ClickHouse(十三):Clickhouse MergeTree系列表引擎 - ReplicingMergeTree
 进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客
📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
👍点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
目录
1. ReplaceingMergeTree建表语句
2. 示例
2. 1测试去重按照Order by 字段进行去重,而不是按照primary 主键字段进行去重。
2.2 测试不指定[ver]列时,插入相同排序字段的数据,保留最新一条数据。
2.3 测试不同分区中有相同的Order by 字段时,不去重。
以上MergeTree不能对相同主键的数据进行去重,ClickHouse提供了ReplacingMergeTree引擎,可以针对同分区内相同主键的数据进行去重,它能够在合并分区时删除重复的数据。值得注意的是,ReplacingMergeTree只是在一定程度上解决了数据重复问题,由于自动分区合并机制在后台定时执行,所以并不能完全保障数据不重复。ReplacingMergeTree 适用于在后台清除重复的数据以节省空间。
1. ReplaceingMergeTree建表语句
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster](name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],...) ENGINE = ReplacingMergeTree([ver])[PARTITION BY expr][ORDER BY expr][SAMPLE BY expr][SETTINGS name=value, ...]- 以上建表语句的解释如下:
- [ver] :可选参数,指定列的版本,可以是UInt*、Date或者DateTime类型的字段作为版本号。该参数决定了数据去重的方式。当没有指定[ver]时,保留最后插入的数据,也就是最新的数据;如果指定了具体的[ver]列,则保留最大版本数据。
使用ReplacingMergeTree是需要注意以下几点:
- 如何判断数据重复
ReplacingMergeTree在去除重复数据时,是以ORDERBY排序键为基准的,而不是PRIMARY KEY。
- 何时删除重复数据
在执行分区合并时,会触发删除重复数据。optimize的合并操作是在后台执行的,无法预测具体执行时间点,除非是手动执行。
- 不同分区的重复数据不会被去重
ReplacingMergeTree是以分区为单位删除重复数据的。只有在相同的数据分区内重复的数据才可以被删除,而不同数据分区之间的重复数据依然不能被剔除。
- 数据去重的策略是什么
如果没有设置[ver]版本号,则保留同一组重复数据中的最新插入的数据;如果设置了[ver]版本号,则保留同一组重复数据中ver字段取值最大的那一行。
- optimize命令使用
一般在数据量比较大的情况,尽量不要使用该命令。因为在海量数据场景下,执行optimize要消耗大量时间。
2. 示例
2. 1测试去重按照Order by 字段进行去重,而不是按照primary 主键字段进行去重。
#创建表 t_replacing_mt ,使用ReplacingMergeTree引擎node1 :) create table t_replacing_mt(:-] id UInt8,:-] name String,:-] age UInt8,:-] gender String:-] ) engine = ReplacingMergeTree():-] order by (id,age):-] primary key id:-] partition by gender;#向表 t_replacing_mt 中插入以下数据:node1 :) insert into t_replacing_mt values (1,'张三',18,'男'),:-] (2,'李四',19,'女'),:-] (3,'王五',20,'男');#查询表 t_replacing_mt 中的数据:node1 :) select * from t_replacing_mt;┌─id─┬─name─┬─age─┬─gender─┐│ 2 │ 李四 │ 19 │ 女 │└───┴────┴────┴──────┘┌─id─┬─name─┬─age─┬─gender─┐│ 1 │ 张三 │ 18 │ 男 ││ 3 │ 王五 │ 20 │ 男 │└───┴────┴────┴──────┘#向表 t_replacing_mt 中插入id 为1的一行数据node1 :) insert into t_replacing_mt values (1,'张三',10,'男');#查询表 t_replacing_mt 数据:node1 :) select * from t_replacing_mt;┌─id─┬─name─┬─age─┬─gender─┐│ 1 │ 张三 │ 10 │ 男 │└────┴──────┴─────┴────────┘┌─id─┬─name─┬─age─┬─gender─┐│ 1 │ 张三 │ 18 │ 男 ││ 3 │ 王五 │ 20 │ 男 │└────┴──────┴─────┴────────┘┌─id─┬─name─┬─age─┬─gender─┐│ 2 │ 李四 │ 19 │ 女 │└────┴──────┴─────┴────────┘#执行 optimize命令手动合并分区数据node1 :) optimize table t_replacing_mt;#查询表 t_replacing_mt 数据,发现没有按照primary key 去重。node1 :) select * from t_replacing_mt;┌─id─┬─name─┬─age─┬─gender─┐│ 2 │ 李四 │ 19 │ 女 │└────┴──────┴─────┴────────┘┌─id─┬─name─┬─age─┬─gender─┐│ 1 │ 张三 │ 10 │ 男 ││ 1 │ 张三 │ 18 │ 男 ││ 3 │ 王五 │ 20 │ 男 │└────┴──────┴─────┴────────┘#再次向表 t_replacing_mt 插入数据:node1 :) insert into t_replacing_mt values (1,'张三三',18,'男');#查询表 t_replacing_mt 数据node1 :) select * from t_replacing_mt;┌─id─┬─name───┬─age─┬─gender─┐│ 1 │ 张三三 │ 18 │ 男 │└───┴──────┴────┴──────┘┌─id─┬─name─┬─age─┬─gender─┐│ 2 │ 李四 │ 19 │ 女 │└───┴────┴────┴──────┘┌─id─┬─name─┬─age─┬─gender─┐│ 1 │ 张三 │ 10 │ 男 ││ 1 │ 张三 │ 18 │ 男 ││ 3 │ 王五 │ 20 │ 男 │└───┴─────┴───┴──────┘#再次执行 optimize命令手动合并分区数据node1 :) optimize table t_replacing_mt;#查询表 t_replacing_mt 数据node1 :) select * from t_replacing_mt;┌─id─┬─name─┬─age─┬─gender─┐│ 2 │ 李四 │ 19 │ 女 │└───┴────┴────┴──────┘┌─id─┬─name───┬─age─┬─gender─┐│ 1 │ 张三 │ 10 │ 男 ││ 1 │ 张三三 │ 18 │ 男 ││ 3 │ 王五 │ 20 │ 男 │└───┴──────┴────┴─────┘注意:通过以上测试发现ClickHouse ReplacingMergeTree中去除重复数据时,是以ORDERBY排序键为基准的,而不是PRIMARY KEY。2.2 测试不指定[ver]列时,插入相同排序字段的数据,保留最新一条数据。
#删除表 t_replacing_mt 重建,使用ReplacingMergeTree引擎node1 :) create table t_replacing_mt(:-] id UInt8,:-] name String,:-] age UInt8,:-] gender String:-] ) engine = ReplacingMergeTree():-] order by id:-] primary key id:-] partition by gender;#向表 t_replacing_mt 中插入以下数据node1 :) insert into t_replacing_mt values (1,'张三',18,'男'),:-] (2,'李四',19,'女'),:-] (3,'王五',20,'男');#查询表 t_replacing_mt 中的数据node1 :) select * from t_replacing_mt ;┌─id─┬─name─┬─age─┬─gender─┐│ 2 │ 李四 │ 19 │ 女 │└────┴──────┴─────┴────────┘┌─id─┬─name─┬─age─┬─gender─┐│ 1 │ 张三 │ 18 │ 男 ││ 3 │ 王五 │ 20 │ 男 │└────┴──────┴─────┴────────┘#向表 t_replacing_mt 中插入排序字段相同的一行数据node1 :) insert into t_replacing_mt values (1,'张三',10,'男');#查询表 t_replacing_mt 中的数据node1 :) select * from t_replacing_mt;┌─id─┬─name─┬─age─┬─gender─┐│ 1 │ 张三 │ 10 │ 男 │└────┴──────┴─────┴────────┘┌─id─┬─name─┬─age─┬─gender─┐│ 2 │ 李四 │ 19 │ 女 │└────┴──────┴─────┴────────┘┌─id─┬─name─┬─age─┬─gender─┐│ 1 │ 张三 │ 18 │ 男 ││ 3 │ 王五 │ 20 │ 男 │ └────┴──────┴─────┴────────┘#执行 optimize命令手动合并分区数据node1 :) optimize table t_replacing_mt;#查询表 t_replacing_mt 中的数据node1 :) select * from t_replacing_mt;┌─id─┬─name─┬─age─┬─gender─┐│ 2 │ 李四 │ 19 │ 女 │└────┴──────┴─────┴────────┘┌─id─┬─name─┬─age─┬─gender─┐│ 1 │ 张三 │ 10 │ 男 ││ 3 │ 王五 │ 20 │ 男 │└────┴──────┴─────┴────────┘注意:通过以上测试可以发现,ClickHouse ReplacingMergeTree中不指定[ver]列时,当插入排序字段相同的数据时,保留最新一条数据。测试指定[ver]列时,插入相同排序字段的数据,保留当前[ver]列最大值。
#删除表 t_replacing_mt 重新创建,使用ReplacingMergeTree引擎,指定[ver]node1 :) create table t_replacing_mt(:-] id UInt8,:-] name String,:-] age UInt8,:-] gender String:-] ) engine = ReplacingMergeTree(age):-] order by id:-] primary key id:-] partition by gender;#向表 t_replacing_mt 中插入数据:node1 :) insert into t_replacing_mt values (1,'张三',18,'男'),:-] (2,'李四',19,'女'),:-] (3,'王五',20,'男');#查询表 t_replacing_mt中数据:node1 :) select * from t_replacing_mt ;┌─id─┬─name─┬─age─┬─gender─┐│ 1 │ 张三 │ 18 │ 男 ││ 3 │ 王五 │ 20 │ 男 │└────┴──────┴─────┴────────┘┌─id─┬─name─┬─age─┬─gender─┐│ 2 │ 李四 │ 19 │ 女 │└────┴──────┴─────┴────────┘#向表 t_replacing_mt 中插入排序字段相同的一行数据node1 :) insert into t_replacing_mt values (1,'张三',10,'男');#查看表 t_replacing_mt中的数据node1 :) select * from t_replacing_mt;┌─id─┬─name─┬─age─┬─gender─┐│ 1 │ 张三 │ 10 │ 男 │└────┴──────┴─────┴────────┘┌─id─┬─name─┬─age─┬─gender─┐│ 1 │ 张三 │ 18 │ 男 ││ 3 │ 王五 │ 20 │ 男 │└────┴──────┴─────┴────────┘┌─id─┬─name─┬─age─┬─gender─┐│ 2 │ 李四 │ 19 │ 女 │└────┴──────┴─────┴────────┘#对表 t_replacing_mt中的数据执行手动分区合并node1 :) optimize table t_replacing_mt;#查看表 t_replacing_mt中的数据node1 :) select * from t_replacing_mt;┌─id─┬─name─┬─age─┬─gender─┐│ 2 │ 李四 │ 19 │ 女 │└────┴──────┴─────┴────────┘┌─id─┬─name─┬─age─┬─gender─┐│ 1 │ 张三 │ 18 │ 男 ││ 3 │ 王五 │ 20 │ 男 │└────┴──────┴─────┴────────┘注意:通过以上测试可以发现,在ClickHouse中创建ReplacingMergeTree时,如果指定了[ver]列,当存在Order by字段重复时,会保留ver列最大值对应的行。2.3 测试不同分区中有相同的Order by 字段时,不去重。
#删除表 t_replacing_mt ,重新创建node1 :) create table t_replacing_mt(:-] id UInt8,:-] name String,:-] age UInt8,:-] gender String:-] ) engine = ReplacingMergeTree():-] order by id:-] primary key id:-] partition by gender;#向表 t_replacing_mt 中插入以下数据:node1 :) insert into t_replacing_mt values (1,'张三',18,'男'),:-] (2,'李四',19,'女'),:-] (3,'王五',20,'男');#再次向表 t_replacing_mt 中插入以下数据:node1 :) insert into t_replacing_mt values (1,'张三三',10,'女');#对表 t_replacing_mt中的数据执行手动分区合并node1 :) optimize table t_replacing_mt;#查看表中的数据node1 :) select * from t_replacing_mt;┌─id─┬─name───┬─age─┬─gender─┐│ 1 │ 张三三 │ 10 │ 女 ││ 2 │ 李四 │ 19 │ 女 │└───┴──────┴────┴─────┘┌─id─┬─name─┬─age─┬─gender─┐│ 1 │ 张三 │ 18 │ 男 ││ 3 │ 王五 │ 20 │ 男 │└───┴────┴────┴─────┘注意:通过以上测试可以发现,在ClickHouse中创建ReplacingMergeTree时,不同分区中相同的Order by 字段不会去重。👨💻如需博文中的资料请私信博主。
相关文章:
ClickHouse(十三):Clickhouse MergeTree系列表引擎 - ReplicingMergeTree
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 &…...

机器学习笔记之优化算法(十)梯度下降法铺垫:总体介绍
机器学习笔记之优化算法——梯度下降法铺垫:总体介绍 引言回顾:线搜索方法线搜索方法的方向 P k \mathcal P_k Pk线搜索方法的步长 α k \alpha_k αk 梯度下降方法整体介绍 引言 从本节开始,将介绍梯度下降法 ( Gradient Descent,GD ) …...

Selenium 根据元素文本内容定位
使用xpath定位元素时,有时候担心元素位置会变,可以考虑使用文本内容来定位的方式。 例如图中的【股市】按钮,只有按钮文本没变,即使位置变化也可以定位到该元素。 xpath内容样例: # 文本内容完全匹配 //button[text(…...

第17章-Spring AOP经典应用场景
文章目录 一、日志处理二、事务控制三、参数校验四、自定义注解五、AOP 方法失效问题1. ApplicationContext2. AopContext3. 注入自身 六、附录1. 示例代码 AOP 提供了一种面向切面操作的扩展机制,通常这些操作是与业务无关的,在实际应用中,可…...

Leetcode周赛 | 2023-8-6
2023-8-6 题1体会我的代码 题2我的超时代码题目体会我的代码 题3体会我的代码 题1 体会 这道题完全就是唬人,只要想明白了,只要有两个连续的数的和,大于target,那么一定可以,两边一次切一个就好了。 我的代码 题2 我…...

ts中interface自定义结构约束和对类的约束
一、interface自定义结构约束对后端接口返回数据 // interface自定义结构 一般用于较复杂的结构数据类型限制 如后端返回的接口数据// 首字母大写;用分割号隔开 interface Iobj{a:number;b:string } let obj:Iobj {a:1,b:2 }// 复杂类型 模拟后端返回的接口数据 interface Il…...

Oracle单实例升级补丁
目录 1.当前DB环境2.下载补丁包和opatch的升级包3.检查OPatch的版本4.检查补丁是否冲突5.关闭数据库实例,关闭监听6.应用patch7.加载变化的SQL到数据库8.ORACLE升级补丁查询 oracle19.3升级补丁到19.18 1.当前DB环境 [oraclelocalhost ~]$ cat /etc/redhat-releas…...

力扣初级算法(二分查找)
力扣初级算法(二分法): 每日一算法:二分法查找 学习内容: 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 2.二分查找流程&…...

探索未来:直播实时美颜SDK在增强现实(AR)直播中的前景
在AR直播中,观众可以与虚拟元素实时互动,为用户带来更加丰富、沉浸式的体验。那么,直播美颜SDK在AR中有哪些应用呢?下文小编将于大家一同探讨美颜SDK与AR有哪些关联。 一、AR直播与直播实时美颜SDK的结合 增强现实技术在直播中…...

SQL 单行子查询 、多行子查询、单行函数、聚合函数 IN 、ANY 、SOME 、ALL
单行子查询 子查询结果是 一个列一行记录 select a,b,c from table where a >(select avg(xx) from table ) 还支持这种写法,这种比较少见 select a,b,c from table where (a ,b)(select xx,xxx from table where col‘000’ )…...
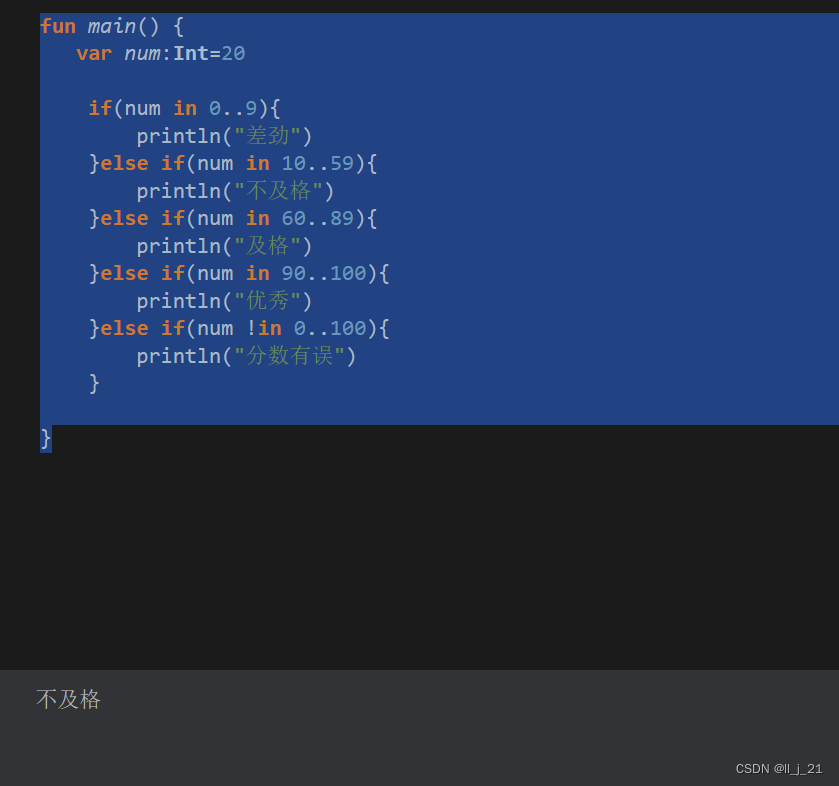
【第一阶段】kotlin的range表达式
range:范围:从哪里到哪里的意思 in:表示在 !in:表示不在 … :表示range表达式 代码示例: fun main() {var num:Int20if(num in 0..9){println("差劲")}else if(num in 10..59){println("不及格")}else if(num in 60..89…...
)
网络防御(5)
一、结合以下问题对当天内容进行总结 1. 什么是恶意软件? 2. 恶意软件有哪些特征? 3. 恶意软件的可分为那几类? 4. 恶意软件的免杀技术有哪些? 5. 反病毒技术有哪些? 6. 反病毒网关的工作原理是什么? 7. 反…...

gradle 命令行单元测试执行问题
文章目录 问题:命令行 执行失败最终解决方案(1)ADB命令(2)Java 环境配置 问题:命令行 执行失败 命令行 执行测试命令 无法使用(之前还能用的。没有任何改动,又不能用了) …...

剑指Offer12.矩阵中的路径 C++
1、题目描述 给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平…...

金鸣识别将无表格线的图片转为excel的几个常用方案
我们知道,金鸣识别要将横竖线齐全的表格图片转为excel非常简单,但要是表格线不齐全甚至没有表格线的图片呢?这就没那么容易了,在识别这类图片时,我们一般会使用以下的一种或多种方法进行处理: 1. 基于布局…...

刚刚更新win11,记事本消失怎么处理?你需要注意些什么?
记录window11的bug hello,我是小索奇 昨天索奇从window10更新到了window11,由于版本不兼容卸载了虚拟机,这是第一个令脑壳大的,算了,还是更新吧,了解了解win11的生态,后期重新装虚拟机 第一个可…...

【QT】 QTabWidgetQTabBar控件样式设计(QSS)
很高兴在雪易的CSDN遇见你 ,给你糖糖 欢迎大家加入雪易社区-CSDN社区云 前言 本文分享QT控件QTabWidget&QTabBar的样式设计,介绍两者可以自定义的内容,以及如何定义,希望对各位小伙伴有所帮助! 感谢各位小伙伴…...

【个人记录】CentOS7 编译安装最新版本Git
说明 使用yum install git安装的git版本是1.8,并不是最新版本,使用gitlab-runner托管时候会拉项目失败,这里使用编译源码方式安装最新版本的git。 基础环境安装 echo "nameserver 8.8.8.8" >> /etc/resolv.conf curl -o /…...

【Linux】计算机网络的背景和协议分层
文章目录 网络发展协议何为协议网络协议协议分层OSI七层模型TCP/IP五层模型(四层) 基本通信流程mac地址和ip地址网络通信本质 网络发展 从一开始计算机作为一台台单机使用,到现在网络飞速发展,从局域网Lan建立起局域网࿰…...

代理模式:静态代理+JDK/CGLIB 动态代理
文章目录 1. 代理模式2. 静态代理3. 动态代理3.1. JDK 动态代理机制3.1.1. 介绍 3.1.2. JDK 动态代理类使用步骤3.1.3. 代码示例3.2. CGLIB 动态代理机制3.2.1. 介绍3.2.2. CGLIB 动态代理类使用步骤3.2.3. 代码示例 3.3. JDK 动态代理和 CGLIB 动态代理对比 4. 静态代理和动态…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

C++使用 new 来创建动态数组
问题: 不能使用变量定义数组大小 原因: 这是因为数组在内存中是连续存储的,编译器需要在编译阶段就确定数组的大小,以便正确地分配内存空间。如果允许使用变量来定义数组的大小,那么编译器就无法在编译时确定数组的大…...