强化学习基础概念
强化学习入门
入门学习第一周:基础概念
经验回放:
将sss,agent当前步的action环与境的交互rrr以及下一步的状态st+1s_{t+1}st+1组成的四元组[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wxhVd0dn-1676710992983)(null)]
组成序列,需要人为指定数组的大小(记作 b)。数组中只保留最近 b 条数据;当数组存满之后,删除掉最旧的数据。数组的大小 b 是个需要调的超参数,会影响训练的结果。通常设置 b 为
10^5 ∼ 10^6。
- 经验回放的优点
经验回放的一个好处在于打破序列的相关性。训练 DQN 的时候,每次我们用一个四元组对 DQN 的参数做一次更新。我们希望相邻两次使用的四元组是独立的。然而当智能体收集经验的时候,相邻两个四元组 有很强的相关性。依次使用这些强关联的四元组训练 DQN,效果往往会很差。经验回放每次从数组里随机抽取一个四元组,用来对 DQN 参数做一次更新。这样随机抽到的四元组都是独立的,消除了相关性。
经验回放的另一个好处是重复利用收集到的经验,而不是用一次就丢弃,这样可以用更少的样本数量达到同样的表现。 - 经验回放的局限性
经验回放不适用于同策略。SARSA等学习算法要求当前执行的策略必须为目标策略(同策略),而经验回放只适用于异策略,因为其用到的都是“过时”的策略函数执行的结果。
优先经验回放
tldr:给四元组序列加权,让不同样本被抽中的概率不一样。如,自动驾驶中绝大部分数据(四元组)都是在正常行驶状态下进行,而这些数据价值不大。出意外的时候的数据很宝贵,但占比极少。这样正常抽样训练的模型会很难好用。
- 如何自动判断样本权重
TD误差越大,将该样本权重设置越高。
解释:TD误差越大,说明该网络的判断与真实估计的差越大,说明网络对当前样本的判断越不好,需要加强对此类样本的学习。
高估问题及解决方法
- 为什么会出现高估
-
自举的高估
tldr:TD误差中等号左右都是Q函数对自己的估计,若等号右端已经高估,那么等号左端也会高估,造成误差的传播,让更多的价值被高估。 -
最大化导致的高估
-
如果DQN是完全恒等于真实Q函数的,那么没有任何误差,然而真实情况不可能如此。只要其有误差,即使是无偏的,那么依然存在高估。因为往一个随机变量里加入任意量均值为0的随机噪声,那么新序列的最大值的期望,一定是大于等于原序列的。
- 高估的危害
废话,高估导致智能体导致估计不准确,作出错误判断 - 高估的解决办法
想要避免 DQN 的高估,要么切断自举,要么避免最大化造成高估︒注意,高估并不是 DQN 自身的属性,高估纯粹是算法造成的。想要避免高估,就要用更好的算法替代原始的 Q 学习算法。(下文详述) - 目标网络
想要切断自举,可以用另一个神经网络计算 TD 目标,而不是用 DQN 自己计算 TD 目标。另一个神经网络被称作目标网络(target network)。
它的神经网络结构与 DQN 完全相同,只有其参数 w−不同于ww^- 不同于 ww−不同于w
我的总结:用另一个目标网络去预测下一步的最优价值,得到目标值;原网络的参数更新方式不变,新网络的更新是移动平均加权的形式。这种方法实际上只能减缓最大化的高估趋势,并不是根除了高估。且该方法对自举的高估没有作用。
- 双Q学习
与上文的目标网络Q学习的差异在于,双Q将网络进行拆分,用DQN选择action,用目标网络来求值
这样做能够减小高估,因为Q函数对于一个确定的a的值,显然是小于等于最优价值函数的。(体会:有点拆东补西,中和的意思,并不是把根儿拔了。)
噪声网络
将原网络中的每个参数w改写为w=u+a∗bw = u+a*bw=u+a∗b
uuu为均值,aaa为正态分布随机变量,bbb为方差。
u和bu和bu和b为可学习参数,a从正态分布抽样,每一步学习需要重新抽样。
噪声网络的好处:
不仅有利于探索,还能增强鲁棒性。
噪声网络自带有随机性,参数的随机性可能使下一步action的输出具有随机性。因此使用了噪声网络即可无需使用其他策略来保证探索的随机性。
策略梯度网络
- 更新策略
- 依赖观察到的s
- 从策略网络抽样得到一个a
- 然后计算出随机梯度,更新策略网络的参数
此处存在的问题是Q函数我们无法知道。因此需要想办法进行估计。
- REINFORCE
tldr:完成一局游戏,将得到的奖励utu_tut作为Q值的蒙特卡洛估计。 - actor-critic
policy网络:输入是状态sss,输出是一个action的概率分布
value_network:输入(s,a),评价当前动作的好坏
训练步骤:- 观测状态sts_tst
- 从随机初始化的策略网络sample出ata_tat
- agent执行ata_tat,观察st+1s_{t+1}st+1和rrr
- 用TD算法更新value_network的参数w
- 用策略梯度更新policy net
带基线的策略梯度算法
tldr:策略梯度公式中用到的策略梯度网络求导乘上实际奖励(对状态价值函数的蒙特卡洛模拟)utu_tut作为策略梯度。一个改进方法为在该实际奖励上减去一个Vπ(s)V_\pi(s)Vπ(s),这样能使梯度更稳定,当然,也引入了一个状态价值网络来作为Vπ(s)V_\pi(s)Vπ(s)
不完全观测问题
- 例子:英雄联盟;绝地求生等
- 基本思路:对于不完全观测的强化学习问题,应当记忆过去的观测,用所有已知的信息做决策。
这正是人类解决不完全观测问题的方式。(即使是完全观测问题,记忆前面几步的状态也是有意义的,如alphago的input) - 记录过去n步的观测,n可能是不定长的,因此RNN和transformer是处理此类问题的好方法,其满足接受不定长的输入而输出的向量维度不变。
alphaGo
基本设定:
- 游戏结束之前,所有r均为0;
- 游戏结束时,获胜:r=+1;失败:r=-1
- behavior cloning:模仿学习(监督学习的一类)
棋盘状态的输入是一个三维立体tensor;输出是19*19的矩阵;
在一次训练中,人类玩家在该状态下走的比如是第256个格子,那么target就是one-hot向量(第256个元素为1其余为0),策略网络的输出是预测值。二者做损失。
一个非常传统的多分类任务。- 体会:该策略应该是只能接近人类水平。论文中说经过该算法,策略算法已经能够击败业余水平玩家。bc算法缺陷是对训练数据中出现较少的s,或者没出现过的s;另外只要有一次s未出现过,那么此后的状态将均没见过,因此错误会累加,此后的策略网络基本都在随机游走,因为这些状态它都没见过;作为人类选手,只需要走出一些非常奇怪的状态,便很大概率能够找到该策略网络没见过的局面从而将其击败。且考虑到围棋的复杂度,这个状态容易撞出来。
- 强化学习:
- 策略网络从behavior cloning的SL网络权重初始化,对手网络最开始也是如此;
- 此后,策略网络使用策略梯度进行更新,而每轮使用的对手网络是随机从历史策略网络中选取一个。这个trick能防止策略网络在当前策略上过拟合。
- alphaGo使用的蒙特卡洛树搜索
-
价值网络能衡量状态好坏;人类棋手下棋时,会预估未来几步的走势
-
选择:使用PUCT算法不断往下搜索节点;具体的,以下为每个节点的计算方式:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t5XFXzXV-1676710993087)(null)] -
用策略函数选取几个好的动作;让策略网络按照选取的动作自我博弈到游戏结束,看这个动作是赢还是输;
-
score(a)=(v+r)/2 其中v是动作做完后价值网络的打分;r是游戏结束的reward;
-
重复很多次,能得到每个动作的平均分值;选择分数最高的a。
-
- 体会:
- alphaGo相当于预先看完了所有的步数;
- 机器的自我博弈及其客观,而人类的自我对弈很难无偏
- 好奇alphaGo/Zero不使用蒙特卡洛树搜索,单纯使用策略网络的对弈水平。蒙特卡洛这招有点儿玩赖,靠着远超于人类的算力当场进行模拟,如果对手(比如柯洁)也每走一步都跟顶级高手博弈几千把、模拟几个月再出手,ai还能获胜吗?
相关文章:

强化学习基础概念
强化学习入门 入门学习第一周:基础概念 经验回放: 将sss,agent当前步的action环与境的交互rrr以及下一步的状态st1s_{t1}st1组成的四元组[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wxhVd0dn-1676710992983)(null)] 组…...
Redis学习【9】之Redis RDB持久化
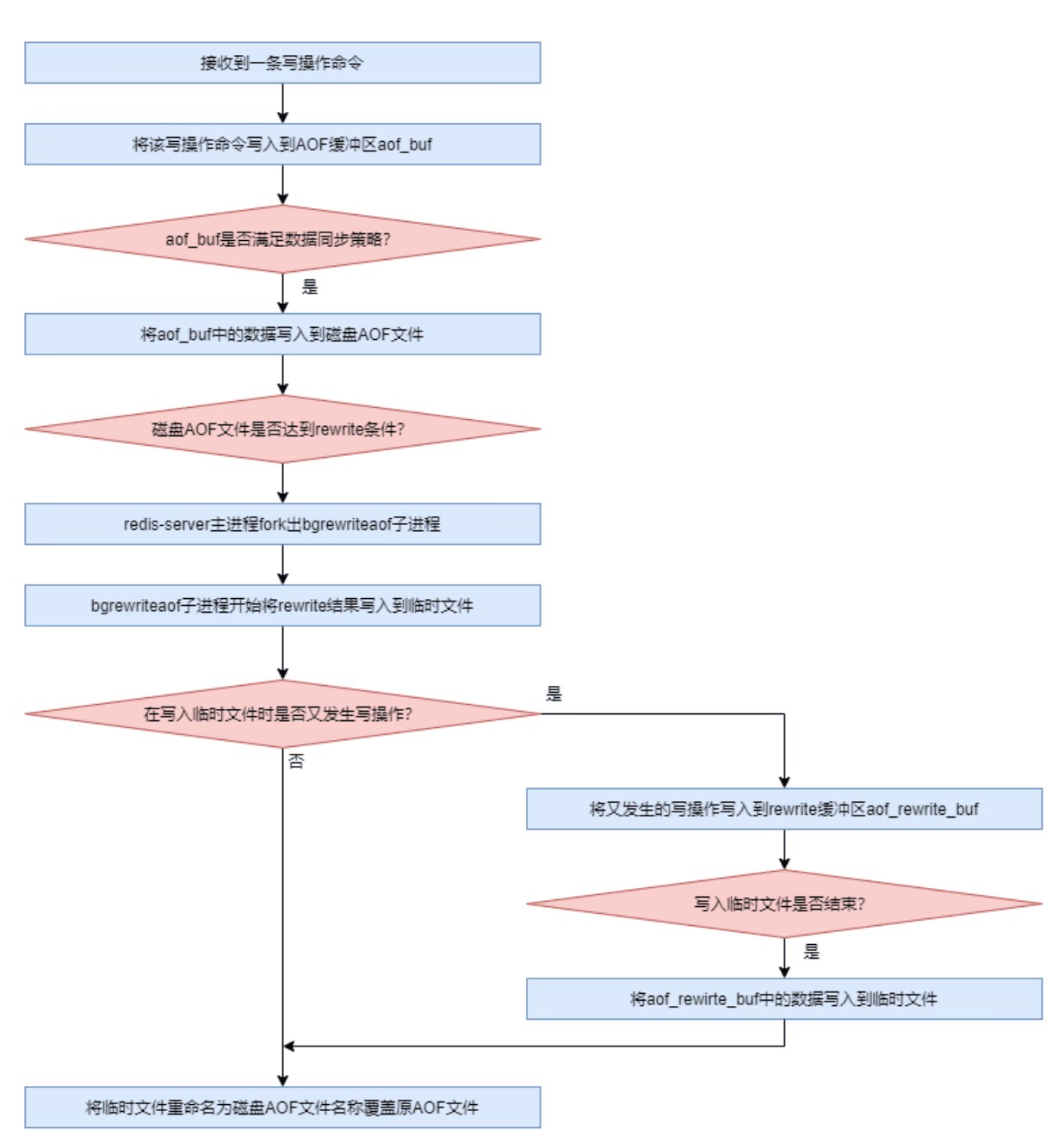
文章目录一 AOF(Append Only File) 持久化二 AOF 基础配置2.1 AOF的开启2.2 文件名配置2.3 混合式持久化开启2.4 AOF 文件目录配置三 AOF 文件格式3.1 Redis 协议3.2 查看 AOF 文件3.3 清单文件3.4 Rewrite 机制3.4.1 rewrite简介3.4.2 rewrite 计算策略3.4.3 手动开启 rewrite…...

分析 vant4 源码,学会用 vue3 + ts 开发毫秒级渲染的倒计时组件,真是妙啊
2022年11月23日首发于掘金,现在同步到公众号。11. 前言大家好,我是若川。推荐点右上方蓝字若川视野把我的公众号设为星标。我倾力持续组织了一年多源码共读,感兴趣的可以加我微信 lxchuan12 参与。另外,想学源码,极力推…...
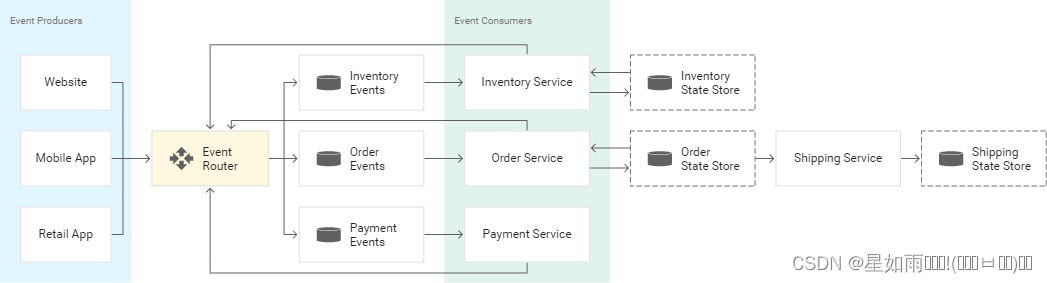
事件驱动型架构
事件驱动型架构是一种软件设计模式,其中微服务会对状态变化(称为“事件”)作出反应。事件可以携带状态(例如商品价格或收货地址),或者事件也可以是标识符(例如,订单送达或发货通知&a…...
)
20222023华为OD机试 - 不含 101 的数(Python)
不含 101 的数 题目 小明在学习二进制时,发现了一类不含 101 的数, 也就是将数字用二进制表示,不能出现 101 。 现在给定一个正整数区间 [l,r],请问这个区间内包含了多少个不含 101 的数? 输入 输入一行,包含两个正整数 l l l, r r r...

杭州电子科技大学2023年MBA招生考试成绩查询和复查申请的通知
根据往年的情况,2023杭州电子大学MBA考试初试成绩可能将于2月21日公布,最早于20号出来,为了广大考生可以及时查询到自己的分数,杭州达立易考教育为大家汇总了信息。根据教育部和浙江省教育考试院关于硕士研究生招生考试工作的统一…...
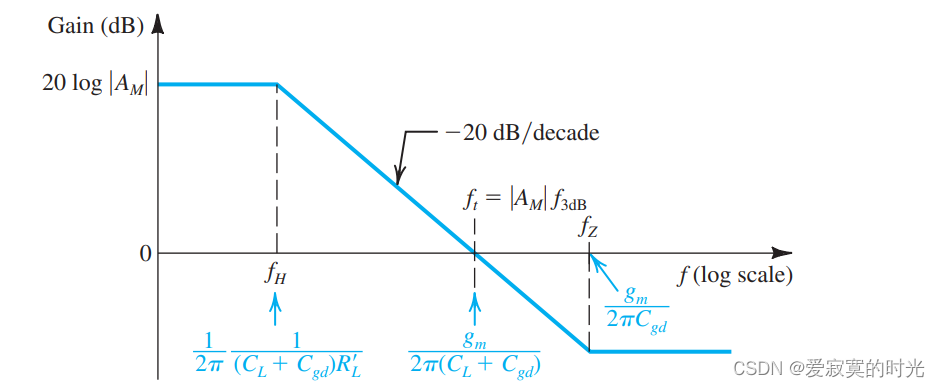
电子技术——CS和CE放大器的高频响应
电子技术——CS和CE放大器的高频响应 在绘制出MOS和BJT的高频响应模型之后,我们对MOS和BJT的高频响应有了进一步的认识。现在我们想知道的是在高频响应中 fHf_HfH 的关系。 高频响应分析对电容耦合还是直接耦合都是适用的,因为在电容耦合中高频模式下…...

2023年数学建模美赛D题(Prioritizing the UN Sustainability Goals):SDGs 优先事项的选择
正在写,不断更新,别着急。。。 4. SDGs 优先事项的选择 4.1 基于SDG密度分布图选择优先事项 虽然每个可持续发展目标的接近度矩阵和中心性度量的结果是通用的,并创建了基本的可持续发展目标网络,但由于各国在网络的不同部分取得…...

springboot实现项目启动前的一些操作
在服务启动时,做一些操作,比如加载配置,初始化数据,请求其他服务的接口等。 有三种方法: 第一种是实现CommandLineRunner接口 第二种是实现ApplicationRunner接口 第三种是使用注解:PostConstruct 三者使用…...

详解JavaScript的形参,实参以及传参
文章目录 前言一、参数是什么?二、形参和实参 1.形参 2.实参三、传参 1.参数传递的对应关系2.两个传参的例子 总结前言 编程初学者在接触JavaScript这门语言时,很难搞懂里面的逻辑,这就会导致入门慢,入门难。这种难度一般…...

Vue中的diff算法
diff算法介绍 diff算法是一种高效对比算法。diff算法在组件更新即响应式数据监控到数据的改变,重新生成虚拟DOM树的时候调用,然后通过diff算法计算出前后虚拟dom树的差异点,更新dom时只更新变化的部分。 直接比较和修改两个数的复杂度为什么…...

【面试题】前端春招第二面
不容错过的一些面试题小细节,话不多说,直接看题~大厂面试题分享 面试题库后端面试题库 (面试必备) 推荐:★★★★★地址:前端面试题库HTML/CSS/Javascript/ES篇(1)标准盒模型和怪异盒…...
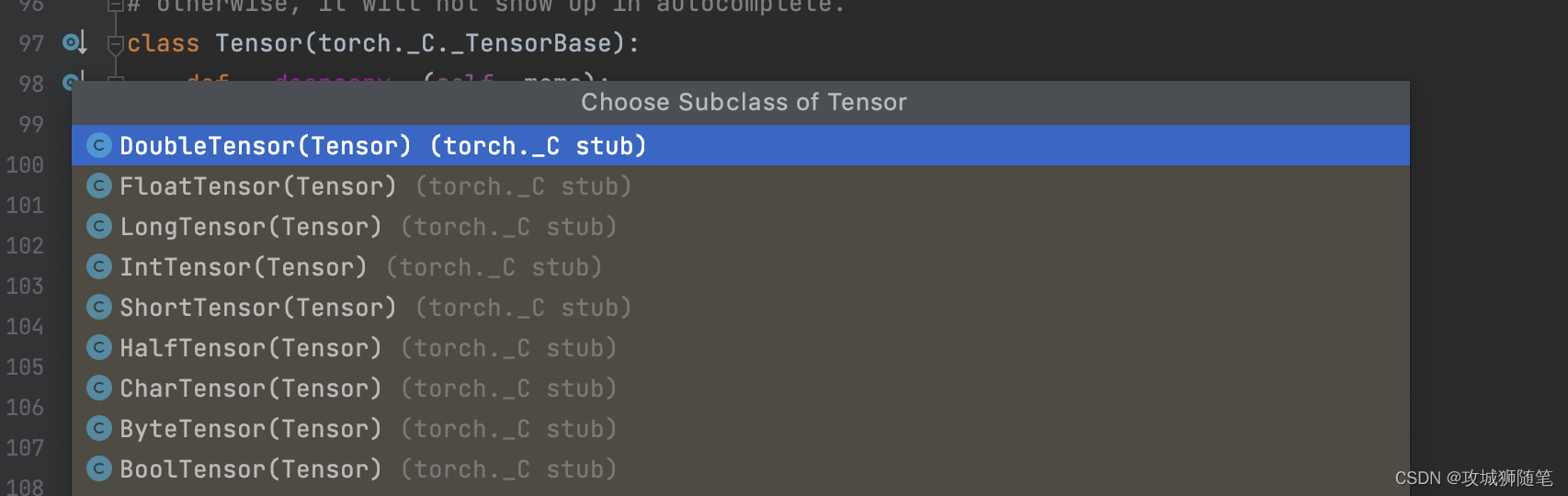
Pytorch 基础之张量数据类型
学习之前:先了解 Tensor(张量) 官方文档的解释是: 张量如同数组和矩阵一样, 是一种特殊的数据结构。在PyTorch中, 神经网络的输入、输出以及网络的参数等数据, 都是使用张量来进行描述。 说白了就是一种数据结构 基本数据类型…...
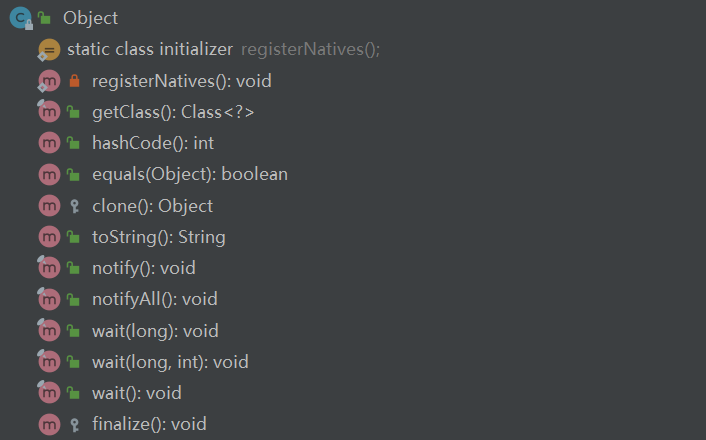
Java 基础面试题——常见类
目录1.String 为什么是不可变的?2.字符串拼接用“” 和 StringBuilder 有什么区别?3.String、StringBuffer 和 StringBuilder 的区别是什么?4.String 中的 equals() 和 Object 中的 equals() 有何区别?5.Object 类有哪些常用的方法?6.如何获…...

Windows 系统从零配置 Python 环境,安装CUDA、CUDNN、PyTorch 详细教程
文章目录1 配置 python 环境1.1 安装 Anaconda1.2 检查环境安装成功1.3 创建虚拟环境1.4 进入/退出 刚刚创建的环境1.5 其它操作1.5.1 查看电脑上所有已创建的环境1.5.2 删除已创建的环境2 安装 CUDA 和 CUDNN2.1 查看自己电脑支持的 CUDA 版本2.2 安装 CUDA2.3 安装 CUDNN2.4 …...
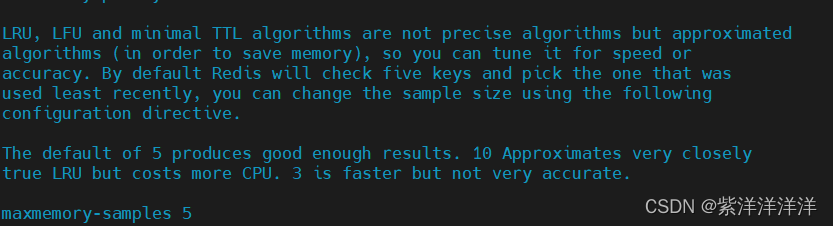
[REDIS]redis的一些配置文件
修改配置文件 vim /etc/redis/redis.conf目录 protected-mode tcp-backlog timeout tcp-keepalive daemonize pidfile loglevel databases 设置密码 maxclients maxmemory maxmemory-policy maxmemory-samples 默认情况下 bind127.0.0.1 只能接受本机的访问请求。在不写的情况…...

Java反序列化漏洞——CommonsCollections4.0版本—CC2、CC4
一、概述4.0版本的CommonsCollections对之前的版本做了一定的更改,那么之前的CC链反序列化再4版本中是否可用呢。实际上是可用的,比如CC6的链,引入的时候因为⽼的Gadget中依赖的包名都是org.apache.commons.collections ,⽽新的包…...

下载网上压缩包(包含多行json)并将其转换为字典的解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理…...

【郭东白架构课 模块一:生存法则】11|法则五:架构师为什么要关注技术体系的外部适应性?
你好, 我是郭东白。 前四条法则分别讲了目标、资源、人性和技术周期,这些都与架构活动的外部环境有关。那么今天我们来讲讲在架构活动内部,也就是在架构师可控的范围内,应该遵守哪些法则。今天这节课,我们就先从技术体…...

Mindspore安装
本文用于记录搭建昇思MindSpore开发及使用环境的过程,并通过MindSpore的API快速实现了一个简单的深度学习模型。 什么是MindSpore? 昇思MindSpore是一个全场景深度学习框架,旨在实现易开发、高效执行、全场景覆盖三大目标。 安装步骤 鉴于笔者手头硬…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

线程与协程
1. 线程与协程 1.1. “函数调用级别”的切换、上下文切换 1. 函数调用级别的切换 “函数调用级别的切换”是指:像函数调用/返回一样轻量地完成任务切换。 举例说明: 当你在程序中写一个函数调用: funcA() 然后 funcA 执行完后返回&…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...