PostgreSQL的学习心得和知识总结(一百二十三)|深入理解PostgreSQL数据库开源扩展pg_dirtyread的使用场景和实现原理
目录结构
注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下:
1、参考书籍:《PostgreSQL数据库内核分析》
2、参考书籍:《数据库事务处理的艺术:事务管理与并发控制》
3、PostgreSQL数据库仓库链接,点击前往
4、日本著名PostgreSQL数据库专家 铃木启修 网站主页,点击前往
5、参考书籍:《PostgreSQL中文手册》
6、参考书籍:《PostgreSQL指南:内幕探索》,点击前往
7、参考书籍:《事务处理 概念与技术》
8、本人 pg_dirtyread git仓库,点击前往
1、本文内容全部来源于开源社区 GitHub和以上博主的贡献,本文也免费开源(可能会存在问题,评论区等待大佬们的指正)
2、本文目的:开源共享 抛砖引玉 一起学习
3、本文不提供任何资源 不存在任何交易 与任何组织和机构无关
4、大家可以根据需要自行 复制粘贴以及作为其他个人用途,但是不允许转载 不允许商用 (写作不易,还请见谅 💖)
5、本文内容基于PostgreSQL15.1源码开发而成
PostgreSQL数据库开源扩展pg_dirtyread的使用场景和实现原理
- 文章快速说明索引
- 问题描述背景说明
- 功能实现源码解析
- 功能实现细节说明

文章快速说明索引
学习目标:
做数据库内核开发久了就会有一种 少年得志,年少轻狂 的错觉,然鹅细细一品觉得自己其实不算特别优秀 远远没有达到自己想要的。也许光鲜的表面掩盖了空洞的内在,每每想到于此,皆有夜半临渊如履薄冰之感。为了睡上几个踏实觉,即日起 暂缓其他基于PostgreSQL数据库的兼容功能开发,近段时间 将着重于学习分享Postgres的基础知识和实践内幕。
学习内容:(详见目录)
1、PostgreSQL数据库开源扩展pg_dirtyread的使用场景和实现原理
学习时间:
2023-02-16 10:18:54
学习产出:
1、PostgreSQL数据库基础知识回顾 1个
2、CSDN 技术博客 1篇
3、PostgreSQL数据库内核深入学习
注:下面我们所有的学习环境是Centos7+PostgreSQL15.1(pg_backtrace1.0)+Oracle19C+MySQL8.0
postgres=# select version();version
-----------------------------------------------------------------------------PostgreSQL 14.4 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.1.0, 64-bit
(1 row)postgres=# \dxList of installed extensionsName | Version | Schema | Description
--------------+---------+------------+------------------------------pg_backtrace | 1.0 | public | Dump backtrace i errorsplpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(2 rows)postgres=##-----------------------------------------------------------------------------#SQL> select * from v$version; BANNER Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production
BANNER_FULL Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production Version 19.17.0.0.0
BANNER_LEGACY Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production
CON_ID 0#-----------------------------------------------------------------------------#mysql> select version();
+-----------+
| version() |
+-----------+
| 8.0.27 |
+-----------+
1 row in set (0.06 sec)mysql>
问题描述背景说明
pg_dirtyread这个插件之前我们已经多次提过,一直没有详细介绍过其使用场景和实现原理。接下来我们快速过一下这个短小精悍功能强大的插件:
[postgres@song197:~/postgres/contrib → REL_15_1]$ git clone git@github.com:TsinghuaLucky912/pg_dirtyread.git
Cloning into 'pg_dirtyread'...
remote: Enumerating objects: 422, done.
remote: Counting objects: 100% (27/27), done.
remote: Compressing objects: 100% (23/23), done.
remote: Total 422 (delta 10), reused 15 (delta 4), pack-reused 395
Receiving objects: 100% (422/422), 88.79 KiB | 0 bytes/s, done.
Resolving deltas: 100% (238/238), done.
[postgres@song197:~/postgres/contrib → REL_15_1]$
[postgres@song197:~/postgres/contrib → REL_15_1]$ cd pg_dirtyread/
[postgres@song197:~/postgres/contrib/pg_dirtyread → master]$ ls
contrib dirtyread_tupconvert.c expected Makefile pg_dirtyread--1.0.sql pg_dirtyread.c README.md tupconvert.c.upstream
debian dirtyread_tupconvert.h LICENSE pg_dirtyread--1.0--2.sql pg_dirtyread--2.sql pg_dirtyread.control sql tupconvert.h.upstream
[postgres@song197:~/postgres/contrib/pg_dirtyread → master]$
[postgres@song197:~/postgres/contrib/pg_dirtyread → master]$
[postgres@song197:~/postgres/contrib/pg_dirtyread → master]$
[postgres@song197:~/postgres/contrib/pg_dirtyread → master]$ make
gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Werror=vla -Wendif-labels -Wmissing-format-attribute -Wimplicit-fallthrough=3 -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -Wno-format-truncation -g -O0 -fPIC -I. -I./ -I/home/postgres/test/include/server -I/home/postgres/test/include/internal -D_GNU_SOURCE -c -o pg_dirtyread.o pg_dirtyread.c
gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Werror=vla -Wendif-labels -Wmissing-format-attribute -Wimplicit-fallthrough=3 -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -Wno-format-truncation -g -O0 -fPIC -I. -I./ -I/home/postgres/test/include/server -I/home/postgres/test/include/internal -D_GNU_SOURCE -c -o dirtyread_tupconvert.o dirtyread_tupconvert.c
gcc -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Werror=vla -Wendif-labels -Wmissing-format-attribute -Wimplicit-fallthrough=3 -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -Wno-format-truncation -g -O0 -fPIC -shared -o pg_dirtyread.so pg_dirtyread.o dirtyread_tupconvert.o -L/home/postgres/test/lib -Wl,--as-needed -Wl,-rpath,'/home/postgres/test/lib',--enable-new-dtags
[postgres@song197:~/postgres/contrib/pg_dirtyread → master]$ ls
contrib dirtyread_tupconvert.c dirtyread_tupconvert.o LICENSE pg_dirtyread--1.0--2.sql pg_dirtyread--2.sql pg_dirtyread.control pg_dirtyread.so sql tupconvert.h.upstream
debian dirtyread_tupconvert.h expected Makefile pg_dirtyread--1.0.sql pg_dirtyread.c pg_dirtyread.o README.md tupconvert.c.upstream
[postgres@song197:~/postgres/contrib/pg_dirtyread → master]$
[postgres@song197:~/postgres/contrib/pg_dirtyread → master]$
[postgres@song197:~/postgres/contrib/pg_dirtyread → master]$ make install -j8
/usr/bin/mkdir -p '/home/postgres/test/lib'
/usr/bin/mkdir -p '/home/postgres/test/share/extension'
/usr/bin/install -c -m 755 pg_dirtyread.so '/home/postgres/test/lib/pg_dirtyread.so'
/usr/bin/mkdir -p '/home/postgres/test/share/extension'
/usr/bin/install -c -m 644 .//pg_dirtyread.control '/home/postgres/test/share/extension/'
/usr/bin/install -c -m 644 .//pg_dirtyread--1.0.sql .//pg_dirtyread--1.0--2.sql .//pg_dirtyread--2.sql '/home/postgres/test/share/extension/'
[postgres@song197:~/postgres/contrib/pg_dirtyread → master]$
pg_dirtyread 扩展提供了从表中读取死的但未清理的行的能力。支持 PostgreSQL 9.2 及更高版本。(在 9.2 上,至少需要 9.2.9。)一旦构建并安装了 pg_dirtyread,您就可以将它添加到数据库中。加载 pg_dirtyread 就像以超级用户身份连接到数据库并运行一样简单:
CREATE EXTENSION pg_dirtyread;SELECT * FROM pg_dirtyread('tablename') AS t(col1 type1, col2 type2, ...);
需要注意:pg_dirtyread() 函数返回 RECORD,因此有必要附加一个描述表模式的表别名子句。列按名称匹配,因此可以在别名中省略某些列,或重新排列列。如下:
postgres=# \dxList of installed extensionsName | Version | Schema | Description
---------+---------+------------+------------------------------plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(1 row)postgres=# CREATE EXTENSION pg_dirtyread;
CREATE EXTENSION
postgres=# \dxList of installed extensionsName | Version | Schema | Description
--------------+---------+------------+------------------------------------------pg_dirtyread | 2 | public | Read dead but unvacuumed rows from tableplpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(2 rows)postgres=# CREATE TABLE foo (bar bigint, baz text);
CREATE TABLE
postgres=# ALTER TABLE foo SET (
postgres(# autovacuum_enabled = false, toast.autovacuum_enabled = false
postgres(# );
ALTER TABLE
postgres=# select * from pg_type where typname like '%foo%';oid | typname | typnamespace | typowner | typlen | typbyval | typtype | typcategory | typispreferred | typisdefined | typdelim | typrelid | typsubscript | typelem | typarray | typinput | typoutput | typreceive | typsend | typmodin | typmodout | typanalyze | typalign | typstorage | typnotnull | typbasetype | typtypmod | typndims | typcollation | typdefaultbin | typdefault | typacl
-------+---------+--------------+----------+--------+----------+---------+-------------+----------------+--------------+----------+----------+-------------------------+---------+----------+-----------+------------+-------------+-------------+----------+-----------+------------------+----------+------------+------------+-------------+-----------+----------+--------------+---------------+------------+--------16388 | foo | 2200 | 10 | -1 | f | c | C | f | t | , | 16386 | - | 0 | 16387 | record_in | record_out | record_recv | record_send | - | - | - | d | x | f | 0 | -1 | 0 | 0 | | | 16387 | _foo | 2200 | 10 | -1 | f | b | A | f | t | , | 0 | array_subscript_handler | 16388 | 0 | array_in | array_out | array_recv | array_send | - | - | array_typanalyze | d | x | f | 0 | -1 | 0 | 0 | | |
(2 rows)postgres=#
postgres=# INSERT INTO foo VALUES (1, 'Test'), (2, 'New Test');
INSERT 0 2
postgres=#
postgres=# create extension pageinspect ;
CREATE EXTENSION
postgres=# \dxList of installed extensionsName | Version | Schema | Description
--------------+---------+------------+-------------------------------------------------------pageinspect | 1.10 | public | inspect the contents of database pages at a low levelpg_dirtyread | 2 | public | Read dead but unvacuumed rows from tableplpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(3 rows)postgres=# select * from heap_page_items(get_raw_page('foo',0)) ;lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+--------------------------------------1 | 8152 | 1 | 37 | 736 | 0 | 0 | (0,1) | 2 | 2050 | 24 | | | \x01000000000000000b546573742 | 8104 | 1 | 41 | 736 | 0 | 0 | (0,2) | 2 | 2050 | 24 | | | \x0200000000000000134e65772054657374
(2 rows)postgres=# DELETE FROM foo WHERE bar = 1;
DELETE 1
postgres=# select * from heap_page_items(get_raw_page('foo',0)) ;lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+--------------------------------------1 | 8152 | 1 | 37 | 736 | 738 | 0 | (0,1) | 8194 | 258 | 24 | | | \x01000000000000000b546573742 | 8104 | 1 | 41 | 736 | 0 | 0 | (0,2) | 2 | 2306 | 24 | | | \x0200000000000000134e65772054657374
(2 rows)postgres=# select * from foo;bar | baz
-----+----------2 | New Test
(1 row)postgres=# select * from heap_page_items(get_raw_page('foo',0)) ;lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+--------------------------------------1 | 8152 | 1 | 37 | 736 | 738 | 0 | (0,1) | 8194 | 1282 | 24 | | | \x01000000000000000b546573742 | 8104 | 1 | 41 | 736 | 0 | 0 | (0,2) | 2 | 2306 | 24 | | | \x0200000000000000134e65772054657374
(2 rows)postgres=#
如上,foo表并没有vacuum,所以使用pageinspect也是可以看到 死元组 的存在,如下使用pg_dirtyread再看一下(并看一下清理之后的):
postgres=# select * from foo;bar | baz
-----+----------2 | New Test
(1 row)postgres=# SELECT * FROM pg_dirtyread('foo') as t(bar bigint, baz text);bar | baz
-----+----------1 | Test2 | New Test
(2 rows)postgres=# vacuum foo;
VACUUM
postgres=# SELECT * FROM pg_dirtyread('foo') as t(bar bigint, baz text);bar | baz
-----+----------2 | New Test
(1 row)postgres=# select * from heap_page_items(get_raw_page('foo',0)) ;lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+--------------------------------------1 | 0 | 0 | 0 | | | | | | | | | | 2 | 8144 | 1 | 41 | 736 | 0 | 0 | (0,2) | 2 | 2306 | 24 | | | \x0200000000000000134e65772054657374
(2 rows)postgres=#
在pg_dirtyread的新版本中,又新增了一些功能(Dropped Columns和System Columns) 如下:
Dropped Columns:只要表没有被重写(例如通过 VACUUM FULL 或 CLUSTER),就可以检索删除列的内容。使用 dropped_N 访问第 N 列,从 1 开始计数(下面有演示)。PostgreSQL 删除了原始列的类型信息,因此如果在表别名中指定了正确的类型,则只能进行少量完整性检查;检查的是类型长度、类型对齐、类型修饰符和按值传递。
postgres=# \d
Did not find any relations.
postgres=# CREATE TABLE ab(a text, b text);
CREATE TABLE
postgres=# INSERT INTO ab VALUES ('Hello', 'World');
INSERT 0 1
postgres=# ALTER TABLE ab DROP COLUMN b;
ALTER TABLE
postgres=# DELETE FROM ab;
DELETE 1
postgres=# select * from ab;a
---
(0 rows)postgres=# SELECT * FROM pg_dirtyread('ab') ab(a text, dropped_2 text);a | dropped_2
-------+-----------Hello | World
(1 row)postgres=# SELECT * FROM pg_dirtyread('ab') ab(a text, b text);
2023-02-16 11:24:17.799 CST [4660] ERROR: Error converting tuple descriptors!
2023-02-16 11:24:17.799 CST [4660] DETAIL: Attribute "b" does not exist in type ab.
2023-02-16 11:24:17.799 CST [4660] STATEMENT: SELECT * FROM pg_dirtyread('ab') ab(a text, b text);
ERROR: Error converting tuple descriptors!
DETAIL: Attribute "b" does not exist in type ab.
postgres=#
System Columns:可以通过将它们包含在附加到 pg_dirtyread() 调用的表别名中来检索系统列,例如 xmax 和 ctid。一个布尔类型的特殊列 dead 可用于报告死行(如 HeapTupleIsSurelyDead)。死列在恢复期间不可用,即最明显的是在备用服务器上不可用。oid 列仅在 PostgreSQL 版本 11 及更早版本中可用。
postgres=# CREATE TABLE foo2 (bar bigint, baz text);
CREATE TABLE
postgres=# ALTER TABLE foo2 SET (
postgres(# autovacuum_enabled = false, toast.autovacuum_enabled = false
postgres(# );
ALTER TABLE
postgres=# INSERT INTO foo2 VALUES (1, 'Test'), (2, 'New Test');
INSERT 0 2
postgres=# select * from foo2 ;bar | baz
-----+----------1 | Test2 | New Test
(2 rows)postgres=# DELETE FROM foo2 WHERE bar = 1;
DELETE 1
postgres=# SELECT * FROM pg_dirtyread('foo2') AS t(tableoid oid, ctid tid, xmin xid, xmax xid, cmin cid, cmax cid, dead boolean,
postgres(# bar bigint, baz text);tableoid | ctid | xmin | xmax | cmin | cmax | dead | bar | baz
----------+-------+------+------+------+------+------+-----+----------16442 | (0,1) | 747 | 748 | 0 | 0 | f | 1 | Test16442 | (0,2) | 747 | 0 | 0 | 0 | f | 2 | New Test
(2 rows)postgres=#
当然这两个也可以结合在一起进行使用,如下:
postgres=# SELECT * FROM pg_dirtyread('foo2') AS t(tableoid oid, ctid tid, xmin xid, xmax xid, cmin cid, cmax cid, dead boolean,bar bigint, baz text);tableoid | ctid | xmin | xmax | cmin | cmax | dead | bar | baz
----------+-------+------+------+------+------+------+-----+----------16442 | (0,1) | 747 | 748 | 0 | 0 | f | 1 | Test16442 | (0,2) | 747 | 0 | 0 | 0 | f | 2 | New Test
(2 rows)postgres=# ALTER TABLE foo2 DROP COLUMN baz;
ALTER TABLE
postgres=# SELECT * FROM pg_dirtyread('foo2') AS t(tableoid oid, ctid tid, xmin xid, xmax xid, cmin cid, cmax cid, dead boolean,bar bigint, dropped_2 text);tableoid | ctid | xmin | xmax | cmin | cmax | dead | bar | dropped_2
----------+-------+------+------+------+------+------+-----+-----------16442 | (0,1) | 747 | 748 | 0 | 0 | f | 1 | Test16442 | (0,2) | 747 | 0 | 0 | 0 | f | 2 | New Test
(2 rows)postgres=# vacuum foo2 ;
VACUUM
postgres=# SELECT * FROM pg_dirtyread('foo2') AS t(tableoid oid, ctid tid, xmin xid, xmax xid, cmin cid, cmax cid, dead boolean,bar bigint, dropped_2 text);tableoid | ctid | xmin | xmax | cmin | cmax | dead | bar | dropped_2
----------+-------+------+------+------+------+------+-----+-----------16442 | (0,2) | 747 | 0 | 0 | 0 | f | 2 | New Test
(1 row)postgres=#
功能实现源码解析
postgres=# \dfList of functionsSchema | Name | Result data type | Argument data types | Type
--------+--------------+------------------+---------------------+------public | pg_dirtyread | SETOF record | regclass | func
(1 row)postgres=# \df+ pg_dirtyread List of functionsSchema | Name | Result data type | Argument data types | Type | Volatility | Parallel | Owner | Security | Access privileges | Language | Source code | Description
--------+--------------+------------------+---------------------+------+------------+----------+----------+----------+-------------------+----------+--------------+-------------public | pg_dirtyread | SETOF record | regclass | func | volatile | unsafe | postgres | invoker | | c | pg_dirtyread |
(1 row)postgres=#
接下来,以下面SQL为例,详细介绍一下这个插件的作用原理:
postgres=# SELECT * FROM foo ;bar | baz
-----+----------2 | New Test
(1 row)postgres=# ALTER TABLE foo DROP COLUMN baz;
ALTER TABLE
postgres=# SELECT * FROM pg_dirtyread('foo') AS t(tableoid oid, ctid tid, xmin xid, xmax xid, cmin cid, cmax cid, dead boolean,bar bigint, dropped_2 text);tableoid | ctid | xmin | xmax | cmin | cmax | dead | bar | dropped_2
----------+-------+------+------+------+------+------+-----+-----------16447 | (0,1) | 754 | 755 | 0 | 0 | t | 1 | Test16447 | (0,2) | 754 | 0 | 0 | 0 | f | 2 | New Test
(2 rows)postgres=#-- foo 表第一行数据被delete;第二列 baz被drop;此时表并未被清理
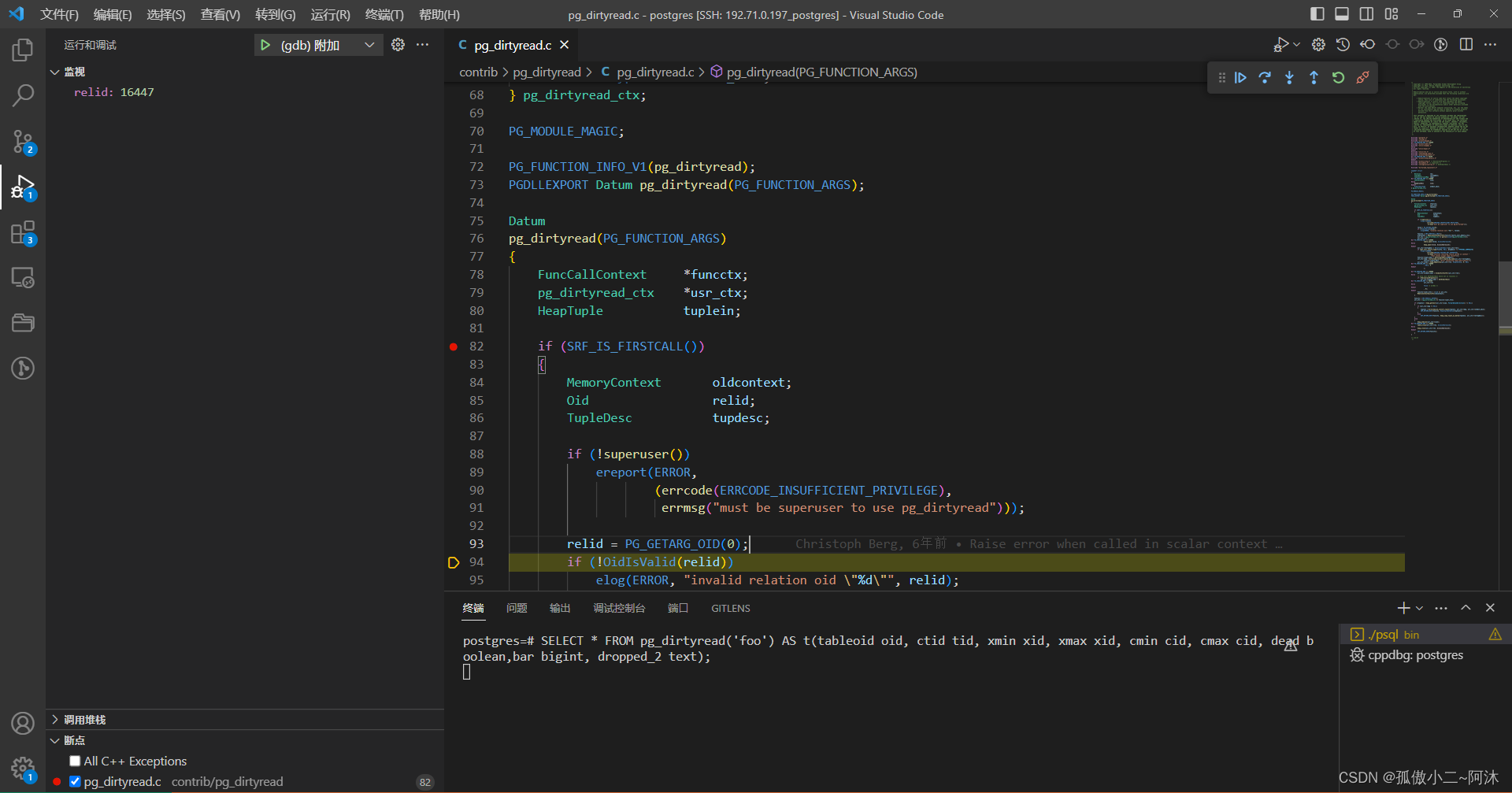
此时函数调用堆栈,如下:
pg_dirtyread.so!pg_dirtyread(FunctionCallInfo fcinfo)
ExecMakeTableFunctionResult(SetExprState * setexpr, ExprContext * econtext, MemoryContext argContext, TupleDesc expectedDesc, _Bool randomAccess)
FunctionNext(FunctionScanState * node)
ExecScanFetch(ScanState * node, ExecScanAccessMtd accessMtd, ExecScanRecheckMtd recheckMtd)
ExecScan(ScanState * node, ExecScanAccessMtd accessMtd, ExecScanRecheckMtd recheckMtd)
ExecFunctionScan(PlanState * pstate)
ExecProcNodeFirst(PlanState * node)
ExecProcNode(PlanState * node)
ExecutePlan(EState * estate, PlanState * planstate, _Bool use_parallel_mode, CmdType operation, _Bool sendTuples, uint64 numberTuples, ScanDirection direction, DestReceiver * dest, _Bool execute_once)
standard_ExecutorRun(QueryDesc * queryDesc, ScanDirection direction, uint64 count, _Bool execute_once)
ExecutorRun(QueryDesc * queryDesc, ScanDirection direction, uint64 count, _Bool execute_once)
PortalRunSelect(Portal portal, _Bool forward, long count, DestReceiver * dest)
PortalRun(Portal portal, long count, _Bool isTopLevel, _Bool run_once, DestReceiver * dest, DestReceiver * altdest, QueryCompletion * qc)
exec_simple_query(const char * query_string)
PostgresMain(const char * dbname, const char * username)
BackendRun(Port * port)
BackendStartup(Port * port)
ServerLoop()
PostmasterMain(int argc, char ** argv)
main(int argc, char ** argv)
如上的SQL 返回值是record oid => '2249',此刻的tupdesc 如下:
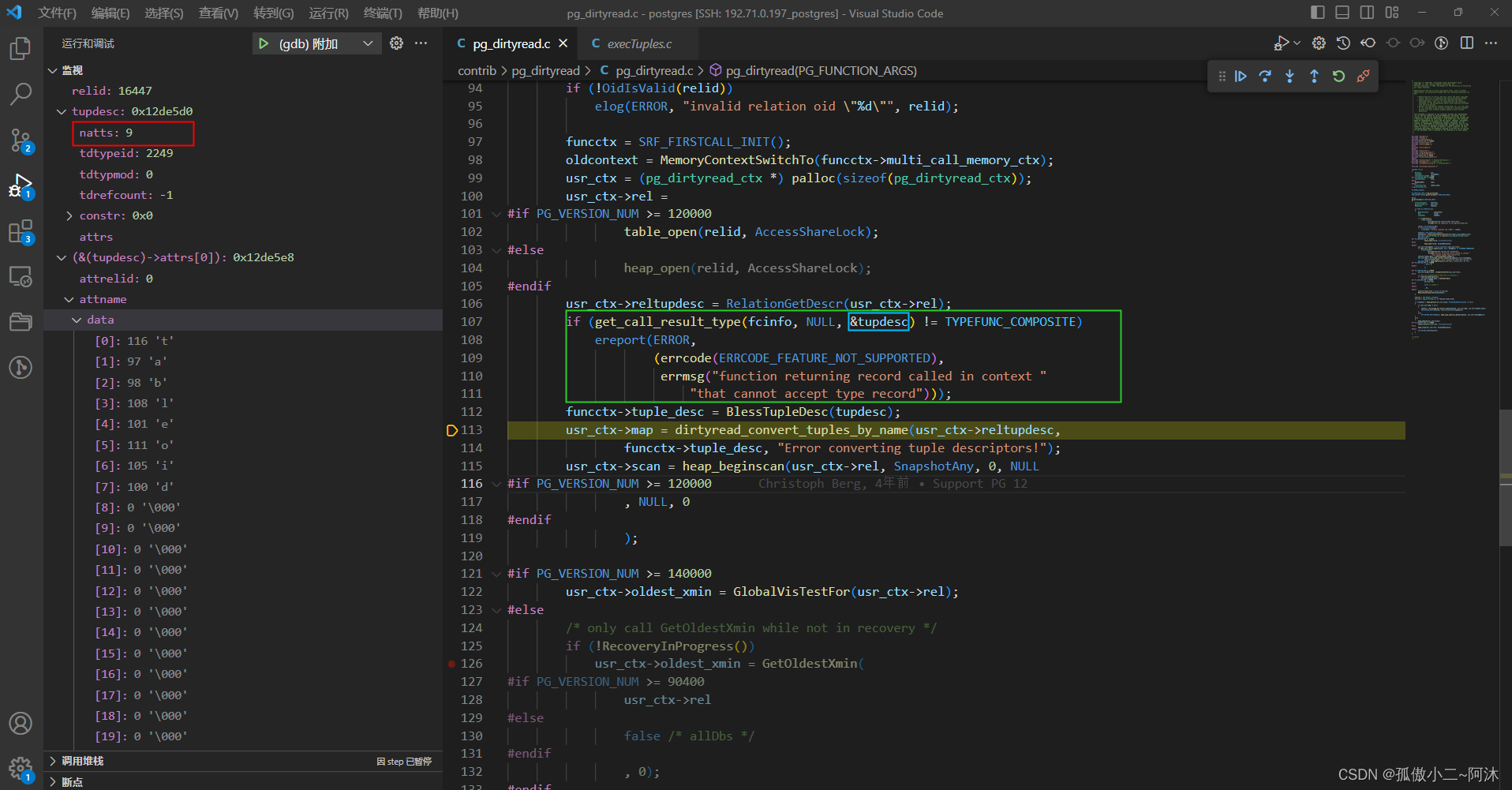
接下来看一下今天的第一个重点,dirtyread_convert_tuples_by_name函数:
// contrib/pg_dirtyread/dirtyread_tupconvert.c/** The conversion setup routines have the following common API:* 转换设置例程具有以下通用 API:** The setup routine checks whether the given source and destination tuple* descriptors are logically compatible. If not, it throws an error.* If so, it returns NULL if they are physically compatible (ie, no conversion* is needed), else a TupleConversionMap that can be used by do_convert_tuple* to perform the conversion.* 设置例程检查给定的源和目标元组描述符在逻辑上是否兼容* 如果不是,它会抛出一个错误* 如果是这样,如果它们在物理上兼容(即不需要转换),则返回 NULL,否则返回 do_convert_tuple 可以用来执行转换的 TupleConversionMap** The TupleConversionMap, if needed, is palloc'd in the caller's memory* context. Also, the given tuple descriptors are referenced by the map,* so they must survive as long as the map is needed.* 如果需要,TupleConversionMap 会在调用者的内存上下文中被分配* 此外,给定的元组描述符由map引用,因此只要需要map,它们就必须存在** The caller must supply a suitable primary error message to be used if* a compatibility error is thrown. Recommended coding practice is to use* gettext_noop() on this string, so that it is translatable but won't* actually be translated unless the error gets thrown.* 如果抛出兼容性错误,调用者必须提供要使用的合适的主要错误消息* 推荐的编码做法是在此字符串上使用 gettext_noop() ,这样它是可翻译的,但除非抛出错误,否则实际上不会被翻译*** Implementation notes:* 实施说明:** The key component of a TupleConversionMap is an attrMap[] array with* one entry per output column. This entry contains the 1-based index of* the corresponding input column, or zero to force a NULL value (for* a dropped output column). The TupleConversionMap also contains workspace* arrays.* TupleConversionMap 的关键组件是一个 attrMap[] 数组,每个输出列有一个条目* 此条目包含相应输入列的从 1 开始的索引,或零以强制 NULL 值(对于删除的输出列)* TupleConversionMap 还包含工作区数组*//** Set up for tuple conversion, matching input and output columns by name.* (Dropped columns are ignored in both input and output.) This is intended* for use when the rowtypes are related by inheritance, so we expect an exact* match of both type and typmod. The error messages will be a bit unhelpful* unless both rowtypes are named composite types.* 设置元组转换,按名称匹配输入和输出列* (丢弃的列在输入和输出中都被忽略。)* 这是为了在行类型通过继承相关时使用,所以我们期望类型和 typmod 完全匹配* 除非两个行类型都命名为复合类型,否则错误消息将有点无用*/
TupleConversionMap *
dirtyread_convert_tuples_by_name(TupleDesc indesc,TupleDesc outdesc,const char *msg)
{.../* Verify compatibility and prepare attribute-number map *//* 验证兼容性并准备属性编号映射 */attrMap = dirtyread_convert_tuples_by_name_map(indesc, outdesc, msg);...
}
此时说明一下:
/*
indesc: 该表的列 在这里 为2列(即使第二列被删掉了,注意 attisdropped 属性)outdesc: 我们这里要输入的 record 对应 (这里自然就是 7个系统列 + 2个用户的列)msg: "Error converting tuple descriptors!"
*/
接下来先看一下dirtyread_convert_tuples_by_name_map函数:
// contrib/pg_dirtyread/dirtyread_tupconvert.cstatic const struct system_columns_t {char *attname;Oid atttypid;int32 atttypmod;int attnum;
} system_columns[] = {{ "ctid", TIDOID, -1, SelfItemPointerAttributeNumber },
#if PG_VERSION_NUM < 120000{ "oid", OIDOID, -1, ObjectIdAttributeNumber },
#endif{ "xmin", XIDOID, -1, MinTransactionIdAttributeNumber },{ "cmin", CIDOID, -1, MinCommandIdAttributeNumber },{ "xmax", XIDOID, -1, MaxTransactionIdAttributeNumber },{ "cmax", CIDOID, -1, MaxCommandIdAttributeNumber },{ "tableoid", OIDOID, -1, TableOidAttributeNumber },{ "dead", BOOLOID, -1, DeadFakeAttributeNumber }, /* fake column to return HeapTupleIsSurelyDead */{ 0 },
};/** Return a palloc'd bare attribute map for tuple conversion, matching input* and output columns by name. (Dropped columns are ignored in both input and* output.) This is normally a subroutine for convert_tuples_by_name, but can* be used standalone.* 返回用于元组转换的 palloc 裸属性映射,按名称匹配输入和输出列* (丢弃的列在输入和输出中都被忽略。)* 这通常是 convert_tuples_by_name 的子例程,但可以单独使用** This version from dirtyread_tupconvert.c adds the ability to retrieve dropped* columns by requesting "dropped_N" as output column, where N is the attnum.* 这个来自 dirtyread_tupconvert.c 的版本增加了通过请求“dropped_N”作为输出列来检索删除的列的能力,其中 N 是 attnum*/
AttrNumber *
dirtyread_convert_tuples_by_name_map(TupleDesc indesc,TupleDesc outdesc,const char *msg)
{...// 这个遍历 outdescfor (i = 0; i < n; i++){...// 这个遍历 indescfor (j = 0; j < indesc->natts; j++){...}.../* Check dropped columns */if (attrMap[i] == 0)if (strncmp(attname, "dropped_", sizeof("dropped_") - 1) == 0){...}.../* Check system columns */if (attrMap[i] == 0)for (j = 0; system_columns[j].attname; j++)if (strcmp(attname, system_columns[j].attname) == 0){...}...}...
}
这里我们把indesc和outdesc的关键属性(重要的)列举,如下:
| attrelid | attname | atttypid | attlen | attnum | attisdropped |
|---|---|---|---|---|---|
| 16447 | bar | 20 | 8 | 1 | f |
| 同上 | 空 | 0 | -1 | 2 | t |
| attrelid | attname | atttypid | attlen | attnum | attisdropped |
|---|---|---|---|---|---|
| 0 | tableoid | 26 | 4 | 1 | f |
| 0 | ctid | 27 | 6 | 2 | f |
| 0 | xmin | 28 | 4 | 3 | f |
| 0 | xmax | 28 | 4 | 4 | f |
| 0 | cmin | 29 | 4 | 5 | f |
| 0 | cmax | 29 | 4 | 6 | f |
| 0 | dead | 16 | 1 | 7 | f |
| 0 | bar | 20 | 8 | 8 | f |
| 0 | dropped_2 | 25 | -1 | 9 | f |
解释一下上面这9个输出列,其匹配如下:
// contrib/pg_dirtyread/dirtyread_tupconvert.h
// FirstLowInvalidHeapAttributeNumber -7
#define DeadFakeAttributeNumber FirstLowInvalidHeapAttributeNumber/*检查系统列 attrMap[0] = system_columns[5].attnum; -6 就是 TableOidAttributeNumber
检查系统列 attrMap[1] = system_columns[0].attnum; -1 就是 SelfItemPointerAttributeNumber
检查系统列 attrMap[2] = system_columns[1].attnum; -2 就是 MinTransactionIdAttributeNumber
检查系统列 attrMap[3] = system_columns[3].attnum; -4 就是 MaxTransactionIdAttributeNumber
检查系统列 attrMap[4] = system_columns[2].attnum; -3 就是 MinCommandIdAttributeNumber
检查系统列 attrMap[5] = system_columns[4].attnum; -5 就是 MaxCommandIdAttributeNumber
检查系统列 attrMap[6] = system_columns[6].attnum; -7 就是 DeadFakeAttributeNumber检查表的列 attrMap[7] = (AttrNumber) (0 + 1); 1 就是 bar 列检查删除列 attrMap[8] = (AttrNumber) 2; 2就是 原 baz 列
*/
经过函数dirtyread_convert_tuples_by_name_map之后的attrMap就是上面的内容!之后函数dirtyread_convert_tuples_by_name也就结束了!
继续 如下:
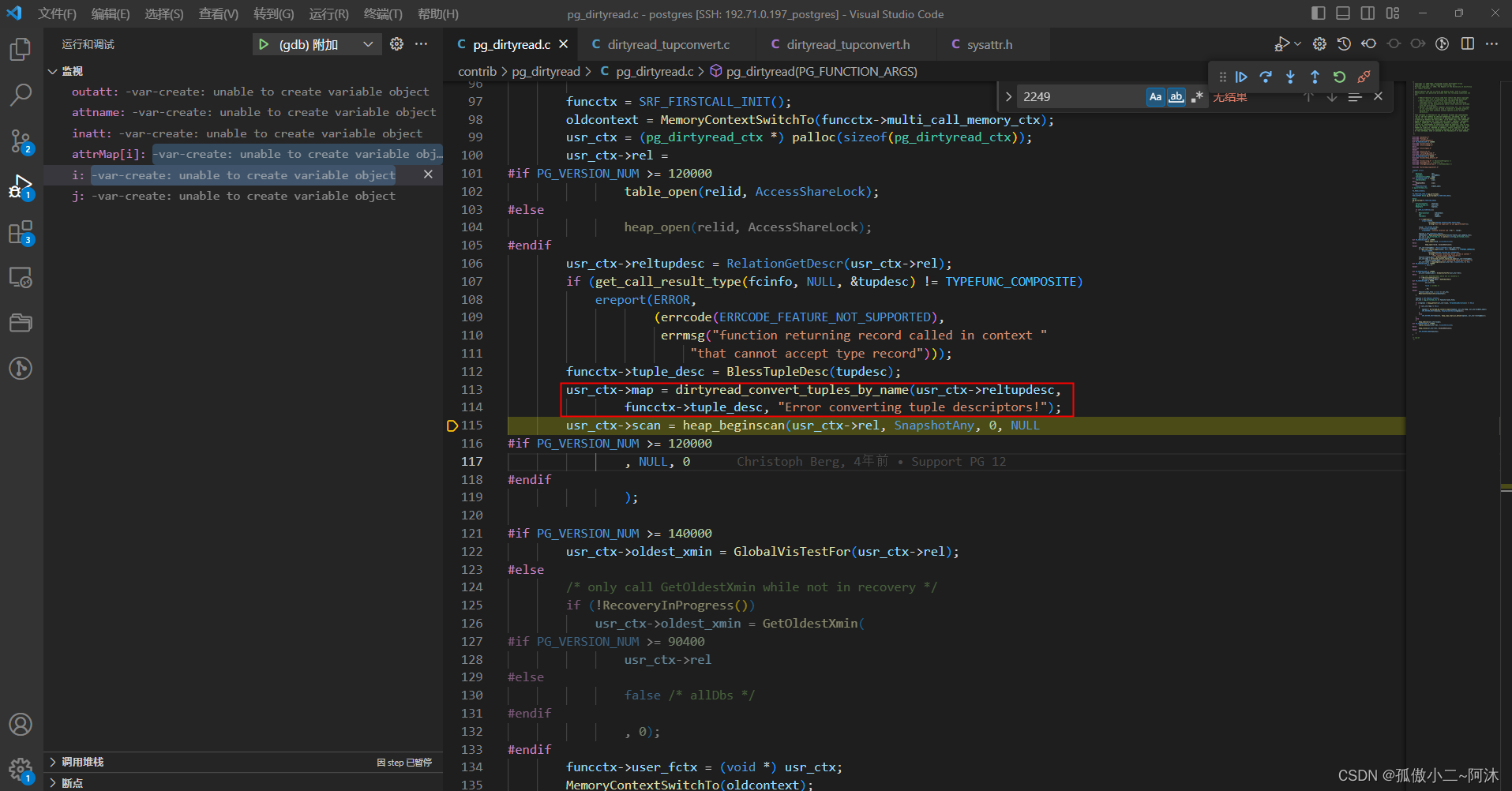
如上图所示:接下来就是遍历这个表 heap_beginscan,以ForwardScanDirection的方式获取全部元组,如下:
// contrib/pg_dirtyread/pg_dirtyread.c...if ((tuplein = heap_getnext(usr_ctx->scan, ForwardScanDirection)) != NULL){if (usr_ctx->map != NULL){tuplein = dirtyread_do_convert_tuple(tuplein, usr_ctx->map, usr_ctx->oldest_xmin);SRF_RETURN_NEXT(funcctx, HeapTupleGetDatum(tuplein));}elseSRF_RETURN_NEXT(funcctx, heap_copy_tuple_as_datum(tuplein, usr_ctx->reltupdesc));}else{heap_endscan(usr_ctx->scan);
#if PG_VERSION_NUM >= 120000table_close(usr_ctx->rel, AccessShareLock);
#elseheap_close(usr_ctx->rel, AccessShareLock);
#endifSRF_RETURN_DONE(funcctx);}
}
接下来 我们再介绍一下 第二个重点 dirtyread_do_convert_tuple函数,如下:
// contrib/pg_dirtyread/dirtyread_tupconvert.c/** Perform conversion of a tuple according to the map.* 根据映射执行元组的转换*/
HeapTuple
dirtyread_do_convert_tuple(HeapTuple tuple, TupleConversionMap *map, OldestXminType oldest_xmin)
{AttrNumber *attrMap =
#if PG_VERSION_NUM >= 130000map->attrMap->attnums;
#elsemap->attrMap;
#endifDatum *invalues = map->invalues;bool *inisnull = map->inisnull;Datum *outvalues = map->outvalues;bool *outisnull = map->outisnull;int outnatts = map->outdesc->natts;int i;/** Extract all the values of the old tuple, offsetting the arrays so that* invalues[0] is left NULL and invalues[1] is the first source attribute;* this exactly matches the numbering convention in attrMap.* * 提取旧元组的所有值,偏移数组,使 invalues[0] 为 NULL,invalues[1] 为第一个源属性* 这完全符合 attrMap 中的编号约定*/heap_deform_tuple(tuple, map->indesc, invalues + 1, inisnull + 1);/** Transpose into proper fields of the new tuple.* 转置到新元组的适当字段中*/for (i = 0; i < outnatts; i++){int j = attrMap[i];if (j == DeadFakeAttributeNumber){outvalues[i] = HeapTupleIsSurelyDead(tuple
#if PG_VERSION_NUM < 90400->t_data
#endif, oldest_xmin);outisnull[i] = false;}else if (j < 0)outvalues[i] = heap_getsysattr(tuple, j, map->indesc, &outisnull[i]);else{outvalues[i] = invalues[j];outisnull[i] = inisnull[j];}}/** Now form the new tuple.*/return heap_form_tuple(map->outdesc, outvalues, outisnull);
}
其他的不再详解,我们这里主要看一下 最下面的那个 for 循环,如下:
- 如果是 dead 则其值为
HeapTupleIsSurelyDead函数的返回值 - 为系统列 其值获取使用
heap_getsysattr - 表的普通列 使用
invalues[j]方式
最后通过函数heap_form_tuple来构造这个(要返回的)元组:
/** Now form the new tuple.*/return heap_form_tuple(map->outdesc, outvalues, outisnull);
如上是函数第一次调用(第一行的构造逻辑),轮到第二次 此时的函数堆栈调用如下(同上):
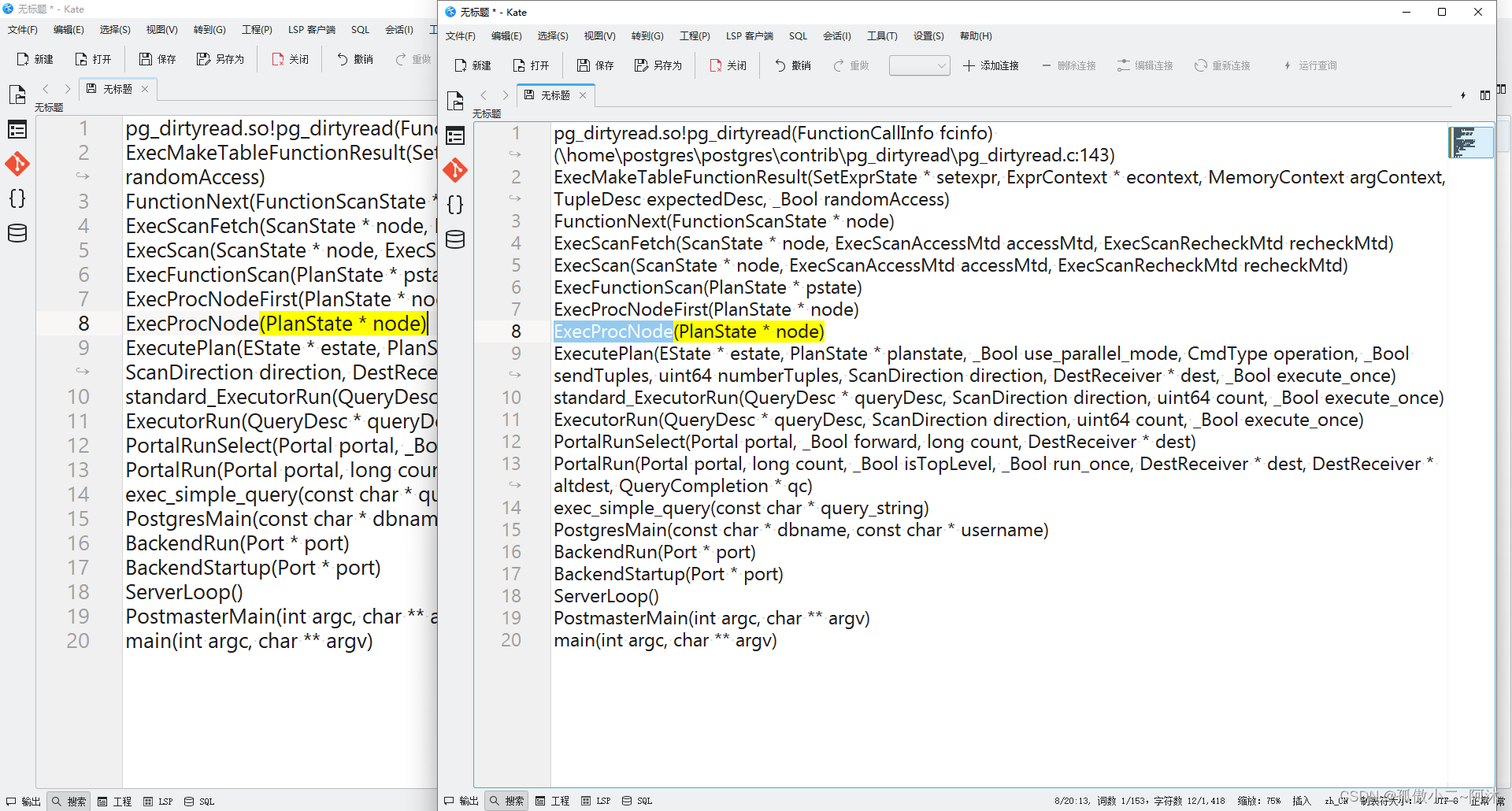
第二行元组 构造 省略!表遍历结束,再无元组 pg_dirtyread函数执行完成!
postgres=# SELECT * FROM pg_dirtyread('foo') AS t(tableoid oid, ctid tid, xmin xid, xmax xid, cmin cid, cmax cid, dead boolean,bar bigint, dropped_2 text);tableoid | ctid | xmin | xmax | cmin | cmax | dead | bar | dropped_2
----------+-------+------+------+------+------+------+-----+-----------16447 | (0,1) | 754 | 755 | 0 | 0 | t | 1 | Test16447 | (0,2) | 754 | 0 | 0 | 0 | f | 2 | New Test
(2 rows)postgres=#
功能实现细节说明
接下来,我们详细看一下几个细节,如下:
细节一:判断dead返回值的函数HeapTupleIsSurelyDead,如下:
// src/backend/access/heap/heapam_visibility.c/** HeapTupleIsSurelyDead** Cheaply determine whether a tuple is surely dead to all onlookers.* We sometimes use this in lieu of HeapTupleSatisfiesVacuum when the* tuple has just been tested by another visibility routine (usually* HeapTupleSatisfiesMVCC) and, therefore, any hint bits that can be set* should already be set. We assume that if no hint bits are set, the xmin* or xmax transaction is still running. This is therefore faster than* HeapTupleSatisfiesVacuum, because we consult neither procarray nor CLOG.* It's okay to return false when in doubt, but we must return true only* if the tuple is removable.* * 廉价地确定一个元组是否对所有旁观者来说肯定是死的* 当元组刚刚被另一个可见性例程(通常是 HeapTupleSatisfiesMVCC)测试时,* 我们有时会使用它代替 HeapTupleSatisfiesVacuum,因此,应该已经设置了可以设置的任何提示位* * 我们假设如果没有设置提示位,则 xmin 或 xmax 事务仍在运行* 因此,这比 HeapTupleSatisfiesVacuum 更快,因为我们既不查询 procarray 也不查询 CLOG* 有疑问时返回 false 是可以的,但只有当元组可移动时我们才必须返回 true*/
bool
HeapTupleIsSurelyDead(HeapTuple htup, GlobalVisState *vistest);
两个参数:
/*
htup: 当前判断的 元组vistest:如下
*/

其值的获取来源,如下:
// src/backend/storage/ipc/procarray.c/** If rel != NULL, return test state appropriate for relation, otherwise* return state usable for all relations. The latter may consider XIDs as* not-yet-visible-to-everyone that a state for a specific relation would* already consider visible-to-everyone.* 如果 rel != NULL,则返回适用于关系的测试状态,否则返回可用于所有关系的状态* 后者可能将 XID 视为尚未对所有人可见,而特定关系的状态已将其视为对所有人可见** This needs to be called while a snapshot is active or registered, otherwise* there are wraparound and other dangers.* 这需要在快照处于活动状态或已注册时调用,否则会有环绕和其他危险** See comment for GlobalVisState for details.*/
GlobalVisState *
GlobalVisTestFor(Relation rel)
{GlobalVisState *state = NULL;/* XXX: we should assert that a snapshot is pushed or registered */Assert(RecentXmin);switch (GlobalVisHorizonKindForRel(rel)){case VISHORIZON_SHARED:state = &GlobalVisSharedRels;break;case VISHORIZON_CATALOG:state = &GlobalVisCatalogRels;break;case VISHORIZON_DATA:state = &GlobalVisDataRels;break;case VISHORIZON_TEMP:state = &GlobalVisTempRels;break;}Assert(FullTransactionIdIsValid(state->definitely_needed) &&FullTransactionIdIsValid(state->maybe_needed));return state;
}
我们继续看一下:
postgres=# SELECT * FROM pg_dirtyread('foo') AS t(tableoid oid, ctid tid, xmin xid, xmax xid, cmin cid, cmax cid, dead boolean,bar bigint, dropped_2 text);tableoid | ctid | xmin | xmax | cmin | cmax | dead | bar | dropped_2
----------+-------+------+------+------+------+------+-----+-----------16447 | (0,1) | 754 | 755 | 0 | 0 | t | 1 | Test16447 | (0,2) | 754 | 0 | 0 | 0 | f | 2 | New Test
(2 rows)postgres=# select txid_status(754);txid_status
-------------committed
(1 row)postgres=# select txid_status(755);txid_status
-------------committed
(1 row)postgres=# SELECT txid_current ();txid_current
--------------757
(1 row)postgres=#
事务754插入这两行数据,事务755删除第一行(这两个事务都已提交)。关于元组可见性的内容 不在详解,有兴趣的小伙伴可以看一下本人之前的博客:
- PostgreSQL的学习心得和知识总结(四十九)|深入理解PostgreSQL数据库行可见性判断机制基础,点击前往
相关文章:
PostgreSQL的学习心得和知识总结(一百二十三)|深入理解PostgreSQL数据库开源扩展pg_dirtyread的使用场景和实现原理
目录结构 注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下: 1、参考书籍:《PostgreSQL数据库内核分析》 2、参考书籍:《数据库事务处理的艺术:事务管理与并发控制》 3、PostgreSQL数据库仓库…...
ubuntu清理挖矿病毒
0 序言 我之前搭建的hadoop用于测试,直接使用了8088和9870端口,没有放入docker,从而没有端口映射。于是,就被不法之徒盯上了,hadoop被提交了很多job,使得系统被感染了挖矿病毒,在前几天阿里云站…...

【代码随想录训练营】【Day16】第六章|二叉树|104.二叉树的最大深度|559.n叉树的最大深度|111.二叉树的最小深度|222.完全二叉树的节点个数
二叉树的最大深度 题目详细:LeetCode.104 递归法很容易理解: 定义一个全局变量max, 记录二叉树的最大深度在递归函数中增加一个深度参数,表示当前的节点的深度然后对二叉树进行深度优先遍历当遍历到叶子节点时,比较…...
transformer总结
1.注意力机制 意义:人类的注意力机制极大提高了信息处理的效率和准确性。 公式: 1)自注意力机制 b都是在考虑了所有a的情况下生成的。 以产生b1向量为例: 1.在a这个序列中,找到与a1相关的其他向量 2.每个向量与a1关联的程度&a…...

dart flutter入门教程,开发手册 分享
我最近在学校dart flutter.这是我收集的一些手册和教程. 不需要关注公众号,不需要加好友. 我发现flutter(dart)的中文资料比较奇缺.入门的教程非常多.但是api手册几乎没有(全是英文的). 收集原则 1.中文(我英文不好) 2.不要pdf的,网上有一些pdf的 从入门到进阶的,但是太长…...

教育舆情监测关键词有哪些,TOOM教育舆情监测系统流程?
教育舆情监测是指对教育领域的舆情进行收集、分析和处理的过程。舆情是指公众在各种渠道上对教育政策、教育机构、教育事件等方面的言论、态度和情绪。通过对教育舆情的监测和分析,可以了解公众对教育行业的看法和反应,提高对教育行业的管控能力…...
MySQL高级(一)
MySQL-day01 1 MySQL简介 1.1 MySQL简介 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB(创始人Michael Widenius)公司开发,2008被Sun收购(10亿美金),2009年Sun被Oracle收购。MariaDBMaria…...
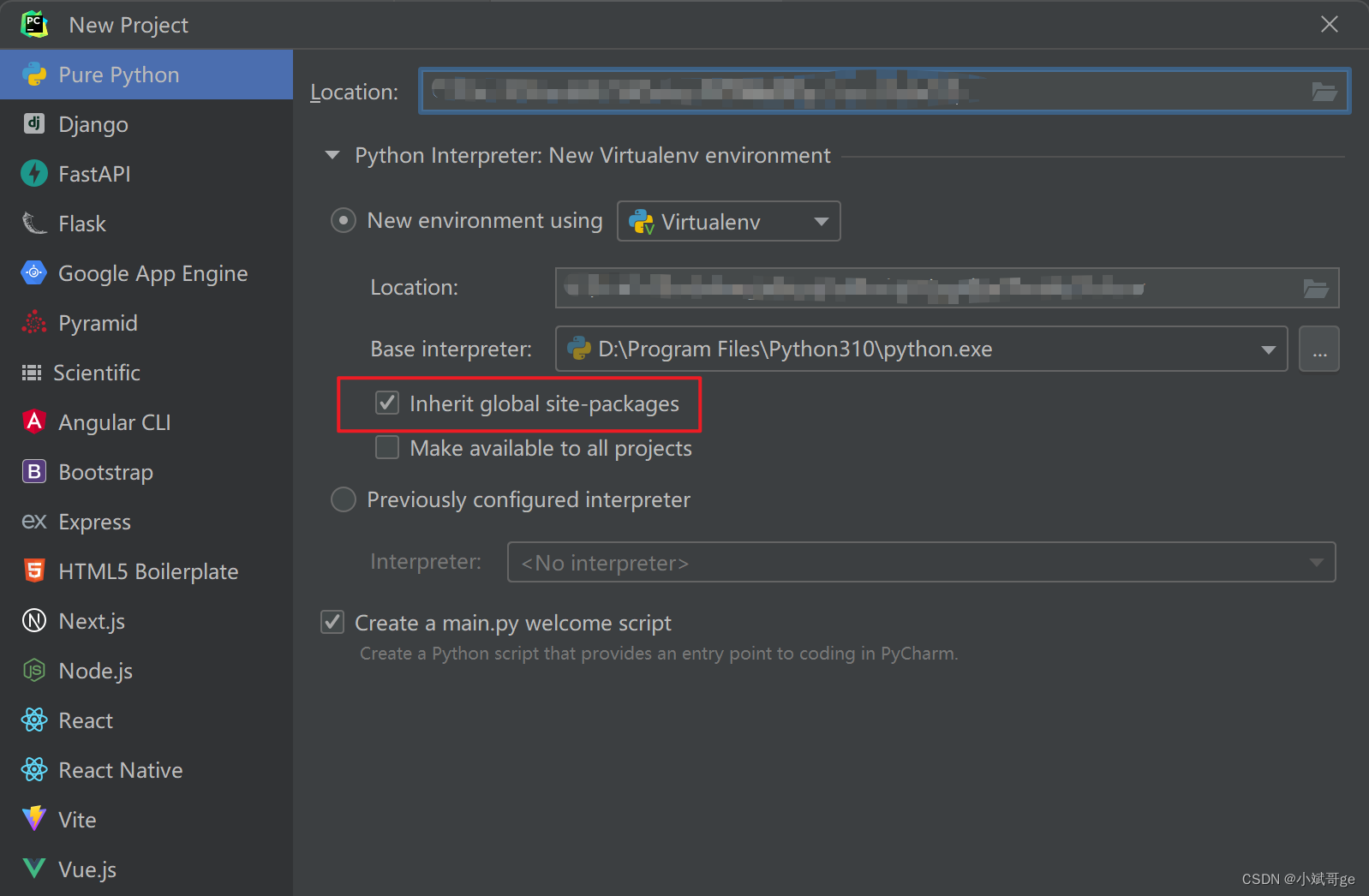
如何将Python项目部署到新电脑上运行?
如何将Python项目部署到新电脑上运行? 在工作中,可能需要在新服务器上部署项目代码,例如新增服务器、把测试环境的代码部署到生产环境等。 在生活中,也会遇到换新电脑,需要将自己在旧电脑上写的(项目&…...
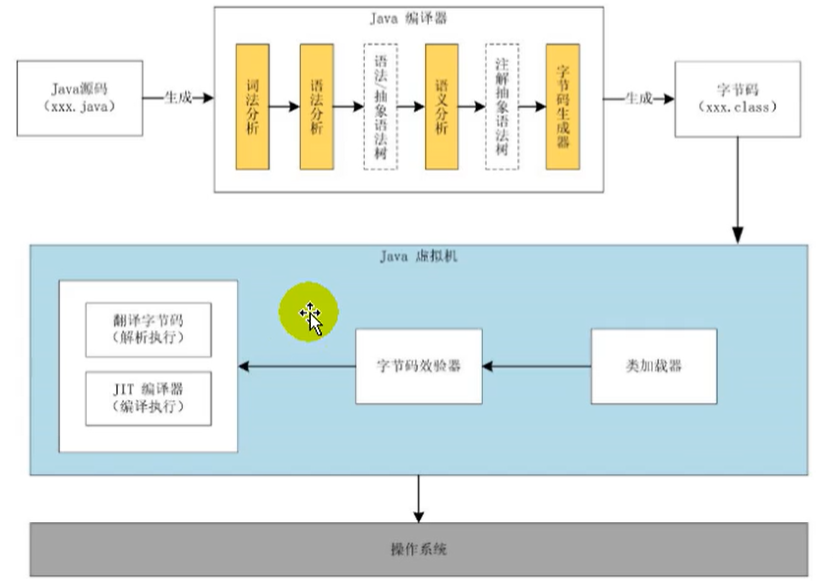
JVM和JAVA体系结构
1、为什么要学习JVM作为Java工程师的你曾被伤害过吗?你是否也遇到过这些问题?运行着的线上系统突然卡死,系统无法访问,甚至直接OOM想解决线上JVM GC问题,但却无从下手新项目上线,对各种JVM参数设置一脸茫然…...
(十)、通过云对象修改阅读量+点赞功能的实现【uniapp+uinicloud多用户社区博客实战项目(完整开发文档-从零到完整项目)】
1,通过云对象importObj修改阅读量 1.1 新建云对象 1.2 云对象中写自增自减方法 封装云对象utilsObj中的自增自减方法,方法名取为operation,传递4个参数。 // 云对象教程: https://uniapp.dcloud.net.cn/uniCloud/cloud-obj // jsdoc语法提…...
)
刷力扣的第一天脑子要长出来的感觉(怎么有人大四才开始啊啊啊啊啊啊啊啊啊啊啊啊,又是等成绩的一天,)
刷力扣的第一天脑子要长出来的感觉(为什么大四才开始啊啊啊啊啊啊啊啊啊啊啊啊) emmm,自己还是想不太出来(只是一点想法),可能还是会参考评论区,求各位轻喷 分析:带符号一定不是回…...
Nuclei文*件上*传FUZZ POC
目录 1.前言 2. Nuclei文件上传FUZZ POC 3. 实战中的应用 1.前言 该文件上传FUZZ POC主要来源于一个靶*场,该POC 主要用来FUZZ目标js页面中的upload ajax请求,以此来进一步尝试文件上传漏*洞利*用。 这里也要感谢下“打工仔1号”提供的开*发人员常见的文*件上*传javaScr…...

完美解决方案-雪花算法ID到前端之后精度丢失问题
最近公司的一个项目组要把以前的单体应用进行为服务拆分,表的ID主键使用Mybatis plus默认 的雪花算法来生成。 快下班的时候,小伙伴跑过来找我,:“快给我看看这问题,卡这卡了小半天了!”。连拉带拽&#x…...

工程管理系统源码之高效的工程项目管理软件
高效的工程项目管理软件不仅能够提高效率还应可以帮你节省成本提升利润 在工程行业中,管理不畅以及不良的项目执行,往往会导致项目延期、成本上升、回款拖后,最终导致项目整体盈利下降。企企管理云业财一体化的项目管理系统,确保…...

390. 消除游戏
列表 arr 由在范围 [1, n] 中的所有整数组成,并按严格递增排序。请你对 arr 应用下述算法:从左到右,删除第一个数字,然后每隔一个数字删除一个,直到到达列表末尾。重复上面的步骤,但这次是从右到左。也就是…...

springBoot JPA代码生成器
介绍通过IDEA配置文件,根据数据库表结构快速生产Service、ServiceImpl、repository、repositoryImpl、自动生成常用的jpa增删改查等方法。使用的版本Spring Boot2.1.6.RELEASE spring-boot-starter-data-jpa使用idea 生成代码步骤打开idea(https://images.gitee.co…...

相同月利率条件下不同还款方式贷款的APR与IRR研究
文章目录前提假设一次性还本付息先息后本等额本息等额本金简单二分法求解IRR的程序汇总实验对比前提假设 因为常见的信贷产品还款期数定义都是按照月,假设只借一期的利率(月利率)为r,在此条件下,研究不同还款方式下的…...

【论文】智能隧道检测车的现状及改进策略
本文转载自《智慧城轨》2022年第11期 作者:黄丹樱1,韦强1,朱椰毅2,范骁1,林浩立1 单位:1 浙江师范大学工学院;2 浙江金温铁道开发有限公司 声明:本文仅用于学术分享,不做商业用途,如有侵权,联…...

【代码随想录二刷】Day16-二叉树-C++
代码随想录二刷Day16 每日任务 104.二叉树的最大深度 559.n叉树的最大深度 111.二叉树的最小深度 222.完全二叉树的节点个数 语言:C 104. 二叉树的最大深度 链接:https://leetcode.cn/problems/maximum-depth-of-binary-tree/ 递归法(前序…...

Lecture5 实现线性回归(Linear Regression with PyTorch)
目录 1 Pytorch实现线性回归 1.1 实现思路 1.2 完整代码 2 各部分代码逐行详解 2.1 准备数据集 2.2 设计模型 2.2.1 代码 2.2.2 代码逐行详解 2.2.3 疑难点解答 2.3 构建损失函数和优化器 2.4 训练周期 2.5 测试结果 3 线性回归中常用优化器 1 Pytorch实现线性回归…...

无根仪式:当AI时代的时间加速膨胀
我给我的AI代理编程,让它在每晚我睡觉时执行研究任务。并非因为它实用。我只是不想浪费我的token。而且,这么做感觉是对的。 周六早上,它带回了一份关于“声音主权”的报告——这个理念是,每一个曾经凝聚在一起的社群,…...

在OpenClaw争议中,除了技术层面的抓取,是否存在文化层面上拿来主义与贡献者文化的深层冲突?
开源世界最近有个讨论挺有意思,说的是如果国内大厂都像腾讯那样,给一些主流开源项目搞个自己的“本地优化版镜像”,长远下去会怎么样。不少人担心,这么一来,开源项目本身的“原创性”和“全球统一性”会不会慢慢被瓦解…...

2026年最全Java面试题,及答案汇总!
适宜阅读人群 需要面试的初/中/高级 java 程序员想要查漏补缺的人想要不断完善和扩充自己 java 技术栈的人java 面试官 具体面试题 下面一起来看 208 道面试题,具体的内容。 一、Java 基础 1.JDK 和 JRE 有什么区别? 2. 和 equals 的区别是什么&am…...

解锁论文写作新境界:书匠策AI,你的期刊论文智能导航员
在学术的浩瀚海洋中,每一位研究者都像是勇敢的航海家,而期刊论文则是他们探索未知、分享发现的重要航标。然而,撰写一篇高质量的期刊论文并非易事,它要求研究者不仅具备深厚的专业知识,还需掌握一定的写作技巧与规范。…...

快速体验AI写春联:春联生成模型-中文-base镜像一键启动指南
快速体验AI写春联:春联生成模型-中文-base镜像一键启动指南 春节临近,家家户户都开始张罗着贴春联。一副好春联,既要对仗工整、平仄协调,又要寓意吉祥、文采斐然。自己创作吧,总觉得词穷;上网找吧…...

使用MATLAB进行SUNFLOWER MATCH LAB模型输出结果的可视化分析
使用MATLAB进行SUNFLOWER MATCH LAB模型输出结果的可视化分析 对于很多科研工作者和数据分析师来说,MATLAB是一个再熟悉不过的老朋友了。它强大的矩阵运算能力和丰富的可视化工具箱,让数据分析和结果呈现变得得心应手。然而,当我们使用像SUN…...

2026-03-15 GitHub 热点项目精选
🌟 2026-03-15 GitHub Python 热点项目精选(14个) 每日同步 GitHub Trending 趋势,筛选优质 Python 项目,助力开发者快速把握技术风向标~ 📋 项目列表(按 Star 数排序) 1. volcengine/OpenViki…...

3分钟上手!AI驱动的视频背景智能替换工具
3分钟上手!AI驱动的视频背景智能替换工具 【免费下载链接】MatAnyone MatAnyone: Stable Video Matting with Consistent Memory Propagation 项目地址: https://gitcode.com/gh_mirrors/ma/MatAnyone 在当今内容创作领域,视频抠图已成为不可或缺…...

NLP-StructBERT与图数据库Neo4j结合:构建知识图谱语义检索系统
NLP-StructBERT与图数据库Neo4j结合:构建知识图谱语义检索系统 想象一下,你面对一个庞大的知识库,里面有成千上万的实体和它们之间错综复杂的关系。你想问:“苹果公司的创始人是谁?”或者“治疗高血压的常用药物有哪些…...

【泛微系统】知识管理-查询文档页面默认显示全部文档
E9查阅文档默认显示:我的收藏改成默认全部目录: 解决方案: 注:0-全部目录;1-我的收藏 ecology/WEB-INF/prop/doc_full_search.properties属性文件里的参数配置为default_treenode0...