CUDA中的图内存节点
CUDA中的图内存节点

文章目录
- CUDA中的图内存节点
- 1. 简介
- 2. 支持的架构和版本
- 3. API基础知识
- 3.1. 图节点 APIs
- 3.2. 流捕获
- 3.3. 在分配图之外访问和释放图内存
- 3.4. cudaGraphInstantiateFlagAutoFreeOnLaunch
- 4. 优化内存复用
- 4.1. 解决图中的重用问题
- 4.2. 物理内存管理和共享
- 5. 性能考虑
- 5.1. First Launch / cudaGraphUpload
- 6. Physical Memory Footprint
- 7. Peer Access
- 7.1. Peer Access with Graph Node APIs
- 7.2. Peer Access with Stream Capture
1. 简介
图内存节点允许图创建和拥有内存分配功能。图内存节点具有 GPU 有序生命周期语义,它指示何时允许在设备上访问内存。这些 GPU 有序生命周期语义支持驱动程序管理的内存重用,并与流序分配 API cudaMallocAsync 和 cudaFreeAsync 相匹配,这可能在创建图形时被捕获。
图分配在图的生命周期内具有固定的地址,包括重复的实例化和启动。这允许图中的其他操作直接引用内存,而无需更新图,即使 CUDA 更改了后备物理内存也是如此。在一个图中,其图有序生命周期不重叠的分配可以使用相同的底层物理内存。
CUDA 可以重用相同的物理内存进行跨多个图的分配,根据 GPU 有序生命周期语义对虚拟地址映射进行别名化。例如,当不同的图被启动到同一个流中时,CUDA 可以虚拟地为相同的物理内存取别名,以满足具有单图生命周期的分配的需求。
2. 支持的架构和版本
图内存节点需要支持 11.4 的 CUDA 驱动程序并支持 GPU 上的流序分配器。 以下代码段显示了如何检查给定设备上的支持。
int driverVersion = 0;
int deviceSupportsMemoryPools = 0;
int deviceSupportsMemoryNodes = 0;
cudaDriverGetVersion(&driverVersion);
if (driverVersion >= 11020) { // avoid invalid value error in cudaDeviceGetAttributecudaDeviceGetAttribute(&deviceSupportsMemoryPools, cudaDevAttrMemoryPoolsSupported, device);
}
deviceSupportsMemoryNodes = (driverVersion >= 11040) && (deviceSupportsMemoryPools != 0);在驱动程序版本检查中执行属性查询可避免 11.0 和 11.1 驱动程序上的无效值返回代码。 请注意,计算清理程序在检测到 CUDA 返回错误代码时会发出警告,并且在读取属性之前进行版本检查将避免这种情况。 图形内存节点仅在驱动程序版本 11.4 和更高版本上受支持。
3. API基础知识
图内存节点是表示内存分配或空闲操作的图节点。 简而言之,分配内存的节点称为分配节点。 同样,释放内存的节点称为空闲节点。 分配节点创建的分配称为图分配。 CUDA 在节点创建时为图分配分配虚拟地址。 虽然这些虚拟地址在分配节点的生命周期内是固定的,但分配内容在释放操作之后不会持久,并且可能被引用不同分配的访问覆盖。
每次图运行时,图分配都被视为重新创建。 图分配的生命周期与节点的生命周期不同,从 GPU 执行到达分配图节点时开始,并在发生以下情况之一时结束:
- GPU 执行到达释放图节点
- GPU 执行到达释放
cudaFreeAsync()流调用 - 立即释放对
cudaFree()的调用
注意:图销毁不会自动释放任何实时图分配的内存,即使它结束了分配节点的生命周期。 随后必须在另一个图中或使用 cudaFreeAsync()/cudaFree() 释放分配。
就像其他图节点一样,图内存节点在图中按依赖边排序。 程序必须保证访问图内存的操作:
- 在分配节点之后排序。
- 在释放内存的操作之前排序
图分配生命周期根据 GPU 执行开始和结束(与 API 调用相反)。 GPU 排序是工作在 GPU 上运行的顺序,而不是工作队列或描述的顺序。 因此,图分配被认为是“GPU 有序”。
3.1. 图节点 APIs
可以使用内存节点创建 API、cudaGraphAddMemAllocNode 和 cudaGraphAddMemFreeNode 显式创建图形内存节点。 cudaGraphAddMemAllocNode 分配的地址在传递的 CUDA_MEM_ALLOC_NODE_PARAMS 结构的 dptr 字段中返回给用户。 在分配图中使用图分配的所有操作必须在分配节点之后排序。 类似地,任何空闲节点都必须在图中所有分配的使用之后进行排序。 cudaGraphAddMemFreeNode 创建空闲节点。
在下图中,有一个带有分配和空闲节点的示例图。 内核节点 a、b 和 c 在分配节点之后和空闲节点之前排序,以便内核可以访问分配。 内核节点 e 没有排在 alloc 节点之后,因此无法安全地访问内存。 内核节点 d 没有排在空闲节点之前,因此它不能安全地访问内存。
以下代码片段建立了该图中的图:
// Create the graph - it starts out empty
cudaGraphCreate(&graph, 0);// parameters for a basic allocation
cudaMemAllocNodeParams params = {};
params.poolProps.allocType = cudaMemAllocationTypePinned;
params.poolProps.location.type = cudaMemLocationTypeDevice;
// specify device 0 as the resident device
params.poolProps.location.id = 0;
params.bytesize = size;cudaGraphAddMemAllocNode(&allocNode, graph, NULL, 0, ¶ms);
nodeParams->kernelParams[0] = params.dptr;
cudaGraphAddKernelNode(&a, graph, &allocNode, 1, &nodeParams);
cudaGraphAddKernelNode(&b, graph, &a, 1, &nodeParams);
cudaGraphAddKernelNode(&c, graph, &a, 1, &nodeParams);
cudaGraphNode_t dependencies[2];
// kernel nodes b and c are using the graph allocation, so the freeing node must depend on them. Since the dependency of node b on node a establishes an indirect dependency, the free node does not need to explicitly depend on node a.
dependencies[0] = b;
dependencies[1] = c;
cudaGraphAddMemFreeNode(&freeNode, graph, dependencies, 2, params.dptr);
// free node does not depend on kernel node d, so it must not access the freed graph allocation.
cudaGraphAddKernelNode(&d, graph, &c, 1, &nodeParams);// node e does not depend on the allocation node, so it must not access the allocation. This would be true even if the freeNode depended on kernel node e.
cudaGraphAddKernelNode(&e, graph, NULL, 0, &nodeParams);
3.2. 流捕获
可以通过捕获相应的流序分配和免费调用 cudaMallocAsync 和 cudaFreeAsync 来创建图形内存节点。 在这种情况下,捕获的分配 API 返回的虚拟地址可以被图中的其他操作使用。 由于流序的依赖关系将被捕获到图中,流序分配 API 的排序要求保证了图内存节点将根据捕获的流操作正确排序(对于正确编写的流代码)。
忽略内核节点 d 和 e,为清楚起见,以下代码片段显示了如何使用流捕获来创建上图中的图形:
cudaMallocAsync(&dptr, size, stream1);
kernel_A<<< ..., stream1 >>>(dptr, ...);// Fork into stream2
cudaEventRecord(event1, stream1);
cudaStreamWaitEvent(stream2, event1);kernel_B<<< ..., stream1 >>>(dptr, ...);
// event dependencies translated into graph dependencies, so the kernel node created by the capture of kernel C will depend on the allocation node created by capturing the cudaMallocAsync call.
kernel_C<<< ..., stream2 >>>(dptr, ...);// Join stream2 back to origin stream (stream1)
cudaEventRecord(event2, stream2);
cudaStreamWaitEvent(stream1, event2);// Free depends on all work accessing the memory.
cudaFreeAsync(dptr, stream1);// End capture in the origin stream
cudaStreamEndCapture(stream1, &graph);
3.3. 在分配图之外访问和释放图内存
图分配不必由分配图释放。当图不释放分配时,该分配会在图执行之后持续存在,并且可以通过后续 CUDA 操作访问。这些分配可以在另一个图中访问或直接通过流操作访问,只要访问操作在分配之后通过 CUDA 事件和其他流排序机制进行排序。随后可以通过定期调用 cudaFree、cudaFreeAsync 或通过启动具有相应空闲节点的另一个图,或随后启动分配图(如果它是使用 cudaGraphInstantiateFlagAutoFreeOnLaunch 标志实例化)来释放分配。在内存被释放后访问内存是非法的 - 必须在所有使用图依赖、CUDA 事件和其他流排序机制访问内存的操作之后对释放操作进行排序。
注意:因为图分配可能彼此共享底层物理内存,所以必须考虑与一致性和一致性相关的虚拟混叠支持规则。简单地说,空闲操作必须在完整的设备操作(例如,计算内核/ memcpy)完成后排序。具体来说,带外同步——例如,作为访问图形内存的计算内核的一部分,通过内存进行信号交换——不足以提供对图形内存的写操作和该图形内存的自由操作之间的排序保证。
以下代码片段演示了在分配图之外访问图分配,并通过以下方式正确建立顺序:使用单个流,使用流之间的事件,以及使用嵌入到分配和释放图中的事件。
使用单个流建立的排序:
void *dptr;
cudaGraphAddMemAllocNode(&allocNode, allocGraph, NULL, 0, ¶ms);
dptr = params.dptr;cudaGraphInstantiate(&allocGraphExec, allocGraph, NULL, NULL, 0);cudaGraphLaunch(allocGraphExec, stream);
kernel<<< …, stream >>>(dptr, …);
cudaFreeAsync(dptr, stream);
通过记录和等待 CUDA 事件建立的排序:
void *dptr;// Contents of allocating graph
cudaGraphAddMemAllocNode(&allocNode, allocGraph, NULL, 0, ¶ms);
dptr = params.dptr;// contents of consuming/freeing graph
nodeParams->kernelParams[0] = params.dptr;
cudaGraphAddKernelNode(&a, graph, NULL, 0, &nodeParams);
cudaGraphAddMemFreeNode(&freeNode, freeGraph, &a, 1, dptr);cudaGraphInstantiate(&allocGraphExec, allocGraph, NULL, NULL, 0);
cudaGraphInstantiate(&freeGraphExec, freeGraph, NULL, NULL, 0);cudaGraphLaunch(allocGraphExec, allocStream);// establish the dependency of stream2 on the allocation node
// note: the dependency could also have been established with a stream synchronize operation
cudaEventRecord(allocEvent, allocStream)
cudaStreamWaitEvent(stream2, allocEvent);kernel<<< …, stream2 >>> (dptr, …);// establish the dependency between the stream 3 and the allocation use
cudaStreamRecordEvent(streamUseDoneEvent, stream2);
cudaStreamWaitEvent(stream3, streamUseDoneEvent);// it is now safe to launch the freeing graph, which may also access the memory
cudaGraphLaunch(freeGraphExec, stream3);
使用图外部事件节点建立的排序:
void *dptr;
cudaEvent_t allocEvent; // event indicating when the allocation will be ready for use.
cudaEvent_t streamUseDoneEvent; // event indicating when the stream operations are done with the allocation.// Contents of allocating graph with event record node
cudaGraphAddMemAllocNode(&allocNode, allocGraph, NULL, 0, ¶ms);
dptr = params.dptr;
// note: this event record node depends on the alloc node
cudaGraphAddEventRecordNode(&recordNode, allocGraph, &allocNode, 1, allocEvent);
cudaGraphInstantiate(&allocGraphExec, allocGraph, NULL, NULL, 0);// contents of consuming/freeing graph with event wait nodes
cudaGraphAddEventWaitNode(&streamUseDoneEventNode, waitAndFreeGraph, NULL, 0, streamUseDoneEvent);
cudaGraphAddEventWaitNode(&allocReadyEventNode, waitAndFreeGraph, NULL, 0, allocEvent);
nodeParams->kernelParams[0] = params.dptr;// The allocReadyEventNode provides ordering with the alloc node for use in a consuming graph.
cudaGraphAddKernelNode(&kernelNode, waitAndFreeGraph, &allocReadyEventNode, 1, &nodeParams);// The free node has to be ordered after both external and internal users.
// Thus the node must depend on both the kernelNode and the
// streamUseDoneEventNode.
dependencies[0] = kernelNode;
dependencies[1] = streamUseDoneEventNode;
cudaGraphAddMemFreeNode(&freeNode, waitAndFreeGraph, &dependencies, 2, dptr);
cudaGraphInstantiate(&waitAndFreeGraphExec, waitAndFreeGraph, NULL, NULL, 0);cudaGraphLaunch(allocGraphExec, allocStream);// establish the dependency of stream2 on the event node satisfies the ordering requirement
cudaStreamWaitEvent(stream2, allocEvent);
kernel<<< …, stream2 >>> (dptr, …);
cudaStreamRecordEvent(streamUseDoneEvent, stream2);// the event wait node in the waitAndFreeGraphExec establishes the dependency on the “readyForFreeEvent” that is needed to prevent the kernel running in stream two from accessing the allocation after the free node in execution order.
cudaGraphLaunch(waitAndFreeGraphExec, stream3);
3.4. cudaGraphInstantiateFlagAutoFreeOnLaunch
在正常情况下,如果图有未释放的内存分配,CUDA 将阻止重新启动图,因为同一地址的多个分配会泄漏内存。使用 cudaGraphInstantiateFlagAutoFreeOnLaunch 标志实例化图允许图在其仍有未释放的分配时重新启动。在这种情况下,启动会自动插入一个异步释放的未释放分配。
启动时自动对于单生产者多消费者算法很有用。在每次迭代中,生产者图创建多个分配,并且根据运行时条件,一组不同的消费者访问这些分配。这种类型的变量执行序列意味着消费者无法释放分配,因为后续消费者可能需要访问。启动时自动释放意味着启动循环不需要跟踪生产者的分配 - 相反,该信息与生产者的创建和销毁逻辑保持隔离。通常,启动时自动释放简化了算法,否则该算法需要在每次重新启动之前释放图所拥有的所有分配。
注意: cudaGraphInstantiateFlagAutoFreeOnLaunch 标志不会改变图销毁的行为。应用程序必须显式释放未释放的内存以避免内存泄漏,即使对于使用标志实例化的图也是如此。
以下代码展示了使用 cudaGraphInstantiateFlagAutoFreeOnLaunch 来简化单生产者/多消费者算法:
// Create producer graph which allocates memory and populates it with data
cudaStreamBeginCapture(cudaStreamPerThread, cudaStreamCaptureModeGlobal);
cudaMallocAsync(&data1, blocks * threads, cudaStreamPerThread);
cudaMallocAsync(&data2, blocks * threads, cudaStreamPerThread);
produce<<<blocks, threads, 0, cudaStreamPerThread>>>(data1, data2);
...
cudaStreamEndCapture(cudaStreamPerThread, &graph);
cudaGraphInstantiateWithFlags(&producer,graph,cudaGraphInstantiateFlagAutoFreeOnLaunch);
cudaGraphDestroy(graph);// Create first consumer graph by capturing an asynchronous library call
cudaStreamBeginCapture(cudaStreamPerThread, cudaStreamCaptureModeGlobal);
consumerFromLibrary(data1, cudaStreamPerThread);
cudaStreamEndCapture(cudaStreamPerThread, &graph);
cudaGraphInstantiateWithFlags(&consumer1, graph, 0); //regular instantiation
cudaGraphDestroy(graph);// Create second consumer graph
cudaStreamBeginCapture(cudaStreamPerThread, cudaStreamCaptureModeGlobal);
consume2<<<blocks, threads, 0, cudaStreamPerThread>>>(data2);
...
cudaStreamEndCapture(cudaStreamPerThread, &graph);
cudaGraphInstantiateWithFlags(&consumer2, graph, 0);
cudaGraphDestroy(graph);// Launch in a loop
bool launchConsumer2 = false;
do {cudaGraphLaunch(producer, myStream);cudaGraphLaunch(consumer1, myStream);if (launchConsumer2) {cudaGraphLaunch(consumer2, myStream);}
} while (determineAction(&launchConsumer2));cudaFreeAsync(data1, myStream);
cudaFreeAsync(data2, myStream);cudaGraphExecDestroy(producer);
cudaGraphExecDestroy(consumer1);
cudaGraphExecDestroy(consumer2);
4. 优化内存复用
CUDA 以两种方式重用内存:
- 图中的虚拟和物理内存重用基于虚拟地址分配,就像在流序分配器中一样。
- 图之间的物理内存重用是通过虚拟别名完成的:不同的图可以将相同的物理内存映射到它们唯一的虚拟地址。
4.1. 解决图中的重用问题
CUDA 可以通过将相同的虚拟地址范围分配给生命周期不重叠的不同分配来重用图中的内存。 由于可以重用虚拟地址,因此不能保证指向具有不相交生命周期的不同分配的指针是唯一的。
下图显示了添加一个新的分配节点 (2),它可以重用依赖节点 (1) 释放的地址。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WyskpwCH-1675998508667)(new-alloc-node.png)]
下图显示了添加新的 alloc 节点(3)。 新的分配节点不依赖于空闲节点 (2),因此不能重用来自关联分配节点 (2) 的地址。 如果分配节点 (2) 使用由空闲节点 (1) 释放的地址,则新分配节点 3 将需要一个新地址。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FSu9HS4r-1675998508667)(adding-new-alloc-nodes.png)]
4.2. 物理内存管理和共享
CUDA 负责在按 GPU 顺序到达分配节点之前将物理内存映射到虚拟地址。作为内存占用和映射开销的优化,如果多个图不会同时运行,它们可能会使用相同的物理内存进行不同的分配,但是如果它们同时绑定到多个执行图,则物理页面不能被重用,或未释放的图形分配。
CUDA 可以在图形实例化、启动或执行期间随时更新物理内存映射。 CUDA 还可以在未来的图启动之间引入同步,以防止实时图分配引用相同的物理内存。对于任何 allocate-free-allocate 模式,如果程序在分配的生命周期之外访问指针,错误的访问可能会默默地读取或写入另一个分配拥有的实时数据(即使分配的虚拟地址是唯一的)。使用计算清理工具可以捕获此错误。
下图显示了在同一流中按顺序启动的图形。在此示例中,每个图都会释放它分配的所有内存。由于同一流中的图永远不会同时运行,CUDA 可以而且应该使用相同的物理内存来满足所有分配。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yqcLZiwv-1675998508667)(sequentially-launched-graphs.png)]
5. 性能考虑
当多个图启动到同一个流中时,CUDA 会尝试为它们分配相同的物理内存,因为这些图的执行不能重叠。 在启动之间保留图形的物理映射作为优化以避免重新映射的成本。 如果稍后启动其中一个图,使其执行可能与其他图重叠(例如,如果它启动到不同的流中),则 CUDA 必须执行一些重新映射,因为并发图需要不同的内存以避免数据损坏 .
一般来说,CUDA中图内存的重新映射很可能是由这些操作引起的
- 更改启动图形的流
- 图内存池上的修剪操作,显式释放未使用的内存(在物理内存占用中讨论)
- 当另一个图的未释放分配映射到同一内存时重新启动一个图将导致在重新启动之前重新映射内存
重新映射必须按执行顺序发生,但在该图的任何先前执行完成之后(否则可能会取消映射仍在使用的内存)。 由于这种排序依赖性,以及映射操作是操作系统调用,映射操作可能相对昂贵。 应用程序可以通过将包含分配内存节点的图一致地启动到同一流中来避免这种成本。
5.1. First Launch / cudaGraphUpload
在图实例化期间无法分配或映射物理内存,因为图将在其中执行的流是未知的。 映射是在图形启动期间完成的。 调用 cudaGraphUpload 可以通过立即执行该图的所有映射并将该图与上传流相关联,将分配成本与启动分开。 如果图随后启动到同一流中,它将启动而无需任何额外的重新映射。
使用不同的流进行图上传和图启动的行为类似于切换流,可能会导致重新映射操作。 此外,允许无关的内存池管理从空闲流中提取内存,这可能会抵消上传的影响。
6. Physical Memory Footprint
异步分配的池管理行为意味着销毁包含内存节点的图(即使它们的分配是空闲的)不会立即将物理内存返回给操作系统以供其他进程使用。要显式将内存释放回操作系统,应用程序应使用 cudaDeviceGraphMemTrim API。
cudaDeviceGraphMemTrim 将取消映射并释放由图形内存节点保留的未主动使用的任何物理内存。尚未释放的分配和计划或运行的图被认为正在积极使用物理内存,不会受到影响。使用修剪 API 将使物理内存可用于其他分配 API 和其他应用程序或进程,但会导致 CUDA 在下次启动修剪图时重新分配和重新映射内存。请注意,cudaDeviceGraphMemTrim 在与 cudaMemPoolTrimTo() 不同的池上运行。图形内存池不会暴露给流序内存分配器。 CUDA 允许应用程序通过 cudaDeviceGetGraphMemAttribute API 查询其图形内存占用量。查询属性 cudaGraphMemAttrReservedMemCurrent 返回驱动程序为当前进程中的图形分配保留的物理内存量。查询 cudaGraphMemAttrUsedMemCurrent 返回至少一个图当前映射的物理内存量。这些属性中的任何一个都可用于跟踪 CUDA 何时为分配图而获取新的物理内存。这两个属性对于检查共享机制节省了多少内存都很有用。
7. Peer Access
图分配可以配置为从多个 GPU 访问,在这种情况下,CUDA 将根据需要将分配映射到对等 GPU。 CUDA 允许需要不同映射的图分配重用相同的虚拟地址。 发生这种情况时,地址范围将映射到不同分配所需的所有 GPU。 这意味着分配有时可能允许比其创建期间请求的更多对等访问; 然而,依赖这些额外的映射仍然是一个错误。
7.1. Peer Access with Graph Node APIs
cudaGraphAddMemAllocNode API 接受节点参数结构的 accessDescs 数组字段中的映射请求。 poolProps.location 嵌入式结构指定分配的常驻设备。 假设需要来自分配 GPU 的访问,因此应用程序不需要在 accessDescs 数组中为常驻设备指定条目。
cudaMemAllocNodeParams params = {};
params.poolProps.allocType = cudaMemAllocationTypePinned;
params.poolProps.location.type = cudaMemLocationTypeDevice;
// specify device 1 as the resident device
params.poolProps.location.id = 1;
params.bytesize = size;// allocate an allocation resident on device 1 accessible from device 1
cudaGraphAddMemAllocNode(&allocNode, graph, NULL, 0, ¶ms);accessDescs[2];
// boilerplate for the access descs (only ReadWrite and Device access supported by the add node api)
accessDescs[0].flags = cudaMemAccessFlagsProtReadWrite;
accessDescs[0].location.type = cudaMemLocationTypeDevice;
accessDescs[1].flags = cudaMemAccessFlagsProtReadWrite;
accessDescs[1].location.type = cudaMemLocationTypeDevice;// access being requested for device 0 & 2. Device 1 access requirement left implicit.
accessDescs[0].location.id = 0;
accessDescs[1].location.id = 2;// access request array has 2 entries.
params.accessDescCount = 2;
params.accessDescs = accessDescs;// allocate an allocation resident on device 1 accessible from devices 0, 1 and 2. (0 & 2 from the descriptors, 1 from it being the resident device).
cudaGraphAddMemAllocNode(&allocNode, graph, NULL, 0, ¶ms);
7.2. Peer Access with Stream Capture
对于流捕获,分配节点在捕获时记录分配池的对等可访问性。 在捕获 cudaMallocFromPoolAsync 调用后更改分配池的对等可访问性不会影响图将为分配进行的映射。
// boilerplate for the access descs (only ReadWrite and Device access supported by the add node api)
accessDesc.flags = cudaMemAccessFlagsProtReadWrite;
accessDesc.location.type = cudaMemLocationTypeDevice;
accessDesc.location.id = 1;// let memPool be resident and accessible on device 0cudaStreamBeginCapture(stream);
cudaMallocAsync(&dptr1, size, memPool, stream);
cudaStreamEndCapture(stream, &graph1);cudaMemPoolSetAccess(memPool, &accessDesc, 1);cudaStreamBeginCapture(stream);
cudaMallocAsync(&dptr2, size, memPool, stream);
cudaStreamEndCapture(stream, &graph2);//The graph node allocating dptr1 would only have the device 0 accessibility even though memPool now has device 1 accessibility.
//The graph node allocating dptr2 will have device 0 and device 1 accessibility, since that was the pool accessibility at the time of the cudaMallocAsync call.
相关文章:
CUDA中的图内存节点
CUDA中的图内存节点 文章目录CUDA中的图内存节点1. 简介2. 支持的架构和版本3. API基础知识3.1. 图节点 APIs3.2. 流捕获3.3. 在分配图之外访问和释放图内存3.4. cudaGraphInstantiateFlagAutoFreeOnLaunch4. 优化内存复用4.1. 解决图中的重用问题4.2. 物理内存管理和共享5. 性…...

你真的看好低代码开发吗?
低代码开发前景如何,大家真的看好低代码开发吗?之前有过很多关于低代码的内容,这篇就来梳理下国内外低代码开发平台发展现状及前景。 01、国外低代码开发平台现状 2014年,研究机构Forrester Research发表的报告中提到“面向客户…...
一篇带你MySQL运维
1. 日志 1.1 错误日志 错误日志是 MySQL 中 重要的日志之一,它记录了当 mysqld启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息。当数据库出现任何故障导致无法正常使用时,建议首先查看此日志。 该日志是默认开启的&…...

《嵌入式 – GD32开发实战指南》第22章 SPI
开发环境: MDK:Keil 5.30 开发板:GD32F207I-EVAL MCU:GD32F207IK 22.1 SPI简介 SPI,是Serial Peripheral interface的缩写,顾名思义就是串行外围设备接口。是Motorola首先在其MC68HCXX系列处理器上定义的…...

一个优质软件测试工程师的简历应该有的样子(答应我一定要收藏起来)
个人简历 基本信息 姓 名:xxx 性 别: 女 年 龄:24 现住 地址: 深圳 测试 经验:3年 学 历:本科 联系 电话:18xxxxxxxx 邮 箱:xxxxl163.com 求职意向 应聘岗位:软件…...
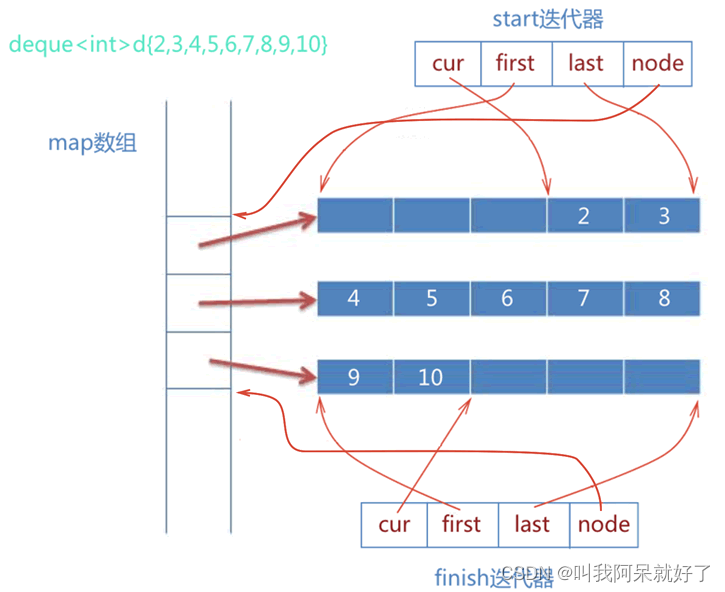
C++ 浅谈之 STL Deque
C 浅谈之 STL Deque HELLO,各位博友好,我是阿呆 🙈🙈🙈 这里是 C 浅谈系列,收录在专栏 C 语言中 😜😜😜 本系列阿呆将记录一些 C 语言重要的语法特性 🏃&a…...

Koa2-项目中的基本应用
文章目录安装配置koa2配置nodemon,热更新我们的项目中间件什么是中间件👻洋葱模型路由中间件连接数据库 - mysql后端允许跨域处理请求getpostputdelete后续会继续更新安装配置koa2 👻安装 koa2 npm i koa2 -s👻在package.json 配置,当然是在…...
:配置)
Flask入门(2):配置
目录2.Flask配置2.1 直接写入主脚本2.2 系统环境变量2.3 单独的配置文件2.4 多个配置类2.5 Flask内置配置2.Flask配置 我们都知道,Flask应用程序肯定是需要各种各样的配置。来满足我们不同的需求的,这样可以使我们的应用程序更加灵活。比如可以根据需要…...

Linux--fork
一、fork入门知识 fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。可以简单地说fork()的作用就是创建一…...
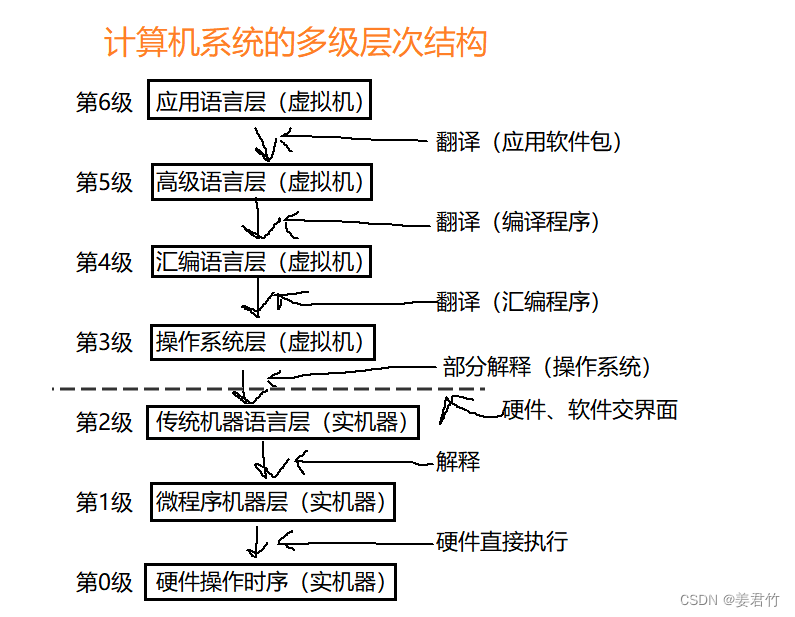
计算机组成原理(一)
1.了解计算机硬件的发展和软件的发展历程; 硬件: 电子管时代(1946-1959):电子管、声汞延迟线、磁鼓 晶体管时代(1959-1964):晶体管、磁芯 中、小规模集成电路时代&#…...

【SpringBoot】实现Async异步任务
1. 环境准备 在 Spring Boot 入口类上配置 EnableAsync 注解开启异步处理。 创建任务抽象类 AbstractTask,并分别配置三个任务方法 doTaskOne(),doTaskTwo(),doTaskThree()。 public abstract class AbstractTask {private static Random r…...

Node =>Express学习
1.Express 能做什么 能快速构建web网站的服务器 或 Api接口的服务期 Web网站服务器,专门对外提供Web网页资源的服务器Api接口服务器:专门对外提供API接口的服务器 2.安装 在项目所处的目录中,运行以下命令,简装到项目中了 npm …...
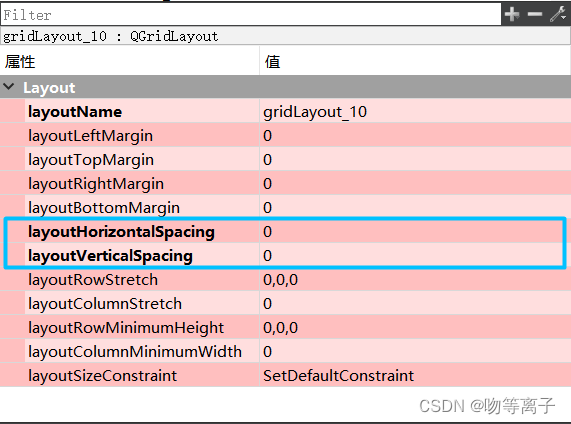
QT基础入门【布局篇】消除控件之间的间隔
一、相关参数 layoutLeftMargin: layout内的布局距离边框左端的距离。 layoutTopMargin: layout内的布局距离边框顶端的距离。 layoutRightMargin: layout内的布局距离边框右端的距离。 layoutBottomMargin: layout内的布局距离边框底端的距离。 layoutHorizontalSpacing: layo…...

vue脚手架 element-ui spring boot 实现图片上传阿里云 并保存到数据库
一.阿里云 注册登陆就不讲了,登陆进去后如下操作 1. 进入对象存储OSS 创建一个新的Bucket 随后点击新建的bucket 2.去访问RAM 前往RAM控制台 3.去创建用户 4.创建密匙 5.随后返回RAM控制台 给用户增加权限,文件上传所需权限,需要带含有…...

【FPGA】Verilog:组合电路 | 3—8译码器 | 编码器 | 74LS148
前言:本章内容主要是演示Vivado下利用Verilog语言进行电路设计、仿真、综合和下载 示例:编码/译码器的应用 功能特性: 采用 Xilinx Artix-7 XC7A35T芯片 配置方式:USB-JTAG/SPI Flash 高达100MHz 的内部时钟速度 存储器&…...
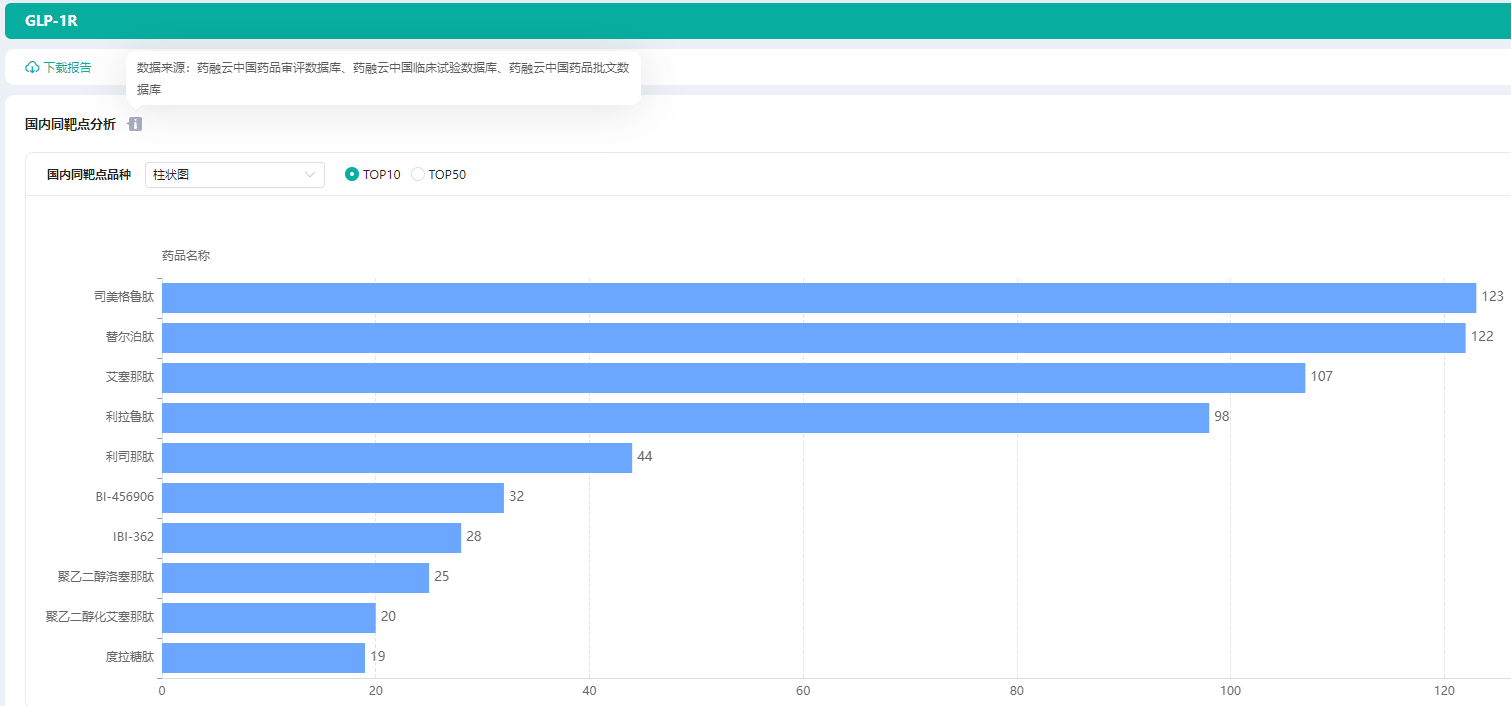
GLP-1类药物研发进展-销售数据-上市药品前景分析
据一项2021 年的报告发现,当 GLP-1 类似物用于治疗 2 型糖尿病时,全因死亡率降低了 12%,它们不仅降糖效果显著,同时还兼具减重、降压、改善血脂谱等作用。近几年,随着GLP-1R激动剂类药物市场规模不断增长,美…...

C++远程监控系统接收端- RevPlayMDIChildWnd.cpp
void CRevPlayWnd::InitMultiSock() { int RevBuf; int status; BOOL bFlag; CString ErrMsg; SOCKADDR_IN stLocalAddr; SOCKADDR_IN stDestAddr; SOCKET hNewSock; int RevLensizeof(RevBuf); //创建一个IP组播套接字 MultiSock W…...
QT之OpenGL深度测试
QT之OpenGL深度测试1. 深度测试概述1. 1 提前深度测试1.2 深度测试相关函数2. 深度测试精度2.1 深度冲突3. Demo4. 参考1. 深度测试概述 在OpenGL中深度测试(Depth Testing)是关闭的,此时在渲染图形时会产生一种现象后渲染的会把最先渲染的遮挡住。而在启用深度测试…...
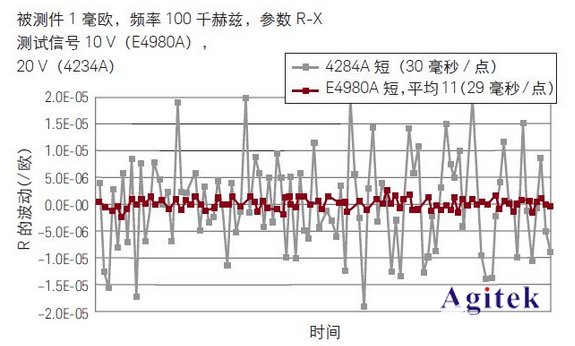
用LCR测试仪测试无线充电系统中的线圈
宽阻抗范围用来表征电感和质量因数– 高精度 DCR 测量– 制造环节快速测量– 大量夹具可供选择智能终端上不断增加新功能,电池寿命成为用户最头痛的问题之一。相比便携式电源和电缆供电而言,无线充电技术因其方便性和多功能性获得了很大的关注࿰…...

华为、南卡和漫步者蓝牙耳机怎么选?国产高性价比蓝牙耳机推荐
随着蓝牙耳机的快速发展,现如今使用蓝牙耳机的人也越来越多。其中,日益增多的国产蓝牙耳机品牌也逐渐被大众认识、认可。目前一些热销的国产蓝牙耳机,如华为、南卡和漫步者等都是大家比较熟知的品牌。那么,这三个品牌哪个性价比高…...

世界第一个开源可商用 .NET Office 转 PDF 工具/库 - MiniPdf涝
1. 智能软件工程的范式转移:从库集成到原生框架演进 在生成式人工智能(Generative AI)从单纯的文本生成向具备自主规划与执行能力的“代理化(Agentic)”系统跨越的过程中,.NET 生态系统正在经历一场自该平台…...

Windows Server 2019开启SSH服务踩坑全记录:从PowerShell命令到防火墙规则,一篇搞定
Windows Server 2019 SSH服务部署终极指南:从零构建到企业级安全配置 当我们需要在Windows Server环境中实现安全高效的远程管理时,SSH服务已经成为现代运维体系中不可或缺的一环。不同于传统的RDP远程桌面,SSH提供了更轻量级、更安全的命令行…...
)
华为OD机试 - FLASH坏块监测系统 - 并查集(Java 新系统 200分)
华为OD机试 新系统 题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试(JAVA)真题》。 刷的越多,抽中的概率越大,私信哪吒,备注华为OD,加入华为OD刷题交流群,每一题都有详细的答题思路、详细的代码注释、3个测试用例、为什么这道题采用XX算法、XX算法的适…...

RelayModule:嵌入式继电器面向对象驱动库
1. RelayModule 库深度解析:面向嵌入式系统的数字继电器模块面向对象驱动设计继电器是嵌入式系统中实现强电控制与弱电隔离的核心执行器件,广泛应用于工业自动化、智能家居、电源管理及测试设备等场景。传统继电器驱动多采用裸机 GPIO 直接控制ÿ…...

怎么查询MongoDB中数组长度大于N的文档_基于索引的额外长度字段方案
MongoDB中用$expr$size查数组长度大于N的文档虽原生支持,但无法走索引,适合中小集合或配合其他可索引条件使用;而维护tags_length字段并建索引可实现高效范围查询,前提是严格保证写时一致性。用 $expr $size 直接查数组长度大于 …...

3步搞定微信聊天记录完整备份:WeChatExporter终极免费解决方案
3步搞定微信聊天记录完整备份:WeChatExporter终极免费解决方案 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 微信聊天记录中保存着珍贵的记忆和重要的工作沟…...

MySQL锁机制:从全局锁到行级锁的深度解读秤
如果有多个供应商,你也可以使用 [[CC-Switch]] 来可视化管理这些API key,以及claude code 的skills。 # 多平台安装指令 curl -fsSL https://claude.ai/install.sh | bash ## Claude Code 配置 GLM Coding Plan curl -O "https://cdn.bigmodel.cn/i…...

ESP32/ESP8266轻量级OTA固件升级库详解
1. 项目概述ESP32FwUploader 是一款专为 ESP32 和 ESP8266 系列微控制器设计的轻量级、高可靠性固件空中升级(Over-The-Air, OTA)库。它并非简单封装 ESP-IDF 或 Arduino Core 的原生 OTA 接口,而是以“开箱即用”和“工程鲁棒性”为核心目标…...

Typecho完美实现回复可见功能
之前转载过这么一篇文章《typecho非插件实现回复可见功能》,可以实现回复可见功能,但是有个问题,在文章列表页展示文章缩略内容时,如果回复可见内容刚好在缩略内容的位置上时,就会暴露出来,同时Feed里面也会…...

LVGL Linux模拟器实战:从GUI-Guider设计到EVDEV按键事件处理的完整链路
LVGL Linux模拟器实战:从GUI-Guider设计到EVDEV按键事件处理的完整链路 在嵌入式GUI开发领域,LVGL凭借其轻量级、高性能的特性已成为众多开发者的首选。本文将带您深入探索一个常被忽视但至关重要的技术环节:如何让GUI-Guider设计的界面在Lin…...