深度学习基础-机器学习基本原理
本文大部分内容参考《深度学习》书籍,从中抽取重要的知识点,并对部分概念和原理加以自己的总结,适合当作原书的补充资料阅读,也可当作快速阅览机器学习原理基础知识的参考资料。
前言
深度学习是机器学习的一个特定分支。我们要想充分理解深度学习,必须对机器学习的基本原理有深刻的理解。
大部分机器学习算法都有超参数(必须在学习算法外手动设定)。机器学习本质上属于应用统计学,其更加强调使用计算机对复杂函数进行统计估计,而较少强调围绕这些函数证明置信区间;因此我们会探讨两种统计学的主要方法: 频率派估计和贝叶斯推断。同时,大部分机器学习算法又可以分成监督学习和无监督学习两类;本文会介绍这两类算法定义,并给出每个类别中一些算法示例。
本章内容还会介绍如何组合不同的算法部分,例如优化算法、代价函数、模型和数据 集,来建立一个机器学习算法。最后,在 5.11 节中,我们描述了一些限制传统机器学习泛化能力的因素。正是这些挑战推动了克服这些障碍的深度学习算法的发展。
大部分深度学习算法都是基于随机梯度下降算法进行求解的。
5.1 学习算法
机器学习算法是一种能够从数据中学习的算法。这里所谓的“学习“是指:“如果计算机程序在任务 TTT 中的性能(以 PPP 衡量)随着经验 EEE 而提高,则可以说计算机程序从经验 EEE 中学习某类任务 TTT 和性能度量 PPP。”-来自 Mitchell (1997)
经验 EEE,任务 TTT 和性能度量 PPP 的定义范围非常宽广,本文不做详细解释。
5.1.1 任务 T
从 “任务” 的相对正式的定义上说,学习过程本身不能算是任务。学习是我们所谓的获取完成任务的能力。机器学习可以解决很多类型的任务,一些非常常见的机器学习任务列举如下:
- 分类:在这类任务中,计算机程序需要指定某些输入属于 kkk 类中的哪一类,例如图像分类中的二分类问题,多分类、单标签问题、多分类多标签问题。
- 回归:在这类任务中,计算机程序需要对给定输入预测数值。为了解决这个任务,学习算法需要输出函数 f:Rn→Rf : \mathbb{R}^n \to \mathbb{R}f:Rn→R。除了返回结果的形式不一样外,这类 问题和分类问题是很像的。
- 机器翻译
- 结构化输出
- 异常检测
- 合成和采样
- 去噪
- 密度估计或概率质量函数估计
- 输入缺失分类
- 转录
- 缺失值填补
5.1.2 性能度量 P
为了评估机器学习算法的能力,我们必须设计其性能的定量度量,即算法的精度指标。通常,性能度量 PPP 特定于系统正在执行的任务 TTT。
可以理解为不同的任务有不同的性能度量。
对于诸如分类、缺失输入分类和转录任务,我们通常度量模型的准确率(accu- racy)。准确率是指该模型输出正确结果的样本比率。我们也可以通过错误率(error rate)得到相同的信息。错误率是指该模型输出错误结果的样本比率。
我们使用测试集(test set)数据来评估系统性能,将其与训练机器学习系统的训练集数据分开。
值得注意的是,性能度量的选择或许看上去简单且客观,但是选择一个与系统理想表现能对应上的性能度量通常是很难的。
5.1.3 经验 E
根据学习过程中的不同经验,机器学习算法可以大致分类为两类
- 无监督(
unsuper-vised)算法 - 监督(
supervised)算法
无监督学习算法(unsupervised learning algorithm)训练含有很多特征的数据集,然后学习出这个数据集上有用的结构性质。在深度学习中,我们通常要学习生成数据集的整个概率分布,显式地,比如密度估计,或是隐式地,比如合成或去噪。 还有一些其他类型的无监督学习任务,例如聚类,将数据集分成相似样本的集合。
监督学习算法(supervised learning algorithm)也训练含有很多特征的数据集,但与无监督学习算法不同的是数据集中的样本都有一个标签(label)或目标(target)。例如,Iris 数据集注明了每个鸢尾花卉样本属于什么品种。监督学习算法通过研究 Iris 数据集,学习如何根据测量结果将样本划分为三个不同品种。
半监督学习算法中,一部分样本有监督目标,另外一部分样本则没有。在多实例学习中,样本的整个集合被标记为含有或者不含有该类的样本,但是集合中单独的样本是没有标记的。
大致说来,无监督学习涉及到观察随机向量 xxx 的好几个样本,试图显式或隐式地学习出概率分布 p(x)p(x)p(x),或者是该分布一些有意思的性质; 而监督学习包含观察随机向量 xxx 及其相关联的值或向量 yyy,然后从 xxx 预测 yyy,通常是估计 p(y∣x)p(y | x)p(y∣x)。术语监督学习(supervised learning)源自这样一个视角,教员或者老师提供目标 yyy 给机器学习系统,指导其应该做什么。在无监督学习中,没有教员或者老师,算法必须学会在没有指导的情况下理解数据。
无监督学习和监督学习并不是严格定义的术语。它们之间界线通常是模糊的。很多机器学习技术可以用于这两个任务。
尽管无监督学习和监督学习并非完全没有交集的正式概念,它们确实有助于粗略分类我们研究机器学习算法时遇到的问题。传统地,人们将回归、分类或者结构化输出问题称为监督学习。支持其他任务的密度估计通常被称为无监督学习。
表示数据集的常用方法是设计矩阵(design matrix)。
5.1.4 示例: 线性回归
我们将机器学习算法定义为,通过经验以提高计算机程序在某些任务上性能的算法。这个定义有点抽象。为了使这个定义更具体点,我们展示一个简单的机器学习示例: 线性回归(linear regression)。
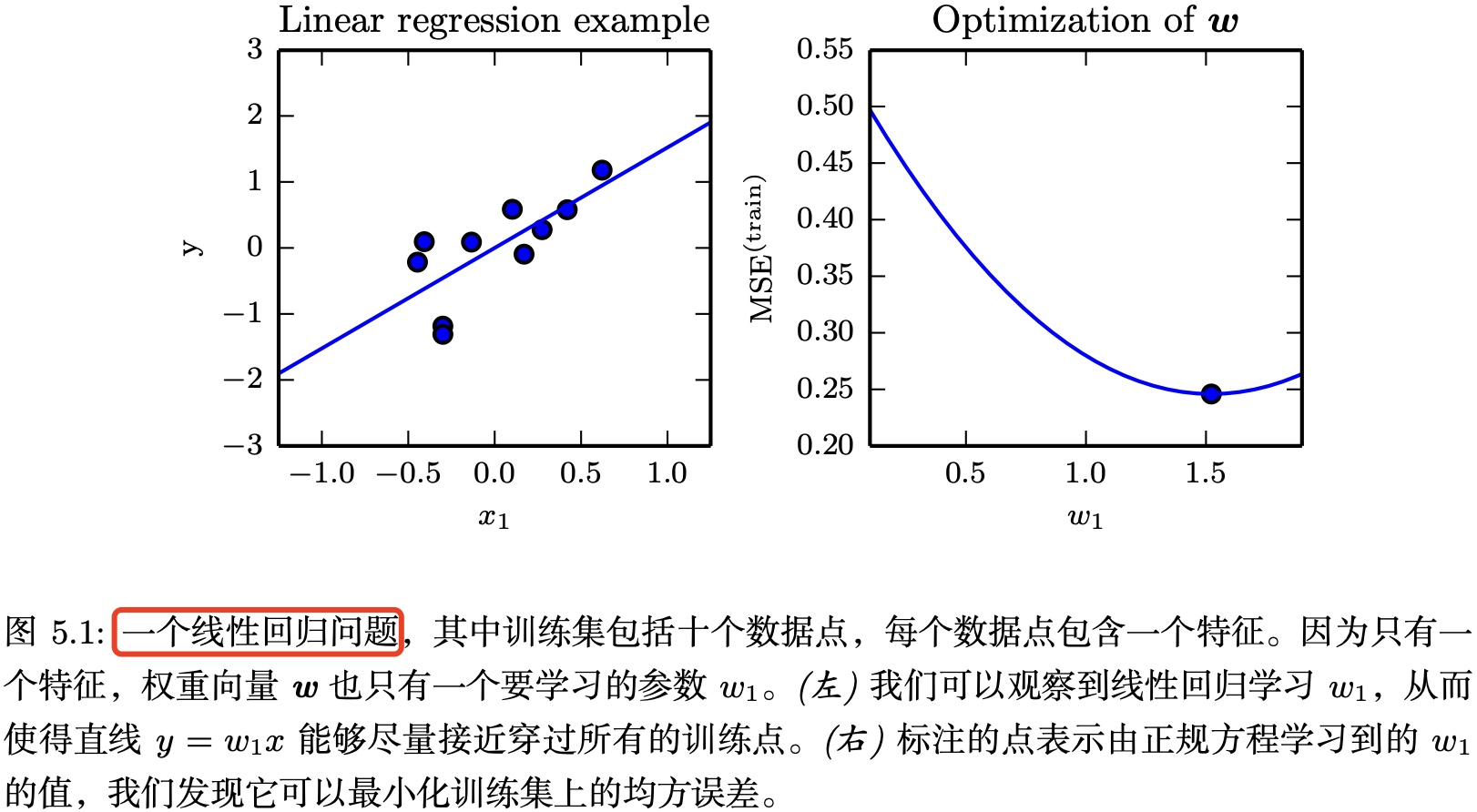
顾名思义,线性回归解决回归问题。 换句话说,目标是构建一个系统,该系统可以将向量 x∈Rx \in \mathbb{R}x∈R 作为输入,并预测标量 y∈Ry \in \mathbb{R}y∈R 作为输出。在线性回归的情况下,输出是输入的线性函数。令 y^\hat{y}y^ 表示模型预测值。我们定义输出为
y^=w⊤x(5.3)\hat{y} = w^{⊤}x \tag{5.3} y^=w⊤x(5.3)
其中 w∈Rnw \in \mathbb{R}^{n}w∈Rn 是参数(parameter)向量。
参数是控制系统行为的值。在这种情况下,wiw_iwi 是系数,会和特征 xix_ixi 相乘之 后全部相加起来。我们可以将 www 看作是一组决定每个特征如何影响预测的权重 (weight)。
通过上述描述,我们可以定义任务 TTT : 通过输出 y^=w⊤x\hat{y} = w^{⊤}xy^=w⊤x 从 xxx 预测 yyy。
我们使用测试集(test set)来评估模型性能如何,将输入的设计矩 阵记作 X\textit{X}X(test),回归目标向量记作 yyy(test)。
回归任务常用的一种模型性能度量方法是计算模型在测试集上的 均方误差(mean squared error)。如果 y^\hat{y}y^(test) 表示模型在测试集上的预测值,那么均方误差表示为:
MSEtest=1m∑i(y^(test)−y(test))i2(5.4)MSE_{test} = \frac{1}{m} \sum_{i}(\hat{y}^{(test)}-y^{(test)})_{i}^{2} \tag{5.4} MSEtest=m1i∑(y^(test)−y(test))i2(5.4)
直观上,当 y^(test)\hat{y}^{(test)}y^(test) = y(test)y^{(test)}y(test) 时,我们会发现误差降为 0。
图 5.1 展示了线性回归算法的使用示例。
5.2 容量、过拟合和欠拟合
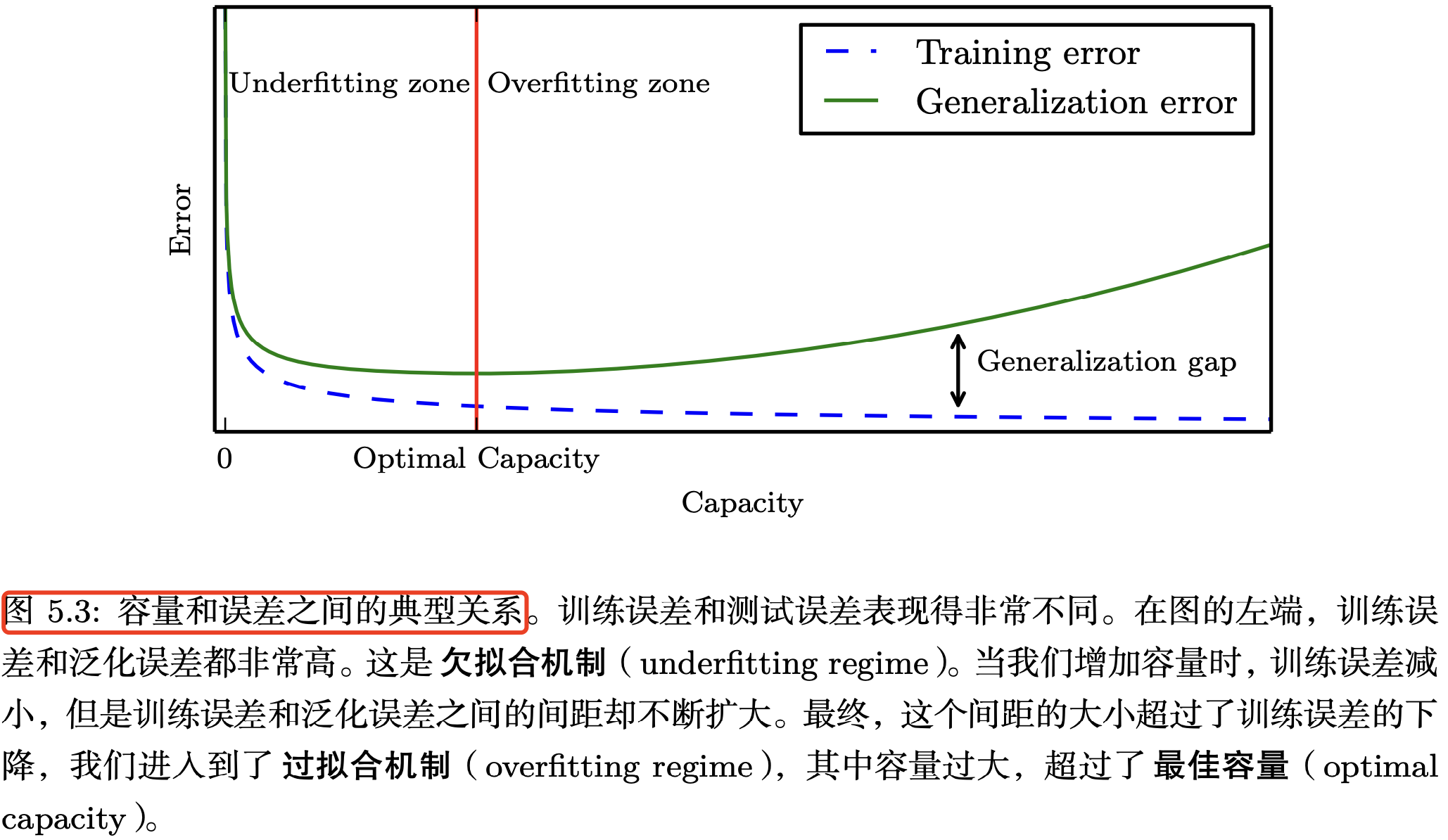
机器学习的挑战主要在于算法如何在测试集(先前未观测的新输入数据)上表现良好,而不只是在训练集上表现良好,即训练误差和泛化误差读比较小,也可理解为算法泛化性比较好。所谓泛化性(generalized)好指的是,算法在在测试集(以前未观察到的输入)上表现良好。
机器学习算法的两个主要挑战是: 欠拟合(underfitting)和过拟合(overfitting)。
- 欠拟合是指模型不能在训练集上获得足够低的误差。
- 而过拟合是指训练误差和和测试误差之间的差距太大。
通过调整模型的容量(capacity),我们可以控制模型是否偏向于过拟合或者欠拟合。通俗地讲,模型的容量是指其拟合各种函数的能力。容量低的模型可能很难拟合训练集,容量高的模型可能会过拟合,因为记住了不适用于测试集的训练集性质。
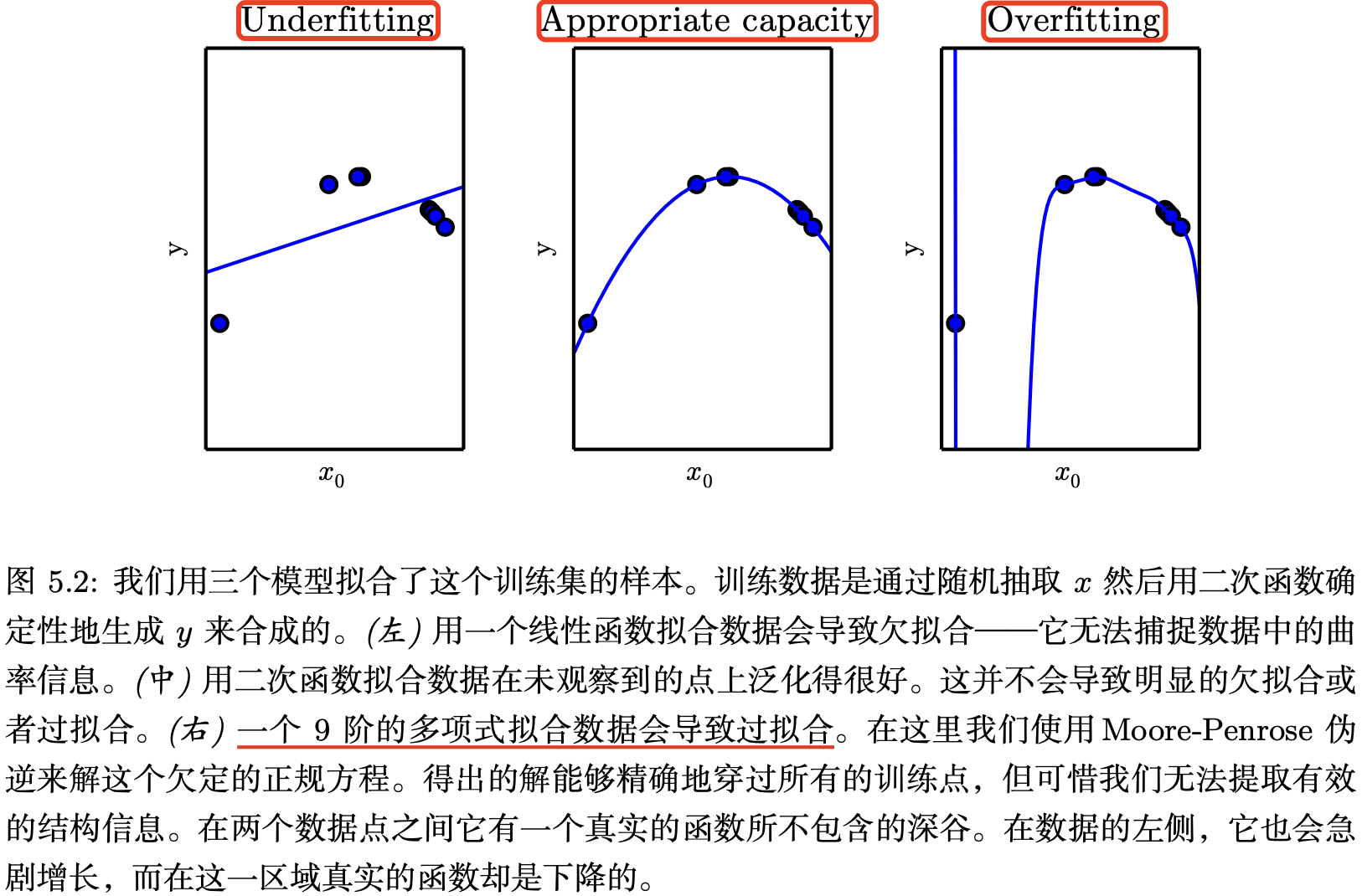
一种控制训练算法容量的方法是选择假设空间(hypothesis space),即学习算法可以选择作为解决方案的函数集。例如,线性回归算法将其输入的所有线性函数的集合作为其假设空间。我们可以推广线性回归以在其假设空间中包含多项式,而不仅仅是线性函数。这样做就增加模型的容量。
注意,学习算法的效果不仅很大程度上受影响于假设空间的函数数量,也取决于这些函数的具体形式。
当机器学习算法的容量适合于所执行任务的复杂度和所提供训练数据的数量时,算法效果通常会最佳。容量不足的模型不能解决复杂任务。容量高的模型能够解决复杂的任务,但是当其容量高于任务所需时,有可能会过拟合。
图 5.2 展示了上述原理的使用情况。我们比较了线性,二次和 9 次预测器拟合真实二次函数的效果。
提高机器学习模型泛化性的早期思想是奥卡姆剃刀原则,即选择“最简单”的那一个模型。
统计学习理论提供了量化模型容量的不同方法。在这些中,最有名的是 Vapnik- Chervonenkis 维度(Vapnik-Chervonenkis dimension, VC)。VC 维度量二元分类 器的容量。VC 维定义为该分类器能够分类的训练样本的最大数目。假设存在 mmm 个 不同 xxx 点的训练集,分类器可以任意地标记该 mmm 个不同的 xxx 点,VC 维被定义为 mmm 的最大可能值。
因为可以量化模型的容量,所以使得统计学习理论可以进行量化预测。统计学习理论中最重要的结论阐述了训练误差和泛化误差之间差异的上界随着模型容量增长而增长,但随着训练样本增多而下降 (Vapnik and Chervonenkis, 1971; Vapnik, 1982; Blumer et al., 1989; Vapnik, 1995)。这些边界为机器学习算法可以有效解决问题提供了理论 验证,但是它们很少应用于实际中的深度学习算法。一部分原因是边界太松,另一部分原因是很难确定深度学习算法的容量。由于有效容量受限于优化算法的能力,所以确定深度学习模型容量的问题特别困难。而且我们对深度学习中涉及的非常普遍的非凸优化问题的理论了解很少。
虽然更简单的函数更可能泛化(训练误差和测试误差的差距小),但我们仍然必须选择一个足够复杂的假设来实现低训练误差。通常,随着模型容量的增加,训练误差会减小,直到它逐渐接近最小可能的误差值(假设误差度量具有最小值)。通常,泛化误差是一个关于模型容量的 U 形曲线函数。如下图 5.3 所示。
5.2.1 没有免费午餐定理
机器学习的没有免费午餐定理(Wolpert,1996)指出,对所有可能的数据生成分布进行平均,每个分类算法在对以前未观察到的点进行分类时具有相同的错误率。换句话说,在某种意义上,没有任何机器学习算法普遍优于其他任何算法。
上述这个结论听着真的让人伤感,但庆幸的是,这些结论仅在我们考虑所有可能的数据生成分布时才成立。如果我们对实际应用中遇到的概率分布类型做出假设,那么我们可以设计出在这些分布上表现良好的学习算法。
这意味着机器学习研究的目标不是找一个通用学习算法或是绝对最好的学习算法。反之,我们的目标是理解什么样的分布与人工智能获取经验的 “真实世界” 相关,什么样的学习算法在我们关注的数据生成分布上效果最好。
总结:没有免费午餐定理清楚地阐述了没有最优的学习算法,即暗示我们必须在特定任务上设计性能良好的机器学习算法。
5.2.2 正则化
所谓正则化,是指我们通过修改学习算法,使其降低泛化误差而非训练误差的方法。
正则化是一种思想(策略),它是机器学习领域的中心问题之一,其重要性只有优化能与其相媲美。
一般地,正则化一个学习函数 f(x;θ)f(x;\theta)f(x;θ) 的模型,我们可以给代价函数添加被称为正则化项(regularizer)的惩罚。如果正则化项是 Ω(w)=w⊤w\Omega(w) = w^{\top}wΩ(w)=w⊤w,则称为权重衰减(weight decay)。
例如,我们可以加入权重衰减(weight decay)来修改线性回归的目标函数,如偏好于平方 L2L^2L2 范数较小权重的目标函数形式:
J(w)=MSEtrain+λw⊤w(5.18)J(w) = MSE_{train} + \lambda w^{⊤}w \tag{5.18} J(w)=MSEtrain+λw⊤w(5.18)
其中 J(w)J(w)J(w) 是目标函数,www 是权重参数。λ\lambdaλ 是超参数,需提前设置,其控制我们对较小权重的偏好强度。当 λ=0\lambda = 0λ=0,我们没有任何偏好。λ\lambdaλ 越大,则权重越小。最小化 J(w)J(w)J(w) 会导致权重的选择在拟合训练数据和较小权重之间进行权衡。
和上一节没有最优的学习算法一样,一样的,也没有最优的正则化形式。反之,我们必须挑选一个非常适合于我们所要解决的任务的正则形式。
5.3 超参数和验证集
超参数的值不是通过学习算法本身学习出来的,而是需要算法定义者手动指定的。
5.3.1 验证集的作用
通常,80% 的训练数据用于训练,20% 用于验证。验证集是用于估计训练中或训练后的泛化误差,从而更新超参数。
5.3.2 交叉验证
一个小规模的测试集意味着平均测试误差估计的统计不确定性,使得很难判断算法 A 是否比算法 B 在给定的任务上做得更好。解决办法是基于在原始数据上随机采样或分离出的不同数据集上重复训练和测试,最常见的就是 kkk-折交叉验证,即将数据集分成 kkk 个 不重合的子集。测试误差可以估计为 kkk 次计算后的平均测试误差。在第 iii 次测试时, 数据的第 iii 个子集用于测试集,其他的数据用于训练集。算法过程如下所示。
k 折交叉验证虽然一定程度上可以解决小数据集上测试误差的不确定性问题,但代价则是增加了计算量。

5.4 估计、偏差和方差
统计领域为我们提供了很多工具来实现机器学习目标,不仅可以解决训练集上 的任务,还可以泛化。基本的概念,例如参数估计、偏差和方差,对于正式地刻画泛化、欠拟合和过拟合都非常有帮助。
5.4.1 点估计
点估计试图为一些感兴趣的量提供单个 ‘‘最优’’ 预测。一般地,感兴趣的量可以是单个参数也可以是一个向量参数,例如第 5.1.4 节线性回归中的权重,但是也有可能是整个函数。
为了区分参数估计和真实值,我们习惯将参数 θ\thetaθ 的点估计表示为 θ^\hat{\theta}θ^。
令 x(1),...,x(m){x^{(1)}, . . . , x^{(m)}}x(1),...,x(m) 是 mmm 个独立同分布(i.i.d.)的数据点。 点估计(point esti-mator)或统计量(statistics)是这些数据的任意函数:
θm^=g(x(1),...,x(m)).(5.19)\hat{\theta_m} =g(x^{(1)},...,x^{(m)}). \tag{5.19} θm^=g(x(1),...,x(m)).(5.19)
5.4.2 偏差
估计的偏差定义如下:
bias(θm^)=E(θm^)−θ,(5.19)bias(\hat{\theta_m}) = E(\hat{\theta_m}) − \theta, \tag{5.19} bias(θm^)=E(θm^)−θ,(5.19)
其中期望作用在所有数据(看作是从随机变量采样得到的)上,θ^\hat{\theta}θ^ 是用于定义数据生成分布的 θ\thetaθ 的真实值。如果 bias(θm^)=0bias(\hat{\theta_m}) = 0bias(θm^)=0,那么估计量 θm^\hat{\theta_m}θm^ 则被称为是无偏 (unbiased),同时意味着 E(θm^)=θE(\hat{\theta_m}) = \thetaE(θm^)=θ。
5.4.3 方差和标准差
方差记为 Var(θ^)Var(\hat{\theta})Var(θ^) 或 σ2\sigma^{2}σ2,方差的平方根被称为标准差。
5.4.4 权衡偏差和方差以最小化均方误差
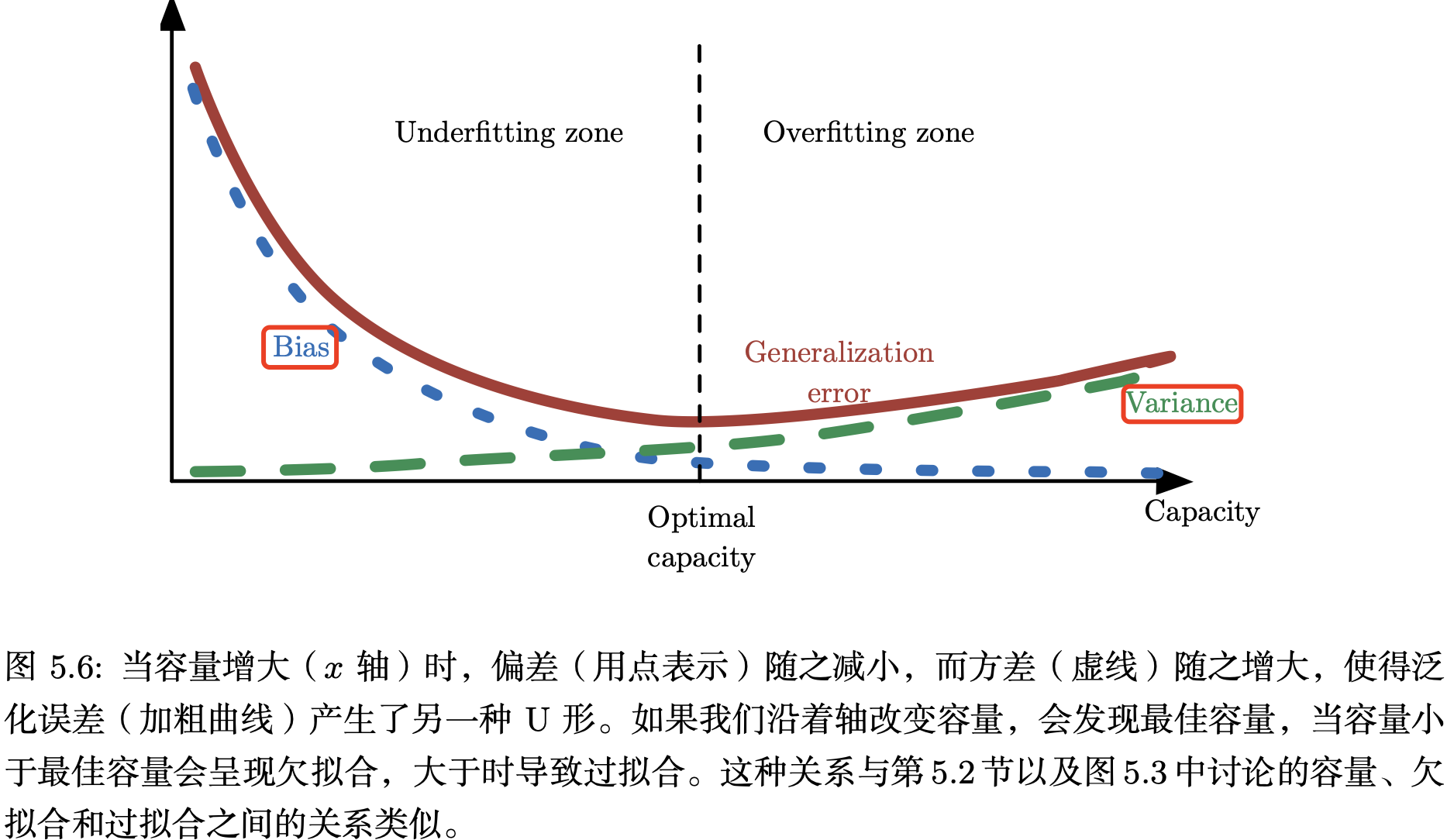
偏差和方差度量着估计量的两个不同误差来源。偏差度量着偏离真实函数或参数的误差期望。而方差度量着数据上任意特定采样可能导致的估计期望的偏差。
偏差和方差的关系和机器学习容量、欠拟合和过拟合的概念紧密相联。用 MSE 度量泛化误差(偏差和方差对于泛化误差都是有意义的)时,增加容量会增加方差,降低偏差。如图 5.6 所示,我们再次在关于容量的函数中,看到泛化误差的 U 形曲线。
5.5,最大似然估计
与其猜测某个函数可能是一个好的估计器,然后分析它的偏差和方差,我们更希望有一些原则,我们可以从中推导出特定的函数,这些函数是不同模型的良好估计器。最大似然估计就是其中最为常用的准则。
5.6 贝叶斯统计
到目前为止,我们已经描述了频率统计(frequentist statistics)和基于估计单一 θ\thetaθ 值的方法,然后基于该估计作所有的预测。 另一种方法是在进行预测时考虑所有可能的 θ\thetaθ 值。 后者属于贝叶斯统计(Bayesian statistics)的范畴。
如 5.4.1 节中讨论的,频率派的视角是真实参数 θ\thetaθ 是未知的定值,而点估计 θ^\hat{\theta}θ^ 是考虑数据集上函数(可以看作是随机的)的随机变量。
贝叶斯统计的视角完全不同。贝叶斯用概率反映知识状态的确定性程度。数据集能够被直接观测到,因此不是随机的。另一方面,真实参数 θ\thetaθ 是未知或不确定的, 因此可以表示成随机变量。
5.7 监督学习算法
回顾 5.1.3 节内容,简单来说,监督学习算法是给定一组输入 xxx 和输出 yyy 的训练 集,学习如何关联输入和输出。在许多情况下,输出 yyy 可能难以自动收集,必须由人类“监督者”提供,但即使训练集目标是自动收集的,该术语仍然适用。
5.8 无监督学习算法
回顾第5.1.3节,无监督算法只处理 “特征’’,不操作监督信号。监督和无监督算法之间的区别没有规范严格的定义,因为没有客观的测试来区分一个值是特征还是监督者提供的目标。通俗地说,无监督学习的大多数尝试是指从不需要人为注释的样本的分布中提取信息。该术语通常与密度估计相关,学习从分布中采样、学习从分布中去噪、寻找数据分布的流形或是将数据中相关的样本聚类。
5.8.1 PCA 降维
PCA(Principal Component Analysis)是学习数据表示的无监督学习算法,常用于高维数据的降维,可用于提取数据的主要特征分量。
PCA 的数学推导可以从最大可分型和最近重构性两方面进行,前者的优化条件为划分后方差最大,后者的优化条件为点到划分平面距离最小。
5.8.2 k-均值聚类
另外一个简单的表示学习算法是 kkk-均值聚类。kkk-均值聚类算法将训练集分成 kkk 个靠近彼此的不同样本聚类。因此我们可以认为该算法提供了 kkk-维的 one-hot 编码向量 hhh 以表示输入 xxx。当 xxx 属于聚类 iii 时,有 hi=1h_i = 1hi=1,hhh 的其他项为零。
kkk-均值聚类初始化 k 个不同的中心点 μ(1),...,μ(k){μ^{(1)}, . . . , μ^{(k)}}μ(1),...,μ(k),然后迭代交换以下两个不同的步骤直到算法收敛。
- 步骤一,每个训练样本分配到最近的中心点 μ(i)μ^{(i) }μ(i) 所代表的聚类 iii。
- 步骤二,每一个中心点 μ(i)μ^{(i) }μ(i) 更新为聚类 iii 中所有训练样本 x(j)x^{(j)}x(j) 的均值。
关于聚类的一个问题是聚类问题本身是病态的。这是说没有单一的标准去度量聚类的数据在真实世界中效果如何。我们可以度量聚类的性质,例如类中元素到类中心点的欧几里得距离的均值。这使我们可以判断从聚类分配中重建训练数据的效果如何。然而我们不知道聚类的性质是否很好地对应到真实世界的性质。此外,可能有许多不同的聚类都能很好地对应到现实世界的某些属性。我们可能希望找到和 一个特征相关的聚类,但是得到了一个和任务无关的,同样是合理的不同聚类。
例如,假设我们在包含红色卡车图片、红色汽车图片、灰色卡车图片和灰色汽车图片的数据集上运行两个聚类算法。如果每个聚类算法聚两类,那么可能一个算法将汽车和卡车各聚一类,另一个根据红色和灰色各聚一类。假设我们还运行了第三个聚类算法,用来决定类别的数目。这有可能聚成了四类,红色卡车、红色汽车、灰色卡 车和灰色汽车。现在这个新的聚类至少抓住了属性的信息,但是丢失了相似性信息。 红色汽车和灰色汽车在不同的类中,正如红色汽车和灰色卡车也在不同的类中。该聚类算法没有告诉我们灰色汽车和红色汽车的相似度比灰色卡车和红色汽车的相似度更高,我们只知道它们是不同的。
5.9 随机梯度下降
几乎所有的深度学习算法都用到了一个非常重要的优化算法: 随机梯度下降 (stochastic gradient descent, SGD)。
机器学习中反复出现的一个问题是好的泛化需要大的训练集,但大的训练集的 计算代价也更大。
机器学习算法中的代价函数通常可以分解成每个样本的代价函数的总和。

随机梯度下降的核心是,梯度是期望,而期望可使用小规模的样本近似估计。具体来说,在算法的每一步,我们从训练集中均匀抽出一小批量(minibatch)样本 B=x(1),...,x(m′)B={x^{(1)},...,x^{(m′)}}B=x(1),...,x(m′)。小批量的数目 m′m′m′ 通常是一个相对较小的数,一般为 2n2^n2n(取决于显卡显卡)。重要的是,当训练集大小 m 增长时,m′m′m′ 通常是固定的。我们可能在拟合几十亿的样本时,但每次更新计算只用到几百个样本。

梯度下降往往被认为很慢或不可靠。以前,将梯度下降应用到非凸优化问题被认为很鲁莽或没有原则。但现在,我们知道梯度下降用于深度神经网络模型的训练时效果是不错的。优化算法不一定能保证在合理的时间内达到一个局部最小值,但它通常能及时地找到代价函数一个很小的值,并且是有用的。
随机梯度下降在深度学习之外有很多重要的应用。它是在大规模数据上训练大型线性模型的主要方法。对于固定大小的模型,每一步随机梯度下降更新的计算量 不取决于训练集的大小 m。在实践中,当训练集大小增长时,我们通常会使用一个更大的模型,但这并非是必须的。达到收敛所需的更新次数通常会随训练集规模增大而增加。然而,当 m 趋向于无穷大时,该模型最终会在随机梯度下降抽样完训练 集上的所有样本之前收敛到可能的最优测试误差。继续增加 m 不会延长达到模型可能的最优测试误差的时间。从这点来看,我们可以认为用 SGD 训练模型的渐近代价是关于 m 的函数的 O(1)O(1)O(1) 级别。
5.10 构建机器学习算法 pipeline
几乎所有的深度学习算法都可以被描述为一个相当简单的 pipeline:
- 特定的数据集
- 代价函数
- 优化过程
- 神经网络模型。
参考资料
- 《深度学习》
- 【机器学习】降维——PCA(非常详细)
相关文章:
深度学习基础-机器学习基本原理
本文大部分内容参考《深度学习》书籍,从中抽取重要的知识点,并对部分概念和原理加以自己的总结,适合当作原书的补充资料阅读,也可当作快速阅览机器学习原理基础知识的参考资料。 前言 深度学习是机器学习的一个特定分支。我们要想…...

C语言操作符详解 一针见血!
目录算数操作符移位操作符位操作符赋值操作符单目操作符关系操作符逻辑操作符条件操作符逗号表达式下标引用、函数调用和结构成员表达式求值11.1 隐式类型转换算数操作符💭 注意/ 除法 --得到的是商% 取模(取余)--得到的是余数如果除法操作符…...
前端面试题汇总
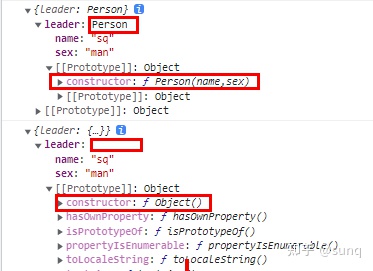
一:JavaScript 1、闭包是什么?利弊?如何解决弊端? 闭包是什么:JS中内层函数可以访问外层函数的变量,外层函数无法操作内存函数的变量的特性。我们把这个特性称作闭包。 闭包的好处: 隔离作用…...

以数据驱动管理场景,低代码助力转型下一站
数据驱动 数据驱动,是通过移动互联网或者其他的相关软件为手段采集海量的数据,将数据进行组织形成信息,之后对相关的信息讲行整合和提炼,在数据的基础上经过训练和拟合形成自动化的决策模型,简单来说,就是…...

2023年全国数据治理DAMA-CDGA/CDGP考试报名到弘博创新
弘博创新是DAMA中国授权的数据治理人才培养基地,贴合市场需求定制教学体系,采用行业资深名师授课,理论与实践案例相结合,快速全面提升个人/企业数据治理专业知识与实践经验,通过考试还能获得数据专业领域证书。 DAMA认…...

流程控制之循环
文章目录五、流程控制之循环5.1 步进循环语句for5.1.1 带列表的for循环语句5.1.2 不带列表的for循环语句5.1.3 类C风格的for循环语句5.2 while循环语句5.2.1 while循环读取文件5.2.2 while循环语句示例5.3 until循环语句5.4 select循环语句5.5 嵌套循环5.4 利用break和continue…...
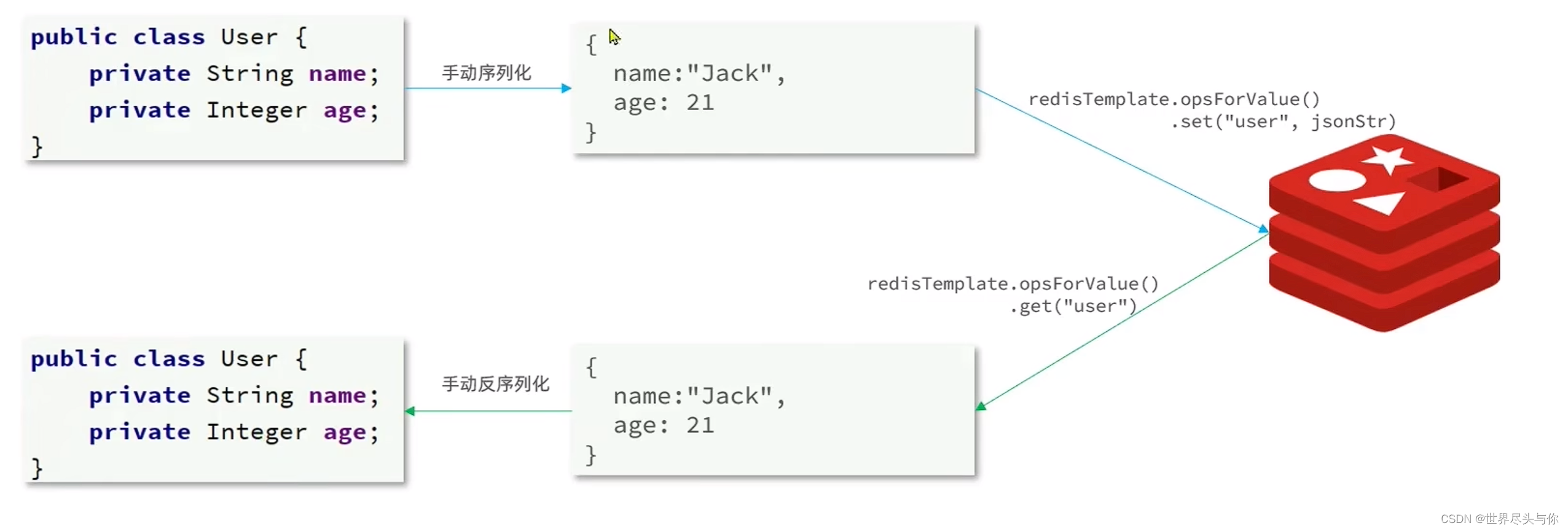
SpringDataRedis快速入门
SpringDataRedis快速入门1.SpringDataRedis简介2.RedisTemplate快速入门3.RedisSerializer4.StringRedisTemplate1.SpringDataRedis简介 SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis Spri…...

MySQL 的执行计划 explain 详解
目录 什么是执行计划 执行计划的内容 select子句的类型 访问类型 索引的存在形式...
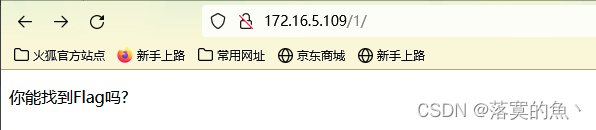
2023年网络安全比赛--Web综合渗透测试中职组(超详细)
一、竞赛时间 180分钟 共计3小时 二、竞赛阶段 1.通过URL访问http://靶机IP/1,对该页面进行渗透测试,将完成后返回的结果内容作为FLAG值提交; 2.通过URL访问http://靶机IP/2,对该页面进行渗透测试,将完成后返回的结果内容作为FLAG值提交; 3.通过URL访问http://靶机IP/3,对…...
【c++之于c的优化 - 下】
前言 一、inline 概念 以inline修饰的函数叫做内联函数,编译时C编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率。 如果在上述函数前增加inline关键字将其改成内联函数,在编译期间编译…...
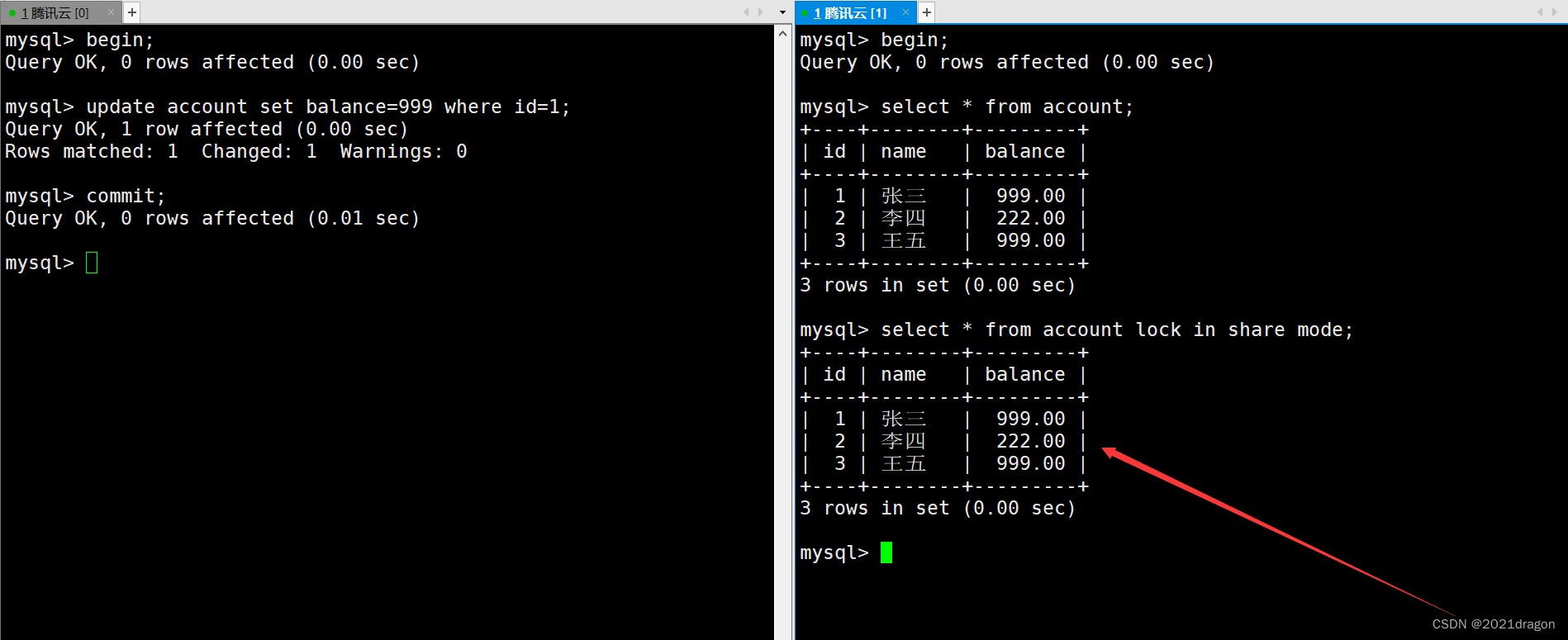
MySQL事务管理
文章目录MySQL事务管理事务的概念事务的版本支持事务的提交方式事务的相关演示事务的隔离级别查看与设置隔离级别读未提交(Read Uncommitted)读提交(Read Committed)可重复读(Repeatable Read)串行化&#…...

二维计算几何全家桶
参考文章:范神的神仙博客 前置芝士 一些高中数学 向量的叉积:向量的点积为 a⋅b∣a∣∣b∣cos<a,b>a\cdot b|a||b|\cos<a,b>a⋅b∣a∣∣b∣cos<a,b>,向量的叉积为 ab∣a∣∣b∣sin<a,b>a\times b|a||b|\sin<…...
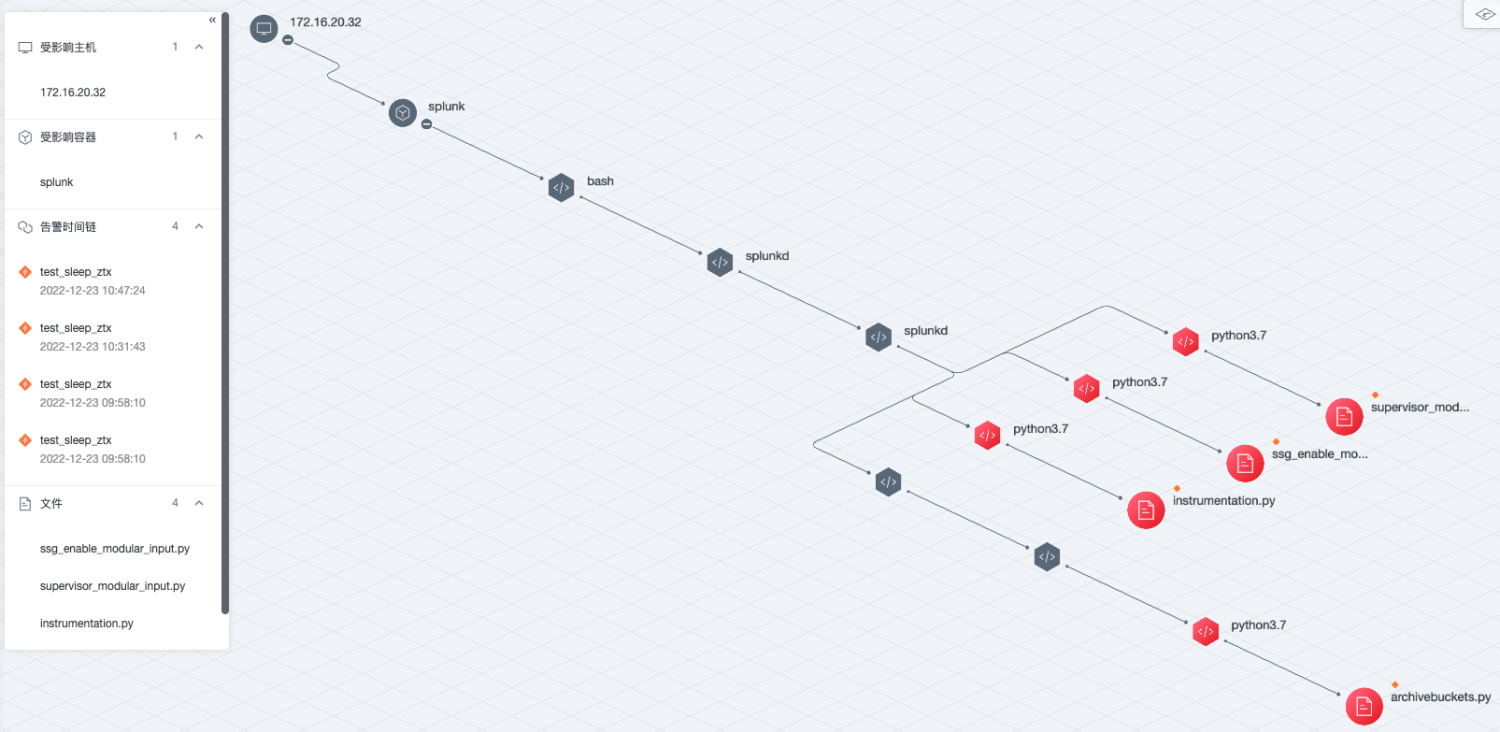
基于图的下一代入侵检测系统
青藤云安全是一家主机安全独角兽公司,看名字就知道当前很大一块方向专注云原生应用安全,目前主营的是主机万相/容器蜂巢产品,行业领先,累计支持 800万 Agent。当前公司基于 NebulaGraph 结合图技术开发的下一代实时入侵检测系统已…...

若依框架---树状层级部门数据库表
👏作者简介:大家好,我是小童,Java开发工程师,CSDN博客博主,Java领域新星创作者 📕系列专栏:前端、Java、Java中间件大全、微信小程序、微信支付、若依框架、Spring全家桶 Ǵ…...
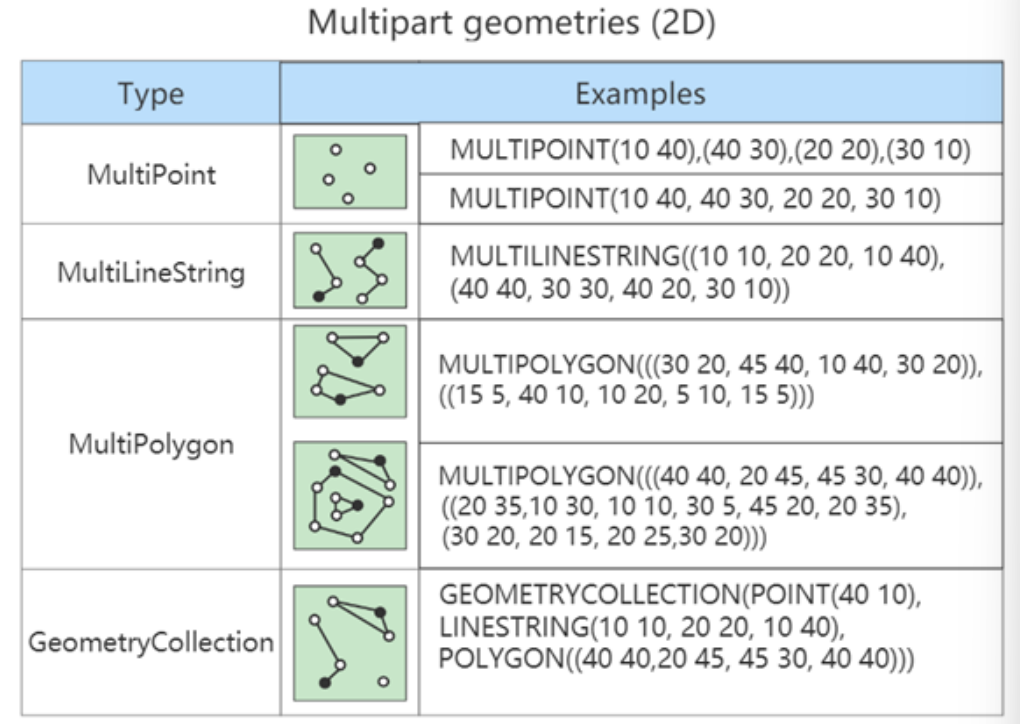
【Mysql第十期 数据类型】
文章目录1. MySQL中的数据类型2.类型介绍2.2 可选属性2.2.2 UNSIGNED2.2.3 ZEROFILL2.3 适用场景2.4 如何选择?3. 浮点类型3.2 数据精度说明3.3 精度误差说明4. 定点数类型4.1 类型介绍4.2 开发中经验5. 位类型:BIT6. 日期与时间类型6.1 YEAR类型6.2 DAT…...

2023-2-9 刷题情况
删除子文件夹 题目描述 你是一位系统管理员,手里有一份文件夹列表 folder,你的任务是要删除该列表中的所有 子文件夹,并以 任意顺序 返回剩下的文件夹。 如果文件夹 folder[i] 位于另一个文件夹 folder[j] 下,那么 folder[i] 就…...
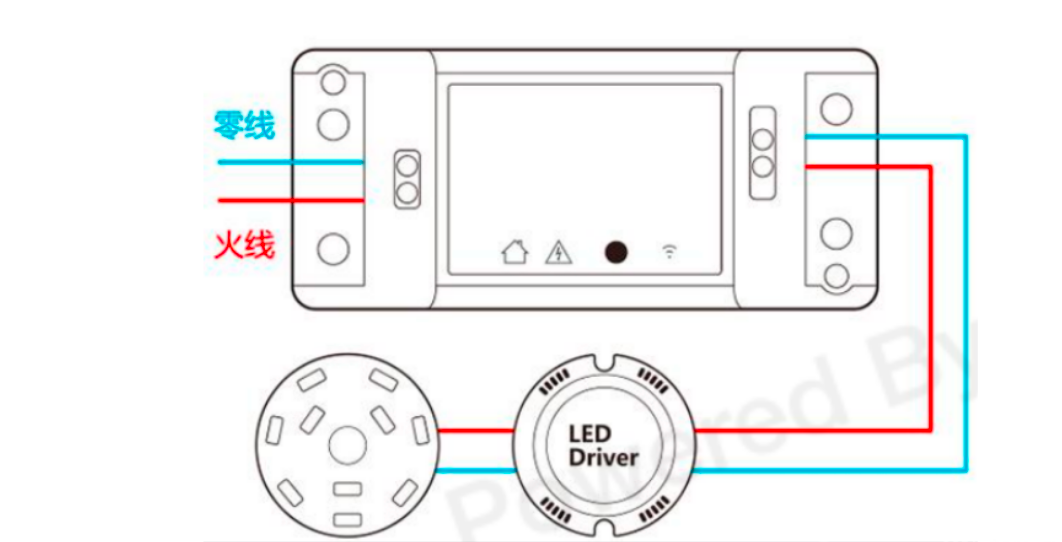
Homekit智能家居DIY设备-智能通断开关
智能通断器,也叫开关模块,可以非常方便地接入家中原有开关、插座、灯具、电器的线路中,通过手机App或者语音即可控制电路通断,轻松实现原有家居设备的智能化改造。 随着智能家居概念的普及,越来越多的人想将自己的家改…...
概述)
【java】EJB(Enterprise Java Bean)概述
EJB概述目录一、什么情况下需要企业Bean需要使用EJB的N个理由二、EJB的基本分类2.1、Enterprise Bean2.2、 Message Driven Bean(MDB)——消息驱动Bean,基于JMS三、定义客户端访问的接口3.1、 远程客户端——客户端与其调用的EJB对象不在同一个JVM进程中3.2、本地客户端——客户…...

Android 10.0 Launcher3桌面禁止左右滑动
1.1概述 在10.0的rom定制化开发中,由于Launcher3有一些功能需要定制,这样的需求也好多的,现在功能需求要求桌面固定在Launcher3的app列表页,不让左右移动,就是禁止左右移动的功能实现,所以需要禁止滑动分析页面滑动部分的功能,然后禁用 2.1Launcher3桌面禁止左右滑动的核…...

日期类的实现
文章目录1. 日期类的具体实现1.查询当前月份的天数2. 构造函数的实现(注意)3.d1d24. d1!d25. d1<d26. d1<d27. d1>d28. d1>d29. 日期天数10.日期天数11.日期-天数12. 日期-天数13. d和 d14. --d 和 d--15.日期日期 返回天数2. 函数的声明——date.h3. 函数的定义—…...

【逆向实战】从算法到驱动:剖析学生机房管理助手7.8的进程隐藏与设备管控机制
1. 学生机房管理助手7.8逆向分析实战 记得第一次在学生机房看到那个熟悉的蓝色图标时,我就知道又要和这个"老朋友"斗智斗勇了。学生机房管理助手7.8版本相比之前的7.5版本,最明显的变化就是进程名随机化算法的调整。用dnSpy反编译脱壳后的mai…...

Java 线程同步:锁机制、CountDownLatch、CyclicBarrier
在现代软件开发中,多线程编程已经成为一项基础技能。无论是为了提升系统吞吐量,还是充分利用多核处理器的计算能力,我们几乎无法回避并发编程。然而,多线程环境带来的不仅仅是性能提升,更是一系列棘手的挑战——当多个…...
)
Altium Designer 19编译原理图,别再被‘has only one pin’和‘off grid’警告搞懵了(附三种实战解法)
Altium Designer 19编译原理图:三大典型警告的深度解析与实战应对 刚接触Altium Designer的新手工程师们,在完成第一个原理图设计后点击"编译"按钮时,往往会遭遇这样的场景:满心期待瞬间被满屏英文警告浇灭。那些"…...

如何快速下载Steam游戏清单:Onekey一键获取Depot Manifest完整指南
如何快速下载Steam游戏清单:Onekey一键获取Depot Manifest完整指南 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey Onekey是一款专为Steam平台设计的Depot Manifest下载器࿰…...

手把手教你定制i.MX8MP的SD卡镜像:从WKS文件到一键烧录
手把手教你定制i.MX8MP的SD卡镜像:从WKS文件到一键烧录 在嵌入式Linux开发中,为NXP i.MX8M Plus处理器定制SD卡镜像是一个常见但颇具挑战性的任务。不同于通用Linux发行版的安装过程,嵌入式系统需要开发者精确控制从启动加载程序到根文件系统…...
)
别再傻傻分不清了!NumPy里np.dot、np.multiply和*的实战区别(附代码避坑)
NumPy乘法操作终极指南:从原理到避坑实战 刚接触NumPy时,最让人头疼的莫过于各种乘法操作的区别。记得我第一次实现神经网络前向传播时,因为错用了*代替np.dot,导致损失函数完全不收敛,调试了整整一个下午才发现问题所…...

如何配置Oracle UTL_FILE目录_CREATE DIRECTORY语法与权限分配
必须由SYS或具CREATE ANY DIRECTORY权限的用户执行CREATE DIRECTORY;目录名是Oracle标识符,OS路径需oracle用户有读写权;UTL_FILE.FOPEN首参须为目录名而非OS路径;须GRANT READ/WRITE给具体用户;PDB中目录需在对应容器…...
)
ESP32开发环境搭建:手把手教你搞定Python依赖报错(ESP-IDF 4.x/5.x通用)
ESP32开发环境搭建:手把手教你搞定Python依赖报错(ESP-IDF 4.x/5.x通用) 第一次接触ESP32开发时,看到终端里突然跳出一堆红色报错信息,那种手足无措的感觉我至今记忆犹新。特别是当错误提示"The following Python…...

SSL/TLS 的演进
在学习SSL和TLS握手过程中,书上(计算机网络:自顶向下的方法)和博客文章,总会有一些出入和矛盾点,让我摸不着头脑,所以我通过 AI 对 SSL 和 TLS 各个版本握手模式进行了总结,希望帮到…...

STM32F103驱动AD9959 DDS信号发生器:从CubeMX引脚配置到四通道频率调节实战
STM32F103驱动AD9959 DDS信号发生器实战指南 在电子设计竞赛和嵌入式系统开发中,DDS(直接数字频率合成)技术因其高精度、快速频率切换和相位可编程等优势,成为信号发生器设计的首选方案。AD9959作为一款四通道DDS芯片,…...