2月datawhale组队学习:大数据
文章目录
- 一、大数据概述
- 二、 Hadoop
- 2.1 Hadoop概述
- 2.2 su:Authentication failure
- 2.3 使用sudo命令报错`xxx is not in the sudoers file. This incident will be reported.`
- 2.4 创建用户datawhale,安装java8:
- 2.5 安装单机版Hadoop
- 2.5.1 安装Hadoop
- 2.5.2 修改hadoop-env.sh文件配置
- 2.5.3 Hadoop伪分布式安装
- 2.5.4 启动Hadoop
- 2.6 Hadoop3.3.1集群模式安装
- 2.6.1 修改配置文件
- 2.6.2 修改hosts文件
- 2.6.3 配置节点和公钥
- 2.6.4 启动Hadoop
- 2.6.5 测试HDFS集群以及MapReduce任务程序
- 三、HDFS
- 3.1 HDFS概述
- 3.2 HDFS的使用和管理
- 3.2.1 启动HDFS
- 3.2.2 验证HDFS运行状态
- 3.3 常用HDFS命令
- 3.3.1 .`ls`命令
- 5.`put`命令(拷贝)
- 3.3.2 `moveFromLocal`命令(拷贝后删除本地)
- 3.3.3 `get`命令
- 3.3.4 `rm`命令
- 9.`mkdir`命令
- 10.`cp`命令
- 11. `mv`命令
- 12.`count`命令
- 13. `du`命令
- 14.`setrep`命令
- 15. `stat`命令
- 16.`balancer`命令
- 17. `dfsadmin`命令
- 18. 其他命令
- 18.1 `cat`命令
- 18.2 `appendToFile`命令
- 18.3 `chown`命令
本文参考
datawhale项目juicy-bigdata,欢迎star。

一、大数据概述
见datawhale大数据教程
二、 Hadoop
由于Hadoop本身是使用Java语言编写的,因此Hadoop的开发和运行都需要Java的支持,一般要求Java 6或者更新的版本
2.1 Hadoop概述
见datawhale大数据教程,有空再整理。
2.2 su:Authentication failure
在 Terminal 输入 su 或者输入 su - root 后,输入登录密码,显示su:Authentication failure 。
解决方法:
- 输入 sudo passwd root,显示 [sudo] password for User:
- Enter new UNIX password(输入登录密码):
- Retypenew UNIX password:
- 显示 passws:
password updated successfully,这时候就可以用刚设置的密码进入 root 了。
2.3 使用sudo命令报错xxx is not in the sudoers file. This incident will be reported.
原因分析:当前用户没有sudo权限,需在/etc/sudoers系统文件添加vboxuser ALL=(ALL) ALL语句。
su # 切换到超级用户
vi /etc/sudoers # 打开/etc/sudoers文件
进入编辑模式,找到“root ALL=(ALL:ALL) ALL”一行,在下面插入“xxx ALL=(ALL:ALL) ALL”语句

2.4 创建用户datawhale,安装java8:
1. 安装java8
点此下载安装包:(密码: hO38),输入以下命令:
sudo adduser datawhale # 创建datawhale用户
su datawhale # 切换到datawhale用户
sudo tar -xzvf jdk-8u311-linux-x64.tar.gz -C /opt # 解压安装包到opt文件夹
sudo mv /opt/jdk1.8.0_311/ /opt/java # 将jdk1.8.0_311目录重命名为java
sudo chown -R datawhale:datawhale /opt/java # 修改java目录的所属用户
2. 修改系统环境变量
输入sudo vim /etc/profile 打开/etc/profile文件,在文件末尾输入:
#java
export JAVA_HOME=/opt/java
export PATH=$JAVA_HOME/bin:$PATH
保存后输入source /etc/profile使环境配置生效。输入java -version,出现以下信息表示安装成功:
java version "1.8.0_311"
Java(TM) SE Runtime Environment (build 1.8.0_311-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.311-b11, mixed mode)
3. 设置SSH登录权限
对于Hadoop的伪分布和全分布而言,Hadoop名称节点(NameNode)需要启动集群中所有机器的Hadoop守护进程,这个过程可以通过SSH登录来实现。Hadoop并没有提供SSH输入密码登录的形式,因此,为了能够顺利登录每台机器,需要将所有机器配置为名称节点,可以通过SSH无密码的方式登录它们。
为了实现SSH无密码登录方式,首先需要让NameNode生成自己的SSH密钥,命令如下:
su datawhale # 切换为datawhale用户
ssh-keygen -t rsa # 执行该命令后,遇到提示信息,一直按回车就可以
NameNode生成密钥之后,需要将它的公共密钥发送给集群中的其他机器。我们可以将id_dsa.pub中的内容添加到需要SSH无密码登录的机器的~/ssh/authorized_keys目录下,然后就可以无密码登录这台机器了。对于无密码登录本机而言,可以执行以下命令:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
这时可以通过ssh localhost命令来检测一下是否需要输入密码。 测试ssh连接,看到“sucessful login”,则配置成功
datawhale@loaclhost:~$ ssh localhost
Welcome to Ubuntu 22.04.1 LTS (GNU/Linux 5.15.0-53-generic x86_64)* Documentation: https://help.ubuntu.com* Management: https://landscape.canonical.com* Support: https://ubuntu.com/advantageThis system has been minimized by removing packages and content that are
not required on a system that users do not log into.To restore this content, you can run the 'unminimize' command.
2.5 安装单机版Hadoop
2.5.1 安装Hadoop
点此下载安装包:(密码: hO38),输入以下命令:
sudo tar -xzvf hadoop-3.3.1.tar.gz -C /opt/ # 解压安装包到opt文件夹
sudo mv /opt/hadoop-3.3.1/ /opt/hadoop # 重命名为hadoop
sudo chown -R datawhale:datawhale /opt/hadoop # 修改hadoop目录的所属用户和所属组
vim /etc/profile # 修改系统环境变量
在文件末尾,添加如下内容:
#hadoop
export HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
输入source /etc/profile重启环境变量。再输入hadoop version查看版本号命令验证是否安装成功:
Hadoop 3.3.1
Source code repository https://github.com/apache/hadoop.git -r a3b9c37a397ad4188041dd80621bdeefc46885f2
Compiled by ubuntu on 2021-06-15T05:13Z
Compiled with protoc 3.7.1
From source with checksum 88a4ddb2299aca054416d6b7f81ca55
This command was run using /opt/hadoop/share/hadoop/common/hadoop-common-3.3.1.jar
如果想切换另一个用户,使得刚才安装的Java和Hadoop也能使用,可以在切换新用户后重启环境变量,也就是输入
source /etc/profile,这样新用户就可以使用了,否则会显示没有这个命令。
2.5.2 修改hadoop-env.sh文件配置
对于单机安装,首先需要更改hadoop-env.sh文件,用于配置Hadoop运行的环境变量,命令如下:
cd /opt/hadoop/
vim etc/hadoop/hadoop-env.sh
在文件末尾,添加如下内容:export JAVA_HOME=/opt/java/。
Hadoop文档中还附带了一些例子来供我们测试,此时可以运行WordCount的示例,检测一下Hadoop安装是否成功。执行命令如下:
mkdir input #在/opt/hadoop/目录下新建input文件夹,用来存放输入数据
cp etc/hadoop/*.xml input # 将etc/hadoop/文件夹下的配置文件拷贝至input文件夹中
# 在hadoop目录下新建output文件夹,用于存放输出数据,并运行wordCount示例
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar grep input output 'dfs[a-z.]+'
cat output/* # 查看输出数据的内容dfsadmin # 输出结果
这意味着,在所有的配置文件中,只有一个符合正则表达式dfs[a-z.]+的单词,输出结果正确。
2.5.3 Hadoop伪分布式安装
分布式安装是指在一台机器上模拟一个小的集群。当Hadoop应用于集群时,不论是伪分布式还是真正的分布式运行,都需要通过配置文件对各组件的协同工作进行设置。对于伪分布式配置,我们需要修改core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml这4个文件。
1.修改core-site.xml文件配置
打开core-site.xml文件,命令如下:
vim /opt/hadoop/etc/hadoop/core-site.xml
添加下面配置到<configuration>与</configuration>标签之间,添加内容如下:
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>
</configuration>
上面配置中,<name>标签代表了配置项的名字,<value>项设置的是配置的值。对于该文件,我们只需要在其中指定HDFS的地址和端口号,端口号按照官方文档设置为9000即可。
2.修改hdfs-site.xml文件配置
打开hdfs-site.xml文件,命令如下:
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
添加下面配置到<configuration>与</configuration>标签之间,添加内容如下:
<configuration><property><name>dfs.replication</name><value>1</value></property>
</configuration>
对于hdfs-site.xml文件,我们设置replication值为1,这也是Hadoop运行的默认最小值,用于设置HDFS文件系统中同一份数据的副本数量。
3.修改mapred-site.xml文件配置
打开mapred-site.xml文件,命令如下:
vim /opt/hadoop/etc/hadoop/mapred-site.xml
添加下面配置到<configuration>与</configuration>标签之间,修改后的mapred-site.xml文件内容如下:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.application.classpath</name><value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value></property>
</configuration>
4.修改yarn-site.xml文件配置
vim /opt/hadoop/etc/hadoop/yarn-site.xml
添加下面配置到<configuration>与</configuration>标签之间。
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property>
</configuration>
对于本书的实验,通过上述配置后,就已经满足运行要求了。更详细的配置可以参考官方文档。
2.5.4 启动Hadoop
1. 格式化分布式文件系统
在配置完成后,首先需要初始化文件系统,由于Hadoop的很多工作是在自带的 HDFS文件系统上完成的,因此,需要将文件系统初始化之后才能进一步执行计算任务。执行初始化的命令如下:
su datawhale
hdfs namenode -format
在看到运行结果中出现“successfully formatted”之后,则说明初始化成功。
2023-02-16 02:44:43,852 INFO common.Storage: Storage directory /tmp/hadoop-datawhale/dfs/name has been successfully formatted.
2023-02-16 02:44:43,888 INFO namenode.FSImageFormatProtobuf: Saving image file /tmp/hadoop-datawhale/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2023-02-16 02:44:43,991 INFO namenode.FSImageFormatProtobuf: Image file /tmp/hadoop-datawhale/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 401 bytes saved in 0 seconds .
2023-02-16 02:44:44,005 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2023-02-16 02:44:44,032 INFO namenode.FSNamesystem: Stopping services started for active state
2023-02-16 02:44:44,033 INFO namenode.FSNamesystem: Stopping services started for standby state
2023-02-16 02:44:44,037 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2023-02-16 02:44:44,038 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at zhxscut/127.0.1.1
************************************************************/
2. 启动Hadoop
运行/opt/hadoop/sbin/start-all.sh就可以启动Hadoop的所有进程(等待10s)。可以通过提示信息得知,所有的启动信息都写入到对应的日志文件。如果出现启动错误,则可以查看相应的错误日志。
若要关闭Hadoop,运行
/opt/hadoop/sbin/stop-all.sh。
datawhale@zhxscut:/opt/hadoop$ /opt/hadoop/sbin/start-all.shWARNING: Attempting to start all Apache Hadoop daemons as datawhale in 10 seconds.
WARNING: This is not a recommended production deployment configuration.
WARNING: Use CTRL-C to abort.
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [zhxscut]
Starting resourcemanager
Starting nodemanagers
3. 查看Hadoop进程
运行之后,输入jps命令可以查看所有的Java进程。正常启动后,可以得到如下类似结果:
datawhale@zhxscut:/opt/hadoop$ jps
1441 NameNode
1738 SecondaryNameNode
1548 DataNode
1933 ResourceManager
2031 NodeManager
2367 Jps
4. Hadoop WebUI管理界面
此时,可以通过http://localhost:8088访问Web界面,查看Hadoop的信息。
5. 测试HDFS集群以及MapReduce任务程序
利用Hadoop自带的WordCount示例程序进行检查集群,并在主节点上进行如下操作,创建执行MapReduce任务所需的HDFS目录:
hadoop fs -mkdir /user
hadoop fs -mkdir /user/datawhale
hadoop fs -mkdir /input
创建测试文件,命令如下:
vim /home/datawhale/test
在test文件中,添加以下内容:
Hello world!
使用Shift+:,输入wq后回车,保存并关闭编辑器。
将测试文件上传到Hadoop HDFS集群目录,命令如下:
hadoop fs -put /home/datawhale/test /input
执行wordcount程序,命令如下:
hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /out
通过以下命令,查看执行结果:
hadoop fs -ls /out
执行结果如下:
Found 2 items
-rw-r--r-- 1 root supergroup 0 time /out/_SUCCESS
-rw-r--r-- 1 root supergroup 17 time /out/part-r-00000
可以看到,结果中包含_SUCCESS文件,表示Hadoop集群运行成功。
查看具体的输出结果,命令如下:
hadoop fs -text /out/part-r-00000
输出结果如下:
Hello 1
world! 1
✅ 官网安装请参考:Hadoop单节点集群安装
✅ 安装问题:Hadoop中DataNode没有启动
VERSION参考查询目录:tmp/hadoop-datawhale/dfs/data/current/VERSION
2.6 Hadoop3.3.1集群模式安装
java与hadoop的安装与伪分布式流程一致,此处不再赘述,后面的配置文件有所不同。
2.6.1 修改配置文件
1. 修改hadoop hadoop-env.sh文件配置
vim /opt/hadoop/etc/hadoop/hadoop-env.sh
末端添加如下内容:
export JAVA_HOME=/opt/java/
2. 修改hadoop core-site.xml文件配置
vim /opt/hadoop/etc/hadoop/core-site.xml
添加下面配置到<configuration>与</configuration>标签之间。
<property><name>fs.defaultFS</name><value>hdfs://master:9000</value>
</property>
3. 修改hadoop hdfs-site.xml文件配置
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
添加下面配置到<configuration>与</configuration>标签之间。
<property><name>dfs.replication</name><value>3</value>
</property>
4. 修改hadoop yarn-site.xml文件配置
vim /opt/hadoop/etc/hadoop/yarn-site.xml
添加下面配置到<configuration>与</configuration>标签之间。
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
5. mapred-site.xml文件配置
vim /opt/hadoop/etc/hadoop/mapred-site.xml
添加下面配置到<configuration>与</configuration>标签之间。
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
6. 修改hadoop workers文件配置
vim /opt/hadoop/etc/hadoop/workers
覆盖写入主节点映射名和从节点映射名:
master
slave1
slave2
2.6.2 修改hosts文件
查看master ip地址
ip addr
记录下显示的ip,例:172.18.0.4
打开slave1 节点,做如上操作,记录下显示的ip,例:172.18.0.3
打开slave2 节点,做如上操作,记录下显示的ip,例:172.18.0.2
编辑/etc/hosts文件:
sudo vim /etc/hosts
添加master IP地址对应本机映射名和其它节点IP地址对应映射名(如下只是样式,请写入实验时您的正确IP):
172.18.0.4 master
172.18.0.3 slave1
172.18.0.2 slave2
2.6.3 配置节点和公钥
在datawhale用户下创建公钥:(若上边做伪分布式时已生成过密钥则不必再做)
ssh-keygen -t rsa
依次回车默认创建完成。然后输入以下命令:
# 拷贝公钥:
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2# 修改文件权限:(master和slave均需修改)
chmod 700 /home/datawhale/.ssh
chmod 700 /home/datawhale/.ssh/*# 测试连接是否正常
ssh master # 拷贝文件到所有从节点
scp -r /opt/java/ /opt/hadoop/ slave1:/tmp/
scp -r /opt/java/ /opt/hadoop/ slave2:/tmp/
提示:命令执行过程中需要输入“yes”和密码“datawhale”。三台节点请依次执行完成。
至此,主节点配置完成。现在,请去slave1和slave2依次完成节点配置。以下内容在所有从节点配置完成之后回来继续进行!
2.6.4 启动Hadoop
1. 格式化分布式文件系统
hdfs namenode -format
2. 启动Hadoop
/opt/hadoop/sbin/start-all.sh
重新启动前记得要先关闭
/opt/hadoop/sbin/stop-all.sh
3. 查看Hadoop进程
在hadoop主节点执行:
jps
输出结果必须包含6个进程,结果如下:
2529 DataNode
2756 SecondaryNameNode
3269 NodeManager
3449 Jps
2986 ResourceManager
2412 NameNode
在hadoop从节点执行同样的操作:
jps
输出结果必须包含3个进程,具体如下:
2529 DataNode
3449 Jps
2412 NameNode
4. 打开Hadoop WebUI管理界面:
firefox http://master:8088
2.6.5 测试HDFS集群以及MapReduce任务程序
利用Hadoop自带的WordCount示例程序进行检查集群;在主节点进行如下操作,创建HDFS目录:
hadoop fs -mkdir /datawhale/
hadoop fs -mkdir /datawhale/input
创建测试文件
vim /home/datawhale/test
添加文字datawhale,然后:
hadoop fs -put /home/datawhale/test /datawhale/input # 将测试文件上传到到Hadoop HDFS集群目录
# 执行wordcount程序:
hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /datawhale/input/ /datawhale/out/
hadoop fs -ls /datawhale/out/ 查看执行结果
如果列表中结果包含”_SUCCESS“文件,代码集群运行成功。

查看具体的执行结果,可以用如下命令:
hadoop fs -text /datawhale/out/part-r-00000

到此,集群安装完成。
三、HDFS
3.1 HDFS概述
见《datawhale大数据教程三:HDFS》。
3.2 HDFS的使用和管理
3.2.1 启动HDFS
以下作废,应该直接使用datawhale用户执行,因为Hadoop超级用户是datawhale。
中间新建文件夹时可能报错
mkdir: Call From zhxscut/127.0.1.1 to localhost:9000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused,我运行hdfs namenode -format之后就可以执行hadoop fs命令了。
启动HDFS,查看进程
cd /opt/hadoop/sbin/start-dfs.sh # 启动Hadoop的HDFS相关进程
jps # 查看HDFS进程
datawhale@zhxscut:/opt/hadoop$ jps
2835 ResourceManager
4915 Jps
2937 NodeManager
2490 DataNode
2650 SecondaryNameNode
3564 NameNode
3.2.2 验证HDFS运行状态
datawhale@zhxscut:/opt/hadoop$ hadoop fs -mkdir /myhadoop1
datawhale@zhxscut:/opt/hadoop$ hadoop fs -ls /
Found 5 items
drwxr-xr-x - datawhale supergroup 0 2023-02-16 06:38 /input
drwxr-xr-x - datawhale supergroup 0 2023-02-16 06:39 /myhadoop1
drwxr-xr-x - datawhale supergroup 0 2023-02-16 06:39 /out
drwx------ - datawhale supergroup 0 2023-02-16 06:38 /tmp
drwxr-xr-x - datawhale supergroup 0 2023-02-16 06:37 /user
3.3 常用HDFS命令
3.3.1 .ls命令
hadoop fs -ls / # 列出hdfs文件系统根目录下的目录和文件Found 5 items
drwxr-xr-x - datawhale supergroup 0 2023-02-16 06:38 /input
drwxr-xr-x - datawhale supergroup 0 2023-02-16 06:39 /myhadoop1
drwxr-xr-x - datawhale supergroup 0 2023-02-16 06:39 /out
drwx------ - datawhale supergroup 0 2023-02-16 06:38 /tmp
drwxr-xr-x - datawhale supergroup 0 2023-02-16 06:37 /userhadoop fs -ls -R / 列出hdfs文件系统所有的目录和文件
5.put命令(拷贝)
hadoop fs -put <local file> <hdfs file>:将本地文件上传(拷贝)到hdfs上 ,其中<hdfs file>的父目录必须存在,否则命令执行失败。hadoop fs -put <local dir> <hdfs dir>:将本地目录上传(拷贝)到hdfs上 ,其中<hdfs dir>的父目录必须存在,否则命令执行失败。
示例:
hadoop fs -put /opt/hadoop/README.txt / # 将/opt/hadoop/README.txt文件上传到hdfs文件系统根目录
hadoop fs -put /opt/hadoop/logs / # 将/opt/hadoop/log文件夹上传到hdfs文件系统根目录
hadoop fs -ls / # 查看是否拷贝成功datawhale@zhxscut:/opt/hadoop$ hadoop fs -ls /
Found 7 items
-rw-r--r-- 1 datawhale supergroup 175 2023-02-16 06:47 /README.txt
drwxr-xr-x - datawhale supergroup 0 2023-02-16 06:38 /input
drwxr-xr-x - datawhale supergroup 0 2023-02-16 06:49 /logs
drwxr-xr-x - datawhale supergroup 0 2023-02-16 06:39 /myhadoop1
drwxr-xr-x - datawhale supergroup 0 2023-02-16 06:39 /out
drwx------ - datawhale supergroup 0 2023-02-16 06:38 /tmp
drwxr-xr-x - datawhale supergroup 0 2023-02-16 06:37 /user
3.3.2 moveFromLocal命令(拷贝后删除本地)
hadoop fs -moveFromLocal <local src> <hdfs dst>:将本地文件/文件夹上传到hdfs中,但本地文件/文件夹会被删除。 例如,执行如下命令,上传本地文件/文件夹至hdfs中:
hadoop fs -moveFromLocal /opt/hadoop/NOTICE.txt /myhadoop1
hadoop fs -moveFromLocal /opt/hadoop/logs /myhadoop1
datawhale@zhxscut:/opt/hadoop$ hadoop fs -ls /myhadoop1
Found 2 items
-rw-r--r-- 1 datawhale supergroup 1541 2023-02-16 06:55 /myhadoop1/NOTICE.txt
drwxr-xr-x - datawhale supergroup 0 2023-02-16 06:56 /myhadoop1/logs
3.3.3 get命令
hadoop fs -get < hdfs file or dir > < local file or dir>:将hdfs文件系统中的文件/文件夹下载到本地。例如,将hdfs文件系统中/myhadoop1目录下的NOTICE.txt和logs分别下载到本地路径/opt/hadoop目录:
hadoop fs -get /myhadoop1/NOTICE.txt /opt/hadoop/
hadoop fs -get /myhadoop1/logs /opt/hadoop/
注意:
- 拷贝多个文件或目录到本地时,本地要为文件夹路径
local file不能和hdfs file名字不能相同,否则会提示文件已存在。- 如果用户不是root用户,
local路径要使用该用户文件夹下的路径,否则会出现权限问题
3.3.4 rm命令
hadoop fs -rm <hdfs file> ...:删除一个或多个文件hadoop fs -rm -r <hdfs dir> ...:删除一个或多个目录
datawhale@zhxscut:/opt/hadoop$ hadoop fs -rm /README.txt
Deleted /README.txt
datawhale@zhxscut:/opt/hadoop$ hadoop fs -rm -r /logs
Deleted /logs
9.mkdir命令
1)创建一个新目录
使用如下命令,在hdfs文件系统中创建一个目录,该命令只能一级一级的创建目录,如果父目录不存在,则会报错:
hadoop fs -mkdir <hdfs path>
例如,在hdfs文件系统的/myhadoop1目录下创建test目录,命令如下:
hadoop fs -mkdir /myhadoop1/test
2)创建一个新目录(-p选项)
使用如下命令,在hdfs文件系统中创建一个目录,如果父目录不存在,则创建该父目录:
hadoop fs -mkdir -p <hdfs dir> ...
例如,在hdfs文件系统创建/myhadoop1/test目录,命令如下:
hadoop fs -mkdir -p /myhadoop2/test
3)查询目录
查看刚刚创建的/myhadoop1/test和/myhadoop2/test目录是否存在,命令如下:
hadoop fs -ls /
hadoop fs -ls /myhadoop1
hadoop fs -ls /myhadoop2
执行结果如下:
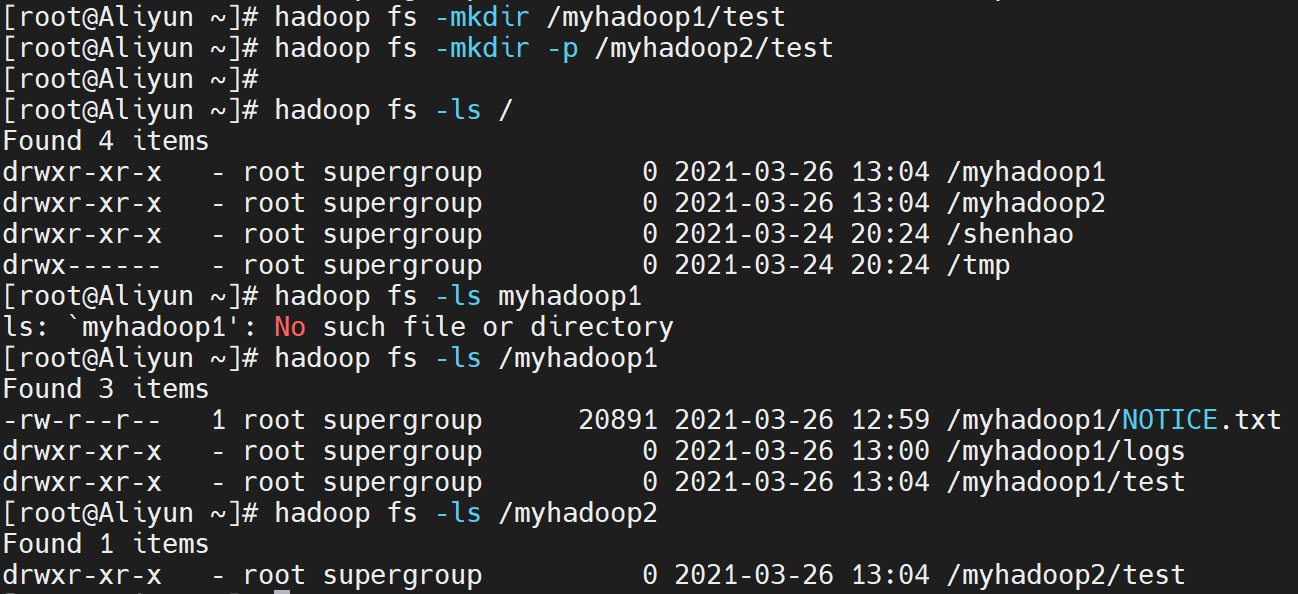
ps:命令好多,不过都很硬核,嘤嘤嘤,各位看官,要坚持看下去哟

10.cp命令
使用如下命令,在hdfs文件系统上进行文件或目录的拷贝,如果目标文件不存在,则命令执行失败,相当于给文件重命名并保存,源文件还存在:
hadoop fs -cp <hdfs file or dir>... <hdfs dir>
按照下面的步骤,使用cp命令,将/LICENSE.txt拷贝到/myhadoop1目录下:
1) 拷贝一个本地文件到HDFS的根目录下
将本地/opt/hadoop目录下的LICENSE.txt文件上传到hdfs文件系统的根目录下,命令如下:
hadoop fs -put /opt/hadoop/LICENSE.txt /
查看hdfs文件系统的根目录下的LICENSE.txt是否存在,命令如下:
hadoop fs -ls /
2)将此文件拷贝到/myhadoop1目录下
使用cp命令,将hdfs文件系统中根目录下的LICENSE.txt文件拷贝到/myhadoop1目录下,命令如下:
hadoop fs -cp /LICENSE.txt /myhadoop1
3)查看/myhadoop1目录
使用如下命令,查看hdfs文件系统的/myhadoop1目录下是否存在LICENSE.txt文件:
hadoop fs -ls /myhadoop1
执行结果如下:

11. mv命令
使用如下命令,在hdfs文件系统上进行文件或目录的移动,如果目标文件不存在,则命令执行失败,相当于给文件重命名并保存,源文件不存在;源路径有多个时,目标路径必须为目录,且必须存在:
hadoop fs -mv <hdfs file or dir>... <hdfs dir>
**注意:**跨文件系统的移动(local到hdfs或者反过来)都是不允许的。
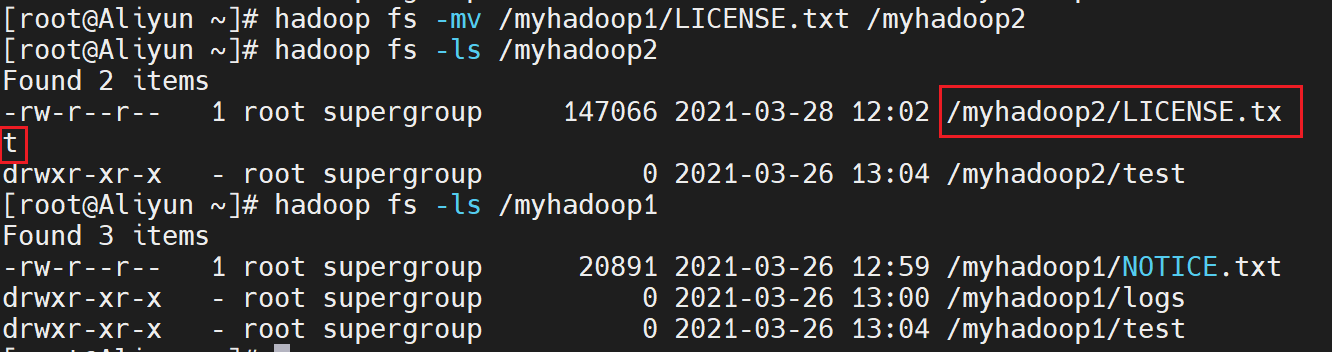
按照下面的步骤,使用mv命令,将/myhadoop1/LICENSE.txt移动到/myhadoop2目录下:
1)移动一个 HDFS文件
使用mv命令,将hdfs文件系统的/myhadoop1目录下的LICENSE.txt文件移动到/myhadoop2目录下,命令如下:
hadoop fs -mv /myhadoop1/LICENSE.txt /myhadoop2
2)查询/myhadoop2目录
使用如下命令,查看hdfs文件系统的/myhadoop2目录下是否存在LICENSE.txt文件:
hadoop fs -ls /myhadoop2
执行结果如下:
12.count命令
使用如下命令,统计hdfs对应路径下的目录个数,文件个数,文件总计大小:
hadoop fs -count <hdfs path>
例如,查看/myhadoop1/logs目录下的目录个数,文件个数,文件总计大小,命令如下:
hadoop fs -count /myhadoop1/logs
执行结果如下:

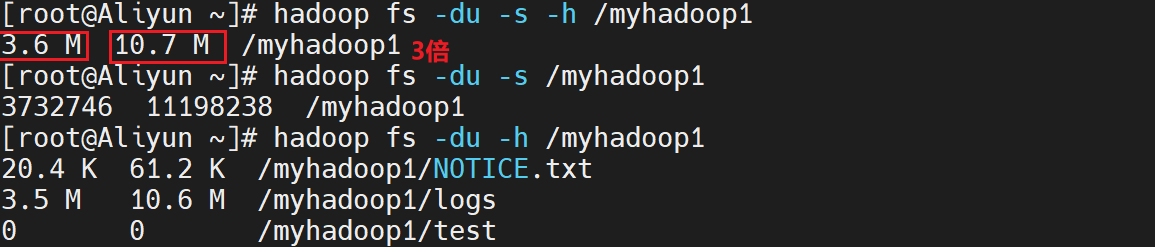
13. du命令
- 显示hdfs对应路径下每个文件夹和文件的大小
hadoop fs -du <hdsf path>
- 显示hdfs对应路径下所有文件大小的总和
hadoop fs -du -s <hdsf path>
- 显示hdfs对应路径下每个文件夹和文件的大小,文件的大小用方便阅读的形式表示,例如用64M代替67108864
hadoop fs -du -h <hdsf path>
例如,执行如下命令,可以查看hdfs文件系统/myhadoop2目录下的每个文件夹和文件的大小、所有文件大小的总和:
hadoop fs -du /myhadoop2
hadoop fs -du -s /myhadoop2
hadoop fs -du -h /myhadoop2
hadoop fs -du -s -h /myhadoop2
执行结果如下:
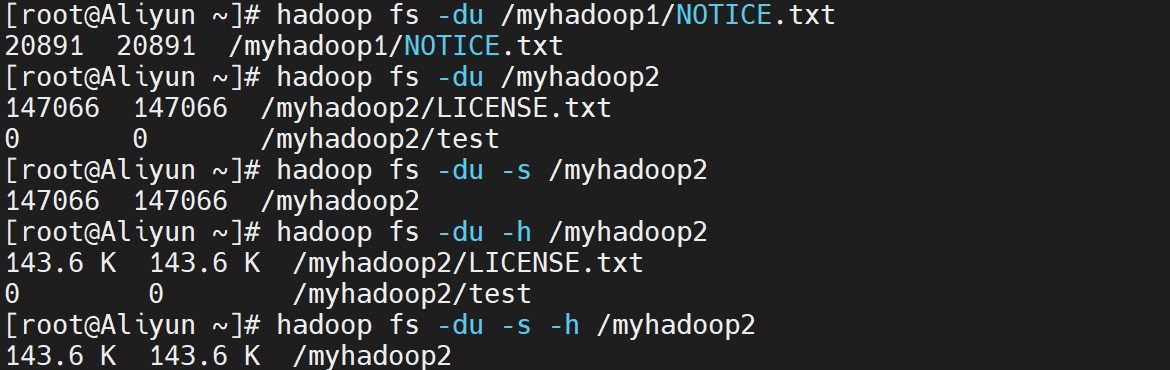
执行结果说明:
- 第一列:表示该目录下总文件大小
- 第二列:表示该目录下所有文件在集群上的总存储大小,该大小和副本数相关,设置的默认副本数为3 ,所以第二列的是第一列的三倍 (第二列内容 = 文件大小 ×\times× 副本数)
- 第三列:表示查询的目录
14.setrep命令
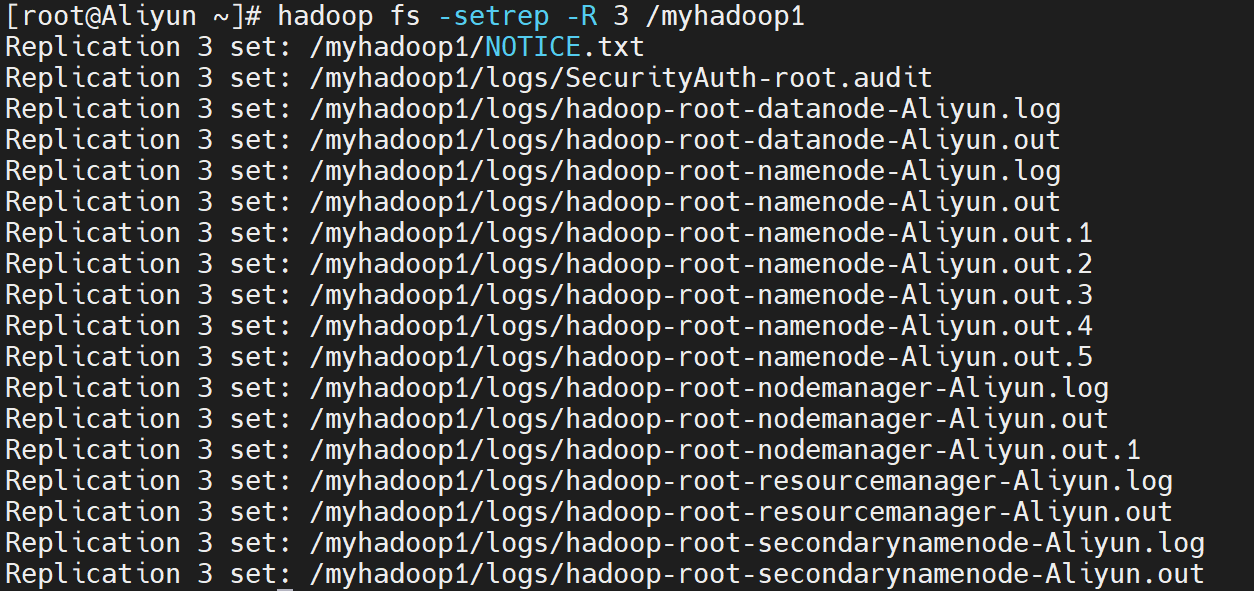
使用如下命令,改变一个文件在hdfs文件系统中的副本个数,数字3表示所设置的副本个数,其中,-R选项可以对一个目录下的所有目录和文件递归执行改变副本个数的操作:
hadoop fs -setrep -R 3 <hdfs path>
例如,对hdfs文件系统中/myhadoop1目录下的所有目录和文件递归执行,设置为3个副本,命令如下:
hadoop fs -setrep -R 3 /myhadoop1
执行结果如下:
15. stat命令
使用如下命令,查看对应路径的状态信息:
hdoop fs -stat [format] < hdfs path >
其中,[format]可选参数有:
%b:文件大小%o:Block大小%n:文件名%r:副本个数%y:最后一次修改日期和时间
例如,查看hdfs文件系统中/myhadoop2/LICENSE.txt文件的大小,命令如下:
hadoop fs -stat %b /myhadoop2/LICENSE.txt
执行结果如下:

16.balancer命令
该命令主要用于,当管理员发现某些DataNode保存数据过多,某些DataNode保存数据相对较少,可以使用如下命令手动启动内部的均衡过程:
hadoop balancer
或
hdfs balancer
17. dfsadmin命令
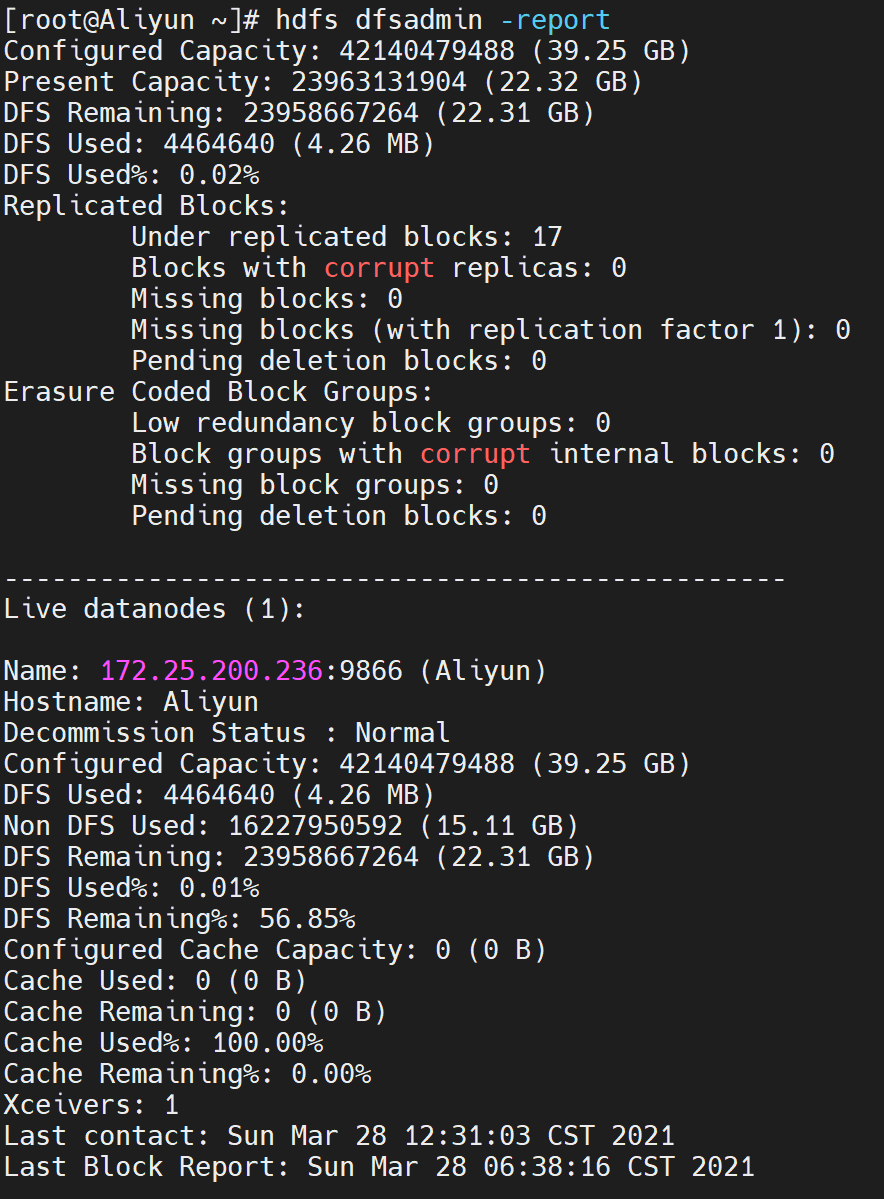
该命令主要用于管理员通过dfsadmin管理HDFS:
1)使用-help参数,查看相关的帮助:
hdfs dfsadmin -help
2) 使用-report参数,查看文件系统的基本数据:
hdfs dfsadmin -report
执行结果如下:
3) 使用-safemode参数,操作安全模式:
hdfs dfsadmin -safemode <enter | leave | get | wait>
其中:
enter:进入安全模式leave:离开安全模式get:查看是否开启安全模式wait:等待离开安全模式
例如,进入安全模式,执行命令如下:
hdfs dfsadmin -safemode enter
执行结果如下:

18. 其他命令

18.1 cat命令
使用cat命令,查看hdfs文件系统中文本文件的内容,例如,查看根目录下的deom.txt文件内容:
hadoop fs -cat /demo.txthadoop fs -tail -f /demo.txt
当使用hadoop fs -tail -f命令后,终端会根据文件描述符进行追踪,当文件改名或被删除,追踪停止。终端操作如下:
- 此时要想暂停刷新,使用
Ctrl+S暂停终端,S表示sleep - 若想要继续刷新终端,使用
Ctrl+Q,Q表示quiet - 若想退出
tail命令,直接使用Ctrl+C,也可以使用Ctrl+Z
Ctrl+C和Ctrl+Z都是中断命令,当他们的作用却不一样的:Ctrl+C比较暴力,就是发送Terminal到当前的程序,比如正在运行一个查找功能,文件正在查找中,使用Ctrl+C会强制结束当前这个进程Ctrl+Z则会将当前程序挂起,暂停执行这个程序,比如mysql终端下,需要跳出来执行其他的文件操作,又不想退出mysql终端(因为下次还需要输入用户名密码进入,很麻烦),于是可以使用Ctrl+Z将mysql挂起,然后进行其他操作,输入fg回车可以回到mysql终端,担任也可以挂起很多进程到后台,执行fg <编号>就能将挂起的进程返回到当前的终端。配合bg和fg命令能更方便的进行前后台切换
18.2 appendToFile命令
将本地文件内容追加到hdfs文件系统中的文本文件里,命令格式如下:
hadoop fs -appendToFile <local file> <hdfs file>
执行示例如下:

18.3 chown命令
使用chown命令,修改hdfs文件系统中文件的读、写、执行的权限,命令示例如下:
hadoop fs -chown user:group /datawhale
hadoop fs -chmod 777 /datawhale
其中,参数说明如下:
chown:定义谁拥有文件chmod:定义可以对该文件做什么
相关文章:
2月datawhale组队学习:大数据
文章目录一、大数据概述二、 Hadoop2.1 Hadoop概述2.2 su:Authentication failure2.3 使用sudo命令报错xxx is not in the sudoers file. This incident will be reported.2.4 创建用户datawhale,安装java8:2.5 安装单机版Hadoop2.5.1 安装Hadoop2.5.2 修…...

在Spring框架中创建Bean实例的几种方法
我们希望Spring框架帮忙管理Bean实例,以便得到框架所带来的种种功能,例如依赖注入等。将一个类纳入Spring容器管理的方式有几种,它们可以解决在不同场景下创建实例的需求。 XML配置文件声明 <?xml version"1.0" encoding"…...
PyQt5 界面预览工具
简介 一款为了预览PyQt5设计的UI界面而开发的工具,使用时需要结合PyCharm同时使用。 下载 PyQt5界面预览工具 参数说明 使用配置 启动PyCharm,找到File -> Settings,打开 找到Tools -> External Tools点击打开,在新界面…...

day44【代码随想录】动态规划之零钱兑换II、组合总和 Ⅳ、零钱兑换
文章目录前言一、零钱兑换II(力扣518)二、组合总和 Ⅳ(力扣377)三、零钱兑换(力扣322)总结前言 1、零钱兑换II 2、组合总和 Ⅳ 3、零钱兑换 一、零钱兑换II(力扣518) 给你一个整数…...
计算机网络第1章(概述)学习笔记
❤ 作者主页:欢迎来到我的技术博客😎 ❀ 个人介绍:大家好,本人热衷于Java后端开发,欢迎来交流学习哦!( ̄▽ ̄)~* 🍊 如果文章对您有帮助,记得关注、点赞、收藏、…...
GPT-3(Language Models are Few-shot Learners)简介
GPT-3(Language Models are Few-shot Learners) 一、GPT-2 1. 网络架构: GPT系列的网络架构是Transformer的Decoder,有关Transformer的Decoder的内容可以看我之前的文章。 简单来说,就是利用Masked multi-head attention来提取文本信息&a…...
容器安全风险and容器逃逸漏洞实践
本文博客地址:https://security.blog.csdn.net/article/details/128966455 一、Docker存在的安全风险 1.1、Docker镜像存在的风险 不安全的第三方组件:用户自己的代码依赖若干开源组件,这些开源组件本身又有着复杂的依赖树,甚至…...

2023年美赛B题-重新想象马赛马拉
背景 肯尼亚的野生动物保护区最初主要是为了保护野生动物和其他自然资源资源。肯尼亚议会于2013年通过了《野生动物保护和管理法》提供更公平的资源共享,并允许替代的、以社区为基础的管理工作[1]。此后,肯尼亚增加了修正案,以解决立法中的空…...
Docker常用命令总结
目录 一、帮助启动类命令 (1)启动docker (2)停止docker (3)重启docker (4)查看docker (5)设置开机自启 (6)查看docker概要信息…...
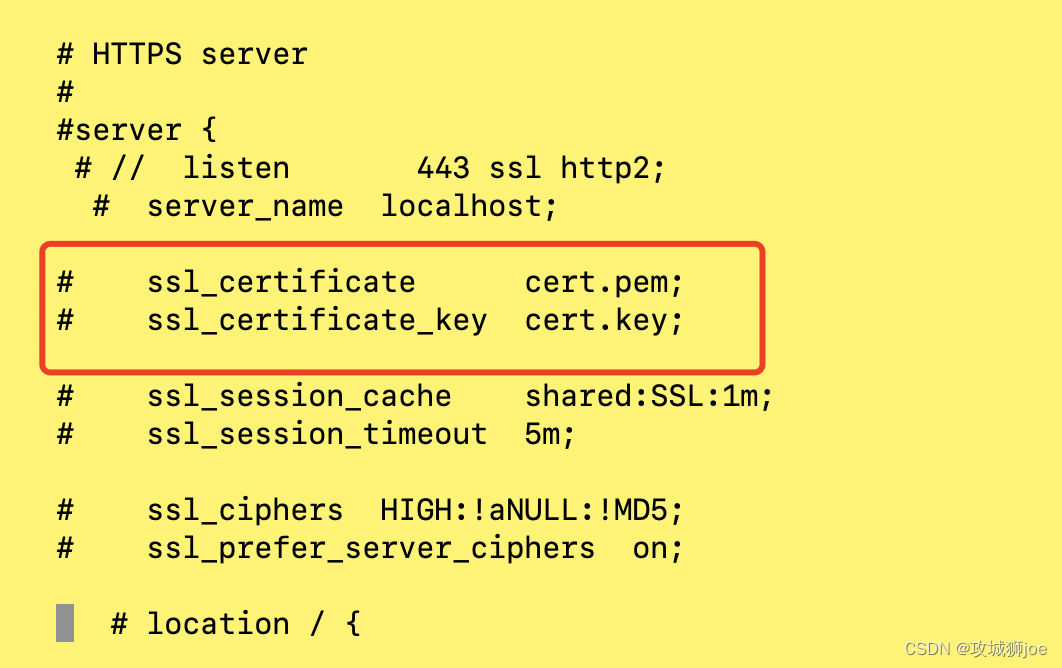
mac环境,安装NMP遇到的问题
一 背景 项目开发中,公司项目需要使用本地的环境运行,主要是php这块的业务。没有使用docker来处理,重新手动撸了一遍。记录下其中遇到的问题; 二 遇到的问题 2.1 Nginx的问题 brew install nginx后,启动nginx,报错如下:nginx: [emerg] no "ssl_certificate" …...

Web Worker 与 SharedWorker 的介绍和使用
目录一、Web Worker1 Web Worker 是什么2 Web Worker 使用3 简单示例二、SharedWorker2.1 SharedWorker 是什么2.2 SharedWorker 的使用方式2.3 多页面数据共享的例子一、Web Worker 1 Web Worker 是什么 Web Worker是 HTML5 标准的一部分,这一规范定义了一套 API…...

React:Redux和Flux
React,用来构建用户界面,它有三个特点: 作为view,构建上用户界面虚拟DOM,目的就是高性能DOM渲染【diff算法】、组件化、多端同构单向数据流,是一种自上而下的渲染方式。Flux 在一个React应用中,UI部分是由无数个组件嵌套构成的,组件和组件之间就存在层级关系,也就是父…...

TypeScript 学习之Class
基本使用 class Greeter {// 属性greeting: string;// 构造函数constructor(message: string) {// 用this 访问类的属性this.greeting message;}// 方法greet() {return Hello, this.greeting;} } // 实例化 let greeter new Greeter(World);声明了一个Greeter类ÿ…...
doris - 数仓 拉链表 按天全量打宽表性能优化
数仓 拉链表 按天全量打宽性能优化现状描述优化现状描述 1、业务历史数据可以变更 2、拉链表按天打宽 3、拉链表模型分区字段设计不合理,通用的过滤字段没有作为分区分桶字段 4、拉链表表数据量略大、模型数据分区不合理和服务器资源限制,计算任务执行超…...

服务器虚拟化及优势
服务器虚拟化是从一台物理服务器创建多个服务器实例的过程。每个服务器实例代表一个隔离的虚拟环境。在每个虚拟环境中,都可以运行单独的操作系统。 1.更有效的资源调配 使用虚拟化技术大大节省了所占用的空间,减少了数据中心里服务器和相关硬件的数量。…...
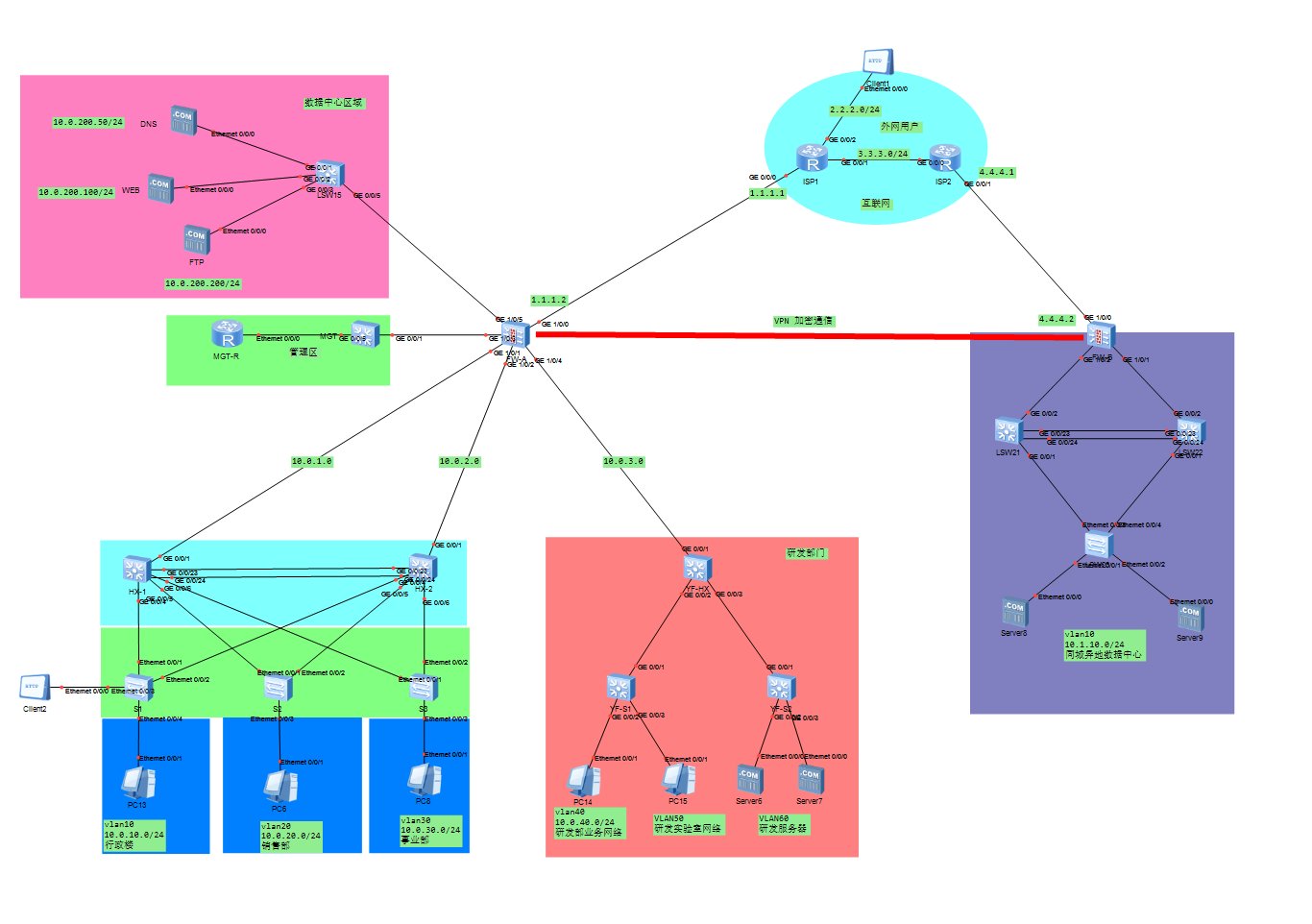
华为ensp模拟校园网/企业网实例(同城灾备及异地备份中心保证网络安全)
文章简介:本文用华为ensp对企业网络进行了规划和模拟,也同样适用于校园、医院等场景。如有需要可联系作者,可以根据定制化需求做修改。作者简介:网络工程师,希望能认识更多的小伙伴一起交流,私信必回。一、…...

git命令篇(持续更新中)
首先介绍这个网页:https://learngitbranching.js.org/?localezh_CN --提交命令 git commit --创建分支 git branch <分支名> --切换分支 git checkout <分支名> --合并分支 (合并到主分支去,把我合并到谁的身上去) 自己写的分支合并到主线…...
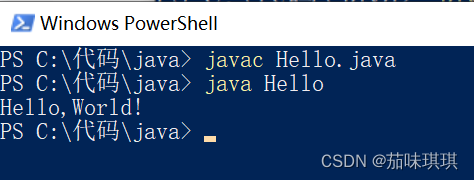
用记事本实现“HelloWorld”输出
一、在任意文件夹中创建一个新的文本文档文件并写入以下代码 public class Hello{public static void main (String[] args){System.out.print("Hello,World!");} } 二、修改文件名称及文件类型为 Hello.java 特别注意:文件命名必须与代码中类的名称相同…...
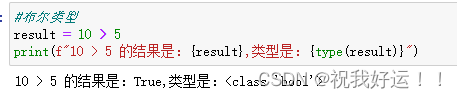
Python基础1
1. 注释 单行注释:以#开头。一般建议注释和内容用空格隔开。 多行注释:以一对三个双引号括起来的内容是注释。“““示例注释”””。 2. 数据类型 验证数据类型的方法:type(被查看类型的数据)。 注意:…...

4.2 双点双向路由重发布
1. 实验目的 熟悉双点双向路由重发布的应用场景掌握双点双向路由重发布的配置方法2. 实验拓扑 双点双向路由重发布如图4-6所示: 图4-6:双点双向路由重发布 3. 实验步骤 IP地址的配置R1的配置 <Huawei>system-v…...

从IE到Edge:捷宇高拍仪SDK在Vue3中的现代化改造全记录
从IE到Edge:捷宇高拍仪SDK在Vue3中的现代化改造全记录 当企业级硬件设备遇上现代前端框架,技术栈的代际差异往往成为开发者的"拦路虎"。捷宇高拍仪作为政务、金融等行业的常用影像采集设备,其传统ActiveX控件方案在IE退役后暴露出明…...

快速上手CosyVoice:3步完成声音克隆,制作个性化语音问候和提醒
快速上手CosyVoice:3步完成声音克隆,制作个性化语音问候和提醒 1. 认识CosyVoice语音克隆系统 CosyVoice是阿里巴巴通义实验室开发的多语言语音生成模型,它最大的特点就是能让你用短短几秒钟的参考音频,克隆出一个几乎一模一样的…...

如何用skhd打造设计师专属的macOS快捷键方案:终极效率提升指南
如何用skhd打造设计师专属的macOS快捷键方案:终极效率提升指南 【免费下载链接】skhd Simple hotkey daemon for macOS 项目地址: https://gitcode.com/gh_mirrors/sk/skhd 想要在macOS上实现专业级快捷键自定义?skhd(Simple Hotkey …...

Alpamayo-R1-10B环境部署:32GB内存+30GB存储+CUDA驱动全检查清单
Alpamayo-R1-10B环境部署:32GB内存30GB存储CUDA驱动全检查清单 1. 项目概述 Alpamayo-R1-10B是NVIDIA推出的自动驾驶专用开源视觉-语言-动作(VLA)模型,核心为100亿参数规模。该模型结合AlpaSim模拟器与Physical AI AV数据集,构成完整的自动…...

玩过电源设计的都知道,Buck电路的双闭环控制就像炒菜放盐——调不好整锅都得翻车。今天咱们直接上干货,从数学建模到仿真验证,手把手把PI调节器的门道拆开了说
buck双闭环控制仿真降压电路PI调节器设计降压斩波电路建模和数学模型建模 建模方法有状态空间平均法,开关元件平均模型法,开关网络平均模型法提供双闭环调节器设计方案 从滤波器设计到pi调节器设计再到仿真。 从滤波器设计到建模,得到被控对象…...
)
5分钟搞定SkyWalking 9.5.0的Docker部署与Java应用集成(含常见报错解决)
5分钟搞定SkyWalking 9.5.0的Docker部署与Java应用集成(含常见报错解决) 在微服务架构盛行的今天,分布式系统的监控与追踪已成为开发者必备技能。Apache SkyWalking作为一款开源的APM(应用性能监控)系统,凭…...

BilibiliDown终极指南:三步搞定B站视频下载,离线观看无限制
BilibiliDown终极指南:三步搞定B站视频下载,离线观看无限制 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.…...

BLE Current Time Service嵌入式实现与时间同步实战
1. BLE Current Time Service 技术解析与嵌入式实现指南1.1 服务定位与工程价值BLE Current Time Service(CTS)是蓝牙 SIG 官方定义的标准 GATT 服务(UUID:0x1805),专用于在低功耗蓝牙设备间同步高精度时间信息。该服务…...

Youtu-Parsing助力AI编程:自动解析技术文档生成代码片段
Youtu-Parsing助力AI编程:自动解析技术文档生成代码片段 每次接触一个新的开发库或者框架,你是不是也经历过这样的时刻?面对动辄几十页的官方文档,或者一个结构复杂的开源项目README,感觉无从下手。想快速写个Demo试试…...
完整代码分享)
Cesium项目实战:免Key调用高德地图的三种服务(矢量/影像/注记)完整代码分享
Cesium项目实战:免Key调用高德地图的三种服务(矢量/影像/注记)完整代码分享 在WebGIS开发领域,Cesium作为一款强大的三维地理可视化引擎,常需要与各类地图服务结合使用。高德地图作为国内主流的地图服务提供商…...