【爬虫】4.5 实践项目——爬取当当网站图书数据
目录
1. 网站图书数据分析
2. 网站图书数据提取
3. 网站图书数据爬取
(1)创建 MySQL 数据库
(2)创建 scrapy 项目
(3)编写 items.py 中的数据项目类
(4)编写 pipelines_1.py 中的数据处理类
(5)编写 pipelines_2.py 中的数据处理类
(6)编写 Scrapy 的配置文件
(7)编写 Scrapy 爬虫程序
(8)执行 Scrapy 爬虫程序
实践内容:Scrapy框架+Xpath信息提取方法设计商城(这里用的当当网)商品信息网站及爬虫程序,以关键字“书包”(python)搜索页面的商品,爬取(学号相关的特定某几个页面(最后一位,页面大于3)及限定数量商品(最后3位))商品信息。
编程思路:
1. 功能描述
- 输入:需要爬取的商品与学号
- 输出:书本信息并保存的MySQL中
2. 程序的结构设计
- 从当当网上获取数据:使用scripy框架,使用xpath查找html元素
- 下面两个特定数量爬取写了两个管道 pipelines_1.py, pipelines_2.py
- 爬取1:(最后一位,页面大于3)——>(3,>3)并输出到MySQL中,open_scripy,把数据INSERT到数据库中,close_scripy
- 爬取2:(最后3位)——>103条数据,并输出到MySQL,open_scripy,把数据INSERT到数据库中,close_scripy
1. 网站图书数据分析
当当图书网站是国内比较大型的图书网站,这个项目的目的就是对该网站的某个主题的一类图书的数据的爬取,把爬取的数据存储到MySQL数据库中。
例如我们关心Python类的图书,想知道网站上有什么Python的图书,用 Chrome浏览器进入当当网站,在搜索关键字中输入"Python"搜索得到 Python的图书,地址转为:
http://search.dangdang.com/?key=Python&act=input
这类的图书很多,点击“下一页”后地址转为:
http://search.dangdang.com/?key=Python&act=input&page_index=2
从地址上我们知道知道搜索的关键字是key参数,页码参数是page_index, 而act=input参数只是表明是通过输入进行的查询。
网页元素分析,为后面使用Xpath查找做准备
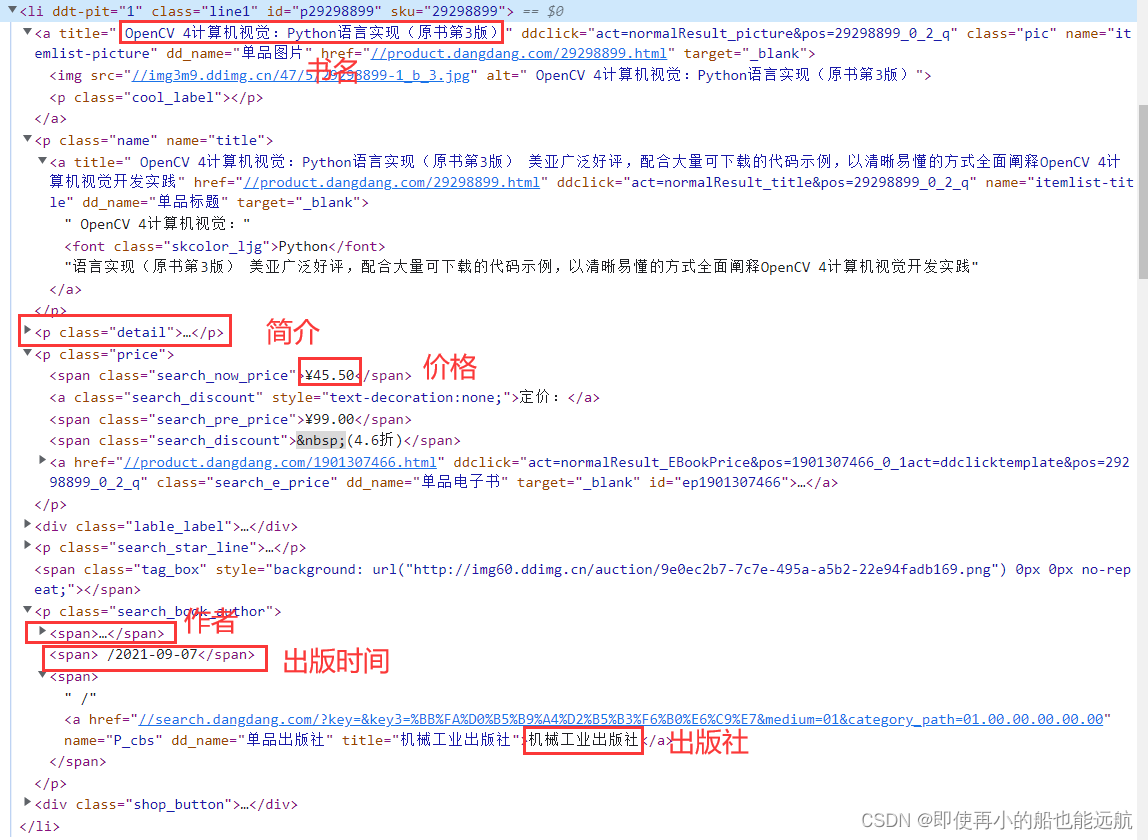
仔细分析 HTML 代码结构,可以看到每本书都是一个<li>的项目,而且它们的结构完全是一样的,这些<li>包含在一个<ul>中。
在代码中选择第一个<li>,点击鼠标右键弹出菜单,执行"Edit as HTML" 进入文本编辑,复制出一本书<li>项目的代码,这段代码放到记事本中, 保存为book.txt文本文件时提示包含Unicode编码字符或者utf-16,于是按要求以 Unicode编码保存为book.txt文件。然后编写一小段程序用BeautifulSoup 装载:
BeautifulSoup 装载 Test1.py 如下:
# BeautifulSoup 装载
from bs4 import BeautifulSoupfobj = open("book.txt", "rb")
data = fobj.read()
fobj.close()
data = data.decode("utf-16")
soup = BeautifulSoup(data, "lxml")
print(soup.prettify())
通过 prettify 整理后就可以清晰看到<li>层次结构,结果如下:
<html>
<body>
<li class="line1" ddt-pit="1" id="p1230345797" sku="1230345797">
<a class="pic" dd_name="单品图片" ddclick="act=normalResult_picture&pos=1230345797_0_1_q" href="//product.dangdang.com/1230345797.html" name="itemlist-picture" target="_blank" title=" Python 算法教程">
<img alt=" Python 算法教程" src="//img3m7.ddimg.cn/32/4/1230345797-1_b_1.jpg"/>
<p class="cool_label">
</p>
</a>
<p class="name" name="title">
<a dd_name="单品标题" ddclick="act=normalResult_title&pos=1230345797_0_1_q" href="//product.dangdang.com/1230345797.html" name="itemlist-title" target="_blank" title=" Python 算法教程 ">
<font class="skcolor_ljg">
Python
</font>
算法教程
</a>
</p>
<p class="detail">
精通Python基础算法 畅销书Python基础教程作者力作
</p>
<p class="price">
<span class="search_now_price">
¥51.75
</span>
<a class="search_discount" style="text-decoration:none;">
定价:
</a>
<span class="search_pre_price">
¥69.00
</span>
<span class="search_discount">
(7.5折)
</span>
</p>
<p block="" class="search_shangjia">
<span class="icon_shangjia">
</span>
<a dd_name="单品店铺" href="//shop.dangdang.com/20734" name="itemlist-shop-name" target="_blank" title="人民邮电出版社官方旗舰店">
人民邮电出版社官方旗舰店
</a>
<span class="new_lable" y="">
</span>
</p>
<p class="search_star_line">
<span class="search_star_black">
<span style="width: 100%;">
</span>
</span>
<a class="search_comment_num" dd_name="单品评论" ddclick="act=click_review_count&pos=1230345797_0_1_q" href="//product.dangdang.com/1230345797.html?point=comment_point" name="itemlist-review" target="_blank">
8条评论
</a>
</p>
<span class="tag_box">
</span>
<p class="search_book_author">
<span>
[挪威]
<a dd_name="单品作者" href="//search.dangdang.com/?key2=Magnus&medium=01&category_path=01.00.00.00.00.00" name="itemlist-author" title="[挪威] Magnus Lie Hetland 赫特兰">
Magnus
</a>
Lie
<a dd_name="单品作者" href="//search.dangdang.com/?key2=Hetland&medium=01&category_path=01.00.00.00.00.00" name="itemlist-author" title="[挪威] Magnus Lie Hetland 赫特兰">
Hetland
</a>
<a dd_name="单品作者" href="//search.dangdang.com/?key2=赫特兰&medium=01&category_path=01.00.00.00.00.00" name="itemlist-author" title="[挪威] Magnus Lie Hetland 赫特兰">
赫特兰
</a>
</span>
<span>
/2016-01-01
</span>
<span>
/
<a dd_name="单品出版社" href="//search.dangdang.com/?key=&key3=%C8%CB%C3%F1%D3%CA%B5%E7%B3%F6%B0%E6%C9%E7&medium=01&category_path=01.00.00.00.00.00" name="P_cbs" title="人民邮电出版社">
人民邮电出版社
</a>
</span>
</p>
<div class="shop_button">
<p class="bottom_p">
<a class="search_btn_cart" dd_name="加入购物车" ddclick="act=normalResult_addToCart&pos=1230345797_0_1_q" href="javascript:AddToShoppingCart(1230345797)" name="Buy">
加入购物车
</a>
<a class="search_btn_collect" dd_name="加入收藏" ddclick="act=normalResult_favor&pos=1230345797_0_1_q" href="javascript:void(0);" id="lcase1230345797" name="collect">
收藏
</a>
</p>
</div>
</li>
</body>
</html>
2. 网站图书数据提取
假定只关心图书的名称title、作者author、出版时间date、出版 社publisher、价格price以及书的内容简介detail,那么用book.txt存储的代码来测试获取的方法。从book.txt中的代码的分析,我们可以编写 test.py 程序获取这些数据.
图书数据获取 Test2.py 如下:
# 图书数据获取
from bs4 import BeautifulSoup
from bs4.dammit import UnicodeDammit
import scrapyclass TestItem:def __init__(self):self.title = ""self.author = ""self.date = ""self.publisher = ""self.price = ""self.detail = ""def show(self):print(self.title)print(self.author)print(self.date)print(self.price)print(self.publisher)print(self.detail)try:# 这段程序从book.txt中装载数据,并识别它的编码,生成Selector对象,并由此找到<li>元素节点。fobj = open("book.txt", "rb")data = fobj.read()fobj.close()dammit = UnicodeDammit(data, ["utf-8", "utf-16", "gbk"])data = dammit.unicode_markupselector = scrapy.Selector(text=data)li = selector.xpath("//li")# <li>中有多个<a>,从HTML代码可以看到书名包含在第一个<a>的title属性中,# 因此通过position()=1找出第一个<a>,然后取出title属性值就是书名title。title = li.xpath("./a[position()=1]/@title").extract_first()# 价钱包含在<li>中的class='price'的<p>元素下面的 class='search_now_price'的<span>元素的文本中。price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()# 作者包含在<li>下面的class='search_book_author'的<p>元素下面的第一个# <span>元素的title属性中,其中span[position()=1]就是限定第一个 <span>。author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()# 出版日期包含在<li>下面的class='search_book_author'的<p>元素下面的倒数第二个<span>元素的文本中,# 其中span[position()=last()-1]就是限定倒数第二个 <span>,last()是最后一个<span>的序号。date = li.xpath("./p[@class='search_book_author']/span[position()=last()-1] / text()").extract_first()# 出版社包含在<li>下面的class='search_book_author'的<p>元素下面的最 后一个<span>元素的title属性中,# 其中span[position()=last()]就是最后一 个 <span>,last()是最后一个<span>的序号。publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title").extract_first()# 在<li>下面的class='detail'的<p>的文本就是书的简介。detail = li.xpath("./p[@class='detail']/text()").extract_first()item = TestItem()# 无论是哪个数据存在, 那么extract_first()就返回这个数据的值,# 如果不存在就返回None,为了避免出现None的值,我们把None转为空字符串。item.title = title.strip() if title else ""item.author = author.strip() if author else ""# 从HTML中看到日期前面有一个符号"/",因此如果日期存在时就把这个前导的符号"/"去掉。item.date = date.strip()[1:] if date else ""item.publisher = publisher.strip() if publisher else ""item.price = price.strip() if price else ""item.detail = detail.strip() if detail else ""item.show()
except Exception as err:print(err)
程序执行结果:
Python 算法教程
[挪威] Magnus Lie Hetland 赫特兰
2016-01-01
¥51.75
人民邮电出版社
精通Python基础算法 畅销书Python基础教程作者力作
3. 网站图书数据爬取
(1)创建 MySQL 数据库
注意:下面创建数据库与数据表,已在 pipelines.py 中编写了
在 MySQL 中创建数据库 scripy, 创建2个图书表books如下:
CREATE DATABASE scripy;CREATE TABLE books(bTitle VARCHAR(512),bAuthor VARCHAR(256),bPublisher VARCHAR(256),bDate VARCHAR(32),bPrice VARCHAR(16),bDetail text
);(2)创建 scrapy 项目
scrapy startproject Project_books
(3)编写 items.py 中的数据项目类
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass BookItem(scrapy.Item):# define the fields for your item here like:title = scrapy.Field()author = scrapy.Field()date = scrapy.Field()publisher = scrapy.Field()detail = scrapy.Field()price = scrapy.Field()(4)编写 pipelines_1.py 中的数据处理类
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
import pymysqlclass BookPipeline(object):def open_spider(self, spider):print("opened_爬取1")try:self.con = pymysql.connect(host="127.0.0.1", port=3306, user='root', password="123456", charset="utf8")self.cursor = self.con.cursor(pymysql.cursors.DictCursor)self.cursor.execute("CREATE DATABASE IF NOT EXISTS scripy")self.con = pymysql.connect(host="127.0.0.1", port=3306, user='root', password="123456", db='scripy',charset="utf8")self.cursor = self.con.cursor(pymysql.cursors.DictCursor)self.cursor.execute("CREATE TABLE IF NOT EXISTS books_1(""bTitle VARCHAR(512),""bAuthor VARCHAR(256),""bPublisher VARCHAR(256),""bDate VARCHAR(32),""bPrice VARCHAR(16),""bDetail text)")self.cursor.execute("DELETE FROM books_1")self.opened = Trueself.count_1 = 0except Exception as err:print(err)self.opened = Falsedef close_spider(self, spider):if self.opened:self.con.commit()self.con.close()self.opened = Falseprint("closed_爬取1")print(f"总共爬取{self.count_1}本书籍")def process_item(self, item, spider):try:print(item["title"])print(item["author"])print(item["publisher"])print(item["date"])print(item["price"])print(item["detail"])print()if self.opened:self.cursor.execute("INSERT INTO books_1(bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail)""value (%s,%s,%s,%s,%s,%s)",(item["title"], item["author"], item["publisher"],item["date"], item["price"], item["detail"]))self.count_1 += 1except Exception as err:print(err)# spider.crawler.engine.close_spider(spider, "无有效信息,关闭spider") # pepline 中使用此关闭方法return item
(5)编写 pipelines_2.py 中的数据处理类
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
import pymysqlclass Input_message:key = input('请输入需要爬取当当网的某类书籍:')id = input("请输入学号:") # 102002103page = id[-1] # 爬取1-->第3页开始,爬取大于3页结束page_1 = int(input(f"从第{page}开始,爬取__页(请大于3页):"))num = id[-3:] # 爬取2-->103件商品class BookPipeline(object):def open_spider(self, spider):print("opened_爬取2")try:self.con = pymysql.connect(host="127.0.0.1", port=3306, user='root', password="123456", charset="utf8")self.cursor = self.con.cursor(pymysql.cursors.DictCursor)self.cursor.execute("CREATE DATABASE IF NOT EXISTS scripy")self.con = pymysql.connect(host="127.0.0.1", port=3306, user='root', password="123456", db='scripy',charset="utf8")self.cursor = self.con.cursor(pymysql.cursors.DictCursor)self.cursor.execute("CREATE TABLE IF NOT EXISTS books_2(""bTitle VARCHAR(512),""bAuthor VARCHAR(256),""bPublisher VARCHAR(256),""bDate VARCHAR(32),""bPrice VARCHAR(16),""bDetail text)")self.cursor.execute("DELETE FROM books_2")self.opened = Trueself.count_2 = 0except Exception as err:print(err)self.opened = Falsedef close_spider(self, spider):if self.opened:self.con.commit()self.con.close()self.opened = Falseprint("closed_爬取2")print(f"总共爬取{self.count_2}本书籍")def process_item(self, item, spider):try:print(item["title"])print(item["author"])print(item["publisher"])print(item["date"])print(item["price"])print(item["detail"])print()if self.opened:self.cursor.execute("INSERT INTO books_2(bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail)""value (%s,%s,%s,%s,%s,%s)",(item["title"], item["author"], item["publisher"],item["date"], item["price"], item["detail"]))self.count_2 += 1if self.count_2 == int(Input_message.num): # 学号后3为BookPipeline.close_spider(self, spider)except Exception as err:print(err)# spider.crawler.engine.close_spider(spider, "无有效信息,关闭spider") # pepline 中使用此关闭方法return item
在scrapy的过程中一旦打开一个 spider 爬虫, 就会执行这个类的 open_spider(self,spider) 函数,一旦这个 spider 爬虫关闭, 就执行这个类的 close_spider(self,spider) 函数。因此程序在open_spider 函数中连接 MySQL数据库,并创建操作游标 self.cursor,在close_spider中提交数 据库并关闭数据库,程序中使用 count 变量统计爬取的书籍数量。 在数据处理函数中每次有数据到达,就显示数据内容,并使用 insert 的SQL语句把数据插入到数据库中。
(6)编写 Scrapy 的配置文件settings.py
ITEM_PIPELINES = {"Project_books.pipelines_1.BookPipeline": 300,"Project_books.pipelines_2.BookPipeline": 300,
}简单的配置 settings,这样就可以把爬取的数据推送到管道的BookPipeline类中。
(7)编写 Scrapy 爬虫程序MySpider.py
import scrapy
from ..items import BookItem
from bs4.dammit import UnicodeDammit
from ..pipelines_2 import Input_messageclass MySpider(scrapy.Spider):name = "mySpider"source_url = "https://search.dangdang.com/"act = '&act=input&page_index='# 以下信息写道pipelines2里了# id = input("请输入学号:") # 102002103# page = id[-1] # 爬取1-->第3页开始,爬取大于3页结束# page_1 = int(input(f"从第{page}开始,爬取__页(请大于3页):"))# num = id[-3:] # 爬取2-->103件商品# 指明要爬取的网址def start_requests(self):# url = 'http://search.dangdang.com/?key=Python&act=input&page_index=2'url = MySpider.source_url + "?key=" + Input_message.key + MySpider.act + Input_message.pageyield scrapy.Request(url=url, callback=self.parse)# 回调函数def parse(self, response, **kwargs):try:dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])data = dammit.unicode_markupselector = scrapy.Selector(text=data)lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")for li in lis:title = li.xpath("./a[position()=1]/@title").extract_first()price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()date = li.xpath("./p[@class='search_book_author']/span[position()=last()-1]/text()").extract_first()publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title").extract_first()detail = li.xpath("./p[@class='detail']/text()").extract_first()# detail 有时没有,结果Noneitem = BookItem()item["title"] = title.strip() if title else ""item["author"] = author.strip() if author else ""item["date"] = date.strip()[1:] if date else ""item["publisher"] = publisher.strip() if publisher else ""item["price"] = price.strip() if price else ""item["detail"] = detail.strip() if detail else ""yield item# 最后一页时 link 为None# 1.连续爬取不同的页# link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()# if link:# url = response.urljoin(link)# yield scrapy.Request(url=url, callback=self.parse)# 2.翻页(学号最后一位+1,学号最后一位+input > 3)for i in range(int(Input_message.page) + 1, int(Input_message.page) + Input_message.page_1):url = MySpider.source_url + "?key=" + Input_message.key + MySpider.act + str(i)yield scrapy.Request(url, callback=self.parse)except Exception as err:print(err)
分析网站的HTML代码发现在一个 <div class='paging'> 的元素中包含了翻页的 信息,<div>下面的 <ul name='Fy'> 下面的 <li class='next'> 下面的 <a> 链接就是 下一页的链接,取出这个链接地址,通过 response.urljoin 函数整理成绝对地址,再次产生一个scrapy.Request对象请求,回调函数仍然为这个parse函数,这样就可以 递归调用parse函数,实现下一个网页的数据爬取。爬取到最后一页时,下一页的链接为空,link=None就不再递归调用了。
(8)执行 Scrapy 爬虫程序run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())执行这个程序就可以爬取到所有关于 xxx 的书籍,这些书籍的数据存储到MySQL的scripy数据库中,执行完毕后在MySQL中可以看到爬取的结果,产生了两张表,对应不同的数量要求。
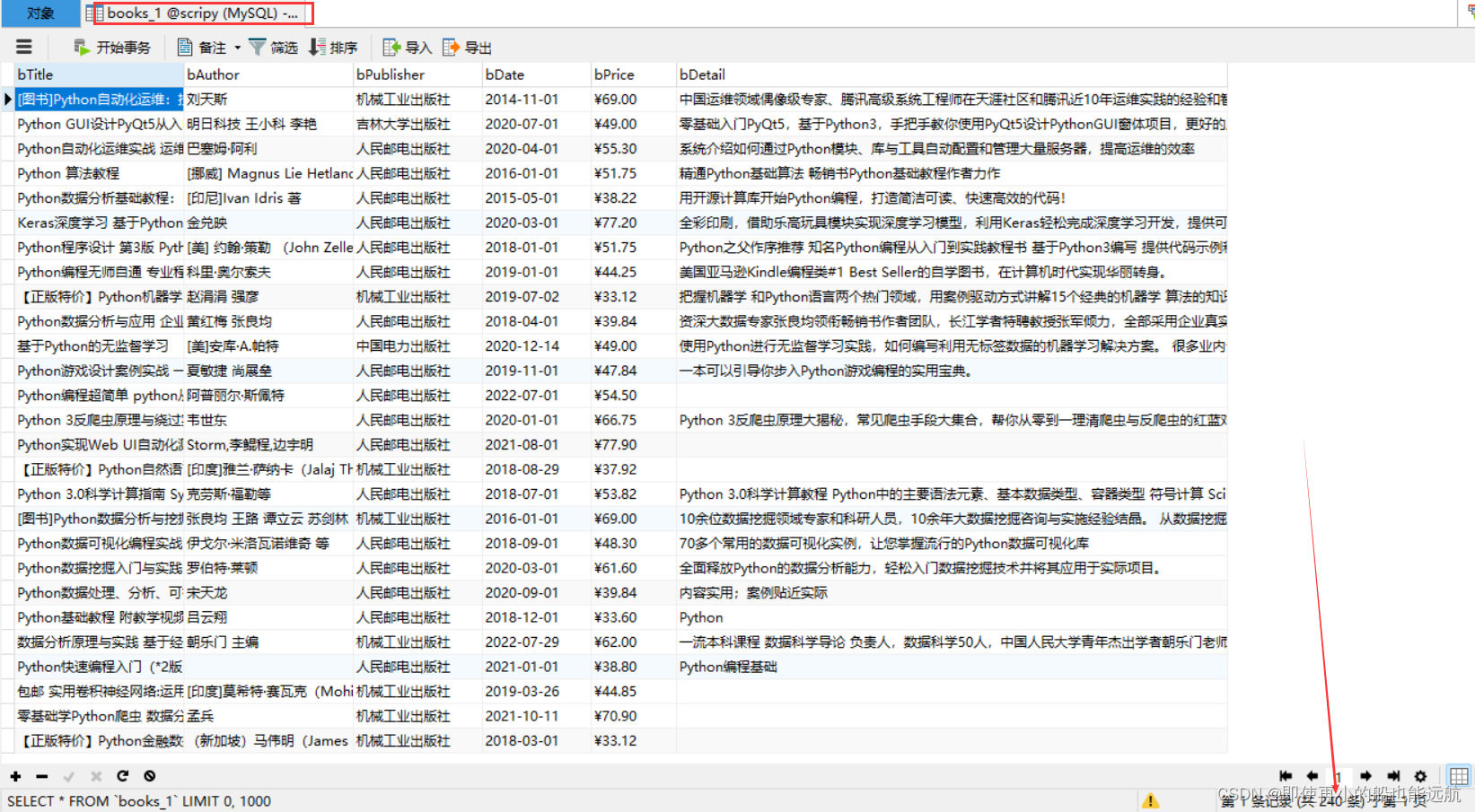
控制台结果如下:


数据库结果如下:

总结:
scrapy把数据爬取与数据存储分开处理,它们都是异步执行的, MySpider每爬取到一个数据项目item,就yield推送给pipelines.py 程序存储,等待存储完毕后又再次爬取另外一个数据项目item,再次yield推送到pipelines.py程序,然后再次存储,......,这个过程一 直进行下去,直到爬取过程结束,文件books.txt中就存储了所有的 爬取数据了。
相关文章:
【爬虫】4.5 实践项目——爬取当当网站图书数据
目录 1. 网站图书数据分析 2. 网站图书数据提取 3. 网站图书数据爬取 (1)创建 MySQL 数据库 (2)创建 scrapy 项目 (3)编写 items.py 中的数据项目类 (4)编写 pipelines_1.py …...

Socket 编程:基础概念辨析
文章目录 参考Socket APIBSD UNIX 操作系统BSD UNIX 与 Socket API Socket套接字套接字地址套接字 VS 套接字地址套接字的表示方法 TCP 套接字与 UDP 套接字TCP 套接字监听套接字连接套接字 UDP套接字 TCP 服务器端与 TCP 客户端通信的基本流程服务器端客户端 参考 项目描述刘…...

git lfs下载指定文件git lfs pull --include=“*.bin“
git lfs pull --include"*.bin"...

JavaScript 数组 函数
目录 1.数组的概念 2.创建数组 2.1 数组创建的方式 2.2利用new 创建数组 2.3 利用数组字面量创建数组 2.4 数据元素的类型 3.获取数组当元素 3.1数组元素的索引 4.遍历数组 4.1数组的长度 5.数组中新增元素 5.1通过修改length 长度新增数组元素 5.2通过修改数组索引…...

【哈佛积极心理学笔记】第7讲 逆境还是机遇
第7讲 逆境还是机遇 How can we raise base level? One of the things is coping, putting ourselves on the line. How to become an optimist. Optimism as an interpretation style, not as a Pollyannaish feel good kind of approach. Three approaches: First is to t…...
java springboot整合MyBatis做数据库查询操作
首先 我们还是要搞清楚 MyBatis 工作中都需要那些东西 首先是基础配置 你要连哪里的数据 连什么类型的数据库 以什么权限去连 然后 以 注解还是xml方式去映射sql 好 我们直接上代码 我们先创建一个文件夹 然后打开idea 新建一个项目 然后 按我下图的操作配置一下 然后点下一…...

11 二阶矩方法和Lovasz局部引理
文章目录 11 二阶矩方法和Lovasz局部引理11.1 The Second-Moment Method——二阶矩方法11.1.1 二阶矩方法定理11.1.2 二阶矩方法的应用——随机图阈值 11.2 Lovasz Local Lemma——Lovasz局部引理11.2.1 LLL定理11.2.2 LLL定理证明 11.3 Asymmetric LLL 11 二阶矩方法和Lovasz局…...

低代码赛道拥挤 生态聚合成为破局关键
在云计算和移动互联网的强劲推动下,企业数字化转型的步伐正在加速,对于软件应用开发的需求也呈现出爆发式的增长。这样的背景下,低代码平台凭借其独特的优势迅速崛起并引发了业界的广泛关注。 自2020年以来,低代码领域已成为投资…...
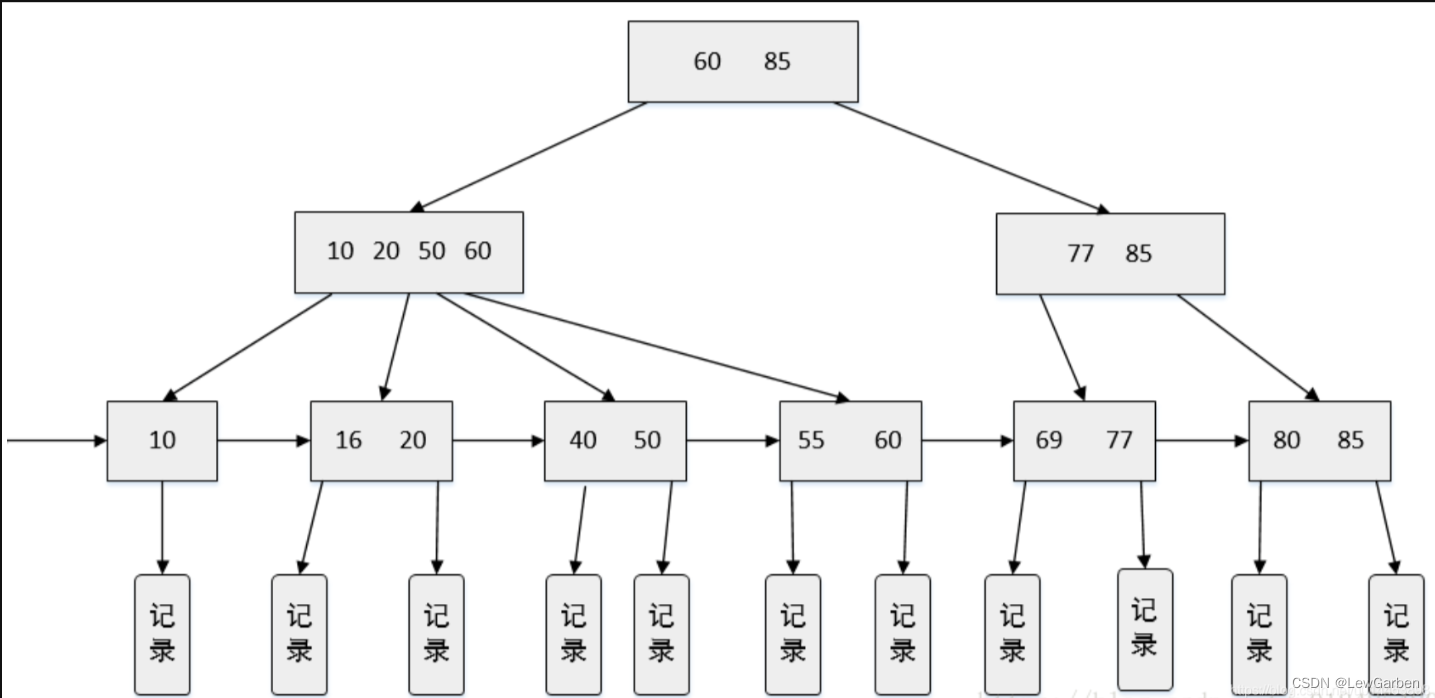
B+树:高效存储与索引的完美结合
目录 引言:一、定义:二、B树和B树三、特点:四、应用场景:总结: 引言: 在计算机科学领域中,数据结构的选择对于高效存储和索引数据至关重要。B树(B tree)作为一种自平衡的…...

左右排版的PDF,如何转换为单栏排版的word?
将左右排版的PDF转换为单行排版的WORD文字版需要进行以下步骤: 1. 使用PDF转换工具将PDF转换为WORD格式。有很多在线或离线的PDF转WORD工具可供选择,例如金鸣表格文字识别、Adobe Acrobat、Smallpdf、Zamzar等。 2. 打开WORD文档后,选择“页…...

D349周赛:注意题目提示里,数据范围隐含的算法复杂度提示
文章目录 6470.既不是最大值也不是最小值完整版为什么两个for循环时间复杂度还是不变的 6465.执行子串操作后的字典序最小字符串思路最开始的写法题意理解的问题 修改版a必须单独拿出来的原因 6449.收集巧克力思路注意提示信息 完整版补充:由数据范围反推算法复杂度…...

iOS -- block one
demo贴上我的github blockOne 块类似于匿名函数或闭包,在许多其他编程语言中也存在类似的概念。 Block 以下是块的一些基本知识: 块的定义:块是由一对花括号 {} 包围的代码片段,可以包含一段可执行的代码。块的定义使用 ^ 符号…...

第十二篇:强化学习SARSA算法
你好,我是郭震(zhenguo) 今天强化学习第二十篇:强化学习SARSA算法 1 历史 SARSA(「State-Action-Reward-State-Action」)算法是一种经典的强化学习算法,用于解决马尔可夫决策过程(MDP࿰…...

电力vr智能巡检模拟实操教学灵活性高成本低
传统电力智能运检服务培训采用交接班期间开展智能带电检测仪器的操作培训,教学时间、场地及材料有限,有了VR技术,将推动电力智能运检服务培训走向高科技、高效率和智能化水平。 深圳华锐视点凭借着对VR实训系统的深入研发和升级,多…...
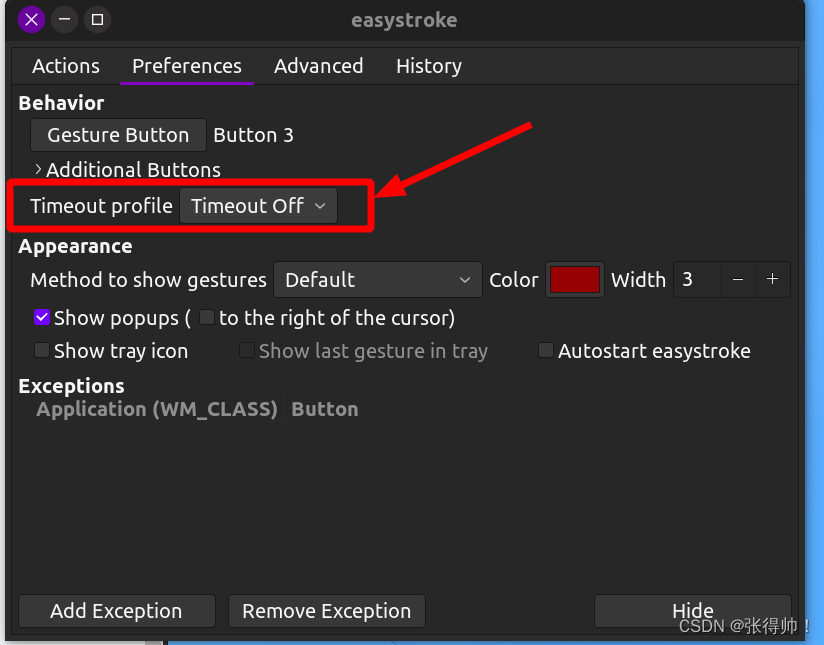
vscode右键点击,松开后自动触发鼠标所在位置的按钮(误触发双击效果)
例如如下,右键展开菜单,松手会自动触发转到声明功能 解决方案: 1、安装easystroke sudo apt-get install easystroke 2、打开easystroke,选择preferences tab 3、点击Gesture Button,在出现的框中右键单击一次 4、点…...

【UE5】分分钟简单使用像素流云服务(Pixel Streaming)
【UE5】分分钟简单使用像素流云服务(Pixel Streaming) 前言 UE5的Pixel Streaming已经封装的很好,简单三步实现简单的服务搭建。 安装插件打包项目运行服务 注:实例平台为Windows 安装插件 编辑→插件→输入查询Pixel Strea…...

2021 年全国硕士研究生入学统一考试管理类专业学位联考逻辑试题
2021 年全国硕士研究生入学统一考试管理类专业学位联考逻辑试题 一. 逻辑推理:第 26~55 小题,每小题 2 分,共 60 分。下列每题给出的 A、B、C、D、E 五个选项中,只有一项是符合试题要求的。 26.哲学是关于世界观、方法论的学问。哲…...

【算法】【算法杂谈】两个排序数组中找第k小的数
目录 前言问题介绍解决方案代码编写java语言版本c语言版本c语言版本 思考感悟写在最后 前言 当前所有算法都使用测试用例运行过,但是不保证100%的测试用例,如果存在问题务必联系批评指正~ 在此感谢左大神让我对算法有了新的感悟认识! 问题介…...

ABAP 新语法--Open SQL(草稿)
1. 常量 1.1 常量赋值 常量字段可以用来为内表中的部分字段赋初始值,字段类型和长度依据输入常量的值决定 SELECTmara~matnr, " 物料号mara~matkl, " 物料组mara~mtart, " 物料类型 AS lkenz, " 删除标识,常量空字符串123 AS fla…...

2023最新常用开发网站汇总
1、在线画图工具 • 在线画图工具ProcessOn:https://www.processon.com/ • 在线画图工具draw.io:https://app.diagrams.net/ • 在线思维导图工具:http://www.mindline.cn/webapp • PlantUML在线编辑器:http://haha98k.com/…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

Python如何给视频添加音频和字幕
在Python中,给视频添加音频和字幕可以使用电影文件处理库MoviePy和字幕处理库Subtitles。下面将详细介绍如何使用这些库来实现视频的音频和字幕添加,包括必要的代码示例和详细解释。 环境准备 在开始之前,需要安装以下Python库:…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...