MySQL 索引及查询优化总结
一个简单的对比测试
前面的案例中,c2c_zwdb.t_file_count表只有一个自增id,FFileName字段未加索引的sql执行情况如下:

在上图中,type=all,key=null,rows=33777。该sql未使用索引,是一个效率非常低的全表扫描。如果加上联合查询和其他一些约束条件,数据库会疯狂的消耗内存,并且会影响前端程序的执行。
这时给FFileName字段添加一个索引:
alter table c2c_zwdb.t_file_count add index index_title(FFileName);
再次执行上述查询语句,其对比很明显:

在该图中,type=ref,key=索引名(index_title),rows=1。该sql使用了索引index_title,且是一个常数扫描,根据索引只扫描了一行。
比起未加索引的情况,加了索引后,查询效率对比非常明显。
MySQL索引
通过上面的对比测试可以看出,索引是快速搜索的关键。MySQL索引的建立对于MySQL的高效运行是很重要的。对于少量的数据,没有合适的索引影响不是很大,但是,当随着数据量的增加,性能会急剧下降。如果对多列进行索引(组合索引),列的顺序非常重要,MySQL仅能对索引最左边的前缀进行有效的查找。
下面介绍几种常见的MySQL索引类型。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。
1、MySQL索引类型
(1) 主键索引 PRIMARY KEY
它是一种特殊的唯一索引,不允许有空值。一般是在建表的时候同时创建主键索引。

当然也可以用 ALTER 命令。记住:一个表只能有一个主键。
(2) 唯一索引 UNIQUE
唯一索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。可以在创建表的时候指定,也可以修改表结构,如:
ALTER TABLE table_name ADD UNIQUE (column)
(3) 普通索引 INDEX
这是最基本的索引,它没有任何限制。可以在创建表的时候指定,也可以修改表结构,如:
ALTER TABLE table_name ADD INDEX index_name (column)
(4) 组合索引 INDEX
组合索引,即一个索引包含多个列。可以在创建表的时候指定,也可以修改表结构,如:
ALTER TABLE table_name ADD INDEX index_name(column1, column2, column3)
(5) 全文索引 FULLTEXT
全文索引(也称全文检索)是目前搜索引擎使用的一种关键技术。它能够利用分词技术等多种算法智能分析出文本文字中关键字词的频率及重要性,然后按照一定的算法规则智能地筛选出我们想要的搜索结果。
可以在创建表的时候指定,也可以修改表结构,如:
ALTER TABLE table_name ADD FULLTEXT (column)
2、索引结构及原理
mysql中普遍使用B+Tree做索引,但在实现上又根据聚簇索引和非聚簇索引而不同,本文暂不讨论这点。
b+树介绍
下面这张b+树的图片在很多地方可以看到,之所以在这里也选取这张,是因为觉得这张图片可以很好的诠释索引的查找过程。

如上图,是一颗b+树。浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。
真实的数据存在于叶子节点,即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
查找过程
在上图中,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
性质
(1) 索引字段要尽量的小。
通过上面b+树的查找过程,或者通过真实的数据存在于叶子节点这个事实可知,IO次数取决于b+数的高度h。
假设当前数据表的数据量为N,每个磁盘块的数据项的数量是m,则树高h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;
而m = 磁盘块的大小/数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的;如果数据项占的空间越小,数据项的数量m越多,树的高度h越低。这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。
(2) 索引的最左匹配特性。
当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
建索引的几大原则
(1) 最左前缀匹配原则
对于多列索引,总是从索引的最前面字段开始,接着往后,中间不能跳过。比如创建了多列索引(name,age,sex),会先匹配name字段,再匹配age字段,再匹配sex字段的,中间不能跳过。mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。
一般,在创建多列索引时,where子句中使用最频繁的一列放在最左边。
看一个补符合最左前缀匹配原则和符合该原则的对比例子。
实例:表c2c_db.t_credit_detail建有索引(Flistid,Fbank_listid)

不符合最左前缀匹配原则的sql语句:
select * from t_credit_detail where Fbank_listid='201108010000199'\G
该sql直接用了第二个索引字段Fbank_listid,跳过了第一个索引字段Flistid,不符合最左前缀匹配原则。用explain命令查看sql语句的执行计划,如下图:

从上图可以看出,该sql未使用索引,是一个低效的全表扫描。
符合最左前缀匹配原则的sql语句:
select * from t_credit_detail where Flistid='2000000608201108010831508721' and Fbank_listid='201108010000199'\G
该sql先使用了索引的第一个字段Flistid,再使用索引的第二个字段Fbank_listid,中间没有跳过,符合最左前缀匹配原则。用explain命令查看sql语句的执行计划,如下图:

从上图可以看出,该sql使用了索引,仅扫描了一行。
对比可知,符合最左前缀匹配原则的sql语句比不符合该原则的sql语句效率有极大提高,从全表扫描上升到了常数扫描。
(2) 尽量选择区分度高的列作为索引。
比如,我们会选择学号做索引,而不会选择性别来做索引。
(3) =和in可以乱序
比如a = 1 and b = 2 and c = 3,建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
(4) 索引列不能参与计算,保持列“干净”
比如:Flistid+1>‘2000000608201108010831508721‘。原因很简单,假如索引列参与计算的话,那每次检索时,都会先将索引计算一次,再做比较,显然成本太大。
(5) 尽量的扩展索引,不要新建索引。
比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
索引的不足
虽然索引可以提高查询效率,但索引也有自己的不足之处。
索引的额外开销:
(1) 空间:索引需要占用空间;
(2) 时间:查询索引需要时间;
(3) 维护:索引须要维护(数据变更时);
不建议使用索引的情况:
(1) 数据量很小的表
(2) 空间紧张
常用优化总结
优化语句很多,需要注意的也很多,针对平时的情况总结一下几点:
1、有索引但未被用到的情况(不建议)
(1) Like的参数以通配符开头时
尽量避免Like的参数以通配符开头,否则数据库引擎会放弃使用索引而进行全表扫描。
以通配符开头的sql语句,例如:select * from t_credit_detail where Flistid like '%0'\G

这是全表扫描,没有使用到索引,不建议使用。
不以通配符开头的sql语句,例如:select * from t_credit_detail where Flistid like '2%'\G

很明显,这使用到了索引,是有范围的查找了,比以通配符开头的sql语句效率提高不少。
(2) where条件不符合最左前缀原则时
例子已在最左前缀匹配原则的内容中有举例。
(3) 使用!= 或 <> 操作符时
尽量避免使用!= 或 <>操作符,否则数据库引擎会放弃使用索引而进行全表扫描。使用>或<会比较高效。
select * from t_credit_detail where Flistid != '2000000608201108010831508721'\G
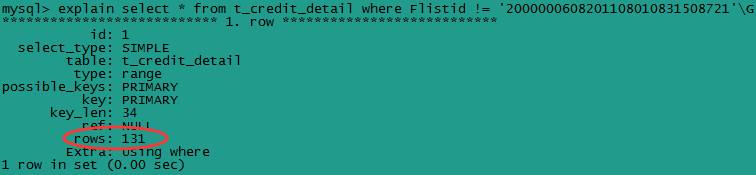
(4) 索引列参与计算
应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。
select * from t_credit_detail where Flistid +1 > '2000000608201108010831508722'\G

(5) 对字段进行null值判断
应尽量避免在where子句中对字段进行null值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: 低效:select * from t_credit_detail where Flistid is null ;
可以在Flistid上设置默认值0,确保表中Flistid列没有null值,然后这样查询: 高效:select * from t_credit_detail where Flistid =0;
(6) 使用or来连接条件
应尽量避免在where子句中使用or来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如: 低效:select * from t_credit_detail where Flistid = '2000000608201108010831508721' or Flistid = '10000200001';
可以用下面这样的查询代替上面的 or 查询: 高效:select from t_credit_detail where Flistid = '2000000608201108010831508721' union all select from t_credit_detail where Flistid = '10000200001';

2、避免select *
在解析的过程中,会将'*' 依次转换成所有的列名,这个工作是通过查询数据字典完成的,这意味着将耗费更多的时间。
所以,应该养成一个需要什么就取什么的好习惯。
3、order by 语句优化
任何在Order by语句的非索引项或者有计算表达式都将降低查询速度。
方法:1.重写order by语句以使用索引;
2.为所使用的列建立另外一个索引3.绝对避免在order by子句中使用表达式。
复制
4、GROUP BY语句优化
提高GROUP BY 语句的效率, 可以通过将不需要的记录在GROUP BY 之前过滤掉
低效:
SELECT JOB , AVG(SAL)
FROM EMP
GROUP by JOB
HAVING JOB = ‘PRESIDENT'
OR JOB = ‘MANAGER'
高效:
SELECT JOB , AVG(SAL)
FROM EMP
WHERE JOB = ‘PRESIDENT'
OR JOB = ‘MANAGER'
GROUP by JOB
5、用 exists 代替 in
很多时候用 exists 代替 in 是一个好的选择: select num from a where num in(select num from b) 用下面的语句替换: select num from a where exists(select 1 from b where num=a.num)
6、使用 varchar/nvarchar 代替 char/nchar
尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
7、能用DISTINCT的就不用GROUP BY
SELECT OrderID FROM Details WHERE UnitPrice > 10 GROUP BY OrderID
可改为:
SELECT DISTINCT OrderID FROM Details WHERE UnitPrice > 10
8、能用UNION ALL就不要用UNION
UNION ALL不执行SELECT DISTINCT函数,这样就会减少很多不必要的资源。
9、在Join表的时候使用相当类型的例,并将其索引
如果应用程序有很多JOIN 查询,你应该确认两个表中Join的字段是被建过索引的。这样,MySQL内部会启动为你优化Join的SQL语句的机制。
而且,这些被用来Join的字段,应该是相同的类型的。例如:如果你要把 DECIMAL 字段和一个 INT 字段Join在一起,MySQL就无法使用它们的索引。对于那些STRING类型,还需要有相同的字符集才行。(两个表的字符集有可能不一样)
相关文章:
MySQL 索引及查询优化总结
一个简单的对比测试 前面的案例中,c2c_zwdb.t_file_count表只有一个自增id,FFileName字段未加索引的sql执行情况如下: 在上图中,typeall,keynull,rows33777。该sql未使用索引,是一个效率非常低…...
什么是AJAX?
AJAX是一种基于Web的技术,它允许Web应用程序在不刷新整个页面的情况下与服务器进行交互。通过AJAX,Web应用程序可以使用JavaScript向服务器发送异步请求并在不干扰用户的情况下更新页面的部分内容。 AJAX是Asynchronous JavaScript and XML的缩写。尽管…...

报表生成器FastReport .Net用户指南:显示数据列、HTML标签
FastReport .Net是一款全功能的Windows Forms、ASP.NET和MVC报表分析解决方案,使用FastReport .NET可以创建独立于应用程序的.NET报表,同时FastReport .Net支持中文、英语等14种语言,可以让你的产品保证真正的国际性。 FastReport.NET官方版…...

bootstrap-dialog弹框,去掉遮盖层,可移动
1.去掉遮盖层的设置data-backdrop"false" <div class"modal fade" id"modal" aria-modal"true" role"dialog" data-backdrop"false" style"width:50%"><div class"modal-dialog modal-l…...

7. user-Agent破解反爬机制
文章目录 1. 为什么要设置反爬机制2. 服务器如何区分浏览器访问和爬虫访问3. 反爬虫机制4. User-Agent是什么5. 如何查询网页的User-Agent6. user-agent信息解析7. 爬虫程序user-agent和浏览器user-agent的区别8. 代码查看爬虫程序的user-agent9. 在代码中加入请求头信息 1. 为…...

3.Nginx+Tomcat负载均衡和动静分离群集
文章目录 NginxTomcat负载均衡和动静分离群集Nginx作用实验七层反向代理nginx动静分离四层反向代理负载均衡 NginxTomcat负载均衡和动静分离群集 Nginx是-款非常优秀的HTTP服务器软件 支持高达50 000个并发连接数的响应拥有强大的静态资源处理能力运行稳定内存、CPU等系统资源…...
数据结构与算法之树结构
目录 为什么要使用树结构树结构基本概念树的种类树的存储与表示常见的一些树的应用场景为什么要使用树结构 线性结构中不论是数组还是链表,他们都存在着诟病;比如查找某个数必须从头开始查,消耗较多的时间。使用树结构,在插入和查找的性能上相对都会比线性结构要好 树结构…...

【python】 用来将对象持久化的 pickle 模块
pickle 模块可以对一个 Python 对象的二进制进行序列化和反序列化。说白了,就是它能够实现任意对象与二进制直接的相互转化,也可以实现对象与文本之间的相互转化。 比如,我程序里有一个 python 对象,我想把它存到磁盘里ÿ…...

【博客654】prometheus配置抓取保护以防止压力过载
prometheus抓取保护配置以防止压力过载 场景 担心您的应用程序指标可能突然激增,以及指标突然激增导致prometheus压力过载 就像生活中的许多事情一样,标签要有节制。当带有用户 ID 或电子邮件地址的标签被添加到指标时,虽然它不太可能结束…...

Backtrader官方中文文档:第十三章Observers观察者
本文档参考backtrader官方文档,是官方文档的完整中文翻译,可作为backtrader中文教程、backtrader中文参考手册、backtrader中文开发手册、backtrader入门资料使用。 本章包含 backtrader 官方Observers章节全部内容,入口 : https://backtrader.com/docu/observers-and-sta…...

算法leetcode|54. 螺旋矩阵(rust重拳出击)
文章目录 54. 螺旋矩阵:样例 1:样例 2:提示: 分析:题解:rust:go:c:python:java:每次循环移动一步:每次循环完成一个顺时针:…...
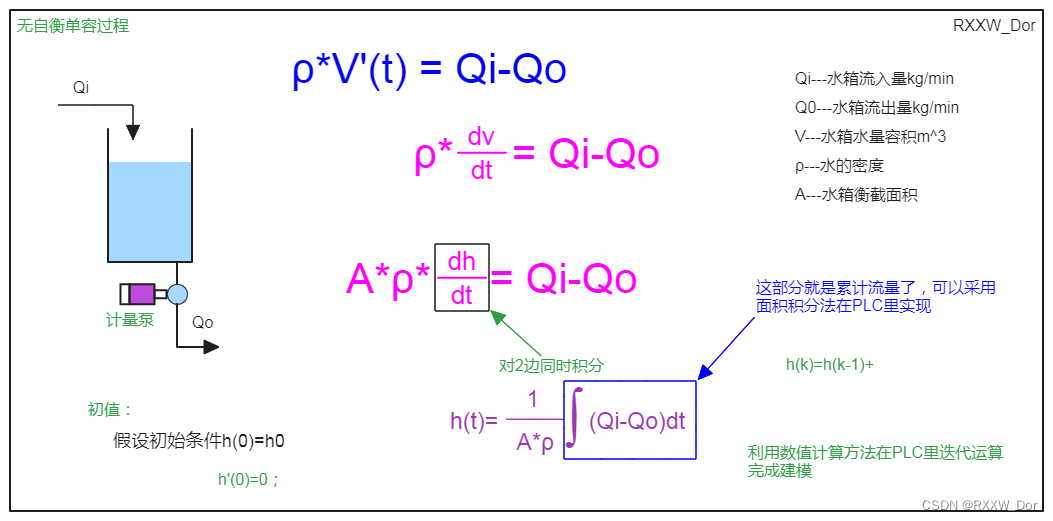
单容水箱建模(自衡单容水箱+无自衡单容水箱)
自衡单容水箱Simulink建模和PLC源代码请参看下面文章链接: 单容双容水箱建模(simulink仿真+PLC代码)_RXXW_Dor的博客-CSDN博客PLC通过伯努利方程近似计算水箱流量详细内容请参看下面的文章博客PLC通过伯努利方程近似计算水箱流量(FC)_怎么用伯努利方程求某水位流量_RXXW_Dor的…...
分享Python7个爬虫小案例(附源码)
本次的7个python爬虫小案例涉及到了re正则、xpath、beautiful soup、selenium等知识点,非常适合刚入门python爬虫的小伙伴参考学习。注:若涉及到版权或隐私问题,请及时联系我删除即可。 1.使用正则表达式和文件操作爬取并保存“某吧”某帖子…...

我用ChatGPT写2023高考语文作文(一):全国甲卷
2023年 全国甲卷 适用地区:广西、贵州、四川、西藏 人们因技术发展得以更好地掌控时间,但也有人因此成了时间的仆人。 这句话引发了你怎样的联想与思考?请写一篇文章。 要求:选准角度,确定立意,明确文体&am…...

c++ modbusTCP
//Modbus TCP是一种基于TCP/IP协议的Modbus协议,它允许Modbus协议通过以太网进行通信。 //在C中,可以使用第三方库来实现Modbus TCP通信,例如libmodbus和QModbus。 //使用libmodbus库实现Modbus TCP通信的示例代码如下: //c #incl…...
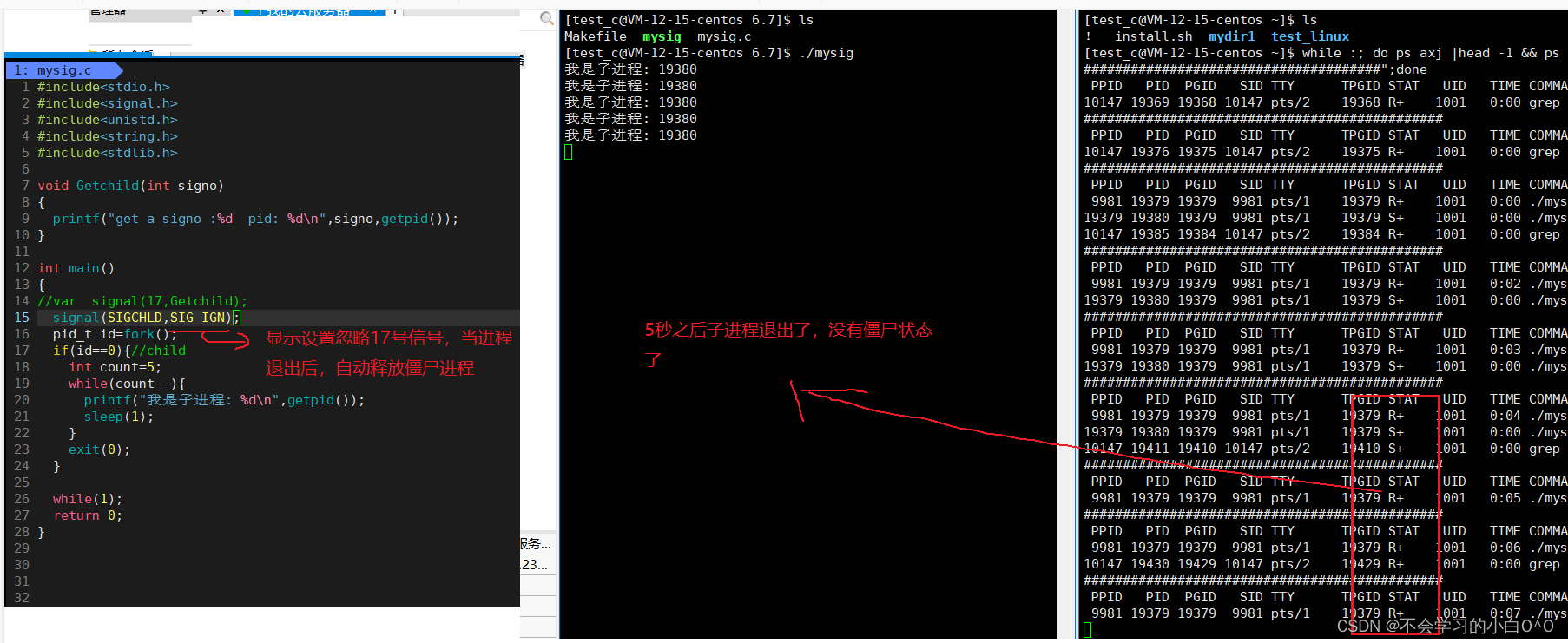
linux(信号结尾)
目录: 1.可重入函数 2.volatile关键字 3.SIGCHLD信号 -------------------------------------------------------------------------------------------------------------------------------- 1.可重入函数----------用来描述一个函数的特点的 1.在单进程当中也存…...
【漏洞修复】node-exporter被检测出来pprof调试信息泄露漏洞
node-exporter被检测出来pprof调试信息泄露漏洞 说在前面解决方法结语 说在前面 惯例开篇吐槽,有些二五仔习惯搞点自研的安全扫描工具,然后加点DIY元素,他也不管扫的准不准,就要给你报个高中危的漏洞,然后就要去修复&…...

在linux 上安装 NFS服务器软件
在 Ubuntu Linux 中创建 NFS 文件系统通常需要完成以下步骤: 安装 NFS 服务器软件。您可以在终端上使用以下命令来安装所需的软件包。sudo apt-get update sudo apt-get install nfs-kernel-server创建要共享的目录。例如,您可以创建一个名为 /var/nfs/shared 的目录。sudo m…...
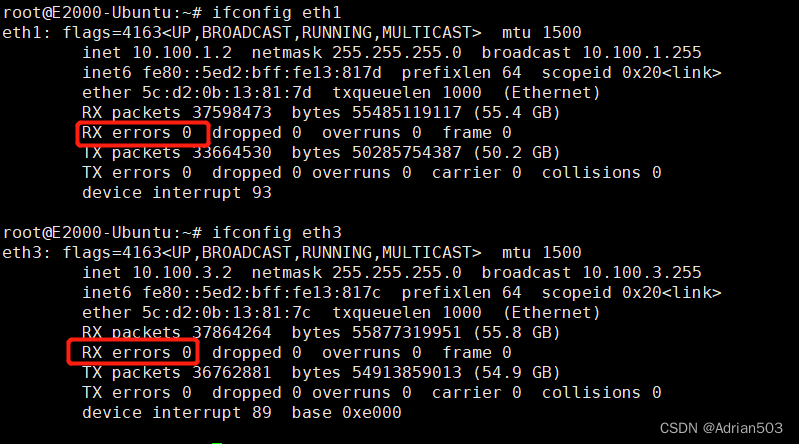
网卡中的Ring buffer -- 解决 rx_resource_errors 丢包
1、软硬件环境 硬件: 飞腾E2000Q 平台 软件: linux 4.19.246 2、问题现象 网卡在高速收包的过程中,出现 rx error , 细查是 rx_resource_errors 如下: rootE2000-Ubuntu:~# ifconfig eth1 eth1: flags4163<UP,BROADCAST,RU…...
)
六月九号补题日记:Codeforces Round 877 (Div. 2)
专注是不够的,很重要的一方面在于细节,关注细节:精细和专注才是成功的重点!!! A 题意:给你一堆数字,说这一堆数字是由最初的两个数字相减得到的,让你求出两个数字其中一…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...

scikit-learn机器学习
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可: # Also add the following code, # so that every time the environment (kernel) starts, # just run the following code: import sys sys.path.append(/home/aistudio/external-libraries)机…...

Spring AI Chat Memory 实战指南:Local 与 JDBC 存储集成
一个面向 Java 开发者的 Sring-Ai 示例工程项目,该项目是一个 Spring AI 快速入门的样例工程项目,旨在通过一些小的案例展示 Spring AI 框架的核心功能和使用方法。 项目采用模块化设计,每个模块都专注于特定的功能领域,便于学习和…...

论文阅读:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving 摘要翻译 自动驾驶技术作为推动交通和城市出行变革的催化剂,正从基于规则的系统向数据驱动策略转变。传统的模块化系统受限于级联模块间的累积误差和缺乏灵活性的预设规则。…...

SpringAI实战:ChatModel智能对话全解
一、引言:Spring AI 与 Chat Model 的核心价值 🚀 在 Java 生态中集成大模型能力,Spring AI 提供了高效的解决方案 🤖。其中 Chat Model 作为核心交互组件,通过标准化接口简化了与大语言模型(LLM࿰…...

Android写一个捕获全局异常的工具类
项目开发和实际运行过程中难免会遇到异常发生,系统提供了一个可以捕获全局异常的工具Uncaughtexceptionhandler,它是Thread的子类(就是package java.lang;里线程的Thread)。本文将利用它将设备信息、报错信息以及错误的发生时间都…...