Python 使用pandas处理Excel —— 快递订单处理 数据匹配 邮费计算
问题背景
有表A,其数据如下
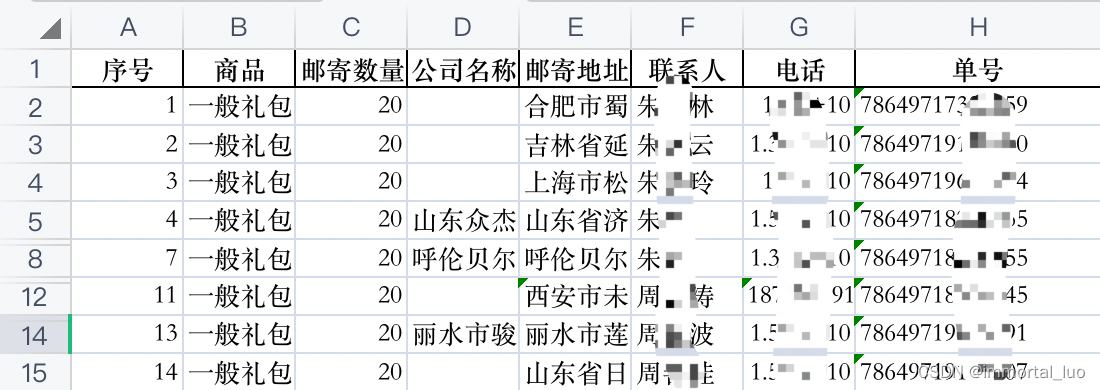
关键信息是邮寄地址和单号。
表B:
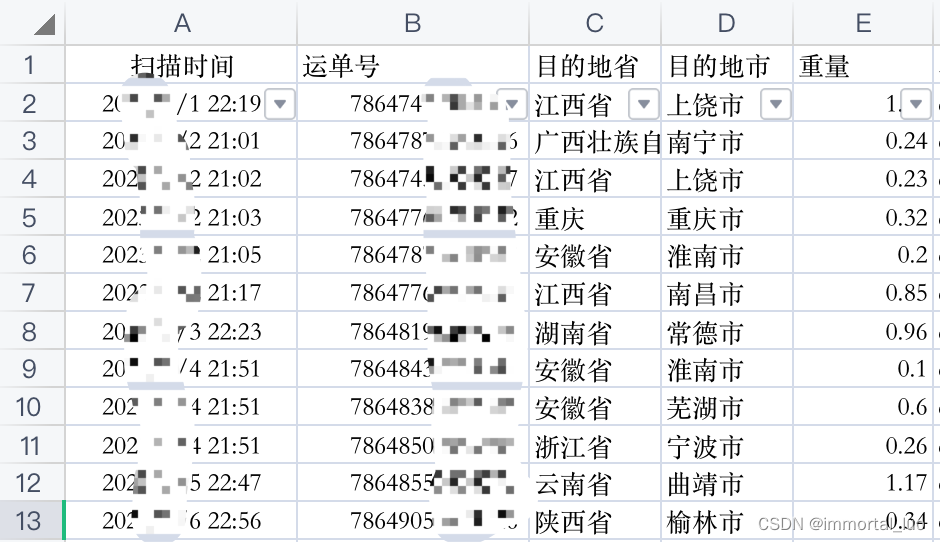
关键信息是运单号和重量
我们需要做的是,对于表A中的每一条数据,根据其单号,在表B中查找到对应的重量。
在表A中新增一列重量,将刚才查到的数据填在该列。
更近一步地,会再提供一张价格表:
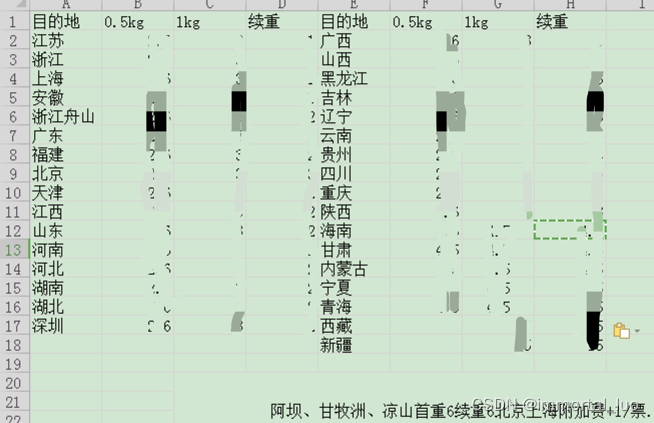
我们需要根据表A的邮寄地址和刚得到的重量计算该订单的运费。
同样在表A中新增一列运费,将计算得到的运费填写在该列。
准备工作
建立一个文件夹,在该文件夹下再建立三个文件夹,分别是origin、query和result,里面分别放表A(可以放多个表)、表B(也可以放多个表),result放的是最终的结果。
其它细节
1、可以发现有些单号为空的行被折叠了,为了保持原样,所以我们会添加一列collapse,如果订单号为空,就设置collapse为1,否则为空。之后再根据collapse这列折叠单号为空的行,后面会介绍。
2、会存在一些在表B中找不到重量信息的订单号,这些订单将被输出在命令行窗口。
3、也可以处理有多个sheet的表。
代码
import os
import re
import pandas as pd
import cpca
import math# 将所有待处理的文件都保存在这个路径下
ROOT_DIR = '/Users/XXX/Desktop/OrderProcessing/'
# 所有结果将保存在这个路径下
SAVE_DIR = '/Users/XXX/Desktop/OrderProcessing/result/'# 参照此格式,三个数字分别表示0.5kg,首重,续重。
# 注意省份名称一定要规范。不过不要求Excel表格中的邮寄地址必须要规范。
COST_TABLE_ORIGIN = {'江苏省': [1, 3, 1],'浙江省': [1, 3, 1],'上海市': [1, 3, 1],'安徽省': [1, 3, 1],'舟山市': [1, 3, 1]}def calc_cost(province, city, weight, cost_table):"""根据地区和重量计算运费:param province: 省份:param city: 城市:param weight: 重量:param cost_table: 价格表:return: 价格"""costs = Noneadditional = 0if str(province) in "北京市" or str(province) in "上海市":additional = 1for p, cost in cost_table.items():if str(city) in p:costs = costif costs is None:for p, cost in cost_table.items():if str(province) in p:costs = costif costs is None:print(" 计算费用时发生错误,可能是价格表中没有对应的地区")return Noneif weight <= 0.5:return costs[0] + additionalelif weight <= 1:return costs[1] + additionalelse:return costs[1] + math.ceil(weight - 1) * costs[2] + additionaldef query_weight_by_order(file_name, order, order_str='运单号', weight_str='重量'):"""根据订单号查询重量:param file_name: 去哪个文件里查找:param order: 订单号:param order_str: 订单的列名:param weight_str: 重量的列名:return: 该订单的重量"""df = pd.read_excel(io=file_name)num_rows = len(df.index.values)weight = Nonefor row in range(num_rows):if str(df.iloc[row][order_str]) == order:weight = df.iloc[row][weight_str]breakreturn weightdef add_weight(read_file_name, write_file_name, sheet_name=None, collapse_flag=True):"""添加重量信息:param read_file_name: 读取文件:param write_file_name: 写入文件:param sheet_name: 工作表名称:param collapse_flag: 是否隐藏指定行,比如某项值为空,则隐藏该行:return:"""if sheet_name is None:df = pd.read_excel(io=read_file_name)writer = pd.ExcelWriter(write_file_name)else:df = pd.read_excel(io=read_file_name, sheet_name=sheet_name)# 这样写好像有点笨if os.path.exists(write_file_name):writer = pd.ExcelWriter(write_file_name, mode='a')else:writer = pd.ExcelWriter(write_file_name, mode='w')num_rows = len(df.index.values)if '单号' not in df.columns.values:print(" 没有单号这一列,请确保单号那列的列名为'单号'")writer.close()returnfor row in range(num_rows):order = str(df.loc[row, '单号'])'''像order这一列,如果全是正常的单号,读进来会是浮点数,比如78649717XXX259.0如果有几行是"停发",读进来的就都是不带小数点的了,比如78XXX17332259空值就是显示nan'''if order == "nan" or order == "停发": # pd.isnull(order)if order == "nan" and collapse_flag: # 若订单号为空,则标记隐藏该行df.loc[row, 'collapse'] = 1continue# 到这里的,就是带小数点的订单号,或者正常的不带小数点的订单号if order[-2] == '.': # 去除小数点order = order[:-2]# df.loc[row, '单号'] = order# 有可能写了多个订单号,比如786497173XXX9;78649719X80XX0;786497X799ZXX4# 这种情况下,就把多个订单的重量进行累加orders = re.split(',|;|\n| |,|;', order)weight = 0for o in orders:if len(o) <= 0:continuew = None'''这里就是根据订单的不同查询不同的表比如Y开头的,查哪个表;数字开头的,查哪个表此处需要自定义'''if o[0] == 'Y':# 根据订单号查询重量w = query_weight_by_order(ROOT_DIR + "query/A.xlsx", o, order_str='运单号码', weight_str='计费重量(kg)')elif '0' <= o[0] <= '9':w = query_weight_by_order(ROOT_DIR + "query/B.xlsx", o)if w is not None and (isinstance(w, float) or isinstance(w, int)):weight += welse:print(" 没有找到该订单的重量数据:" + o)if weight > 0:df.loc[row, '重量'] = weight# 格式化地址信息address = cpca.transform([df.loc[row, '邮寄地址']])# 计算运费cost = calc_cost(address.loc[0, '省'], address.loc[0, '市'], weight, COST_TABLE_ORIGIN)if cost is None:print(" 发生错误的订单号为:", order)continueelse:df.loc[row, '运费'] = costif sheet_name is None:df.to_excel(writer, index=False)else:df.to_excel(writer, index=False, sheet_name=sheet_name)writer.close()"""
TODO:
1、修改ROOT_DIR和SAVE_DIR
2、将所有待处理的xlsx文件保存在ROOT_DIR/origin路径下,查询表保存在ROOT_DIR/query路径下
2、修改查询订单重量的代码,只需要简单地填写文件名,关键的列名等
3、修改价格表,并在调用calc_cost方法的地方指定价格表
"""
if __name__ == '__main__':if not os.path.exists(ROOT_DIR):print(ROOT_DIR + "不存在")exit()if not os.path.exists(SAVE_DIR):print("创建目录:" + SAVE_DIR)os.mkdir(SAVE_DIR)else:ans = input("是否删除%s下的所有文件?(Y/N):" % SAVE_DIR)if ans == "Y":# 删除该目录下的所有文件for filename in os.listdir(SAVE_DIR):os.remove(SAVE_DIR+filename)print("已删除SAVE_DIR下的所有文件")print("开始处理")for filename in os.listdir(ROOT_DIR+"origin/"):if filename[0] == '.' or filename[-4:] != "xlsx": # 去除隐藏文件和非xlsx文件continueprint("正在处理:" + filename)xlsx = pd.ExcelFile(ROOT_DIR + "origin/" + filename)sheet_names = xlsx.sheet_namesxlsx.close() # 不知道是不是需要for sheet_name in sheet_names:print(" 正在处理:", sheet_name)add_weight(ROOT_DIR + "origin/" + filename, SAVE_DIR + filename, sheet_name)print("处理完毕")处理结果
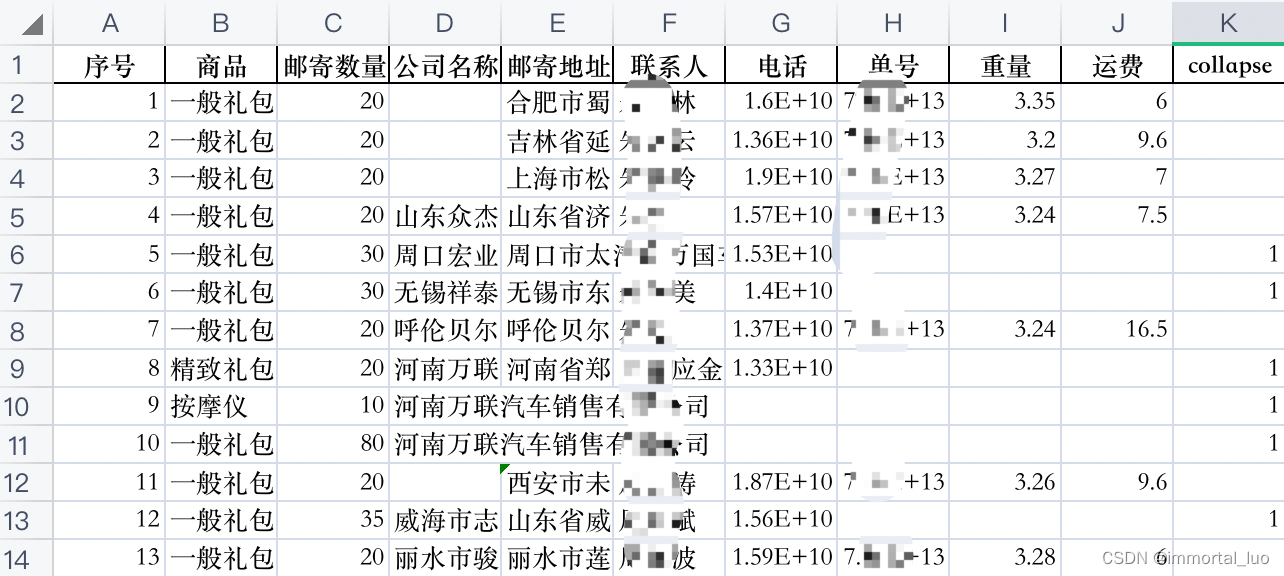
然后我们需要根据collapse列来折叠单号为空的行。
这个我还不知道怎么通过pandas实现,现在就只能先通过Excel自带的功能处理。
比如Mac版的WPS是这么处理的
1、选中collapse列

2、按command+G。按下图设置

3、点击定位
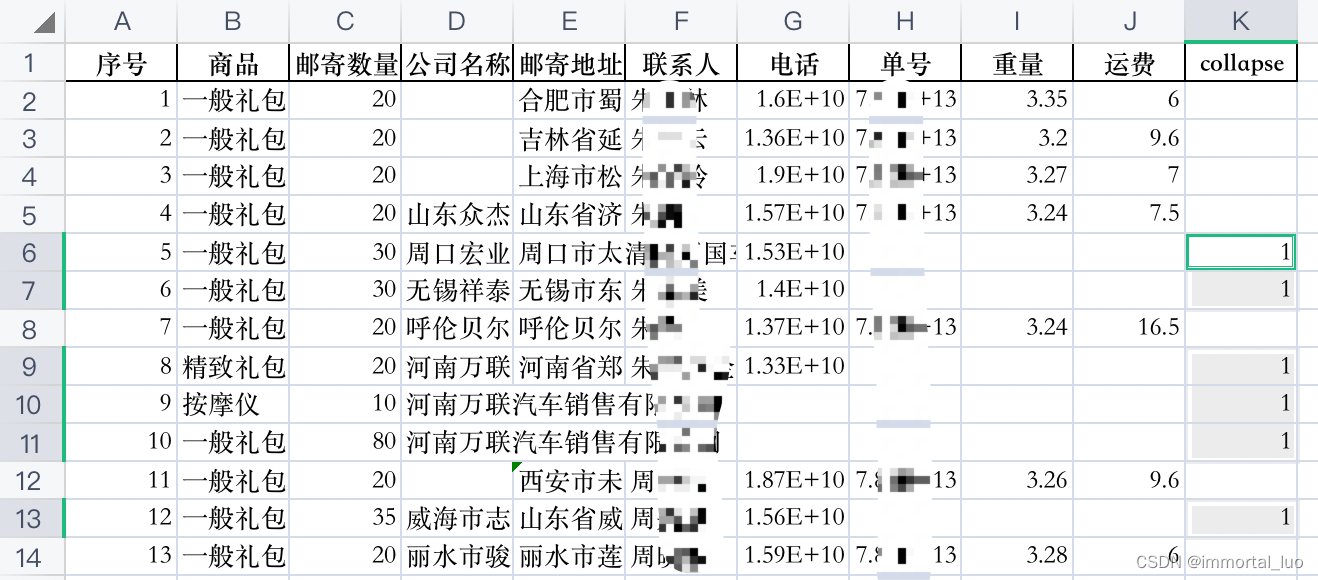
可以发现collapse为1的行被选中了
4、点击command+9。单号为空的行就被折叠了
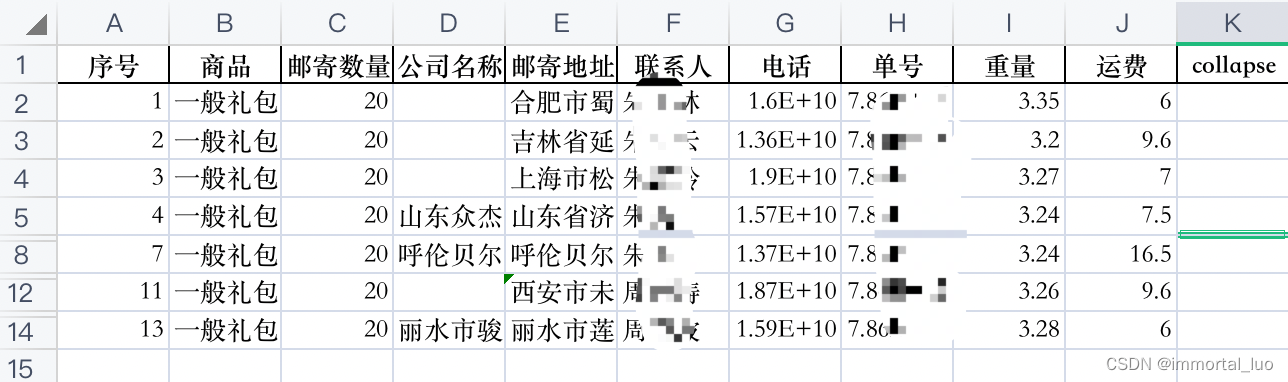
5、然后再删除collapse这列就行了
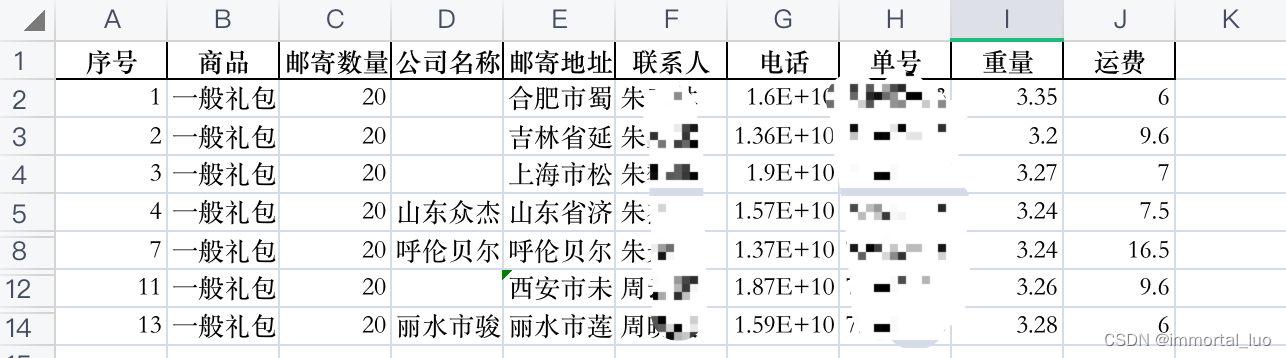
最终结果:
命令行窗口输出
是否删除/Users/XXX/Desktop/OrderProcessing/result/下的所有文件?(Y/N):Y
已删除SAVE_DIR下的所有文件
开始处理
正在处理:table1.xlsx正在处理: Sheet1正在处理: Sheet2
正在处理:A.xlsx正在处理: AA没有找到该订单的重量数据:中通:786XXXX23没有找到该订单的重量数据:786X5780XX37没有找到该订单的重量数据:合在一起打包没有找到该订单的重量数据:786493XX3783158正在处理: AB计算费用时发生错误,可能是价格表中没有对应的地区发生错误的订单号为: 78649XXX184656计算费用时发生错误,可能是价格表中没有对应的地区发生错误的订单号为: 786497XXX08769没有找到该订单的重量数据:786X979XX8226没有找到该订单的重量数据:5箱没有找到该订单的重量数据:直发正在处理: AC正在处理: AD没有找到该订单的重量数据:YT699X121XX068没有找到该订单的重量数据:YT6993X9X987155没有找到该订单的重量数据:786499616XXX08没有找到该订单的重量数据:YT6XXX875919847没有找到该订单的重量数据:786497XXX57489正在处理: AE没有单号这一列,请确保单号那列的列名为'单号'
处理完毕Process finished with exit code 0相关文章:
Python 使用pandas处理Excel —— 快递订单处理 数据匹配 邮费计算
问题背景 有表A,其数据如下 关键信息是邮寄地址和单号。 表B: 关键信息是运单号和重量 我们需要做的是,对于表A中的每一条数据,根据其单号,在表B中查找到对应的重量。 在表A中新增一列重量,将刚才查到的…...
【黑马SpringCloud(7)】分布式事务
分布式事务事务的ACID原则分布式事务理论基础CAP定理BASE理论Seataseata的部署seata的集成事务模式XA模式Seata的XA模型优缺点实现XA模式AT模式案例:AT模式更新数据脏写问题优缺点实现AT模式TCC模式流程分析Seata的TCC模型事务悬挂和空回滚实现TCC模式优缺点SAGA模式…...
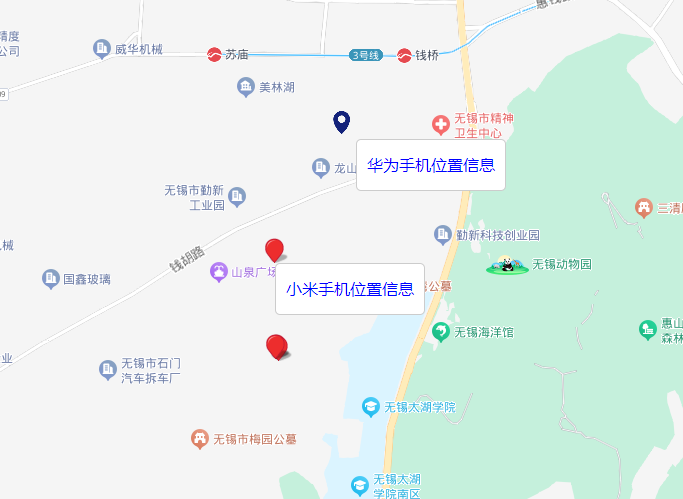
百度地图API添加自定义标记解决单html文件跨域
百度地图API添加自定义标记解决单html文件跨域 因为要往百度地图上添加一些标注点,而且这些标注点要用自定义的图片,而且只能使用单html文件,不能使用服务器(也别问为什么,就是这么个需求),做起…...

如何停止/重启/启动Redis服务
一、命令行直接启动/停止/重启redis 可以直接通过下面的命令启动/停止/重启redis /etc/init.d/redis-server start 启动redis服务 /etc/init.d/redis-server stop 停止redis服务 /etc/init.d/redis-server restart 重启redis服务1、启动redis服务…...
python 的selenium自动操控浏览器教程(2)
人生苦短,我用py 文章目录人生苦短,我用py关于部分网页无法找到元素的问题1方案1方案2关于部分网页无法找到元素的问题2解决方案被网站检查出来我们使用了selenium了怎么办?如何实现前进后退当使用py删除文件时报禁止访问怎么办怎么使用py实现…...

【Deformable Convolution】可变形卷积记录
every blog every motto: You can do more than you think. https://blog.csdn.net/weixin_39190382?typeblog 0. 前言 可变形卷积记录 1. 正文 预印版: Deformable Convolutional Networks v1 Deformable ConvNets v2: More Deformable, Better Results 发表版…...

Oracle-Mysql 函数转换
Oracle-Mysql 函数转换limit <> ROWNUMcast <> TO_NUMBERcast as signedcast as unsignedregexp a_\\d <> REGEXP_LIKEschema() <> SELECT USER FROM DUALinformation_schema.COLUMNS表 <> ALL_TAB_COLUMNS表unix_timestampfrom_unixtime <&g…...
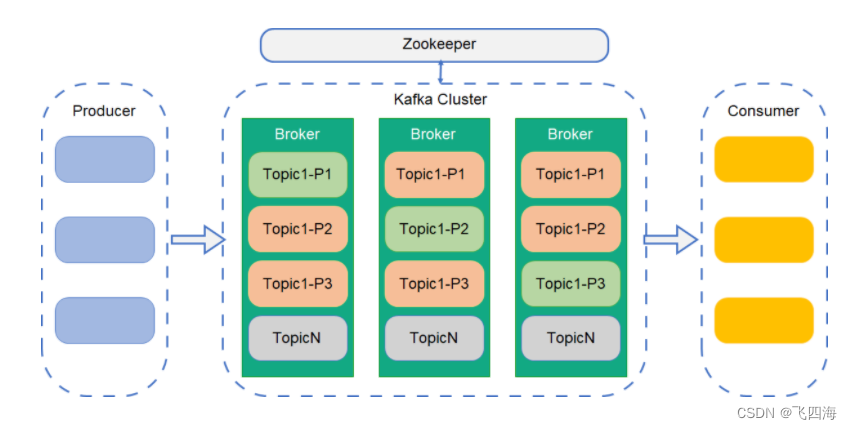
【Kafka】一.认识Kafka
kafka是一个分布式消息队列。由 Scala 开发的高性能跨语言分布式消息队列,单机吞吐量可以到达 10w 级,消息延迟在 ms 级。具有高性能、持久化、多副本备份、横向扩展能力。 生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。 一般在…...

Linux软件管理YUM
目录 yum配置文件 创建仓库 yum查询功能 yum安装与升级功能 yum删除功能 yum仓库产生的问题和解决之道 yum与dnf 网络源 YUM就是通过分析RPM的标头数据后,根据各软件的相关性制作出属性依赖时的解决方案,然后可以自动处理软件的依赖属性问题&…...
【自学MYSQL】MySQL Windows安装
MySQL Windows安装 MySQL Windows下载 首先,我们打开 MySQL 的官网,网址如下: https://dev.mysql.com/downloads/mysql/在官网的主页,我们首先根据我们的操作系统,选择对应的系统,这里我们选择 Windows&…...

Linux c编程之常用技巧
一、说明 在Linux C的实际编程应用中,有很多有用的实践技巧,编程中掌握这些知识,会对编程有事半功倍的效果。 二、常用技巧 2.1 if 变量条件的写法 main.c: #include <stdio.h>int main(int argc, char *argv[]) {int a =...
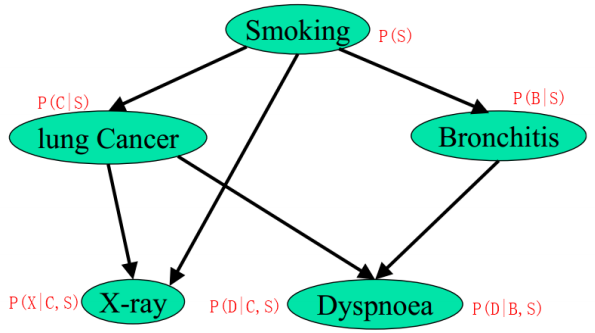
21- 朴素贝叶斯 (NLP自然语言算法) (算法)
朴素贝叶斯要点 概率图模型算法往往应用于NLP自然语言处理领域。根据文本内容判定 分类 。 概率密度公式: 高斯朴素贝叶斯算法: from sklearn.naive_bayes import GaussianNB model GaussianNB() model.fit(X_train,y_train) 伯努利分布朴素贝叶斯算法 fro…...
设计模式第七讲-外观模式、适配器模式、模板方法模式详解
一. 外观模式 1. 背景 在现实生活中,常常存在办事较复杂的例子,如办房产证或注册一家公司,有时要同多个部门联系,这时要是有一个综合部门能解决一切手续问题就好了。 软件设计也是这样,当一个系统的功能越来越强&…...
flutter-第1章-配置环境
flutter-第1章-配置环境 本文针对Windows系统。 一、安装Android Studio 从Android Studio官网下载最新版本,一直默认安装就行。 安装完成要下载SDK,可能会需要科学上网。 打开AS,随便创建一个新项目。 点击右上角的SDK Manager 找到SDK…...
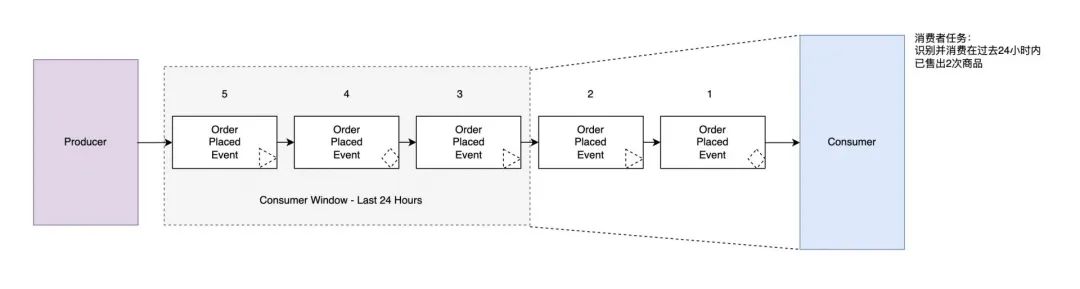
“消息驱动、事件驱动、流 ”的消息模型
文章目录背景消息驱动 Message-Driven事件驱动 Event-Driven流 Streaming事件规范标准简介: 本文旨在帮助大家对近期消息领域的高频词“消息驱动(Message-Driven),事件驱动(Event-Driven)和流(S…...

量化股票配对交易可以用Python语言实现吗?
量化股票配对交易可以用Python语言实现吗?Python 是一种流行的编程语言,可用于所有类型的领域,包括数据科学。有大量软件包可以帮助您实现目标,许多公司使用 Python 来开发与金融界相关的以数据为中心的应用程序和科学计算。 最重…...

机器学习洞察 | 一文带你“讲透” JAX
在上篇文章中,我们详细分享了 JAX 这一新兴的机器学习模型的发展和优势,本文我们将通过 Amazon SageMaker 示例展示如何部署并使用 JAX。JAX 的工作机制JAX 的完整工作机制可以用下面这幅图详细解释:图片来源:“Intro to JAX” video on YouT…...
OpenFaaS介绍
FaaS 云计算时代出现了大量XaaS形式的概念,从IaaS(Infrastructure as a Service)、PaaS(Platform as a Service)、SaaS(Software as a Service)到容器云引领的CaaS(Containers as a Service),再到火热的微服务架构,它们都在试着将各种软、硬…...

【算法设计与分析】STL容器、递归算法、分治法、蛮力法、回溯法、分支限界法、贪心法、动态规划;各类算法代码汇总
文章目录前言一、STL容器二、递归算法三、分治法四、蛮力法五、回溯法六、分支限界法七、贪心法八、动态规划前言 本篇共为8类算法(STL容器、递归算法、分治法、蛮力法、回溯法、分支限界法、贪心法、动态规划),则各取每类算法中的几例经典示例进行展示。 一、STL容…...
vue初识
第一次接触vue,前端的html,css,jquery,js学习也有段时间了,就照着B站的视频简单看了一些,了解了一些简单的用法,这边做一个记录。 官网 工具:使用VSCode以及Live Server插件(能够实时预览) 第…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...