实训总结-----Scrapy爬虫
1.安装指令
pip install scrapy2.创建 scrapy 项目
任意终端 进入到目录(用于存储我们的项目)
scrapy startproject 项目名
会在目录下面 创建一个以 项目名 命名的文件夹
终端也会有提示
cd 项目名
scrapy genspider example example.com
3.运行爬虫指令
scrapy crawl 爬虫名 --nolog //nolog是不看日志
4.输出 xml csv json格式的文件
scrapy crawl 爬虫名 -o 文件名
5.目录

(1)__init__.py 此文件为项目的初始化文件,主要写的是一些项目的初始化信息。
(2)items.py 爬虫项目的数据容器文件,主要用来定义我们要获取的数据
(3)piplines.py 爬虫项目的管道文件,主要用来对items里面定义的数据进行进一步的加工与处理
(4)settings.py 爬虫项目的设置文件,主要为爬虫项目的一些设置信息
(5)spiders文件夹 此文件夹下放置的事爬虫项目中的爬虫部分相关
6.novel.py文件
import scrapy
from scrapy import Selector
# scrapy01 文件的名字
# items scrapy01文件下面的名字
# Scrapy01Item items里面的类名
from scrapy01.items import Scrapy01Itemclass NovelSpider(scrapy.Spider):# 爬虫名name = "novel"#允许爬取的域名allowed_domains = ["www.shicimingju.com"]# 爬取的具体地址 必须在 允许域名的下面 子域名start_urls = ["https://www.shicimingju.com/book/hongloumeng.html"]# parse 爬取到数据 默认/调用的def parse(self, response):# response 已经 是爬取的结果 requests.get()sel = Selector(response)li_list = sel.css('div.book-mulu > ul > li')for li_item in li_list:novel_item = Scrapy01Item()# 章节是 a标签内容# 取标签内容 标签名::text# extract() 所有的标签# extract_first() 第一个标签chapter = li_item.css('a::text').extract_first()# 链接是 a标签属性# 取标签属性值 标签名::(属性)url = li_item.css("a::attr(href)").extract_first()# novel_item的字段和 items.py里面 定义的模型 对应novel_item['chapter'] = chapternovel_item['url'] = urlprint("novel_item:",novel_item)# return novel_item # 循环一次就出去了yield novel_item # yield 迭代器
# 配置伪装 头 settings里面配置 17行7.piplines.py文件对数据进行json和xlsx导出
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
import jsonimport openpyxl
from itemadapter import ItemAdapterclass Scrapy01XlsxPipeline:def __init__(self):print('init---------初始化')# 创建工作库self.wb = openpyxl.Workbook()# 获取激活的工作self.ws = self.wb.activeself.ws.title = '红楼梦'# 参数是元组self.ws.append(('章节','地址'))# item就是爬虫文件 解析/parse的数据def process_item(self, item, spider):print('process_item-----钩子----数据',item)# item.['chapter']chapter = item.get('chapter','默认值')url = item.get('url') or ''# 追加数据self.ws.append((chapter,url))return item# 开始爬取 必须写第二个参数spiderdef open_spider(self,spider):print('打开蜘蛛')# 爬取完毕def close_spider(self,spider):self.wb.save('红楼梦1.xslx')print('爬取完毕')class Scrapy01JsonPipeline:def __init__(self):# 存储爬取的数据self.data = []self.fp = open("./练习.json",'w',encoding='utf-8')# 拿到数据就走def process_item(self,item,spider):url = item.get("url") or ''chapter = item.get("chapter",'')# 添加爬取数据self.data.append((chapter,url))# 防止每爬取一次数据就写一次if len(self.data)>50:json.dump(self.data,self.fp,ensure_ascii=False)self.data.clear()return itemdef close_spider(self,spider):if len(self.data) > 0:json.dump(self.data, self.fp, ensure_ascii=False)self.fp.close()print('关闭')
# 共52条数据
# 节流 51次写入一次 置空
# 第52次 完了走关闭 发现还有一条数据写入
8.items.py
import scrapyclass Scrapy01Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# passchapter = scrapy.Field()# 存储 章节内容的urlurl=scrapy.Field()# 根据自己的需求 定义字段 N个9.settings.py文件
1.USER_AGENT需要打开爬取数据
USER_AGENT ="Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.57"2.开启管道,Scrapy01XlsxPipeline和Scrapy01JsonPipeline都是iplines.py文件中的类名。
# 开启管道 配置多个管道 数字越小优先级越小
# Scrapy01XlsxPipeline 管道文件类名
ITEM_PIPELINES = {"scrapy01.pipelines.Scrapy01XlsxPipeline": 300,"scrapy01.pipelines.Scrapy01JsonPipeline": 200,
}相关文章:
实训总结-----Scrapy爬虫
1.安装指令 pip install scrapy 2.创建 scrapy 项目 任意终端 进入到目录(用于存储我们的项目) scrapy startproject 项目名 会在目录下面 创建一个以 项目名 命名的文件夹 终端也会有提示 cd 项目名 scrapy genspider example example.com 3.运行爬虫指令 scrapy craw…...

前端开发职业规划指南:如何做好职业规划与发展
引言 前端开发是目前互联网行业中最火热的职业之一,也是非常具有发展前景的职业之一。随着互联网技术的不断更新和发展,前端开发的职业规划也在不断地发生变化。本文将从几个方面来探讨前端开发的职业规划。 一、职业发展路径 1.前端初级工程师 前端初…...
创业第一步:如何写好商业计划书
即使你的项目不需要融资,你也把标准商业计划书作为一个工具模板来应用,帮助更全面的盘点你要做的事情。 撰写一份性感的商业计划书如同造房子:第一步是科学设计,打好结构(有清晰的撰写逻辑);第…...
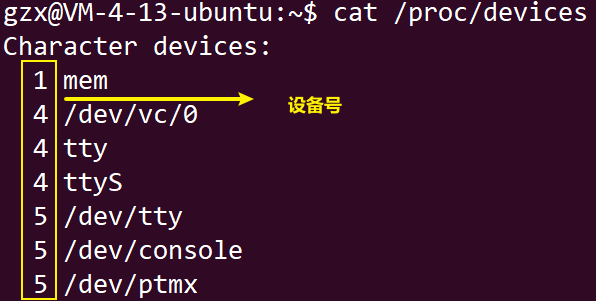
【Linux驱动】字符设备驱动相关宏 / 函数介绍(module_init、register_chrdev)
驱动运行有两种方式: 方式一:直接编译到内核,Linux内核启动时自动运行驱动程序方式二:编译成模块,使用 insmod 命令加载驱动模块 我们在调试的时候,采用第二种方式是最合适的,每次修改驱动只需…...

axios解决跨域问题
Vue3中使用axios访问聚合的天气API,出现跨域问题,需要在前端进行一些配置: 首先是修改vue.config.js: const { defineConfig } require(vue/cli-service) module.exports defineConfig({transpileDependencies: true,devServe…...

R语言作图——热图聚类及其聚类结果输出
代码 不多说了,做个记录,代码如下。 library(pheatmap) library(RColorBrewer) # args commandArgs(TRUE) betafile "twist_common_panel_434.csv" infofile "twist_common_panel_434.txt" title "twist_common_panel&qu…...

Tomcat优化
Tomcat优化 Tomcat默认安装下的缺省配置并不适合生产环境,它可能会频繁出现假死现象需要重启,只有通过不断压测优化才能让它最高效率稳定的运行。优化主要包括三方面,分别为操作系统优化(内核参数优化),Tom…...

我的GIT练习TWO
目录 前言 GIT安装教程 Git作者 GIT优点 GIT缺点 为什么要使用 Git GIT练习TWO C1 C2 C3 C4 C5 C6 C7 总结 前言 Git 是一个分布式版本控制及源代码管理工具;Git 可以为你的项目保存若干快照,以此来对整个项目进行版本管理 GIT安装教程 点击进入查看教程…...

个人器件库整理
样品本 包含如下: 电容器件: 元件值封装备注钽电容47uF 10V1206钽电容10uF 10V1206电容10uF 10% 10V0603X5R,CL10A106KP8NNNC 元件值封装备注100nF电容50V,10%0603 电阻器件: 元件值封装备注75 Ω \Omega Ω…...

javascript——内存管理
JavaScript内存管理是Web开发中的一个重要主题。正确管理内存可以提高应用程序的性能和稳定性。本文将介绍JavaScript中的内存管理概念、常见的内存泄漏问题以及一些有效的内存管理技巧。 什么是JavaScript内存管理? JavaScript具有自动内存管理机制,开…...

Qt5.15.2安卓Android项目开发环境配置
1、Qt Creator 4.11.2 官方下载:https://download.qt.io/archive/qtcreator/4.11/4.11.2/ 镜像下载:https://mirrors.cloud.tencent.com/qt/archive/qtcreator/4.11/4.11.2/ 2、Qt 5.15.2 Android 官方更新器内部下载 参考:https://blog…...
)
第四十三章 弹跳训练2(灵识扫描)
“再不脱离便会陷死在里面。”这个声音似乎来自脑海深处某个隐秘角落。 双眼一睁,灵识退去,空空的头壳兀自嗡嗡作响,一股说不清道不明的失落感笼罩全身,似要将自己拖入抑郁的谷底。 不!没什么好失落沮丧的!…...

【location对象的方法,history对象,navigator--BOM】
location对象的方法 location.assign()//跟href一样,可以跳转页面(也称重定向页面) location.replace()//替换当前页面,因为不记录历史,所以不能后退页面 location.reload()//重新加载页面,相当于刷新按钮或…...
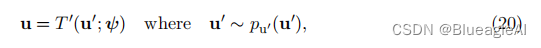
论文笔记:Normalizing Flows for Probabilistic Modeling and Inference
Abstract 正则流(Normalizing flows)提供了一种通用的机制来定义富有表达力的概率分布,只需要指定一个(通常简单的)基础分布和一系列可逆变换。 Intraduction 正则流通过将简单的密度通过一系列变换来产生更丰富、可…...

java 异常类介绍
Java 异常(Exception)是指在程序运行期间出现的错误或异常情况。Java 异常处理机制允许程序在出现异常情况时进行处理,避免程序崩溃或出现不可预知的错误 一、Java 异常的概念 Java 异常是指程序在运行期间出现的错误或异常情况。Java 异常…...
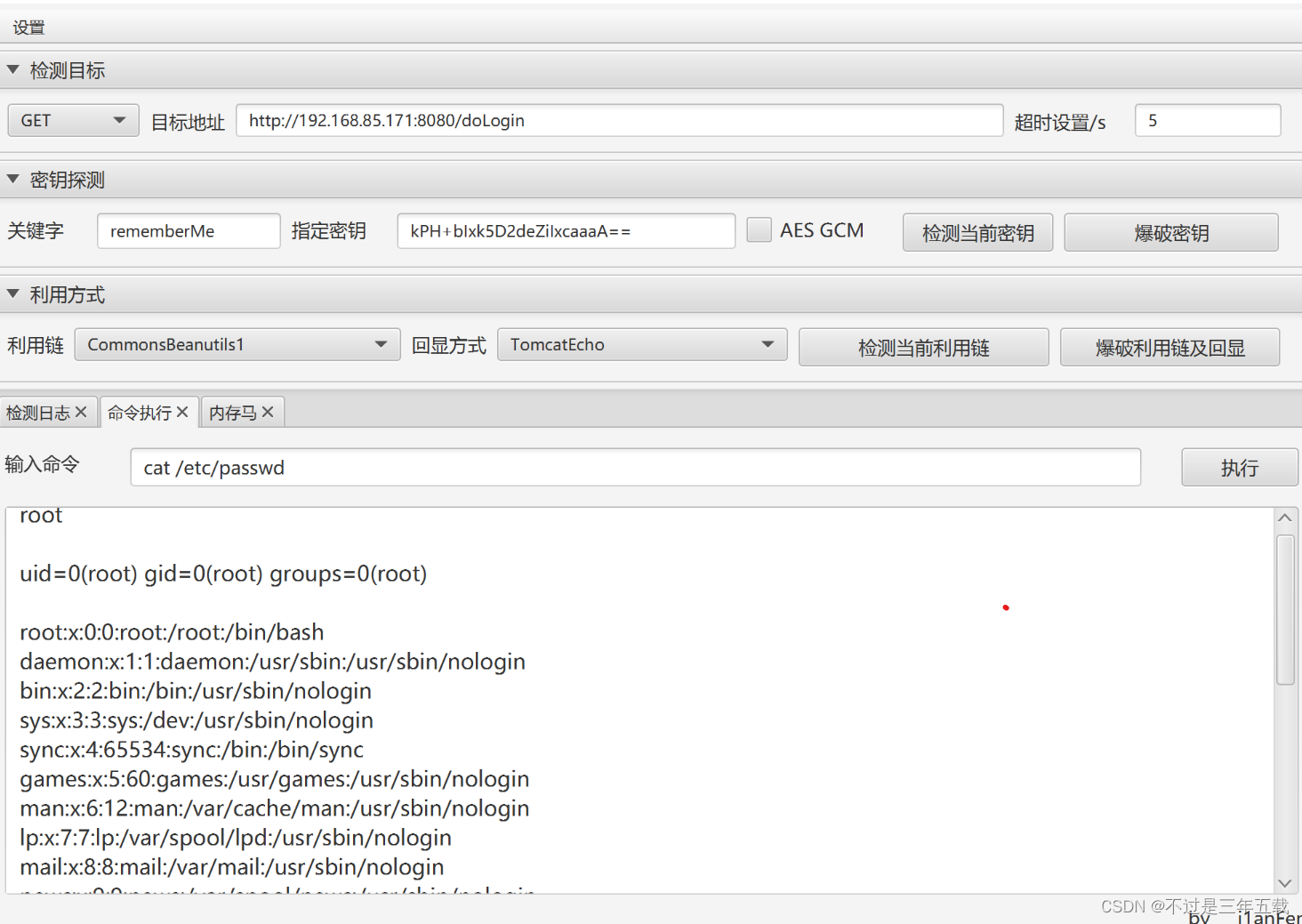
shiro 550 反序列化rce
Apach shiro 是一款开源安全框架,提供身份验证,授权,会话管理等。 shiro 550 反序列化漏洞rce 通关利用它反序列化的漏洞直接执行rce 加密的用户信息序列化后储存在名为remenber -me的cooike中。攻击者可以使用shiro默认密钥伪造cooike&am…...

【C++】---模板初阶(超详练气篇)
个人主页:平行线也会相交💪 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 平行线也会相交 原创 收录于专栏【C之路】💌 本专栏旨在记录C的学习路线,望对大家有所帮助🙇 希望我们一起努力、成长&…...
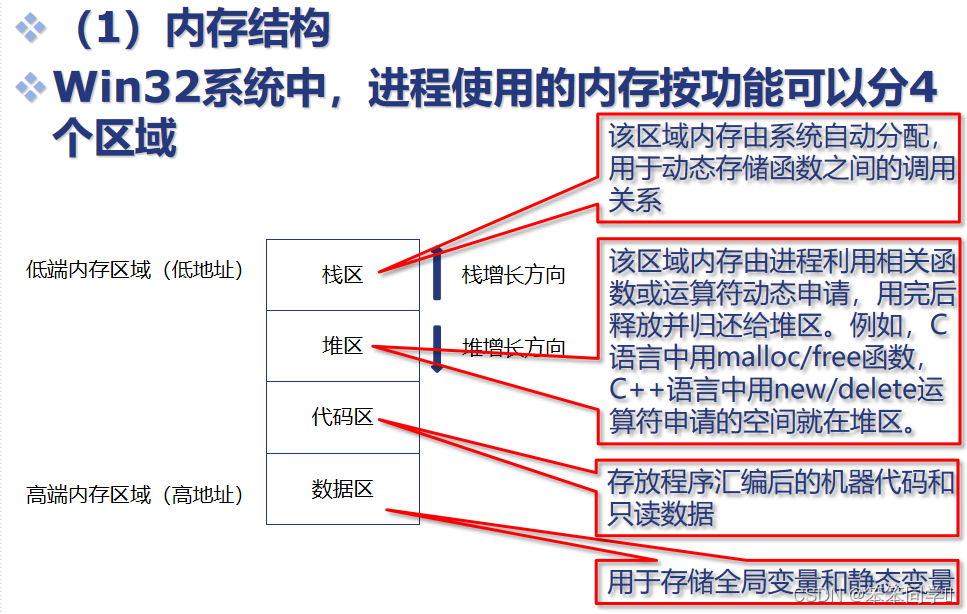
windows系统典型漏洞分析
内存结构 缓冲区溢出漏洞 缓冲区溢出漏洞就是在向缓冲区写入数据时,由于没有做边界检查,导致写入缓冲区的数据超过预先分配的边界,从而使溢出数据覆盖在合法数据上而引起系统异常的一种现象。 ESP、EPB ESP:扩展栈指针(…...

WPF开发txt阅读器:需求分析和文件读写
文章目录 需求分析读取文本文件保存文本文件 需求分析 尽管现在比较主流的阅读格式已经是epub, modi之类的,但txt的使用范围要远比前两者广泛,所以做一个txt阅读器还是有必要的。 但是对于书籍阅读而言,纯文本不包含目录信息,这…...
C++服务器框架开发9——日志系统LogFormatter_4/各个类的关系梳理/std::function/std::get
该专栏记录了在学习一个开发项目的过程中遇到的疑惑和问题。 其教学视频见:[C高级教程]从零开始开发服务器框架(sylar) 上一篇:C服务器框架开发8——日志系统LogFormatter_3/override/宏定义优化switchcase结构 C服务器框架开发9——日志系统LogFormatt…...

LRCGET终极指南:如何快速为本地音乐库批量下载同步歌词的完整解决方案
LRCGET终极指南:如何快速为本地音乐库批量下载同步歌词的完整解决方案 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否拥有海量离线音…...

AI模型选型实战:基于开源工具llmarena.ai的成本与性能对比
1. 项目概述:一个为开发者而生的AI模型比价与选型工具在AI应用开发这个行当里摸爬滚打了几年,我最大的感触就是“选择困难症”越来越严重了。早些年,大家基本就盯着OpenAI的API,GPT-3.5够用,GPT-4更强,没太…...

Dify 2026多模态集成终极 checklist:涵盖17个合规性节点、8类GPU显存泄漏模式、5种跨模态token截断策略
更多请点击: https://intelliparadigm.com 第一章:Dify 2026多模态集成全景概览 Dify 2026标志着低代码AI应用平台正式迈入原生多模态协同时代。其核心架构不再将文本、图像、音频与视频视为独立通道,而是通过统一的语义对齐中间表示&#x…...

DuckDuckGPT:隐私优先的AI搜索工具自建部署与安全实践
1. 项目概述:当DuckDuckGo遇上GPT,一个隐私优先的AI搜索工具如果你和我一样,既想体验AI对话的强大能力,又对数据隐私问题心存芥蒂,那么最近在GitHub上悄然走红的“DuckDuckGPT”项目,绝对值得你花时间研究一…...

别再只用LSTM了!用PyTorch手把手教你搭建BiGRU模型,轻松搞定序列分类任务
突破序列建模思维定式:BiGRU在PyTorch中的高效实践指南 当处理文本分类、时间序列预测等任务时,许多开发者会条件反射地选择LSTM作为默认方案。这种惯性思维可能让我们错过更高效的解决方案——双向门控循环单元(BiGRU)。与LSTM相比,BiGRU在保…...

别只盯着SIwave:用Ansys Q3D提取PCB寄生电感电阻的另一种思路
突破传统思维:Ansys Q3D在PCB寄生参数提取中的高阶应用 在高速PCB设计领域,寄生参数提取一直是个绕不开的关键环节。大多数工程师的第一反应是打开SIwave进行电源完整性分析,却往往忽略了Ansys工具链中另一个隐藏的利器——Q3D Extractor。这…...

RedBench:大语言模型红队测试的通用基准数据集
1. 项目背景与核心价值在人工智能安全领域,大语言模型(LLM)的对抗性测试一直是个棘手问题。传统测试方法往往针对特定风险场景设计,缺乏系统性和可扩展性。RedBench的出现填补了这一空白——这是首个面向大语言模型红队测试的通用基准数据集,…...

3大突破性解决方案:GroundingDINO如何用文本指令彻底改变目标检测
3大突破性解决方案:GroundingDINO如何用文本指令彻底改变目标检测 【免费下载链接】GroundingDINO [ECCV 2024] Official implementation of the paper "Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection" 项目…...

为什么92%的PHP项目还在手写表单逻辑?揭秘被低估的PSR-14事件驱动表单引擎架构
更多请点击: https://intelliparadigm.com 第一章:PHP表单开发的现状与认知陷阱 当前,大量遗留 PHP 应用仍依赖 $_POST 和 $_GET 直接读取表单数据,缺乏输入验证、CSRF 防护与输出转义机制,导致 XSS、SQL 注入与会话…...

VLAM模型优化:提升GUI自动化测试准确率至89%
1. 项目背景与核心价值GUI自动化领域正在经历从传统脚本录制回放向智能交互的范式转变。去年我在为某金融客户端设计自动化测试方案时,发现传统基于坐标定位的脚本在面对频繁迭代的UI时维护成本极高。而当前最前沿的视觉语言动作模型(VLAM)能…...