【MySQL】MySQL表的增删改查(CRUD)

✨个人主页:bit me👇
✨当前专栏:MySQL数据库👇
✨算法专栏:算法基础👇
✨每日一语:生命久如暗室,不碍朝歌暮诗
目 录
- 🔓一. CRUD
- 🔒二. 新增(Create)
- 🔎如何修改MySQL配置:
- 📚三. 查询(Retrieve)
- 📙1. 全列查询
- 📘2. 指定列查询
- 📗3. 查询带有表达式
- 📕4. 起别名查询
- 📒5. 去重查询
- 📔6. 排序查询
- 📓7. 条件查询
- 📰8. 分页查询
- 🔐四. 修改(Update)
- 🔏五. 删除(Delete)
🔓一. CRUD
- CRUD : Create,Retrieve,Update,Delete
- 新增数据
- 查询数据
- 修改数据
- 删除数据
MySQL的工作就是组织管理数据,先保存,保存好了后好进行增删改查
增删改查的前提是已经把数据库创建好,并且选中了,表也创建就绪
- 注释:在SQL中可以使用“–空格+描述”来表示注释说明
- CRUD 即增加(Create)、查询(Retrieve)、更新(Update)、删除(Delete)四个单词的首字母缩写
🔒二. 新增(Create)
insert into 表名 values(值,值,值…);
- 注意此处的值的个数要和表的列数匹配,值的类型也要和列的类型匹配(不匹配就会报错!!!)
所以也更好的体现出关系型数据库的一个优势:对数据进行更严格的校验检查,更容易发现问题!
- 我们先在库里创建一个学生表:
mysql> create table student(id int, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
- 查看表的结构
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
- 新增
mysql> insert into student values (1,"zhangsan");
Query OK, 1 row affected (0.00 sec)
注意:在SQL中表示字符串,可以使用单引号也可以使用双引号,他们两个是等价关系,在SQL中没有 " 字符类型 ",只有字符串类型,所以单引号就可以表示字符串。
在这里无论我们表的列数不匹配还是类型不匹配,都是会报错的
mysql> insert into student values(2);
ERROR 1136 (21S01): Column count doesn't match value count at row 1
mysql> insert into student values ("zhangsan",3);
ERROR 1366 (HY000): Incorrect integer value: 'zhangsan' for column 'id' at row 1
注意:出现ERROR意味着当前的操作是不生效的
拓展:
我们在这里还可以插入中文数据:
mysql> insert into student values (2,"张三");
Query OK, 1 row affected (0.00 sec)
在这块我们还需知道,数据库表示中文需要明确字符编码,MySQL默认的字符集叫做拉丁文,不支持中文,为了可以存储,就需要把字符集改为UTF-8。在这里我们介绍一种一劳永逸的方法来修改字符集 --> 修改MySQL的配置文件
🔎如何修改MySQL配置:
- 先确认当前数据库的字符集
show variables like ‘character%’;
mysql> show variables like 'character%';
+--------------------------+---------------------------------------------------------+
| Variable_name | Value |
+--------------------------+---------------------------------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | C:\Program Files\MySQL\MySQL Server 5.7\share\charsets\ |
+--------------------------+---------------------------------------------------------+
8 rows in set, 1 warning (0.00 sec)
可以看到我的数据库就是UTF-8字符集
- 找到配置文件 – my.ini
①:可以使用软件Everything来寻找
搜索框里输入my.ini即可找到,但是可能会出现多个my.ini导致无法辨别哪一个才是我们要找的,所以不推荐
②:在我们的系统找到MySQL并且完成这一系列操作
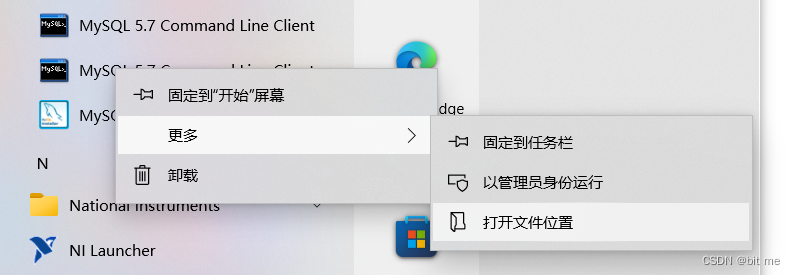
- 右键快捷键进入属性:
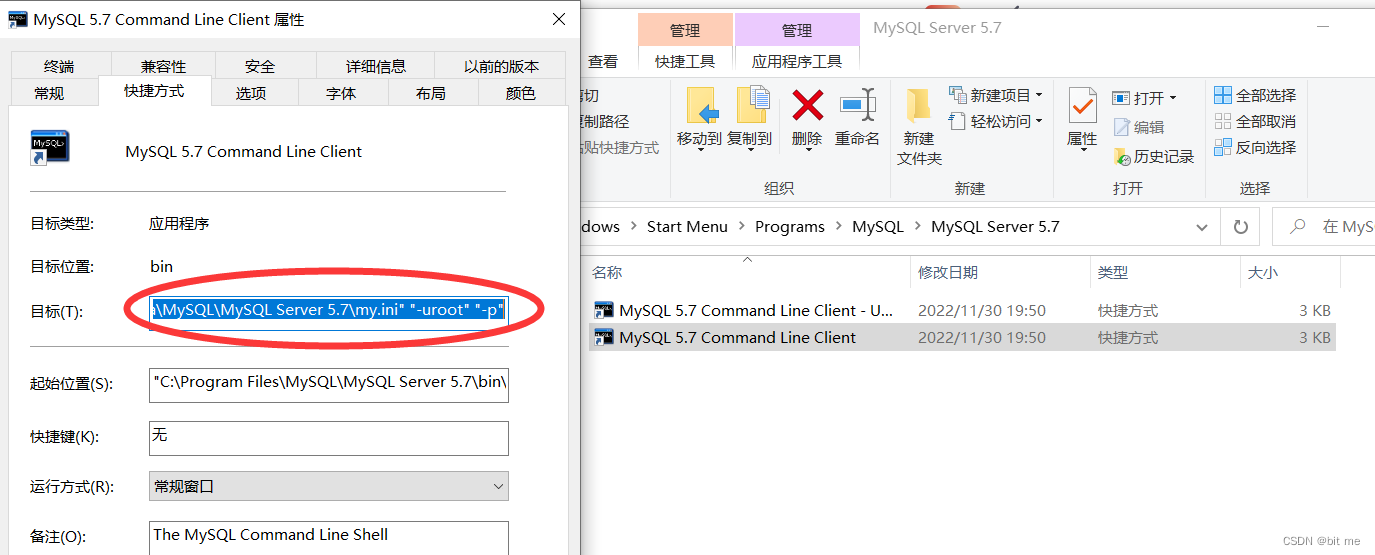
- 拷贝出目标里面的内容,这里就是MySQL的可执行程序路径和配置文件路径

- 把MySQL配置文件的位置复制过来
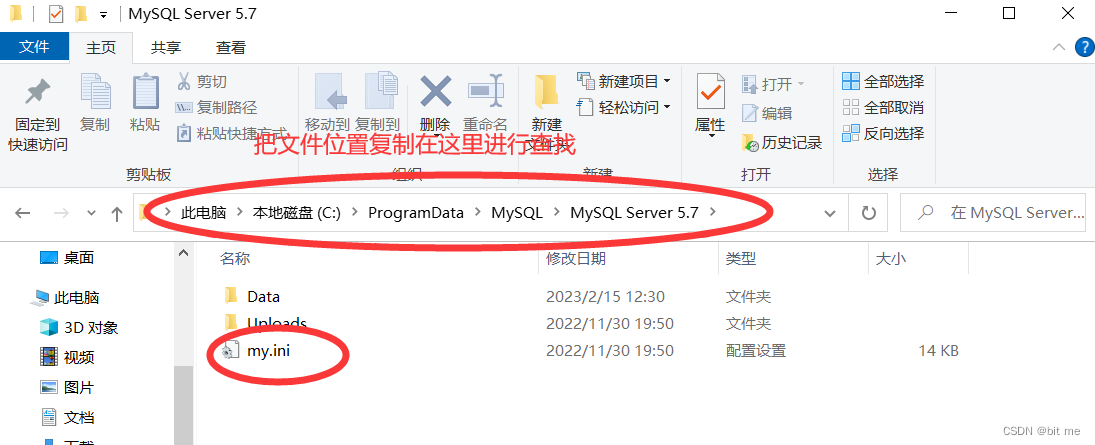
这就是我们要找的配置文件
- 修改配置文件
①:修改配置文件之前,一定要先备份!!!复制粘贴到旁边一份保存着,以免改错还原不回去了!!!
②:编辑ini文件,用记事本打开即可,找到下面没有#的地方,有#号的地方是注释
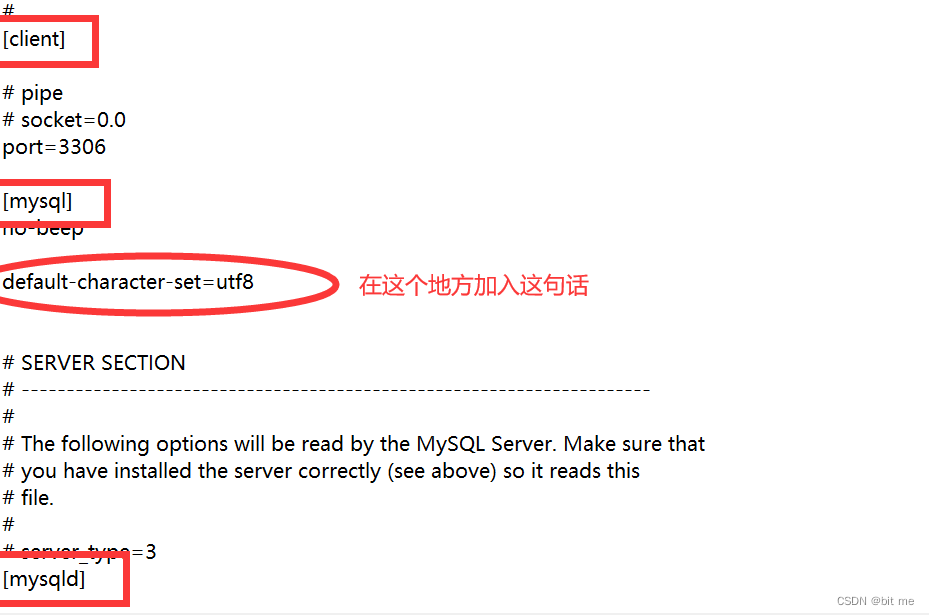
- ini文件中,有一些 [ ] ,每个 [ ] 称为是一个selection,相当于把一组功能有联系的配置放到了一起,构成了一个selection。
- 具体在[mysql]加入的那句话,那个配置项是按照键值对的方式来组织的,注意这里的键值对单词拼写,等于号俩边不要有空格。
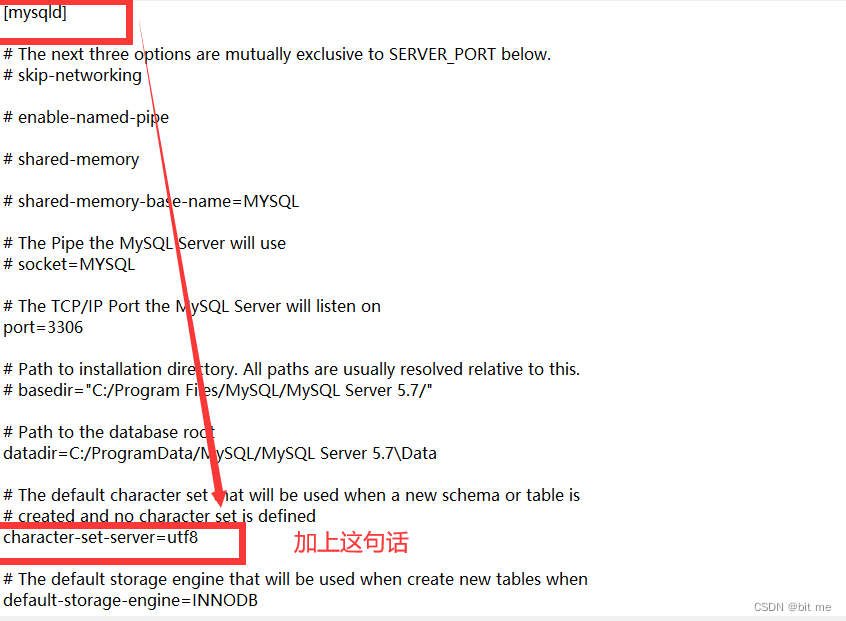
修改完成后记得保存(Ctrl + s)就可以退出了
- 配置文件不是修改完了就立即生效,还需要额外进行一些操作
①:重启MySQL服务器!不重启就不会生效!
- 重启服务器不是关闭黑框框(是客户端)
在我们的搜索里搜索服务,找到MySQL然后右键进行重启即可
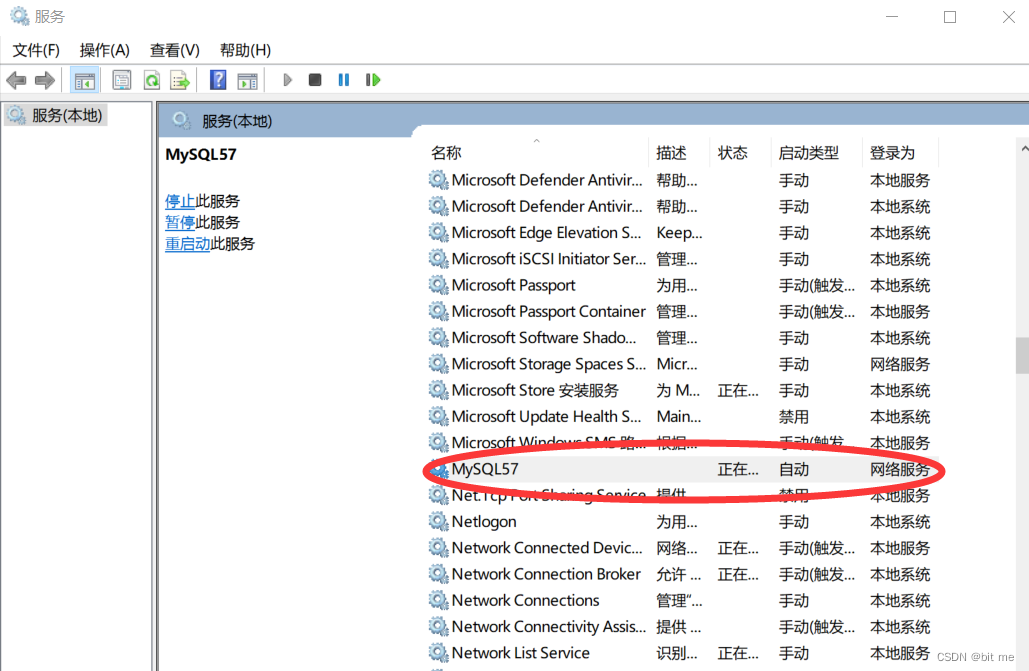
- 最后状态栏显示 " 正在运行 " 说明是重启成功的!!!
- 如果是其他内容(启动中…)则是重启失败,最大的原因就是配置文件修改错误
②:修改配置文件,对已经创建好的数据库是没有影响的,必须要删除旧的数据库,重建数据库表。
至此MySQL配置修改就彻底结束了,继续insert的探讨
insert插入的时候可以指定列进行插入,不一定非得把这一行的所有列都插入数据,可以想插入几列就插入几列
mysql> insert into student (name) values ("lisi");
Query OK, 1 row affected (0.00 sec)
如上我们在学生名字这一列插入list,其他未被插入(id)填入的值就是默认值,默认的默认值就是啥都不填,也就是NULL。
insert语句还可以一次插入多条记录,在values后面,带有多组(),每个()之间使用 , 来分割
mysql> insert into student values(1,"zhangsan"),(2,"lisi"),(3,"wangwu");
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
- 在MySQL中,一次插入一条记录分多次插入 比 一次插入多条记录慢的很多!!
- 原因是MySQL是一个客户端/服务器结构的程序,每次在客户端里输入的命令sql,都是通过网络来进行传输的。
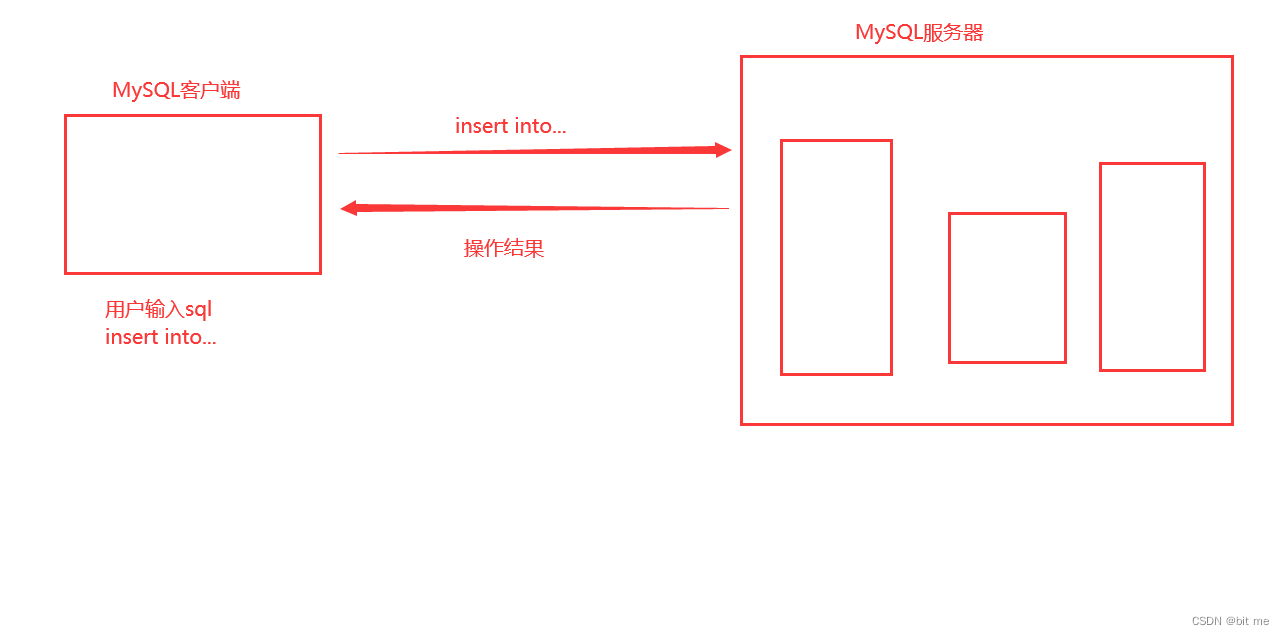
- 数据库服务器需要解析请求,获取到其中的sql,解析sql执行相关操作,并且把操作结果返回给客户端
- 如果要是一次插入一条,分成多次插入就会有多个请求/相应,如果要是一次插入多条,就一次请求/相应就够了
结语:插入是SQL中最简单的一个操作,也是最常用的一个操作
📚三. 查询(Retrieve)
查询是SQL中最最重要也最复杂的操作,此处先介绍一下最简单的查询
📙1. 全列查询
- 直接把整个表里面的数据都查询出来。
- select * from 表名;
其中*是通配符,表示匹配任意的列(所有的列)
mysql> select * from student;
+------+----------+
| id | name |
+------+----------+
| 1 | zhangsan |
| 2 | 张三 |
| NULL | list |
| 1 | zhangsan |
| 2 | lisi |
| 3 | wangwu |
+------+----------+
6 rows in set (0.00 sec)
注意理解这里的执行过程,牢记,客户端和服务器之间通过网络进行通信
这一组结果是通过网络返回的,最终呈现在客户端上,这些数据是服务器筛选得到的数据结果,客户端也是以表格的形式进行呈现,但是大家不要把客户端显示的这个表格视为是服务器上数据的本体,这个客户端上显示的表格是个“临时表”。
问题:如果当前数据库的数据特别多,执行上述select*会发生什么情况呢?
- 服务器要先读取磁盘,把这些数据都查询出来,再通过网卡把数据传输给客户端,由于数据量非常大,极有可能就把磁盘IO(input output)吃满,或者把网络带宽吃满。最直观的感受就是会感受到卡顿,至于卡多久,不明确!!!
在执行一些SQL的时候如果执行的时间比较长,随时可以按 Ctrl + c 来中断,以免造成不必要的损失
📘2. 指定列查询
- select 列名,列名,列名… from 表名;
mysql> select id from student;
+------+
| id |
+------+
| 1 |
| 2 |
| NULL |
| 1 |
| 2 |
| 3 |
+------+
6 rows in set (0.00 sec)
当我们省略掉一些不必要的列的时候,就可以节省大量的磁盘IO和网络带宽了
MySQL是客户端服务器结构的程序,在此处看到的这个表结果,也同样是 " 临时表 " 只是在客户端这里显示成这个样子,而不是说服务器上就真有一个这样的表,里面只存了id列。
select所有的操作结果都是临时表,都不会影响到数据库服务器原有的数据!!!
📗3. 查询带有表达式
- 让查询结果进行一些计算
select 表达式 from 表名;
- 创建一个新的表格:
mysql> create table exam_result (id int, name varchar(20), chinese decimal(3,1),math decimal(3,1), english decimal(3,1));
Query OK, 0 rows affected (0.01 sec)
decimal(3,1)表示的是三个数字长度,保留一位小时,如90.1,33.4
- 查看表格:
mysql> desc exam_result;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
| chinese | decimal(3,1) | YES | | NULL | |
| math | decimal(3,1) | YES | | NULL | |
| english | decimal(3,1) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
5 rows in set (0.00 sec)
- 插入数据:
mysql> INSERT INTO exam_result (id,name, chinese, math, english) VALUES-> (1,'唐三藏', 67, 98, 56),-> (2,'孙悟空', 87.5, 78, 77),-> (3,'猪悟能', 88, 98.5, 90),-> (4,'曹孟德', 82, 84, 67),-> (5,'刘玄德', 55.5, 85, 45),-> (6,'孙权', 70, 73, 78.5),-> (7,'宋公明', 75, 65, 30);
Query OK, 7 rows affected (0.00 sec)
Records: 7 Duplicates: 0 Warnings: 0
- 再次查询表格
mysql> select * from exam_result;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
+------+-----------+---------+------+---------+
7 rows in set (0.00 sec)
让每个人的语文成绩都加10分
mysql> select name,chinese + 10 from exam_result;
+-----------+--------------+
| name | chinese + 10 |
+-----------+--------------+
| 唐三藏 | 77.0 |
| 孙悟空 | 97.5 |
| 猪悟能 | 98.0 |
| 曹孟德 | 92.0 |
| 刘玄德 | 65.5 |
| 孙权 | 80.0 |
| 宋公明 | 85.0 |
+-----------+--------------+
7 rows in set (0.00 sec)
但是需要注意的是这里得到的结果都是 " 临时表 " ,对数据库服务器上面的数据是没有任何影响的!!!
再度查看表结构
mysql> select * from exam_result;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
+------+-----------+---------+------+---------+
7 rows in set (0.00 sec)
如果数据变化超过了decimal(3,1),就是出现了多位数结果的情况,临时表依旧会保证显示的结果是正确的,但是尝试往原始表中插入一个超出范围的数据就是不行的!!!
临时表当中的列完全取决于select指定的列名
📕4. 起别名查询
select 表达式 as 别名 from 表名;
如求语数英三科总分
mysql> select name, chinese + math + english from exam_result;
+-----------+--------------------------+
| name | chinese + math + english |
+-----------+--------------------------+
| 唐三藏 | 221.0 |
| 孙悟空 | 242.5 |
| 猪悟能 | 276.5 |
| 曹孟德 | 233.0 |
| 刘玄德 | 185.5 |
| 孙权 | 221.5 |
| 宋公明 | 170.0 |
+-----------+--------------------------+
7 rows in set (0.00 sec)
如上我们看到的总分表达不是很合理,不直观,我们可以对它起个别名
mysql> select name, chinese + english + math as total from exam_result;
+-----------+-------+
| name | total |
+-----------+-------+
| 唐三藏 | 221.0 |
| 孙悟空 | 242.5 |
| 猪悟能 | 276.5 |
| 曹孟德 | 233.0 |
| 刘玄德 | 185.5 |
| 孙权 | 221.5 |
| 宋公明 | 170.0 |
+-----------+-------+
7 rows in set (0.00 sec)
这样我们的表达就清晰明了
- 可以通过as指定别名,as也可以省略,但是个人建议写上
还有一些奇奇怪怪的表达式查询,如:
mysql> select 10 from exam_result;
+----+
| 10 |
+----+
| 10 |
| 10 |
| 10 |
| 10 |
| 10 |
| 10 |
| 10 |
+----+
7 rows in set (0.00 sec)
这样的SQL语句也可以执行,因为把10也当作是一个表达式(语法上没错,实际上没啥意义)
- 表达式查询,这里进行的计算,都是列和列之间的计算!!!而不是行和行之间的计算(行和行之间的计算有另外的方法)
📒5. 去重查询
- 把查询结果相同的行,合并成一个
select distinct 列名 from 表名;
比如他们各自数学成绩,有一个98.0重合的(上面数据没有重合,此处假设),进行去重查询之后就只剩下一个98.0
mysql> select distinct math from exam_result;
+------+
| math |
+------+
| 98.0 |
| 78.0 |
| 84.0 |
| 85.0 |
| 73.0 |
| 65.0 |
+------+
6 rows in set (0.00 sec)
- distinct 也可也以指定多个列,必须是多个列值完全相同的时候才会视为相同(才会去重)
我们在上面继续添加相同信息
mysql> insert into exam_result (name, math) values ('唐三藏', 98.0);
Query OK, 1 row affected (0.00 sec)
mysql> select * from exam_result;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
| NULL | 唐三藏 | NULL | 98.0 | NULL |
+------+-----------+---------+------+---------+
8 rows in set (0.00 sec)
对名字和数学列相同进行去重:
mysql> select distinct name, math from exam_result;
+-----------+------+
| name | math |
+-----------+------+
| 唐三藏 | 98.0 |
| 孙悟空 | 78.0 |
| 猪悟能 | 98.5 |
| 曹孟德 | 84.0 |
| 刘玄德 | 85.0 |
| 孙权 | 73.0 |
| 宋公明 | 65.0 |
+-----------+------+
7 rows in set (0.00 sec)
📔6. 排序查询
- 查询过程中,对于查询到的结果进行排序!(针对临时表排序,对于数据库上原来存的数据没有影响)
select 列名 from 表名 order by 列名;
- 按照语文成绩升序排序:
mysql> select * from exam_result order by chinese;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| NULL | 唐三藏 | NULL | 98.0 | NULL |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
+------+-----------+---------+------+---------+
8 rows in set (0.00 sec)
- 按照语文成绩降序排序:
mysql> select * from exam_result order by chinese desc;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| NULL | 唐三藏 | NULL | 98.0 | NULL |
+------+-----------+---------+------+---------+
8 rows in set (0.00 sec)
降序排序只需要在末尾加个 desc 即可,升序末尾是asc,但是升序是默认的,可以省略!
- order by 也可以针对带有别名的表达式进行排序
总成绩降序排序
mysql> select name, chinese + math + english as total from exam_result order by total desc;
+-----------+-------+
| name | total |
+-----------+-------+
| 猪悟能 | 276.5 |
| 孙悟空 | 242.5 |
| 曹孟德 | 233.0 |
| 孙权 | 221.5 |
| 唐三藏 | 221.0 |
| 刘玄德 | 185.5 |
| 宋公明 | 170.0 |
| 唐三藏 | NULL |
+-----------+-------+
8 rows in set (0.00 sec)
SQL中,如果拿 NULL 和其他类型进行混合运算,结果仍然是NULL
- order by 进行排序的时候,还可以指定多个列进行排序!
当指定多个列排序的时候,就相当于,先以第一个列为标准进行比较,如果第一列不分胜负,那么继续按照第二列进行比较,以此类推…
mysql> select * from exam_result order by math desc,chinese;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| NULL | 唐三藏 | NULL | 98.0 | NULL |
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
+------+-----------+---------+------+---------+
8 rows in set (0.00 sec)
select 操作中,如果没有使用 order by 那么查询结果顺序是不确定的,没有具体的标准进行排序
📓7. 条件查询
- 指定条件,对于查询结果进行筛选
select * from 表名 where 条件;
- 引入where字句,针对查询结果进行筛选。
- 筛选可以简单理解成,对于查询结果依次遍历,把对应的查询结果带入到条件中,条件成立,则把这个记录放到最终查询结果里,条件不成立,则直接舍弃,不作为最终结果。
- 比较运算符:
| 运算符 | 说明 |
|---|---|
| >,>=,<,<= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=,<> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN(option,…) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
- = 表示 =,不是赋值了,SQL中没有 ==
- SQL中,NULL = NULL 执行结果还是NULL,相当于FALSE。NULL <=> NULL 执行结果就是TRUE
- LIKE能进行模糊匹配,匹配的过程中可以带上通配符
- 逻辑运算符:
| 运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
注:
- WHERE条件可以使用表达式,但不能使用别名。
- AND的优先级高于OR,在同时使用时,需要使用小括号()包裹优先执行的部分
进行条件查询的时候,就是通过上述运算符组合最终完成的
①:基本查询
- 查询英语成绩不及格的人
mysql> select * from exam_result where english < 60;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
+------+-----------+---------+------+---------+
3 rows in set (0.00 sec)
条件查询,就是把表里的记录,挨个往条件中带入
- 查询语文成绩比英语成绩好的同学
mysql> select * from exam_result where chinese > english;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
+------+-----------+---------+------+---------+
5 rows in set (0.00 sec)
- 查询总分在200分以下的同学
mysql> select name, chinese + english + math as total from exam_result where chinese + math + english < 200;
+-----------+-------+
| name | total |
+-----------+-------+
| 刘玄德 | 185.5 |
| 宋公明 | 170.0 |
+-----------+-------+
2 rows in set (0.00 sec)
- 错误示例:
mysql> select name, chinese + english + math as total from exam_result where total < 200;
ERROR 1054 (42S22): Unknown column 'total' in 'where clause'
where 中,别名并不能作为筛选条件
②:and 与 or
- 查询语文大于80分并且英语也大于80分的同学
mysql> select * from exam_result where chinese > 80 and english > 80;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
+------+-----------+---------+------+---------+
1 row in set (0.00 sec)
- 查询语文大于80分或者英语大于80分的同学
mysql> select * from exam_result where chinese > 80 or english > 80;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
+------+-----------+---------+------+---------+
3 rows in set (0.00 sec)
- 如果一个条件中同时有 and 和 or ,先算 and 后算 or
mysql> select * from exam_result where chinese > 80 or english > 70 and math > 70;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
+------+-----------+---------+------+---------+
4 rows in set (0.00 sec)
加上括号之后就是先算括号里的
③:范围查询
- 查询语文成绩在80到90之间的同学
mysql> select * from exam_result where chinese >= 80 and chinese <= 90;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
+------+-----------+---------+------+---------+
3 rows in set (0.00 sec)mysql> select * from exam_result where chinese between 80 and 90;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
+------+-----------+---------+------+---------+
3 rows in set (0.00 sec)
- SQL进行条件查询的时候,需要遍历数据,带入条件,遍历操作在数据集合非常大的时候,是比较低效的,数据库内部会做出一些优化手段,尽可能避免遍历
- 在进行优化的时候,MySQL自身实现的一些行为相比于上述直接使用 and 来说,between and 是更好进行优化的
- 查询数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
mysql> select * from exam_result where math in (58,59,98,99);
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| NULL | bit me | NULL | 98.0 | NULL |
+------+-----------+---------+------+---------+
2 rows in set (0.00 sec)mysql> select * from exam_result where math = 58 or math = 59 or math = 98 or math = 99;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| NULL | bit me | NULL | 98.0 | NULL |
+------+-----------+---------+------+---------+
2 rows in set (0.00 sec)
④:模糊查询:LIKE
通过 like 来完成模糊查询,不一定完全相等,只要有一部分匹配即可
mysql> select * from exam_result where name like '孙%';
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
+------+-----------+---------+------+---------+
2 rows in set (0.00 sec)
%孙–>匹配以孙结尾的数据
%孙%–>匹配含孙的数据
%–>匹配任意数据
- 模糊查询中需要用到通配符:
%可以替代任意个字符,_可以用来替代任意一个字符(俩个下划线就代表俩个任意字符)
虽然数据库支持模糊匹配,但是使用中也要慎重使用模糊匹配。模糊匹配本身,其实是非常低效的,如果做成正则表达式这样效率就会更低。
⑤:NULL的查询
mysql> select * from exam_result;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
| NULL | 唐三藏 | NULL | 98.0 | NULL |
+------+-----------+---------+------+---------+
8 rows in set (0.00 sec)mysql> select * from exam_result where chinese = NULL;
Empty set (0.00 sec)mysql> select * from exam_result where chinese <=> NULL;
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| NULL | 唐三藏 | NULL | 98.0 | NULL |
+------+--------+---------+------+---------+
1 row in set (0.00 sec)mysql> select * from exam_result where chinese is NULL;
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| NULL | 唐三藏 | NULL | 98.0 | NULL |
+------+--------+---------+------+---------+
1 row in set (0.00 sec)
- 从上面三个式子查询 NULL 中可以看出
- 直接使用 = 来进行匹配是不能正确进行筛选的
- 使用 <=> 可以正确和 NULL 进行匹配
- 使用 is NULL 也是可以进行比较的
📰8. 分页查询
- 使用 limit 关键字,来进行限制返回的结果条数,使用 offset 来确定从第几条开始进行返回
select 列名 from 表名 limit N offset M;
select 列名 from 表名 limit M, N
- 从第 M 条开始查询,最多返回 N 条记录
mysql> select * from exam_result;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
| NULL | 唐三藏 | NULL | 98.0 | NULL |
+------+-----------+---------+------+---------+
8 rows in set (0.00 sec)mysql> select * from exam_result limit 3;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
+------+-----------+---------+------+---------+
3 rows in set (0.00 sec)mysql> select * from exam_result limit 3 offset 3;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
+------+-----------+---------+------+---------+
3 rows in set (0.00 sec)mysql> select * from exam_result limit 3 offset 6;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
| NULL | 唐三藏 | NULL | 98.0 | NULL |
+------+-----------+---------+------+---------+
2 rows in set (0.00 sec)
- 查询总分前三成绩的同学
mysql> select name, chinese + english + math as total from exam_result order by total desc limit 3;
+-----------+-------+
| name | total |
+-----------+-------+
| 猪悟能 | 276.5 |
| 孙悟空 | 242.5 |
| 曹孟德 | 233.0 |
+-----------+-------+
3 rows in set (0.00 sec)
select * 这样的操作,容易把数据库弄挂了,除了 select * 之外,只要你返回的记录足够多哪怕用了其他方式查询,也是同样有风险的,即使你加上 where 条件筛选,万一筛选的结果很多,还是会弄坏服务器,最稳妥的办法就是加上 limit 。
🔐四. 修改(Update)
- 此处的修改,是针对数据库服务器进行的,这里的修改是持续有效的
update 表名 set 列名 = 值… where 子句
- 核心信息:针对哪个表,的哪些行,的哪些列,改成啥样的值。
把孙悟空数学成绩修改为80分
mysql> update exam_result set math = 80 where name = '孙悟空';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from exam_result;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 80.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
| NULL | 唐三藏 | NULL | 98.0 | NULL |
+------+-----------+---------+------+---------+
8 rows in set (0.00 sec)
将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
mysql> update exam_result set chinese = 70, math = 60 where name = '曹孟德';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from exam_result;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 80.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 70.0 | 60.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
| NULL | 唐三藏 | NULL | 98.0 | NULL |
+------+-----------+---------+------+---------+
8 rows in set (0.00 sec)
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分(先查明成绩总单)
mysql> select name, chinese + english + math as total from exam_result order by total;
+-----------+-------+
| name | total |
+-----------+-------+
| 唐三藏 | NULL |
| 宋公明 | 170.0 |
| 刘玄德 | 185.5 |
| 曹孟德 | 197.0 |
| 唐三藏 | 221.0 |
| 孙权 | 221.5 |
| 孙悟空 | 244.5 |
| 猪悟能 | 276.5 |
+-----------+-------+
8 rows in set (0.00 sec)mysql> update exam_result set math = math + 30 order by chinese + english + math limit 3;
ERROR 1264 (22003): Out of range value for column 'math' at row 1
发现出现了错误,原因就是有数学加30超出了合理范围,但是可以减去30(不能写成 math += 30)
update 后面的条件很重要,修改操作是针对条件筛选之后对剩下的数据进行的修改,如果没写条件,意味着就是对所以行都进行修改!!!
update 也是一种比较危险的操作,除了提前备份就基本无法还原改前数据!!!
🔏五. 删除(Delete)
- 删除符合条件的行
delete from 表名 where 条件;
delete from 表名; --> 把表里的记录都删除了,表只剩下一个空的表了
- 删除唐三藏的信息
mysql> delete from exam_result where name = '唐三藏';
Query OK, 1 row affected (0.00 sec)mysql> select * from exam_result;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 2 | 孙悟空 | 87.5 | 80.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 70.0 | 60.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
+------+-----------+---------+------+---------+
6 rows in set (0.00 sec)
- 删除表里的内容,表还存在!!!
mysql> delete from exam_result;
Query OK, 7 rows affected (0.00 sec)mysql> select * from exam_result;
Empty set (0.00 sec)
drop table 是把整个表都干掉了
相关文章:
【MySQL】MySQL表的增删改查(CRUD)
✨个人主页:bit me👇 ✨当前专栏:MySQL数据库👇 ✨算法专栏:算法基础👇 ✨每日一语:生命久如暗室,不碍朝歌暮诗 目 录🔓一. CRUD🔒二. 新增(Creat…...

GCC for openEuler 数据库性能优化实践
GCC for openEuler是基于开源GCC开发的编译器工具链(包含编译器,汇编器,链接器),在openEuler社区开源发布,并通过鲲鹏社区免费提供二进制包,支持aarch64处理器架构。 关键特性 支持鲲鹏微架构芯…...

【C++】类和对象(第二篇)
文章目录1. 类的6个默认成员函数2. 构造函数2.1 构造函数的引出2.2 构造函数的特性3. 析构函数3.1 析构函数的引出3.2 析构函数的特性4. 拷贝构造函数4.1 概念4.2 特性5.赋值运算符重载5.1 运算符重载概念注意练习5.2 赋值重载实现赋值重载的特性6. const成员函数7. 取地址及co…...

MySQL数据库(数据库约束)
目录 数据库约束 数据库约束的类型: null约束 : unique约束(唯一约束): default约束(默认值约束): primary key约束(主键约束): for…...
Hive的安装与配置
一、配置Hadoop环境先看看伪分布式下的集群环境有没有错误的情况:输入命令:start-all.sh jps查看伪分布式的所有进程是否完善二、解压并配置HiveHive压缩包→ https://pan.baidu.com/s/1eOF_ICZV8rV-CEh3nX-7Xw 提取码: m31e 复制这段内容后打开百度网盘…...

关于医院医用医疗隔离电源系统应用案例的分析探讨
【摘要】:介绍该三级医院采用安科瑞医用隔离电源柜,使用落地式安装方式,从而实现将TN系统转化为IT系统,同时监测系统绝缘情况。 【关键词】医用隔离电源柜;IT系统;绝缘情况;中西医结合医院&…...
【LeetCode】剑指 Offer 07. 重建二叉树 p62 -- Java Version
题目链接:https://leetcode.cn/problems/zhong-jian-er-cha-shu-lcof/ 1. 题目介绍(07. 重建二叉树) 输入某二叉树的前序遍历和中序遍历的结果,请构建该二叉树并返回其根节点。 假设输入的前序遍历和中序遍历的结果中都不含重复的…...

ERROR 1114 (HY000): The table ‘tt2‘ is full
insert 操作时提示is full 问题原因 rootlocalhost 11:55:41 [t]>show table status from t like ‘tt2’ \G ; *************************** 1. row *************************** Name: tt2 Engine: MEMORY Version: 10 Row_format: Fixed Rows: 7056 Avg_row_length: 944…...
考了PMP证后工资大概是多少 ?(含pmp资料)
这个岗位的不同还有每个公司的薪资也是不一样的,具体的数字肯定是没有的,但大概的比例还是有的,据PMI调查,在获得PMP证书的人当中,在PMP认证一年后,年薪有所增长的比例为66%,上涨幅度主要集中在…...
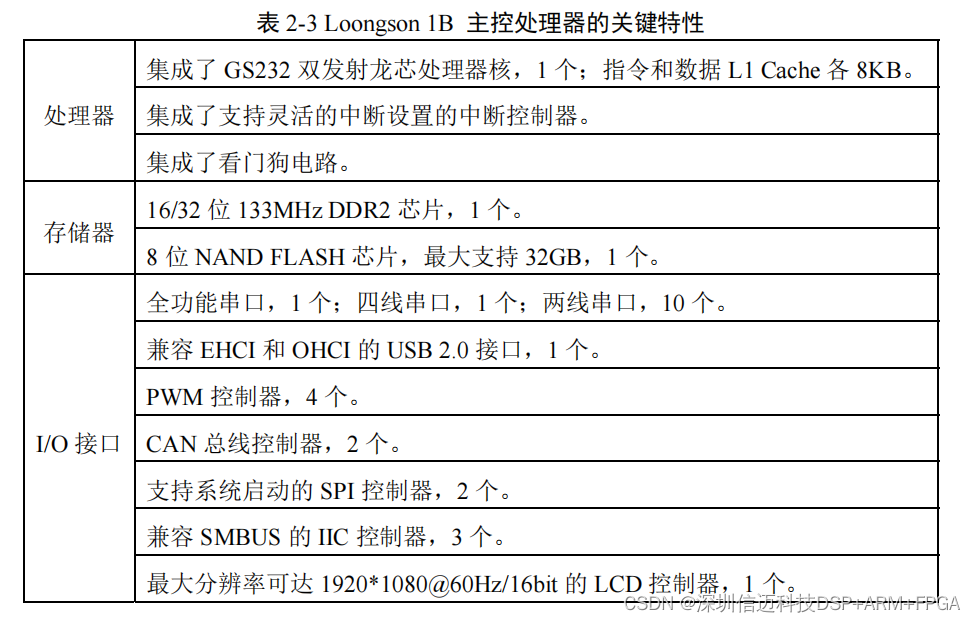
基于国产龙芯 CPU 的气井工业网关研究与设计(一)
当前,我国气田的自动化控制程度还未完全普及,并且与世界已普及的气井站的自 动化程度也存在一定的差距。而在天然气资源相对丰富的国家,开采过程中设备研发资 金投入较大,研发周期较长,更新了一代又一代的自动化开采系…...
40/365 javascript 数据类型
1.数据类型 number类型:整数,小数都属于这一类,不具体区分 字符串:hello, "hello" 布尔类型:true,false 逻辑运算符: && || ! 比较运算符: : 类型不一致&#x…...

后勤管理系统—服务台管理功能
数图互通是一家IT类技术型软件科技公司,专业的不动产、工作场所、空间、固定资产、设备家具、设施运维及可持续性管理解决方案软件供应商。 一、后勤管理系统服务台管理功能包含: 1、专业自动化、集中管理的自助服务助理,随时响应服务请求。…...

Spring Boot 是什么,应该如何学习,有哪些优缺点
1、Spring Boot 是什么? Spring Boot是一个基于Spring框架的开源项目,它简化了Spring应用程序的开发过程,提供了一种快速、便捷、可扩展的方式来构建Spring应用程序。 Spring Boot通过自动化配置机制简化了Spring应用程序的配置过程&#x…...
使用yolov5和强化学习训练一个AI智能欢乐斗地主(一)
这里写自定义目录标题项目介绍项目过程介绍训练yolov5目标检测斗地主收集数据集yolov5调参项目介绍 你好! 欢迎阅读我的文章,本章将介绍,如何使用yolov5和强化学习训练一个AI斗地主,本项目将分为三个部分,其中包含&am…...

C++ 浅谈之 AVL 树和红黑树
C 浅谈之 AVL 树和红黑树 HELLO,各位博友好,我是阿呆 🙈🙈🙈 这里是 C 浅谈系列,收录在专栏 C 语言中 😜😜😜 本系列阿呆将记录一些 C 语言重要的语法特性 dz…...

【Kotlin】Kotlin函数那么多,你会几个?
目录标准函数letrunwithapplyalsotakeIftakeUnlessrepeat小结作用域函数的区别作用域函数使用场景简化函数尾递归函数(tailrec)扩展函数高阶函数内联函数(inline)inlinenoinlinecrossinline匿名函数标准函数 Kotlin标准库包含几个…...
饲养员喂养动物-课后程序(JAVA基础案例教程-黑马程序员编著-第四章-课后作业)
【案例4-2】饲养员喂养动物 记得 关注,收藏,评论哦,作者将持续更新。。。。 【案例目标】 案例描述 饲养员在给动物喂食时,给不同的动物喂不同的食物,而且在每次喂食时,动物都会发出欢快的叫声。例如&…...
数据分析:消费者数据分析
数据分析:消费者数据分析 作者:AOAIYI 创作不易,如果觉得文章不错或能帮助到你学习,记得点赞收藏评论一下哦 文章目录数据分析:消费者数据分析一、前言二、数据准备三、数据预处理四、个体消费者分析五、用户消费行为总…...

Transformer论文阅读:ViT算法笔记
标题:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 会议:ICLR2021 论文地址:https://openreview.net/forum?idYicbFdNTTy 文章目录Abstract1 Introduction2 Related Work3 Method3.1 Vision Transformer3.2…...

Android基础练习解答【2】
文章目录一 填空题二 判断题三 选择题四 简答题一 填空题 1.除了开启开发者选项之外,还需打开手机上的 usb调试 开关,然后才能在手机上调试App。 2.App开发的两大技术路线包括 _原生开发_和混合开发。 3.App工程的编译…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

网站指纹识别
网站指纹识别 网站的最基本组成:服务器(操作系统)、中间件(web容器)、脚本语言、数据厍 为什么要了解这些?举个例子:发现了一个文件读取漏洞,我们需要读/etc/passwd,如…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...

机器学习的数学基础:线性模型
线性模型 线性模型的基本形式为: f ( x ) ω T x b f\left(\boldsymbol{x}\right)\boldsymbol{\omega}^\text{T}\boldsymbol{x}b f(x)ωTxb 回归问题 利用最小二乘法,得到 ω \boldsymbol{\omega} ω和 b b b的参数估计$ \boldsymbol{\hat{\omega}}…...
2025-06-01-Hive 技术及应用介绍
Hive 技术及应用介绍 参考资料 Hive 技术原理Hive 架构及应用介绍Hive - 小海哥哥 de - 博客园https://cwiki.apache.org/confluence/display/Hive/Home(官方文档) Apache Hive 是基于 Hadoop 构建的数据仓库工具,它为海量结构化数据提供类 SQL 的查询能力…...

第6章:Neo4j数据导入与导出
在实际应用中,数据的导入与导出是使用Neo4j的重要环节。无论是初始数据加载、系统迁移还是数据备份,都需要高效可靠的数据传输机制。本章将详细介绍Neo4j中的各种数据导入与导出方法,帮助读者掌握不同场景下的最佳实践。 6.1 数据导入策略 …...

前端异步编程全场景解读
前端异步编程是现代Web开发的核心,它解决了浏览器单线程执行带来的UI阻塞问题。以下从多个维度进行深度解析: 一、异步编程的核心概念 JavaScript的执行环境是单线程的,这意味着在同一时间只能执行一个任务。为了不阻塞主线程,J…...
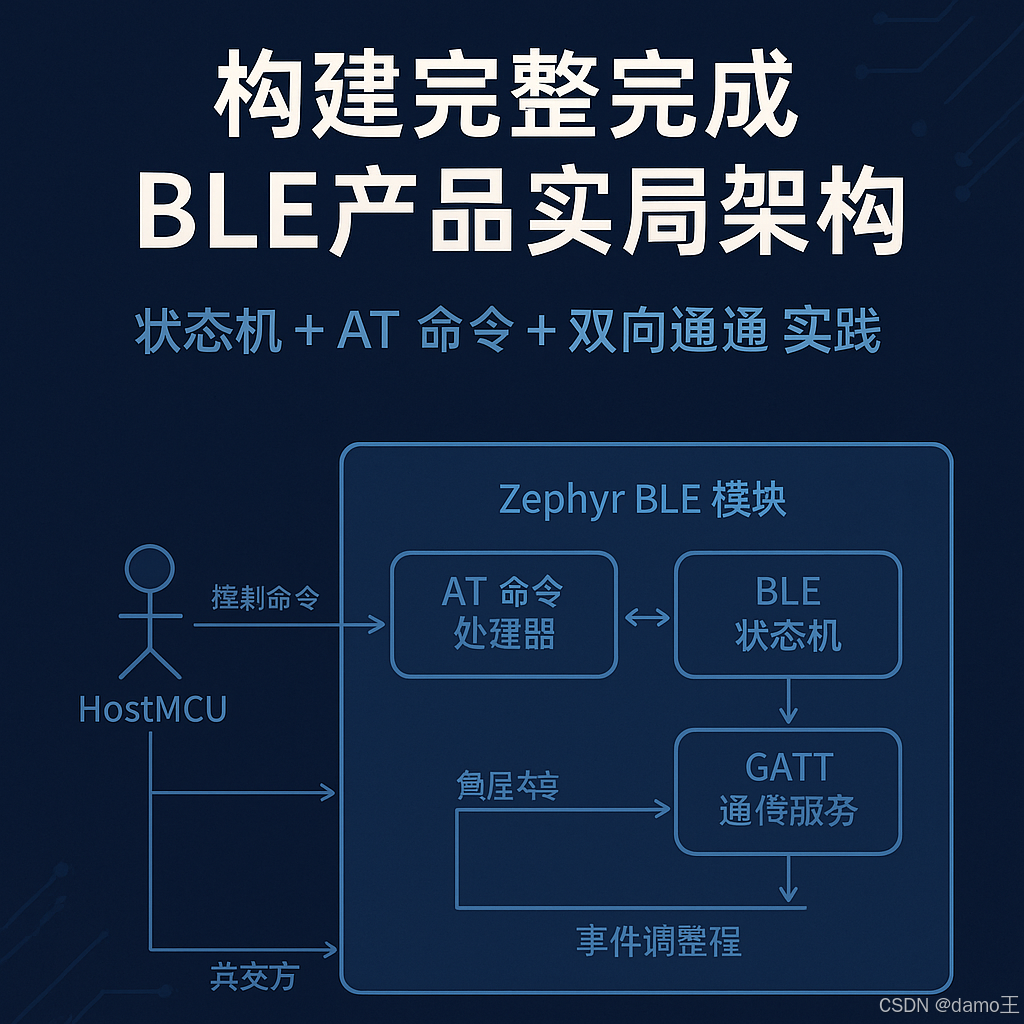
【Zephyr 系列 8】构建完整 BLE 产品架构:状态机 + AT 命令 + 双通道通信实战
🧠关键词:Zephyr、BLE、状态机、双向透传、AT 命令、Buffer、主从共存、系统架构 📌适合人群:希望开发 BLE 产品(模块/标签/终端)具备可控、可测、可维护架构的开发者 🧭 引言:从“点功能”到“系统架构” 前面几篇我们已经逐步构建了 BLE 广播、连接、数据透传系统…...