Apache Hudi初探(八)(与spark的结合)--非bulk_insert模式
背景
之前讨论的都是’hoodie.datasource.write.operation’:'bulk_insert’的前提下,在这种模式下,是没有json文件的已形成如下的文件:
/dt=1/.hoodie_partition_metadata
/dt=1/2ffe3579-6ddb-4c5f-bf03-5c1b5dfce0a0-0_0-41263-0_20230528233336713.parquet
/dt=1/30b7d5b2-12e8-415a-8ec5-18206fe601c0-0_0-22102-0_20230528231643200.parquet
/dt=1/4abc1c6d-a8aa-4c15-affc-61a35171ce69-0_4-22106-0_20230528231643200.parquet
/dt=1/513dee80-2e8c-4db8-baee-a767b9dba41c-0_2-22104-0_20230528231643200.parquet
/dt=1/57076f86-0a62-4f52-8b50-31a5f769b26a-0_1-22103-0_20230528231643200.parquet
/dt=1/84553727-be9d-4273-bad9-0a38d9240815-0_0-59818-0_20230528233513387.parquet
/dt=1/fecd6a84-9a74-40b1-bfc1-13612a67a785-0_0-26640-0_20230528231723951.parquet
因为是"bulk insert"操作,所以没有去重的需要,所以直接采用spark原生的方式,
以下我们讨论非spark原生的方式,
闲说杂谈
继续Apache Hudi初探(二)(与spark的结合)
剩下的代码:
val reconcileSchema = parameters(DataSourceWriteOptions.RECONCILE_SCHEMA.key()).toBooleanval (writeResult, writeClient: SparkRDDWriteClient[HoodieRecordPayload[Nothing]]) =...case _ => { // any other operation// register classes & schemasval (structName, nameSpace) = AvroConversionUtils.getAvroRecordNameAndNamespace(tblName)sparkContext.getConf.registerKryoClasses(Array(classOf[org.apache.avro.generic.GenericData],classOf[org.apache.avro.Schema]))// TODO(HUDI-4472) revisit and simplify schema handlingval sourceSchema = AvroConversionUtils.convertStructTypeToAvroSchema(df.schema, structName, nameSpace)val latestTableSchema = getLatestTableSchema(sqlContext.sparkSession, tableMetaClient).getOrElse(sourceSchema)val schemaEvolutionEnabled = parameters.getOrDefault(DataSourceReadOptions.SCHEMA_EVOLUTION_ENABLED.key(), "false").toBooleanvar internalSchemaOpt = getLatestTableInternalSchema(hoodieConfig, tableMetaClient)val writerSchema: Schema =if (reconcileSchema) {// In case we need to reconcile the schema and schema evolution is enabled,// we will force-apply schema evolution to the writer's schemaif (schemaEvolutionEnabled && internalSchemaOpt.isEmpty) {internalSchemaOpt = Some(AvroInternalSchemaConverter.convert(sourceSchema))}if (internalSchemaOpt.isDefined) {...// Convert to RDD[HoodieRecord]val genericRecords: RDD[GenericRecord] = HoodieSparkUtils.createRdd(df, structName, nameSpace, reconcileSchema,org.apache.hudi.common.util.Option.of(writerSchema))val shouldCombine = parameters(INSERT_DROP_DUPS.key()).toBoolean ||operation.equals(WriteOperationType.UPSERT) ||parameters.getOrElse(HoodieWriteConfig.COMBINE_BEFORE_INSERT.key(),HoodieWriteConfig.COMBINE_BEFORE_INSERT.defaultValue()).toBooleanval hoodieAllIncomingRecords = genericRecords.map(gr => {val processedRecord = getProcessedRecord(partitionColumns, gr, dropPartitionColumns)val hoodieRecord = if (shouldCombine) {val orderingVal = HoodieAvroUtils.getNestedFieldVal(gr, hoodieConfig.getString(PRECOMBINE_FIELD), false, parameters.getOrElse(DataSourceWriteOptions.KEYGENERATOR_CONSISTENT_LOGICAL_TIMESTAMP_ENABLED.key(),DataSourceWriteOptions.KEYGENERATOR_CONSISTENT_LOGICAL_TIMESTAMP_ENABLED.defaultValue()).toBoolean).asInstanceOf[Comparable[_]]DataSourceUtils.createHoodieRecord(processedRecord,orderingVal,keyGenerator.getKey(gr),hoodieConfig.getString(PAYLOAD_CLASS_NAME))} else {DataSourceUtils.createHoodieRecord(processedRecord, keyGenerator.getKey(gr), hoodieConfig.getString(PAYLOAD_CLASS_NAME))}hoodieRecord}).toJavaRDD()val writerDataSchema = if (dropPartitionColumns) generateSchemaWithoutPartitionColumns(partitionColumns, writerSchema) else writerSchema// Create a HoodieWriteClient & issue the write.val client = hoodieWriteClient.getOrElse(DataSourceUtils.createHoodieClient(jsc, writerDataSchema.toString, path,tblName, mapAsJavaMap(addSchemaEvolutionParameters(parameters, internalSchemaOpt) - HoodieWriteConfig.AUTO_COMMIT_ENABLE.key))).asInstanceOf[SparkRDDWriteClient[HoodieRecordPayload[Nothing]]]if (isAsyncCompactionEnabled(client, tableConfig, parameters, jsc.hadoopConfiguration())) {asyncCompactionTriggerFn.get.apply(client)}if (isAsyncClusteringEnabled(client, parameters)) {asyncClusteringTriggerFn.get.apply(client)}val hoodieRecords =if (hoodieConfig.getBoolean(INSERT_DROP_DUPS)) {DataSourceUtils.dropDuplicates(jsc, hoodieAllIncomingRecords, mapAsJavaMap(parameters))} else {hoodieAllIncomingRecords}client.startCommitWithTime(instantTime, commitActionType)val writeResult = DataSourceUtils.doWriteOperation(client, hoodieRecords, instantTime, operation)(writeResult, client)}-
如果开启了Schema Evolution,也就是hoodie.datasource.write.reconcile.schema是true,默认是false,就会进行schema的合并
convertStructTypeToAvroSchema 把df的schema转换成avro的schema
并且从*.hoodie/20230530073115535.deltacommit* 获取internalSchemaOpt,具体的合并就是把即将写入的schema和internalSchemaOpt进行合并
最后赋值给writerSchema,有可能还需要hoodie.schema.on.read.enable,默认是false -
HoodieSparkUtils.createRdd 创建RDD
把df转换为了RDD[GenericRecord]类型,赋值给genericRecords -
val hoodieAllIncomingRecords = genericRecords.map(gr => {
- 首先如果是hoodie.datasource.write.drop.partition.columns为true(默认是false),则会从schema中删除hoodie.datasource.write.
partitionpath.field字段 - 如果hoodie.datasource.write.insert.drop.duplicates为true(默认是false)或者hoodie.datasource.write.operation是upsert(默认
是upsert),或者hoodie.combine.before.insert为true(默认是false),
则会创建HoodieAvroRecord<>(hKey, payload)类型的实例,其中HoodieKey以recordkey和partitionpath组成,playload为OverwriteWithLatestAvroPayload实例, - hoodieAllIncomingRecords就变成了RDD[HoodieAvroRecord]
- 首先如果是hoodie.datasource.write.drop.partition.columns为true(默认是false),则会从schema中删除hoodie.datasource.write.
-
writerDataSchema= client 这些就是创建SparkRDDWriteClient 客户端
-
isAsyncCompactionEnabled
默认asyncCompactionTriggerFnDefined是没有的,所以不会开启异步的Compaction,isAsyncClusteringEnabled同理也是 -
val hoodieRecords =
如果配置了hoodie.datasource.write.insert.drop.duplicates为true(默认是false),则会进行去重处理,具体是调用DataSourceUtils.dropDuplicates方法:SparkRDDReadClient client = new SparkRDDReadClient<>(new HoodieSparkEngineContext(jssc), writeConfig);return client.tagLocation(incomingHoodieRecords).filter(r -> !((HoodieRecord<HoodieRecordPayload>) r).isCurrentLocationKnown());- SparkRDDReadClient client 在创建Client的时候,会进行索引的创建this.index = SparkHoodieIndexFactory.createIndex(clientConfig);
如果有hoodie.index.class设置,则实例化对象,否则根据hoodie.index.type的值来建立索引(默认是HoodieSimpleIndex,适合做测试用) - client.tagLocation(incomingHoodieRecords)…
从要插入的记录中过滤出在index中不存在的记录,最终调用的是index.tagLocation方法
如果hoodie.datasource.write.insert.drop.duplicates为false,则保留所有的记录
- SparkRDDReadClient client 在创建Client的时候,会进行索引的创建this.index = SparkHoodieIndexFactory.createIndex(clientConfig);
-
client.startCommitWithTime 开始写操作,这涉及到回滚的操作
- 会先过滤出需要回滚的的的写失败的文件,如果hoodie.cleaner.policy.failed.writes是EAGER(默认是EAGER),就会在这次提交中回滚失败的文件
- 然后创建一个后缀为deltacommit.requested的文件,此时没有真正的写
-
val writeResult = DataSourceUtils.doWriteOperation
真正的写操作
相关文章:
(与spark的结合)--非bulk_insert模式)
Apache Hudi初探(八)(与spark的结合)--非bulk_insert模式
背景 之前讨论的都是’hoodie.datasource.write.operation’:bulk_insert’的前提下,在这种模式下,是没有json文件的已形成如下的文件: /dt1/.hoodie_partition_metadata /dt1/2ffe3579-6ddb-4c5f-bf03-5c1b5dfce0a0-0_0-41263-0_202305282…...
)
Java之旅(九)
Java 循环语句 Java 中的循环语句包括 for、while 和 do-while,它们都可以用于实现循环结构。 for 语句用于循环执行一段代码块,直到给定的条件表达式的布尔值为 false。 for 语句的一般格式如下: for (initialization; condition; update…...

6年测试经验之谈,为什么要做自动化测试?
一、自动化测试 自动化测试是把以人为驱动的测试行为转化为机器执行的一种过程。 个人认为,只要能服务于测试工作,能够帮助我们提升工作效率的,不管是所谓的自动化工具,还是简单的SQL 脚本、批处理脚本,还是自己编写…...

二分法的边界条件 2517. 礼盒的最大甜蜜度
2517. 礼盒的最大甜蜜度 给你一个正整数数组 price ,其中 price[i] 表示第 i 类糖果的价格,另给你一个正整数 k 。 商店组合 k 类 不同 糖果打包成礼盒出售。礼盒的 甜蜜度 是礼盒中任意两种糖果 价格 绝对差的最小值。 返回礼盒的 最大 甜蜜度。 记录一…...

java设计模式(十六)命令模式
目录 定义模式结构角色职责代码实现适用场景优缺点 定义 命令模式(Command Pattern) 又叫动作模式或事务模式。指的是将一个请求封装成一个对象,使发出请求的责任和执行请求的责任分割开,然后可以使用不同的请求把客户端参数化&a…...

[运维] iptables限制指定ip访问指定端口和只允许指定ip访问指定端口
iptables限制指定ip访问指定端口 要使用iptables限制特定IP地址访问特定端口,您可以使用以下命令: iptables -A INPUT -p tcp -s <IP地址> --dport <端口号> -j DROP请将 <IP地址> 替换为要限制的IP地址,将 <端口号&g…...
)
JS学习笔记(3. 流程控制)
1. 分歧 1.1 if条件 if (条件) {...} // 为真则执行,单条语句可省略大括号 if (条件) {...} else {...}// 为真则执行if,否则执行else if (条件1) {...} else if (条件2) {...} else {...} // 条件1为真则,条件2为真则,否则执…...
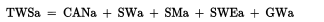
遥感云大数据在灾害、水体与湿地领域典型案例及GPT模型教程
详情点击链接:遥感云大数据在灾害、水体与湿地领域典型案例及GPT模型教程 一:平台及基础开发平台 GEE平台及典型应用案例; GEE开发环境及常用数据资源; ChatGPT、文心一言等GPT模型 JavaScript基础; GEE遥感云重…...
什么是文件描述符以及重定向的本质和软硬链接(Linux)
目录 1 什么是文件?什么是文件操作?认识系统接口open 什么是文件描述符认识Linux底层进程如何打开的文件映射关系重定向的本质理解软硬链接扩展问题 1 什么是文件?什么是文件操作? 文件 文件内容 文件属性(文件属性…...

LVM逻辑卷元数据丢失恢复案例 —— 筑梦之路
Lvm常见的故障主要是pv出现异常,有以下几种情况 一个是pv所在的磁盘发生了lvm的元数据损坏一个是系统无法识别到pv所在的磁盘一个是系统异常,断电等导致重启后盘符发生变化,也就是系统识别的磁盘uuid发生变化,但是wwid还是可以对应…...

Java技术规范概览
Java技术规范 目录概述需求: 设计思路实现思路分析1.Java JSR的部分2.JSR-000373.JSR-0000394.JSR-000337 参考资料和推荐阅读 Survive by day and develop by night. talk for import biz , show your perfect code,full busy,skip hardness,make a bet…...

【OpenMMLab AI实战营第二期】二十分钟入门OpenMMLab笔记
OpenMMlab 主页:openmmlab.com 开源地址:https://github.com/open-mmlab 学习视频地址:https://www.bilibili.com/video/BV1js4y1i72P/ 概述 开源成为人工智能行业发展引擎 时间轴 theano:2007 Caffe:2013 Ten…...
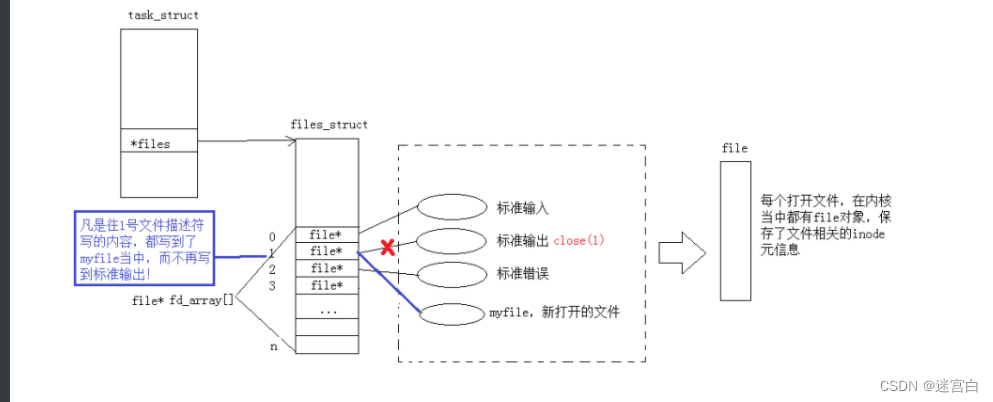
docker-compose单机容器集群编排
docker-compose dockerfile模板文件可以定义一个独立的应用容器,如果需要多个容器就需要服务编排。服务编排有很多技术方案 docker-compose开源的项目实现对容器集群的快速编排 docker-compose将所管理的容器分为三层,分别为工程,服务&#…...

CentOS7 安装Gitlab
1、安装依赖 sudo yum install -y curl openssh-server ca-certificates tzdata perl libsemanage-devel 2、安装邮件服务工具 sudo yum install -y postfix 3、配置GitLab 软件源镜像 curl -fsSL https://packages.gitlab.cn/repository/raw/scripts/setup.sh | /bin/bash …...
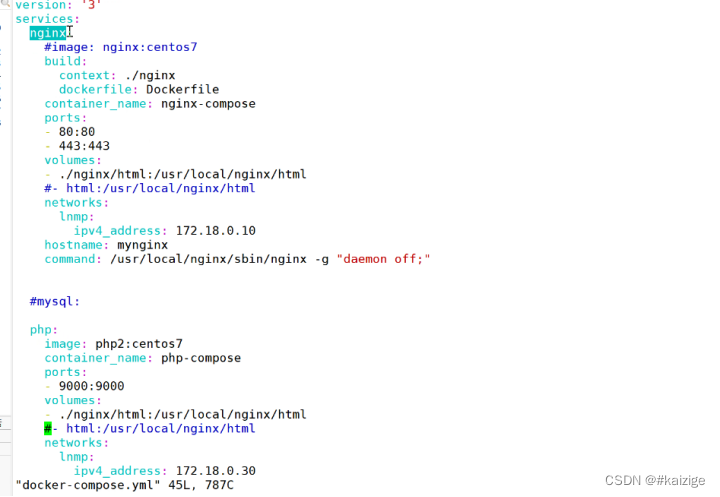
Mysql InnoDB的Buffer Pool
Buffer Pool 在MySQL服务器启动的时候就向操作系统申请了⼀⽚连续的内存,他们给这⽚内存起了个名,叫做Buffer Pool(中⽂名 是缓冲池)。 默认情况下Buffer Pool只有128M⼤⼩,最⼩值为5M,通过修改配置文件设…...
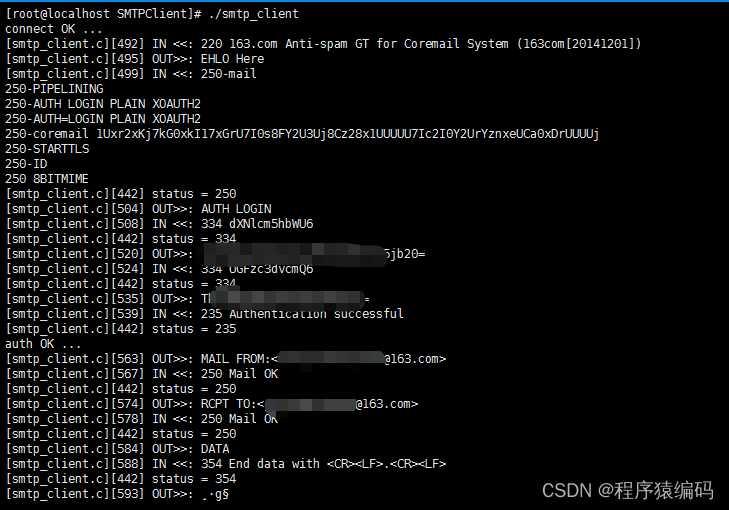
SMTP简单邮件传输协议(C/C++ 发送电子邮件)
SMTP是用于通过Internet发送电子邮件的协议。电子邮件客户端(如Microsoft Outlook或macOS Mail应用程序)使用SMTP连接到邮件服务器并发送电子邮件。邮件服务器还使用SMTP将邮件从一个邮件服务器交换到另一个。它不用于从服务器下载电子邮件;相…...
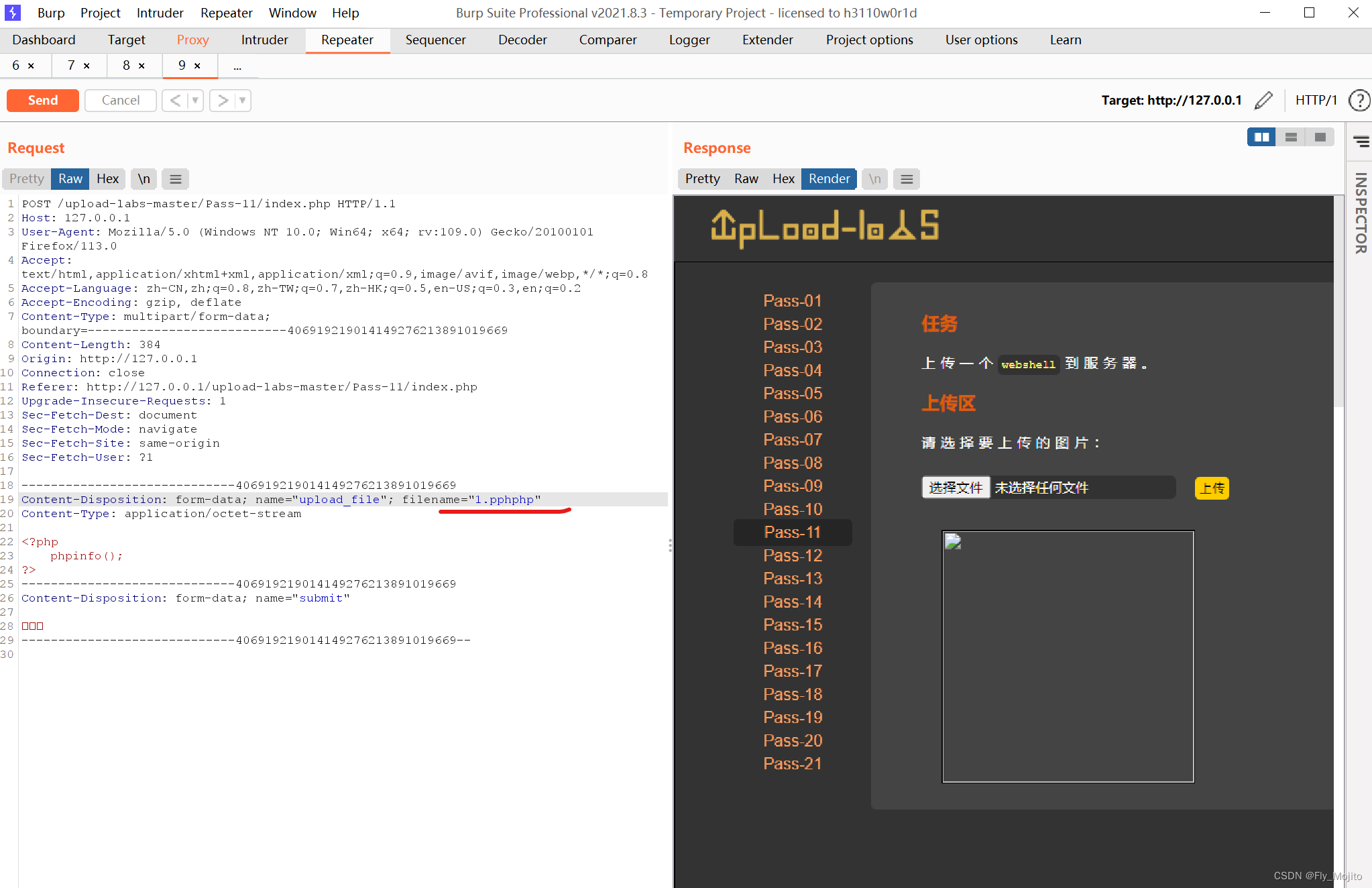
uploads靶场通关(1-11关)
Pass-01(JS校验) 看题目我们准备好我们的php脚本文件,命名为1.php 上传该php文件,发现上传失败 方法一:将浏览器的JavaScript禁用 然后就能上传了 方法二: 查看源码,发现只能上传以下形式的文…...

6.1黄金探底回升是否到顶,今日多空如何布局
近期有哪些消息面影响黄金走势?今日黄金多空该如何研判? 黄金消息面解析:周三(5月31日)黄金期货价格攀升,美国国债收益率下降推动金价升至一周最高收盘位。美市尾盘,现货黄金收报1962.42美元/盎司,上升3…...

自定义ViewGroup实现流式布局
目录 1、View的绘制流程 2、自定义ViewGroup构造函数的作用 3、onMeasure 方法 3.1、View的度量方式 3.2、onMeasure方法参数的介绍 3.3、自定义ViewGroup onMeasure 方法的实现 4、onLayout方法 5、onDraw方法 6、自定义View的生命周期 7、自定义流式布局的实现 扩展ÿ…...

Git版本控制
目录 版本控制 概念 为什么需要版本控制? 常见的版本控制工具 Git 1、安装 2、了解基本的Linux命令 3、配置git 用户名和邮箱 4、git 工作模式 5、git 项目管理 6、git 分支 托管平台 远程仓库 Gitee 关联多个远程库 Git服务器 Git GUI 版本控制 概…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

wpf在image控件上快速显示内存图像
wpf在image控件上快速显示内存图像https://www.cnblogs.com/haodafeng/p/10431387.html 如果你在寻找能够快速在image控件刷新大图像(比如分辨率3000*3000的图像)的办法,尤其是想把内存中的裸数据(只有图像的数据,不包…...
在 Spring Boot 中使用 JSP
jsp? 好多年没用了。重新整一下 还费了点时间,记录一下。 项目结构: pom: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://ww…...
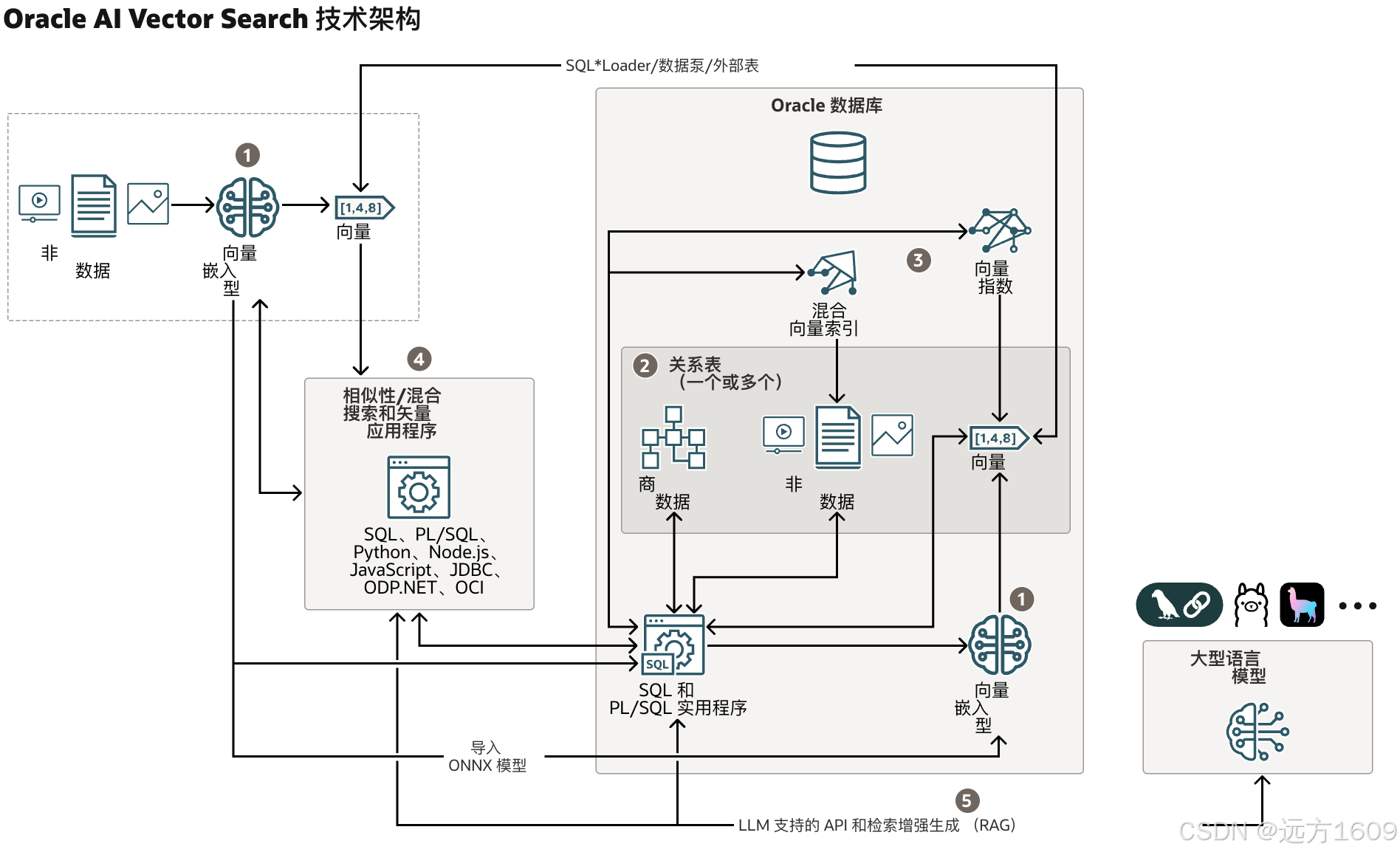
9-Oracle 23 ai Vector Search 特性 知识准备
很多小伙伴是不是参加了 免费认证课程(限时至2025/5/15) Oracle AI Vector Search 1Z0-184-25考试,都顺利拿到certified了没。 各行各业的AI 大模型的到来,传统的数据库中的SQL还能不能打,结构化和非结构的话数据如何和…...

十九、【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建
【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建 前言准备工作第一部分:回顾 Django 内置的 `User` 模型第二部分:设计并创建 `Role` 和 `UserProfile` 模型第三部分:创建 Serializers第四部分:创建 ViewSets第五部分:注册 API 路由第六部分:后端初步测…...

深度剖析 DeepSeek 开源模型部署与应用:策略、权衡与未来走向
在人工智能技术呈指数级发展的当下,大模型已然成为推动各行业变革的核心驱动力。DeepSeek 开源模型以其卓越的性能和灵活的开源特性,吸引了众多企业与开发者的目光。如何高效且合理地部署与运用 DeepSeek 模型,成为释放其巨大潜力的关键所在&…...

Python网页自动化Selenium中文文档
1. 安装 1.1. 安装 Selenium Python bindings 提供了一个简单的API,让你使用Selenium WebDriver来编写功能/校验测试。 通过Selenium Python的API,你可以非常直观的使用Selenium WebDriver的所有功能。 Selenium Python bindings 使用非常简洁方便的A…...