08- 汽车产品聚类分析综合项目 (机器学习聚类算法) (项目八)
- 找出性价比较高的车
-
LabelEncoder: python:sklearn标签编码(LabelEncoder) sklearn.preprocessing.LabelEncoder的使用:在训练模型之前,通常都要对数据进行一定得处理。将类别编号是一种常用的处理方法,比如把类别“电脑”,“手机”编号为0和1,可使用LabelEncoder函数。
-
作用: 将n个类别编码为0~n-1之间的整数(包括0和n-1)
-
- 找出聚类种类最佳参数
sse =[]
ss = []
for k in range(2,11):kmeans = KMeans(n_clusters= k)kmeans.fit(train_x)sse.append(kmeans.inertia_)ss.append(silhouette_score(train_x,kmeans.predict(train_x)))- kmean 聚类算法模型
kmeans = KMeans(n_clusters=8)
kmeans.fit(train_x)
predict_y = kmeans.predict(train_x) # 预测汽车产品聚类分析综合项目实战
现在人们购车成为稀松平常,你的第一辆车是什么品牌,你打算什么时候更换车辆?汽车品牌多如牛毛,使用数据分析相关知识点,使用机器学习中的聚类算法,进行建模,从而对根据汽车相关属性对汽车进行类别划分,帮你选好车!熟悉算法建模业务流程,掌握机器学习建模的思想和基本操作。
- 数据加载
- 数值编码化
- 归一化操作
- Kmeans算法参数筛选
- 分层聚类使用
- DBSCAN算法使用
- 对比不同算法效果
1 导入模块
# 使用 KMeans 进行聚类,导入库
from sklearn.cluster import KMeans # 聚类算法
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
# 预处理
from sklearn import preprocessing # 归一化
from sklearn.preprocessing import LabelEncoder # 标签编码
import pandas as pd
# 矩阵运算
import numpy as np2 数据加载
data = pd.read_csv('./car_price.csv')
data.shape # (205, 26)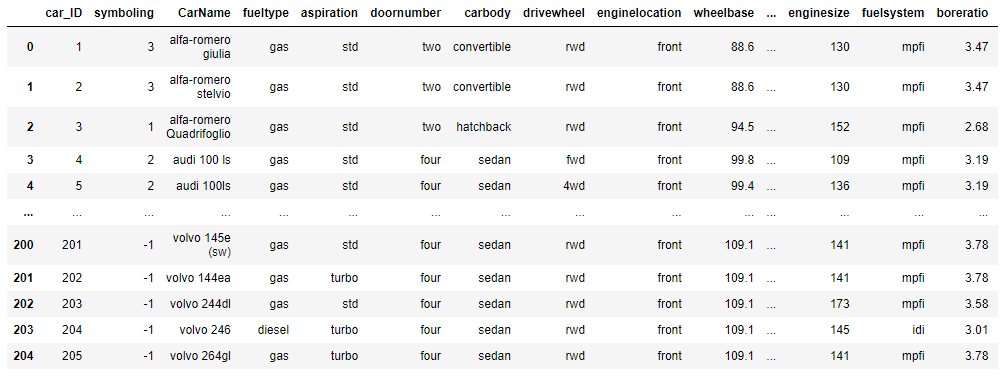
3 去除无效数据
train_X = data.drop(['car_ID','CarName'],axis = 1)
train_X.shape # 205, 244 特征工程(将属性转换为数值)
# 将非数值特征转换为数值
le = LabelEncoder()
colums = ['fueltype','aspiration','doornumber','carbody','drivewheel','enginelocation','enginetype','cylindernumber','fuelsystem']
for column in colums:# 训练并将标签转换为归一化的代码train_X[column] = le.fit_transform(train_X[column])
train_X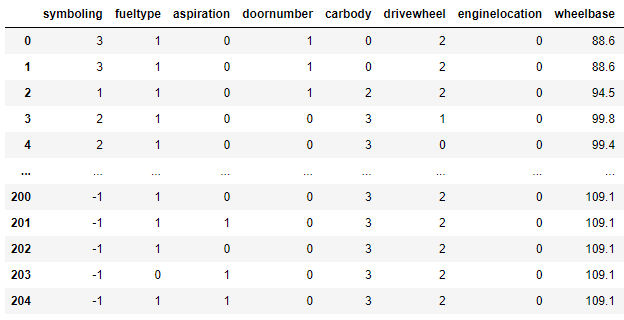
5 归一化
# 规范化到[0,1] 空间
min_max_scaler = preprocessing.MinMaxScaler()
# MinMaxscaler( )将每个要素缩放到给定范围,怡合数据,然后进行转换
train_x = min_max_scaler.fit_transform(train_X)
train_x
6 聚类参数选择
6.1 显示所有系统字体
# 查找自己电脑的字体,从中选择
# 本电脑上,选择的STKaiti
from matplotlib.font_manager import FontManager
fm = FontManager()
[font.name for font in fm.ttflist]
6.2 字体设置
plt.rcParams['font.family'] = 'STKaiti'
plt.rcParams['font.size'] = 206.3 SSE(簇惯性)
sse =[]
ss = []
for k in range(2,11):kmeans = KMeans(n_clusters= k)kmeans.fit(train_x)sse.append(kmeans.inertia_)ss.append(silhouette_score(train_x,kmeans.predict(train_x)))plt.figure(figsize=(16,6))
x = range(2,11)
plt.subplot(1,2,1)
plt.plot(x,sse,'o-')
plt.xlabel('K')
plt.ylabel('SSE簇惯性')plt.subplot(1,2,2)
plt.plot(x,ss,'r*-')
plt.xlabel('K')
plt.ylabel('轮廓系数')
plt.savefig('./1-聚类簇数.png',dpi = 200)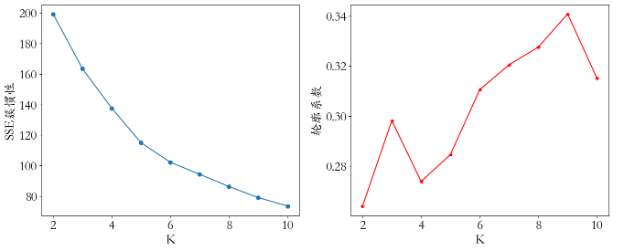
6.4 聚类运算
kmeans = KMeans(n_clusters=8)
kmeans.fit(train_x)# 预测
predict_y = kmeans.predict(train_x)
predict_y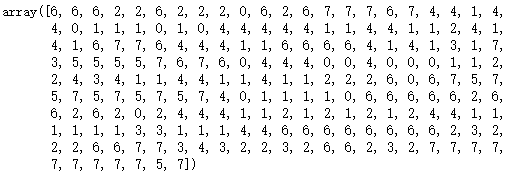
7 结果分析
7.1 结果合并
result = pd.concat((data,pd.DataFrame(predict_y)),axis =1)result.rename({0:u'聚类结果'},axis = 1,inplace = True)
result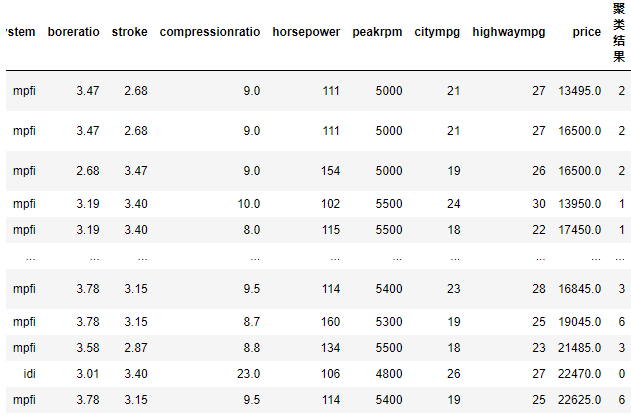
# 分组运算
g1 = result.groupby(by = ['聚类结果','carbody'])[['price']].mean()
g1 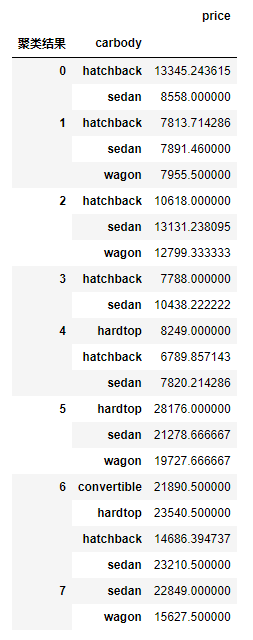
g2 = g1.unstack() # 数据重塑
g2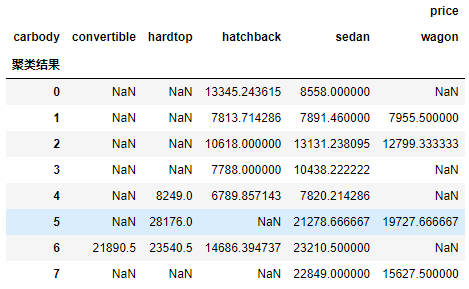
g2.sort_values(by= ('price','sedan'))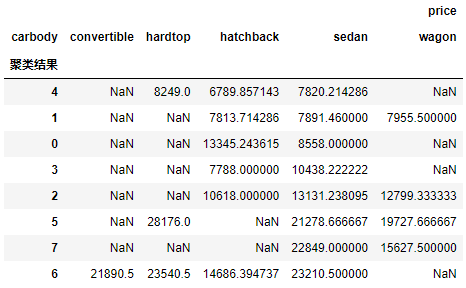
7.2 低端轿车聚类结果
# 查看,类别是1的标准三厢车(具体根据分组运算结果确定)
cond = result.apply(lambda x : x['聚类结果'] == 4 and 'sedan' in x['carbody'] ,axis = 1)
columns = ['CarName','wheelbase','price','horsepower','carbody','fueltype','聚类结果']
# 价格降序排名
result[cond][columns].sort_values('price',ascending= False)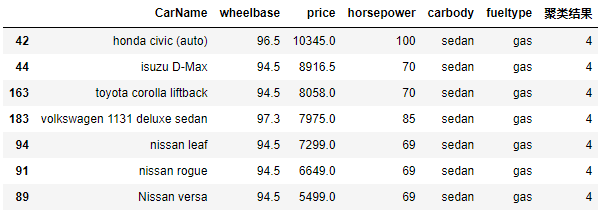
7.3 高端轿车聚类结果
# 根据条件(售价)筛选高端轿车(三厢车)
cond = result.apply(lambda x : x['聚类结果'] == 7 and 'sedan' in x['carbody'], axis =1)
columns = ['CarName','wheelbase','price','horsepower','carbody','fueltype','聚类结果']
# 价格降序排名
result[cond][columns].sort_values('price',ascending= False)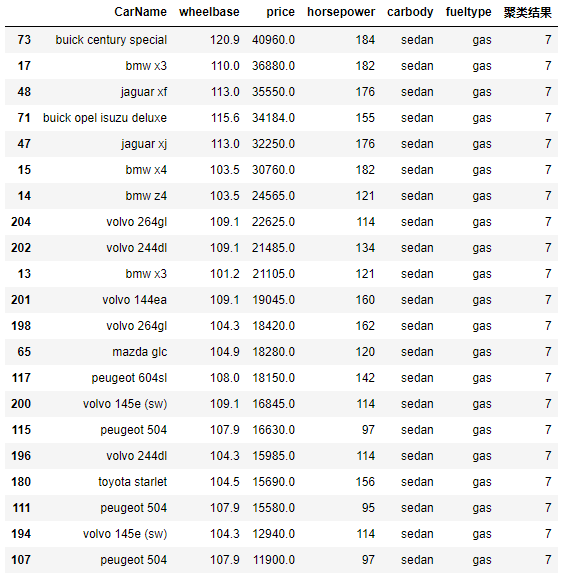
7.4 中端 SUV聚类结果
cond = result.apply(lambda x : x['聚类结果'] == 2 and 'wagon' in x['carbody'], axis =1)
columns = ['CarName','wheelbase','price','horsepower','carbody','fueltype','聚类结果']
# 价格降序排名
result[cond][columns].sort_values('price',ascending= False)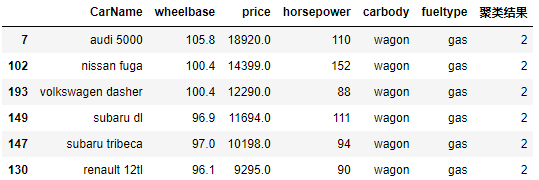
相关文章:
08- 汽车产品聚类分析综合项目 (机器学习聚类算法) (项目八)
找出性价比较高的车 LabelEncoder: python:sklearn标签编码(LabelEncoder) sklearn.preprocessing.LabelEncoder的使用:在训练模型之前,通常都要对数据进行一定得处理。将类别编号是一种常用的处理方法,比如把类别“电脑”,“手机…...

揭开苹果供应链,如何将其命运与中国深度捆绑
前 言 诺基亚在2007年时拥有9亿用户,在手机市场上占据主导地位,福布斯在当时以“谁能赶上手机之王?”为标题刊登了一篇关于该公司的报道,与此同时,苹果公司推出了iPhone系列产品。16年后,苹果公司以充足的…...
Mybatis 之useGeneratedKeys注意点
一.例子 Order.javapublic class Order {private Long id;private String serial; }orderMapper.xml<?xml version"1.0" encoding"UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org/DTD Mapper 3.0" "http://mybatis.org/dtd…...
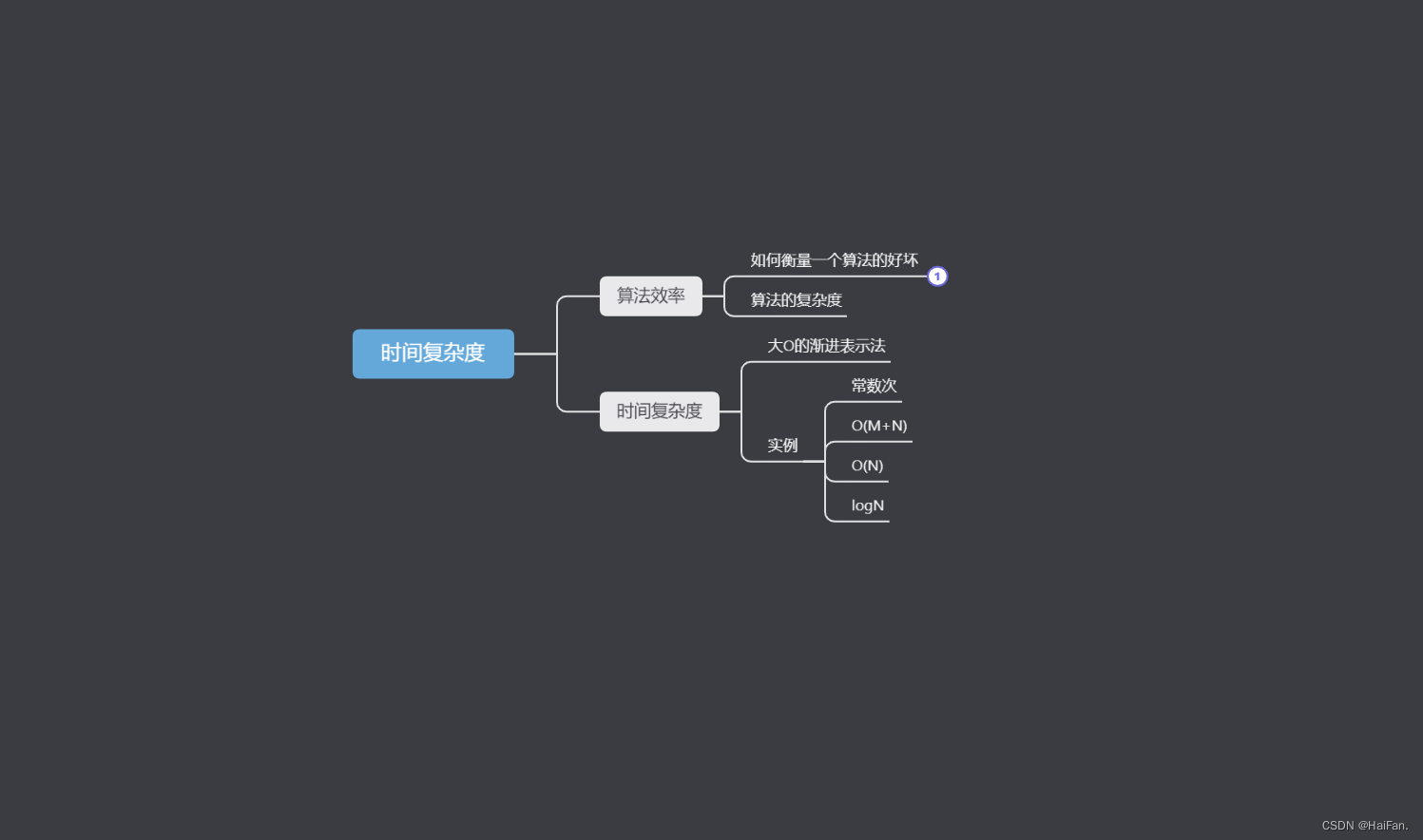
数据结构---时间复杂度
专栏:数据结构 个人主页:HaiFan. 专栏简介:开学数据结构,接下来会慢慢坑新数据结构的内容!!!! 时间复杂度前言1.算法效率1.1如何衡量一个算法的好坏1.2算法的复杂度2.时间复杂度2.1大…...

如何保证集合是线程安全的 ConcurrentHashMap如何实现高效地线程安全?
第10讲 | 如何保证集合是线程安全的? ConcurrentHashMap如何实现高效地线程安全? 我在之前两讲介绍了 Java 集合框架的典型容器类,它们绝大部分都不是线程安全的,仅有的线程安全实现,比如 Vector、Stack,在性能方面也…...

C++对象模型和this指针
成员变量和成员函数分开存储:基本概念:在C中,类内的成员变量和成员函数分开存储只有非静态成员变量才属于类的对象上每个空对象都会有一个独一无二的内存地址,所以,空对象占用内存空间的大小为1代码实现:#i…...
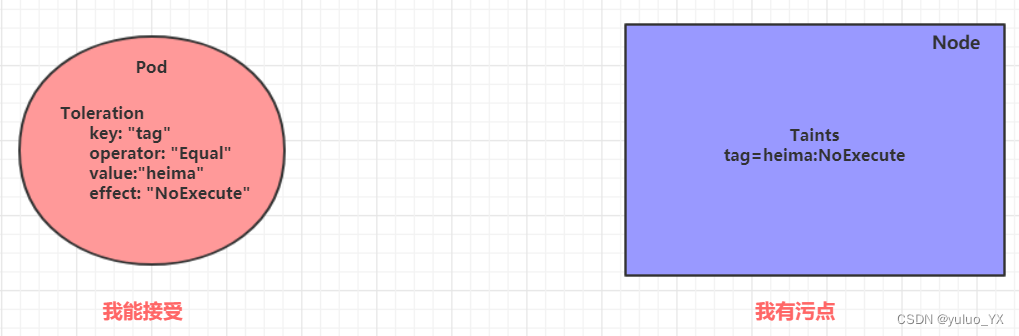
kubernetes教程 --Pod调度
Pod调度 在默认情况下,一个Pod在哪个Node节点上运行,是由Scheduler组件采用相应的算法计算出来的,这个过程是不受人工控制的。但是在实际使用中,这并不满足的需求,因为很多情况下,我们想控制某些Pod到达某…...

功率放大器科普知识(晶体管功率放大器的注意事项)
虽然功率放大器是电子实验室的常用仪器,但是很多人对于它却没有清晰的认识,下面就让安泰电子来为大家介绍功率放大器的科普内容以及使用注意事项,希望大家可以对功率放大器有清晰的认识。功率放大器可以把输入信号的功率放大,以满…...
CentOS 7转化系统为阿里龙蜥Anolis OS 7
转载:原社区CentOS 7迁移Anolis OS 7迁移手册 一、注意事项 Anolis OS 7生态上和依赖管理上保持跟CentOS7.x兼容,一键式迁移脚本centos2anolis.py,实现CentOS7.x到Anolis OS 7的平滑迁移。 使用迁移脚本前需要注意如下事项: 迁…...
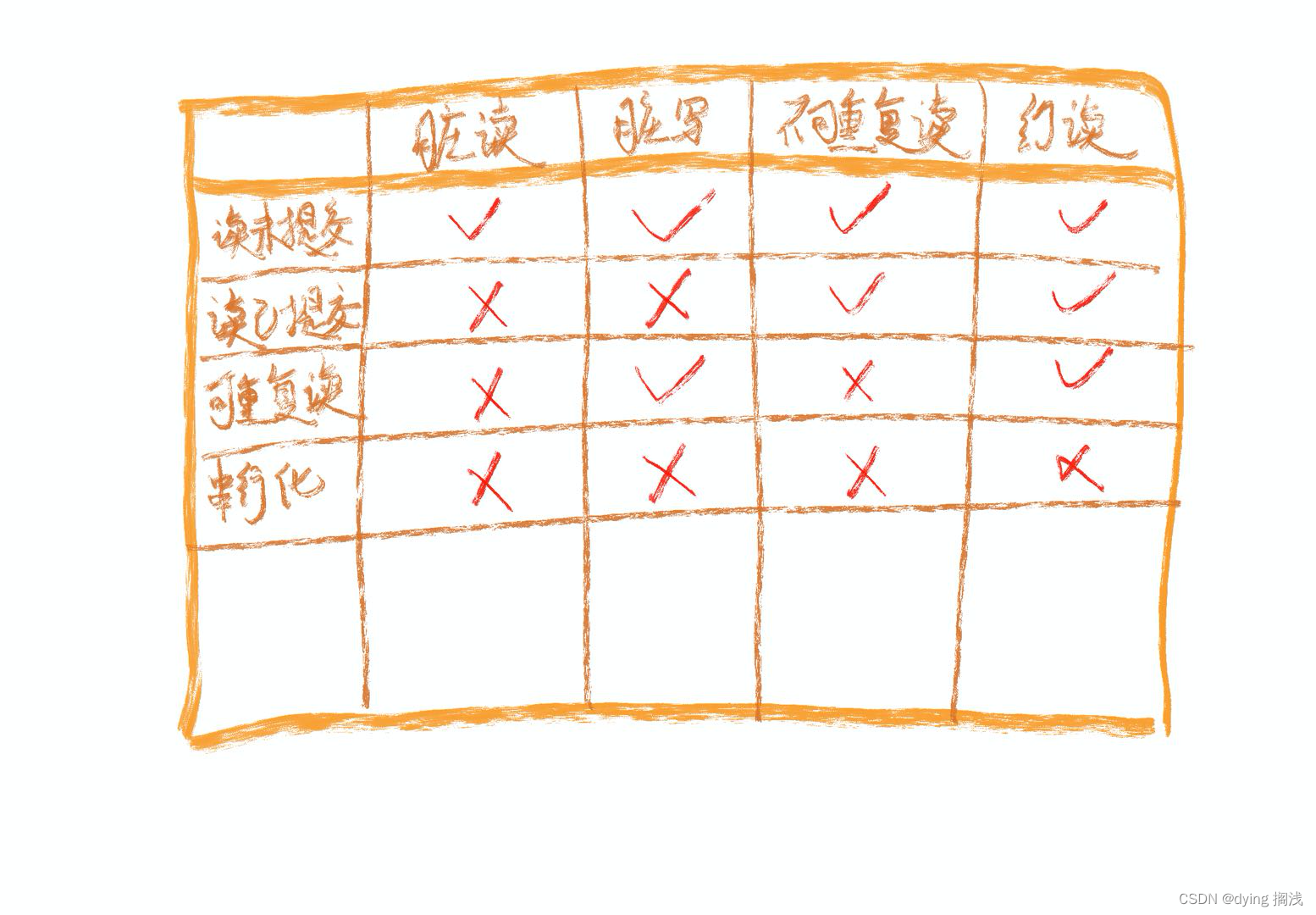
【快速复习】一文看懂 Mysql 核心存储 隔离级别 锁 MVCC 机制
一文看懂 Mysql 核心存储 & 隔离级别 & 锁 & MVCC 机制 Mysql InnoDB 引擎下核心存储 数据&索引存储 IBD 文件 mysql 实际存储采用 B 树结构。 B 树是一种多路搜索树,其搜索性能高于 B 树 所有叶节点在同一深度,保证搜索效率仅叶节…...
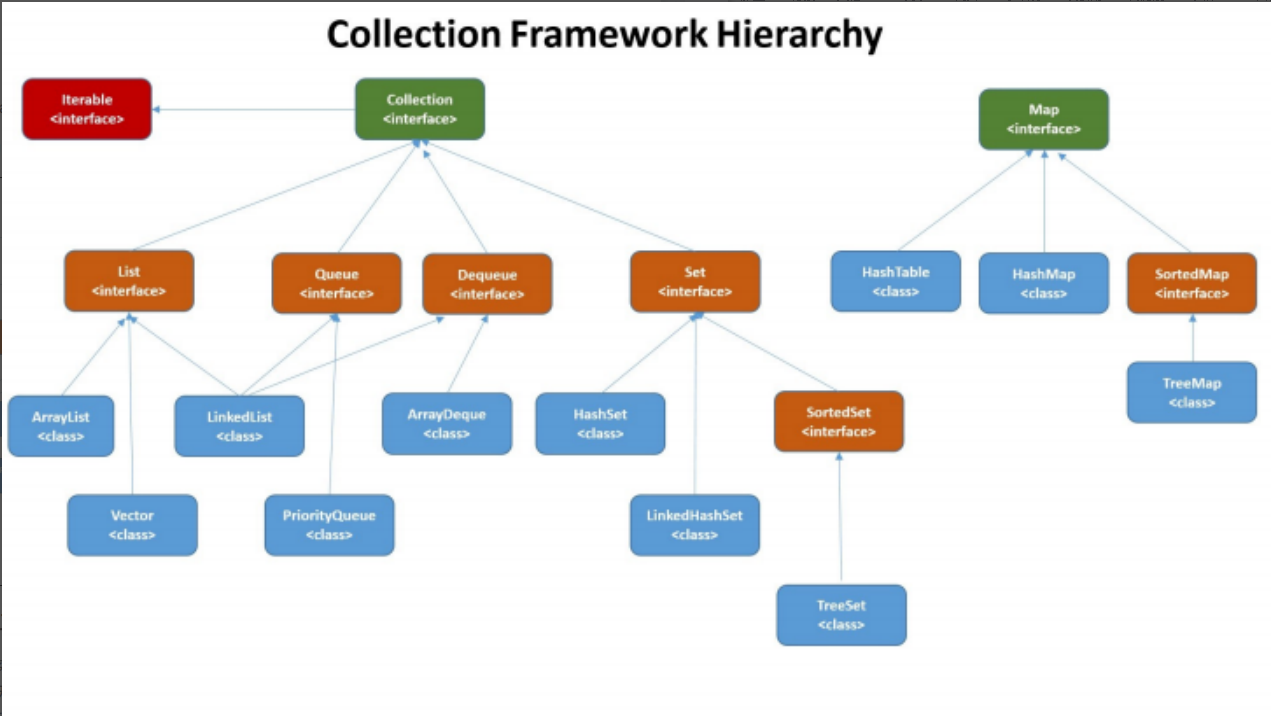
面试题----集合
概述 从上图可以看出,在Java 中除了以 Map 结尾的类之外, 其他类都实现了 Collection 接⼝。 并且,以 Map 结尾的类都实现了 Map 接⼝List,Set,Map List (对付顺序的好帮⼿): 存储的元素是有序的、可重复的。 Set (注重独⼀⽆⼆…...
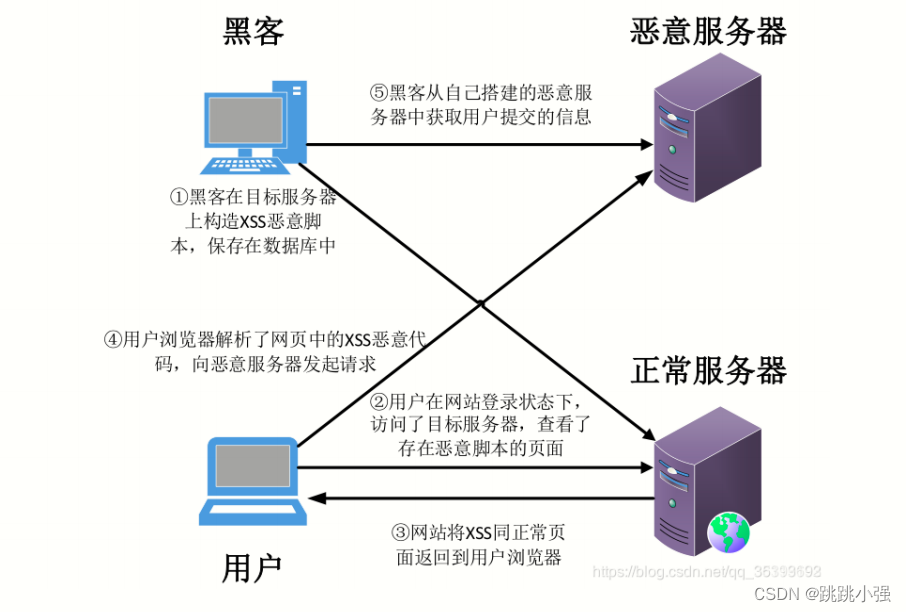
XSS注入基础入门篇
XSS注入基础入门篇1.XSS基础概念2. XSS的分类以及示例2.1 反射型XSS2.1.1 示例1:dvwa low 级别的反射型XSS2.1.2 攻击流程2.2 DOM型XSS2.2.1 示例2:DOM型XSS注入1.环境部署2.基础版本3.进阶绕过2.3 存储型XSS2.3.1 示例1:dvwa low示例2.3.2 攻…...
链表)
刷题 - 数据结构(二)链表
1. 链表 1.1 题目:合并两个有序链表 链表的建立与插入:关键在于留出头部,创建迭代指针。 ListNode* head new ListNode; // 通过new 创建了一个数据类型为ListNode的数据 并把该数据的地址赋值给ListNodeListNode* p 0; // 再创建一个数据…...

用于隔离PWM的光耦合器选择和使用
光耦合器(或光隔离器)是一种将电路电隔离的器件,不仅在隔离方面非常出色,而且允许您连接到具有不同接地层或在不同电压电平下工作的电路。光耦合器具有“故障安全”功能,因为如果受到高于最大额定值的电压,…...
面试完阿里,字节,腾讯的测试岗,复盘以及面试总结
前段时间由于某些原因辞职了,最近一直在面试。面试这段时间,经历过不同业务类型的公司(电商、酒店出行、金融、新能源、银行),也遇到了很多不同类型的面试官。 参加完三家大厂的面试聊聊我对面试的一些看法࿰…...

分享一个外贸客户案例
春节期间一个外贸人收到了客户的回复,但因为自己的处理方式造成了一个又一个问题,我们可以从中学到一些技巧和知识。“上次意大利的客人询价后,一直没回复(中间有打过电话,对方说口语不行,我写过邮件跟进过…...
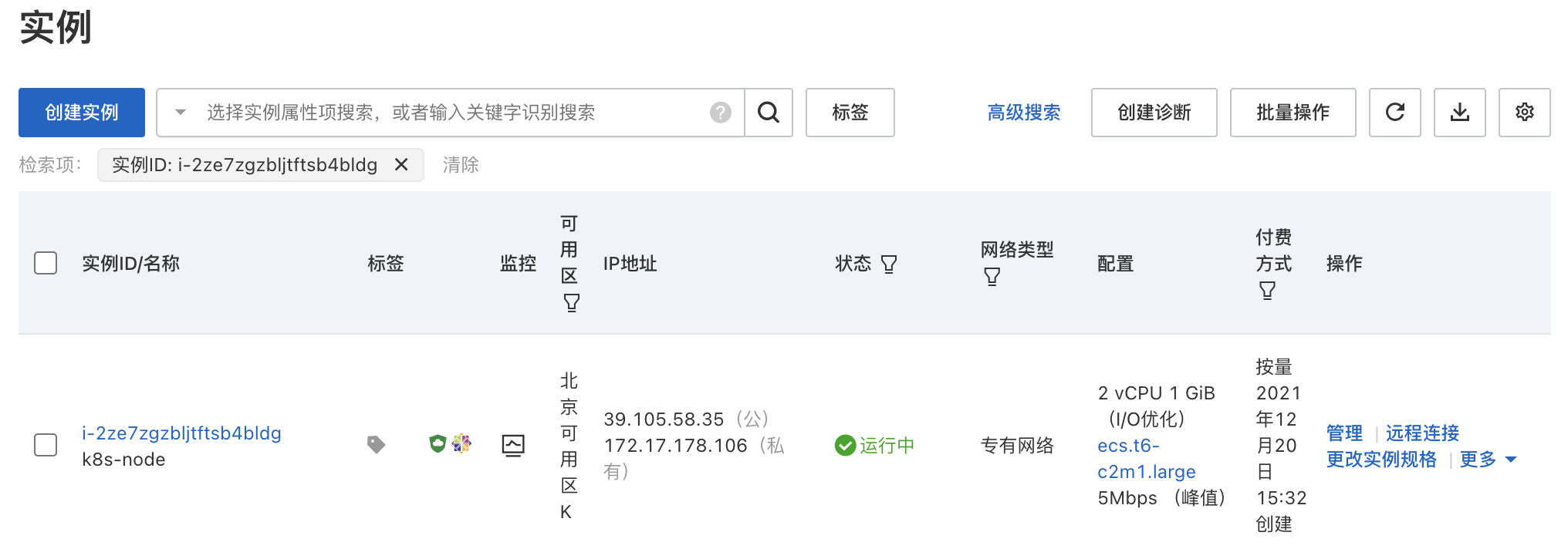
【Kubernetes】第二篇 - 购买阿里云 ECS 实例
一,前言 上一篇,简单介绍了 CI/CD 的概念以及 ECS 服务规划,搭建整套服务需要三台服务器,配置如下: ECS 配置启动服务说明2核4GJenkins Nexus Dockerci-server2核4GDocker Kubernetesk8s-master1核1GDocker Kube…...

数影周报:据传国内45亿条快递数据泄露,聆心智能完成Pre-A轮融资
本周看点:据传国内45亿条快递数据泄露;消息称微软解雇150 名云服务销售;消息称TikTok计划在欧洲再开两个数据中心;衣服长时间放购物车被淘宝客服嘲讽;聆心智能完成Pre-A轮融资......数据安全那些事据传国内45亿条快递数…...
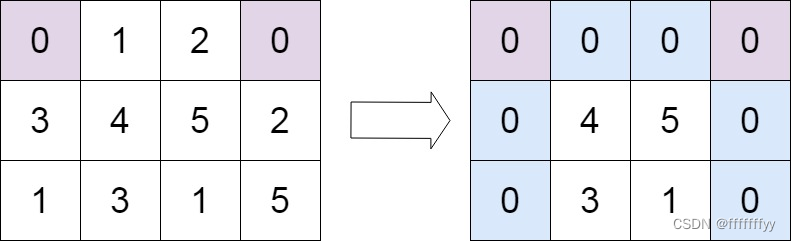
Leetcode力扣秋招刷题路-0073
从0开始的秋招刷题路,记录下所刷每道题的题解,帮助自己回顾总结 73. 矩阵置零 给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。 示例 1: 输入:mat…...

遥感数字图像处理
遥感数字图像处理 来源:慕课北京师范大学朱文泉老师的课程 遥感应用:遥感制图、信息提取 短期内了解知识结构–>有选择的剖析经典算法原理–>系统化知识结构、并尝试实践应用 跳出算法(尤其是数学公式) 关注原理及解决问…...

腾讯对OpenClaw技能数据的抓取行为,究竟是符合开源精神的本地镜像还是侵害开发者权益的恶意抄袭?
关于腾讯抓取OpenClaw技能数据这件事,最近在开发者圈子里讨论得挺多。乍一看,这似乎又是一个大厂与小开发者之间的经典矛盾,但仔细琢磨,会发现里面有些细节值得掰开谈谈。 先说说开源精神这件事。开源社区的核心,其实是…...

3.15二刷基础90、105、106、110
题目:对于一个字符串,编程找出其中的所有整数。例如,字符串“a12bc34d05”,其中有整数12、34、5。要点总结:用一个temp字符串保留中间的结果,如果扫到字母且temp有值,那么一个整数扫完了&#x…...

专注AI优化的服务商
随着人工智能技术向各行业深度渗透,企业在AI应用过程中常面临模型效率低、部署成本高、场景适配难等核心痛点。专注AI优化的服务商成为破解这些问题的关键力量,而超智引擎人工智能科技凭借其专业技术能力与深度行业经验,为企业提供高效的AI优…...

STC32G12K128 ZERO开发板:树莓派Zero兼容的8051高性能嵌入式平台
1. 项目概述STC32G12K128 ZERO 是一款面向嵌入式开发与教学实践的紧凑型高性能MCU开发板,其物理尺寸与引脚布局严格兼容树莓派Zero标准(53.5 mm 29.5 mm),在保持极小体积的同时,完整释放STC32G12K128芯片全部128个I/O…...

MySQL函数索引避坑指南:别让函数毁了你的索引!
明明给字段建了索引,可查询时加个简单的函数(比如DATE(create_time)、UPPER(name)),执行速度瞬间变慢;EXPLAIN一看,key字段显示NULL,索引直接失效,全表扫描找上门。比如这样一条SQL&…...

【Dify多智能体协同成本控制白皮书】:20年架构师亲授3类隐性成本识别法与5步动态预算收敛策略
第一章:Dify多智能体协同成本控制的战略价值与范式演进在大模型应用规模化落地的临界点上,Dify 通过原生支持多智能体(Multi-Agent)编排,将传统单任务推理的成本结构重构为可调度、可度量、可优化的协同治理范式。其战…...

浦语灵笔2.5-7B真实案例:视障用户上传照片→自然语言描述生成演示
浦语灵笔2.5-7B真实案例:视障用户上传照片→自然语言描述生成演示 1. 项目背景与价值 想象一下,如果你无法看到这个世界,却收到了一张朋友发来的照片,那种好奇与无奈交织的感觉。对于视障用户来说,图片内容一直是个难…...

解决NX二次开发DLL签名问题:从编译到部署的完整避坑指南
解决NX二次开发DLL签名问题:从编译到部署的完整避坑指南 在工业设计领域,NX作为一款功能强大的CAD/CAM/CAE软件,其二次开发能力为企业的定制化需求提供了无限可能。然而,许多开发者在进行NX二次开发时,常常会遇到一个令…...
 两张图总结 Neutron 架构 - 每天5分钟玩转)
运维系列虚拟化系列OpenStack系列【仅供参考】:Service Plugin / Agent - 每5玩OpenStack(73) 两张图总结 Neutron 架构 - 每天5分钟玩转
Service Plugin / Agent - 每天5分钟玩转 OpenStack(73) && 两张图总结 Neutron 架构 - 每天5分钟玩转 OpenStack(74) Service Plugin / Agent - 每天5分钟玩转 OpenStack(73) DHCP Routing Firewall Load Balance 两张图总结 Neutron 架构 - 每天5分钟玩转 Open…...

为什么某些老电脑只支持4G内存?
为什么有些老电脑只支持4G内存?首先要明确: (1) 32位操作系统限制的是“能用多少”, (2) 老电脑某些老主板限制的是“能插多大”。简单来说:32位系统确实只认4G,但很多老…...