Apache Kafka 入门教程
Apache Kafka 入门教程
- 一、简介
- 简介
- 架构
- 二、Kafka 安装和配置
- JDK
- 安装 Kafka
- 配置文件详解
- 三、Kafka 的基本操作
- 启动和关闭
- Topic 创建和删除
- Partitions 和 Replication 配置
- Producer 和 Consumer 使用方法
- Producer
- Consumer
- 四、Kafka 高级应用
- 消息的可靠性保证
- Kafka Stream
- Kafka Connect
- 五、Kafka 集群管理
- 集群环境的部署
- 操作和维护集群
- 监控和告警
- 消息备份和恢复
- 热点问题处理
- 集群扩容和缩容
- 扩容操作
- 缩容操作
- 六、应用案例
- 日志收集
- 数据同步
- 实时处理
- 七、优化调优
- 性能指标优化
- 参数配置优化
- 架构设计优化
一、简介
简介
Apache Kafka 是由 Apache 软件基金会开发的一个开源流处理平台,用于处理实时的大规模数据流。Kafka 的目标是为了处理活跃的流式数据,包括传感器数据,网站日志,应用程序内部的消息,等等。它可以处理成千上万的消息,并让你迅速地处理和存储这些消息。在 Kafka 中,生产者负责将消息发送到 Kafka 集群中的 Broker,消费者则从 Broker 订阅并接收消息。
架构
Kafka 的架构由 Producer,Broker 和 Consumer 三部分组成,同时具备高并发、高吞吐量和分布式等特点。Producer 可以将消息发送到 Broker,Consumer 可以从 Broker 订阅和接收消息,而 Broker 则可以存储多个 Topic。一个 Topic 可以有多个 Partition,Partition 中的消息可以通过 Offset 进行管理,Kafka 中的消息以 Append-only 形式进行存储。
二、Kafka 安装和配置
JDK
- 下载 JDK,例如:jdk-8u291-linux-x64.tar.gz。
- 解压 JDK 到任意目录,例如 /usr/lib/jvm/jdk1.8.0_291。
- 配置环境变量,例如:
$ export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_291$ export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH$ export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
安装 Kafka
- 下载 Kafka,例如:kafka_2.12-2.8.0.tgz。
- 解压 Kafka 到任意目录,例如 /opt/kafka。
- 修改配置文件,根据需要修改 server.properties 文件。
配置文件详解
Kafka 的配置文件位于 config/server.properties。下面是一些常用的配置项及其含义:
- broker.id,Broker 的唯一标识符。
- advertised.listeners,监听该 Broker 的客户端连接地址和端口。
- log.dirs,消息存储文件目录。
- zookeeper.connect,使用的 ZooKeeper 地址和端口。
- num.network.threads,用于处理网络请求的线程数。
- num.io.threads,用于处理磁盘 IO 的线程数。
- socket.receive.buffer.bytes 和 socket.send.buffer.bytes,用于控制 TCP 缓冲区大小。
- group.initial.rebalance.delay.ms,当 Consumer Group 内有 Consumer 加入或离开时,延迟多久再开始重新 balabce。
- auto.offset.reset,Consumer Group 在消费新的 Topic 或 Partition 时的 offset 已经不存在时,如何设置 offset,默认是 latest。
三、Kafka 的基本操作
启动和关闭
//启动Kafka
$KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_HOME/config/server.properties//关闭Kafka
$KAFKA_HOME/bin/kafka-server-stop.sh
Topic 创建和删除
import kafka.admin.AdminUtils;
import kafka.utils.ZkUtils;//创建Topic
String topicName = "test";
int numPartitions = 3;
int replicationFactor = 2;
Properties topicConfig = new Properties();
AdminUtils.createTopic(zkUtils, topicName, numPartitions, replicationFactor, topicConfig);//删除Topic
AdminUtils.deleteTopic(zkUtils, topicName);
Partitions 和 Replication 配置
可以在创建Topic时指定Partitions数和Replication Factor,如果需要修改可以通过以下命令修改:
//修改Partitions数
bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic test --partitions 4//修改Replication Factor
bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic test --replication-factor 3
Producer 和 Consumer 使用方法
Producer
import org.apache.kafka.clients.producer.*;Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)producer.send(new ProducerRecord<String, String>("test", Integer.toString(i), Integer.toString(i)));producer.close();
Consumer
import org.apache.kafka.clients.consumer.*;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");Consumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("test"));
while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records)System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
四、Kafka 高级应用
消息的可靠性保证
在 Kafka 中消息的可靠性保证是通过两种机制来实现的:支持副本机制和 ISR (In-Sync Replicas)列表。
-
支持副本机制
副本机制是指一个主题(Topic)下的分区(Partition)可以有多个副本,每个副本都存储了完整的消息,其中一个副本被指定为 leader 副本,其他副本为 follower 副本。当 producer 发送消息到某个分区时,只需要发送给 leader 副本,leader 副本再将消息分发给其他 follower 副本,这样就保证了消息的可靠性。即使某个 follower 副本出现了故障,也不会影响消息的消费,因为其他副本依然存放着完整的消息。 -
ISR (In-Sync Replicas)列表
ISR 列表是指当前与 leader 副本保持同步的所有 follower 副本构成的列表。当某个 follower 副本落后于 leader 副本时,会从 ISR 列表中移除,直到追上 leader 副本后再加入到 ISR 列表中。这个机制保证了 Kafka 集群的高可用性,同时也保证了消息的可靠性。 -
At least once 语义
Kafka 默认保证的是 At least once 语义,即 “至少处理一次”,这种语义可以通过消息的重复消费来保证,但是会带来处理效率的损失。如果希望保证消息仅被处理一次,可以选择使用幂等性(Idempotence)或事务机制。
Kafka Stream
Kafka Stream 是 Kafka 生态系统中基于流处理模型的一个库。它充分利用了 Kafka 的优点,比如高吞吐、扩展性好、可靠性高等,支持实时的数据流处理和批量处理,并且操作符也非常丰富。
-
Stream 流处理模型
Stream 流处理模型是一种将输入数据流转换为输出数据流的模型,可以完成实时的数据处理。在 Kafka Stream 中,数据流由一个一个记录(Record)组成,每个记录由一个键(Key)和一个值(Value)构成。通过对 Stream 流处理模型的熟练掌握,可以快速开发出高效、高可靠性的流处理程序。 -
操作符详解
操作符是 Kafka Stream 中最核心的概念,是用于转换数据流的最基本单元。Kafka Stream 提供了丰富的操作符,包括过滤器、映射器、聚合器、分组器等,开发者可以根据需要灵活选择。其中,映射器和聚合器是最常用的操作符,它们可以完成对数据流的各种处理和转换。
Kafka Connect
Kafka Connect 是 Kafka 生态系统中用于将数据集成到和从 Kafka 中的工具。它通过 Connector 来实现数据的传输,Kafka Connect 可以集成各种数据源和数据目的地,如文件、数据库、消息队列等。使用 Kafka Connect 可以快速的完成数据的导入和导出,并且可以实现数据的有效管理和监控。
-
Connector 快速入门教程
Kafka Connect 的使用非常简单,只需要编写一个 Connector 配置文件,然后启动 Kafka Connect 进程即可。在 Connector 的配置文件中,需要指定数据源和数据目的地的配置信息,并定义如何从数据源中读取数据,以及如何将数据发送到数据目的地中。 -
实现自定义 Connect
如果 Kafka Connect 自带的 Connector 不能满足需求,开发者还可以自定义 Connector 来实现数据的导入和导出。开发者可以参考 Kafka Connect 源码中已经实现的 Connector 来进行开发,并根据需要完善自己的 Connector 功能。通过自定义 Connector,开发者可以灵活定制符合自己业务需求的数据接入方案。
五、Kafka 集群管理
集群环境的部署
为了部署 Kafka 集群,可以按如下步骤进行:
- 确保集群所有节点的操作系统都是一致的,建议使用 CentOS 7。
- 下载并配置 JDK,Kafka 依赖于 Java 运行环境。
- 下载 Kafka 安装包,解压到指定目录。
- 修改 Kafka 配置文件
server.properties,需要注意的配置项包括以下几个:broker.id:表示当前节点的 ID,必须在所有节点中唯一。listeners:用于设置 Kafka 绑定的地址和端口,其中端口号需要在每个节点上都是唯一的。建议使用 IP 地址而非主机名作为监听地址。log.dirs:表示消息日志保存的路径,建议为每个节点分别设置,避免多个节点共用一个目录导致数据混乱。zookeeper.connect:表示 ZooKeeper 的连接地址,ZooKeeper 是 Kafka 集群的重要组件。
操作和维护集群
Kafka 集群的运维主要包括以下几个方面:
监控和告警
Kafka 集群应该具备完善的监控和告警机制,能够及时检测和处理集群中的异常情况,防止集群的宕机或数据丢失等问题。通常使用开源监控系统,如 Prometheus、Grafana。
消息备份和恢复
为了防止消息丢失,Kafka 集群需要配置合适的备份策略,保证消息能够在系统故障或数据中心故障时依然可用。具体可以采用多副本备份策略或异地多活等方式来备份数据,也可以使用相关的数据备份工具。
热点问题处理
如果集群出现消费热点问题,需要及时排查,可以使用 Kafka 自带的 Consumer Lag 工具或第三方工具进行分析,找出出现热点的原因并制定相应的解决方案。
集群扩容和缩容
当 Kafka 集群无法满足业务需求或需要优化性能时,我们可能需要对集群进行扩容或缩容操作。
扩容操作
扩容可通过增加节点数量和调整多个配置项来进行:
- 增加节点数量:新增节点需要与集群中的其它节点具有相同的环境配置,包括操作系统和 Java 版本等。新增节点后需要更新
server.properties文件,并重启 Kafka 进程才能让新节点生效。同时需要重新分配分区并执行数据迁移。 - 调整多个配置项:可以通过调整消息生产和消费的吞吐量、扩容 Broker 的资源、增加副本数等一系列操作来提升 Kafka 集群的性能。
缩容操作
缩容可通过减少节点数量和删除多个配置项来进行:
- 减少节点数量:需要首先确认是否有冗余的节点存在,如果存在冗余节点可以将其停机或从集群中移除。同时需要更新
server.properties文件,并重启 Kafka 进程才能让缩容生效。需要注意的是,在进行节点缩容时需要重新分配分区和执行数据迁移。 - 删除多个配置项:可以通过调整消息保留时间、削弱单个 Broker 的吞吐量等一系列操作来缩小 Kafka 集群的规模。
在进行扩容和缩容操作前,需要通过合适的监控工具了解当前集群的状态和性能表现,根据实际需求进行配置和调整。同时使用备份策略,确保数据的完整性和可用性。
六、应用案例
日志收集
Kafka 作为一个分布式的消息队列,其在日志收集方面能够做到高效、可靠且低延迟的处理。以下是一个简单的 Java 代码示例,用于将系统日志发送到 Kafka 集群中:
import org.apache.kafka.clients.producer.*;
import java.util.Properties;public class KafkaLogProducer {private final KafkaProducer<String, String> producer;private final String topic;public KafkaLogProducer(String brokers, String topic) {Properties prop = new Properties();// 配置 Kafka 集群地址prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);// 配置 key 和 value 的序列化器prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");this.producer = new KafkaProducer(prop);this.topic = topic;}public void sendLog(String message) {producer.send(new ProducerRecord<>(topic, message));}public void close() {producer.close();}
}
数据同步
Kafka 除了可以作为日志收集的工具之外,还可以用于数据同步。使用 Kafka 可以将数据从一个系统复制到另一个系统,并且可以实现异步和批量处理。以下是一个简单的 Java 代码示例,用于把数据从源数据库同步到目标数据库:
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.clients.producer.*;
import java.sql.*;
import java.util.Properties;public class KafkaDataSync {private final KafkaConsumer<String, String> consumer;private final KafkaProducer<String, String> producer;private final String sourceTopic;private final String targetTopic;public KafkaDataSync(String brokers, String sourceTopic, String targetTopic) {Properties prop = new Properties();// 配置 Kafka 集群地址prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);// 配置 key 和 value 的序列化器prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");this.producer = new KafkaProducer(prop);// 配置消费者组Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);props.put(ConsumerConfig.GROUP_ID_CONFIG, "group1");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");consumer = new KafkaConsumer(props);consumer.subscribe(Arrays.asList(sourceTopic));this.sourceTopic = sourceTopic;this.targetTopic = targetTopic;}public void start() throws SQLException {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {String message = record.value();// 将数据解析并同步到目标数据库syncData(message);}}}public void close() {consumer.close();producer.close();}private void syncData(String message) {// 数据同步逻辑代码// ...// 将同步后的数据发送到目标 Kafka Topic 中producer.send(new ProducerRecord<>(targetTopic, message));}}
实时处理
Kafka 作为一个分布式流处理平台,具有强大的实时处理能力。可以支持多种实时计算框架和处理引擎,例如 Apache Storm、Apache Flink 和 Apache Spark 等。以下是一个简单的 Kafka 流处理代码示例,用于统计指定时间范围内的日志数量:
import org.apache.kafka.streams.*;
import org.apache.kafka.streams.kstream.*;
import java.util.Properties;public class KafkaStreamProcessor {public static void main(String[] args) {Properties props = new Properties();// 配置 Kafka 集群地址props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");// 配置 key 和 value 的序列化器和反序列化器props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());StreamsBuilder builder = new StreamsBuilder();KStream<String, String> messages = builder.stream("logs");// 统计指定时间范围内的日志数量KTable<Windowed<String>, Long> logsCount = messages.mapValues(log -> 1).groupByKey().windowedBy(TimeWindows.of(Duration.ofMinutes(5))).count();logsCount.toStream().foreach((key, value) -> System.out.println(key.toString() + " -> " + value));KafkaStreams streams = new KafkaStreams(builder.build(), props);streams.start();}
}
七、优化调优
性能指标优化
Kafka 集群的性能受多种因素影响,为了提高 Kafka 集群的性能,需要关注以下几个重要的性能指标:
- 消息吞吐量(Message throughput):指 Kafka 集群每秒能够处理的消息数量,这取决于硬件配置、网络和磁盘速度、消息大小和复杂度等因素。
- 延迟(Latency):指消息从生产者发送到被消费者接收到的时间间隔,这主要取决于网络延迟和磁盘 I/O 性能。
- 磁盘使用率(Disk utilization):指 Kafka 集群磁盘空间使用情况,如果磁盘使用率过高,可能会导致性能下降甚至堆积。
- 网络带宽(Network bandwidth):指 Kafka 集群节点之间的网络传输速度,如果带宽不足,可能会限制消息吞吐量和延迟。
参数配置优化
Kafka 集群的性能受多个参数的影响,为了优化 Kafka 集群的性能,需要考虑以下几个关键参数:
- 分区数量(number of partitions):分区数对于 Kafka 集群的性能至关重要,它决定了消息并行处理的能力。在平衡并行处理和分布式存储之间做出权衡是至关重要的。
- 复制因子(replication factor):Kafka 提供了副本机制来保证数据的可靠性,增加副本机制可以提高容错能力,但也会增加网络负载和磁盘使用率。副本因子的选择应该根据数据的关键程度和集群的需求进行调整。
- 批量大小(batch size):批量发送和接收消息是优化 Kafka 吞吐量的一个重要方法。较大的批量大小可以减少网络传输和 I/O 操作的数量,从而提高吞吐量。同时,较大的批量大小也会使得消息的延迟增大,需要做好权衡。
- 最大连接数(maximum connections):Kafka 服务器使用一次处理一个连接的方式,因此连接上限对于 Kafka 集群性能而言非常重要。过多的连接可能会导致服务器资源不足,从而造成性能的下降。
架构设计优化
为了进一步提高 Kafka 集群的性能和可靠性,需要对集群的系统架构进行优化。以下是一些常用的系统架构优化方法:
- 添加缓存层(Add a caching layer):使用缓存将频繁访问的数据存储到内存中,可以减少 I/O 负载,加速数据访问。
- 数据压缩(Use data compression):在 Kafka 集群中使用消息压缩算法,可以大幅减少网络传输和磁盘写入。
- 垂直扩展和水平扩展(Vertical and horizontal scaling):通过增加节点或者增加机器来扩展 Kafka 集群的规模,从而提高其性能和容错能力。
- 异地多活(Geo-replication):将多个 Kafka 集群分布在不同地理位置,通过异地多活技术实现数据冗余,提高数据的可用性。
相关文章:

Apache Kafka 入门教程
Apache Kafka 入门教程 一、简介简介架构 二、Kafka 安装和配置JDK安装 Kafka配置文件详解 三、Kafka 的基本操作启动和关闭Topic 创建和删除Partitions 和 Replication 配置Producer 和 Consumer 使用方法ProducerConsumer 四、Kafka 高级应用消息的可靠性保证Kafka StreamKaf…...
python皮卡丘编程代码教程,用python打印皮卡丘
大家好,小编来为大家解答以下问题,如何用print函数打印一只皮卡丘,用python如何打印丘比特之心,现在让我们一起来看看吧!...
shell脚本:数据库的分库分表
#!/bin/bash ######################### #File name:db_fen.sh #Version:v1.0 #Email:admintest.com #Created time:2023-07-29 09:18:52 #Description: ########################## MySQL连接信息 db_user"root" db_password"RedHat123" db_cmd"-u${…...
)
AtCoder Beginner Contest 312(A~D)
A //语法题也要更仔细嘞,要不然也会wa #include <bits/stdc.h> // #pragma GCC optimize(3,"Ofast","inline") // #pragma GCC optimize(2) using namespace std; typedef long long LL; #define int LL typedef pair<int, int> …...

SQL中Partition的相关用法
使用Partition可以根据指定的列或表达式将数据分成多个分区。每个分区都是逻辑上独立的,可以单独进行查询、插入、更新和删除操作。Partition可以提高查询性能,因为它可以限制在特定分区上执行查询,而不是在整个表上执行。 在SQL中ÿ…...
微服务——Docker
docker与虚拟机的区别 首先要知道三个层次 硬件层:计算机硬件 内核层:与硬件交互,提供操作硬件的指令 应用层: 系统应用封装内核指令为函数,便于程序员调用。用户程序基于系统函数库实现功能。 docker在打包的时候直接把应用层的函数库也进行打包&a…...

测试|测试用例方法篇
测试|测试用例方法篇 文章目录 测试|测试用例方法篇1.测试用例的基本要素:测试环境,操作步骤,测试数据,预期结果…2.测试用例带来的好处3.测试用例的设计思路,设计方法,具体设计方法之间的关系**设计测试用…...

负载均衡的策略有哪些? 负载均衡的三种方式?
负载均衡的策略有哪些? 负载均衡的策略有如下: 1. 轮询(Round Robin):按照请求的顺序轮流分配到不同的服务器。 2. 权重(Weighted):给不同的服务器分配不同的权重,根据权重比例来…...
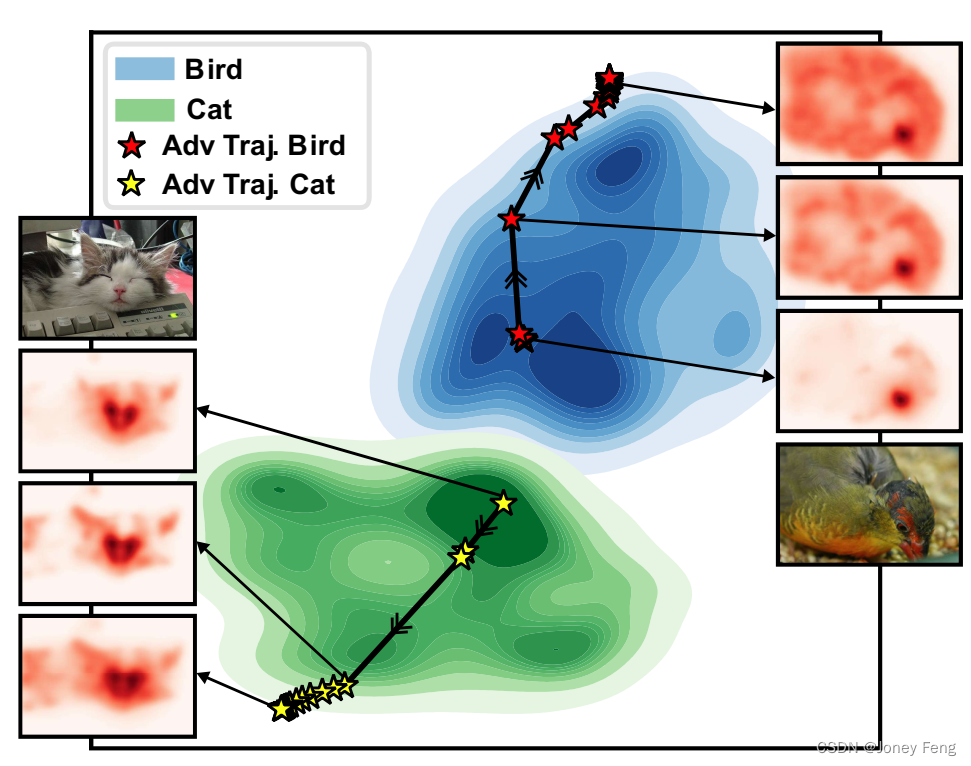
二十三章:抗对抗性操纵的弱监督和半监督语义分割的属性解释
0.摘要 弱监督语义分割从分类器中生成像素级定位,但往往会限制其关注目标对象的一个小的区域。AdvCAM是一种图像的属性图,通过增加分类分数来进行操作。这种操作以反对抗的方式实现,沿着像素梯度的相反方向扰动图像。它迫使最初被认为不具有区…...

curator实现的zookeeper可重入锁
Curator是一个Apache开源的ZooKeeper客户端库,它提供了许多高级特性和工具类,用于简化在分布式环境中使用ZooKeeper的开发。其中之一就是可重入锁。 Curator提供了InterProcessMutex类来实现可重入锁。以下是使用Curator实现ZooKeeper可重入锁的示例&am…...
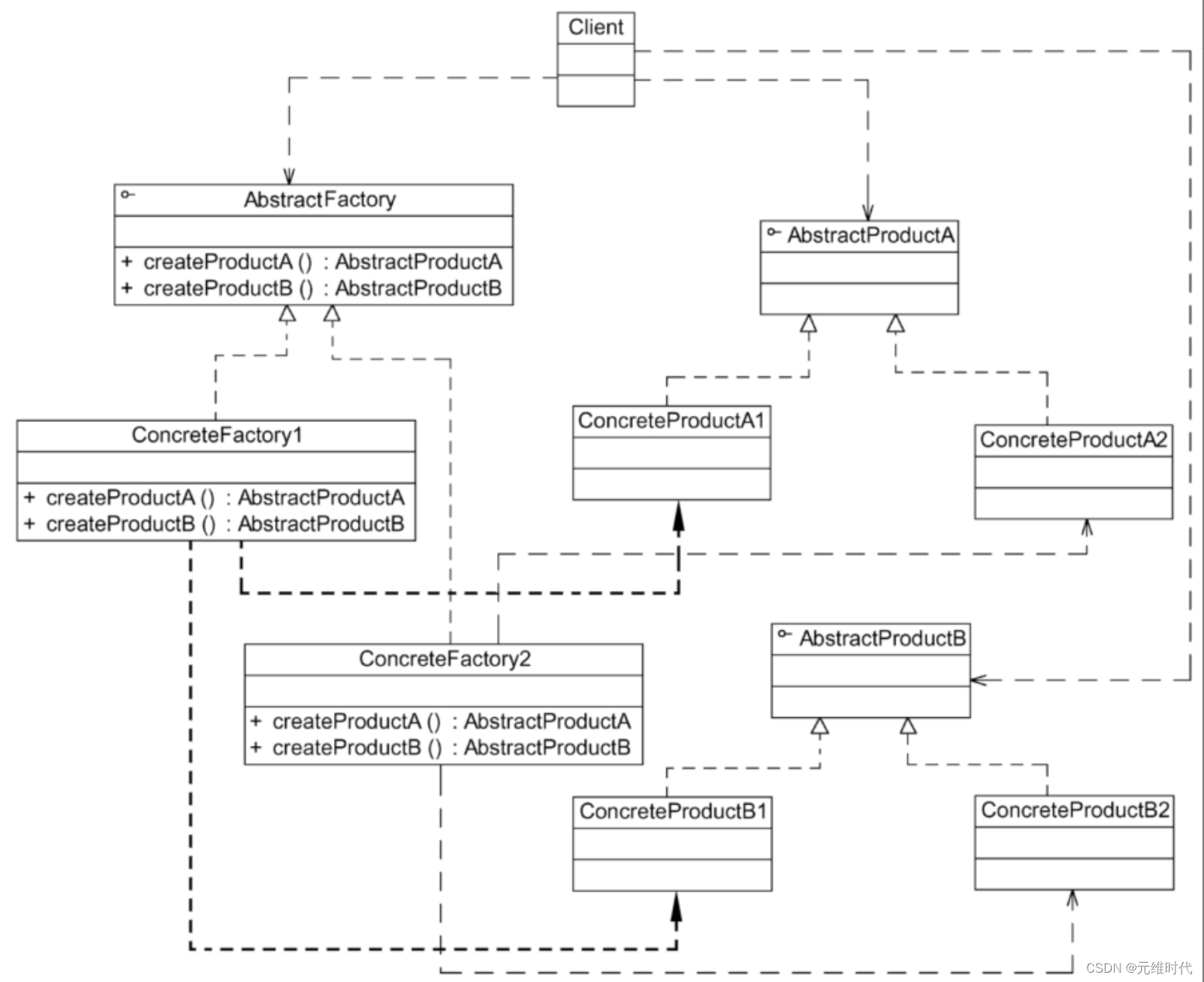
抽象工厂模式——产品族的创建
1、简介 1.1、简介 抽象工厂模式为创建一组对象提供了一种解决方案。与工厂方法模式相比,抽象工厂模式中的具体工厂不只是创建一种产品,它负责创建一族产品 1.2、定义 抽象工厂模式(Abstract Factory Pattern):提供…...

【C语言初阶篇】自定义类型结构体我不允许还有人不会!
🎬 鸽芷咕:个人主页 🔥 个人专栏:《C语言初阶篇》 《C语言进阶篇》 ⛺️生活的理想,就是为了理想的生活! 文章目录 📋 前言1 . 什么是结构体1.1 结构的定义1.2 结构的声明 2.结构体初始化2.1 用标签名定义和初始化2.2…...

重大更新|Sui主网即将上线流动性质押,助力资产再流通
Sui社区一直提议官方上线流动质押功能,现在通过SIP过程,已经升级该协议以实现这一功能。 Sui使用委托权益证明机制(DPoS)来选择和奖励负责运营网络的验证节点。为了保障网络安全,验证节点通过质押SUI token获得质押奖…...

day3 驱动开发 c语言编程
通过ioctl(内核应用层) 控制led灯三盏,风扇,蜂鸣器,小马达 头文件head.h #ifndef __LED_H__ #define __LED_H__typedef struct {volatile unsigned int TZCR; // 0x000volatile unsigned int res1[2]; // 0x…...
【字节跳动青训营】后端笔记整理-3 | Go语言工程实践之测试
**本文由博主本人整理自第六届字节跳动青训营(后端组),首发于稀土掘金:🔗Go语言工程实践之测试 | 青训营 目录 一、概述 1、回归测试 2、集成测试 3、单元测试 二、单元测试 1、流程 2、规则 3、单元测试的例…...

【Android】Recyclerview的缓存复用
介绍 RecyclerView是Android开发中常用的一个高度可定制的列表视图组件。它是在ListView和GridView的基础上进行了改进和增强,旨在提供更好的性能和更灵活的布局管理。 RecyclerView的主要特点如下: 灵活的布局管理器(LayoutManager&#…...
机器学习:混合高斯聚类GMM(求聚类标签)+PCA降维(3维降2维)习题
使用混合高斯模型 GMM,计算如下数据点的聚类过程: Datanp.array([1,2,6,7]) 均值初值为: μ1,μ21,5 权重初值为: w1,w20.5,0.5 方差: std1,std21,1 K2 10 次迭代后数据的聚类标签是多少? 采用python代码实现: from scipy import…...

libuv库学习笔记-processes
Processes libuv提供了相当多的子进程管理函数,并且是跨平台的,还允许使用stream,或者说pipe完成进程间通信。 在UNIX中有一个共识,就是进程只做一件事,并把它做好。因此,进程通常通过创建子进程来完成不…...

c++ 给无名形参提供默认值
如上图,若函数的形参不在函数体里使用,可以不提供形参名,而且可以给此形参提供默认值。也能编译通过。 在看vs2019上的源码时,也出现了这种写法。应用SFINAE(substitute false is not an error)原则&#x…...
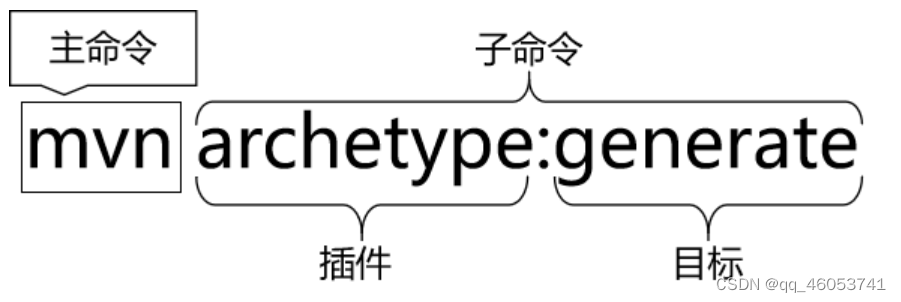
NO1.使用命令行创建Maven工程
①在工作空间目录下打开命令窗口 ②使用命令行生成Maven工程 mvn archetype:generate 运行 MVN 原型:生成命令,下面根据提示操作 选择一个数字或应用过滤器(格式:[groupId:]artifactId,区分大小写包含)&a…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

AI,如何重构理解、匹配与决策?
AI 时代,我们如何理解消费? 作者|王彬 封面|Unplash 人们通过信息理解世界。 曾几何时,PC 与移动互联网重塑了人们的购物路径:信息变得唾手可得,商品决策变得高度依赖内容。 但 AI 时代的来…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...