clickhouse 删除操作
OLAP 数据库设计的宗旨在于分析适合一次插入多次查询的业务场景,市面上成熟的 AP 数据库在更新和删除操作上支持的均不是很好,当然 clickhouse 也不例外。但是不友好不代表不支持,本文主要介绍在 clickhouse 中如何实现数据的删除,以及最新版本中 clickhouse 所做的一些技术突破
一、mutations
刚接触 clickhouse 的小伙伴或许对 mutations 就很熟悉了,mutation 查询可以看成 alter 语句的变种。虽然 mutation 能够最终实现修改和删除的需求,但不能完全以通常意义的 delete 和 update 来理解,我们需要清醒的认识到它的不同:
- mutation 是一个很重的操作,适合批量数据操作
- 不支持事务、一旦操作立刻生效无法回滚
- mutation 为异步操作
1.1 实操
创建一张表用于测试 mutations 操作
create table mutations_operate
(UserId UInt64,Score UInt64,CreateTime DateTime
) engine = MergeTree()partition by toYYYYMMDD(CreateTime)order by UserId;
接下来分别插入两批不同分区的数据
insert into mutations_operate
select number,abs(number - 100),'2023-08-08 00:00:00'
from system.numbers
limit 1000000;insert into mutations_operate
select number,abs(number - 100),'2023-08-09 00:00:00'
from system.numbers
limit 1000000;
尝试删除 20230808 分区中 1000-10000 之间的所有数据,sql 如下
alter table mutations_operate delete where toYYYYMMDD(CreateTime) = 20230808 and UserId between 1000 and 10000;
可以统计一下该分区的数据条数来确认是否成功删除,从体验来说目前的数据规模感受不来 mutations 的“重”,感觉像是瞬间完成的。
当然我们也可以查看system.mutations表来监控 mutations 操作的进度
select table, mutation_id, `block_numbers.number` as num, is_done
from system.mutations;Query id: 0878a0f1-a5ff-474c-8f84-518ce5dc5e1d┌─table─────────────┬─mutation_id────┬─num─┬─is_done─┐
│ mutations_operate │ mutation_3.txt │ [3] │ 1 │
└───────────────────┴────────────────┴─────┴─────────┘1 row in set. Elapsed: 0.002 sec.
mutation_id 是一个日志文件,可以在表存储目录中查看,完整记录了本次操作的语句和时间,例如
format version: 1
create time: 2023-08-09 18:54:06
commands: DELETE WHERE (toYYYYMMDD(CreateTime) = 20230808) AND ((UserId >= 1000) AND (UserId <= 10000))
而其中的 3 以及block_numbers.number是 mutation 号,每执行一条 delete 或 update 语句都会对应一个唯一的编号
id_done 表示本次 mutation 操作是否执行完成,1 表示已经完成
1.2 原理
为了探寻 mutation 操作的原理和执行流程重置一下表数据(删除重建即可),在插入两批数据后查看磁盘目录
» du -h0B ./detached
7.7M ./20230809_2_2_0
7.7M ./20230808_1_1_015M .
可以看到两个分区目录均是 7.7M
尝试执行删除操作后,首先你会在日志中看到下面的查询信息
<Debug> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Key condition: unknown, (column 0 in [1000, +Inf)), (column 0 in (-Inf, 10000]), and, and
<Debug> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Key condition: unknown, (column 0 in [1000, +Inf)), (column 0 in (-Inf, 10000]), and, and
<Debug> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): MinMax index condition: (toYYYYMMDD(column 0) in [20230808, 20230808]), unknown, unknown, and, and
<Debug> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): MinMax index condition: (toYYYYMMDD(column 0) in [20230808, 20230808]), unknown, unknown, and, and
<Trace> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Running binary search on index range for part 20230808_1_1_0 (124 marks)
<Trace> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Found (LEFT) boundary mark: 0
<Debug> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Selected 0/1 parts by partition key, 0 parts by primary key, 0/0 marks by primary key, 0 marks to read from 0 ranges
<Trace> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Found (RIGHT) boundary mark: 2
<Trace> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Found continuous range in 13 steps
<Debug> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Selected 1/1 parts by partition key, 1 parts by primary key, 2/123 marks by primary key, 2 marks to read from 1 ranges
<Trace> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Spreading mark ranges among streams (default reading)
<Trace> MergeTreeInOrderSelectProcessor: Reading 1 ranges in order from part 20230808_1_1_0, approx. 16384 rows starting from 0
<Trace> Aggregator: Aggregation method: without_key
<Trace> AggregatingTransform: Aggregated. 0 to 1 rows (from 0.00 B) in 0.000570041 sec. (0.000 rows/sec., 0.00 B/sec.)
<Trace> Aggregator: Merging aggregated data
<Trace> MutateTask: Part 20230809_2_2_0 doesn't change up to mutation version 3
首先,clickhouse 会使用我们执行的删除语句中附带的 where 条件在每个分区中执行 count 查询,为了判断哪些分区有需要被删除的数据,从日志可以看出Reading 1 ranges in order from part 20230808_1_1_0, approx. 16384 rows starting from 0以及Part 20230809_2_2_0 doesn't change up to mutation version 3。注意日志中所说 20230808 的范围是 0~16384 并不是实际删除的范围,而是索引的范围。我们知道 mergeTree 引擎默认的跳数索引的间隔是 8192 而我们删除的数据范围是 1000-10000,显然作为一个整周期自然是 0-16384(2x8192)
当我们再次查看磁盘目录
» du -h0B ./detached
7.7M ./20230809_2_2_0
7.7M ./20230808_1_1_00B ./20230809_2_2_0_3
7.6M ./20230808_1_1_0_323M .
总目录从 15M 变成了 12M,而两个分区也都各自生成了一个以 mutation version 为后缀的新分区
因此接下来的逻辑如下:
clickhouse 会创建一个 tmp_mut_ 为前缀、mutation version 为后缀的临时分区目录,例如这里的就是 tmp_mut_20230808_1_1_0_3
对于需要删除的分区,会在 tmp_mut 目录中生成全新的 .bin 和 .mrk 文件
对于无需删除的分区,clickhouse 会创建一个 tmp_clone_ 为前缀、mutation version 为后缀的临时分区目录并将原分区里面的数据以硬链接的方式拷贝过去,并修改目录名称为正确的格式
下面是执行的日志情况
<Debug> delete_operate.mutations_operate (4351d317-2cd6-4328-85fe-49d5beeff5c3): Clone part /opt/homebrew/var/lib/clickhouse/store/435/4351d317-2cd6-4328-85fe-49d5beeff5c3/20230809_2_2_0/ to /opt/homebrew/var/lib/clickhouse/store/435/4351d317-2cd6-4328-85fe-49d5beeff5c3/tmp_clone_20230809_2_2_0_3
<Trace> delete_operate.mutations_operate (4351d317-2cd6-4328-85fe-49d5beeff5c3): Renaming temporary part tmp_clone_20230809_2_2_0_3 to 20230809_2_2_0_3 with tid (1, 1, 00000000-0000-0000-0000-000000000000).
<Trace> MergedBlockOutputStream: filled checksums 20230808_1_1_0_3 (state Temporary)
<Trace> delete_operate.mutations_operate (4351d317-2cd6-4328-85fe-49d5beeff5c3): Renaming temporary part tmp_mut_20230808_1_1_0_3 to 20230808_1_1_0_3 with tid (1, 1, 00000000-0000-0000-0000-000000000000)
从磁盘目录也可以佐证这一点,首先上面的 20230809_2_2_0_3 占用空间为 0B,当然这是 mac 独有的现实方式,在其它 linux 系统不一定是这么显示,进入各个分区查看一下
wjun :: data/delete_operate/mutations_operate ‹stable› » ll 20230808_1_1_0_3
total 15632
-rw-r-----@ 1 wjun admin 17863 Aug 9 19:36 CreateTime.bin
-rw-r-----@ 1 wjun admin 369 Aug 9 19:36 CreateTime.cmrk2
-rw-r-----@ 1 wjun admin 3968891 Aug 9 19:36 Score.bin
-rw-r-----@ 1 wjun admin 409 Aug 9 19:36 Score.cmrk2
-rw-r-----@ 1 wjun admin 3969011 Aug 9 19:36 UserId.bin
-rw-r-----@ 1 wjun admin 409 Aug 9 19:36 UserId.cmrk2
-rw-r-----@ 1 wjun admin 490 Aug 9 19:36 checksums.txt
-rw-r-----@ 1 wjun admin 90 Aug 9 19:36 columns.txt
-rw-r-----@ 1 wjun admin 6 Aug 9 19:36 count.txt
-rw-r-----@ 1 wjun admin 10 Aug 9 19:36 default_compression_codec.txt
-rw-r-----@ 1 wjun admin 1 Aug 9 19:36 metadata_version.txt
-rw-r-----@ 1 wjun admin 8 Aug 9 19:36 minmax_CreateTime.idx
-rw-r-----@ 1 wjun admin 4 Aug 9 19:36 partition.dat
-rw-r-----@ 1 wjun admin 188 Aug 9 19:36 primary.cidx
wjun :: data/delete_operate/mutations_operate ‹stable› » ll 20230809_2_2_0_3
total 15768
-rw-r-----@ 2 wjun admin 18042 Aug 9 19:35 CreateTime.bin
-rw-r-----@ 2 wjun admin 375 Aug 9 19:35 CreateTime.cmrk2
-rw-r-----@ 2 wjun admin 4004938 Aug 9 19:35 Score.bin
-rw-r-----@ 2 wjun admin 415 Aug 9 19:35 Score.cmrk2
-rw-r-----@ 2 wjun admin 4004915 Aug 9 19:35 UserId.bin
-rw-r-----@ 2 wjun admin 415 Aug 9 19:35 UserId.cmrk2
-rw-r-----@ 2 wjun admin 490 Aug 9 19:35 checksums.txt
-rw-r-----@ 2 wjun admin 90 Aug 9 19:35 columns.txt
-rw-r-----@ 2 wjun admin 7 Aug 9 19:35 count.txt
-rw-r-----@ 2 wjun admin 10 Aug 9 19:35 default_compression_codec.txt
-rw-r-----@ 2 wjun admin 8 Aug 9 19:35 minmax_CreateTime.idx
-rw-r-----@ 2 wjun admin 4 Aug 9 19:35 partition.dat
-rw-r-----@ 2 wjun admin 173 Aug 9 19:35 primary.cidx
20230809_2_2_0_3 分区 inode 被连接次数为 2 表示建立了硬链接。
因此 mutation 的删除逻辑如下:
- 每个分区执行附带删除操作的 where 条件的 count 查询,获取需要执行删除操作的分区
- 对于需要执行删除操作的分区会创建一个临时目录并生成全新(删除需要删除的行)的文件,随后 rename
- 对于无需执行删除操作的分区会创建一个临时目录并以硬链接的方式拷贝文件,随后 rename
- 原分区在
system.parts中会被置为 inactive 状态 - 在下一次 merge 是删除原分区
而对于更新操作基本逻辑一致,需要注意的是需要执行更新操作的分区会有如下两种情况:
- 分区类型为 wide:只会重新生成受影响行的 bin 和 mrk 文件,不受影响的文件以硬链接的方式拷贝
- 分区类型为 compact:因为所有列都是一个文件,因此会重新生成 bin 和 mrk 文件
更新和删除操作流程不一致的原因是:删除影响全部列而更新只影响部分列
mergeTree 表的分区类型分为 wide 和 compact 两种受
min_bytes_for_wide_part和min_rows_for_wide_part参数影响。wide 类型的分区一个列一个文件,compact 类型的分区所有列公用一个文件,当分区数据的行数和字节较小时为 compact 类型,不管是查询所有字段或某个字段相对较快;当数据量很大时就会以列式存储来追求 AP 查询性能
1.3 不足
当我们走一遍 mutation 时发现在删除任务完成后表 merge 前的这一段时间磁盘空间不减反增,这个就让用户很难接受了。因此就可能会出现因为磁盘空间不足想要删除数据,结果删除操作导致空间进一步不足的窘境。同时 mutation 会重写受影响的分区,这也是 mutation 操作重的原因所在。
二、mergeTree
对于 clickhouse 这类高性能分析型数据库而言,修改源文件是一件非常奢侈且代价昂贵的操作,相对于直接修改源文件,我们将修改和新增操作都转换为新增操作,即以增代删将是一个非常不错的选择。是不是和 Hbase 的思路十分接近。在 mergeTree 家族中有一个特殊的表引擎叫 CollapsingMergeTree,翻译过来叫折叠合并树引擎就是提供了这样的功能。它通过定义一个 sign 标记字段来记录数据行的状态。如果 sign 为 1 表示这是一行有效的数据,如果 sign 为 -1 表示这行数据被删除。当 CollapsingMergeTree 分区合并时同一分区的 +1、-1 将会被抵消,犹如一张纸折叠一般。
2.1 实操
创建 CollapsingMergeTree 表
create table collapsing_table
(Id String,Code Int32,CreateTime DateTime,Sign Int8
) engine = CollapsingMergeTree(Sign)partition by toYYYYMMDD(CreateTime)order by Id;
注:和其它 mergeTree 引擎一样 CollapsingMergeTree 依然是以 order by 字段作为后续数据唯一性的依据
插入一批原始数据
insert into collapsing_table values ('A000', 100, '2023-08-09 00:00:00', 1);
insert into collapsing_table values ('A001', 100, '2023-08-09 00:00:00', 1);
insert into collapsing_table values ('A002', 100, '2023-08-09 00:00:00', 1);
修改 A000 的 Code 为 200 并删除 A002 的数据
# 修改 A000 的 Code 为 200
insert into collapsing_table values ('A000', 100, '2023-08-09 00:00:00', -1);
insert into collapsing_table values ('A000', 200, '2023-08-09 00:00:00', 1);
# 删除 A002 的数据
insert into collapsing_table values ('A002', 100, '2023-08-09 00:00:00', -1);
# 手动执行一下分区合并操作
optimize table collapsing_table final;
可以观察到数据已经被删除和修改。
CollapsingMergeTree 在分区合并折叠数据的时候,遵循下面规则
- 如果 sign = 1 比 sign = -1 多一行,最后保留 sign = 1 的数据
- 如果 sign = 1 比 sign = -1 少一行,最后保留 sign = -1 的数据
- 如果 sign = 1 和 sign = -1 一样多,且最后一行时 sign = 1,则保留第一行的 sign = -1 和最后一行 sign = 1
- 如果 sign = 1 和 sign = -1 一样多,且最后一行时 sign = -1,则什么也不保留
- 其余情况 clickhouse 会打印告警日志,但不会报错且查询情况不可预知
2.2 不足
当前表的数据如下
select *
from collapsing_table;Query id: 4b1da757-d02a-4b88-92e5-1fe659ca462c┌─Id───┬─Code─┬──────────CreateTime─┬─Sign─┐
│ A002 │ 300 │ 2023-08-09 00:00:00 │ -1 │
└──────┴──────┴─────────────────────┴──────┘
┌─Id───┬─Code─┬──────────CreateTime─┬─Sign─┐
│ A002 │ 300 │ 2023-08-09 00:00:00 │ 1 │
└──────┴──────┴─────────────────────┴──────┘
┌─Id───┬─Code─┬──────────CreateTime─┬─Sign─┐
│ A000 │ 200 │ 2023-08-09 00:00:00 │ 1 │
│ A001 │ 100 │ 2023-08-09 00:00:00 │ 1 │
└──────┴──────┴─────────────────────┴──────┘4 rows in set. Elapsed: 0.003 sec.
从操作来看 A002 是要被删除的
但是如果查询sql如下
select Id, sum(Code), count(Code), avg(Code)
from collapsing_table
group by Id;Query id: 610f6503-1344-4ba0-9564-6327277ffe95┌─Id───┬─sum(Code)─┬─count(Code)─┬─avg(Code)─┐
│ A001 │ 100 │ 1 │ 100 │
│ A000 │ 200 │ 1 │ 200 │
│ A002 │ 600 │ 2 │ 300 │
└──────┴───────────┴─────────────┴───────────┘3 rows in set. Elapsed: 0.005 sec.
此时的结果是不对的,因此需要改写 sql
select Id, sum(Code * Sign), count(Code * Sign), avg(Code * Sign)
from collapsing_table
group by Id
having sum(Sign) > 0;Query id: a3fe84d0-33a5-4287-bd02-49ab03df1852┌─Id───┬─sum(multiply(Code, Sign))─┬─count(multiply(Code, Sign))─┬─avg(multiply(Code, Sign))─┐
│ A001 │ 100 │ 1 │ 100 │
│ A000 │ 200 │ 1 │ 200 │
└──────┴───────────────────────────┴─────────────────────────────┴───────────────────────────┘2 rows in set. Elapsed: 0.005 sec.
当然还有一种方式就是在查询数据前执行分区合并操作optimize table collapsing_table final;,但这种方式效率极低在生产中慎用
同时 CollapsingMergeTree 还存在一些问题,例如在分区合并前用户是可以看到所有数据的。当然上面所说的问题都不是最致命的,CollapsingMergeTree 最致命点在于对于 sign 的写入顺序有严格的要求,对于一个删除操作正常的顺序应该是先写入 1 再写入 -1
insert into collapsing_table values ('A002', 300, '2023-08-09 00:00:00', 1);
insert into collapsing_table values ('A002', 300, '2023-08-09 00:00:00', -1);
但如果颠倒顺序
insert into collapsing_table values ('A002', 300, '2023-08-09 00:00:00', -1);
insert into collapsing_table values ('A002', 300, '2023-08-09 00:00:00', 1);
则不会被删除。而在生产环境一旦 CollapsingMergeTree 在多线程中处理就无法保证写入顺序了。
当然幸运的是 clickhouse 也注意到 CollapsingMergeTree 的缺点并推出了新的表引擎 VersionedCollapsingMergeTree,在 CollapsingMergeTree 的基础上将按照写入顺序折叠修改为按照版本号顺序进行折叠,而版本号交由用户来管理。VersionedCollapsingMergeTree 引擎的操作就交给读者来体验,毕竟下面还有一种更贴合 TP 数据库操作的删除操作
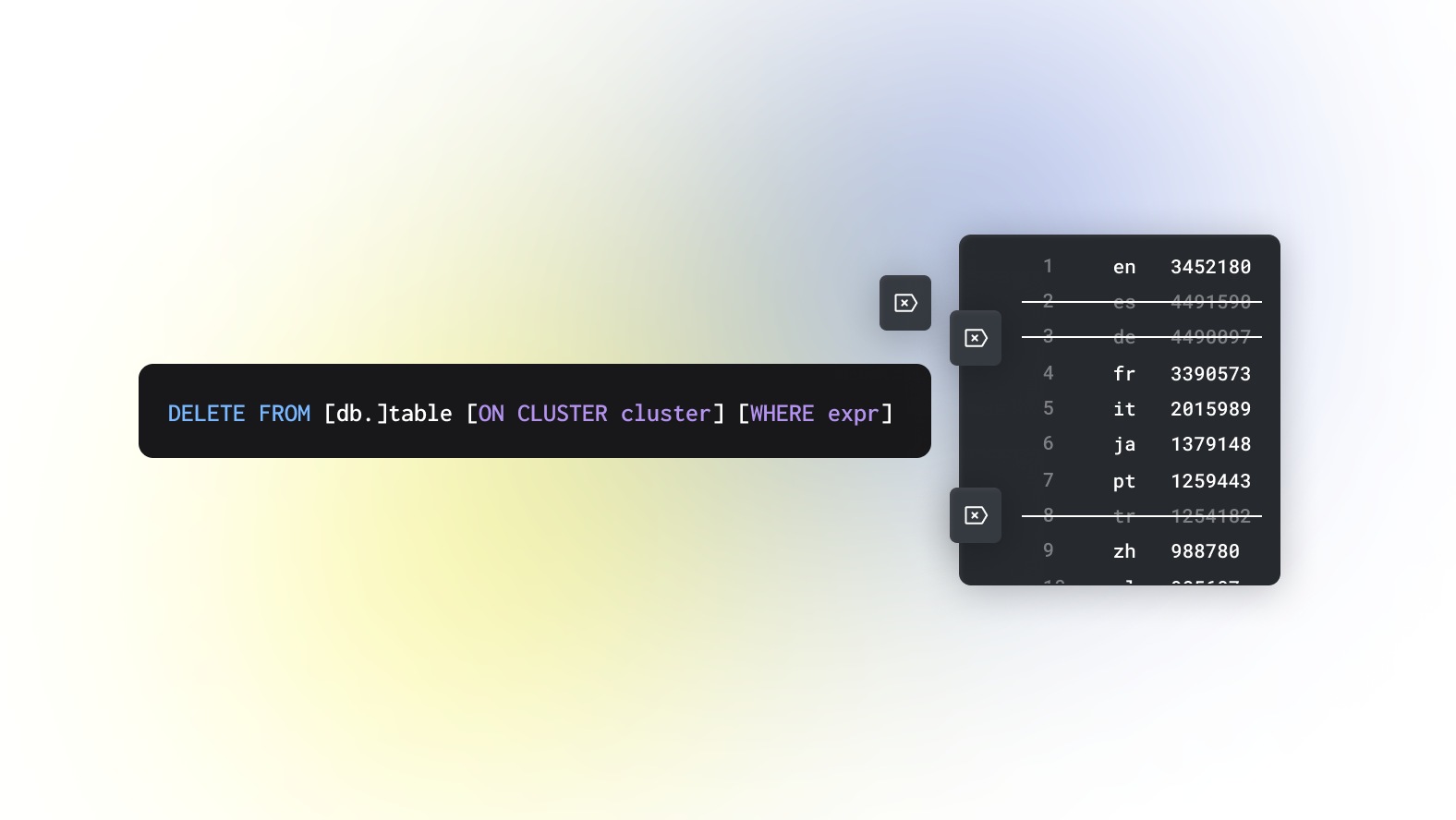
三、lightweight
上面介绍了通过 mutation 和 mergeTree 来实现删除操作,但是 mutation 操作太重,mergeTree 则需要修改 sql 已经且删除首分区合并时机影响。从 clickhouse v22.8 开始提供了一个轻量级删除功能且语法为标准 sql 🎉🎉🎉
3.1 实操
准备表和数据
create table lightweight_operate
(UserId UInt64,Score UInt64,CreateTime DateTime
) engine = MergeTree()partition by toYYYYMMDD(CreateTime)order by UserId;insert into lightweight_operate
select number,abs(number - 100),'2023-08-08 00:00:00'
from system.numbers
limit 1000000;insert into lightweight_operate
select number,abs(number - 100),'2023-08-09 00:00:00'
from system.numbers
limit 1000000;
同样删除 20230808 分区中 1000-10000 之间的所有数据,sql 如下
delete from lightweight_operate where toYYYYMMDD(CreateTime) = 20230808 and UserId between 1000 and 10000;
验证一下
select count() from lightweight_operate where toYYYYMMDD(CreateTime) = 20230808;Query id: 0344da3b-5ea5-436d-ba29-cfb1a8e3420e┌─count()─┐
│ 990999 │
└─────────┘1 row in set. Elapsed: 0.008 sec. Processed 1.00 million rows, 5.00 MB (128.59 million rows/s., 642.93 MB/s.)
成功删除
3.2 原理
查看磁盘目录
» ll
total 16
drwxr-x---@ 16 wjun admin 512 Aug 9 21:09 20230808_1_1_0
drwxr-x---@ 18 wjun admin 576 Aug 9 21:10 20230808_1_1_0_3
drwxr-x---@ 16 wjun admin 512 Aug 9 21:09 20230809_2_2_0
drwxr-x---@ 15 wjun admin 480 Aug 9 21:10 20230809_2_2_0_3
drwxr-x---@ 2 wjun admin 64 Aug 9 21:09 detached
-rw-r-----@ 1 wjun admin 1 Aug 9 21:09 format_version.txt
-rw-r-----@ 1 wjun admin 171 Aug 9 21:10 mutation_3.txt» du -h0B ./detached
7.7M ./20230809_2_2_0
7.7M ./20230808_1_1_00B ./20230809_2_2_0_328K ./20230808_1_1_0_315M .
可以看出轻量删除依然是一个 mutation 操作,从system.mutations表也可以验证,但轻量删除生成的新的分区 20230808_1_1_0_3 仅 28K,那么轻量删除和 mutation 删除的区别在哪
查看 20230808_1_1_0_3 磁盘目录
wjun :: data/delete_operate/lightweight_operate ‹stable› » ll 20230808_1_1_0_3
total 15800
-rw-r-----@ 2 wjun admin 18042 Aug 9 21:09 CreateTime.bin
-rw-r-----@ 2 wjun admin 375 Aug 9 21:09 CreateTime.cmrk2
-rw-r-----@ 2 wjun admin 4004938 Aug 9 21:09 Score.bin
-rw-r-----@ 2 wjun admin 415 Aug 9 21:09 Score.cmrk2
-rw-r-----@ 2 wjun admin 4004915 Aug 9 21:09 UserId.bin
-rw-r-----@ 2 wjun admin 415 Aug 9 21:09 UserId.cmrk2
-rw-r-----@ 1 wjun admin 4493 Aug 9 21:10 _row_exists.bin
-rw-r-----@ 1 wjun admin 236 Aug 9 21:10 _row_exists.cmrk2
-rw-r-----@ 1 wjun admin 589 Aug 9 21:10 checksums.txt
-rw-r-----@ 1 wjun admin 110 Aug 9 21:10 columns.txt
-rw-r-----@ 2 wjun admin 7 Aug 9 21:09 count.txt
-rw-r-----@ 1 wjun admin 10 Aug 9 21:10 default_compression_codec.txt
-rw-r-----@ 1 wjun admin 1 Aug 9 21:10 metadata_version.txt
-rw-r-----@ 2 wjun admin 8 Aug 9 21:09 minmax_CreateTime.idx
-rw-r-----@ 2 wjun admin 4 Aug 9 21:09 partition.dat
-rw-r-----@ 2 wjun admin 173 Aug 9 21:09 primary.cidx
发现多了一组 _row_exists 文件而其余文件的 inode 连接数均为 2,也就是说轻量删除是真正的给字段添加了一个标记。
在查询的时候过滤
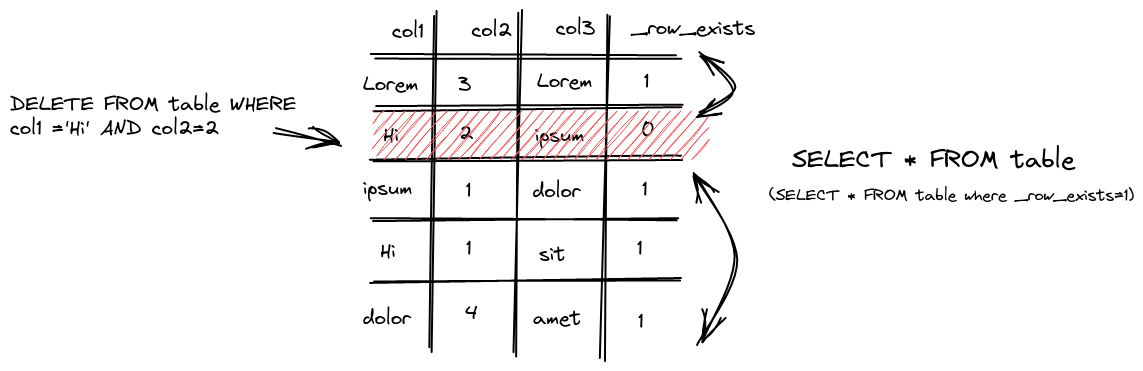
在分区合并的时候删除
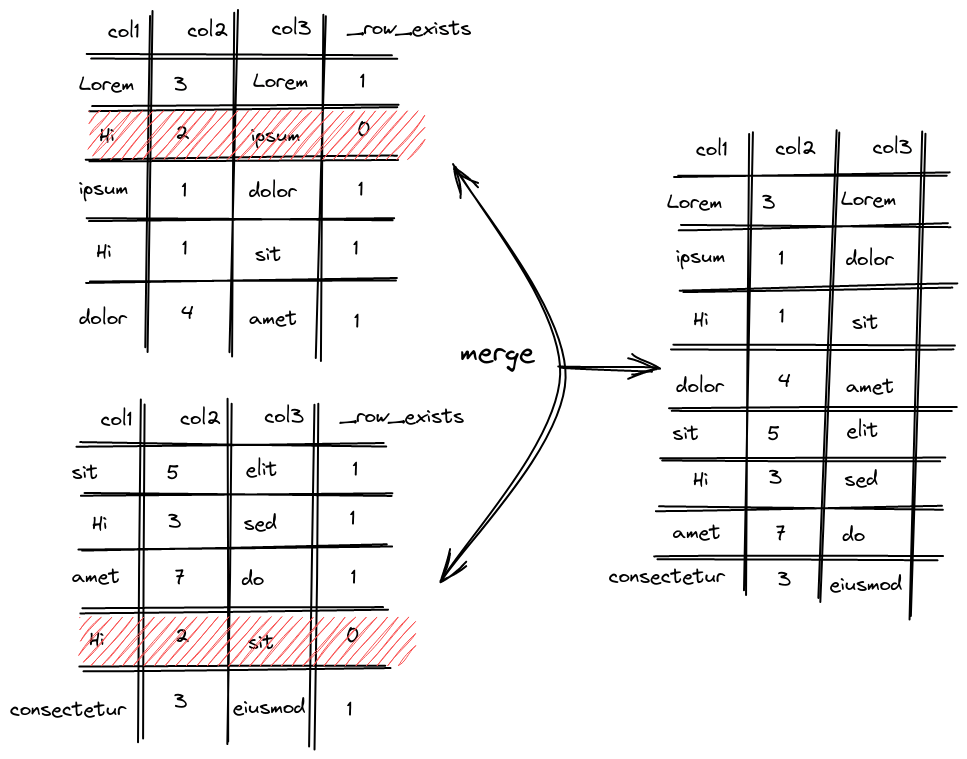
比 mutation 轻的点在于轻量删除不会重构整个分区目录而是重写 _row_exists 文件这样涉及到的修改会少很多,至于分区的拷贝和不涉及删除操作的分区操作逻辑则和上面介绍的 mutation 流程一致
3.3 不足
轻量删除的设计思路相比之前的会好上很多,但 clickhouse 毕竟不是 TP 数据库,目前轻量删除依然存在一些问题和限制,如:
- 轻量删除是异步的,只有在分区合并的时候才会被真正删除(轻量删除执行完是逻辑上删除)
- 对 wide 类型分区友好,对于 compact 类型分区和 mutation 删除差别不大
相关文章:
clickhouse 删除操作
OLAP 数据库设计的宗旨在于分析适合一次插入多次查询的业务场景,市面上成熟的 AP 数据库在更新和删除操作上支持的均不是很好,当然 clickhouse 也不例外。但是不友好不代表不支持,本文主要介绍在 clickhouse 中如何实现数据的删除,…...
C 语言中,「.」与「->」有什么区别?
使用“.”的话,只需要声明一个结构体。格式是结构体类型名结构体名。然后通过结构体名加上“.”再加上域名,就可以引用结构体的域了。因为结构体的内存是自动分配的,就像使用int a;一样。而使用“->”的话,需要声明一个结构体的…...
github pages 用法详解 发布自己的网站
github pages 基础用法 URL 规则 假设你的 github 帐号为 mygithub,需要发布的仓库名为 myrepo,那么 pages 的 URL 为: https://mygithub.github.io/myrepo 添加内容 用任意编辑器写好(或者生成)标准的网页内容&a…...

坤简炫酷的JQuery轮播图插件
介绍: 找到了一个炫酷的JQuery轮播图插件,只需要配置三四行代码就可以实现很多二维三维炫酷的切换效果。 视频效果及教程: https://www.bilibili.com/video/BV1Fu4y1d776/ 代码: https://github.com/w-x-x-w/AwesomeWeb 使用…...

C# 条件编译
C# 条件编译 C# 条件编译:根据不同的需求,编译生成不同的程序版本,条件编译是一种编译预处理命令,它是在编译代码之前对源代码进行处理。它可以根据条件,决定是否编译某段代码 条件编译的三种形式: 第一种…...

IntelliJ IDEA如何重新弹出git身份验证窗口
1、点击File菜单—>点击Settings—>点击Appearance & Behavior—>点击System Settings—>点击Passwords—>选中Do not save, forget passwords after restart—>点击Apply—>点击OK,如下所示: 2、重启IntelliJ IDEA—>通过g…...

【雕爷学编程】Arduino动手做(200)---WS2812B幻彩LED灯带4
37款传感器与模块的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止37种的。鉴于本人手头积累了一些传感器和执行器模块,依照实践出真知(一定要动手做)的理念,以学习和交流为目的&#x…...

【雕爷学编程】Arduino动手做(201)---DFRobot 行空板03
37款传感器与模块的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止37种的。鉴于本人手头积累了一些传感器和执行器模块,依照实践出真知(一定要动手做)的理念,以学习和交流为目的&#x…...
Spring中Bean的“一生”(生命周期)
文章目录 一、图解二、文字解析总结 一、图解 >注:处于同一行的执行顺序是从左往右 二、文字解析 SpringBean的生命周期总体分为四个阶段:实例化>属性注入>初始化>销毁 Step1 实例化Bean:根据配置文件中Bean的定义,…...
安卓:LitePal操作数据库
目录 一、LitePal介绍 常用方法: 1、插入数据: 2、更新数据: 3、删除数据: 4、查询数据: 二、LitePal的基本用法: 1、集成LitePal: 2、创建LitePal配置文件: 3、创建模型类…...
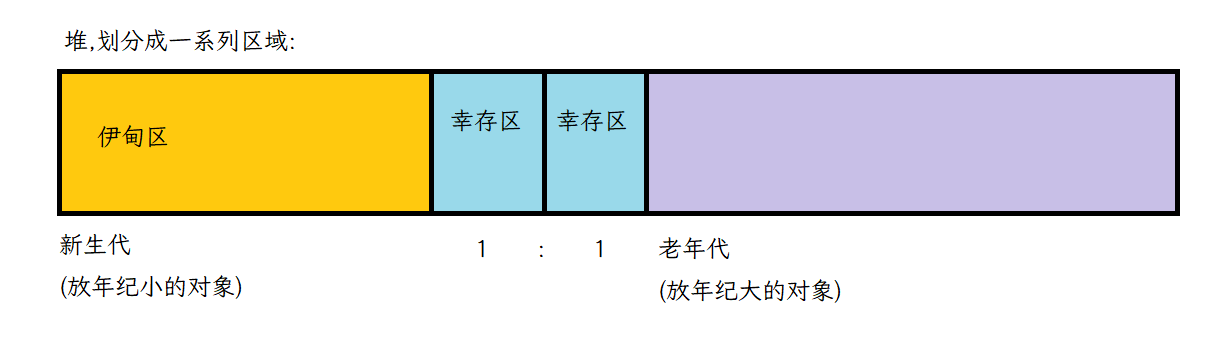
【JavaEE初阶】了解JVM
文章目录 一. JVM内存区域划分二. JVM类加载机制2.1 类加载整体流程2.2 类加载的时机2.3 双亲委派模型(经典) 三. JVM垃圾回收机制(GC)3.1 GC实际工作过程3.1.1 找到垃圾/判定垃圾1. 引用计数(不是java的做法,Python/PHP)2. 可达性分析(Java的做法) 3.1.2 清理垃圾1. 标记清除2…...
)
基于vue2.0和elementUi的vue农历日期组件vue-jlunar-datepicker(插件)
vue-jlunar-datepicker(插件) vue实现农历日历插件——vue-jlunar-datepicker插件 这个插件本身是基于vue2.0和elementUi框架来实现的。 安装 vue-jlunar-datepicker 插件 npm install vue-jlunar-datepicker --save // 如果安装过程中,出现…...

Python爬虫——selenium_元素定位
元素定位:自动化要做的就是模拟鼠标和键盘来操作这些元素,点击,输入等等。操作这些元素前首先要找到它们,WebDriver提供很多定位元素的方法 from selenium import webdriver# 创建浏览器对象 path files/chromedriver.exe brows…...

短视频内容平台(如TikTok、Instagram Reel、YouTube Shorts)的系统设计
现在,短视频内容已成为新趋势,每个人都在从TikTok、Instagram、YouTube等平台上消费这些内容。让我们看看如何为TikTok创建一个系统。 这样的应用程序看起来很小,但在后台有很多事情正在进行。以下是相关的挑战: •由于该应用程序…...

【git】Git 回退到指定版本:
文章目录 方法一: 使用 git reset 命令方法二:使用 git revert 命令方法三:使用 git checkout 命令常见的错误及其解决办法如下: 方法一: 使用 git reset 命令 命令可以将当前分支的 HEAD 指针指向指定的提交,从而回退代码到指定版…...

kibana+nginx配置密码 ubuntu
JAVA进阶之路-nginx设置密码 Kibana——通过Nginx代理Kibana并实现登陆认证 需要配置一下nginx文件 nginx配置文件详解 密码生成安装软件 apt install apache2-utils...
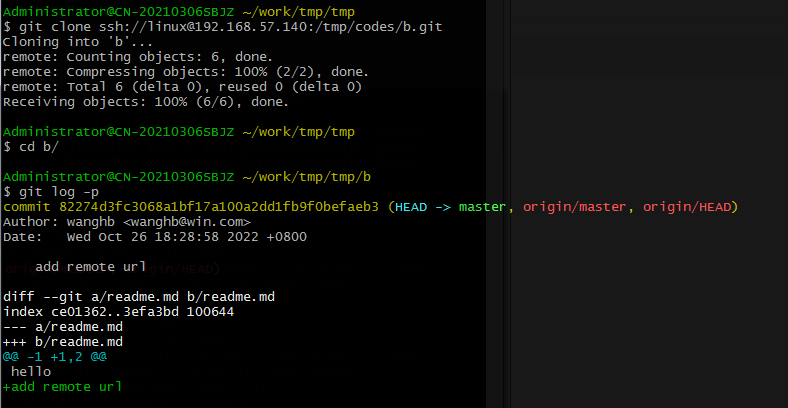
Git仓关联多个远程仓路径
前言 Git仓如果需要将代码push到多个仓,常用的做法是添加多个远程仓路径,然后分别push。这样虽然可以实现目的,但是需要多次执行push指令,很麻烦。 本文介绍关联多个远程仓路径且执行一次push指令的方法:git remote …...
使用ffmpeg将m4a及wav等文件转换为MP3格式
要使用ffmpeg将m4a及wav等文件转换为MP3格式,您可以按照以下步骤进行操作: 安装 ffmpeg 确保您已经安装了ffmpeg软件。如果没有安装,请访问ffmpeg的官方网站https://ffmpeg.org/ 并按照说明进行安装。 Win10 / Win11 可以通过 winget 命令…...

【CI/CD】Git Flow 分支模型
Git Flow 分支模型 1.前言 Git Flow 模型(本文所阐述的分支模型)构思于 2010 年,也就是 Git 诞生后不久,距今已有 10 多年。在这 10 多年中,Git Flow 在许多软件团队中大受欢迎。 在这 10 多年里,Git 本身…...
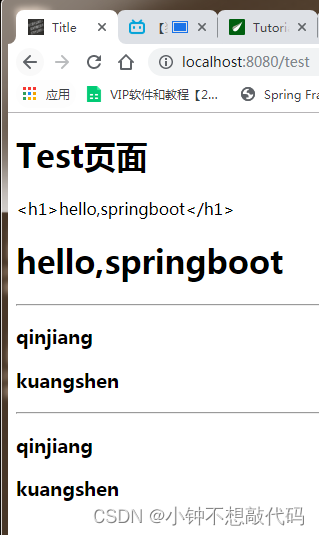
SpringBoot Thymeleaf模板引擎
Thymeleaf 模板引擎 前端交给我们的页面,是html页面。如果是我们以前开发,我们需要把他们转成jsp页面,jsp好处就是当我们查出一些数据转发到JSP页面以后,我们可以用jsp轻松实现数据的显示,及交互等。 jsp支持非常强大…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...

省略号和可变参数模板
本文主要介绍如何展开可变参数的参数包 1.C语言的va_list展开可变参数 #include <iostream> #include <cstdarg>void printNumbers(int count, ...) {// 声明va_list类型的变量va_list args;// 使用va_start将可变参数写入变量argsva_start(args, count);for (in…...

PostgreSQL——环境搭建
一、Linux # 安装 PostgreSQL 15 仓库 sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-$(rpm -E %{rhel})-x86_64/pgdg-redhat-repo-latest.noarch.rpm# 安装之前先确认是否已经存在PostgreSQL rpm -qa | grep postgres# 如果存在࿰…...