Python基础-数据类型之列表
一、列表的定义
name = ["小明", "小红", "笑笑"]
二、列表的使用
除了序列中的操作,列表还有一些其他的操作。
(1)不使用列表方法对列表进行修改
1:通过索引修改列表中的值
name = ["Kitty", "Julie", "Ross"]
name[1] = "egon"
print(name) # ["Kitty", "egon", "Ross"]2:通过切片修改一定范围的值(切片赋值),替换的长度等于被替换的长度
list_str = ["k","i","t","t","y"]
list_str[1:3] = "ab"
print(list_str) # ["k","a","b","t","y"]3:切片赋值替换原列表中长度不同的值(替换的长度大于/小于被替换的长度)
list_str = ["k","i","t","t","y"]
print(list_str[1:3]) # ['i', 't']
# 替换的长度大于被替换的长度
list_str[1:3] = "python"
print(list_str) # ['k', 'p', 'y', 't', 'h', 'o', 'n', 't', 'y']
# 替换的长度小于被替换的长度
list_str[1:3] = "p"
print(list_str) # ['k', 'p', 't', 'y']4:在列表中插入值
4.1:在某个具体的索引位置进行插入
例:已知list_str = ["k","y"],得到list_str = ["k","i","t","t","y"]
list_str = ["k","y"]
print(list_str[1:1]) # []
list_str[1:1] = ["i","t","t"]
print(list_str) # ['k', 'i', 't', 't', 'y']注释:list_str[1:1]表示在列表list_str中索引为1的位置占了一个位置,然后将["i","t","t"]进行解包,将每个元素从索引1开始,依次进行插入
4.2:在某个具体的位置,将值替换掉
例:已知nums = [2,3,4],想要得到nums=[2,5,6,7,4]
nums = [2,3,4]
print(nums[1:2]) # [3]
nums[1:2] = [5,6,7]
print(nums) # [2, 5, 6, 7, 4]在这里,我犯了一个错误,认为nums[1]和nums[1:2]得到的结果是一样的,于是我就直接把nums[1]=[5,6,7],最后得到的结果是[2,[5,6,7],4],才发现nums[1]和nums[1:2]得到的结果是不一样的,只是它两的值是一样的都是3,nums[1]得到的是一个具体的值3,nums[1:2]得到的结果是一个列表[3],而nums[1]=[5,6,7]就是将索引1的值替换成了一个列表。
5:删除列表中的元素
5.1:切片删
例:已知list_str = ["k","i","t","t","y"],得到list_str = ["k","i","y"]
list_str = ["k","i","t","t","y"]
list_str[2:4] = []
print(list_str) # ['k', 'i', 'y']5.2:使用del删除
list_str = ["k","i","t","t","y"]
del list_str[2:4]
print(list_str) # ['k', 'i', 'y'](2)使用列表方法进行操作列表
1:增加元素append(),在列表的末尾追加一个对象
使用方法:list.append(object)
返回值为:None,修改了原列表
nums = [1,2,3,4]
result = nums.append(5)
print(result) # None
print(nums) # [1, 2, 3, 4, 5]2:增加元素extend(),在列表的末尾一次性追加另一个序列的多个值
使用方法:list.extend(object)
返回值为:None,修改了原列表
# 追加列表
nums = [1,2,3,4]
nums1 = [5,6,7,8]
result = nums.extend(nums1)
print(result) # None
print(nums) # [1, 2, 3, 4, 5, 6, 7, 8]
print(nums1) # [5, 6, 7, 8]
# 追加元组
nums = [1,2,3,4]
nums1 = (5,6,7,8)
result = nums.extend(nums1)
print(result) # None
print(nums) # [1, 2, 3, 4, 5, 6, 7, 8]
print(nums1) # (5, 6, 7, 8)
# 追加字符串
nums = [1,2,3,4]
nums1 = "abc"
result = nums.extend(nums1)
print(result) # None
print(nums) # [1, 2, 3, 4, 'a', 'b', 'c']
print(nums1) # abc两个列表相加,也是将一个列表中的值追加到另一个列表的末尾。
与extend()方法有什么区别呢?
extend()的返回值为None,是在原列表的基础上进行追加的;
而两个列表相加,返回值为一个列表对象,会得到一个新列表,不修改原列表。
3:增加元素insert():将对象插入到列表指定的索引位置。
list.insert(index, object)
返回值为:None,修改了原列表
nums = [1,2,3,4]
# 插入列表
result = nums.insert(2, [5,6,7])
print(result) # None
print(nums) # [1, 2, [5, 6, 7], 3, 4]
# 插入一个元素,a
result = nums.insert(2, 'a') # 还可以用:nums[2:2] = 'a'
print(nums) # [1, 2, 'a', 3, 4]4:删除元素pop(),移除列表中的元素,不指定索引默认删除列表中的最后一个元素,指定索引删除对应索引的元素
list.pop(index) # index不填,默认为0
返回值为:被删除元素的值,修改了原列表
nums = [1,2,3,4]
# result = nums.pop()
# print(result) # 4
# print(nums) # [1, 2, 3]
result = nums.pop(2) # 指定删除索引为2的元素
print(result) # 3
print(nums) # [1,2,4]5:删除元素remove(),用于删除列表中的第一个匹配项,如果没有匹配到,则会报错。
list.remove(object)
返回值为:None,修改了原列表
nums = [1, 2, 3, 1, 4, 5, 1]
result = nums.remove(1) # 删除元素1
print(result) # None
print(nums) # [2, 3, 1, 4, 5, 1]
nums.remove(6) # 报错:ValueError: list.remove(x): x not in list
6:清空列表clear()
list.clear()
返回值为None,修改了原列表
nums = [1,2,3,4]
result = nums.clear()
print(result) # None
print(nums) # []7:查找/统计元素count(),统计某个元素在列表中出现的次数,如果元素不存在,返回0。可用来查找一个元素是否在列表中,返回值为0表示,这个元素不在列表中。
list.count(object)
返回值为:元素出现的次数,不改变原列表
nums = [1, 2, 3, 1, 4, 5, 1]
result = nums.count(1) # 统计元素1的出现次数
print(result) # 3
result1 = nums.count(6) # 统计元素6的出现次数
print(result1) # 08:查找元素index(),从列表中找出某个值第一个匹配的索引位置,如果匹配不到,则报错。
list.index(object, startindex, endindex) # startindex表示查询范围的起始位置,endindex表示查询范围的结束位置
返回值为:出现元素的第一个索引值,不改变原列表
nums = [2, 3, 1, 4, 1, 5, 6, 1]
result = nums.index(1) # 不指定查询范围,查询元素1出现的位置
print(result) # 2
result1 = nums.index(1, 3, 6) # 指定查询范围,查询元素1出现的位置
print(result1) # 4
result2 = nums.index(1, 5) # 指定查询范围,只指定开始位置,查询元素1出现的位置
print(result2) # 7
result3 = nums.index(7) # 报错,ValueError: 7 is not in list要判断一个元素是否在列表中,有三种方法:
第一种,使用成员运算符in(not in),存在返回True,不存在返回False
第二种,使用count()方法,存在,返回值不为0,不存在,返回值为0
第三种,使用index()方法,存在,返回元素所在的第一个索引,不存在,报错
9:翻转列表reverse(),将列表中的元素反向存放
list.reverse(object)
返回值为:None,修改了原列表
nums = [1,2,3,4,5]
result = nums.reverse()
print(result) # None
print(nums) # [5, 4, 3, 2, 1]还可以使用[::-1]进行翻转列表,返回值是一个新列表,不修改原列表
nums = [1,2,3,4,5]
result = nums[::-1]
print(result) # [5, 4, 3, 2, 1]
print(nums) # [1, 2, 3, 4, 5]10:排序sort(),对原列表进行排序,排序时列表中的元素之间必须是相同的数据类型,不可混搭,否则报错。
list.sort(key, reverse) # 不填写参数,默认从小到大进行排序;如果指定参数,则使用比较函数指定的比较函数
key:用于指定一个函数,即key=函数,即为排序提供一种方法,函数需要有返回值。
reverse:排序规则,按照升序/降序进行排序,默认值为reverse = False(升序),reverse = True(降序)
返回值为:None,修改了原列表
nums = [3, 5, 2, 7, 1]
result = nums.sort()
print(result) # None
print(nums) # [1, 2, 3, 5, 7]
result1 = nums.sort(reverse=True)
print(nums) # [7, 5, 3, 2, 1]参数key的使用:
a = ['p', 'pyt', 'py', 'pytho', 'pyth', 'python']
a.sort(key=len) # key=len,len指的是len()这个方法,表示按照列表中的元素长度进行排序,默认升序
print(a) # ['p', 'py', 'pyt', 'pyth', 'pytho', 'python']将key与lambda匿名函数结合
a = [('AZ','abc',154),('BZ','aac',144),('AB','abd',253)]
# 按照第二个元素进行升序排序
a.sort(key=lambda i:i[1])
print(a) # [('BZ', 'aac', 144), ('AZ', 'abc', 154), ('AB', 'abd', 253)]11:复制copy(),对列表进行复制
nums = [1, 2, 3, 4]
nums_copy = nums.copy()
print(nums_copy) # [1, 2, 3, 4]
print(id(nums_copy), id(nums)) # 2702229178248 2702229178696对单层列表进行复制,是完全复制的,得到的是一个完全新的列表,对应的是两个不同的内存地址
注意:对一个复杂对象的子对象(序列里面嵌套序列,字典里面嵌套序列)并不会完全复制。
nums = [1, 2, 3, ['a', 'b']]
nums_copy = nums.copy()
print(nums_copy) # [1, 2, 3, ['a', 'b']]
print(id(nums_copy), id(nums)) # 1883311377224 1883311376264
print(id(nums[3]), id(nums_copy[3])) # 1883311376712 1883311376712第一层列表对应的内存地址是不同,而第二层列表对应的地址是相同的,所以修改nums第二层列表中的值,nums_copy第二层的值会一起被修改
nums = [1, 2, 3, ['a', 'b']]
nums_copy = nums.copy()
print(nums_copy) # [1, 2, 3, ['a', 'b']]
print(id(nums_copy), id(nums)) # 1883311377224 1883311376264
print(id(nums[3]), id(nums_copy[3])) # 1883311376712 1883311376712
nums[3][1] = 'abcd'
print(nums, nums_copy) # [1, 2, 3, ['a', 'abcd']] [1, 2, 3, ['a', 'abcd']]要进行完全复制,需要导入copy库的deepcopy,deepcopy()可以对一个复杂对象进行完全复制
nums = [1, 2, 3, ['a', 'b']]
from copy import deepcopy
nums_deepcopy = deepcopy(nums)
print(nums_deepcopy) # [1, 2, 3, ['a', 'b']]
print(id(nums), id(nums_deepcopy)) # 1759708448648 1759708449672
print(id(nums[3]), id(nums_deepcopy[3])) # 1759708449096 1759708465288
nums[3][1] = 'abcd'
print(nums, nums_deepcopy) # [1, 2, 3, ['a', 'abcd']] [1, 2, 3, ['a', 'b']]相关文章:

Python基础-数据类型之列表
一、列表的定义 name ["小明", "小红", "笑笑"] 二、列表的使用 除了序列中的操作,列表还有一些其他的操作。 (1)不使用列表方法对列表进行修改 1:通过索引修改列表中的值 name ["Kit…...
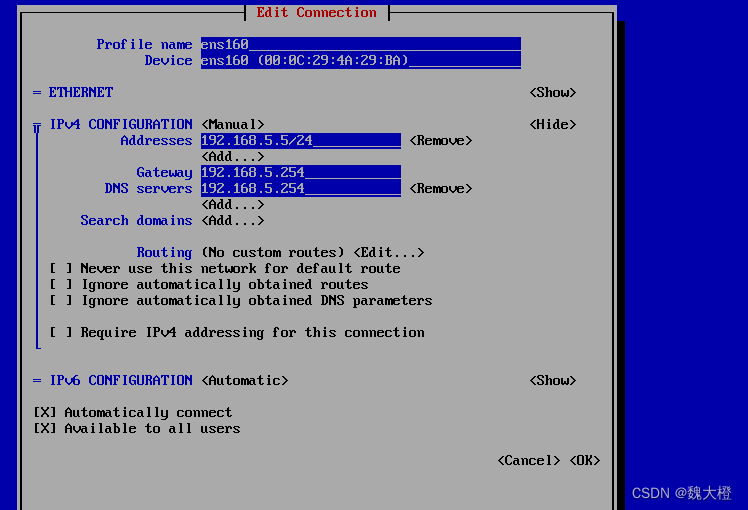
Linux系统基本设置:网络设置(三种界面网络地址配置)
网络地址配置:图形界面配置、命令行界面配置、文本图形界面配置 命令行界面配置 查看网络命令: 想要知道你有多少网卡,都可以通过这两个命令来查看 手动设置网络参数,我们可以使用nmcli这个命令来设置,我们需要知道…...
:查询性能分析)
MySQL(二):查询性能分析
文章目录一、使用explain进行分析二、如何优化数据的访问三、如何重构大查询一、使用explain进行分析 Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。 比较重要的字段有: select_type : 查询类型,有…...
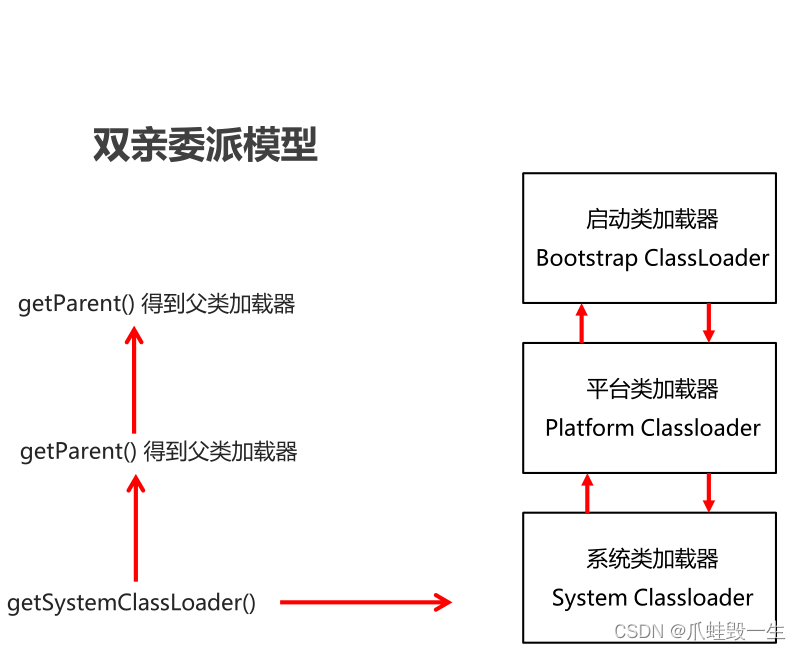
Java基础-类加载器
写在前面的话: 基础加强包含了: 反射,动态代理,类加载器,xml,注解,日志,单元测试等知识点 其中最难的是反射和动态代理,其他知识点都非常简单 由于B站P数限制,…...
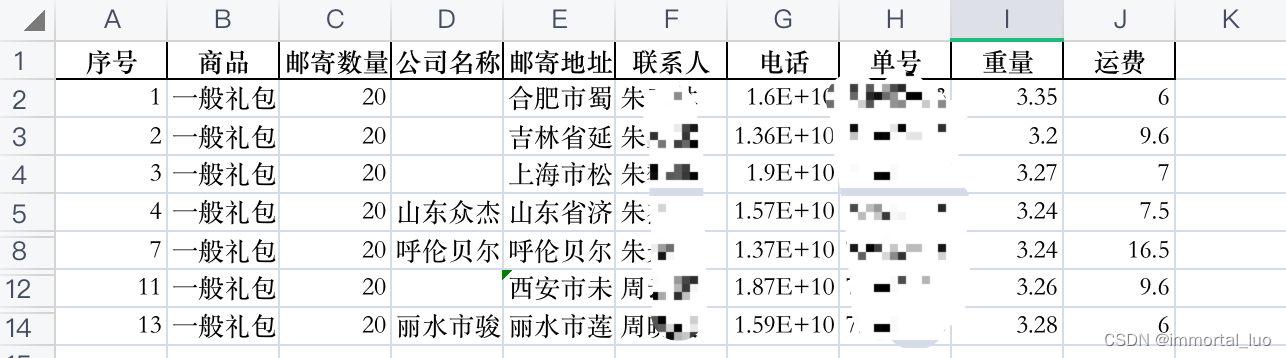
Python 使用pandas处理Excel —— 快递订单处理 数据匹配 邮费计算
问题背景 有表A,其数据如下 关键信息是邮寄地址和单号。 表B: 关键信息是运单号和重量 我们需要做的是,对于表A中的每一条数据,根据其单号,在表B中查找到对应的重量。 在表A中新增一列重量,将刚才查到的…...
【黑马SpringCloud(7)】分布式事务
分布式事务事务的ACID原则分布式事务理论基础CAP定理BASE理论Seataseata的部署seata的集成事务模式XA模式Seata的XA模型优缺点实现XA模式AT模式案例:AT模式更新数据脏写问题优缺点实现AT模式TCC模式流程分析Seata的TCC模型事务悬挂和空回滚实现TCC模式优缺点SAGA模式…...
百度地图API添加自定义标记解决单html文件跨域
百度地图API添加自定义标记解决单html文件跨域 因为要往百度地图上添加一些标注点,而且这些标注点要用自定义的图片,而且只能使用单html文件,不能使用服务器(也别问为什么,就是这么个需求),做起…...

如何停止/重启/启动Redis服务
一、命令行直接启动/停止/重启redis 可以直接通过下面的命令启动/停止/重启redis /etc/init.d/redis-server start 启动redis服务 /etc/init.d/redis-server stop 停止redis服务 /etc/init.d/redis-server restart 重启redis服务1、启动redis服务…...
python 的selenium自动操控浏览器教程(2)
人生苦短,我用py 文章目录人生苦短,我用py关于部分网页无法找到元素的问题1方案1方案2关于部分网页无法找到元素的问题2解决方案被网站检查出来我们使用了selenium了怎么办?如何实现前进后退当使用py删除文件时报禁止访问怎么办怎么使用py实现…...

【Deformable Convolution】可变形卷积记录
every blog every motto: You can do more than you think. https://blog.csdn.net/weixin_39190382?typeblog 0. 前言 可变形卷积记录 1. 正文 预印版: Deformable Convolutional Networks v1 Deformable ConvNets v2: More Deformable, Better Results 发表版…...

Oracle-Mysql 函数转换
Oracle-Mysql 函数转换limit <> ROWNUMcast <> TO_NUMBERcast as signedcast as unsignedregexp a_\\d <> REGEXP_LIKEschema() <> SELECT USER FROM DUALinformation_schema.COLUMNS表 <> ALL_TAB_COLUMNS表unix_timestampfrom_unixtime <&g…...
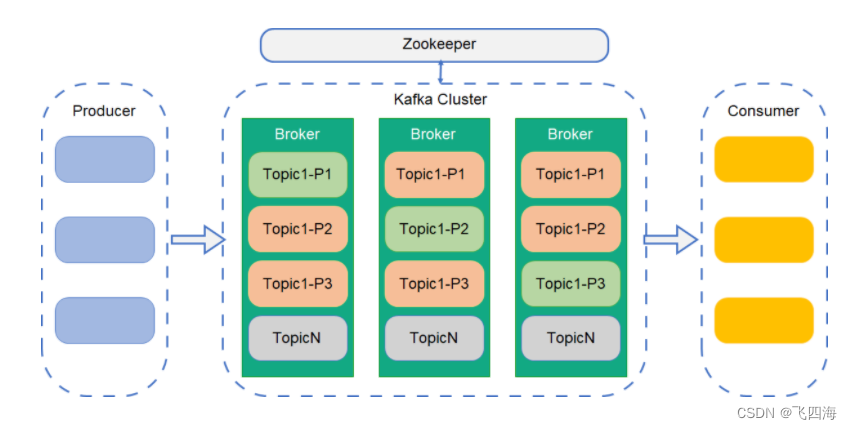
【Kafka】一.认识Kafka
kafka是一个分布式消息队列。由 Scala 开发的高性能跨语言分布式消息队列,单机吞吐量可以到达 10w 级,消息延迟在 ms 级。具有高性能、持久化、多副本备份、横向扩展能力。 生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。 一般在…...

Linux软件管理YUM
目录 yum配置文件 创建仓库 yum查询功能 yum安装与升级功能 yum删除功能 yum仓库产生的问题和解决之道 yum与dnf 网络源 YUM就是通过分析RPM的标头数据后,根据各软件的相关性制作出属性依赖时的解决方案,然后可以自动处理软件的依赖属性问题&…...
【自学MYSQL】MySQL Windows安装
MySQL Windows安装 MySQL Windows下载 首先,我们打开 MySQL 的官网,网址如下: https://dev.mysql.com/downloads/mysql/在官网的主页,我们首先根据我们的操作系统,选择对应的系统,这里我们选择 Windows&…...

Linux c编程之常用技巧
一、说明 在Linux C的实际编程应用中,有很多有用的实践技巧,编程中掌握这些知识,会对编程有事半功倍的效果。 二、常用技巧 2.1 if 变量条件的写法 main.c: #include <stdio.h>int main(int argc, char *argv[]) {int a =...
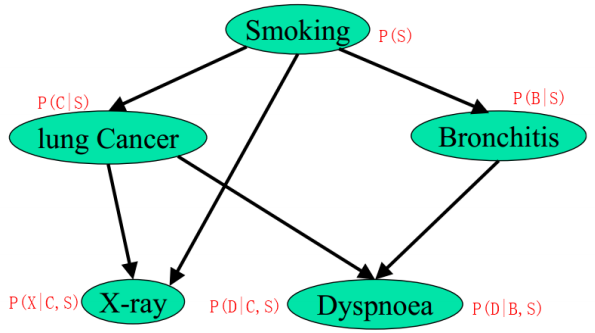
21- 朴素贝叶斯 (NLP自然语言算法) (算法)
朴素贝叶斯要点 概率图模型算法往往应用于NLP自然语言处理领域。根据文本内容判定 分类 。 概率密度公式: 高斯朴素贝叶斯算法: from sklearn.naive_bayes import GaussianNB model GaussianNB() model.fit(X_train,y_train) 伯努利分布朴素贝叶斯算法 fro…...
设计模式第七讲-外观模式、适配器模式、模板方法模式详解
一. 外观模式 1. 背景 在现实生活中,常常存在办事较复杂的例子,如办房产证或注册一家公司,有时要同多个部门联系,这时要是有一个综合部门能解决一切手续问题就好了。 软件设计也是这样,当一个系统的功能越来越强&…...
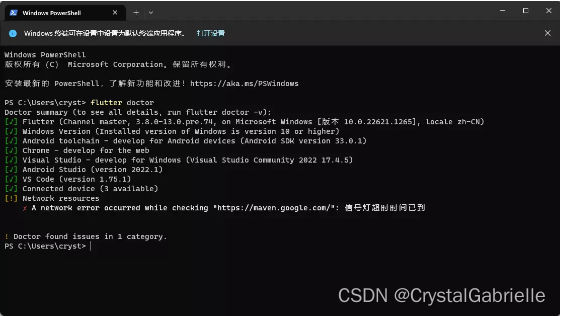
flutter-第1章-配置环境
flutter-第1章-配置环境 本文针对Windows系统。 一、安装Android Studio 从Android Studio官网下载最新版本,一直默认安装就行。 安装完成要下载SDK,可能会需要科学上网。 打开AS,随便创建一个新项目。 点击右上角的SDK Manager 找到SDK…...
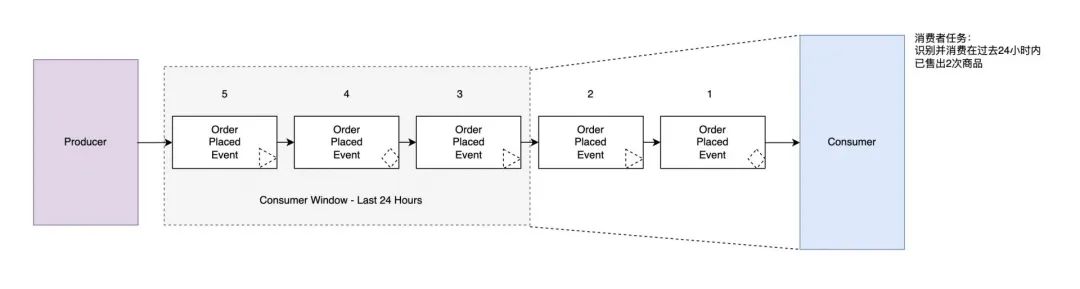
“消息驱动、事件驱动、流 ”的消息模型
文章目录背景消息驱动 Message-Driven事件驱动 Event-Driven流 Streaming事件规范标准简介: 本文旨在帮助大家对近期消息领域的高频词“消息驱动(Message-Driven),事件驱动(Event-Driven)和流(S…...

量化股票配对交易可以用Python语言实现吗?
量化股票配对交易可以用Python语言实现吗?Python 是一种流行的编程语言,可用于所有类型的领域,包括数据科学。有大量软件包可以帮助您实现目标,许多公司使用 Python 来开发与金融界相关的以数据为中心的应用程序和科学计算。 最重…...

产品经理必看:如何用IPD的Charter任务书避免研发踩坑?
产品经理实战指南:用IPD Charter任务书打造高成功率产品 在中小企业和初创公司中,产品失败最常见的原因往往不是技术实现问题,而是从一开始就选错了方向。作为产品负责人,你是否经历过这样的困境:研发团队埋头苦干大半…...
-------从概念到蓝图:开启虚实交互的实践之门)
UE数字孪生(一)-------从概念到蓝图:开启虚实交互的实践之门
1. 数字孪生:当物理世界遇见虚拟镜像 第一次听说"数字孪生"这个词时,我脑海里浮现的是科幻电影里的全息投影。直到去年参与智慧园区项目,亲眼看到运维人员通过3D模型实时监控电梯运行状态,才真正理解这项技术的魔力。简…...
)
UE4开发者必备:这些Console命令让你的渲染调试效率翻倍(附快捷键大全)
UE4渲染调试实战:Console命令与快捷键的高效组合指南 在虚幻引擎4的开发过程中,渲染调试往往是项目优化的关键环节。每当画面出现异常或性能骤降时,开发者需要快速定位问题根源。传统的手动排查方式不仅耗时费力,还容易遗漏关键细…...

Qwen-Image低显存部署全攻略:RTX3060也能流畅运行文生图
Qwen-Image低显存部署全攻略:RTX3060也能流畅运行文生图 1. 为什么选择Qwen-Image Qwen-Image作为阿里云通义千问团队推出的开源图像生成模型,在中文文本渲染方面展现出惊人的能力。与市场上其他主流模型相比,它能够准确生成包含复杂排版的…...

深度学习中的池化与下采样:原理与实践指南
1. 池化与下采样:深度学习的降维利器 第一次接触深度学习时,我被卷积神经网络(CNN)中那些神秘的操作搞得一头雾水。直到亲手实现了一个简单的图像分类器,才发现**池化(Pooling)和下采样…...

SolidWorks用户福音:Nanbeige 4.1-3B辅助三维设计文档生成
SolidWorks用户福音:Nanbeige 4.1-3B辅助三维设计文档生成 作为一名和三维设计软件打了十几年交道的工程师,我太懂那种感觉了:模型画得又快又好,但一到写文档环节,头就开始疼。零件说明、装配指南、材料清单ÿ…...
了!手把手教你启用STM32F4的硬件真随机数(附F1模拟方案对比))
别再只用软件rand()了!手把手教你启用STM32F4的硬件真随机数(附F1模拟方案对比)
嵌入式开发实战:STM32硬件真随机数生成方案深度解析 在物联网设备安全认证、动态验证码生成等场景中,高质量的随机数直接影响系统安全性。许多开发者习惯使用标准库的rand()函数,却不知STM32F4系列内置的硬件随机数发生器(RNG)能提供更优解决…...

Makefile通用模板:可执行程序、静态库与动态库构建
1. Makefile通用模板工程实践指南在嵌入式Linux开发与跨平台软件构建中,Makefile不仅是编译自动化的核心载体,更是工程化管理能力的直接体现。区别于Windows平台IDE封装的“一键编译”抽象层,Linux环境要求开发者直面编译器调用、依赖解析、链…...

ACM模板里那些“神秘”文件都是干嘛的?从acmart.cls到.bst文件深度解析
ACM模板文件全解析:从acmart.cls到.bst文件的深度指南 当你第一次打开ACM官方LaTeX模板时,可能会被一堆扩展名奇怪的文件搞得一头雾水——.cls、.bst、.bbx、.cbx、.dbx,它们看起来像是某种神秘代码。这些文件实际上控制着你论文的每一个排版…...

Qt代码的编译过程【详解】
我们来聊聊Qt代码的编译过程。这个话题有点技术性,但别担心,我会用通俗的语言一步步解释清楚。Qt是一个流行的跨平台C框架,它能让开发者轻松创建GUI应用和其他程序。但它的编译过程有点“魔法”,主要归功于一个叫moc(M…...