如何通俗理解扩散模型?
扩散模型(Diffusion Model)是一类十分先进的基于扩散思想的深度学习生 成模型。生成模型除了扩散模型之外,还有出现较早的 VAE ( Variational Auto- Encoder,变分自编码器) 和 GAN ( Generative Adversarial Net ,生成对抗网络) 等。 虽然它们与扩散模型也有一些渊源,不过这并不在本书的讨论范围之内。同时本书 也不会深入介绍扩散模型背后复杂的数学原理。即便如此,你仍然可以基于本书介绍的内容学会通过相关代码来生成精美的图像。
本章涵盖的知识点如下。
● 扩散模型的原理,旨在介绍扩散模型是如何“扩散”的。
● 扩散模型的发展,旨在介绍扩散模型在图像生成方面的技术迭代与生态发展 历程。
● 扩散模型的应用,旨在介绍扩散模型除了图像生成领域之外的其他应用。
1.1 扩散模型的原理
扩散模型是一类生成模型,它运用了物理热力学中的扩散思想,主要包括前向 扩散和反向扩散两个过程。本节将介绍扩散模型的原理,其中不包含复杂的数学 推导。
1.1.1 生成模型
在深度学习中,生成模型的目标是根据给定的样本(训练数据) 生成新样本。 首先给定一批训练数据X,假设其服从某种复杂的真实分布 p(x),则给定的训练数 据可视为从该分布中采样的观测样本 x 。如果能够从这些观测样本中估计出训练数据的真实分布,不就可以从该分布中源源不断地采样出新的样本了吗?生成模型实 际上就是这么做的,它的作用是估计训练数据的真实分布,并将其假定为 q(x)。在 深度学习中,这个过程称为拟合网络。
那么问题来了,怎么才能知道估计的分布 q(x) 和真实分布p(x) 的差距大不大 呢?一种简单的思路是要求所有的训练数据样本采样自 q(x) 的概率最大。这种思路 实际上来自统计学中的最大似然估计思想,它也是生成模型的基本思想之一,因此 生成模型的学习目标就是对训练数据的分布进行建模。
1.1.2 扩散过程
最大似然估计思想已经在一些模型(如 VAE)上应用并取得了不错的效果。扩 散模型可看作一个更深层次的 VAE。扩散模型的表达能力更加丰富,而且其核心在
于扩散过程。
扩散的思想来自物理学中的非平衡热力学分支。非平衡热力学专门研究某些不 处于热力学平衡中的物理系统,其中最为典型的研究案例是一滴墨水在水中扩散的 过程。在扩散开始之前,这滴墨水会在水中的某个地方形成一个大的斑点,我们可 以认为这是这滴墨水的初始状态,但要描述该初始状态的概率分布则很困难,因为 这个概率分布非常复杂。随着扩散过程的进行,这滴墨水随着时间的推移逐步扩散 到水中,水的颜色也逐渐变成这滴墨水的颜色,如图 1- 1 所示。此时,墨水分子的 概率分布将变得更加简单和均匀,这样我们就可以很轻松地用数学公式来描述其中 的概率分布了。
在这种情况下,非平衡热力学就派上用场了,它可以描述这滴墨水随时间推移 的扩散过程中每一个“时间步”(旨在将连续的时间过程离散化)状态的概率分布。 若能够想到办法把这个过程反过来,就可以从简单的分布中逐步推断出复杂的分布。
公认最早的扩散模型 DDPM (Denoising Diffusion Probabilistic Model)的扩散 原理就由此而来,不过仅有上述条件依然很难从简单的分布倒推出复杂的分布。 DDPM 还做了一些假设,例如假设扩散过程是马尔可夫过程 1(即每一个时间步状态的概率分布仅由上一个时间步状态的概率分布加上当前时间步的高斯噪声得到), 以及假设扩散过程的逆过程是高斯分布等。

DDPM 的扩散过程如图 1-2 所示,具体分为前向过程和反向过程两部分。

1 )前向过程
前向过程是给数据添加噪声的过程。假设给定一批训练数据,数据分布为 x0 ~ q(x0) ,其中,0 表示初始状态,即还没有开始扩散。如前所述,将前向加噪过 程分为离散的多个时间步 T,在每一个时间步 t,给上一个时间步t−1 的数据 xt−1 添 加高斯噪声,从而生成带有噪声(简称“带噪”)的数据 xt ,同时数据 xt 也会被送
入下一个时间步 t+1 以继续添加噪声。其中,噪声的方差是由一个位于区间( 0,1 ) 的固定值 βt 确定的,均值则由固定值 βt 和当前时刻“带噪”的数据分布确定。在 反复迭代和加噪(即添加噪声) T 次之后,只要 T 足够大,根据马尔可夫链的性质, 最终就可以得到纯随机噪声分布的数据,即类似稳定墨水系统的状态。
接下来,我们用简单的公式描述一下上述过程。从时间步 t−1 到时间步 t 的单步扩散加噪过程的数学表达式如下:

xt 的函数,因此需要使用扩散模型来优化参数。
3)优化目标
扩散模型预测的是噪声残差,即要求后向过程中预测的噪声分布与前向过程中 施加的噪声分布之间的“距离”最小。
下面我们从另一个角度来看看扩散模型。如果把中间产生的变量看成隐变量 的话,那么扩散模型其实是一种包含 T 个隐变量的模型,因此可以看成更深层次 的 VAE,而 VAE 的损失函数可以使用变分推断来得到变分下界(variational lower bound)。至于具体过程,本书不做过多的公式推导,感兴趣的读者可以参考 DDPM 原文。
扩散模型的最终优化目标的数学表达式如下:

可以看出,在训练 DDPM 时,只要用一个简单的 MSE ( Mean Squared Error, 均方误差)损失来最小化前向过程施加的噪声分布和后向过程预测的噪声分布,就 能实现最终的优化目标。
1.2 扩散模型的发展
扩散模型从最初的简单图像生成模型,逐步发展到替代原有的图像生成模型,直 到如今开启 AI 作画的时代,发展速度可谓惊人。因为本书主要介绍扩散模型的 2D 图 像生成任务,所以本节仅介绍与 2D 图像生成相关的扩散模型的发展历程,具体如下。
● 开始扩散:基础扩散模型的提出与改进。
● 加速生成:采样器。
● 刷新纪录:基于显式分类器引导的扩散模型。
● 引爆网络:基于CLIP (Contrastive Language-Image Pretraining,对比语言-图 像预处理)的多模态图像生成。
● 再次“出圈”:大模型的“再学习”方法— DreamBooth 、LoRA和 ControlNet。
● 开启AI作画时代:众多商业公司提出成熟的图像生成解决方案。
1.2.1 开始扩散:基础扩散模型的提出与改进
在图像生成领域,最早出现的扩散模型是 DDPM (于 2020 年提出)。DDPM 首次将“去噪”扩散概率模型应用到图像生成任务中,奠定了扩散模型在图像生成 领域应用的基础,包括扩散过程定义、噪声分布假设、马尔可夫链计算、随机微分 方程求解和损失函数表征等,后面涌现的众多扩散模型都是在此基础上进行了不同 种类的改进 1。
1.2.2 加速生成:采样器
虽然扩散模型在图像生成领域取得了一定的成果,但是由于其在图像生成阶段 需要迭代多次,因此生成速度非常慢(最初版本的扩散模型的生成速度甚至长达数 分钟),这也是扩散模型一直受到诟病的原因。在扩散模型中,图像生成阶段的速
度和质量是由采样器控制的,因此如何在保证生成质量的前提下加快采样是一个对扩散模型而言至关重要的问题。
论文“Score-Based Generative Modeling through Stochastic Differential Equations” 证明了 DDPM 的采样过程是更普遍的随机微分方程,因此只要能够更离散化地求 解该随机微分方程,就可以将 1000 步的采样过程缩减至 50 步、 20 步甚至更少的 步数,从而极大地提高扩散模型生成图像的速度,如图 1-3 所示。针对如何更快 地进行采样这一问题,目前已经涌现了许多优秀的求解器,如 Euler 、SDE 、DPM- Solver++ 和 Karras 等,这些加速采样方法也是扩散模型风靡全球至关重要的推力。

1.2.3 刷新纪录:基于显式分类器引导的扩散模型
2021 年 5 月以前,虽然扩散模型已经被应用到图像生成领域,但它实际上在 图像生成领域并没有“大红大紫”,因为早期的扩散模型在所生成图像的质量和稳 定性上并不如经典的生成模型 GAN (Generative Adversarial Network,生成对抗网 络),真正让扩散模型开始在研究领域“爆火”的原因是论文“Diffusion Models Beat GANs on Image Synthesis”的发表。 OpenAI 的这篇论文贡献非常大,尤其是该 文推导了在扩散过程中如何使用显式分类器引导。
更重要的是,这篇论文打败了图像生成领域统治多年的 GAN,展示了扩散模 型的强大潜力,使得扩散模型一举成为图像生成领域最火的模型,如图 1-4 所示。

1.2.4 引爆网络:基于 CLIP 的多模态图像生成
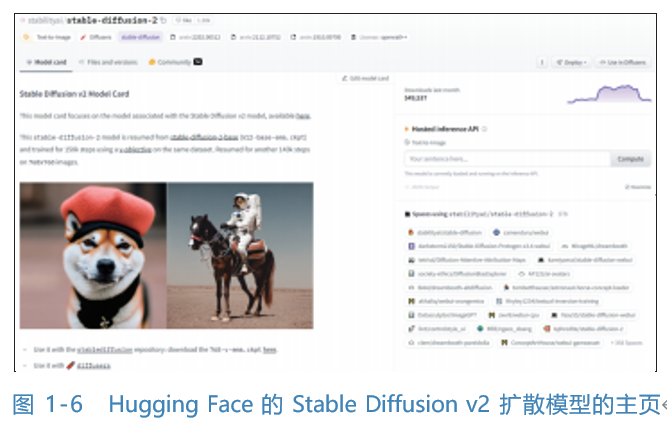
CLIP 是连接文本和图像的模型,旨在将同一语义的文字和图片转换到同一个隐空间中,例如文字“一个苹果”和图片“一个苹果”。正是由于这项技术和扩散模型的结合,才引起基于文字引导的文字生成图像扩散模型在图像生成领域的彻底爆发,例如 OpenAI的 GLIDE、DALL-E、DALL-E 2 (基于 DALL-基于 DALL-E 2 生成的图像如图 1-5 所示),Google 的Imagen以及开源的 Stable Diffusion ( Stable Diffusion v2扩散模型的主页如图 1-6 所示)等,优秀的文字生成图像扩散模型层出不穷,给我们带来无尽的惊喜。
1.2.5 再次“出圈”:大模型的“再学习”方法—— DreamBooth、LoRA 和 ControlNet
自从扩散模型走上大模型之路后,重新训练一个图像生成扩散模型变得非常昂 贵。面对数据和计算资源高昂的成本,个人研究者想要入场进行扩散模型的相关研 究已经变得非常困难。
但实际上,像开源的 Stable Diffusion 这样的扩散模型已经出色地学习到非常多的图像生成知识,因此不需要也没有必要重新训练类似的扩散模型。于是,许多基 于现有的扩散模型进行“再学习”的技术自然而然地涌现,这也使得个人在消费级 显卡上训练自己的扩散模型成为可能。DreamBooth 、LoRA 和 ControlNet 是实现大 模型“再学习”的不同方法,它们是针对不同的任务而提出的。
DreamBooth 可以实现使用现有模型再学习到指定主体图像的功能,只要通过 少量训练将主体绑定到唯一的文本标识符后,就可以通过输入文本提示语来控制自 己的主体以生成不同的图像,如图 1-7 所示。

LoRA 可以实现使用现有模型再学习到自己指定数据集风格或人物的功能,并 且还能够将其融入现有的图像生成中。Hugging Face 提供了训练 LoRA 的 UI 界面, 如图 1-8 所示。

ControlNet 可以再学习到更多模态的信息,并利用分割图、边缘图等功能更精 细地控制图像的生成。第 7 章将对 ControlNet 进行更加细致的讲解。
1.2.6 开启AI作画时代:众多商业公司提出成熟的图像生成解决方案
图像生成扩散模型“爆火”之后,缘于技术的成熟加上关注度的提高以及上手 简易等,网络上的扩散模型“百花齐放”,越来越多的人开始使用扩散模型来生成 图像。
众多提供成熟图像生成解决方案的公司应运而生。例如,图像生成服务提供 商 Midjourney 实现了用户既可以通过 Midjourney 的 Discord 频道主页(如图 1-9 所 示)输入提示语来生成图像,也可以跟全世界的用户一起分享和探讨图像生成的细 节。此外通过 Stability AI 公司开发的图像生成工具箱 DreamStudio (如图 1- 10 所 示),用户既可以使用提示语来编辑图像,也可以将其 SDK 嵌入自己的应用或者作 为 Photoshop 插件使用。当然, Photoshop 也有自己的基于扩散模型的图像编辑工具 库 Adobe Firefly (如图 1- 11 所示),用户可以基于 Photoshop 传统的选区等精细控 制功能来更高效地生成图像。


百度公司推出了文心一格 AI 创作平台(如图 1- 12 所示),而阿里巴巴达摩院 也提出了自己的通义文生图大模型等。除了头部企业以外,一些创业公司也开始崭 露头角,退格网络推出的 Tiamat 图像生成工具已获多轮投资,由该工具生成的精 美概念场景图像登陆上海地铁广告牌。北京毛线球科技有限公司开发的 6pen Art 图 像生成 APP (如图 1- 13 所示)将图像生成带到手机端,使用户在手机上就能体验 AI 作画。
众多的服务商致力于以最成熟、最简单的方式让大众能够通过输入文字或图片 的方式生成想要的图像,真正开启了 AI 作画时代。
1.3 扩散模型的应用
扩散只是一种思想,扩散模型也并非固定的深度网络结构。除此之外,如果将 扩散的思想融入其他领域,扩散模型同样可以发挥重要作用。
在实际应用中,扩散模型最常见、最成熟的应用就是完成图像生成任务,本书 同样聚焦于此。不过即便如此,扩散模型在其他领域的应用仍不容忽视,可能在不 远的将来,它们就会像在图像生成领域一样蓬勃发展,一鸣惊人。
本节将介绍扩散模型在其他领域的应用,具体内容如下。
● 计算机视觉。
● 时序数据预测。
● 自然语言。
● 基于文本的多模态。
● AI基础科学。
1.3.1 计算机视觉
计算机视觉包括 2D 视觉和 3D 视觉两个方面,这里仅介绍扩散模型在 2D 图像 领域的应用。
图像类的应用十分广泛,而且与人们的日常生活息息相关。在扩散模型出现之 前,与图像处理相关的研究已经有很多了,而扩散模型在许多图像处理任务中都可 以很好地发挥作用,具体如下。
● 图像分割与目标检测。图像分割与目标检测是计算机视觉领域的经典任 务,在智能驾驶、质量监测等方面备受关注。而在加入扩散的方法之后, 就可以获取更精准的分割和检测结果了,例如Meta AI的SegDiff分割扩散模 型可以生成分割Mask图(如图1- 14所示),检测扩散模型DiffusionDet同样 可以端到端地从随机矩形框逐步生成检测框(如图1- 15所示)。不过,扩散 模型仍然存在生成速度慢的问题,在应用于一些需要实时检测的场景时需要继续优化。

- 图像超分辨率。图像超分辨率是一项能够将低分辨率图像重建为高分辨率图 像,同时保证图像布局连贯的技术。 CDM (Cascaded Diffusion Model,级联扩散模型)通过采用串联多个扩散模型的方式,分级式地逐步放大分辨率,实现了图像超分辨率1 ,图1-16给出了一个使用CDM实现图像超分辨率的示例。

- 图像修复、图像翻译和图像编辑。图像修复、图像翻译和图像编辑是对图 像的部分或全部区域执行的操作,包括缺失部分修补、风格迁移、内容替 换等。 Palette是一个集成了图像修复、图像翻译和图像编辑等功能的扩散模 型,它可以在一个模型中完成不同的图像级任务1 。图1- 17给出了一个使用 Palette修复图像的示例。
1.3.2 时序数据预测
时序数据预测旨在根据历史观测数据预测未来可能出现的数据,如空气温度预 测、股票价格预测、销售与产能预测等。时序数据预测同样可以视为生成任务,即 基于历史数据的基本条件来生成未来数据,因此扩散模型也能发挥作用。
TimeGrad2 是首个在多元概率时序数据预测任务中加入扩散思想的自回归模 型。为了将扩散过程添加到历史数据中,TimeGrad 首先使用 RNN ( Recurrent Neural Network,循环神经网络)处理历史数据并保存到隐空间中,然后对历史 数据添加噪声以实现扩散过程,由此处理数千维度的多元数据并完成预测任务。 图 1- 18 展示了 TimeGrad 在城市交通流量预测任务中的表现。

时序数据预测在实际生活中的应用非常广泛。在过去,传统机器学习方法以及 深度学习的 RNN 系列方法一直处于主导地位。如今,扩散模型已经表现出巨大的 潜力,而这还仅仅是开始。
1.3.3 自然语言
自然语言领域也是人工智能的一个重要发展方向,旨在研究人类语言与计算机 通信的相关问题,最近“爆火”的 ChatGPT 就是一个自然语言生成问答模型。
实际上,扩散模型同样可以完成语言类的生成任务。只要将自然语言类的句子 分词并转换为词向量之后,就可以通过扩散的方法来学习自然语言的语句生成,进 而完成自然语言领域一些更复杂的任务,如语言翻译、问答对话、搜索补全、情感 分析、文章续写等。
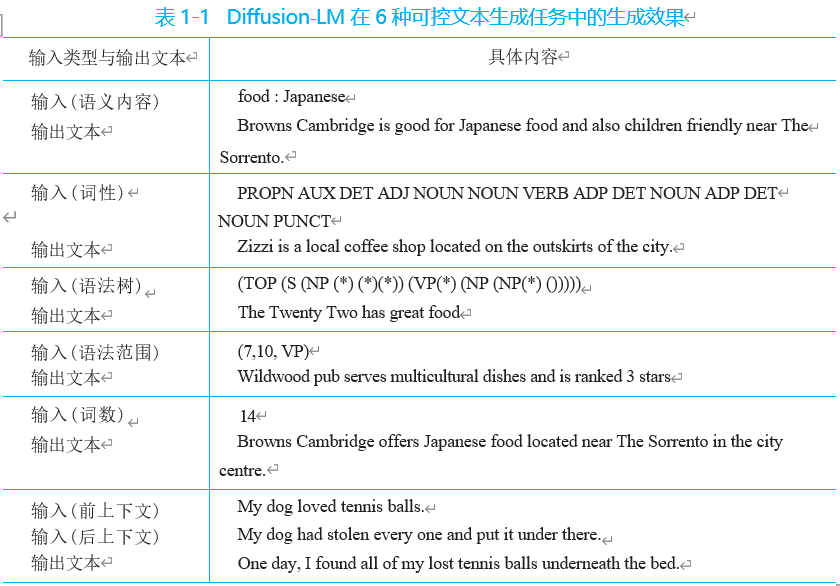
Diffusion-LM1 是首个将扩散模型应用到自然语言领域的扩散语言模型。该模型 旨在解决如何将连续的扩散过程应用到离散的非连续化文本的问题,由此实现语言 类的高细粒度可控生成。经过测试,Diffusion-LM 在 6 种可控文本生成任务中取得 非常好的生成效果,如表 1- 1 所示。
实际上,后续也有非常多的基于 Diffusion-LM 的应用。不过在自然语言领域, 目前的主流模型仍然是 GPT (Generative Pre-trained Transformer),我们非常期待扩 散模型未来能在自然语言领域得到更进一步的发展。
1.3.4 基于文本的多模态
多模态信息指的是多种数据类型的信息,包括文本、图像、音 / 视频、 3D 物 体等。多模态信息的交互是人工智能领域的研究热点之一,对于 AI 理解人类世界、帮助人类处理多种事务具有重要意义。在诸如 DALL-E 2 和 Stable Diffusion 等图像 生成扩散模型以及 ChatGPT 等语言模型出现之后,多模态开始逐渐演变为基于文 本和其他模态的交互,如文本生成图像、文本生成视频、文本生成 3D 等。
● 文本生成图像。文本生成图像是扩散模型最流行、最成熟的应用,输入文本 提示语或仅仅输入几个词,扩散模型就能根据文字描述生成对应的图片。本 章开头介绍的大名鼎鼎的文本生成图像扩散模型DALLE-2 、Imagen以及完 全开源的 Stable Diffusion等,都属于文本和图像的多模态扩散模型。图1- 19 给出了几个使用Imagen实现文字生成图像的示例,后面我们将重点介绍与文 本生成图像相关的应用。

图 1-19 使用 Imagen 实现文字生成图像的几个示例
● 文本生成视频。与文本生成图像类似,文本生成视频扩散模型能够将输入的 文本提示语转换为相应的视频流。不同的是,视频的前后帧需要保持极佳 的连贯性。文本生成视频也有非常广泛的应用,如Meta AI的Make-A-Video (如图1-20所示)以及能够精细控制视频生成的ControlNet Video等。图1-21 展示了Hugging Face上的ControlNet Video Space应用界面。

图 1-20 Meta AI 的 Make-A-Video :一条身着超人外衣、肩披红色斗篷的狗在天空中翱翔
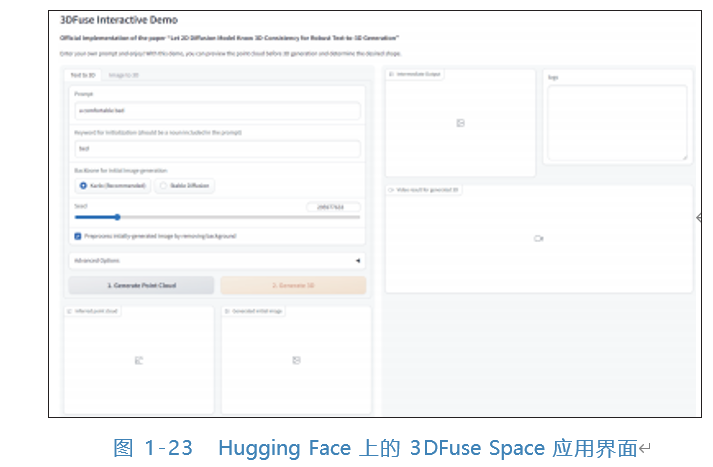
● 文本生成3D。同样,文本生成3D扩散模型能够将输入的文本转换为相应的 3D物体。稍有不同的是, 3D物体的表征有多种方式,如点云、网格、 NeRF 等。不同的应用在实现方式上也略有差异,例如: DiffRF提出了通过扩散的方法实现从文本生成3D辐射场的扩散模型,如图1-22所示; 3DFuse实现了 基于二维图像生成对应的3D点云,我们可以在Hugging Face上体验官方给出 的演示实例,如图1-23所示。虽然目前文本生成3D技术仍处于起步阶段, 但其应用前景非常广阔,包括室内设计、游戏建模、元宇宙数字人等。


1.3.5 AI 基础科学
AI 基础科学又称 AI for Science ,它是人工智能领域具有广阔前景的分支之一, 甚至能够发展为造福全人类的技术。与 AI 基础科学相关的研究成果也不止一次荣登 《自然》杂志。例如,2021 年 DeepMind 研究的 AlphaFold 2 可以预测人类世界 98.5% 的蛋白质, 2022 年 DeepMind 用强化学习控制核聚变反应堆内过热的等离子体等。
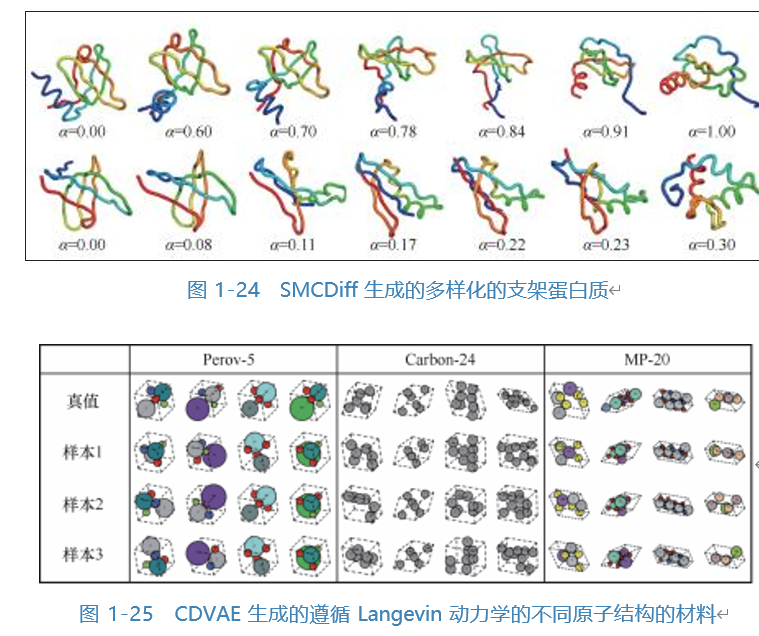
扩散模型对生成类的任务一直表现十分专业,AI 基础科学中生成预测类的研 究当然也少不了扩散模型的参与。SMCDiff 创建了一种扩散模型,该扩散模型可以 根据给定的模体结构生成多样化的支架蛋白质,如图 1-24 所示。 CDVAE 则提出了 一种扩散晶体变分自编码器模型,旨在生成和优化具有固定周期性原子结构的材 料 1,2 ,如图 1-25 所示。
以上内容来自《扩散模型从原理到实战》

HuggingFace平台学习实战,常春藤盟校数据科学硕士与算法工程师带你从理论到实战,了解、掌握扩散模型,快速满足工作中的绘图需求,有效提升效率。
AIGC的应用领域日益广泛,而在图像生成领域,扩散模型则是AIGC技术的一个重要应用。本书以扩散模型理论知识为切入点,由浅入深地介绍了扩散模型的相关知识,并以大量生动有趣的实战案例帮助读者理解扩散模型的相关细节。全书共8章,详细介绍了扩散模型的原理,以及扩散模型退化、采样、DDIM反转等重要概念与方法,此外还介绍了Stable Diffusion、ControlNet与音频扩散模型等内容。最后,附录提供由扩散模型生成的高质量图像集以及Hugging Face社区的相关资源。
本书既适合所有对扩散模型感兴趣的AI研究人员、相关科研人员以及在工作中有绘图需求的从业人员阅读,也可以作为计算机等相关专业学生的参考书。
相关文章:
如何通俗理解扩散模型?
扩散模型(Diffusion Model)是一类十分先进的基于扩散思想的深度学习生 成模型。生成模型除了扩散模型之外,还有出现较早的 VAE ( Variational Auto- Encoder,变分自编码器) 和 GAN ( Generative Adversarial Net ,生成对抗网络) 等。 虽然它们…...
【C#】并行编程实战:并行编程中的模式
本章将介绍并行编程模式,重点是理解并行代码问题场景并使用并行编程/异步技术解决他们。本章会介绍几种最重要的编程模式。 本教程学习工程:魔术师Dix / HandsOnParallelProgramming GitCode 1、MapReduce 模式 引入 MapReduce 是为了解决处理大数据的问…...

Apache Kafka 入门教程
Apache Kafka 入门教程 一、简介简介架构 二、Kafka 安装和配置JDK安装 Kafka配置文件详解 三、Kafka 的基本操作启动和关闭Topic 创建和删除Partitions 和 Replication 配置Producer 和 Consumer 使用方法ProducerConsumer 四、Kafka 高级应用消息的可靠性保证Kafka StreamKaf…...
python皮卡丘编程代码教程,用python打印皮卡丘
大家好,小编来为大家解答以下问题,如何用print函数打印一只皮卡丘,用python如何打印丘比特之心,现在让我们一起来看看吧!...
shell脚本:数据库的分库分表
#!/bin/bash ######################### #File name:db_fen.sh #Version:v1.0 #Email:admintest.com #Created time:2023-07-29 09:18:52 #Description: ########################## MySQL连接信息 db_user"root" db_password"RedHat123" db_cmd"-u${…...
)
AtCoder Beginner Contest 312(A~D)
A //语法题也要更仔细嘞,要不然也会wa #include <bits/stdc.h> // #pragma GCC optimize(3,"Ofast","inline") // #pragma GCC optimize(2) using namespace std; typedef long long LL; #define int LL typedef pair<int, int> …...

SQL中Partition的相关用法
使用Partition可以根据指定的列或表达式将数据分成多个分区。每个分区都是逻辑上独立的,可以单独进行查询、插入、更新和删除操作。Partition可以提高查询性能,因为它可以限制在特定分区上执行查询,而不是在整个表上执行。 在SQL中ÿ…...
微服务——Docker
docker与虚拟机的区别 首先要知道三个层次 硬件层:计算机硬件 内核层:与硬件交互,提供操作硬件的指令 应用层: 系统应用封装内核指令为函数,便于程序员调用。用户程序基于系统函数库实现功能。 docker在打包的时候直接把应用层的函数库也进行打包&a…...

测试|测试用例方法篇
测试|测试用例方法篇 文章目录 测试|测试用例方法篇1.测试用例的基本要素:测试环境,操作步骤,测试数据,预期结果…2.测试用例带来的好处3.测试用例的设计思路,设计方法,具体设计方法之间的关系**设计测试用…...

负载均衡的策略有哪些? 负载均衡的三种方式?
负载均衡的策略有哪些? 负载均衡的策略有如下: 1. 轮询(Round Robin):按照请求的顺序轮流分配到不同的服务器。 2. 权重(Weighted):给不同的服务器分配不同的权重,根据权重比例来…...
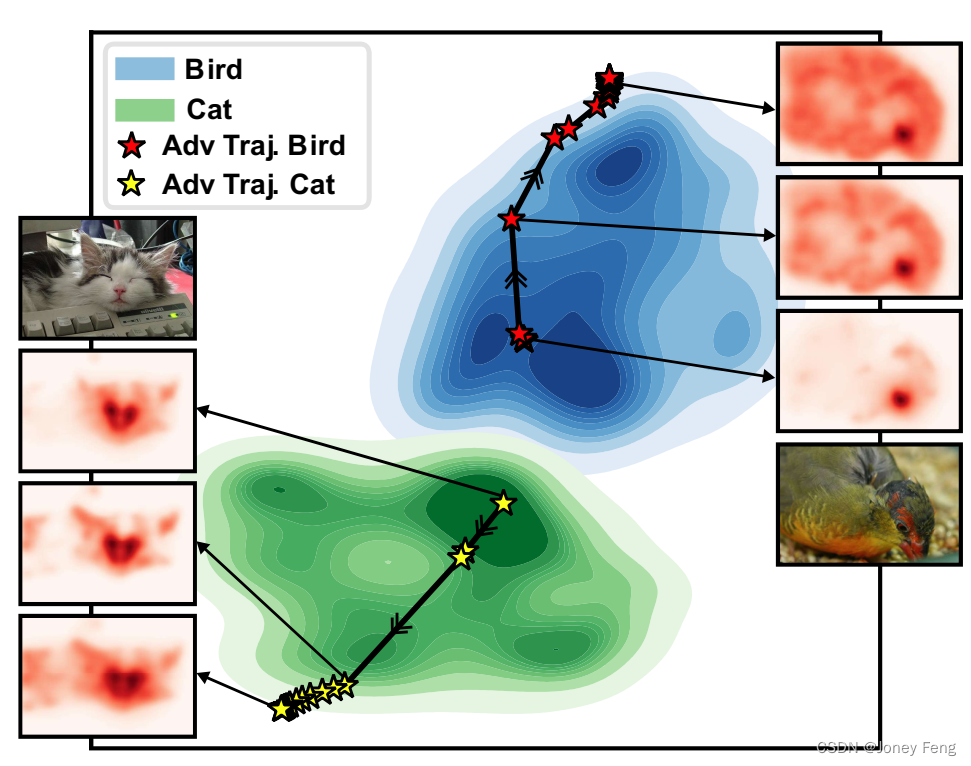
二十三章:抗对抗性操纵的弱监督和半监督语义分割的属性解释
0.摘要 弱监督语义分割从分类器中生成像素级定位,但往往会限制其关注目标对象的一个小的区域。AdvCAM是一种图像的属性图,通过增加分类分数来进行操作。这种操作以反对抗的方式实现,沿着像素梯度的相反方向扰动图像。它迫使最初被认为不具有区…...

curator实现的zookeeper可重入锁
Curator是一个Apache开源的ZooKeeper客户端库,它提供了许多高级特性和工具类,用于简化在分布式环境中使用ZooKeeper的开发。其中之一就是可重入锁。 Curator提供了InterProcessMutex类来实现可重入锁。以下是使用Curator实现ZooKeeper可重入锁的示例&am…...
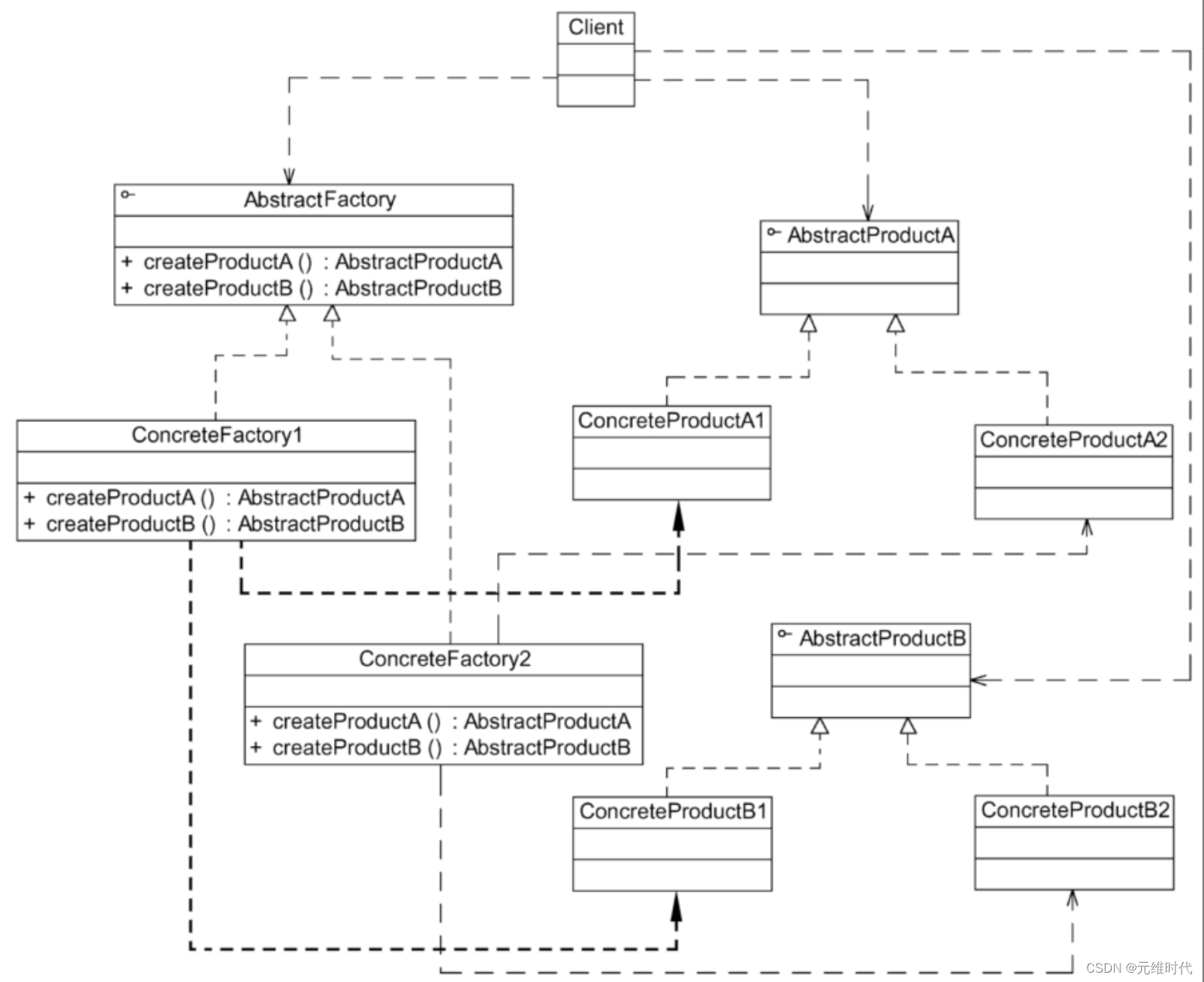
抽象工厂模式——产品族的创建
1、简介 1.1、简介 抽象工厂模式为创建一组对象提供了一种解决方案。与工厂方法模式相比,抽象工厂模式中的具体工厂不只是创建一种产品,它负责创建一族产品 1.2、定义 抽象工厂模式(Abstract Factory Pattern):提供…...

【C语言初阶篇】自定义类型结构体我不允许还有人不会!
🎬 鸽芷咕:个人主页 🔥 个人专栏:《C语言初阶篇》 《C语言进阶篇》 ⛺️生活的理想,就是为了理想的生活! 文章目录 📋 前言1 . 什么是结构体1.1 结构的定义1.2 结构的声明 2.结构体初始化2.1 用标签名定义和初始化2.2…...

重大更新|Sui主网即将上线流动性质押,助力资产再流通
Sui社区一直提议官方上线流动质押功能,现在通过SIP过程,已经升级该协议以实现这一功能。 Sui使用委托权益证明机制(DPoS)来选择和奖励负责运营网络的验证节点。为了保障网络安全,验证节点通过质押SUI token获得质押奖…...

day3 驱动开发 c语言编程
通过ioctl(内核应用层) 控制led灯三盏,风扇,蜂鸣器,小马达 头文件head.h #ifndef __LED_H__ #define __LED_H__typedef struct {volatile unsigned int TZCR; // 0x000volatile unsigned int res1[2]; // 0x…...
【字节跳动青训营】后端笔记整理-3 | Go语言工程实践之测试
**本文由博主本人整理自第六届字节跳动青训营(后端组),首发于稀土掘金:🔗Go语言工程实践之测试 | 青训营 目录 一、概述 1、回归测试 2、集成测试 3、单元测试 二、单元测试 1、流程 2、规则 3、单元测试的例…...

【Android】Recyclerview的缓存复用
介绍 RecyclerView是Android开发中常用的一个高度可定制的列表视图组件。它是在ListView和GridView的基础上进行了改进和增强,旨在提供更好的性能和更灵活的布局管理。 RecyclerView的主要特点如下: 灵活的布局管理器(LayoutManager&#…...
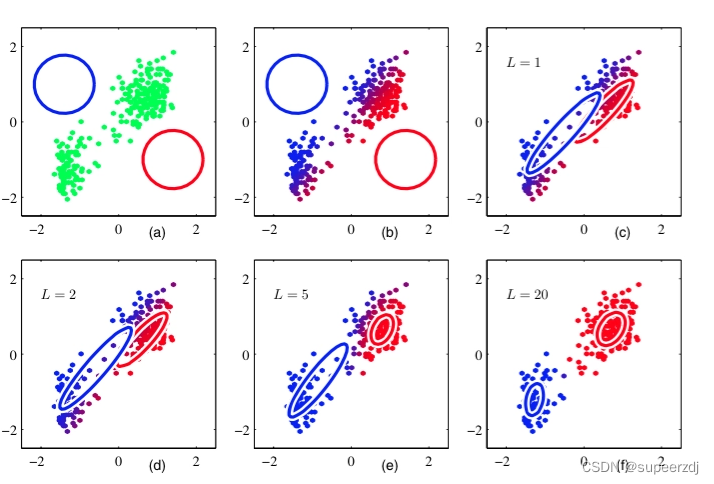
机器学习:混合高斯聚类GMM(求聚类标签)+PCA降维(3维降2维)习题
使用混合高斯模型 GMM,计算如下数据点的聚类过程: Datanp.array([1,2,6,7]) 均值初值为: μ1,μ21,5 权重初值为: w1,w20.5,0.5 方差: std1,std21,1 K2 10 次迭代后数据的聚类标签是多少? 采用python代码实现: from scipy import…...

libuv库学习笔记-processes
Processes libuv提供了相当多的子进程管理函数,并且是跨平台的,还允许使用stream,或者说pipe完成进程间通信。 在UNIX中有一个共识,就是进程只做一件事,并把它做好。因此,进程通常通过创建子进程来完成不…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...

wpf在image控件上快速显示内存图像
wpf在image控件上快速显示内存图像https://www.cnblogs.com/haodafeng/p/10431387.html 如果你在寻找能够快速在image控件刷新大图像(比如分辨率3000*3000的图像)的办法,尤其是想把内存中的裸数据(只有图像的数据,不包…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...