cmu 445 poject 2笔记
2022年的任务 https://15445.courses.cs.cmu.edu/fall2022/project2/
checkpoint 1,实现b+树,读,写,删
checkpoint 2, 实现b+树,迭代器,并发读写删
本文不写代码,只记录遇到的一些思维盲点
checkpoint 1
先理解B+树的几个操作,以及先看一份别的代码,最后再在bushub的代码框架下实现逻辑。
可以参考的一份B+树的代码,带注释。毕竟不看代码,光看图还是有些迷糊的。
// Deletion operation on a B+ Tree in C++#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>#define DEFAULT_ORDER 3typedef struct record {int value;
} record;typedef struct node {void **pointers;int *keys;struct node *parent;bool is_leaf;int num_keys;struct node *next;
} node;int order = DEFAULT_ORDER;
node *queue = NULL;
bool verbose_output = false;void enqueue(node *new_node);
node *dequeue(void);
int height(node *const root);
int path_to_root(node *const root, node *child);
void print_leaves(node *const root);
void print_tree(node *const root);
void find_and_print(node *const root, int key, bool verbose);
void find_and_print_range(node *const root, int range1, int range2,bool verbose);
int find_range(node *const root, int key_start, int key_end, bool verbose,int returned_keys[], void *returned_pointers[]);node *find_leaf(node *const root, int key, bool verbose);
record *find(node *root, int key, bool verbose, node **leaf_out);
int cut(int length);record *make_record(int value);
node *make_node(void);
node *make_leaf(void);
int get_left_index(node *parent, node *left);
node *insert_into_leaf(node *leaf, int key, record *pointer);
node *insert_into_leaf_after_splitting(node *root, node *leaf, int key,record *pointer);
node *insert_into_node(node *root, node *parent, int left_index, int key,node *right);
node *insert_into_node_after_splitting(node *root, node *parent, int left_index,int key, node *right);
node *insert_into_parent(node *root, node *left, int key, node *right);
node *insert_into_new_root(node *left, int key, node *right);
node *start_new_tree(int key, record *pointer);
node *insert(node *root, int key, int value);int get_neighbor_index(node *n);
node *adjust_root(node *root);
node *coalesce_nodes(node *root, node *n, node *neighbor, int neighbor_index,int k_prime);
node *redistribute_nodes(node *root, node *n, node *neighbor,int neighbor_index, int k_prime_index, int k_prime);
node *delete_entry(node *root, node *n, int key, void *pointer);
node *delete_op(node *root, int key);void enqueue(node *new_node) {node *c;if (queue == NULL) {queue = new_node;queue->next = NULL;} else {c = queue;while (c->next != NULL) {c = c->next;}c->next = new_node;new_node->next = NULL;}
}node *dequeue(void) {node *n = queue;queue = queue->next;n->next = NULL;return n;
}void print_leaves(node *const root) {if (root == NULL) {printf("Empty tree.\n");return;}int i;node *c = root;while (!c->is_leaf) c = c->pointers[0];while (true) {for (i = 0; i < c->num_keys; i++) {if (verbose_output) printf("%p ", c->pointers[i]);printf("%d ", c->keys[i]);}if (verbose_output) printf("%p ", c->pointers[order - 1]);if (c->pointers[order - 1] != NULL) {printf(" | ");c = c->pointers[order - 1];} elsebreak;}printf("\n");
}int height(node *const root) {int h = 0;node *c = root;while (!c->is_leaf) {c = c->pointers[0];h++;}return h;
}
int path_to_root(node *const root, node *child) {int length = 0;node *c = child;while (c != root) {c = c->parent;length++;}return length;
}void print_tree(node *const root) {node *n = NULL;int i = 0;int rank = 0;int new_rank = 0;if (root == NULL) {printf("Empty tree.\n");return;}queue = NULL;enqueue(root);while (queue != NULL) {n = dequeue();if (n->parent != NULL && n == n->parent->pointers[0]) {new_rank = path_to_root(root, n);if (new_rank != rank) {rank = new_rank;printf("\n");}}if (verbose_output) printf("(%p)", n);for (i = 0; i < n->num_keys; i++) {if (verbose_output) printf("%p ", n->pointers[i]);printf("%d ", n->keys[i]);}if (!n->is_leaf)for (i = 0; i <= n->num_keys; i++) enqueue(n->pointers[i]);if (verbose_output) {if (n->is_leaf)printf("%p ", n->pointers[order - 1]);elseprintf("%p ", n->pointers[n->num_keys]);}printf("| ");}printf("\n");
}void find_and_print(node *const root, int key, bool verbose) {node *leaf = NULL;record *r = find(root, key, verbose, NULL);if (r == NULL)printf("Record not found under key %d.\n", key);elseprintf("Record at %p -- key %d, value %d.\n", r, key, r->value);
}void find_and_print_range(node *const root, int key_start, int key_end,bool verbose) {int i;int array_size = key_end - key_start + 1;int returned_keys[array_size];void *returned_pointers[array_size];int num_found = find_range(root, key_start, key_end, verbose, returned_keys,returned_pointers);if (!num_found)printf("None found.\n");else {for (i = 0; i < num_found; i++)printf("Key: %d Location: %p Value: %d\n", returned_keys[i],returned_pointers[i], ((record *)returned_pointers[i])->value);}
}int find_range(node *const root, int key_start, int key_end, bool verbose,int returned_keys[], void *returned_pointers[]) {int i, num_found;num_found = 0;node *n = find_leaf(root, key_start, verbose);if (n == NULL) return 0;for (i = 0; i < n->num_keys && n->keys[i] < key_start; i++);if (i == n->num_keys) return 0;while (n != NULL) {for (; i < n->num_keys && n->keys[i] <= key_end; i++) {returned_keys[num_found] = n->keys[i];returned_pointers[num_found] = n->pointers[i];num_found++;}n = n->pointers[order - 1];i = 0;}return num_found;
}node *find_leaf(node *const root, int key, bool verbose) {if (root == NULL) {if (verbose) printf("Empty tree.\n");return root;}int i = 0;node *c = root;while (!c->is_leaf) {if (verbose) {printf("[");for (i = 0; i < c->num_keys - 1; i++) printf("%d ", c->keys[i]);printf("%d] ", c->keys[i]);}i = 0;while (i < c->num_keys) {if (key >= c->keys[i])i++;elsebreak;}if (verbose) printf("%d ->\n", i);c = (node *)c->pointers[i];}if (verbose) {printf("Leaf [");for (i = 0; i < c->num_keys - 1; i++) printf("%d ", c->keys[i]);printf("%d] ->\n", c->keys[i]);}return c;
}record *find(node *root, int key, bool verbose, node **leaf_out) {if (root == NULL) {if (leaf_out != NULL) {*leaf_out = NULL;}return NULL;}int i = 0;node *leaf = NULL;leaf = find_leaf(root, key, verbose);for (i = 0; i < leaf->num_keys; i++)if (leaf->keys[i] == key) break;if (leaf_out != NULL) {*leaf_out = leaf;}if (i == leaf->num_keys)return NULL;elsereturn (record *)leaf->pointers[i];
}int cut(int length) {if (length % 2 == 0)return length / 2;elsereturn length / 2 + 1;
}record *make_record(int value) {record *new_record = (record *)malloc(sizeof(record));if (new_record == NULL) {perror("Record creation.");exit(EXIT_FAILURE);} else {new_record->value = value;}return new_record;
}node *make_node(void) {node *new_node;new_node = malloc(sizeof(node));if (new_node == NULL) {perror("Node creation.");exit(EXIT_FAILURE);}new_node->keys = malloc((order - 1) * sizeof(int));if (new_node->keys == NULL) {perror("New node keys array.");exit(EXIT_FAILURE);}new_node->pointers = malloc(order * sizeof(void *));if (new_node->pointers == NULL) {perror("New node pointers array.");exit(EXIT_FAILURE);}new_node->is_leaf = false;new_node->num_keys = 0;new_node->parent = NULL;new_node->next = NULL;return new_node;
}node *make_leaf(void) {node *leaf = make_node();leaf->is_leaf = true;return leaf;
}int get_left_index(node *parent, node *left) {int left_index = 0;while (left_index <= parent->num_keys && parent->pointers[left_index] != left)left_index++;return left_index;
}node *insert_into_leaf(node *leaf, int key, record *pointer) {int i, insertion_point;insertion_point = 0;// 找到对应的位置,即插入排序while (insertion_point < leaf->num_keys && leaf->keys[insertion_point] < key)insertion_point++;// 往后移动元素,腾挪位置给新的记录for (i = leaf->num_keys; i > insertion_point; i--) {leaf->keys[i] = leaf->keys[i - 1];leaf->pointers[i] = leaf->pointers[i - 1];}leaf->keys[insertion_point] = key;leaf->pointers[insertion_point] = pointer;leaf->num_keys++;return leaf;
}node *insert_into_leaf_after_splitting(node *root, node *leaf, int key,record *pointer) {node *new_leaf;int *temp_keys;void **temp_pointers;int insertion_index, split, new_key, i, j;// 创建一个新的叶子节点new_leaf = make_leaf();temp_keys = malloc(order * sizeof(int));if (temp_keys == NULL) {perror("Temporary keys array.");exit(EXIT_FAILURE);}temp_pointers = malloc(order * sizeof(void *));if (temp_pointers == NULL) {perror("Temporary pointers array.");exit(EXIT_FAILURE);}insertion_index = 0;// 先找到新记录在叶子节点中该插入的位置,需要注意的是叶子节点是order -// 1个key,和order - 1个指针while (insertion_index < order - 1 && leaf->keys[insertion_index] < key)insertion_index++;// 把叶子节点的记录拷贝到tmp数组下,其中给新插入的记录预留一个位置for (i = 0, j = 0; i < leaf->num_keys; i++, j++) {if (j == insertion_index) j++;temp_keys[j] = leaf->keys[i];temp_pointers[j] = leaf->pointers[i];}// 将新记录插入到tmp数组中temp_keys[insertion_index] = key;temp_pointers[insertion_index] = pointer;leaf->num_keys = 0;// 拆分叶子节点split = cut(order - 1);// 将tmp数组的前一半拷贝回当前叶子节点for (i = 0; i < split; i++) {leaf->pointers[i] = temp_pointers[i];leaf->keys[i] = temp_keys[i];leaf->num_keys++;}// 将tmp数组的前一半拷贝回新叶子节点for (i = split, j = 0; i < order; i++, j++) {new_leaf->pointers[j] = temp_pointers[i];new_leaf->keys[j] = temp_keys[i];new_leaf->num_keys++;}free(temp_pointers);free(temp_keys);// 末尾指针指向右兄弟节点new_leaf->pointers[order - 1] = leaf->pointers[order - 1];leaf->pointers[order - 1] = new_leaf;for (i = leaf->num_keys; i < order - 1; i++) leaf->pointers[i] = NULL;for (i = new_leaf->num_keys; i < order - 1; i++) new_leaf->pointers[i] = NULL;new_leaf->parent = leaf->parent;new_key = new_leaf->keys[0];// 父节点要插入一个记录,记录新的叶子节点return insert_into_parent(root, leaf, new_key, new_leaf);
}node *insert_into_node(node *root, node *n, int left_index, int key,node *right) {int i;for (i = n->num_keys; i > left_index; i--) {n->pointers[i + 1] = n->pointers[i];n->keys[i] = n->keys[i - 1];}n->pointers[left_index + 1] = right;n->keys[left_index] = key;n->num_keys++;return root;
}node *insert_into_node_after_splitting(node *root, node *old_node,int left_index, int key, node *right) {int i, j, split, k_prime;node *new_node, *child;int *temp_keys;node **temp_pointers;temp_pointers = malloc((order + 1) * sizeof(node *));if (temp_pointers == NULL) {perror("Temporary pointers array for splitting nodes.");exit(EXIT_FAILURE);}temp_keys = malloc(order * sizeof(int));if (temp_keys == NULL) {perror("Temporary keys array for splitting nodes.");exit(EXIT_FAILURE);}// 将指针拷贝到tmp数组for (i = 0, j = 0; i < old_node->num_keys + 1; i++, j++) {if (j == left_index + 1) j++;temp_pointers[j] = old_node->pointers[i];}// 将key拷贝到tmp数组for (i = 0, j = 0; i < old_node->num_keys; i++, j++) {if (j == left_index) j++;temp_keys[j] = old_node->keys[i];}// 将指针和key插入到tmp数组中,需要注意的是非叶子节点是order个指针,order -// 1个keytemp_pointers[left_index + 1] = right;temp_keys[left_index] = key;split = cut(order); // 按point个数来拆非叶子节点new_node = make_node();old_node->num_keys = 0;for (i = 0; i < split - 1; i++) {old_node->pointers[i] = temp_pointers[i];old_node->keys[i] = temp_keys[i];old_node->num_keys++;}old_node->pointers[i] = temp_pointers[i];k_prime = temp_keys[split - 1]; // 会移到父节点上,所以子节点本来是order个key拆两部分,拆开后就变成两个合起来只有order// - 1 个key了。for (++i, j = 0; i < order; i++, j++) {new_node->pointers[j] = temp_pointers[i];new_node->keys[j] = temp_keys[i];new_node->num_keys++;}new_node->pointers[j] = temp_pointers[i];free(temp_pointers);free(temp_keys);new_node->parent = old_node->parent;for (i = 0; i <= new_node->num_keys; i++) {child = new_node->pointers[i];child->parent = new_node;}// 将中间的key插入到父节点中,然后父节点也添加指针指向新的右节点return insert_into_parent(root, old_node, k_prime, new_node);
}node *insert_into_parent(node *root, node *left, int key, node *right) {int left_index;node *parent;parent = left->parent;if (parent == NULL) // 根节点需要调高return insert_into_new_root(left, key, right);// 找到父节点中,当前叶子节点所在的索引位置left_index = get_left_index(parent, left);if (parent->num_keys <order - 1) // 如果父节点未满,就将新叶子节点right加入父节点中return insert_into_node(root, parent, left_index, key, right);// 父节点已经满了,需要拆分return insert_into_node_after_splitting(root, parent, left_index, key, right);
}node *insert_into_new_root(node *left, int key, node *right) {node *root = make_node();root->keys[0] = key;root->pointers[0] = left;root->pointers[1] = right;root->num_keys++;root->parent = NULL;left->parent = root;right->parent = root;return root;
}node *start_new_tree(int key, record *pointer) {node *root = make_leaf();root->keys[0] = key;root->pointers[0] = pointer;root->pointers[order - 1] = NULL;root->parent = NULL;root->num_keys++;return root;
}node *insert(node *root, int key, int value) {record *record_pointer = NULL;node *leaf = NULL;// 先找到叶子节点record_pointer = find(root, key, false, NULL);if (record_pointer != NULL) { // 如果找到了,就更新valuerecord_pointer->value = value;return root;}// 新建一条记录record_pointer = make_record(value);if (root == NULL) // 如果是第一个记录,就创建树,root为叶子节点return start_new_tree(key, record_pointer);// 找到应该插入的叶子节点leaf = find_leaf(root, key, false);if (leaf->num_keys < order - 1) {// 如果叶子节点未满,就插入叶子节点中leaf = insert_into_leaf(leaf, key, record_pointer);return root;}// 叶子节点满了,此时要进行叶子节点拆分return insert_into_leaf_after_splitting(root, leaf, key, record_pointer);
}int get_neighbor_index(node *n) {int i;for (i = 0; i <= n->parent->num_keys; i++)if (n->parent->pointers[i] == n) return i - 1;printf("Search for nonexistent pointer to node in parent.\n");printf("Node: %#lx\n", (unsigned long)n);exit(EXIT_FAILURE);
}node *remove_entry_from_node(node *n, int key, node *pointer) {int i, num_pointers;i = 0;while (n->keys[i] != key) i++;for (++i; i < n->num_keys; i++) n->keys[i - 1] = n->keys[i];num_pointers = n->is_leaf ? n->num_keys : n->num_keys + 1;i = 0;while (n->pointers[i] != pointer) i++;for (++i; i < num_pointers; i++) n->pointers[i - 1] = n->pointers[i];n->num_keys--;if (n->is_leaf)for (i = n->num_keys; i < order - 1; i++) n->pointers[i] = NULL;elsefor (i = n->num_keys + 1; i < order; i++) n->pointers[i] = NULL;return n;
}node *adjust_root(node *root) {node *new_root;if (root->num_keys > 0) return root;// root高度下降,根往下移,删除只是删除叶子节点,为啥会动root?// 应该不会到这个分支if (!root->is_leaf) {new_root = root->pointers[0];new_root->parent = NULL;}// 最后一个元素,直接清空树根elsenew_root = NULL;free(root->keys);free(root->pointers);free(root);return new_root;
}node *coalesce_nodes(node *root, node *n, node *neighbor, int neighbor_index,int k_prime) {int i, j, neighbor_insertion_index, n_end;node *tmp;if (neighbor_index ==-1) { // 如果是和右兄弟节点合并,先交换下顺序,保证neighbor指向左边节点,而n指向右边节点tmp = n;n = neighbor;neighbor = tmp;}neighbor_insertion_index = neighbor->num_keys;if (!n->is_leaf) { // 非叶子节点neighbor->keys[neighbor_insertion_index] =k_prime; // 左节点先把父节点的key存下来neighbor->num_keys++;n_end = n->num_keys;for (i = neighbor_insertion_index + 1, j = 0; j < n_end;i++, j++) { // 左节点把右节点的key,pointer都拷贝过来neighbor->keys[i] = n->keys[j];neighbor->pointers[i] = n->pointers[j];neighbor->num_keys++;n->num_keys--;}neighbor->pointers[i] = n->pointers[j];for (i = 0; i < neighbor->num_keys + 1;i++) { // 右节点的子节点的父指针都指向左节点tmp = (node *)neighbor->pointers[i];tmp->parent = neighbor;}}else { // 叶子节点for (i = neighbor_insertion_index, j = 0; j < n->num_keys;i++, j++) { // 拷贝右节点的key和指针即可neighbor->keys[i] = n->keys[j];neighbor->pointers[i] = n->pointers[j];neighbor->num_keys++;}neighbor->pointers[order - 1] =n->pointers[order - 1]; // 左节点的最末尾指针指向下一个节点}// 删除父节点对应的key,因为这key下放到下一层节点,或者删除了root = delete_entry(root, n->parent, k_prime, n);free(n->keys);free(n->pointers);free(n);return root;
}node *redistribute_nodes(node *root, node *n, node *neighbor,int neighbor_index, int k_prime_index, int k_prime) {int i;node *tmp;if (neighbor_index != -1) { // 通常从左节点借if (!n->is_leaf) // 非叶子节点,最右指针往右挪一下n->pointers[n->num_keys + 1] = n->pointers[n->num_keys];for (i = n->num_keys; i > 0; i--) { // 先把key和point往右挪一位,给要借的的key腾出空间n->keys[i] = n->keys[i - 1];n->pointers[i] = n->pointers[i - 1];}if (!n->is_leaf) { // 非叶子节点,把左兄弟节点最末尾的指针拷贝过来n->pointers[0] = neighbor->pointers[neighbor->num_keys];tmp = (node *)n->pointers[0];tmp->parent = n;neighbor->pointers[neighbor->num_keys] = NULL;n->keys[0] = k_prime; // 左兄弟节点最大值移到本节点最左侧n->parent->keys[k_prime_index] =neighbor->keys[neighbor->num_keys -1]; // 父节点之前存放左兄弟节点的最大值,改成次大值} else { // 叶子节点,只用调整key和父节点的key就行n->pointers[0] = neighbor->pointers[neighbor->num_keys - 1];neighbor->pointers[neighbor->num_keys - 1] = NULL;n->keys[0] = neighbor->keys[neighbor->num_keys - 1];n->parent->keys[k_prime_index] = n->keys[0];}}else { // 右节点作为兄弟节点来借数据,一般是当前节点是最左端的那个节点才会这样if (n->is_leaf) { // 叶子节点,从右兄弟节点挪过来一个key就行n->keys[n->num_keys] = neighbor->keys[0];n->pointers[n->num_keys] = neighbor->pointers[0];n->parent->keys[k_prime_index] =neighbor->keys[1]; // 父节点原来存放右兄弟节点的第一个key,现在改成第二个key} else { // 非叶子节点n->keys[n->num_keys] = k_prime; // 父节点的第一个key给本节点n->pointers[n->num_keys + 1] = neighbor->pointers[0];tmp = (node *)n->pointers[n->num_keys + 1];tmp->parent = n;n->parent->keys[k_prime_index] =neighbor->keys[0]; // 父节点的第一个key改为右兄弟节点的第一个key}for (i = 0; i < neighbor->num_keys - 1;i++) { // 调整右兄弟节点的key和pointer,都左移一位neighbor->keys[i] = neighbor->keys[i + 1];neighbor->pointers[i] = neighbor->pointers[i + 1];}if (!n->is_leaf) // 如果是非叶子节点,还需要再挪一下右兄弟节点的最右边的指针neighbor->pointers[i] = neighbor->pointers[i + 1];}n->num_keys++;neighbor->num_keys--;return root;
}node *delete_entry(node *root, node *n, int key, void *pointer) {int min_keys;node *neighbor;int neighbor_index;int k_prime_index, k_prime;int capacity;// 先从叶子节点删除本keyn = remove_entry_from_node(n, key, pointer);if (n == root) return adjust_root(root);min_keys = n->is_leaf ? cut(order - 1) : cut(order) - 1;// 叶子节点最小的key格式为order - 1/2, 非叶子节点是order/2 - 1if (n->num_keys >= min_keys) // 如果节点够一半,删除结束return root;// 否则找左兄弟节点,只会是共一个父节点的左兄弟节点neighbor_index = get_neighbor_index(n);k_prime_index = neighbor_index == -1 ? 0 : neighbor_index;k_prime = n->parent->keys[k_prime_index];// 左兄弟节点,或者右兄弟节点neighbor = neighbor_index == -1 ? n->parent->pointers[1]: n->parent->pointers[neighbor_index];capacity = n->is_leaf ? order : order - 1;if (neighbor->num_keys + n->num_keys <capacity) // 如果两个节点的总key个数都不够order,那就合并return coalesce_nodes(root, n, neighbor, neighbor_index, k_prime);else // 如果够order,那就够两个节点分,重新均分下两个接的keyreturn redistribute_nodes(root, n, neighbor, neighbor_index, k_prime_index,k_prime);
}node *delete_op(node *root, int key) {node *key_leaf = NULL;record *key_record = NULL;// 先找叶子节点的记录key_record = find(root, key, false, &key_leaf);if (key_record != NULL && key_leaf != NULL) {// 找到了,开始删除root = delete_entry(root, key_leaf, key, key_record);free(key_record);}// 没找到,就直接结束return root;
}void destroy_tree_nodes(node *root) {int i;if (root->is_leaf)for (i = 0; i < root->num_keys; i++) free(root->pointers[i]);elsefor (i = 0; i < root->num_keys + 1; i++)destroy_tree_nodes(root->pointers[i]);free(root->pointers);free(root->keys);free(root);
}node *destroy_tree(node *root) {destroy_tree_nodes(root);return NULL;
}int main() {node *root;char instruction;root = NULL;root = insert(root, 5, 33);print_tree(root);root = insert(root, 15, 21);print_tree(root);root = insert(root, 25, 31);print_tree(root);root = insert(root, 35, 41);print_tree(root);root = insert(root, 45, 10);print_tree(root);printf("before delete\n");root = delete_op(root, 5);print_tree(root);
}读
比较简单,就是自上而下的查找树,可以做的一个优化,就是节点内的元素是顺序的,可以用二分进行优化下。
写
- 自上而下找到叶子节点
- 如果叶子节点还有空间,即元素个数小于MaxSize,就插入,直接返回成功
- 如果叶子节点满了,此时需要将节点拆分成两个节点,新节点是右兄弟节点,然后再将新的节点的最小key值插入到父节点里
- 需要注意的是,这里拆分时,需要申请一个临时的数组(可容纳MaxSize+1个元素),然后将当前所有元素拷贝出去,进行正常插入后,最后切分
- 我在这踩过坑,直接复用了当前节点的array_,当MaxSize设置为最大值256时,出现数组越界问题。其实报错不是越界,而是修改数据时,发现有别的数组的数据被改乱了。原因就是我在拆分时,越界访问了不属于本节点的page。
- 然后递归处理一直到根节点
删除
比较复杂。可以参考链接3的说明和实现,主要是两类操作:合并和重新分布。
- 自上而下找到叶子节点
- 如果叶子节点还有很多元素,即元素个数大于MinSize,就删除,直接返回成功
- 如果叶子节点小于等于MinSize,此时需要看看该节点兄弟给不给力了
- 如果比较给力,有很多元素,即兄弟节点元素个数 + 本节点元素个数 > MaxSize()
- 重新分布,从兄弟节点挪一个元素过来就行,因为删除只会删一个,因此本节点最少有MinSize -1个元素,只用挪一个就够活
- 如果不给力,即兄弟节点元素个数 + 本节点元素个数 < MaxSize()
- 合并,删除右边节点,即如果本节点在最左边,那就删除右兄弟节点,其他情况,就是删除本节点, 然后更新父节点的指针,并且需要递归往上
- 还需要删除父节点中本节点或者兄弟节点的指针,并递归处理父节点
- 如果父节点是根节点,并且只剩一个指针了,那需要删掉父节点,将父节点指针指向的节点设置为根节点
- 如果比较给力,有很多元素,即兄弟节点元素个数 + 本节点元素个数 > MaxSize()
checkpoint 2
迭代器
比较简单,找到最左侧节点,然后顺着指针往后遍历即可
并发
- 自上而下的获取锁,当本节点是安全的时候,就可以释放上一层的锁,参考下面链接2的介绍
- 安全的判断
- 对于写入,就是再写一个,也不会分裂
- 对于删除,就是删一个,也不会小于MinSize
- 安全的判断
其他的注意事项:
- MaxSize是指定的
- MinSize需要计算
- (对应的MaxSize + 1) / 2
- root节点的minSize恒为2
最后,重点参考下面链接2,来实现代码
参考:
- https://dreampuf.github.io/GraphvizOnline/# 可视化graphviz的网址
- https://www.cnblogs.com/JayL-zxl/p/14324297.html
- https://oi-wiki.org/ds/bplus-tree/#%E6%9F%A5%E6%89%BE
相关文章:

cmu 445 poject 2笔记
2022年的任务 https://15445.courses.cs.cmu.edu/fall2022/project2/ checkpoint 1,实现b树,读,写,删 checkpoint 2, 实现b树,迭代器,并发读写删 本文不写代码,只记录遇到的一些思维盲点 checkp…...

梅开二度的 axios 源码阅读,三千字详细分享功能函数,帮助扩展开发思维
前言 第一遍看 axios 源码,更多的是带着日常开发的习惯,时不时产生出点联想。 第二遍再看 axios 源码,目标明确,就是奔着函数来的。 当有了明确清晰的目标,阅读速度上来了,思绪也转的飞快。 按图索骥&a…...

vcs仿真教程
VCS是在linux下面用来进行仿真看波形的工具,类似于windows下面的modelsim以及questasim等工具,以及quartus、vivado仿真的操作。 1.vcs的基本指令 vcs的常见指令后缀 sim常见指令 2.使用vcs的实例 采用的是全加器的官方教程,首先介绍不使用…...

java 自定义json解析注解 复杂json解析 工具类
java 自定义json解析注解 复杂json解析 工具类 目录java 自定义json解析注解 复杂json解析 工具类1.背景2、需求-各式各样的json一、一星难度json【json对象中不分层】二、二星难度json【json对象中出现层级】三、三星难度json【json对象中存在数组】四、四星难度json【json对象…...

类的 6 个默认成员函数
文章目录一、构造函数1. 构造函数的定义2. 编译器生成的构造函数3. 默认构造函数4. 初始化列表5. 内置成员变量指定缺省值(C11)二、析构函数1. 析构函数的定义2. 编译器生成的析构函数3. 自己写的析构函数的执行方式三、拷贝构造函数1. C语言值传递和返回值时存在 bug2. 拷贝构…...
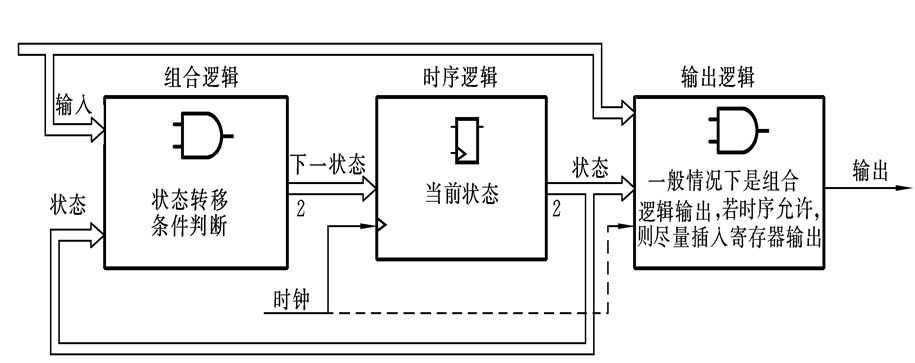
基于Verilog HDL的状态机描述方法
⭐本专栏针对FPGA进行入门学习,从数电中常见的逻辑代数讲起,结合Verilog HDL语言学习与仿真,主要对组合逻辑电路与时序逻辑电路进行分析与设计,对状态机FSM进行剖析与建模。 🔥文章和代码已归档至【Github仓库…...
6年软件测试经历:成长、迷茫、奋斗
前言 测试工作6年,经历过不同产品、共事过不同专业背景、能力的同事,踩过测试各种坑、遇到过各种bug。测试职场生涯积极努力上进业务和技术能力快速进步过、也有努力付出却一无所得过、有对测试生涯前景充满希望认为一片朝气蓬勃过、也有对中年危机思考不…...

OpenMMLab AI实战营第五次课程
语义分割与MMSegmentation 什么是语义分割 任务: 将图像按照物体的类别分割成不同的区域 等价于: 对每个像素进行分类 应用:无人驾驶汽车 自动驾驶车辆,会将行人,其他车辆,行车道,人行道、交…...

【软考】系统集成项目管理工程师(二十)项目风险管理
一、项目风险管理概述1. 风险概念2. 风险分类3. 风险成本二、项目风险管理子过程1. 规划风险管理2. 识别风险3. 实施定性风险分析4. 实施定量风险分析5. 规划风险应对6. 控制风险三、项目风险管理流程梳理一、项目风险管理概述 1. 风险概念 风险是一种不确定事件或条件,一旦…...
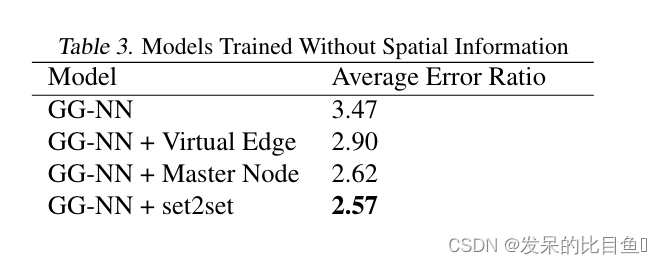
2017-PMLR-Neural Message Passing for Quantum Chemistry
2017-PMLR-Neural Message Passing for Quantum Chemistry Paper: https://arxiv.org/pdf/1704.01212.pdf Code: https://github.com/brain-research/mpnn 量子化学的神经信息传递 这篇文献作者主要是总结了先前神经网络模型的共性,提出了一种消息传递神经网络&am…...
)
Python:每日一题之全球变暖(DFS连通性判断)
题目描述 你有一张某海域 NxN 像素的照片,"."表示海洋、"#"表示陆地,如下所示: ....... .##.... .##.... ....##. ..####. ...###. ....... 其中"上下左右"四个方向上连在一起的一片陆地组成一座岛屿…...
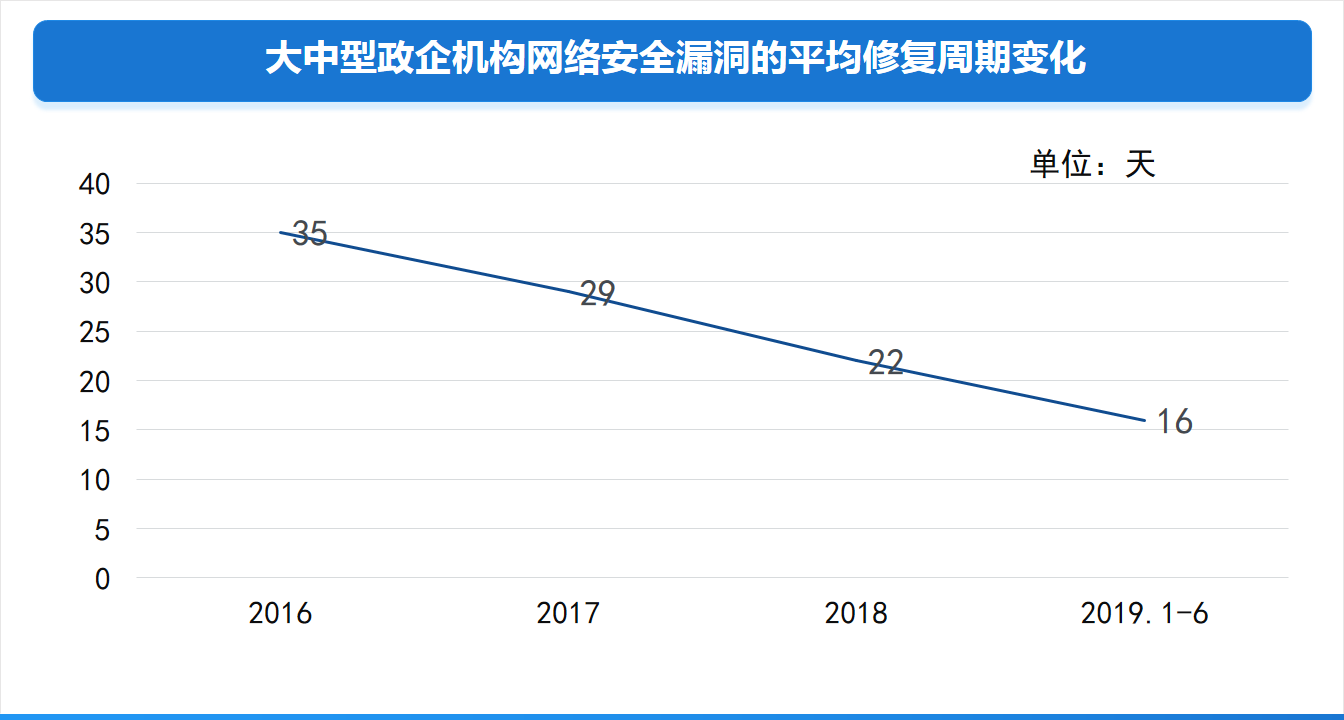
企业级安全软件装机量可能大增
声明 本文是学习大中型政企机构网络安全建设发展趋势研究报告. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 研究背景 大中型政企机构是网络安全保护的重中之重,也是国内网络安全建设投入最大,应用新技术、新产品最多的机构…...

为什么要用频谱分析仪测量频谱?
频谱分析仪是研究电信号频谱结构的仪器,用于信号失真度、调制度、谱纯度、频率稳定度和交调失真等信号参数的测量,可用以测量放大器和滤波器等电路系统的某些参数,是一种多用途的电子测量仪器。从事通信工程的技术人员,在很多时候…...
Python环境搭建、Idea整合
1、学python先要下载什么? 2、python官网 3、idea配置Python 4、idea新建python 学python先要下载什么? python是一种语言,首先你需要下载python,有了python环境,你才可以在你的电脑上使用python。现在大多使用的是pyt…...

HTTP请求返回304状态码以及研究nginx中的304
文章目录1. 引出问题2. 分析问题3. 解决问题4. 研究nginx中的3044.1 启动服务4.2 ETag说明4.3 响应头Cache-Control1. 引出问题 之前在调试接口时,代码总出现304问题,如下所示: 2. 分析问题 HTTP 304: Not Modified是什么意思? …...

【GD32F427开发板试用】使用Arm-2D显示电池电量
本篇文章来自极术社区与兆易创新组织的GD32F427开发板评测活动,更多开发板试用活动请关注极术社区网站。作者:boc 【虽迟但到】 由于快递的原因,11月份申请的,12月1日才收到GD32F427开发板。虽然姗姗来迟,但也没有减少…...

TS第二天 Typesrcipt编译
文章目录自动编译tsconfig.json配置选项include 比较重要excludeextendsfilescompilerOptions 比较重要自动编译 手动模式:每次ts文件修改完,手动编译一次 tsc 01.ts监视模式:ts文件修改完,自动监视编译 tsc 01.ts -w编译所有文…...
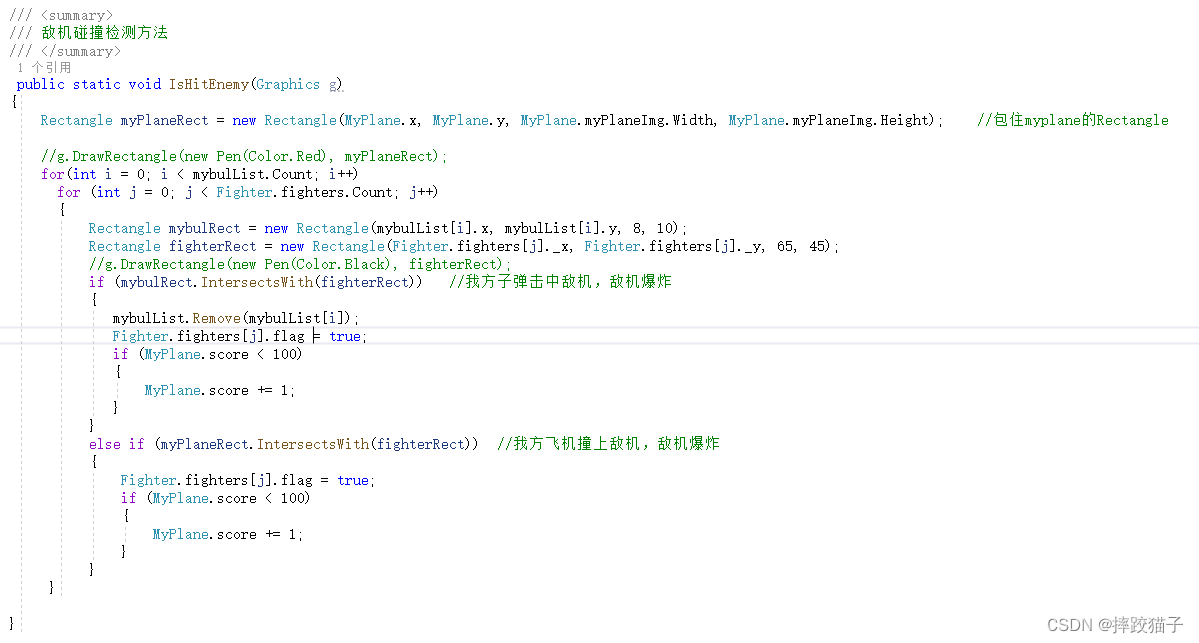
基于C#制作一个飞机大战小游戏
此文主要基于C#制作一个飞机大战游戏,重温经典的同时亦可学习。 实现流程1、创建项目2、界面绘制3、我方飞机4、敌方飞机5、子弹及碰撞检测实现流程 1、创建项目 打开Visual Studio,右侧选择创建新项目。 搜索框输入winform,选择windows窗体…...
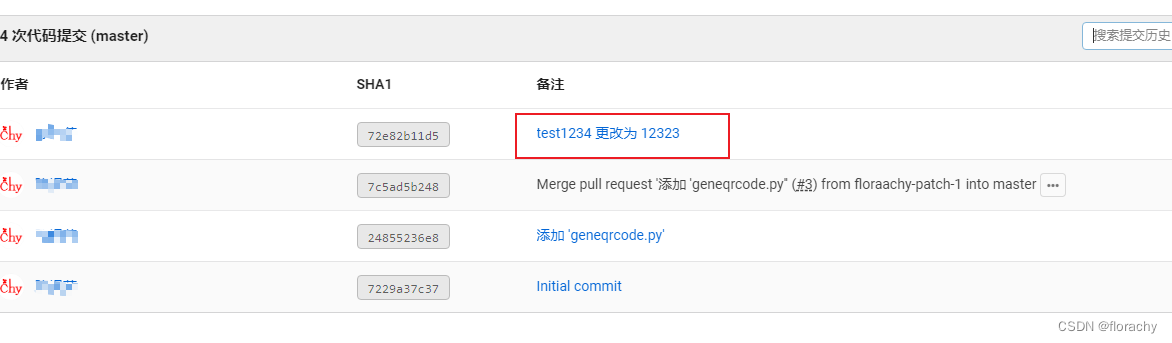
git修改历史提交(commit)信息
我们在开发中使用git经常会遇到想要修改之前commit的提交信息,这里记录下怎么使用git修改之前已经提交的信息。一、修改最近一次commit的信息 首先通过git log查看commit信息。 我这里一共有6次commit记录。 最新的commit信息为“Merge branch ‘master’ of https:…...
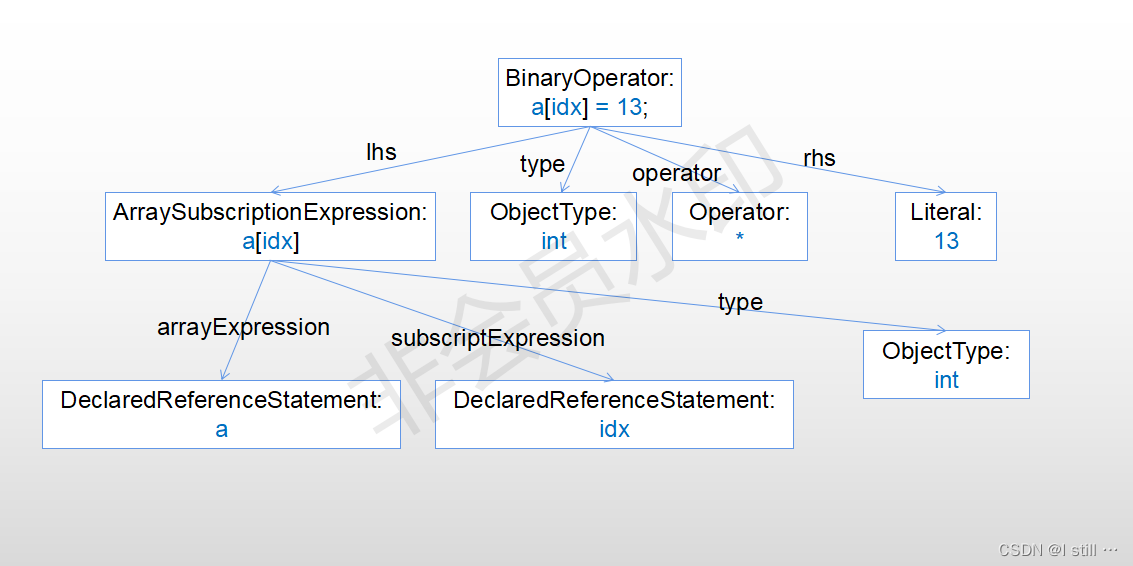
代码解析工具cpg
cpg 是一个跨语言代码属性图解析工具,它目前支持C/C (C17), Java (Java 13)并且对Go, LLVM, python, TypeScript也有支持,在这个项目的根目录下: cpg-core为cpg解析模块的核心功能,主要包括将代码解析为图,core模块只包括对C/C/Ja…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

【7色560页】职场可视化逻辑图高级数据分析PPT模版
7种色调职场工作汇报PPT,橙蓝、黑红、红蓝、蓝橙灰、浅蓝、浅绿、深蓝七种色调模版 【7色560页】职场可视化逻辑图高级数据分析PPT模版:职场可视化逻辑图分析PPT模版https://pan.quark.cn/s/78aeabbd92d1...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...