【WordPress】如何在WordPress中实现真·页面路由
这篇文章也可以在我的博客中查看
页面路由
是什么
页面路由是指从url顺着网线砍到网站内容的途径,说人话就是地址与页面的映射。
就像真实世界的地址一样,我要找你,必须知道你的地址。
在网站中,通过地址找内容的机制,就称为页面路由(Route)
常见的路由有两种方式:
- 页面地址映射到文件夹层级地址
- 页面地址映射到数据结构
WordPress的路由
WordPress采用的是第二种。
在WordPress里,几乎所有的页面访问,其实都是在访问/index.php
而之所以能够输出不同的结果,是依靠读取查询字符串中的数据,再在template_includes中做判断以加载不同的模板文件。
打个比方:www.mysite.com/page/2/访问主页的第二页
事实上等价于访问www.mysite.com/index.php?paged=2
它唯一的好处就是更好看了,有利于SEO
再比如:www.mysite.com/0000/00/00/hello-world/访问第一篇文章
事实上你拿www.mysite.com/index.php?p=1也可以跳转到同样的地址
所以通过添加查询字符串标记,能够检测并跳转到不同的模板文件。
这是WordPress内置的做法。
为什么?
说了半天,为什么需要实现页面路由?
WordPress提供的路由规则不香吗?
因为WordPress只提供了默认的路由路径,而没有直接做法可以往里面添加自己的路由。
比如,我想在/game路径下添加一个很Cool的html小游戏,你会发现做不到。
WordPress中一切皆是文章,你需要展示一个东西,那它必须先成为一篇文章。
你当然也可以创建一个名为game的页面(page),然后添加自定义模板
但这一步本身有必要存在吗?
有些东西,它本身就不好被描述成文章,比如:小游戏,一些功能页面……
因此虽然WordPress不提供,但我们仍然需要自定义的页面路由
我们需要漏油!!!
我们需要漏油!!!
我们需要漏油!!!
本文内容
当然,我们也可以使用查询字符串的形式添加新的路由
可以,但不优雅
因为这始终是污染查询字符串的结构了:
- 虽然概率极低,但我还是并不希望丑陋的
?the_long_long_query_var=1会被偶然发现 - 又或者是
?xid=1与其它插件注册的查询字符串冲突
因此本文:
- 实现真·页面路由
- 不需要创建任何page或者post文件,通过url直接定位到php模板文件
- 相当于扩充WordPress的主题层级模板
- 不使用查询字符串作为标志
- 不破坏WordPress的生态,任何function, hook该生效的还是生效
实现路由
old-school做法
WordPress已经有20年历史了,byd这种做法一直是实现页面路由的主流做法
但不管怎么说,这种查询字符串标记的做法算是鼻祖了
简单来说就是:
- 使用
add_rewrite_rule添加重写规则,使用一个标志查询字符串kbp_book_finder=1作为访问了www.mysite.com/bookfinder/的标志
function bookfinder_rewrite()
{add_rewrite_rule('^bookfinder/?$', 'index.php?kbp_book_finder=1', 'top');
}
add_action('init', 'bookfinder_rewrite');function bookfinder_query_vars($vars)
{$vars[] = 'kbp_book_finder';return $vars;
}
add_filter('query_vars', 'bookfinder_query_vars');
- 在
template_includehook中,查找该标志,然后跳转到php模板文件
function bookfinder_template($template)
{if (!is_404() && get_query_var('kbp_book_finder'))return locate_template('/path/to/your/file/book-finder.php');return $template;
}
add_filter('template_include', 'bookfinder_template');
本文做法
由于不爽这个查询字符串很久了,所以萌生了新的想法:
既然查询字符串的存在意义只是为了标志,那为什么不用其它变量作为标志呢?
经过反复尝试,发现是可以的,至少现在用着没出问题
出问题了再删文章()
分析问题
首先一个路由最重要的是什么?
- 路径
- 行为
- 结果
没错,所以我们需要关注的是:
访问什么地址,服务器做出什么响应,然后跳转/加载到哪个页面
这几个过程分散在WordPress生命周期的不同时期,
为了实现路由的目标,我们需要程序知道目前所加载的到底是什么页面
因此为每个路径加入一个专门标志也是必须的
具体实现
位置标记
首先解决最迫切的“我在哪”问题
WordPress没有为自定义页面实现路径标记信息或系统,因此我们需要手动记录
查询字符串就是一个做法,但其实我们完全可以不用它
我们直接定义一个变量,记录目前的路由路径,并配套若干访问相关的函数:
名称空间不好存变量,我习惯使用静态类充当单例
class Router
{protected static ?string $activePath = null;protected static function setActivePath($path){Router::$activePath = $path;}protected static function atPath($path): bool{return !is_404() && Router::$activePath === $path;}protected static function atAnyPath(): bool{return Router::$activePath !== null;}
}
注册路由
接下来实现最关键的是实现registerRoute方法,负责:
- 定义路径
- 路径相关的重定向
- 如果没重定向,加载哪个php文件
对于每个注册的路由,都需要各自定义这些功能函数
这些函数都是上下文(注册的路径)有关的,因此此时闭包很有用!
public static function registerRoute(string $routePath, string $template, ?callable $redirect = null)
{
}
接下来逐个分析需要的几个闭包函数
- 老朋友,
add_rewrite_rule
1.需要添加重写规则才能够访问,否则直接404。因此我们直接摆烂跳转到不附加任何参数的index.php
2.注意优先级要设置为'top',否则大概率不生效
3.更改重写规则需要刷新永久链接
add_action('init', fn () => add_rewrite_rule($routePath, 'index.php', 'top'));
- 匹配url并设置标记变量
为了在生命周期中尽快生效,使用最早能够获得url的钩子parse_request:
add_action('parse_request', function (wp) use (routePath) {if (preg_match("<routePath>", wp->request))Router::setActivePath(routePath);
});
- 检测标记并选择性进行页面加载
add_filter('template_include', fn ($tpl) => Router::atPath($routePath) ? $template : $tpl);
- 加入重定向逻辑回调函数
有时候我们希望加入与页面绑定的重定向逻辑,虽然在任何位置都可以添加重定向逻辑,但既然是页面相关的逻辑,还是提供一个专门的入口:
注意:重定向后需要退出本次执行,但该函数内不得获知能否成功重定向,因此这需要在传入的回调函数中处理(见后文示例)
if ($redirect)add_action('template_redirect', fn () => Router::atPath($routePath) && $redirect());
路由参数
有时候会有从url读取参数值的需求
借鉴WordPress REST API的做法,我们可以用正则表达式的分组匹配实现参数提取
在上步parse_requesthook中,增加接收匹配结果的$matches变量,并存储到Router中:
我增加了
filterMatches函数,只保留命名分组
class Router
{public static ?array $data = null;public static function registerRoute(string $routePath, string $template, ?callable $redirect = null){add_action('parse_request', function ($wp) use ($routePath) {if (preg_match("<$routePath>", $wp->request, $matches)) {Router::setActivePath($routePath);Router::$data = Router::filterMatches($matches);}});}protected static function filterMatches($matches){return array_filter($matches, fn ($key) => is_string($key), ARRAY_FILTER_USE_KEY);}
}
此时registerRoute所有代码合在一起,是这个样子的:
public static function registerRoute(string $routePath, string $template, ?callable $redirect = null)
{if (!$routePath) return;add_action('init', fn () => add_rewrite_rule($routePath, 'index.php', 'top'));add_action('parse_request', function ($wp) use ($routePath) {if (preg_match("<$routePath>", $wp->request, $matches)) {Router::setActivePath($routePath);Router::$data = Router::filterMatches($matches);}});add_filter('template_include', fn ($tpl) => Router::atPath($routePath) ? $template : $tpl);if ($redirect)add_action('template_redirect', fn () => Router::atPath($routePath) && $redirect());
}
使用示意
重要提示: 更改重写规则后需要更新页面规则:
在设置菜单中找到永久链接,点击保存即可刷新
此时我们已经完成了路由的核心逻辑,可以比较方便地使用:
// https://my.site/bookfinder/
Router::registerRoute('^bookfinder/?$',locate_template('/path/to/file1.php')
);
// https://my.site/user/
Router::registerRoute('^user/?$',locate_template('/path/to/file2.php'),fn () => !is_user_logged_in() && wp_redirect(get_user_login_url()) and exit
);
// https://my.site/date/1970/01/01/
Router::registerRoute('^date/(?P<year>\d{4})/(?P<month>\d{2})/(?P<day>\d{2})/?$',locate_template('/path/to/file3.php'),
);
对于参数,可以在输出页面时按以下方式获取:
名称就是路由中的正则命名分组
print_r(Router::$data['year']);
print_r(Router::$data['month']);
print_r(Router::$data['day']);
问题修复
至此已经实现了路由功能,但(据我所测试)仍存在几个小问题
末尾斜杠
按上面的做法,url无法按照Permalink规则跳转到斜杠或非斜杠版本
无论Permalink设置,都是默认跳转到斜杠版本
为什么?
原因在于add_rewrite_rule跳转到不带参数的index.php,最后会被WordPress识别为网站首页($wp_query->is_home = true)
根据RFC 7230,http请求的path必须以/开头,即使它的内容为空。(相关资料)
因此对于形如https://mysite.com/的站点主页而言,最后的斜杠是必须的
虽然目前浏览器都会在访问时自动给你补/
但WordPress很严谨地遵守了这一规定,将is_home(视为主页)的路径全部补上了斜杠!
这是他们redirect_canonical的源码:
} elseif ( is_front_page() ) {$redirect['path'] = trailingslashit( $redirect['path'] );
}
is_front_page()间接检测了is_home()
然而并不是所有的主页都以空path结束,也不是所有is_home的情况它就真的是home
比如我们现在的情况,我们需要加入一个不属于任何文章的页面,我们只能把它归于is_home
解决办法
找一个$wp_query->is_home被设置完后的钩子,尽快将它设置为false
WordPress使用$wp_query用作主查询,翻看源码后,发现查询后会立马调用handle_404()
因此我们可以利用这个过程的pre_handle_404hook,将它设置为false:
add_filter('pre_handle_404', function ($suppress, $wp_query) use ($routePath) {if (Router::atPath($routePath))$wp_query->init_query_flags();return $suppress;
}, 10, 2);
我们使用了init_query_flags(),将所有conditional tags设置为false。
这是合理的,因为它本就不属于内置的任何状态
事实上受影响的只有is_home(),其它本来就是false
跳过主查询
既然自定义路由页面不存在任何post/page,我们其实没必要进行主查询
这个操作可以帮助减少5次左右查询次数
但我们希望尽可能保持WordPress原有的功能和hook,只跳过主查询
也就是跳过查询过程文档所述的4.3步骤:
4.3 Convert the query specification into a MySQL database query, and run the database query to get the list of posts, in function WP_Query->get_posts(). Save the posts in the $wp_query object to be used in the WordPress Loop.
抑制主查询
因此我们可以选择查询执行前最近的一个hook,将查询语句修改成无效:
add_filter('posts_request', fn ($request, $query) => Router::atPath($routePath) && $query->is_main_query() ? false : $request, 10, 2);
防止返回404
我们之前不会返回404,主要是因为有两个条件:
- 主查询有返回结果
$wp_query->is_home === true
然而经过我们前面的一堆优化,两个条件都不再满足
因此WordPress会在handle_404()直接返回404 not found!
那我们抑制它的作用就好了
同样在pre_handle_404hook。修改原有的代码,返回true,表示抑制404处理:
add_filter('pre_handle_404', function ($suppress, $wp_query) use ($routePath) {if (!Router::atPath($routePath))return $suppress;$wp_query->init_query_flags();return true;
}, 10, 2);
全场最佳:
pre_handle_404
不起眼、看似毫不相关的hook,帮我们解决了一万个问题
条件性回调
上面的做法中,我们为每个可能的路由路径都加入了hook,并在每个回调函数中先检测自身是否为活跃路由,如果时,再执行操作。
但其实没有必要为每个路径都加入hook,因为一次访问只有1个活跃路径
因此在设置活跃路径时,它必然就是本次的路由路径,我们只为它加入hook就可以了。
不过需要注意,不能重复设置活跃路由,否则就乱套了(一般也不会出现设置多次的情况吧?)
代码就留到最后了
最终版本
经历了九九八十一难,终于修成了正果
来看看最后版本的Router吧:
class Router
{/*** 当前活跃的路由路径*/protected static ?string $activePath = null;/*** 活跃路由的参数*/public static ?array $data = null;/*** 注册一个路由路径* @param string $routePath 路径,正则表达式,站点名后的路径部分* @param string $template 加载的php文件* @param callable $redirect 可选的重定向逻辑,在该路由生效时在template_redirect触发*/public static function registerRoute(string $routePath, string $template, ?callable $redirect = null){if (!$routePath)return;/*** 记录到重写规则*/add_action('init', fn () => add_rewrite_rule($routePath, 'index.php', 'top'));/*** 匹配url并设置标记变量,使用最早能够获得url的钩子:*/add_action('parse_request', function ($wp) use ($routePath, $template, $redirect) {if (preg_match("<$routePath>", $wp->request, $matches)) {Router::setActiveRoute($routePath, $template, $redirect);Router::$data = Router::filterMatches($matches);}});}public static function init(){// 如果是初次:刷新add_action('after_switch_theme', 'flush_rewrite_rules');}protected static function setActiveRoute(string $routePath, string $template, ?callable $redirect = null){Router::$activePath = $routePath;/*** 更改页面模板*/add_filter('template_include', fn () => $template);/*** 加入重定向逻辑*/if ($redirect)add_action('template_redirect', fn () => $redirect());/*** 抑制主查询*/add_filter('posts_request', fn ($request, $query) => $query->is_main_query() ? false : $request, 10, 2);/*** 两件事:* 1. 将$wp_query->is_home设置为false,以免redirect_canonical中被标志为home页面强行加末尾斜杠* 2. 抑制由于“抑制主查询+is_home=false”产生的404*/add_filter('pre_handle_404', fn ($_, $wp_query) => $wp_query->init_query_flags() || true, 10, 2);}protected static function filterMatches($matches){return array_filter($matches, fn ($key) => is_string($key), ARRAY_FILTER_USE_KEY);}// 下面的函数没用到,但你可能需要这些函数做一些控制public static function atPath($path): bool{return !is_404() && Router::$activePath === $path;}public static function atAnyPath(): bool{return Router::$activePath !== null;}public static function activePath(): ?string{return Router::$activePath;}
}
其中init函数用于主题加载时刷新永久链接缓存,你也可以加入更多初始化工作
最后再强调一次:add_rewrite_rule需要刷新永久链接缓存才生效
如果你还是忘记了,那只能祝你好运了:)
参考资料
- WordPress: How to create a rewrite rule for a file in a custom plugin
- Disable the MySQL query in the main query
- Query Overview
- Trailing-slash or not in the Homepage
- Do HTTP paths have to start with a slash?
相关文章:

【WordPress】如何在WordPress中实现真·页面路由
这篇文章也可以在我的博客中查看 页面路由 是什么 页面路由是指从url顺着网线砍到网站内容的途径,说人话就是地址与页面的映射。 就像真实世界的地址一样,我要找你,必须知道你的地址。 在网站中,通过地址找内容的机制…...
Android界面设计与用户体验
Android界面设计与用户体验 1. 引言 在如今竞争激烈的移动应用市场,提供优秀的用户体验成为了应用开发的关键要素。无论应用功能多么强大,如果用户界面设计不合理,用户体验不佳,很可能会导致用户流失。因此,在Androi…...
:音画同步)
基于 FFmpeg 的跨平台视频播放器简明教程(八):音画同步
系列文章目录 基于 FFmpeg 的跨平台视频播放器简明教程(一):FFMPEG Conan 环境集成基于 FFmpeg 的跨平台视频播放器简明教程(二):基础知识和解封装(demux)基于 FFmpeg 的跨平台视频…...
)
【NLP pytorch】基于BiLSTM-CRF模型医疗数据实体识别实战(项目详解)
基于BiLSTM-CRF模型医疗数据实体识别实战 1数据来源与加载1.1 数据来源1.2 数据类别名称和定义1.3 数据介绍2 模型介绍2 数据预处理2.1 数据读取2.2 数据标注2.3 数据集划分2.4 词表和标签的生成3 Dataset和DataLoader3.1 Dataset3.2 DataLoader4 BiLSTM模型定义5 CRF模型6 模型…...
)
人工智能原理(1)
*请注意,本文仅供学习使用* 目录 一、人工智能发展 1、孕育期 2、摇篮期 3、形成期 4、发展期(1970-1979) 5、实用期 6、稳步发展期 二、何为人工智能 1、智能的主要观点 2、智能定义 3、人工智能定义 三、人工智能研究方法 1、…...

预测成真,国内传来三个消息,中国年轻人变了,创新力产品崛起
中国的年轻人真的变了! 最近,国内传来三个消息,让外媒的预测成真。 第一,奥迪要开始用国产车的平台了。这里需要说明的是新能源汽车,奥迪也曾多次公开表示,承认了当前中国新能源汽车核心技术上的领先。 第…...
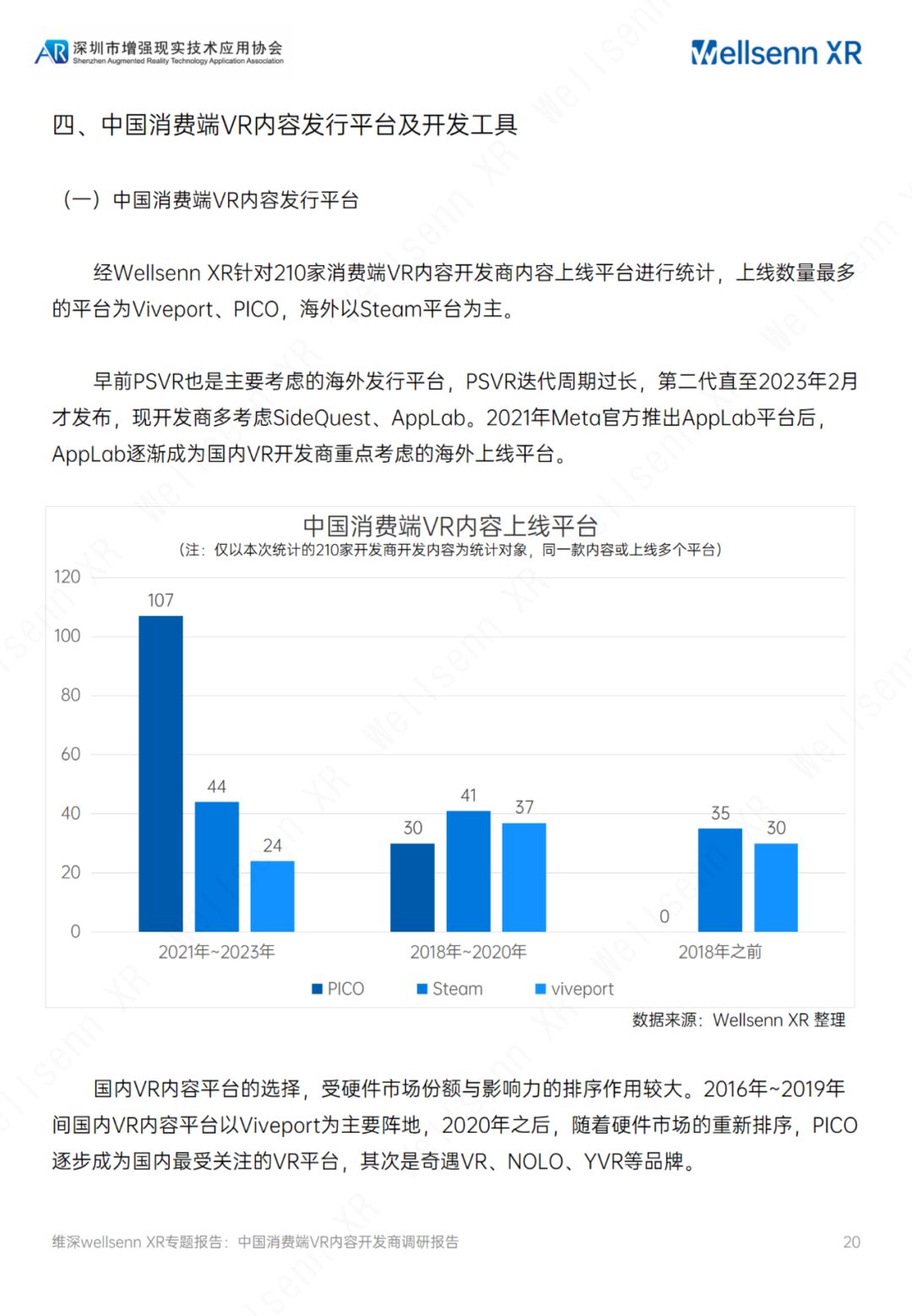
维深(Wellsenn):2023中国消费端VR内容开发商调研报告(附下载
关于报告的所有内容,公众【营销人星球】获取下载查看 核心观点 国内互联网大厂商入局VR,字节跳动、网易表态明确。字节跳动2021年收购国内头部VR硬件厂商PICO后,加速构建VR内容生态,2021年 成立海南创见未来当前已推出VR视频应用…...

redis事务管理详解
事务管理 事务管理乐观锁与悲观锁watch命令实现乐观锁watch命令示例 事务管理 Redis 提供了事务管理功能,可以通过 Redis 的 MULTI、EXEC、WATCH 和 DISCARD 命令来实现。 开启事务: 使用 MULTI 命令开始一个事务,表示接下来执行的命令都属于…...

国产低功耗蓝牙HS6621CxC/6621Px系列支持Find My网络功能方案芯片
目录 什么是“Find My“?HS6621系列简介 什么是“Find My“? “Find My”是苹果公司于19年前推出的针对失物追踪,Find My iPhone(查找我的iPhone)和Find My Friends(查找朋友)的结合体应用。为…...

【openGauss】分区表的介绍与使用
一、openGauss分区表介绍 在openGauss中,数据分区是在一个节点内部对数据按照用户指定的策略做进一步的水平分表,将表中的数据按照指定方式划分为多个互不重叠的部分。 对于大多数用户使用场景,分区表和普通表相比具有以下优点: …...
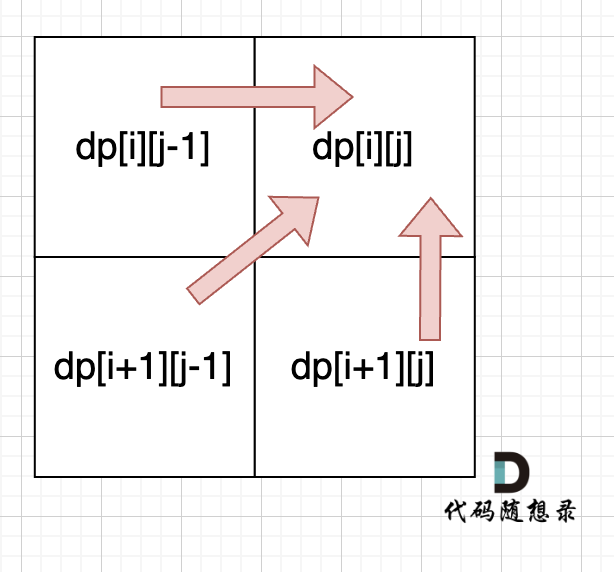
代码随想录算法训练营day57
文章目录 Day57回文子串题目思路代码 最长回文子序列题目思路代码 Day57 回文子串 647. 回文子串 - 力扣(LeetCode) 题目 给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。 回文字符串 是正着读和倒过来读一样的字符串。…...

【基础类】—前后端通信类系统性学习
一、什么是同源策略及限制 同源策略限制从一个源加载的文档或脚本如何与来自另一个源的资源进行交互。这是一个用于隔离潜在恶意文件的关键的安全机制。源:协议、域名和端口, 默认端口是80 三者有一个不同,即源不同,就是跨域 ht…...
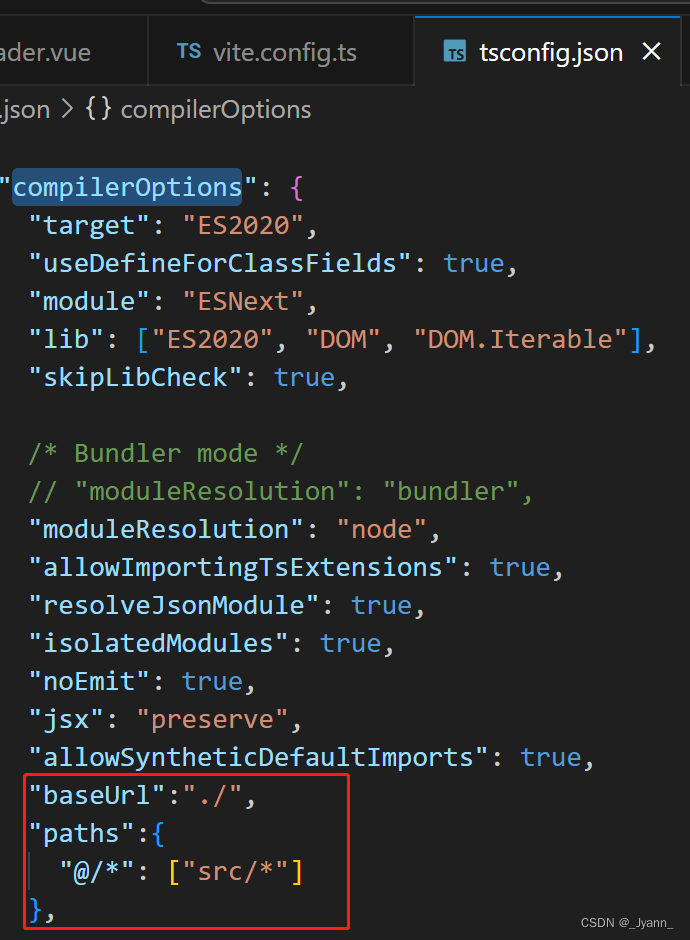
vite项目中使用@代表根路径
1.配置vite.config.ts import { defineConfig } from vite import vue from vitejs/plugin-vue import path from pathexport default defineConfig({plugins: [vue()],resolve: {alias:{: path.resolve(__dirname, src) }} })2.报错path和__dirname 找不到模块“path”或其相…...

冶金化工操作VR虚拟仿真实验软件提高员工们协同作业的配合度
对于高风险行业来说,开展安全教育培训是企业的重点工作,传统培训逐渐跟不上时代变化和工人需求,冶金安全VR模拟仿真培训系统作为一种新型的教育和培训工具,借助VR虚拟现实技术为冶金行业的工人提供一个安全、高效的培训环境。 冶金…...

SQL Server数据库 -- 索引与视图
文章目录 一、索引 聚集索引非聚集索引二、视图三、自定义函数 标量函数表值函数四、游标五、总结 前言 在学习完创建库表、查询等知识点后,为了更加方便优化数据库的存储和内容,我们需要学习一系列的方法例如索引与视图等等,从而使我们更加…...

2023 java web面试秘籍
目录 第一章:Java Web基础知识1.介绍3.Java Web基本概念 4.常见面试问题第二章:Java Web核心概念和技术1.介绍3.Servlet和JSP4.Web安全5.常见面试问题 第三章:Java Web高级概念和技术1.介绍3.Spring框架4.安全性5.常见面试问题 第四章&#x…...

2023-08-05力扣今日二题
链接: 剑指 Offer 18. 删除链表的节点 题意: 如题 解: 基础链表操作 实际代码: #include<iostream> using namespace std; struct ListNode {int val;ListNode *next;ListNode(int x) : val(x), next(NULL) {} }; Li…...
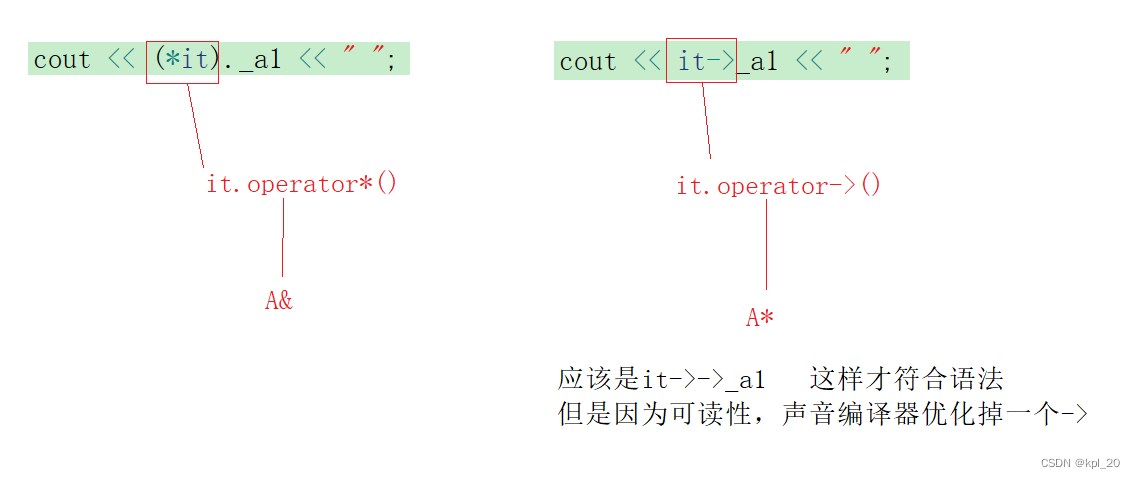
stl_list类(使用+实现)(C++)
list 一、list-简单介绍二、list的常用接口1.常见构造2.iterator的使用3.Capacity和Element access4.Modifiers5.list的迭代器失效 三、list实现四、vector 和 list 对比五、迭代器1.迭代器的实现2.迭代器的分类(按照功能分类)3.反向迭代器(1)、包装逻辑…...

利用hfish反控境外攻击源主机
导师给了7个网络安全课题选题,本想和他聊了下思路,他一挥手让我先做出点东西再来聊就把我打发走了…… 正好前段时间阿里云到校做推广,用优惠卷薅了一台云服务器,装了hfish先看下情况 没想到才装上没两天数据库就爆了࿰…...

4、Rocketmq之存储原理
CommitLog ~ MappedFileQueue ~ MappedFile集合...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...