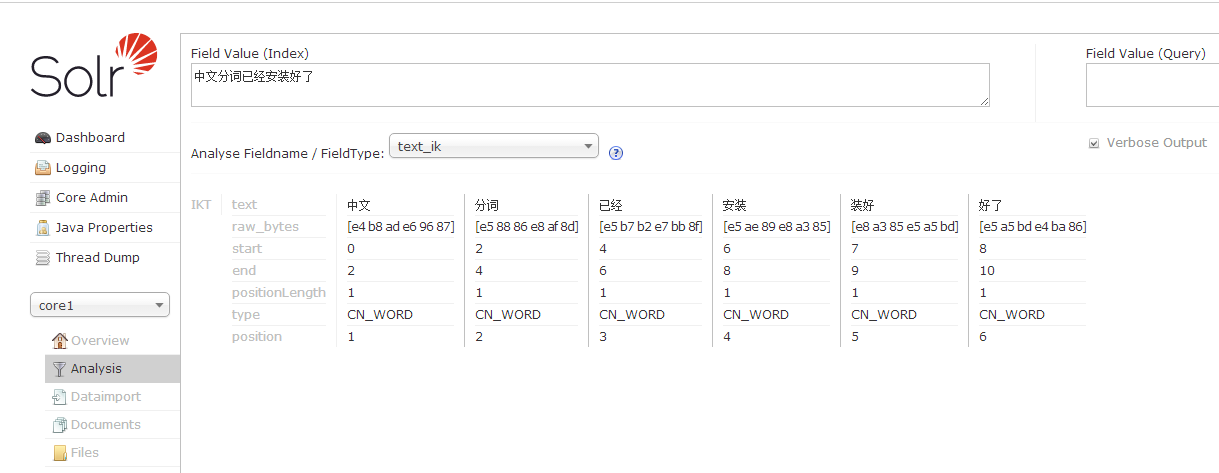
1.3 插入的文档必须与域相匹配
域,我个人也称它为字段,它在solr中有特定的含义,就类似数据库中表的列一样,规范着写入的数据,我们先来做个例子。
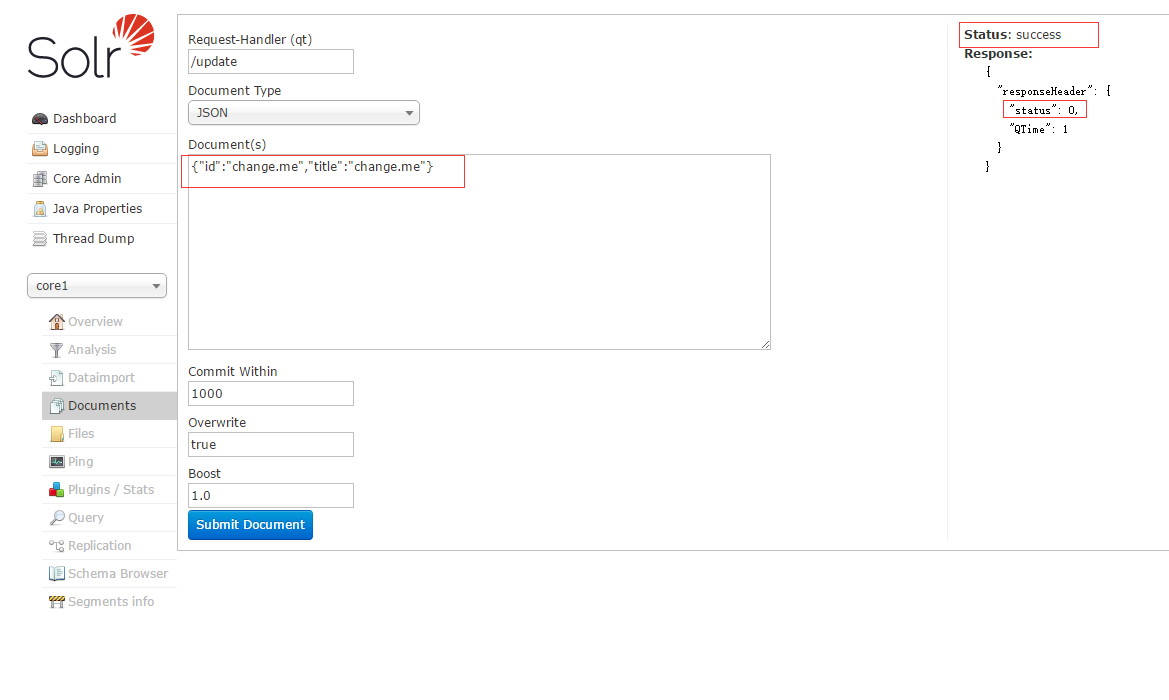
可以看到,我这次插入的文档,有id,title当然,在solr中,每一条记录都必须有着一个唯一的id,它就类似数据库中的主键,不可重复。这条记录的插入是成功的。
但是,如果我把title改成title1,这就与定义的字段不一样了,就会报错,如下图所示

可以看到,这里提示,未知的字段 title1.
1.4 域的定义 field
先拿出一条配置来看一下
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
认识一下这些属性
name:域名
type:域的类型,必须匹配类型,不然会报错
indexed:是否要作索引
stored:是否要存储
required:是否必填,一般只有id才会设置
multiValued:是否有多个值,如果设置为多值,里面的值就采用数组的方式来存储,比如商品图片地址(大图,中图,小图等)
1.5 配置动态域 dynamicField
同样的,也先拿出一条来看看
<dynamicField name="*_i" type="string" indexed="true" stored="true" multiValued="true" />
何谓动态域呢?就是这个域的名称,是由表达式组成的,只要名称满足了这个 表达式,就可以用这个域
同样的认识一下这些属性
name:域的名称,该域的名称是通过一个表达式来指定的,只要符合这这个规则,就可以使用这个域。比如 aa_i,bb_i,13_i等等,只要满足这个表达式皆可
type:对应的值类型,相应的值必须满足这个类型,不然就会报错
indexed:是否要索引
stored:是否要存储
...其它的属性与普通的域一至
1.6 主键域 uniqueKey
给出一条配置
<uniqueKey>id</uniqueKey>
指定一个唯一的主键,每一个文档中,都应该有一个唯一的主键,这个值不要随便改
1.7 复制域 copyField
给出一条配置
<copyField source="cat" dest="text"/>
说明一下相应的属性
source:源域
dest:目标域
复制域,将源域的内容复制到目标域中
注意:目标域必须是允许多值的,如下,nultiValued必须为true,因为可能多个源域对应一个目标域,所以它需要以数组来存储
<field name="text" type="string" indexed="true" stored="true" multiValued="true"/>
1.8 域的类型 fieldType
同样的给出一段配置,这段稍微有点复杂

<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100"><analyzer type="index"><tokenizer class="solr.StandardTokenizerFactory"/><filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /><!-- in this example, we will only use synonyms at query time<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>--><filter class="solr.LowerCaseFilterFactory"/></analyzer><analyzer type="query"><tokenizer class="solr.StandardTokenizerFactory"/><filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /><filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/><filter class="solr.LowerCaseFilterFactory"/></analyzer></fieldType>

给出相应属性的说明
name:域的名称
class:指定solr的类型
analyzer:分词器的配置
type: index(索引分词器),query(查询分词器)
tokenizer:配置分词器
filter:过滤器
1.9 业务字段的实际配置
经过上面的学习,差不多了解了一些常用的配置,如今我们用field来配置实际的业务字段,有属性如下
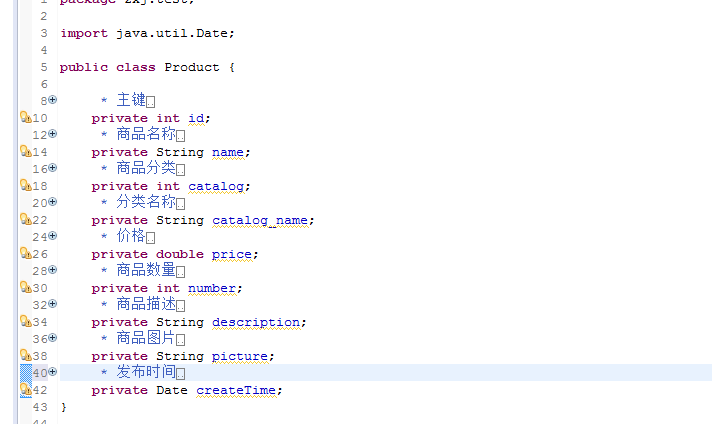
当然,中文分词还是要用的,因为我们在前面的 1.2 章节中,已经配置了一个fieldType的中文分词,所以我们现在一律用中文分词的域类型
主键的id就不需要配置了,默认已经把id配置为主键了,默认的配置如下
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
商品名称(需要分词,需要存储)
<field name="name" type="text_ik" indexed="true" stored="true" />
商品分类(不需要分词,需要存储)
<field name="catalog" type="int" indexed="false" stored="true" />
商品分类名称(需要分词,需要存储)
<field name="catalog_name" type="text_ik" indexed="true" stored="true" />
商品价格(不分词,需要存储)
<field name="price" type="double" indexed="false" stored="true" />
商品描述(需要分词,不需要存储)
<field name="description" type="text_ik" indexed="true" stored="false" />
商品图片(不需要分词,需要存储)
<field name="picture" type="string" indexed="false" stored="true" />
复制域的应用
前面我们了解了复制域,但是却不知道它的应用场景,现在我们结合实际情况来讲一下复制域
用户在搜索框搜索的时候,有可能输入的是商品名称,也有可能输入的是商品描述,也有可能输入的是一个商品类型,那么这些值的搜索,肯定在后台是对应一个域的,那么既然如此,我们就可以把这些域合并成一个,这样在后台只需要单独的对这一个域进行搜索就可以了
先定义一个目标域
<field name="keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
复制域,把商品名称,商品描述,商品类型名称复制到上面的这个域中
<copyField source="name" dest="keywords"/> <copyField source="catalog_name" dest="keywords"/> <copyField source="description" dest="keywords"/>
1.10 dataimport 导入数据库数据
solr默认是没有开启dataimport这个功能的,所以我们要经过一点配置来开启它
- 首先找到solr5.5/dist/solr-dataimporthandler-5.5.2.jar,把这个文件复制到tomcat/webapp/solr/WEB-INF/lib/下,并且找到相应数据库的驱动包,也同样放到该目录。我这里用的是mysql的驱动包。
- 找到solr5.5/example/example-DIH/solr/db/conf/db-data-config.xml,把其复制到solrHome/core1/conf/下,并改名为data-config.xml.
- 找到solrHome/core1/conf/solrconfig.xml,并打开,在里面添加一段内容,如下
-
<requestHandler name="/dataimport" class="solr.DataImportHandler"><lst name="defaults"><str name="config">data-config.xml</str></lst></requestHandler>
- 打开并编辑data-config.xml,完整的配置文件如下
-

<dataConfig><!-- 这是mysql的配置,学会jdbc的都应该看得懂 --><dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/solr/useUnicode=true&characterEncoding=utf-8" user="root" password="密码"/><document><!-- name属性,就代表着一个文档,可以随便命名 --><!-- query是一条sql,代表在数据库查找出来的数据 --><entity name="product" query="select * from products"><!-- 每一个field映射着数据库中列与文档中的域,column是数据库列,name是solr的域(必须是在managed-schema文件中配置过的域才行) --><field column="pid" name="id"/><field column="name" name="product_name"/><field column="catalog" name="product_catalog"/><field column="catalog_name" name="product_catalog_name"/><field column="price" name="product_price"/><field column="description" name="product_description"/><field column="picture" name="product_picture"/></entity></document> </dataConfig>

- 重启tomcat,然后会看到如下页面
-
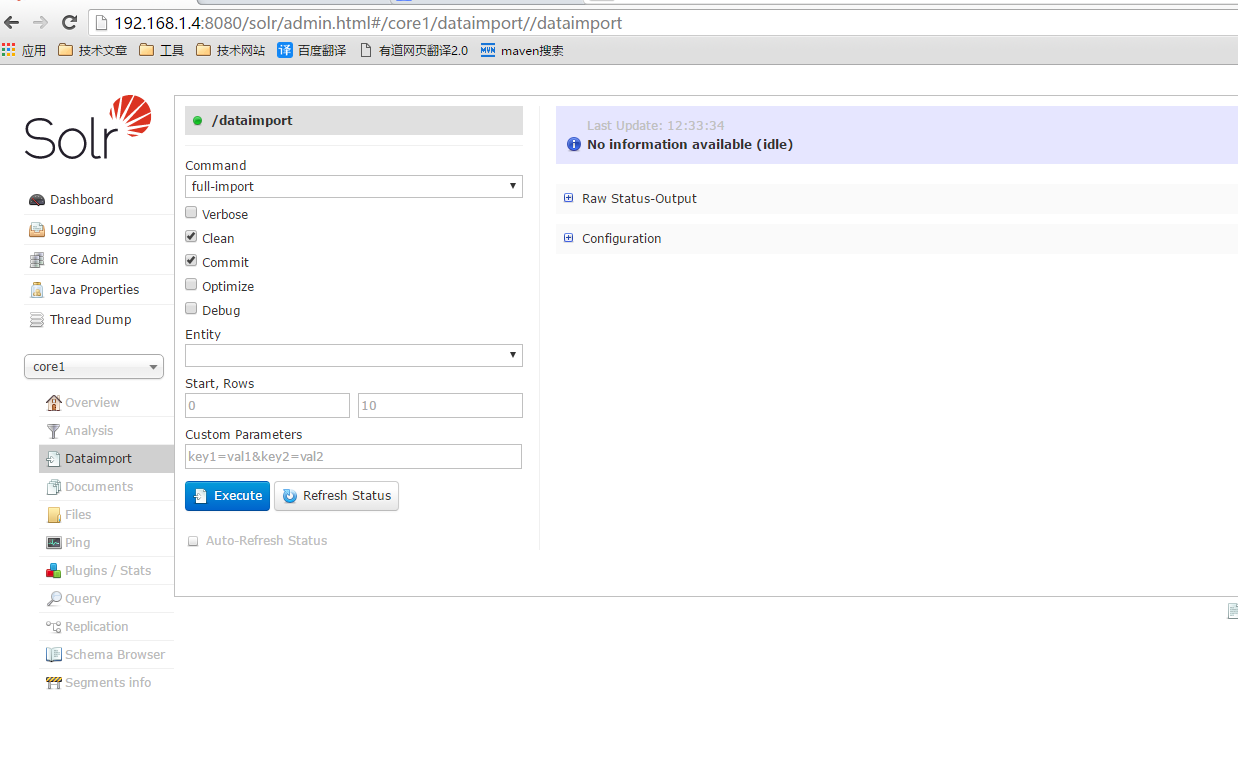
- 点击蓝色的按钮,则开始导入,导入过程依据数量量的大小,需要的时间也不同,可以点击右边的Refresh status来刷新状态,可以查看当前导入了多少条。
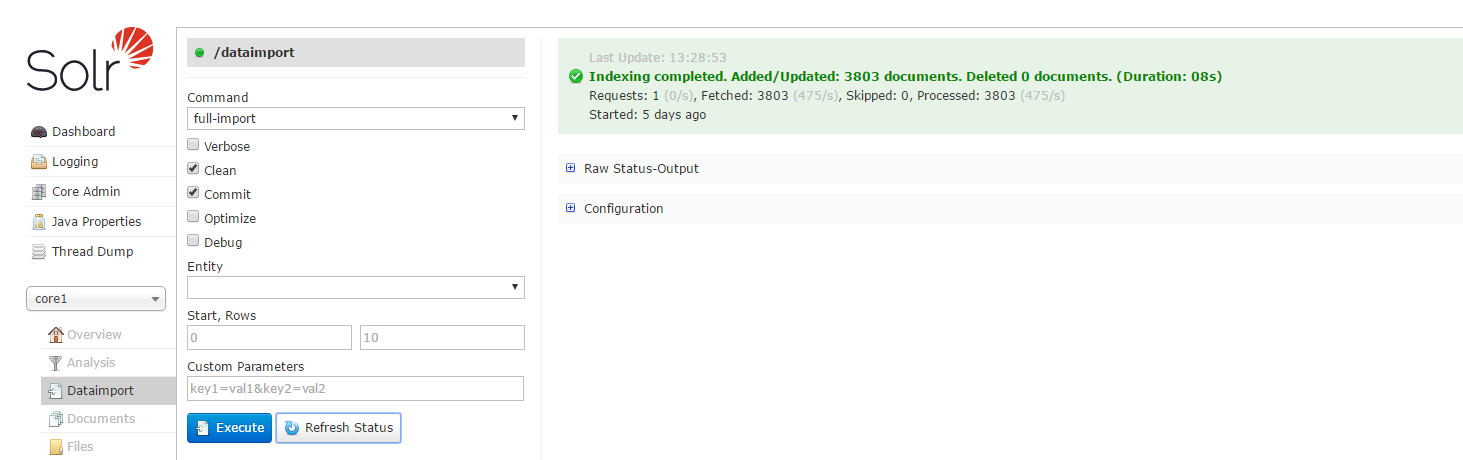
- 导入成功如下
-
二:solrj的使用
上面一章节已经讲完了solr的安装与配置,现在说一下使用solrj来维护solr的索引及操作,solrj就是一个java的客户端,是一个jar包的使用
首先引入MAVEN的依赖,solrj的版本号要对应solr的版本号
<dependency><groupId>org.apache.solr</groupId><artifactId>solr-solrj</artifactId><version>5.5.2</version></dependency>
2.1 增加及修改
首先说明,在solr中,增加与修改都是一回事,当这个id不存在时,则是添加,当这个id存在时,则是修改
代码很好理解,直接给出

private String serverUrl = "http://192.168.1.4:8080/solr/core1";/*** 增加与修改<br>* 增加与修改其实是一回事,只要id不存在,则增加,如果id存在,则是修改* @throws IOException * @throws SolrServerException */@Testpublic void upadteIndex() throws SolrServerException, IOException{//已废弃的方法//HttpSolrServer server = new HttpSolrServer("http://192.168.1.4:8080/solr/core1");//创建HttpSolrClient client = new HttpSolrClient(serverUrl);SolrInputDocument doc = new SolrInputDocument();doc.addField("id", "zxj1");doc.addField("product_name", "javaWEB技术");doc.addField("product_catalog", "1");doc.addField("product_catalog_name", "书籍");doc.addField("product_price", "11");doc.addField("product_description", "这是一本好书");doc.addField("product_picture", "图片地址");client.add(doc);client.commit();client.close();}

2.2 删除索引
删除的代码也直接给出,看代码里面的注释就可以了

/*** 删除索引* @throws Exception*/@Testpublic void deleteIndex()throws Exception{HttpSolrClient client = new HttpSolrClient(serverUrl);//1.删除一个client.deleteById("zxj1");//2.删除多个List<String> ids = new ArrayList<>();ids.add("1");ids.add("2");client.deleteById(ids);//3.根据查询条件删除数据,这里的条件只能有一个,不能以逗号相隔client.deleteByQuery("id:zxj1");//4.删除全部,删除不可恢复client.deleteByQuery("*:*");//一定要记得提交,否则不起作用client.commit();client.close();}

2.3 查询
查询稍微复杂一点,但是与solr管理界面的条件一致
- q - 查询字符串,如果查询所有*:* (id:1)
- fq - (filter query)过虑查询,过滤条件,基于查询出来的结果
- fl - 指定返回那些字段内容,用逗号或空格分隔多个。
- start - 分页开始
- rows - 分页查询数据
- sort - 排序,格式:sort=<field name>+<desc|asc>[,<field name>+<desc|asc>]… 。示例:(score desc, price asc)表示先 “score” 降序, 再 “price” 升序,默认是相关性降序。
- wt - (writer type)指定输出格式,可以有 xml, json, php, phps。
- fl表示索引显示那些field( *表示所有field,如果想查询指定字段用逗号或空格隔开(如:Name,SKU,ShortDescription或Name SKU ShortDescription【注:字段是严格区分大小写的】))
- q.op 表示q 中 查询语句的 各条件的逻辑操作 AND(与) OR(或)
- hl 是否高亮 ,如hl=true
- hl.fl 高亮field ,hl.fl=Name,SKU
- hl.snippets :默认是1,这里设置为3个片段
- hl.simple.pre 高亮前面的格式
- hl.simple.post 高亮后面的格式
- facet 是否启动统计
- facet.field 统计field
1. “:” 指定字段查指定值,如返回所有值*:*
2. “?” 表示单个任意字符的通配
3. “*” 表示多个任意字符的通配(不能在检索的项开始使用*或者?符号)
4. “~” 表示模糊检索,如检索拼写类似于”roam”的项这样写:roam~将找到形如foam和roams的单词;roam~0.8,检索返回相似度在0.8以上的记录。
5. 邻近检索,如检索相隔10个单词的”apache”和”jakarta”,”jakarta apache”~10
6. “^” 控制相关度检索,如检索jakarta apache,同时希望去让”jakarta”的相关度更加好,那么在其后加上”^”符号和增量值,即jakarta^4 apache
7. 布尔操作符AND、||
8. 布尔操作符OR、&&
9. 布尔操作符NOT、!、- (排除操作符不能单独与项使用构成查询)
10. “+” 存在操作符,要求符号”+”后的项必须在文档相应的域中存在
11. ( ) 用于构成子查询
12. [] 包含范围检索,如检索某时间段记录,包含头尾,date:[200707 TO 200710]
给出基本的代码看一下,仅仅作为一个基本的查询,高级的查询,各位要自己结合文档

package zxj.solrj;import java.util.List;
import java.util.Map;import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.junit.Test;/*** 搜索* @author Administrator**/
public class IndexSearch {private String serverUrl = "http://192.168.1.4:8080/solr/core1";@Testpublic void search()throws Exception{HttpSolrClient client = new HttpSolrClient(serverUrl);//创建查询对象SolrQuery query = new SolrQuery();//q 查询字符串,如果查询所有*:*query.set("q", "product_name:小黄人");//fq 过滤条件,过滤是基于查询结果中的过滤query.set("fq", "product_catalog_name:幽默杂货");//sort 排序,请注意,如果一个字段没有被索引,那么它是无法排序的
// query.set("sort", "product_price desc");//start row 分页信息,与mysql的limit的两个参数一致效果query.setStart(0);query.setRows(10);//fl 查询哪些结果出来,不写的话,就查询全部,所以我这里就不写了
// query.set("fl", "");//df 默认搜索的域query.set("df", "product_keywords");//======高亮设置===//开启高亮query.setHighlight(true);//高亮域query.addHighlightField("product_name");//前缀query.setHighlightSimplePre("<span style='color:red'>");//后缀query.setHighlightSimplePost("</span>");//执行搜索QueryResponse queryResponse = client.query(query);//搜索结果SolrDocumentList results = queryResponse.getResults();//查询出来的数量long numFound = results.getNumFound();System.out.println("总查询出:" + numFound + "条记录");//遍历搜索记录//获取高亮信息Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting();for (SolrDocument solrDocument : results) {System.out.println("商品id:" + solrDocument.get("id"));System.out.println("商品名称 :" + solrDocument.get("product_name"));System.out.println("商品分类:" + solrDocument.get("product_catalog"));System.out.println("商品分类名称:" + solrDocument.get("product_catalog_name"));System.out.println("商品价格:" + solrDocument.get("product_price"));System.out.println("商品描述:" + solrDocument.get("product_description"));System.out.println("商品图片:" + solrDocument.get("product_picture"));//输出高亮 Map<String, List<String>> map = highlighting.get(solrDocument.get("id"));List<String> list = map.get("product_name");if(list != null && list.size() > 0){System.out.println(list.get(0));}}client.close();}
}
注意:没有索引的域,是不能用作排序的
相关文章:
solr教程
一:安装配置 下载完成之后,解压solr文件,解压tomcat 1.1 在tomcat安装solr,并且建立solrCore 把solr5.5目录下的server/solr-webapp/webapp 重命名为solr,并且放置到tomcat/webapp的目录下。 打开tomcat/webapp/solr/WEB-INF/web.xml新建…...

基于java语言编写的爬虫程序
Java语言可以使用Jsoup、HttpClient等库进行网络爬虫开发,其中Jsoup提供了HTML解析和DOM操作的功能,HttpClient则提供了HTTP协议的支持。你可以通过使用这些库,构建网络爬虫程序来爬取指定网站的数据。需要注意的是,应该遵守网站的…...
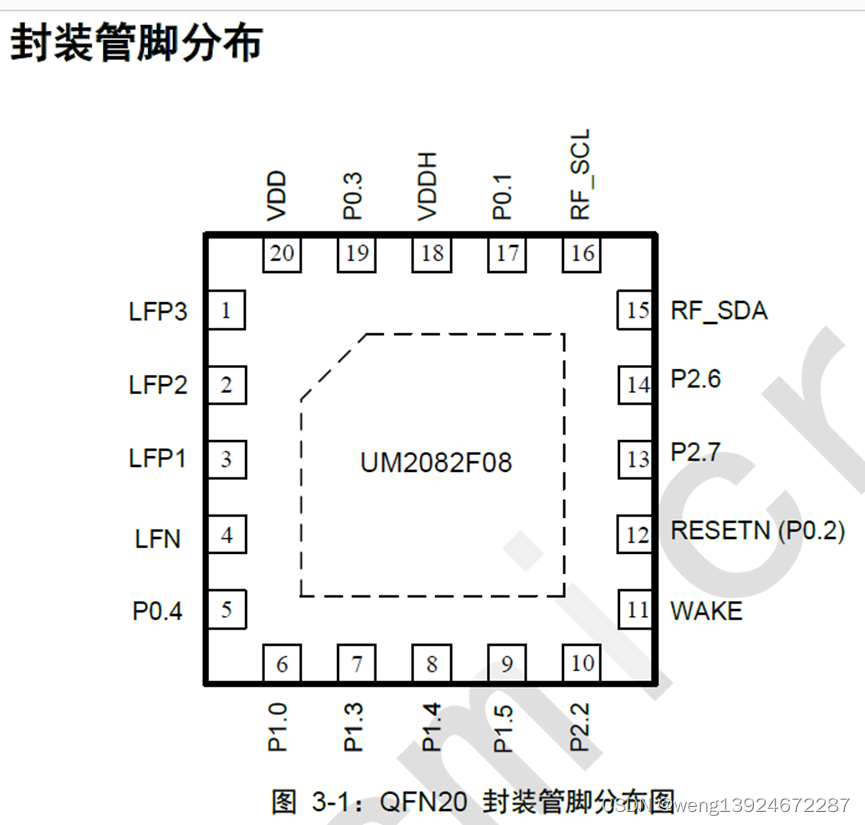
UM2082F08 125k三通道低频无线唤醒ASK接收功能的SOC芯片 汽车PKE钥匙
1产品描述 UM2082F08是基于单周期8051内核的超低功耗8位、具有三通道低频无线唤醒ASK接收功能的SOC芯片。芯片可检测30KHz~300KHz范围的LF (低频)载波频率数据并触发唤醒信号,同时可以调节接收灵敏度,确保在各种应用环境下实现可靠唤醒,其拥…...
【SpringBoot_Project_Actual combat】 Summary of Project experience_需要考虑的问题
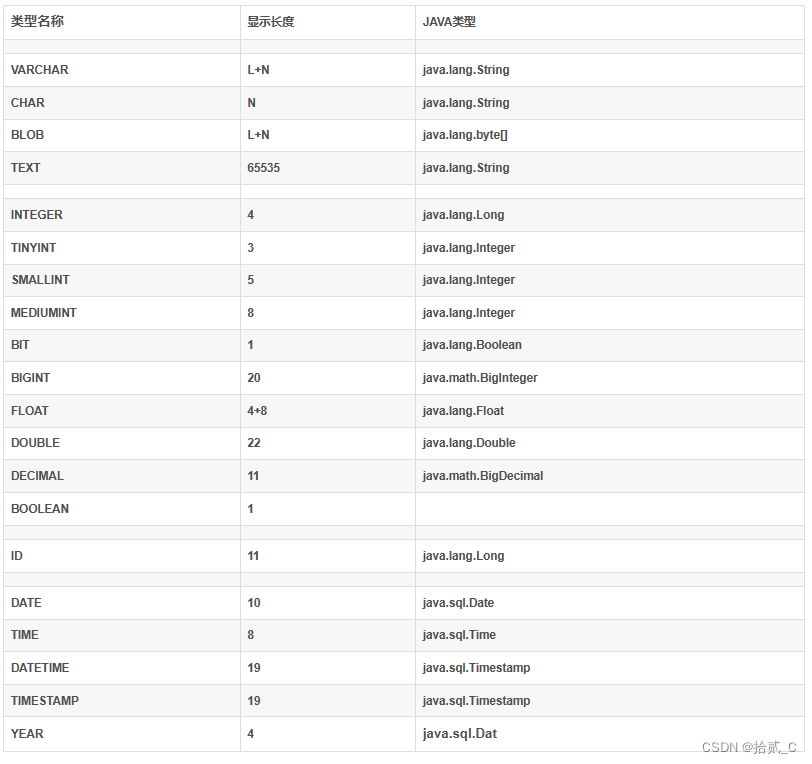
无论是初学者还是有经验的专业人士,在学习一门新的IT技术时,都需要采取一种系统性的学习方法。那么作为一名技术er,你是如何系统的学习it技术的呢。 一、DB Problems 数据库数据类型与java中数据类型对应问题? MySql数据库和java…...

恒容容器放气的瞬时流量的计算与合金氢化物放氢流量曲线的计算
有时候,你会遇到一个问题,该问题的描述如下: 你有一个已知体积的容器,设容器体积为V,里面装有一定压力(初始压力)的气体,如空气或氢气等,设初始压力为1MPa,容器出口连接着一个阀门开…...

网络编程_UDP通信
网络编程_UDP通信 1. TCP与UDP2. 使用UDP通信3. sendto与recvfrom、recv4.实例实例1: 服务器接收、客户端发送实例2:服务器收发、客户方发送、接收。1. TCP与UDP 当使用网络套接字通信时, 套接字的“域”都取AF_INET; 套接字的type: SOCK_STREAM 此时,默认使用TCP协议进行…...
windows修改Pycharm的右键打开方式
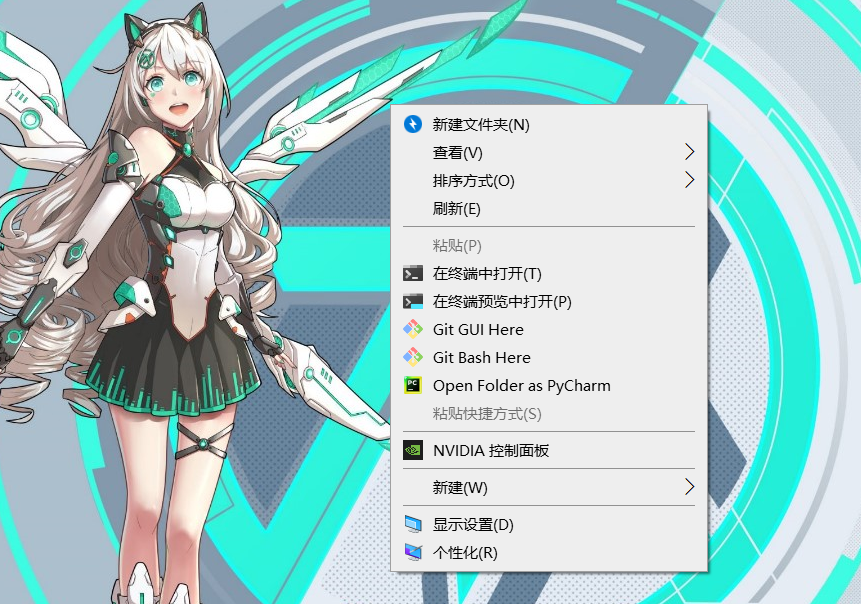
title: windows中open floder as Pycharm太长了怎么修改 date: 2023-06-04 author: IoT_H2 tags: windows系统问题 categories: Markdown 问题描述: Pycharm这一栏这么长,长的我实在是很难受,事实上Jetbrains家的软件都是这个鸟模样 导…...
函数(二))
Python入门(十四)函数(二)
函数(二) 1.传递实参1.1 位置实参1.2 关键字实参1.3 默认值 作者:xiou 1.传递实参 函数定义中可能包含多个形参,因此函数调用中也可能包含多个实参。向函数传递实参的方式很多:可使用位置实参,这要求实参…...

Allure测试报告定制全攻略,优化你的Web自动化测试框架!
目录 前言: 1. Allure测试报告简介 2. Web自动化测试框架简介 3. 封装Web自动化框架 3.1 安装Selenium 3.2 封装Selenium 3.3 定制Allure测试报告 3.3.1 适配翻译插件 3.3.2 定制测试报告样式 4. 示例代码 5. 总结 前言: 随着现在Web应用的普…...

推荐系统算法详解
文章目录 基于人口统计学的推荐算法用户画像 基于内容的推荐算法相似度计算基于内容推荐系统的高层次结构特征工程数值型特征处理类别特征处理时间型特征处理统计型特征处理 推荐系统常见反馈数据基于UGC的推荐TF-IDFTF-IDF算法示例1. 引入依赖2. 定义数据和预处理3. 进行词数统…...
企业网站架构部署与优化之LAMP
LAMP LAMP概述1、各组件的主要作用2、各组件安装顺序 编译安装Apache http服务编译安装MySQL服务编译安装PHP解析环境安装论坛 LAMP概述 LAMP架构是目前成熟的企业网站应用模式之一,指的是协同工作的一整套系统和相关软件,能够提供静态和动态Web站点服务…...
攻防世界安卓逆向练习
文章目录 一.easy-so1. jadx分析程序逻辑2. ida查看so文件3. 解题脚本: 二.ezjni1. 程序逻辑分析2. 解题脚本: 三.easyjava1. 主函数逻辑2. getIndex函数3. getChar函数4.解题脚本 四.APK逆向1.程序逻辑分析2.解题脚本3.动态调试 Android2.0app3 一.easy-so 1. jadx分析程序逻…...
)
自然语言处理从入门到应用——自然语言处理的语言模型(Language Model,LM)
分类目录:《自然语言处理从入门到应用》总目录 语言模型(Language Model,LM)(也称统计语言模型)是描述自然语言概率分布的模型,是一个非常基础和重要的自然语言处理任务。利用语言模型ÿ…...
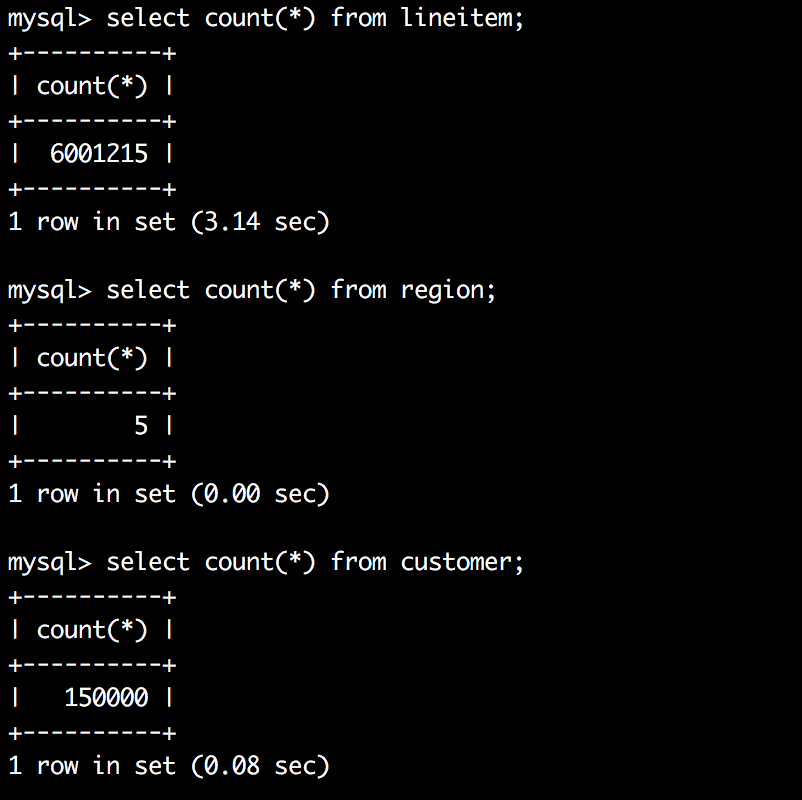
【MySql】InnoDB一棵B+树可以存放多少行数据?
文章目录 背景一、怎么得到InnoDB主键索引B树的高度?二、小结三、最后回顾一道面试题总结参考资料 背景 InnoDB一棵B树可以存放多少行数据?这个问题的简单回答是:约2千万。为什么是这么多呢?因为这是可以算出来的,要搞…...
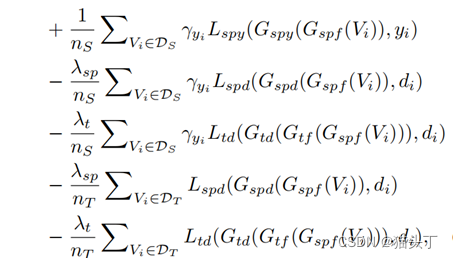
【综述】视频无监督域自适应(VUDA)的小综述
【综述】视频无监督域自适应(VUDA)的小综述 一篇小综述,大家看个乐子就好,参考文献来自于一篇综述性论文 完整PPT已经上传资源:https://download.csdn.net/download/weixin_46570668/87848901?spm1001.2014.3001.550…...

《深入理解计算机系统(CSAPP)》第9章虚拟内存 - 学习笔记
写在前面的话:此系列文章为笔者学习CSAPP时的个人笔记,分享出来与大家学习交流,目录大体与《深入理解计算机系统》书本一致。因是初次预习时写的笔记,在复习回看时发现部分内容存在一些小问题,因时间紧张来不及再次整理…...

信息论与编码 SCUEC DDDD 期末复习
1.证明熵的可加性 2.假设一帧视频图像可以认为是由3*10的五次方个像素组成(每像素均独立变化),如果每个像素可取128个不同的等概率亮度表示。请计算出每帧图像含多少信息量?若有一口述者在约12000个汉字的字汇中选400个字来口述此…...
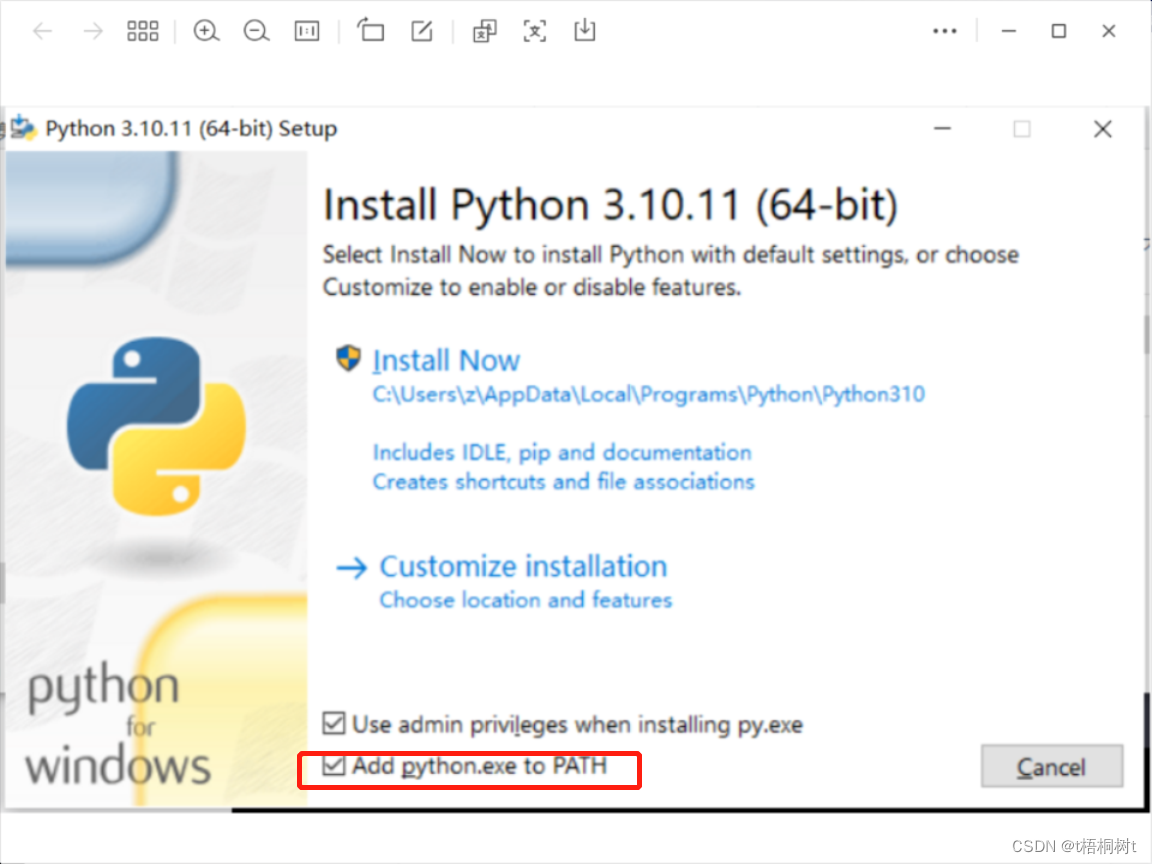
windows安装python开发环境
最近因工作需要,要学习一下python,所以先安装一下python的开发环境,比较简单 下载和安装Python 首先,在浏览器中打开Python的官方网站(https://www.python.org/downloads/) 然后,从该网站下载与你的操…...

java idea常用的快捷方式
文章目录 java idea常用的快捷方式快速复制选多行改变代码格式化 快速代码编辑psvmsout5.forarr.for快速死循环快速补全代码当方法还没创建的时候抽取具有一定功能的代码变成方法 java idea常用的快捷方式 快速复制 c t r l d \color{red}{ctrld} ctrld 选多行改变 A l t 鼠…...

lwIP 开发指南
目录 lwIP 初探TCP/IP 协议栈是什么TCP/IP 协议栈架构TCP/IP 协议栈的封包和拆包 lwIP 简介lwIP 源码下载lwIP 文件说明 MAC 内核简介PHY 芯片介绍YT8512C 简介LAN8720A 简介 以太网接入MCU 方案软件TCP/IP 协议栈以太网接入方案硬件TCP/IP 协议栈以太网接入方案 lwIP 无操作系…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

【论文笔记】若干矿井粉尘检测算法概述
总的来说,传统机器学习、传统机器学习与深度学习的结合、LSTM等算法所需要的数据集来源于矿井传感器测量的粉尘浓度,通过建立回归模型来预测未来矿井的粉尘浓度。传统机器学习算法性能易受数据中极端值的影响。YOLO等计算机视觉算法所需要的数据集来源于…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...