DBA之路---Stream数据共享同步机制与配置方法
oracle的Stream解析–数据共享
在g版本常用,如果是c版本项目一般都会选择goldengate,比stream靠谱多了
Oracle中的stream是消息队列一种应用形式,原理如下:
收集oracle中的事件,将事件保存在队列里,然后将事件发布给不同的订阅者。从管理员角度就是,捕获oracle的redo日志,然后将其通过网络传递到其他数据库来进行一种复制变化,进而完成库级数据同步。 主要目的为数据共享,不是灾容备份
#stream的实现方式#采取guard的logical standy标准,但是在进行日志恢复阶段时不会将redo记录还原成sql语句,而是还原成LCR进行发送,然后再target端再执行LCR语句。可以保证数据的完整性。#限制#因为不是标准的logcial standy进行还原发送,所以需要在两端分别查看stream是否支持将要发送的数据类型select * from dba_streams_newly_supported; #或者all开头select * from dba_streams_unsupported; #所有者,表名,不支持的原因#Stream环境下进行数据同步,分为启动数据库 source database与终点数据库Target Database.在两恶搞数据库上各自创建队列,source作为发送端,target作为接收端
#队列创建后source端发起CP捕获进程,使用logminer从日志中提取ddl dml语句创建并存储与逻辑变记录(LCR)。source会将LCR内同保存到本地发送队列中,最后由pp传播进程发送到Target端
streams使用前的注意点
- 确定复制集等级(共三种复制等级,表级、用户级、库级。用户最麻烦)
- 决定复制站点
- LCR的捕获方式
- 本地捕获 : 从source进行,在联机日志与归档日志中取得LCR
- **下游捕获 ** : 在target进行,尽在归档日志中获取LCR
- 决定拓扑复制结构
stream数据共享创建实操—(用户级复制)
由于数据共享需要分成主库与从库,所以本次创建测试环境,本地不同global_name相同版本的11g数据库两套,实例名称主库prince,从库prince2(安装时设置),使用两个端口两套监听。假定使用同步的是tbbb用户。
下面是最重要的先看好了
#装配错误处理--消除本次配置所有信息(不知道配到哪里?出现了错误?不小心敲错?我允许你从头开始)#主从执行(需要先取消掉已经创建的进程 捕获、传播和应用进程至少不是enabled状态)exec DBMS_STREAMS_ADM.remove_streams_configuration();
(不要本地装两套数据库去设置实验环境,笔者一开始就是这样老是失败出现各种问,最后弄个虚拟机有条件干脆再弄个电脑,无痛安装,我下面就不改流程纯粹图省事)
#操作前注意事项,两端都要进行检查。sys用户进行,主从共用操作#1、启用oracle需要先确保两端安装logminer与开启归档日志#具体操作方式请参照其余文章,此处不再赘述#2、两端数据库参数确认与修改alter system set global_names=true scope = both; #global_name置为有效,可以先show parameter,确认下alter system set aq_tm_processes=2 scope=both;#本参数非必须,oracle默认一般就够,可以确认下#以下为检查参数,需要show parameteralter system set job_queue_processes = 10 scope=both;alter system set sga_target = 300m scope=spfile;alter system set open_links=4 scope=spfile;alter system set statistics_level='TYPICAL' scope=both #务必确认,处于性能统计模式#以下为logminer确认参数alter system set "_job_queue_interval"=1 scope=spfile; #确认提高检查队列所需检查时间alter system set aq_tm_processes=1;alter system set streams_pool_size=200m scope=both;#此参数一定要足够大,防止内存过小使stream信息没有数据即时被同步。#启用追加日志,如果数据库表段有主键就不被需要(logminer时已经开启。可以show检查一下)alter database add supplemental log data#只是同步部分表的表级同步可以进行追加alter table add supplement log group log_group_name(table_column_name) always;#3、预备条件#创建两个专门用于stream管理表空间和用户给予权限,在两个不同的主从库上分别进行#主库CREATE TABLESPACE streams_tbs DATAFILE 'E:/ORACLE/prince/streams_tbs001.dbf' SIZE 100M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED; create user streamadmin1 identified by streamadmin1 DEFAULT TABLESPACE streams_tbsGRANT DBA to streamadmin1;#dba权限exec DBMS_STREAMS_AUTH.GRANT_ADMIN_PRIVILEGE('streamadmin1') #赋予stream管理权限#从库CREATE TABLESPACE streams_tbs DATAFILE 'E:/ORACLE/prince2/streams_tbs001.dbf' SIZE 100M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED; create user streamadmin2 identified by streamadmin2 DEFAULT TABLESPACE streams_tbsGRANT DBA to streamadmin2;#dba权限exec DBMS_STREAMS_AUTH.GRANT_ADMIN_PRIVILEGE('streamadmin2') #赋予stream管理权限#在这两个数据库prince和prince2的tnsname.ora分别加上对端的链接实例名称,用于后续创建dblink使用prince2 = #假设prince主库使用1523端口,那主库下的tnsname.ora就添加如下配置(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT = 1524))#对端使用的端口与ip,我是本地装了两套所以时localhost)(CONNECT_DATA =(SID = prince2)#连接实例名,对端实例名(SERVER = DEDICATED)#看情况指定))#两端创建测试用户(已经有的就不用了)CREATE USER TBBB IDENTIFIED BY TBBB ;grant dba to tbbb;#这边本次测试没有限制,我直接dba省事
#生产环境的还需要额外将主库用户的数据和结构(主要是结构)导入到从库用户里去,千万注意,我这测试环境都是null用户所以无所谓
exp userid=tbb/tbb@prince file='E:\oracle' object_consistent=y rows=y
imp userid=tbb/tbb@prince2 file='E:\oracle' ignore=y commit=y log='E:\oracle\123.log' streams_instantiation=y fromuser=tbb touser=tbb #不同用户还需要做映射
请按照步骤同步进行创建
#stream创建流程-主库(source端)
#1、创建远程dblink#以之前创建的stream管理员账户登录create database link prince2 connect to streamadmin2 identified by streamadmin2 using 'prince2'; #对端的用户名密码 link指定最好与连接实例名称一致否则容易报错。使用tnsname的prince进行连接。#成功后进行如下方式确认是否成功conn streamadmin2/streamadmin2 #连接到从库select * from global_name#通过global_name确认是否到达从库,无误后exit重新进入主库#2、创建stream队列-主库master流队列
exec DBMS_STREAMS_ADM.SET_UP_QUEUE(queue_table => 'TBBBSOURCE_QUEUE_TABLE', queue_name => 'TBBBSOURCE_QUEUE',queue_user => 'STREAMADMIN1');#检查是否成功创建队列select owner,queue_table,name from dba_queues where owner='STREAMADMIN';#3、主库创建捕获进程
exec dbms_streams_adm.add_schema_rules(schema_name => 'tbbb',streams_type => 'capture',streams_name => 'capture_tbbb',queue_name => 'STREAMADMIN1.TBBBSOURCE_QUEUE',include_dml => true,include_ddl => true,include_tagged_lcr => false,source_database => null,inclusion_rule => true);select CAPTURE_NAME,QUEUE_NAME,START_SCN,STATUS,CAPTURE_TYPE from dba_capture;
select * from ALL_CAPTURE_PREPARED_SCHEMAS; #确认进程是否创建成功exec DBMS_CAPTURE_ADM.START_CAPTURE(capture_name => 'CAPTURE_TBB');select capture_name,status from dba_capture;exec dbms_capture_adm.stop_capture(capture_name => 'CAPTURE_TBB'); #停止进程#4、创建传播进程
exec DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES(schema_name=> 'tbbb', streams_name=> 'capture_tbbb', source_queue_name=> 'STREAMADMIN1.TBBBSOURCE_QUEUE',destination_queue_name=> 'STREAMADMIN2.TBBBTARGET_QUEUE@prince2',include_dml => true,include_ddl=> true,source_database => 'prince',inclusion_rule => true,queue_to_queue=> true);#指定的是从库target连接,建议在从库target创建完apply进程后进行,我有碰到报错select * from all_propagation #确认传播进程情况,报错信息和状态会在这里显示select PROPAGATION_NAME,SOURCE_QUEUE_NAME,DESTINATION_QUEUE_NAME,DESTINATION_DBLINK,STATUS from dba_propagation;exec dbms_propagation_adm.start_propagation('capture_tbbb');#启动传播进程(后续使用)exec dbms_propagation_adm.stop_propagation('capture_tbbb');#关闭传播进程exec dbms_aqadm.alter_propagation_schedule(queue_name => 'STREAMADMIN1.TBBBSOURCE_QUEUE',destination => 'prince2',latency =>0); #消除进程休眠时间,变为实时传播。有报错大概率dblink不对,我本地装两套有碰见oci导致的。#stream创建流程-从库(target端)
#1、创建远程dblink#以之前创建的stream管理员账户登录create database link prince connect to streamadmin1 identified by streamadmin1 using 'prince';#提示成功即可,因为是从库,我们无法远程到主库#2、创建stream队列-从库backup流队列 exec dbms_streams_adm.set_up_queue(queue_table=>'prince2_queue_table',queue_name=>'prince2_queue');#检查是否成功创建队列select owner,queue_table,name from dba_queues --name TCOPYTARGET_QUEUEselect owner,queue_table,object_type from dba_queue_tables #两个必须都有,否则一定失败#3、创建apply进程exec DBMS_STREAMS_ADM.ADD_SCHEMA_RULES(schema_name=> 'tbbb',streams_type=> 'apply',streams_name=> 'tbbb_apply_stream',queue_name=> 'STREAMADMIN2.TBBBTARGET_QUEUE',include_dml=> true,include_ddl=> true,include_tagged_lcr => false,source_database => 'prince',inclusion_rule => true);select apply_name,queue_name,status from dba_apply #确认状态exec dbms_apply_adm.start_apply(apply_name => 'tbbb_apply_stream');#进程启动与停止exec dbms_apply_adm.stop_apply(apply_name => 'tbbb_apply_stream');
#启动stream进程#从库启动 apply进程exec dbms_apply_adm.start_apply(apply_name => 'tbbb_apply_stream');#主库启动捕获进程和传播进程exec DBMS_CAPTURE_ADM.START_CAPTURE(capture_name => 'CAPTURE_TBB');exec dbms_propagation_adm.start_propagation('capture_tbbb');
#检验方式主库用户创建、crud等等操作完后去从库用户检查(不是实时的就先==)
#dblink错误处理
select * from dba_db_links;
drop public database link name;
#name为语句查出的db_link名称,只能删除本用户创建dblink,其他用户的就算你是dba也动不了stream数据共享创建实操—(库级复制)
#1、确认参数 且处于归档模式
alter system set aq_tm_processes=4 scope=spfile;
alter system set job_queue_processes=5 scope=spfile;
alter system set global_names=true scope=spfile;
alter system set streams_pool_size=51m scope=spfile;
#2、还是在主库和目标库创建连接,是改tnsname还是直接指定随你
#3、创建主从库的stream管理员
#4、主从库创建文件夹
create directory dir_DBA as 'D:/Stream/prince';
create directory dir_DBA2 as 'D:/Stream/prince2';
#5、主库source执行
dbms_streams_adm.maintain_global(source_directory_object =>'dir_DBA',destination_directory_object =>'dir_DBA2',source_database=>'prince',destination_database =>'prince2',perform_actions=>true,include_ddl=>true,instantiation=>DBMS_STREAMS_ADM.INSTANTIATION_FULL_NETWORK);
#6、然后就完了
相关文章:

DBA之路---Stream数据共享同步机制与配置方法
oracle的Stream解析–数据共享 在g版本常用,如果是c版本项目一般都会选择goldengate,比stream靠谱多了 Oracle中的stream是消息队列一种应用形式,原理如下: 收集oracle中的事件,将事件保存在队列里,然后将…...

CF1790E Vlad and a Pair of Numbers 题解
CF1790E Vlad and a Pair of Numbers 题解题目链接字面描述题面翻译题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1思路代码实现题目 链接 https://www.luogu.com.cn/problem/CF1790E 字面描述 题面翻译 共有 ttt 组数据。 每组数据你会得到一个正整数 xxx&…...

漏洞预警|Apache Kafka Connect JNDI注入漏洞
棱镜七彩安全预警 近日网上有关于开源项目Apache Kafka Connect JNDI注入漏洞,棱镜七彩威胁情报团队第一时间探测到,经分析研判,向全社会发起开源漏洞预警公告,提醒相关安全团队及时响应。 项目介绍 Karaf是Apache旗下的一个开…...

企业小程序开发步骤【教你创建小程序】
随着移动互联网的兴起,微信已经成为了很多企业和商家必备的平台,而其中,微信小程序是一个非常重要的工具。本文将为大家介绍小程序开发步骤,教你创建小程序。 步骤一、注册小程序账号 先准备一个小程序账号,在微信公…...

刚性电路板的特点及与柔性电路板的区别
打开市场上的任何一个电子产品,会发现里面都有一块或多块电路板。电路板是电子产品运行的核心,之前沐渥小编已经给大家介绍了柔性电路板,下面给大家介绍刚性电路板的基础知识。 刚性电路板俗称硬板,是由不容易变形的刚性基材制成的…...

扫码过磅+车牌识别,内蒙古蒙维过磅实现信息化管理
扫码过磅、车牌识别、对接SAP ERP系统设计思路: 无人值守系统升级改造包括车牌自动识别系统、信息化(扫码等方式)管理系统、智能自动控制系统等实现信息无纸化传递。远程监管地点设于公司东磅房,可以实现远程监测监控画面、称重过…...
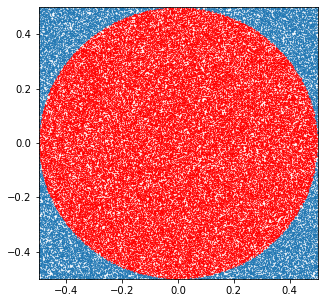
蒙特卡洛计算圆周率
使用MC计算圆周率的小例子,使用python的numpy,matplotlib库import numpy as npimport matplotlib.pyplot as pltdef mc_calculate_pi(t):np.random.seed(t)rand_num np.random.rand(t)rand_num2 np.random.rand(t)l1 rand_num-0.5l2 rand_num2-0.5l0…...
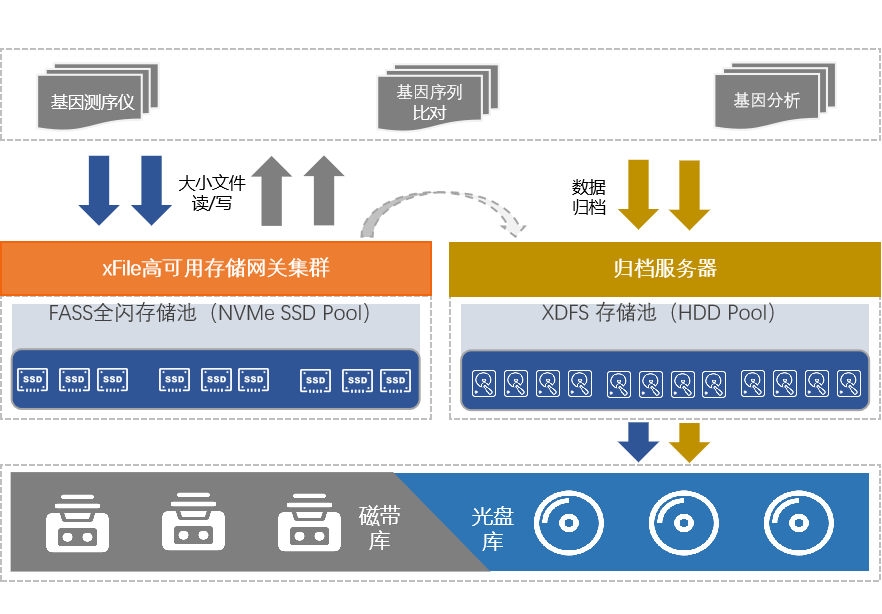
生物信息场景下的用户需求
背景分析概念定义基因测序是一种新型基因检测技术,是基因检测的方法之一,其又叫基因谱测序,是国际上公认的一种基因检测标准。基因测序技术能锁定病变基因,提前预防和治疗。过长的测序周期以及上万美元的仪器成本,成了…...
和sudo(superuser do)的区别?(sudo su与su的区别))
linux su(switch user)和sudo(superuser do)的区别?(sudo su与su的区别)
文章目录linux su(switch user)和sudo(superuser do)的区别?sudo su与su的区别linux su(switch user)和sudo(superuser do)的区别? 在Unix或Linux操作系统中…...
PostgreSQL的学习心得和知识总结(一百二十三)|深入理解PostgreSQL数据库开源扩展pg_dirtyread的使用场景和实现原理
目录结构 注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下: 1、参考书籍:《PostgreSQL数据库内核分析》 2、参考书籍:《数据库事务处理的艺术:事务管理与并发控制》 3、PostgreSQL数据库仓库…...
ubuntu清理挖矿病毒
0 序言 我之前搭建的hadoop用于测试,直接使用了8088和9870端口,没有放入docker,从而没有端口映射。于是,就被不法之徒盯上了,hadoop被提交了很多job,使得系统被感染了挖矿病毒,在前几天阿里云站…...

【代码随想录训练营】【Day16】第六章|二叉树|104.二叉树的最大深度|559.n叉树的最大深度|111.二叉树的最小深度|222.完全二叉树的节点个数
二叉树的最大深度 题目详细:LeetCode.104 递归法很容易理解: 定义一个全局变量max, 记录二叉树的最大深度在递归函数中增加一个深度参数,表示当前的节点的深度然后对二叉树进行深度优先遍历当遍历到叶子节点时,比较…...
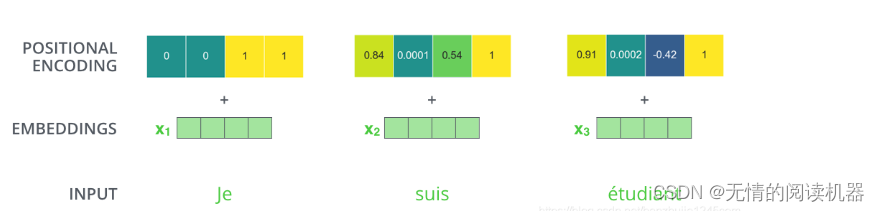
transformer总结
1.注意力机制 意义:人类的注意力机制极大提高了信息处理的效率和准确性。 公式: 1)自注意力机制 b都是在考虑了所有a的情况下生成的。 以产生b1向量为例: 1.在a这个序列中,找到与a1相关的其他向量 2.每个向量与a1关联的程度&a…...

dart flutter入门教程,开发手册 分享
我最近在学校dart flutter.这是我收集的一些手册和教程. 不需要关注公众号,不需要加好友. 我发现flutter(dart)的中文资料比较奇缺.入门的教程非常多.但是api手册几乎没有(全是英文的). 收集原则 1.中文(我英文不好) 2.不要pdf的,网上有一些pdf的 从入门到进阶的,但是太长…...

教育舆情监测关键词有哪些,TOOM教育舆情监测系统流程?
教育舆情监测是指对教育领域的舆情进行收集、分析和处理的过程。舆情是指公众在各种渠道上对教育政策、教育机构、教育事件等方面的言论、态度和情绪。通过对教育舆情的监测和分析,可以了解公众对教育行业的看法和反应,提高对教育行业的管控能力…...
MySQL高级(一)
MySQL-day01 1 MySQL简介 1.1 MySQL简介 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB(创始人Michael Widenius)公司开发,2008被Sun收购(10亿美金),2009年Sun被Oracle收购。MariaDBMaria…...
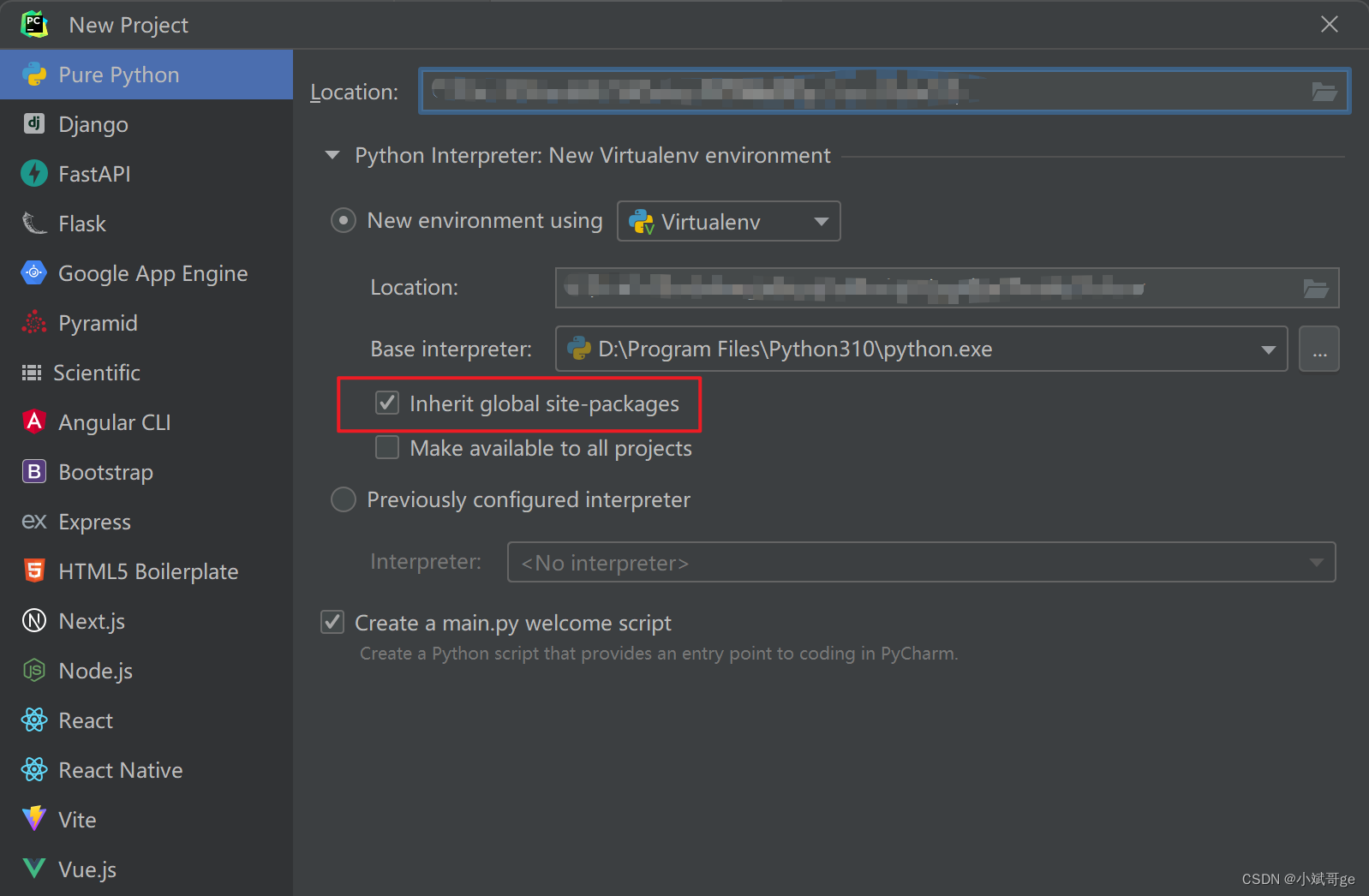
如何将Python项目部署到新电脑上运行?
如何将Python项目部署到新电脑上运行? 在工作中,可能需要在新服务器上部署项目代码,例如新增服务器、把测试环境的代码部署到生产环境等。 在生活中,也会遇到换新电脑,需要将自己在旧电脑上写的(项目&…...
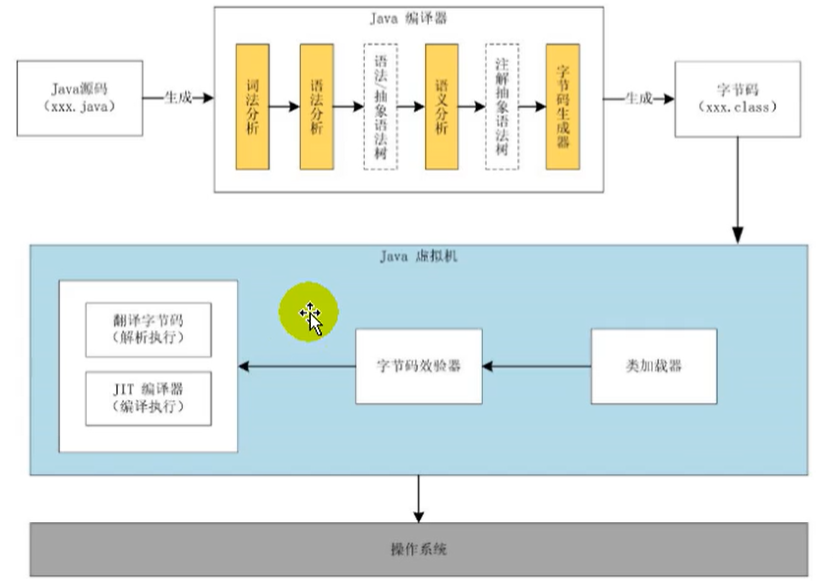
JVM和JAVA体系结构
1、为什么要学习JVM作为Java工程师的你曾被伤害过吗?你是否也遇到过这些问题?运行着的线上系统突然卡死,系统无法访问,甚至直接OOM想解决线上JVM GC问题,但却无从下手新项目上线,对各种JVM参数设置一脸茫然…...
(十)、通过云对象修改阅读量+点赞功能的实现【uniapp+uinicloud多用户社区博客实战项目(完整开发文档-从零到完整项目)】
1,通过云对象importObj修改阅读量 1.1 新建云对象 1.2 云对象中写自增自减方法 封装云对象utilsObj中的自增自减方法,方法名取为operation,传递4个参数。 // 云对象教程: https://uniapp.dcloud.net.cn/uniCloud/cloud-obj // jsdoc语法提…...
)
刷力扣的第一天脑子要长出来的感觉(怎么有人大四才开始啊啊啊啊啊啊啊啊啊啊啊啊,又是等成绩的一天,)
刷力扣的第一天脑子要长出来的感觉(为什么大四才开始啊啊啊啊啊啊啊啊啊啊啊啊) emmm,自己还是想不太出来(只是一点想法),可能还是会参考评论区,求各位轻喷 分析:带符号一定不是回…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

七、数据库的完整性
七、数据库的完整性 主要内容 7.1 数据库的完整性概述 7.2 实体完整性 7.3 参照完整性 7.4 用户定义的完整性 7.5 触发器 7.6 SQL Server中数据库完整性的实现 7.7 小结 7.1 数据库的完整性概述 数据库完整性的含义 正确性 指数据的合法性 有效性 指数据是否属于所定…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...
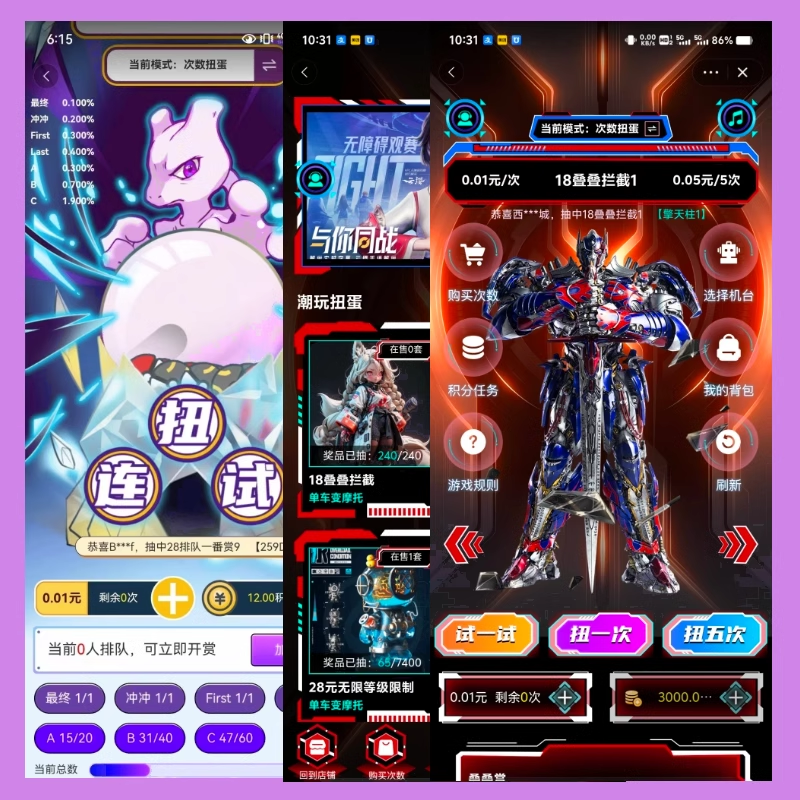
淘宝扭蛋机小程序系统开发:打造互动性强的购物平台
淘宝扭蛋机小程序系统的开发,旨在打造一个互动性强的购物平台,让用户在购物的同时,能够享受到更多的乐趣和惊喜。 淘宝扭蛋机小程序系统拥有丰富的互动功能。用户可以通过虚拟摇杆操作扭蛋机,实现旋转、抽拉等动作,增…...
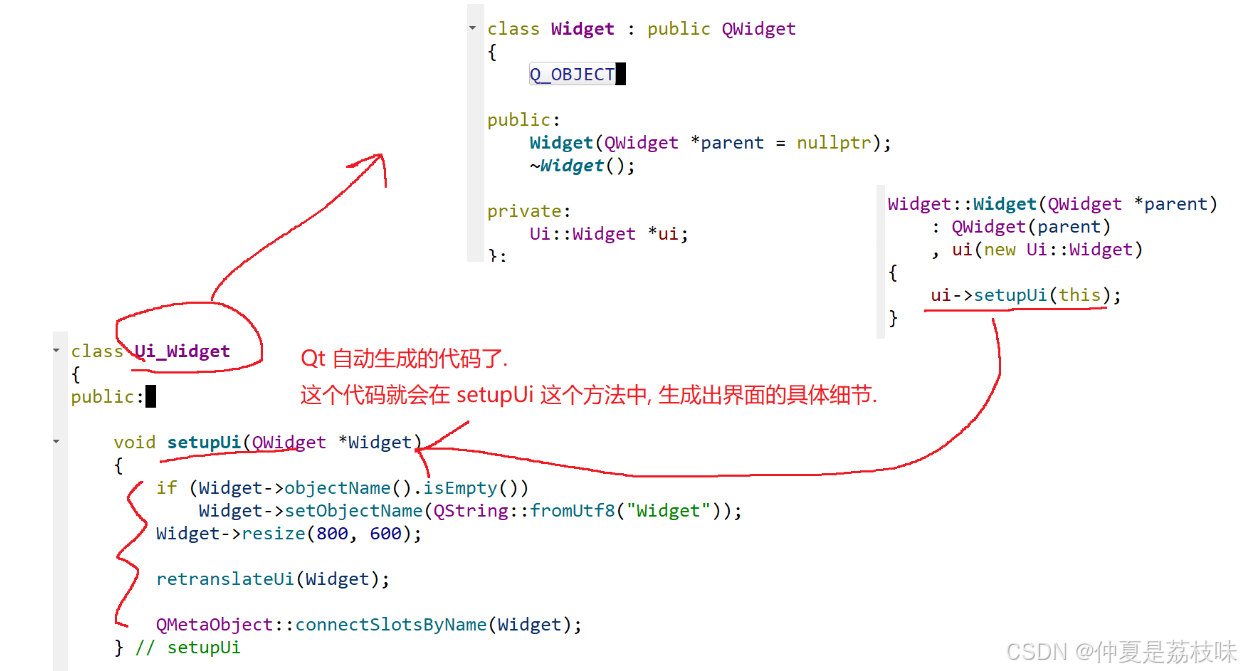
Qt的学习(一)
1.什么是Qt Qt特指用来进行桌面应用开发(电脑上写的程序)涉及到的一套技术Qt无法开发网页前端,也不能开发移动应用。 客户端开发的重要任务:编写和用户交互的界面。一般来说和用户交互的界面,有两种典型风格&…...

DeepSeek越强,Kimi越慌?
被DeepSeek吊打的Kimi,还有多少人在用? 去年,月之暗面创始人杨植麟别提有多风光了。90后清华学霸,国产大模型六小虎之一,手握十几亿美金的融资。旗下的AI助手Kimi烧钱如流水,单月光是投流就花费2个亿。 疯…...

shell脚本质数判断
shell脚本质数判断 shell输入一个正整数,判断是否为质数(素数)shell求1-100内的质数shell求给定数组输出其中的质数 shell输入一个正整数,判断是否为质数(素数) 思路: 1:1 2:1 2 3:1 2 3 4:1 2 3 4 5:1 2 3 4 5-------> 3:2 4:2 3 5:2 3…...