神经网络编程基础
目录
1、二分类(Binary Classification)
2、逻辑回归(Logistic Regression)
3、逻辑回归的代价函数(Logistic Regression Cost Function)
4、梯度下降法(Gradient Descent)
5、使用计算图求导数
6、逻辑回归中的梯度下降(Logistic Regression Gradient
7、m个样本的梯度下降
8、向量化技术
9、向量化逻辑(logitic)回归
10、向量化logistic回归的梯度输出
11、Python中的广播
12、神经网络编程中的小知识点
1、二分类(Binary Classification)
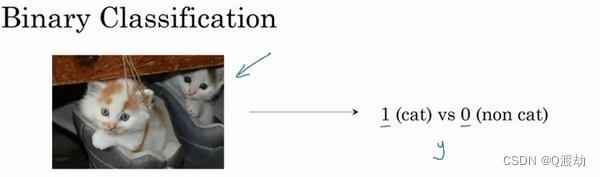
- 逻辑回归(logistic regression)是一个用于二分类(binary classification)的算法。所谓二分类是由输入到判断输出结果是或者不是。比如输入一个包含动物的图片,判断这张图片中的动物是否包含猫,有猫输出标签为 1,不是输出标签为 0,y表示输出的结果标签
- 为了在计算机中保存一张图片,需要保存三个矩阵, 它们分别对应图片中的红、绿、蓝三种颜色通道,每一个颜色通道需要一个矩阵来保存对应图片中红、绿、蓝三种像素的强度值。下面是三个规模为 5 * 4 的矩阵分别表示对应图片中红、绿、蓝三种像素的强度值(注意在实际中图片的每一个颜色通道的矩阵大小应该为 64 * 64的规模)
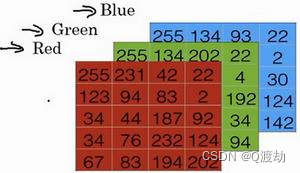
- 使用一个 5 * 4 * 3 的特征向量来保存上面三个颜色通道的像素强度值,大小为 60,使用𝑛𝑥 = 60 表示,来表示输入特征向量的维度
- (符号定义)𝑥:表示一个𝑛𝑥维数据,为输入数据,维度为(𝑛𝑥, 1),说白了就是一个列向量
- 𝑦:表示输出结果,取值为(0,1)
- (𝑥 (𝑖) , 𝑦 (𝑖) ):表示第𝑖组数据,可能是训练数据,也可能是测试数据,此处默认为训练数据,也即一组输入对应一组输出
- 𝑋 = [𝑥 (1) , 𝑥 (2) , . . . , 𝑥 (𝑚) ]:表示所有的训练数据集的输入值,放在一个 𝑛𝑥 × 𝑚的矩阵中,
- 其中𝑚表示样本数目,也即所有列向量构成的一个大矩阵,每一列就是一张图片的特征向量(也即红、蓝、绿三种像素的强度值),总共有 m 个这样的图片
- 𝑌 = [𝑦 (1) , 𝑦 (2) , . . . , 𝑦 (𝑚) ]:对应表示所有训练数据集的输出值,维度为1 × m
- 用一对(𝑥, 𝑦)来表示一个单独的样本,𝑥代表𝑛𝑥维的特征向量,𝑦 表示标签(输出结果)只能为 0 或 1。 而训练集将由𝑚个训练样本组成,其中(𝑥 (1) , 𝑦 (1) )表示第一个样本的输入和输 出,(𝑥 (2) , 𝑦 (2) )表示第二个样本的输入和输出,直到最后一个样本(𝑥 (𝑚) , 𝑦 (𝑚) ),然后所有的 这些一起表示整个训练集。有时候为了强调这是训练样本的个数,会写作𝑀𝑡𝑟𝑎𝑖𝑛,当涉及到 测试集的时候,我们会使用𝑀𝑡𝑒𝑠𝑡来表示测试集的样本数,所以这是测试集的样本数:
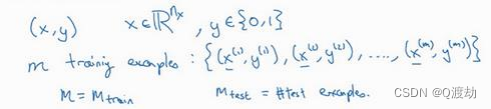
- 最后为了能把训练集表示得更紧凑一点,我们会定义一个矩阵用大写𝑋的表示,它由输入向量𝑥 (1)、𝑥 (2)等组成,如下图放在矩阵的列中,所以现在我们把𝑥 (1)作为第一列放在矩阵中,𝑥 (2)作为第二列,𝑥 (𝑚)放到第𝑚列,然后我们就得到了训练集矩阵𝑋。所以这个矩阵有𝑚列,𝑚是训练集的样本数量,然后这个矩阵的高度记为𝑛𝑥,注意有时候可能因为其他某些原因,矩阵𝑋会由训练样本按照行堆叠起来而不是列,如下图所示:𝑥 (1)的转置直到𝑥 (𝑚)的转置,但是在实现神经网络的时候,使用左边的这种形式,会让整个实现的过程变得更加简单:

- 总之,𝑋是一个规模为𝑛𝑥乘以𝑚的矩阵,当用 Python 实现的时候,会使用 X.shape,这是一条 Python 命令,用于显示矩阵的规模,即 X.shape 等于(𝑛𝑥, 𝑚),𝑋是一个规模为𝑛𝑥乘以𝑚的矩阵,这就是如何将训练样本(输入向量𝑋的集合)表示为一个矩阵
- 同样,为了能更加容易地实现一个神经网络,将标签𝑦放在列 中将会使得后续计算非常方便,所以我们定义大写的𝑌等于𝑦 (1) , 𝑦 (𝑚) , . . . , 𝑦 (𝑚),所以在这里 是一个规模为 1 乘以𝑚的矩阵,同样地使用 Python 将表示为 Y.shape 等于(1, 𝑚),表示这 是一个规模为 1 乘以𝑚的矩阵。
2、逻辑回归(Logistic Regression)
- 假设有一个预测函数 𝑦^ = 𝑤𝑇𝑥 + b,𝑦^ 表示 𝑦 等于 1 的一种可能性或者是机会,前提条件是给定了输入特征X,w上是特征权重,维度与特征向量相同,𝑏是一个实数(表示偏差),得到是一个关于输入𝑥的线性函数
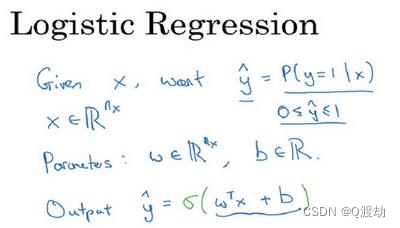
- 但是对于二元分类问题来讲这不是一个非常好的算法,因为你想让𝑦^表示实际值𝑦等于 1的机率的话,𝑦^ 应该在 0 到 1 之间。这是一个需要解决的问题,因为𝑤𝑇𝑥 + 𝑏可能比 1 要大得多,或者甚至为一个负值。对于你想要的在 0 和 1 之间的概率来说它是没有意义的,因此在逻辑回归中,我们的输出应该是𝑦^等于由上面得到的线性函数式子作为自变量的 sigmoid函数,将线性函数转换为非线性函数。
- 下图是 sigmoid 函数的图像,如果我把水平轴作为 𝑧 轴,那么关于 𝑧 的 sigmoid 函数是这样的,它是平滑地从 0 走向 1 ,让我在这里标记纵轴,这是 0 ,曲线与纵轴相交的截距是 0.5 , 这就是关于𝑧 的 sigmoid 函数的图像。我们通常都使用 𝑧 来表示 𝑤 𝑇𝑥 + 𝑏的值
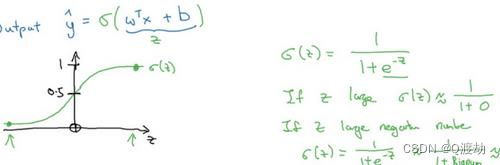
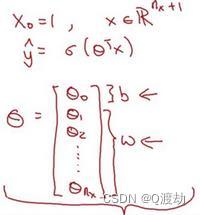
- 因此当实现逻辑回归时,就是去让机器学习参数𝑤 以及 𝑏 这样才使得 𝑦^ 成为对 𝑦 = 1 这一情况的概率的一个很好的估计(y=1,则z趋向无穷) 比如在某些例子里,定义一个额外的特征称之为𝑥 0 ,并且使它等于 1 ,那么现在 𝑋 就是一 个 𝑛 𝑥 加 1 维的变量,然后你定义 𝑦^ = 𝜎(𝜃 𝑇 𝑥) 的 sigmoid 函数。在这个备选的符号惯例里,你 有一个参数向量 𝜃 0 , 𝜃 1 , 𝜃 2 , . . . , 𝜃 𝑛 𝑥 ,这样 𝜃 0 就充当了 𝑏 ,这是一个实数,而剩下的 𝜃 1 直到 𝜃 𝑛 𝑥 充当了𝑤 ,结果就是当你实现你的神经网络时,有一个比较简单的方法是保持 𝑏 和 𝑤 分开
- (神经元的计算过程)线性计算:将输入信号与对应的权重进行加权求和,然后加上一个偏置项,得到一个加权和。数学公式为:z = Wx + b,其中,W是权重矩阵,x是输入信号向量,b是偏置向量。
- 非线性变换:将线性计算得到的结果通过激活函数进行非线性变换,得到最终的输出值。激活函数可以是sigmoid、ReLU、tanh等函数,它们可以将线性计算得到的结果映射到一个非线性的空间中,使得神经元节点可以捕捉到更复杂的数据模式和特征。 因此,整个神经元节点的计算过程是先进行线性计算,再经过激活函数进行非线性变换,最终得到输出值。
- 因此,整个神经元节点的计算过程是先进行线性计算,再经过激活函数进行非线性变换,最终得到输出值。
3、逻辑回归的代价函数(Logistic Regression Cost Function)
- (为什么需要代价函数)为了训练逻辑回归模型的参数参数𝑤和参数𝑏我们,需要一个代价函数(成本函数),通过训练代价函数来得到参数𝑤和参数𝑏。逻辑回归的输出函数:
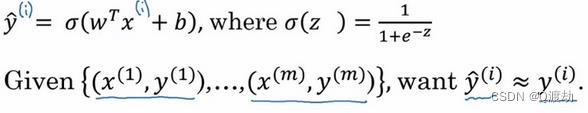
- 为了让模型通过学习调整参数,需要给予一个𝑚样本的训练集,这会在在训练集上找到参数𝑤和参数𝑏,,来得到输出。 对训练集的预测值,将它写成𝑦^,但是更希望它会接近于训练集中的𝑦值,为了对上 面的公式更详细的介绍,需要说明上面的定义是对一个训练样本来说的,这种形式也使 用于每个训练样本,使用这些带有圆括号的上标来区分索引和样本,训练样本𝑖所对应 的预测值是𝑦 (𝑖) ,是用训练样本的𝑤𝑇𝑥 (𝑖) + 𝑏然后通过 sigmoid 函数来得到,也可以把𝑧定义为 𝑧 (𝑖) = 𝑤𝑇𝑥 (𝑖) + 𝑏,我们将使用这个符号(𝑖)注解,上标(𝑖)来指明数据表示𝑥或者𝑦或者𝑧或者其 他数据的第𝑖个训练样本,这就是上标(𝑖)的含义。
- 损失函数又叫做误差函数,用来衡量算法的运行情况,Loss function:𝐿(𝑦^ , 𝑦)。 通过这个 𝐿 称为的损失函数,来衡量预测输出值和实际值有多接近。一般我们用预测值和实际值的平方差或者它们平方差的一半,但是通常在逻辑回归中我们不这么做,因为当我们在学习逻辑回归参数的时候,会发现我们的优化目标不是凸优化,只能找到多个局部最优值,梯度下降法很可能找不到全局最优值,虽然平方差是一个不错的损失函数,但是我们在逻辑回归模型中会定义另外一个损失函数。
- 逻辑回归中用到的损失函数是:𝐿(𝑦^ , 𝑦) = −𝑦log(𝑦^) − (1 − 𝑦)log(1 − 𝑦^)。选择原因如下:当 𝑦 = 1 时损失函数 𝐿 = −log(𝑦^) ,如果想要损失函数 𝐿尽可能得小(靠近0),因为 sigmoid 函数取值 [0,1] ,那么𝑦^就要尽可能大(𝑦^取值为1时), 所以𝑦^ 会无限接近于 1 。当 𝑦 = 0 时损失函数 𝐿 = −log(1 − 𝑦^) ,如果想要损失函数 𝐿尽可能得小(靠近0),那么𝑦^ 就要尽可能小(y ^取值为0时),因为 sigmoid 函数取值[0,1],所以𝑦^会无限接近于 0。在这门课中有很多的函数效果和现在这个类似,就是如果𝑦等于 1,我们就尽可能让𝑦^变大,如果𝑦等于 0,我们就尽可能让 𝑦^ 变小。
- 损失函数是在单个训练样本中定义的,它衡量的是算法在单个训练样本中表现如何,为了衡量算法在全部训练样本上的表现如何,需要定义一个算法的代价函数(成本函数),算法的代价函数是对𝑚个样本的损失函数求和然后除以𝑚:
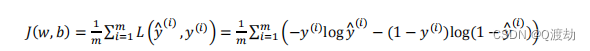
- 损失函数只适用于像这样的单个训练样本,用于衡量单一训练样本的效果。而代价函数是用于衡量参数 w 和 参数b的效果在全部训练集上总代价,所以在训练逻辑回归模型时候,我们需要找到合适的𝑤和𝑏,来让代价函数 𝐽 的总代价降到最低
4、梯度下降法(Gradient Descent)
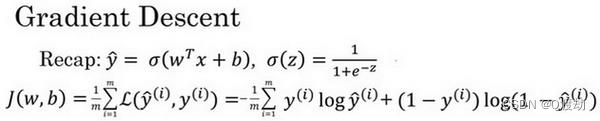
- 在深度学习中,梯度下降法是优化算法之一,用于最小化损失函数。在神经网络中,损失函数通常用来衡量模型预测结果与真实标签之间的误差。
- 梯度下降法的基本思想是,通过不断迭代调整模型参数,使损失函数的值逐渐减小,最终达到最小化损失函数的目的。具体来说,对于给定的损失函数,我们需要计算其关于模型参数(例如神经网络中的权重)的梯度(即导数),然后按照梯度的方向进行参数的更新,使损失函数的值逐渐减小。这个过程可以进行多次迭代,直到损失函数的值达到一个较小的阈值或者达到一定的迭代次数为止。
- (例子)在下面的图中,横轴表示空间参数𝑤和𝑏,在实践中,𝑤可以是更高的维度,但是为了更好地绘图,我们定义𝑤和𝑏,都是单一实数,代价函数(成本函数)𝐽(𝑤, 𝑏)是在水平轴𝑤和𝑏上的曲面,因此曲面的高度就是𝐽(𝑤, 𝑏)在某一点的函数值。我们所做的就是找到使得代价函数(成本函数)𝐽(𝑤, 𝑏)函数值是最小值,对应的参数𝑤和𝑏。代价函数(成本函数)𝐽(𝑤, 𝑏)是一个凸函数(convex function),像一个大碗一样,因为非凸图像有很多不同的局部最小值。由于逻辑回归的代价函数(成本函数)𝐽(𝑤, 𝑏)特性,必须定义代价函数(成本函数)𝐽(𝑤, 𝑏)为凸函数, 初始化𝑤和𝑏。可以用如图那个小红点来初始化参数𝑤和𝑏,也可以采用随机初始化的方法,对于逻辑回归几乎所有的初始化方法都有效,因为函数是凸函数,无论在哪里初始化,应该达到同一点或大致相同的点。
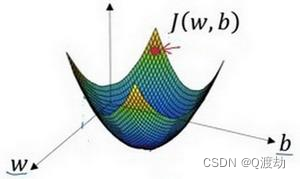
- (例子步骤)(1)、朝着最陡的下坡方向走一步,不断地迭代(2)、朝最陡的下坡方向走一步,如图,走到了如图中第二个小红点处(3)、可能停在这里也有可能继续朝最陡的下坡方向再走一步,如图,经过两次迭代走到第三个小红点处(4)、直到走到全局最优解或者接近全局最优解的地方。通过以上的三个步骤我们可以找到全局最优解,也就是代价函数(成本函数)𝐽(𝑤, 𝑏)这 个凸函数的最小值点
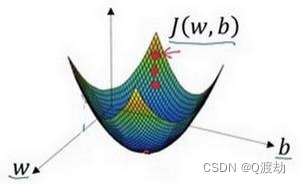
- (例子细化说明,只要一个参数,图像的右半部分)假定代价函数(成本函数)𝐽(𝑤) 只有一个参数𝑤,即用一维曲线代替多维曲线,这样可以更好画出图像。从右半部分进行梯度下降,寻找最优的损失函数,进行不断迭代的公式为𝑤 ≔ 𝑤 − 𝑎 *𝑑𝐽(𝑤)/𝑑𝑤。其中: =表示更新参数,𝑎 表示学习率(learning rate),用来控制步长(step),即向下走一步的长度𝑑𝐽(𝑤)/𝑑𝑤就是函数𝐽(𝑤)对𝑤 求导(derivative),在代码中经常使用𝑑𝑤表示这个结果。假设以如图点为初始点,该点处的斜率的符号是正的,即 𝑑𝐽(𝑤) /𝑑𝑤 > 0,所以接下来会向左走一步。
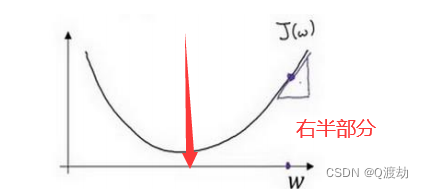
- (例子细化说明,只要一个参数,图像的左半部分)整个梯度下降法的迭代过程就是不断地向右走,即朝着最小值点方向走。因为在左半部分始终有𝑑𝐽(𝑤) /𝑑𝑤 < 0,所以经过𝑤 ≔ 𝑤 − 𝑎 *𝑑𝐽(𝑤)/𝑑𝑤不断循环迭代计算,参数w会越来越大

- (例子细化说明,两个参数)也就是偏导数,比如逻辑回归的代价函数(成本函数)𝐽(𝑤, 𝑏)是含有两个参数的。𝑤 ≔ 𝑤 − 𝑎*𝜕𝐽(𝑤,𝑏)/𝜕𝑤 𝑏 ≔ 𝑏 − 𝑎*𝜕𝐽(𝑤,𝑏)/𝜕𝑏。𝜕 表示求偏导符号,可以读作 round,𝜕𝐽(𝑤,𝑏)/𝜕𝑤就是函数𝐽(𝑤, 𝑏) 对𝑤 求偏导,在代码中我们会使用𝑑𝑤 表示这个结果,𝜕𝐽(𝑤,𝑏)/𝜕𝑏就是函数𝐽(𝑤, 𝑏)对𝑏 求偏导,在代码中我们会使用𝑑𝑏 表示这个结果, 小写字母𝑑用在求导数(derivative),即函数只有一个参数, 偏导数符号𝜕 用在求偏导(partialderivative),即函数含有两个以上的参数
- 梯度下降法有多种变体,例如批量梯度下降(Batch Gradient Descent)、随机梯度下降(Stochastic Gradient Descent)和小批量梯度下降(Mini-Batch Gradient Descent)等。这些变体的主要区别在于每次更新参数时使用的数据量不同。批量梯度下降使用全部训练数据计算梯度,因此每次更新参数的代价较高;随机梯度下降只使用一个样本计算梯度,因此更新速度较快,但可能会出现参数的震荡;小批量梯度下降折中使用部分训练数据计算梯度,既能保证更新速度,又能避免参数震荡。
5、使用计算图求导数
- 一个神经网络的计算,都是按照前向或反向传播过程组织的。首先我们计算出 一个新的网络的输出 (前向过程,蓝色部分过程) ,紧接着进行一个反向传输操作 (红色部分过程) 。后者我们用来计算出对应的梯度或导数

- 𝑑𝐽/𝑑𝑎 = 𝑑𝐽/𝑑𝑣 * 𝑑𝑣/𝑑𝑎 = 3 * 1 = 3
- (符号定义)在实际的神经网络编程中使用 𝑑𝑣 = 3,𝑑𝑣是代码里的变量名,其真正的定义是𝑑𝐽 /𝑑𝑣。𝑑𝑎 = 3 , 𝑑𝑎 是代 码里的变量名,其实代表𝑑𝐽 /𝑑𝑎 的值
- 同理由偏导数可知 𝑑𝐽/𝑑𝑢 = 𝑑𝐽/𝑑𝑣 * 𝑑𝑣/𝑑𝑢 = 3
- 𝑑𝐽/𝑑𝑏 = 𝑑𝐽/𝑑𝑣 * 𝑑𝑣/𝑑𝑢 * 𝑑𝑢/ 𝑑𝑏 = 3 * 1 * c,而 c = 2,所以 𝑑𝐽/𝑑𝑏 = 6
- 𝑑𝐽/𝑑𝑐 = 𝑑𝐽/𝑑𝑣 * 𝑑𝑣/𝑑𝑢 * 𝑑𝑢/ 𝑑𝑐 = 3 * 1 * b,而 b = 3,所以 𝑑𝐽/𝑑𝑐 = 9
- (为什么在神经网络中强调计算偏导数?)
- 在神经网络编程中,计算导数是非常重要的,因为它可以帮助我们对神经网络进行优化和训练。具体来说,计算导数可以帮助我们确定如何调整神经网络中的权重和偏差,以便使其能够更好地拟合训练数据。
- 在训练神经网络时,通常使用反向传播算法来计算每个神经元的导数。反向传播算法通过将误差从输出层反向传播到输入层,并利用链式法则计算每个神经元的导数。然后,根据这些导数来更新神经网络中的权重和偏差,以最小化网络的损失函数。
- 因此,计算导数在神经网络编程中是非常重要的,它可以帮助我们训练出更加准确和有效的神经网络,以便用于各种不同的应用场景,如图像分类、语音识别、自然语言处理等。
6、逻辑回归中的梯度下降(Logistic Regression Gradient


- 需要反向计算出损失函数𝐿(𝑎, 𝑦)关于𝑎的导数,由损失函数𝐿(𝑎, 𝑦)对𝑎求偏导数得 𝑑𝐿(𝑎,𝑦)/𝑑𝑎 = −𝑦/𝑎 + (1 − 𝑦)/(1 − 𝑎),在实际的编程实现过程中𝑑𝐿(𝑎,𝑦)/𝑑𝑎可以简写为𝑑𝑎,表示𝐿(𝑎, 𝑦)对𝑎求偏导数
- 再反向一步,在编写 Python 代码时,只需要用𝑑𝑧 来表示代价函数 𝐿 关于 𝑧 的导数𝑑𝐿 /𝑑𝑧 ,也可以写成𝑑𝐿(𝑎,𝑦) /𝑑𝑧 ,这两种写法都是正确的。 𝑑𝐿 /𝑑𝑧 = 𝑎 − 𝑦。

- 现在进行最后一步反向求偏导,也就是计算𝑤和𝑏变化对代价函数𝐿的影响。𝑑𝑤1 表示 𝜕𝐿/𝜕𝑤1 = 𝑑𝐿/𝑑𝑧 * 𝑑𝑧/𝑑𝑤1,其中 𝑑𝑧/𝑑𝑤1 = 𝑥1,所以 𝜕𝐿/𝜕𝑤1 = 𝑑𝐿/𝑑𝑧 * 𝑑𝑧/𝑑𝑤1 = 𝑥1 ⋅ 𝑑𝑧,同理 𝑑𝑤2 表示 𝜕𝐿/𝜕𝑤2 = 𝑥2 ⋅ 𝑑𝑧, 𝑑𝑏 = 𝑑𝑧
- 因此,关于单个样本的梯度下降算法,你所需要做的就是如下的事情: 使用公式𝑑𝑧 = (𝑎 − 𝑦) 计算 𝑑𝑧 , 使用𝑑𝑤 1 = 𝑥 1 ⋅ 𝑑𝑧 计算 𝑑𝑤 1 , 𝑑𝑤 2 = 𝑥 2 ⋅ 𝑑𝑧 计算 𝑑𝑤 2 , 𝑑𝑏 = 𝑑𝑧 来计算 𝑑𝑏,然后: 更新𝑤1 = 𝑤1 − 𝑎𝑑𝑤1, 更新𝑤2 = 𝑤2 − 𝑎𝑑𝑤2, 更新𝑏 = 𝑏 − 𝛼𝑑𝑏。这就是关于单个样本实例的梯度下降算法中参数更新一次的步骤。
7、m个样本的梯度下降
- 对于 m 个样本的梯度下降,是在单个样本上的 m 次循环,伪代码实现如下
J=0;dw1=0;dw2=0;db=0;
for i = 1 to mz(i) = wx(i)+b;a(i) = sigmoid(z(i));J += -[y(i)log(a(i))+(1-y(i))log(1-a(i));dz(i) = a(i)-y(i);dw1 += x1(i)dz(i);dw2 += x2(i)dz(i);db += dz(i);
J/= m;
dw1/= m;
dw2/= m;
db/= m;
w1=w1-a*dw1
w2=w2-a*dw2
b=b-a*db- 但是在上面的伪代码中,每一个特征向量只有两个特征,但是在实际开发中每一个特征向量有多个特征,此时下面的伪代码就是在做重复计算
dw1 += x1(i)dz(i);
dw2 += x2(i)dz(i);- 所以为了降低这种重复计算,必然要使用 for 循环,遍历每一个特征向量中的特诊。但是新的问题是,在神经网络中多次使用 for 循环会降低算法的效率,时间复杂度很高,所以为了避免这种情况的出现,要避免使用显式 for 循环—向量化技术(尤其在数据集的量非常大)!
8、向量化技术
- 在逻辑回归中你需要去计算𝑧 = 𝑤𝑇𝑥 + 𝑏,𝑤、𝑥都是列向量。如果你有很多的特征那么 就会有一个非常大的向量,所以𝑤 ∈ ℝ𝑛𝑥 , 𝑥 ∈ ℝ𝑛𝑥,所以如果你想使用非向量化方法去计 算𝑤𝑇x
z=0 for i in range(n_x)z+=w[i]*x[i] z+=b - 这是一个非向量化的实现,你会发现这真的很慢,作为一个对比,向量化实现将会非常直接计算 𝑤 𝑇 𝑥 ,代码如下:
z=np.dot(w,x)+b这是向量化计算 𝑤 𝑇 𝑥 的方法,你将会发现这个非常快 - 因此,在编写神经网络程序时要尽量避免 for 循环,能用内置函数或者其他方法代替 for 循环最好,尤其在大容量数据集时,能有效降低程序的时间复杂度
- (向量化的方法)numpy的内置函数:𝑛𝑝. 𝑑𝑜𝑡(𝐴, 𝑣)、𝑛𝑝. 𝑒𝑥𝑝(𝑣)、(𝑙𝑜𝑔)、np.abs()、 np.maximum() 计算元素 𝑦 中的最大值,你也可以 np.maximum(v,0) 、 𝑣 ∗∗ 2 代表获得元素 𝑦 每个值得平方、 𝑣 1 获取元素 𝑦 的倒数等 等。所以当你想写循环时候,检查 numpy 是否存在类似的内置函数,从而避免使用循环 ( loop ) 方式
9、向量化逻辑(logitic)回归
- 𝑧 (1) = 𝑤 𝑇 𝑥 (1) + 𝑏 。然后计算激活函数 𝑎 (1) = 𝜎(𝑧 (1) ) ,计算第一个样本的预测值 𝑦 。对第二个样本进行预测,你需要计算 𝑧 (2) = 𝑤 𝑇 𝑥 (2) + 𝑏 , 𝑎 (2) = 𝜎(𝑧 (2) ) 。对第三个样本进行预测,你需要计算 𝑧 (3) = 𝑤 𝑇 𝑥 (3) + 𝑏 ,𝑎 (3) = 𝜎(𝑧 (3) )
- 依次类推。 如果你有 𝑚 个训练样本,你可能需要这样做 𝑚 次,可以看出,为了完成前向传播步骤, 即对我们的 𝑚 个样本都计算出预测值。有一个办法可以并且不需要任何一个明确的 for 循 环

- 为了计算𝑊𝑇𝑋 + [𝑏𝑏. . . 𝑏] ,numpy 命令是𝑍 = 𝑛𝑝. 𝑑𝑜𝑡(𝑤. 𝑇,𝑋) + 𝑏。这里在 Python 中有一个巧妙的地方,这里 𝑏 是一个实数,或者你可以说是一个 1 × 1 矩阵,只是一个普通的实数。但是当你将这个向量加上这个实数时,Python 自动把这个实数 𝑏 扩展成一个 1 × 𝑚 的行向量。所以这种情况下的操作似乎有点不可思议,它在 Python 中被称作广播(brosdcasting)
- 对于 m 个样本的梯度下降,是在单个样本上的 m 次循环,对每一个特征向量有多个特征的情况做出向量化,伪代码实现如下

10、向量化logistic回归的梯度输出
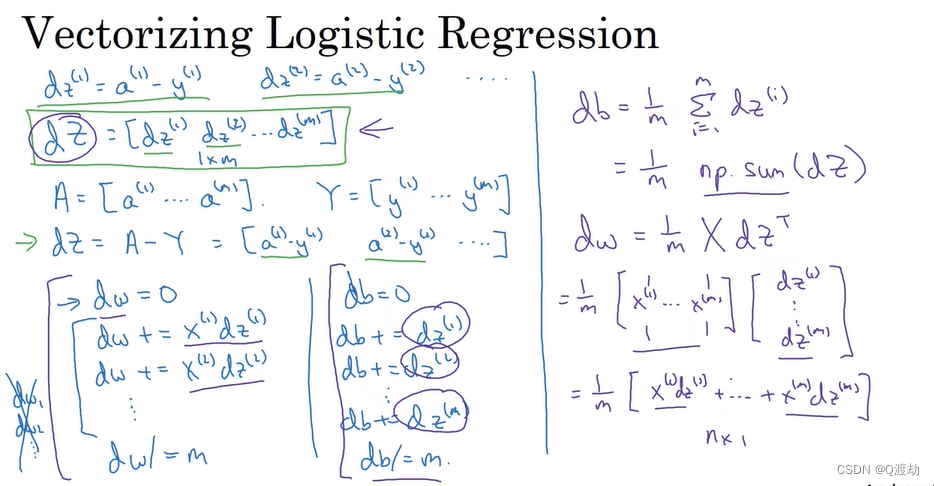
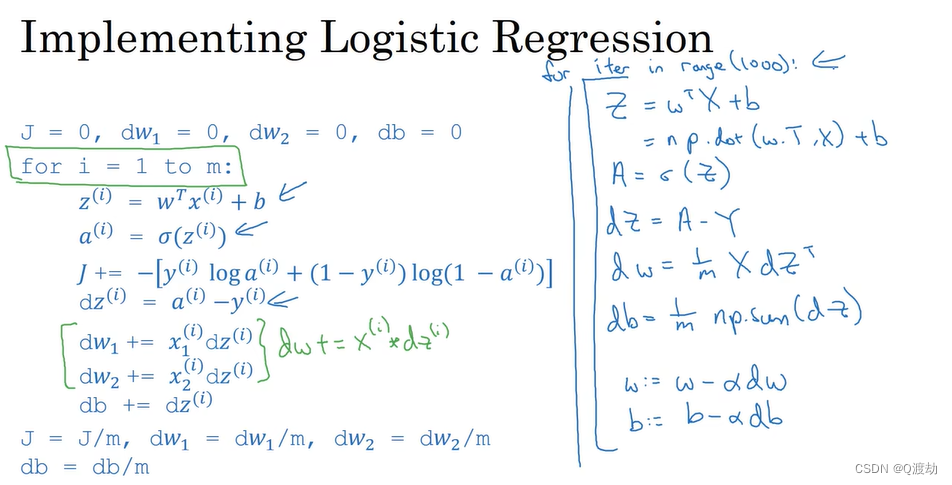
- 伪代码如下
𝑍 = 𝑤𝑇𝑋 + 𝑏 = 𝑛𝑝.𝑑𝑜𝑡(𝑤. 𝑇, 𝑋) + 𝑏 𝐴 = 𝜎(𝑍) 𝑑𝑍 = 𝐴 − 𝑌 𝑑𝑤 = 1/𝑚∗ 𝑋 ∗ 𝑑𝑧𝑇 𝑑𝑏 = 1/𝑚∗ 𝑛𝑝.𝑠𝑢𝑚(𝑑𝑍) 𝑤: = 𝑤 − 𝑎 ∗ 𝑑𝑤 𝑏: = 𝑏 − 𝑎 ∗ 𝑑𝑏11、Python中的广播
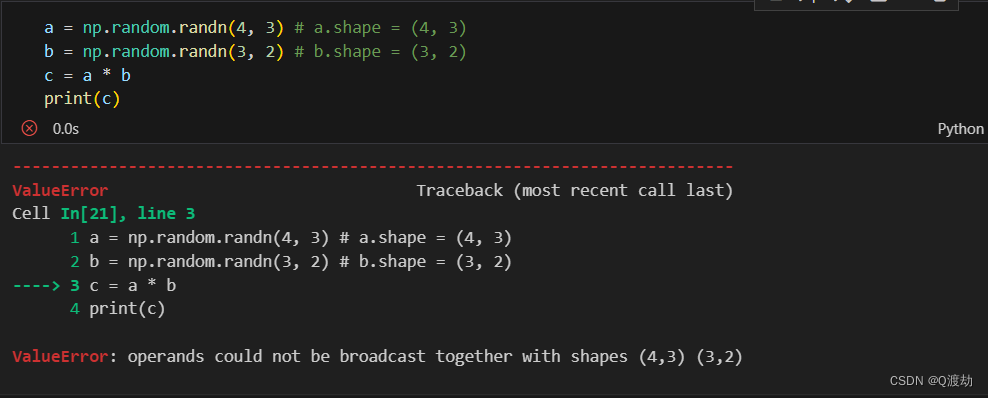
- 在广播操作中,两个矩阵的形状要么相同,要么其中一个矩阵的形状是另一个矩阵的某个维度的长度为1,才能进行广播操作
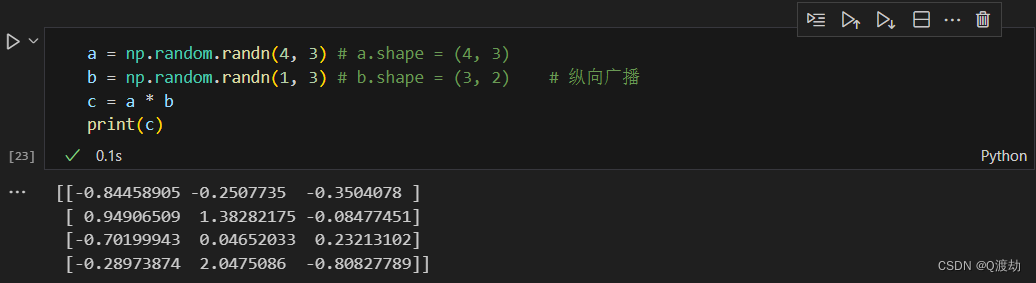
- 修改矩阵 b 为 (1,3)
- 修改矩阵 b 为(4,1)
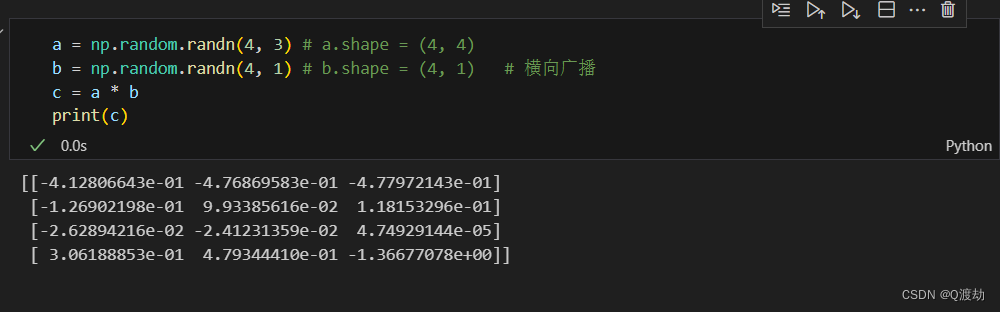
- 当然广播操作不仅存在于按照矩阵中对应元素相乘,而是存在于矩阵的加、减、乘、除。同时要注意矩阵的乘法一定要求维度相同,和按照矩阵中对应元素相乘得到的矩阵是两个不同的概念
12、神经网络编程中的小知识点
- (认知错误)
import numpy as np 𝑎 = 𝑛𝑝. 𝑟𝑎𝑛𝑑𝑜𝑚.randn(5) # 只是一个单纯地一维数组,既不是行向量也不是列向量 print(a) print(a.shape)# 这是一个列向量 b = 𝑛𝑝. 𝑟𝑎𝑛𝑑𝑜𝑚.randn(5,1) print(b) print(b.shape)# 这是一个行向量 c = 𝑛𝑝. 𝑟𝑎𝑛𝑑𝑜𝑚.randn(1,5) print(c) print(c.shape)# 输出的是一个数字,a的内积 print(np.dot(a,a.T))# 输出的是一个矩阵 print(np.dot(b,b.T))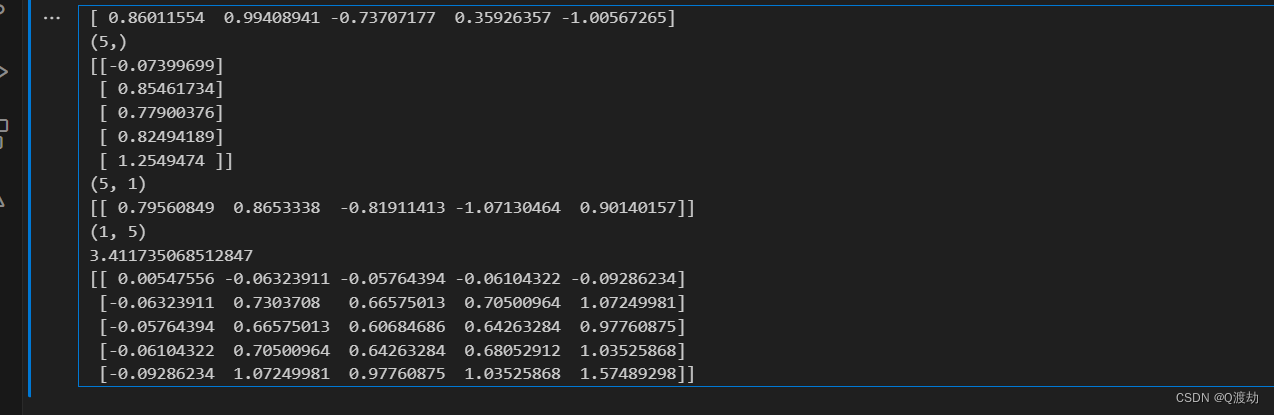
相关文章:
神经网络编程基础
目录 1、二分类(Binary Classification) 2、逻辑回归(Logistic Regression) 3、逻辑回归的代价函数(Logistic Regression Cost Function) 4、梯度下降法(Gradient Descent) 5、使用计算图求导数 6、逻辑回归中的梯度下降&…...

2023年北京/上海/深圳DAMA-CDGA/CDGP数据治理工程师认证报名
DAMA认证为数据管理专业人士提供职业目标晋升规划,彰显了职业发展里程碑及发展阶梯定义,帮助数据管理从业人士获得企业数字化转型战略下的必备职业能力,促进开展工作实践应用及实际问题解决,形成企业所需的新数字经济下的核心职业…...

Python之枚举类Enum定义错误码
在 web 项目中,我们经常使用自定义状态码来告知请求方请求结果以及请求状态;在 Python 中该如何设计自定义的状态码信息呢? 1、普通类字典设计状态码 class RETCODE:OK "0"ERROR …...

GIS大数据处理框架sedona(塞多纳)编程入门指导
GIS大数据处理框架sedona(塞多纳)编程入门指导 简介 Apache Sedona™是一个用于处理大规模空间数据的集群计算系统。Sedona扩展了现有的集群计算系统,如Apache Spark和Apache Flink,使用一组开箱即用的分布式空间数据集和空间SQL,可以有效地…...

C++基础(7)——类和对象(5)
前言 本文主要介绍C中的继承 4.6.1:继承和继承方式(公有、保护、私有) 4.6.2:继承中的对象模型,sizeof()求子类对象大小 4.6.3:子类继承父类后,两者构造和析构顺序 父类先构造、子类先析构 如…...

【Express.js】sql-knex 增删改查
Sql增删改查 本节使用knex作为sql框架,以sqlite数据库为例 准备工作 knex是一个运行在各自数据库Driver上的框架,因此需要安装相应的js版数据库Driver,如: PostgreSQL -> pg, mysql/mariadb -> mysql, sqlite -> sqlite3… 安装…...
构建基于前后端分离的医学影像学学习平台:Java技术实现与深度解析
在医学领域,影像学学习平台是一种重要的工具,用于帮助医学学生和专业人士学习和研究医学影像。本文将介绍如何使用Java构建一个基于前后端分离的医学影像学学习平台,通过结合前沿的Web开发技术和医学影像处理算法,为用户提供强大且高效的学习工具。 技术架构设计: 在构…...

从零开始学习R语言编程:完全指南
一、引言 R语言是一种流行的数据分析语言,广泛应用于学术界、商业界和社会科学研究等领域。与其它数据分析软件相比,R语言的优点包括免费开源、高效可靠、具有强大的数据分析和可视化能力等。R语言的编程基础包括了各种控制结构和函数,可以方…...
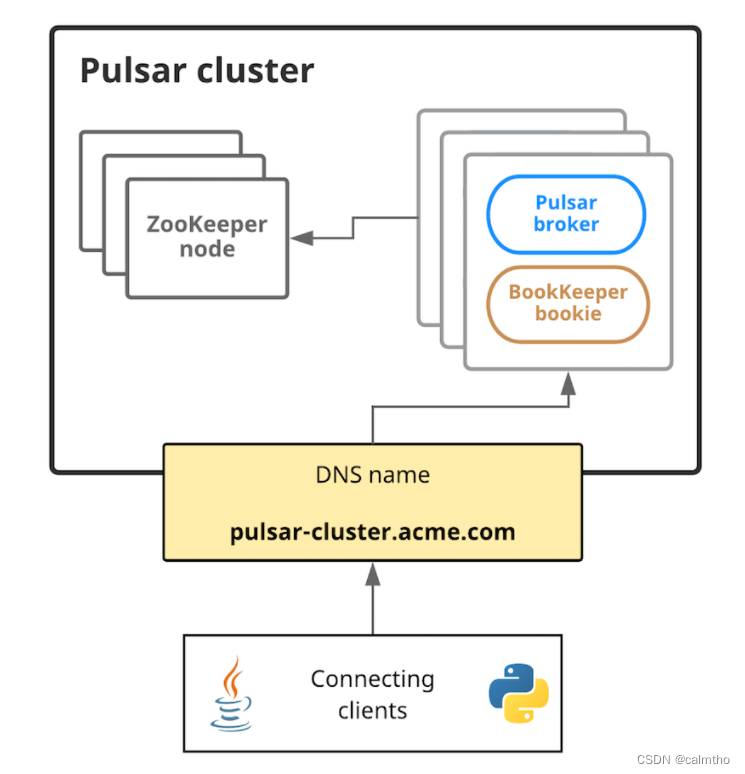
PulsarMQ系列入门篇
文章目录 介绍:部署安装讲解:安装单机版本测试(Linux下): 介绍: PulsarMQ 现托管于apache Apache 软件基金会顶级项目,2016年由雅虎公司开源的分布式多租户消息中间件 ,是下一代云原生分布式消息…...

编程的实践理论 第九章 交互
第九章 交互 根据状态的初始值和终止值,我们已经描述了计算。一个状态变量的声明如下: var x: T S ∃x, x′: T S 它说的是一个状态变量有两个数学变量,一个是初始值,一个是终止值。在这个 声明的作用域内,x和x…...

BSN全球技术创新发展峰会在武汉举办,“延安链”正式发布
原标题:《第二届BSN全球技术创新发展峰会在武汉成功举行》 6月9日,由湖北省人民政府指导,湖北省发展改革委、国家信息中心联合主办,中国移动、中国电信、中国联通、武汉市江汉区人民政府、区块链服务网络(BSN…...
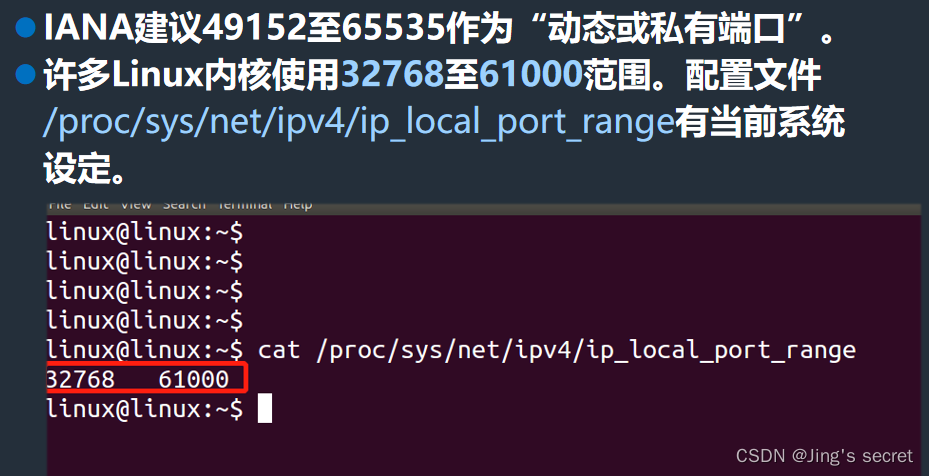
8.4 IP地址与端口号
目录 IP地址 IP地址及编址方式 IP 地址及其表示方法 点分十进制记法举例 IP 地址采用 2 级结构 分类的 IP 地址 分类的 IP 地址 多归属主机 各类 IP 地址的指派范围 编辑 一般不使用的特殊的 IP 地址 编辑 分类的 IP 地址的优点和缺点 划分子网 无分类编址 CIDR 无…...

day56_springmvc
今日内容 零、 复习昨日 零、 复习昨日 一、JSON处理【重点】 springmvc支持json数据交互,但是自己本身没有对应jar,使用的是第三方Jackson,只需要导入对应依赖,springmvc即可使用 如果需要换用到FastJson 导入依赖配置文件中指定json转换的类型为FastJson本次课程没有替换,用的…...

SQL Server Management Studio (SSMS)下载,安装以及连接数据库配置
目录 (一)前言 (二)下载与安装 1. 下载 (1)下载地址 (2)SSMS对操作系统的要求 2. 安装 (1)存放下载好的安装包 (2) 双击进入安…...

go 错误 异常
自定义错误 Go语言中 错误使用内建的 error 类型表示, error类型是一个接口类型:定义如下: error 有一个 Error() 的方法‘所有实现该接口的类型 都可以当做一个错误的类型;Error()方法输入具体错误描述,在打印错误时…...

智慧加油站卸油作业行为分析算法 opencv
智慧加油站卸油作业行为分析系统通过opencvpython网络模型技术,智慧加油站卸油作业行为分析算法实现对卸油作业过程的实时监测。当现场出现卸油作业时人员离岗,打电话人员抽烟等违规行为,灭火器未正确摆放,明火和烟雾等异常状态&a…...
LiangGaRy-学习笔记-Day22
1、shell工具-tput 这个是tput bash工具 具体的操作如下: tput clear:清屏tput cup Y X 第Y行,第X列的位置 tput bold:字体加粗tput sgr0 : 重置命令tput setaf n n:代表数字0-7 0黑色1红色2绿色3黄色4蓝…...

数据库横表和竖表有什么区别
横表和竖表是描述数据库表结构的两种形式,它们之间的主要区别在于数据的组织方式和用途。 横表(宽表): 横表是一种常见的表结构,其特点是每一行数据包含所有相关属性,字段通常作为列出现。横表中的每行代表…...

哈希表--day1--基本理论介绍
文章目录 哈希表哈希函数哈希碰撞拉链法线性探测法 常见的三种哈希函数数组setmap 总结 哈希表 Hash table是根据关键码的值来直接进行访问的数据结构。 其实直白来讲其实数组就是一张哈希表,不过其索引是十分简单的,我们通过0来访问num[0],…...
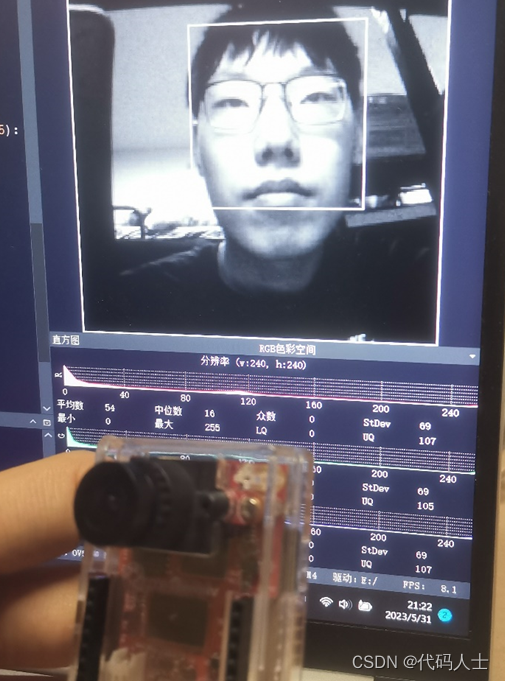
基于OpenMV的疲劳驾驶检测系统的设计
一、前言 借助平台将毕业设计记录下来,方便以后查看以及与各位大佬朋友们交流学习。如有问题可以私信哦。 本文主要从两个方面介绍毕业设计:硬件,软件(算法)。以及对最后的实验结果进行分析。感兴趣的朋友们可以评论区…...

跨平台兼容秘诀:OpenClaw在Linux对接百川2-13B-4bits模型全记录
跨平台兼容秘诀:OpenClaw在Linux对接百川2-13B-4bits模型全记录 1. 为什么选择Linux环境部署OpenClaw 去年夏天,当我第一次尝试在Ubuntu服务器上部署OpenClaw时,完全没料到这会成为我最折腾也最有成就感的开源项目实践。作为长期使用macOS的…...

数据、信息、知识:三者有什么区别
在人工智能、知识表示和知识图谱的学习中,“数据”“信息”“知识”是三个最基础的概念。它们彼此相关,但并不相同。只有区分这三者,才能进一步理解:为什么计算机不能只存储数据,还需要组织信息、表达知识,…...

量子力学语言:狄拉克符号法进阶全集
量子力学语言:狄拉克符号法进阶全集 这是一篇面向“已经见过狄拉克符号,但还没有彻底吃透它”的完整长文。目标不是只会抄写公式,而是真正理解:狄拉克符号到底是什么、为什么它能统一波函数和矩阵、它怎样承载测量、表象变换、多体系统与密度矩阵。 导读 很多人第一次接触…...

FLUX.1-dev驱动像素终端实战:API服务封装与Python脚本批量调用示例
FLUX.1-dev驱动像素终端实战:API服务封装与Python脚本批量调用示例 1. 像素幻梦工坊概述 Pixel Dream Workshop是一款基于FLUX.1-dev扩散模型的像素艺术生成终端,专为创作者设计。它采用16-bit像素风格的现代明亮界面,彻底改变了传统AI绘图…...

GLM-OCR开源模型价值:相比闭源OCR,数据不出域+模型可审计+可定制
GLM-OCR开源模型价值:相比闭源OCR,数据不出域模型可审计可定制 1. 为什么需要关注OCR的数据安全问题 在日常工作中,我们经常需要处理各种文档和图片中的文字信息。传统的OCR技术虽然方便,但当你使用云端OCR服务时,你…...

SolidWorks 扫掠实战:从零构建带倒角的方形螺旋管
1. 从零开始理解方形螺旋管建模 第一次用SolidWorks做方形螺旋管时,我盯着屏幕发呆了半小时——明明圆形螺旋管点几下就能搞定,换成方形截面怎么就报错连连?后来才发现,这种带倒角的异形螺旋管建模,关键不在于操作步骤…...
)
ESP32S3变身HID设备:用esp-iot-solution实现USB键盘鼠标(附常见编译错误修复)
ESP32S3实战:基于esp-iot-solution打造高响应USB HID设备的全流程指南 当ESP32S3遇上USB HID协议,开发者手中的这块开发板瞬间化身为键盘鼠标模拟利器。不同于市面上简单的教程,本文将带您深入esp-iot-solution框架的核心,从环境搭…...

P0400YE FBM04输入输出模块
P0400YE FBM04输入输出模块是一款面向工业自动化系统的通用I/O单元,主要用于实现现场设备与控制系统之间的信号交互,具备高可靠性和良好扩展性,广泛应用于生产线、过程控制及分布式控制系统中。支持多通道数字输入输出,提高系统控…...
)
Docker镜像拉取超时?5分钟搞定国内镜像源加速配置(附最新可用镜像列表)
Docker镜像加速全攻略:2024国内镜像源配置与疑难排解 每次在终端输入docker pull后盯着进度条卡住不动,是不是感觉血压都在飙升?作为国内开发者,Docker官方镜像源的访问问题就像一场永远打不完的"拉锯战"。但别急着摔键…...

智能匹配技术:重新定义Illustrator设计效率提升新范式
智能匹配技术:重新定义Illustrator设计效率提升新范式 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 一、行业困境分析:设计师如何摆脱机械劳动的桎梏&…...