Elasticsearch入门笔记(一)
环境搭建
Elasticsearch是搜索引擎,是常见的搜索工具之一。
Kibana 是一个开源的分析和可视化平台,旨在与 Elasticsearch 合作。Kibana 提供搜索、查看和与存储在 Elasticsearch 索引中的数据进行交互的功能。开发者或运维人员可以轻松地执行高级数据分析,并在各种图表、表格和地图中可视化数据。
其它可视化还有elasticsearch-head(轻量级,有对应的Chrome插件),本文不会详细介绍。
Elasticsearch和Kibana的版本采用7.17.0,环境搭建采用Docker,docker-compose.yml文件如下:
version: "3.1"
# 服务配置
services:elasticsearch:container_name: elasticsearch-7.17.0image: elasticsearch:7.17.0environment:- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"- "http.host=0.0.0.0"- "node.name=elastic01"- "cluster.name=cluster_elasticsearch"- "discovery.type=single-node"ports:- "9200:9200"- "9300:9300"volumes:- ./es/plugins:/usr/share/elasticsearch/plugins- ./es/data:/usr/share/elasticsearch/datanetworks:- elastic_netkibana:container_name: kibana-7.17.0image: kibana:7.17.0ports:- "5601:5601"networks:- elastic_net# 网络配置
networks:elastic_net:driver: bridge
基础命令
- 查看ElasticSearch是否启动成功:
curl http://IP:9200
- 查看集群是否健康
curl http://IP:9200/_cat/health?v
- 查看ElasticSearch所有的index
curl http://IP:9200/_cat/indices
- 查看ElasticSearch所有indices或者某个index的文档数量
curl http://IP:9200/_cat/count?v
curl http://IP:9200/_cat/count/some_index_name?v
- 查看每个节点正在运行的插件信息
curl http://IP:9200/_cat/plugins?v&s=component&h=name,component,version,description
- 查看ik插件的分词结果
curl -H 'Content-Type: application/json' -XGET 'http://IP:9200/_analyze?pretty' -d '{"analyzer":"ik_max_word","text":"美国留给伊拉克的是个烂摊子吗"}'
index操作
- 查看某个index的mapping
curl http://IP:9200/some_index_name/_mapping
- 查看某个index的所有数据
curl http://IP:9200/some_index_name/_search
- 按ID进行查询
curl -X GET http://IP:9200/索引名称/文档类型/ID
- 检索某个index的全部数据
curl http://IP:9200/索引名称/_search?pretty
curl -X POST http://IP:9200/索引名称/_search?pretty -d "{\"query\": {\"match_all\": {} }}"
- 检索某个index的前几条数据(如果不指定size,则默认为10条)
curl -XPOST IP:9200/索引名称/_search?pretty -d "{\"query\": {\"match_all\": {} }, \"size\" : 2}"
- 检索某个index的中间几条数据(比如第11-20条数据)
curl -XPOST IP:9200/索引名称/_search?pretty -d "{\"query\": {\"match_all\": {} }, \"from\" : 10, \"size\" : 10}}"
- 检索某个index, 只返回context字段
curl -XPOST IP:9200/索引名称/_search?pretty -d "{\"query\": {\"match_all\": {} }, \"_source\": [\"context\"]}"
- 删除某个index
curl -XDELETE 'IP:9200/index_name'
ES搜索
- 如果有多个搜索关键字, Elastic 认为它们是or关系。
- 如果要执行多个关键词的and搜索,必须使用布尔查询。
$ curl 'localhost:9200/索引名称/文档类型/_search' -d '
{"query": {"bool": {"must": [{ "match": { "content": "软件" } },{ "match": { "content": "系统" } }]}}
}'
- 复杂搜索:
SQL语句:
select * from test_index where name='tom' or (hired =true and (personality ='good' and rude != true ))
DSL语句:
GET /test_index/_search
{"query": {"bool": {"must": { "match":{ "name": "tom" }},"should": [{ "match":{ "hired": true }},{ "bool": {"must":{ "match": { "personality": "good" }},"must_not": { "match": { "rude": true }}}}],"minimum_should_match": 1}}
}
ik分词器
ik分词器是Elasticsearch的中文分词器插件,对中文分词支持较好。ik版本要与Elasticsearch保持一致。
ik 7.17.0下载地址为:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.17.0 ,下载后将其重名为ik,将其放至Elasticsearch的plugins文件夹下。
ik分词器的使用命令(Kibana环境):
POST _analyze
{"text": "戚发轫是哪里人","analyzer": "ik_smart"
}
输出结果为:
{"tokens" : [{"token" : "戚","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "发轫","start_offset" : 1,"end_offset" : 3,"type" : "CN_WORD","position" : 1},{"token" : "是","start_offset" : 3,"end_offset" : 4,"type" : "CN_CHAR","position" : 2},{"token" : "哪里人","start_offset" : 4,"end_offset" : 7,"type" : "CN_WORD","position" : 3}]
}
ik支持加载用户词典和停用词。ik 提供了配置文件 IKAnalyzer.cfg.xml(将其放在ik/config路径下),可以用来配置自己的扩展用户词典、停用词词典和远程扩展用户词典,都可以配置多个。
配置完扩展用户词典和远程扩展用户词典都需要重启ES,后续对用户词典进行更新的话,需要重启ES,远程扩展用户词典配置完后支持热更新,每60秒检查更新。两个扩展词典都是添加到ik的主词典中,对所有索引生效。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">custom/mydict.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords">custom/ext_stopword.dic</entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
用户词典文件路径为:custom/mydict.dic,停用词词典路径为:custom/ext_stopword.dic,将它们放在ik/config/custom路径下。
用户词典文件中加入’戚发轫’,停用词词典加入’是’,对原来文本进行分词:
POST _analyze
{"text": "戚发轫是哪里人","analyzer": "ik_smart"
}
输出结果如下:
{"tokens" : [{"token" : "戚发轫","start_offset" : 0,"end_offset" : 3,"type" : "CN_WORD","position" : 0},{"token" : "哪里人","start_offset" : 4,"end_offset" : 7,"type" : "CN_WORD","position" : 1}]
}
如果’analyzer’选择ik_smart,则会将文本做最粗粒度的拆分;选择ik_max_word,则会将文本做最细粒度的拆分。测试如下:
POST _analyze
{"text": "戚发轫是哪里人","analyzer": "ik_max_word"
}
输出结果如下:
{"tokens" : [{"token" : "戚发轫","start_offset" : 0,"end_offset" : 3,"type" : "CN_WORD","position" : 0},{"token" : "发轫","start_offset" : 1,"end_offset" : 3,"type" : "CN_WORD","position" : 1},{"token" : "哪里人","start_offset" : 4,"end_offset" : 7,"type" : "CN_WORD","position" : 2},{"token" : "哪里","start_offset" : 4,"end_offset" : 6,"type" : "CN_WORD","position" : 3},{"token" : "里人","start_offset" : 5,"end_offset" : 7,"type" : "CN_WORD","position" : 4}]
}
总结
本文主要介绍了Elasticsearch一些基础命令和用法,是笔者的Elasticsearch学习笔记第一篇,后续将持续更新。
本文代码已放至Github,网址为:https://github.com/percent4/ES_Learning .
相关文章:
)
Elasticsearch入门笔记(一)
环境搭建 Elasticsearch是搜索引擎,是常见的搜索工具之一。 Kibana 是一个开源的分析和可视化平台,旨在与 Elasticsearch 合作。Kibana 提供搜索、查看和与存储在 Elasticsearch 索引中的数据进行交互的功能。开发者或运维人员可以轻松地执行高级数据分析…...
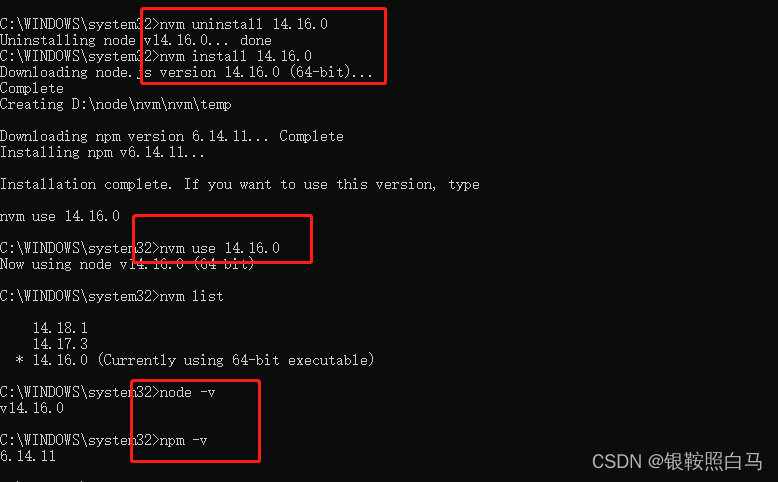
记一次安装nvm切换node.js版本实例详解
最后效果如下: 背景:由于我以前安装过node.js,后续想安装nvm将node.js管理起来。 问题:nvm-use命令行运行成功,但是nvm-list显示并没有成功。 原因:因为安装过node.js,所以原先的node.js不收n…...

生态共建丨YashanDB与构力科技完成兼容互认证
近日,深圳计算科学研究院崖山数据库系统YashanDB V22.2与北京构力科技有限公司BIMBase云平台完成兼容性互认证。经严格测试,双方产品完全兼容、运行稳定。 崖山数据库系统YashanDB是深算院自主研发设计的新型数据库系统,融入原创理论…...

React从入门到实战-react脚手架,消息订阅与发布
创建项目并启动 全局安装 npm install -g create-react-app切换到想创建项目的目录,使用命令:create-react-app 项目名称 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存中…(iQ6hEUgAABpQAAAD1CAYAAABeIRZoAAAAAXNSR0IArs4c6QAAIABJREFUe…...
从零构建深度学习推理框架-1 简介和Tensor
源代码作者:https://github.com/zjhellofss 本文仅作为个人学习心得领悟 ,将原作品提炼,更加适合新手 什么是推理框架? 深度学习推理框架用于对已训练完成的神经网络进行预测,也就是说,能够将深度训练框…...

使用WGCLOUD监测安卓(Android)设备的运行状态
WGCLOUD是一款开源运维监控软件,除了能监控各种服务器、主机、进程应用、端口、接口、docker容器、日志、数据等资源 WGCLOUD还可以监测安卓设备,比如安卓手机、安卓设备等 我们只要下载对应的安卓客户端,部署运行即可,如下是下…...
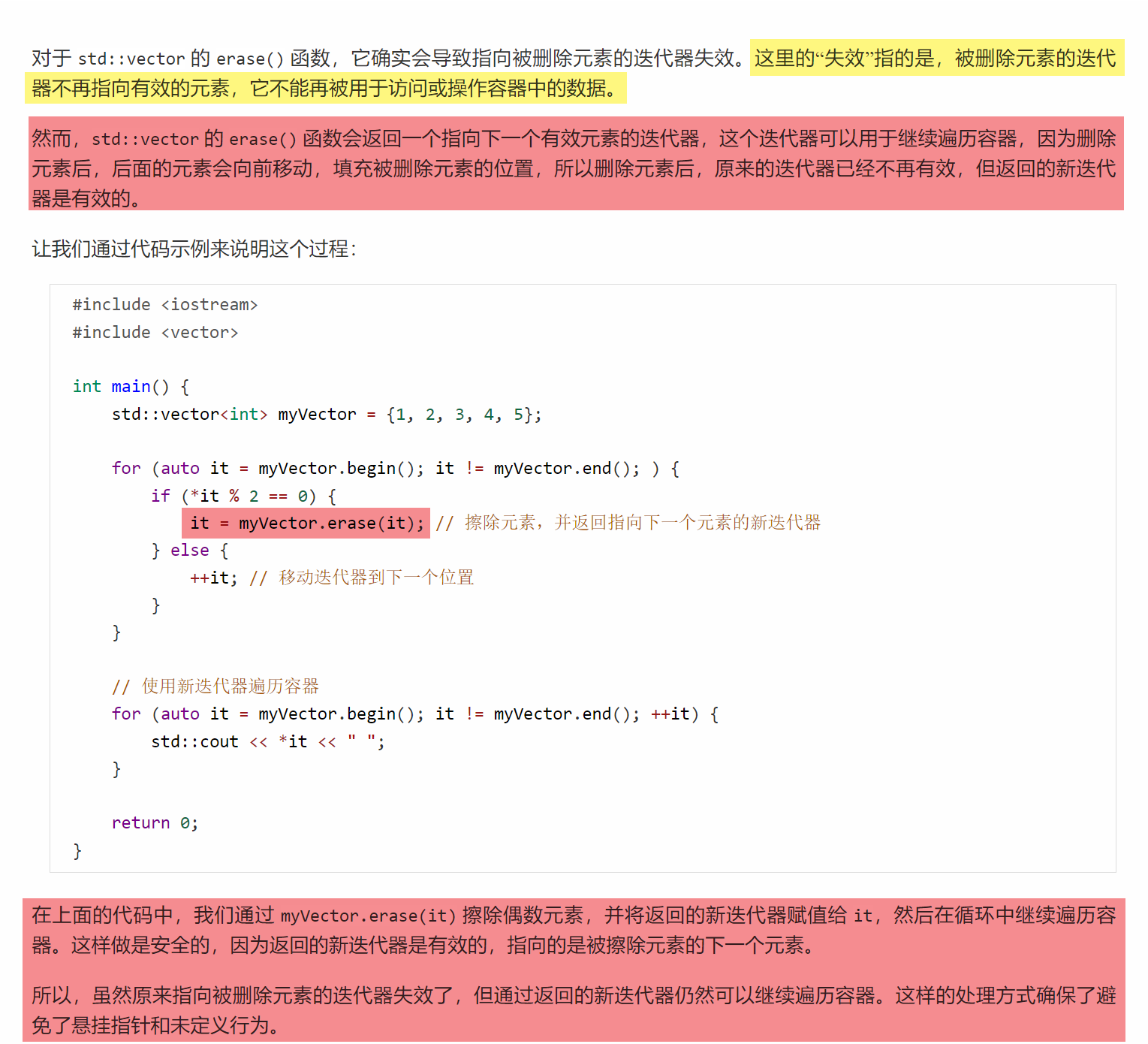
C++笔记之迭代器失效问题处理
C笔记之迭代器失效问题处理 code review! 参考博文:CSTL迭代器失效的几种情况总结 文章目录 C笔记之迭代器失效问题处理一.使用返回新迭代器的插入和删除操作二.对std::vector 来说,擦除(erase)元素会导致迭代器失效 一.使用返回…...

Tomcat的startup.bat文件出现闪退问题
对于双击Tomcat的startup.bat文件出现闪退问题,您提供的分析是正确的。主要原因是Tomcat需要Java Development Kit (JDK)的支持,而如果没有正确配置JAVA_HOME环境变量,Tomcat将无法找到JDK并启动,从而导致闪退。 以下是解决该问题…...

JAVA8-lambda表达式8:在设计模式-模板方法中的应用
传送门 JAVA8-lambda表达式1:什么是lambda表达式 JAVA8-lambda表达式2:常用的集合类api JAVA8-lambda表达式3:并行流,提升效率的利器? JAVA8-lambda表达式4:Optional用法 java8-lambda表达式5…...

React之组件间通信
React之组件间通信 组件通信: 简单讲就是组件之间的传值,包括state、函数等 1、父子组件通信 父组件给子组件传值 核心:1、自定义属性;2、props 父组件中: 自定义属性传值 import Header from /components/Headerconst Home ()…...
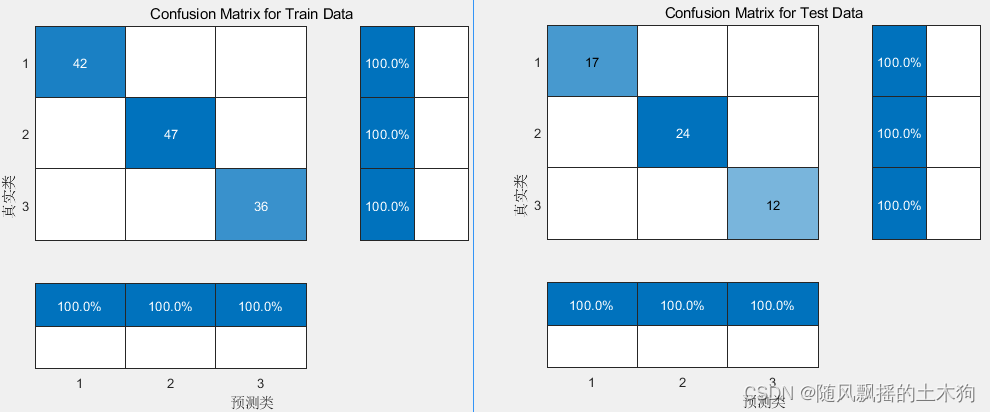
【MATLAB第58期】基于MATLAB的PCA-Kmeans、PCA-LVQ与BP神经网络分类预测模型对比
【MATLAB第58期】基于MATLAB的PCA-Kmeans、PCA-LVQ与BP神经网络分类预测模型对比 一、数据介绍 基于UCI葡萄酒数据集进行葡萄酒分类及产地预测 共包含178组样本数据,来源于三个葡萄酒产地,每组数据包含产地标签及13种化学元素含量,即已知类…...
CF1833 A-E
A题 题目链接:https://codeforces.com/problemset/problem/1833/A 基本思路:for循环遍历字符串s,依次截取字符串s的子串str,并保存到集合中,最后输出集合内元素的数目即可 AC代码: #include <iostrea…...

【深度学习】【Image Inpainting】Generative Image Inpainting with Contextual Attention
Generative Image Inpainting with Contextual Attention DeepFillv1 (CVPR’2018) 论文:https://arxiv.org/abs/1801.07892 论文代码:https://github.com/JiahuiYu/generative_inpainting 论文摘录 文章目录 效果一览摘要介绍论文贡献相关工作Image…...
二维深度卷积网络模型下的轴承故障诊断
1.数据集 使用凯斯西储大学轴承数据集,一共有4种负载下采集的数据,每种负载下有10种 故障状态:三种不同尺寸下的内圈故障、三种不同尺寸下的外圈故障、三种不同尺寸下的滚动体故障和一种正常状态 2.模型(二维CNN) 使…...

redis突然变慢问题定位
CPU 相关:使用复杂度过高命令、O(N)的这个N,数据的持久化,都与耗费过多的 CPU 资源有关 内存相关:bigkey 内存的申请和释放、数据过期、数据淘汰、碎片整理、内存大页、内存写时复制都与内存息息相关 磁盘…...
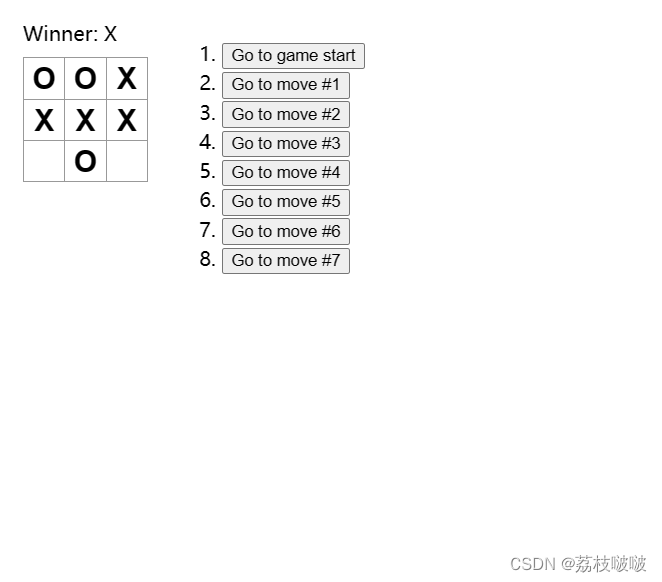
React井字棋游戏官方示例
在本篇技术博客中,我们将介绍一个React官方示例:井字棋游戏。我们将逐步讲解代码实现,包括游戏的组件结构、状态管理、胜者判定以及历史记录功能。让我们一起开始吧! 项目概览 在这个井字棋游戏中,我们有以下组件&am…...

七大经典比较排序算法
1. 插入排序 (⭐️⭐️) 🌟 思想: 直接插入排序是一种简单的插入排序法,思想是是把待排序的数据按照下标从小到大,依次插入到一个已经排好的序列中,直至全部插入,得到一个新的有序序列。例如:…...
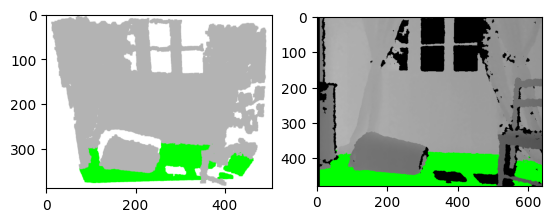
【点云处理教程】03使用 Python 实现地面检测
一、说明 这是我的“点云处理”教程的第3篇文章。“点云处理”教程对初学者友好,我们将在其中简单地介绍从数据准备到数据分割和分类的点云处理管道。 在上一教程中,我们在不使用 Open3D 库的情况下从深度数据计算点云。在本教程中,我们将首先…...
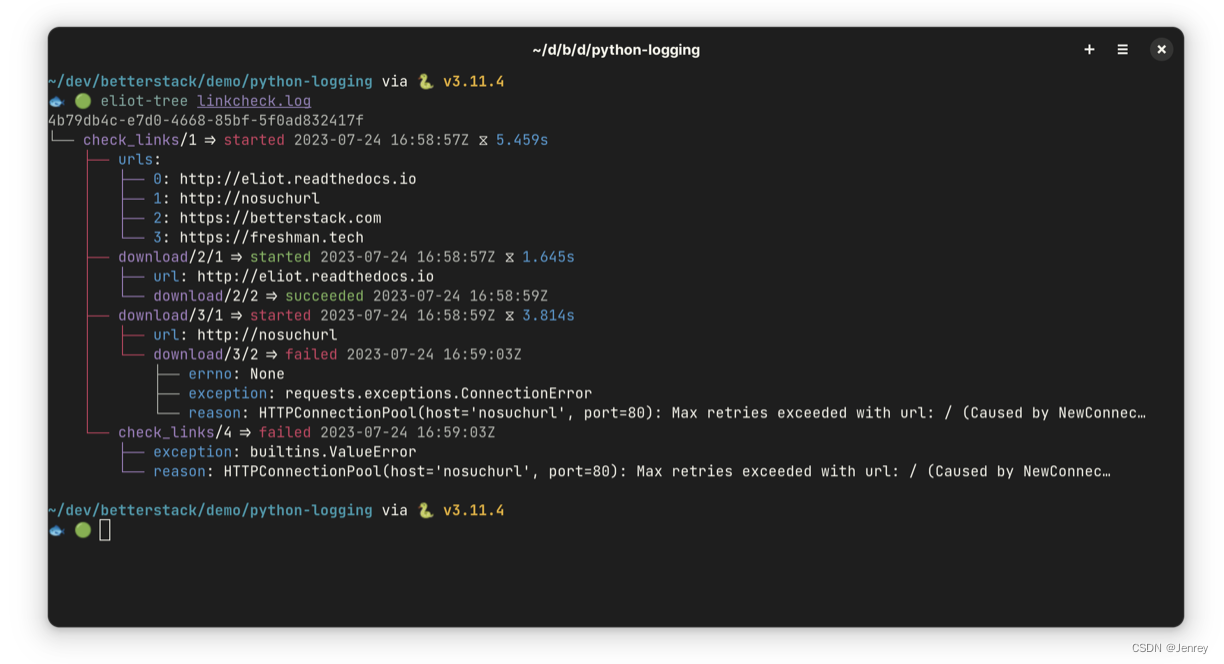
Python 日志记录:6大日志记录库的比较
Python 日志记录:6大日志记录库的比较 文章目录 Python 日志记录:6大日志记录库的比较前言一些日志框架建议1. logging - 内置的标准日志模块默认日志记录器自定义日志记录器生成结构化日志 2. Loguru - 最流行的Python第三方日志框架默认日志记录器自定…...

最近遇到一些问题的解决方案
最近遇到一些问题的解决方案 SpringBoot前后端分离参数传递方式总结Java8版本特性讲解idea使用git更新代码 : update project removeAll引发得java.lang.UnsupportedOperationException异常Java的split()函数用多个不同符号分割 Aspect注解切面demo 抽取公共组件,使…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

uniapp手机号一键登录保姆级教程(包含前端和后端)
目录 前置条件创建uniapp项目并关联uniClound云空间开启一键登录模块并开通一键登录服务编写云函数并上传部署获取手机号流程(第一种) 前端直接调用云函数获取手机号(第三种)后台调用云函数获取手机号 错误码常见问题 前置条件 手机安装有sim卡手机开启…...
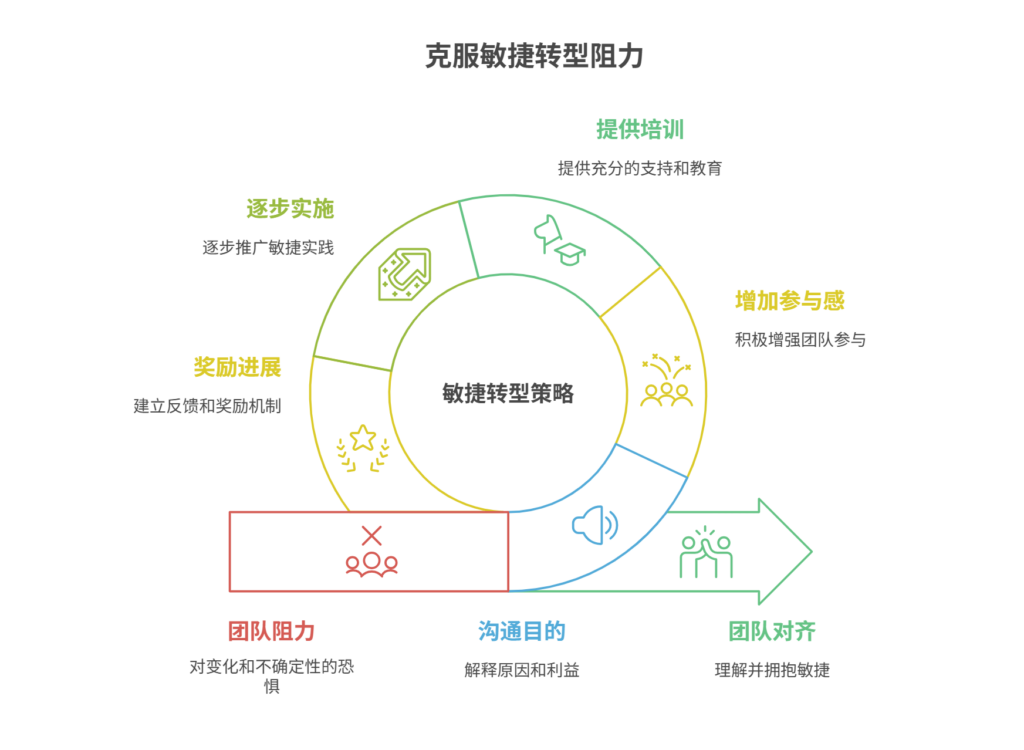
如何应对敏捷转型中的团队阻力
应对敏捷转型中的团队阻力需要明确沟通敏捷转型目的、提升团队参与感、提供充分的培训与支持、逐步推进敏捷实践、建立清晰的奖励和反馈机制。其中,明确沟通敏捷转型目的尤为关键,团队成员只有清晰理解转型背后的原因和利益,才能降低对变化的…...

Xela矩阵三轴触觉传感器的工作原理解析与应用场景
Xela矩阵三轴触觉传感器通过先进技术模拟人类触觉感知,帮助设备实现精确的力测量与位移监测。其核心功能基于磁性三维力测量与空间位移测量,能够捕捉多维触觉信息。该传感器的设计不仅提升了触觉感知的精度,还为机器人、医疗设备和制造业的智…...

如何在Windows本机安装Python并确保与Python.NET兼容
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
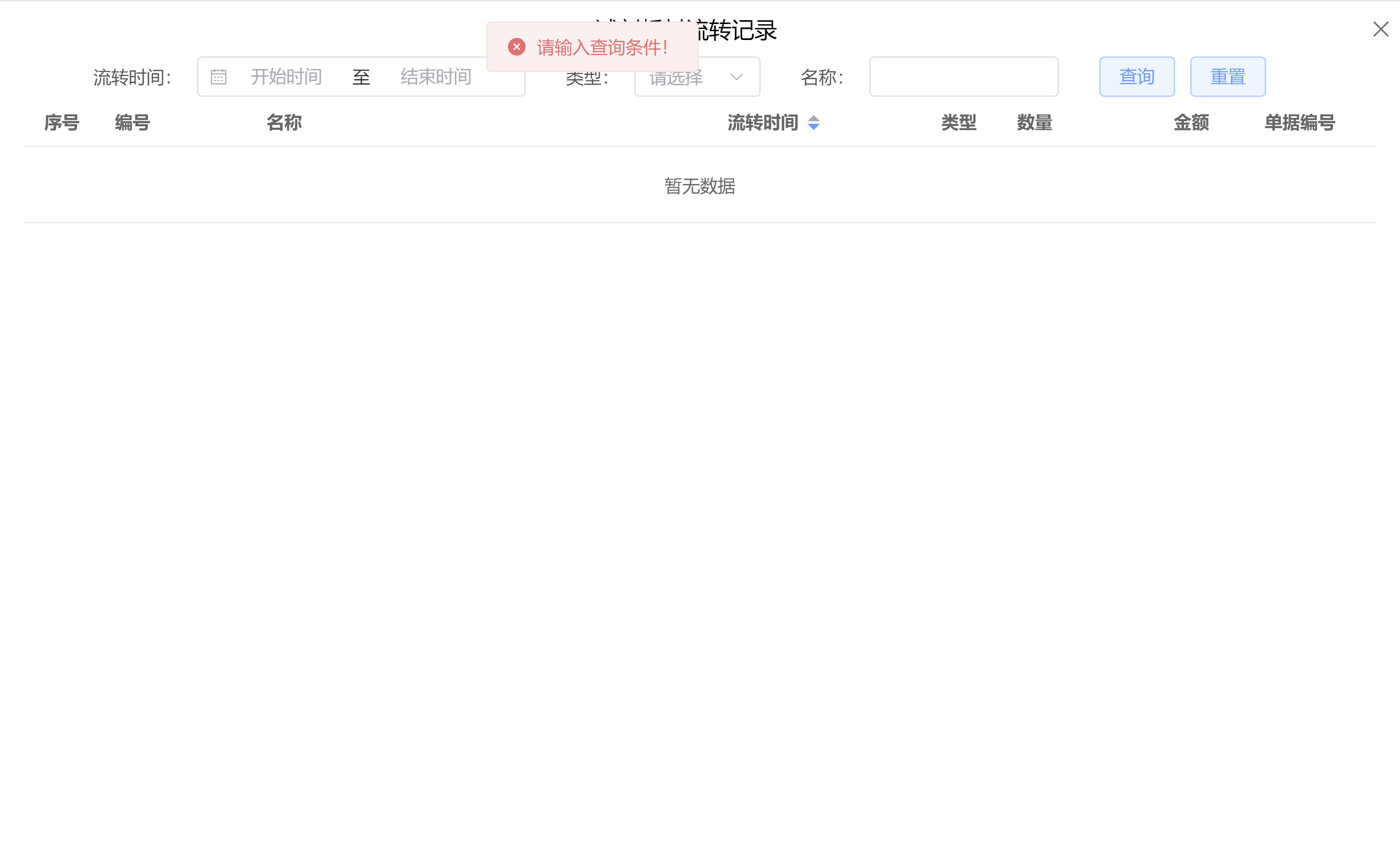
Java后端检查空条件查询
通过抛出运行异常:throw new RuntimeException("请输入查询条件!");BranchWarehouseServiceImpl.java // 查询试剂交易(入库/出库)记录Overridepublic List<BranchWarehouseTransactions> queryForReagent(Branch…...
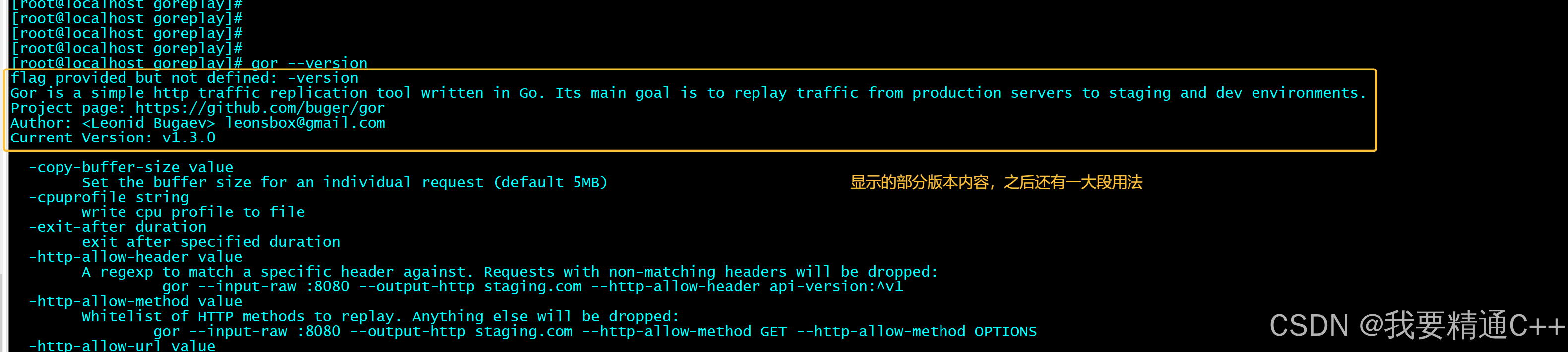
goreplay
1.github地址 https://github.com/buger/goreplay 2.简单介绍 GoReplay 是一个开源的网络监控工具,可以记录用户的实时流量并将其用于镜像、负载测试、监控和详细分析。 3.出现背景 随着应用程序的增长,测试它所需的工作量也会呈指数级增长。GoRepl…...