Quartz与SpringBoot 搞定任务调度
一、Quartz简介
Quartz是OpenSymphony开源组织在Job scheduling领域又一个开源项目,它可以与J2EE与J2SE应用程序相结合也可以单独使用。Quartz可以用来创建简单或为运行十个,百个,甚至是好几万个Jobs这样复杂的程序。Jobs可以做成标准的Java组件或 EJBs。Quartz的最新版本为Quartz 2.3.2
1、组件简介
Job
- Job是一个任务接口,开发者定义自己的任务须实现该接口,并重写execute(JobExecutionContext context)方法.
- Job中的任务有可能并发执行,例如任务的执行时间过长,而每次触发的时间间隔太短,则会导致任务会被并发执行。
- 为了避免出现上面的问题,可以在Job实现类上使用@DisallowConcurrentExecution,保证上一个任务执行完后,再去执行下一个任务
JobDetail - JobDetail是任务详情。 包含有:任务名称,任务组名称,任务描述、具体任务Job的实现类、参数配置等等信息
- 可以说JobDetail是任务的定义,而Job是任务的执行逻辑。
Trigger
Trigger是一个触发器,定义Job执行的时间规则。 - 主要触发器:SimpleTrigger,CronTrigger,CalendarIntervalTrigger,DailyTimeIntervalTrigger。SimpleTrigger:从某一个时间开始,以一定的时间间隔来执行任务,重复多少次。
- CronTrigger: 适合于复杂的任务,使用cron表达式来定义执行规则。
- CalendarIntervalTrigger:指定从某一个时间开始,以一定的时间间隔执行的任务,时间间隔比SimpleTrigger丰富
- DailyTimeIntervalTrigger:指定每天的某个时间段内,以一定的时间间隔执行任务。并且它可以支持指定星期。
- 所有的Trigger都包含了StartTime和endTime这两个属性,用来指定Trigger被触发的时间区间。
- 所有的Trigger都可以设置MisFire策略.
- MisFire策略是对于由于系统奔溃或者任务时间过长等原因导致Trigger在应该触发的时间点没有触发.
- 并且超过了misfireThreshold设置的时间(默认是一分钟,没有超过就立即执行)就算misfire(失火)了。
- 这个时候就该设置如何应对这种变化了。激活失败指令(Misfire Instructions)是触发器的一个重要属性
发生Misfire 对于SimpleTrigger的处理策略
//将任务马上执行一次。对于不会重复执行的任务,这是默认的处理策略。
MISFIRE_INSTRUCTION_FIRE_NOW = 1;// 调度引擎重新调度该任务,立即执行任务,repeat count 保持不变,
// 按照原有制定的执行方案执行repeat count次,但是,如果当前时间,已经晚于end-time,那么这个触发器将不会再被触发
// 简单的说就是,错过了应该触发的时间没有按时执行,但是最终它还是以原来的重复次数执行,就是会比预计终止的时间晚。
MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT//和上面的类似,区别就是不会立马执行,而是在下一个激活点执行,且超时期内错过的执行机会作废。
MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT// 这个也是重新调度任务,但是它只按照剩余次数来触发,
// 比如,应该执行10次,但是中间错过了3次没有执行,那它最终只会执行剩余次数 7次。
MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_REPEAT_COUNT//在下一个激活点执行,并重复到指定的次数。
MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_EXISTING_COUNT// 立即执行任务,repeat count 保持不变,就算到了endtime,也继续执行
MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY
发生Misfire 对于其他的Trigger
//立刻执行一次,然后就按照正常的计划执行。
MISFIRE_INSTRUCTION_FIRE_ONCE_NOW//目前不执行,然后就按照正常的计划执行。这意味着如果下次执行时间超过了end time,实际上就没有执行机会了。
MISFIRE_INSTRUCTION_DO_NOTHING
Scheduler
- 调度器,主要是用来管理Trigger、JobDetail的。
- Scheduler可以通过组名或者名称来对Trigger和JobDetail来进行管理
- 一个Trigger只能对应一个Job,但是一个Job可以对应多个Trigger.
- Scheduler 有两个实现类:RemoteScheduler、StdScheduler。但它是由 SchdulerFactory创建的。
- SchdulerFactory是个接口,它有两个实现类:StdSchedulerFactory、DirectSchedulerFactory
2、相关Builder介绍
Quartz提供了相应的Builder方便我们进行构造。
JobBuilder
这个主要方便我们构建任务详情,常用方法
- withIdentity(String name, String group):配置Job名称与组名
- withDescription(String jobDescription): 任务描述
- requestRecovery(): 出现故障是否重新执行,默认false
- storeDurably(): 作业完成后是否保留存储,默认false
- usingJobData(String dataKey, String value): 配置单个参数key
- usingJobData(JobDataMap newJobDataMap): 配置多个参数,放入一个map
- setJobData(JobDataMap newJobDataMap):
和上面类似,但是这个参数直接指向newJobDataMap,直接设置的参数无效
TriggerBuilder
这个主要方便我们构建触发器,常用方法: - withIdentity(String name, String group): 配置Trigger名称与组名
- withIdentity(TriggerKey triggerKey): 配置Trigger名称与组名
- withDescription(String triggerDescription): 描述
- withPriority(int triggerPriority): 设置优先级,默认是:5
- startAt(Date triggerStartTime): 设置开始时间
- startNow(): 触发器立即生效
- endAt(Date triggerEndTime): 设置结束时间
- withSchedule(ScheduleBuilder schedBuilder):
设置调度builder,下面的builder就是
SimpleScheduleBuilder
几种触发器类型之一,最简单常用的。常用方法:
- repeatForever():指定触发器将无限期重复
- withRepeatCount(int
triggerRepeatCount):指定重复次数,总触发的次数=triggerRepeatCount+1 - repeatSecondlyForever(int seconds):每隔seconds秒无限期重复
- repeatMinutelyForever(int minutes):每隔minutes分钟无限期重复
- repeatHourlyForever(int hours):每隔hours小时无限期重复
- repeatSecondlyForever():每隔1秒无限期重复
- repeatMinutelyForever():每隔1分钟无限期重复
- repeatHourlyForever():每隔1小时无限期重复
- withIntervalInSeconds(int intervalInSeconds):每隔intervalInSeconds秒执行
- withIntervalInMinutes(int intervalInMinutes):每隔intervalInMinutes分钟执行
- withIntervalInHours(int intervalInHours):每隔intervalInHours小时执行
- withMisfireHandlingInstructionFireNow():失火后的策略为:MISFIRE_INSTRUCTION_FIRE_NOW
CronScheduleBuilder
算是非常常用的了,crontab 表达式,常用方法: - cronSchedule(String cronExpression):使用cron表达式。
CalendarIntervalScheduleBuilder
常用方法: - inTimeZone(TimeZone timezone):设置时区
- withInterval(int timeInterval, IntervalUnit
unit):相隔多少时间执行,单位有:毫秒、秒、分、时、天、周、月、年 - withIntervalInSeconds(int intervalInSeconds):相隔秒
- withIntervalInWeeks(int intervalInWeeks):相隔周
- withIntervalInMonths(int intervalInMonths):相隔月
等等方法
DailyTimeIntervalScheduleBuilder - withInterval(int timeInterval, IntervalUnit
unit):相隔多少时间执行,单位有:秒、分、时,其他单位的不支持会报错 - withIntervalInSeconds(int intervalInSeconds):相隔秒
- withIntervalInMinutes(int intervalInMinutes):相隔分
- withIntervalInHours(int intervalInHours):相隔时
- onDaysOfTheWeek(Set
onDaysOfWeek):将触发器设置为在一周的指定日期触发。取值范围可以是1-7,1是星期天,2是星期一… - onDaysOfTheWeek(Integer … onDaysOfWeek):和上面一样,3是星期二…7是星期六
- onMondayThroughFriday():每星期的周一导周五触发
- onSaturdayAndSunday():每星期的周六周日触发
- onEveryDay():每天触发
- withRepeatCount(int repeatCount):重复次数,总的重复次数=1 (at start time) +
repeatCount - startingDailyAt(TimeOfDay timeOfDay):触发的开始时间
- endingDailyAt(TimeOfDay timeOfDay):触发的结束时间
3、基本使用
引用依赖
<dependency><groupId>org.quartz-scheduler</groupId><artifactId>quartz</artifactId><version>2.3.2</version>
</dependency>
在pom.xml文件中,引入
简单例子:
public class Demo {public static final String COUNT = "count";//这个属性如不是static,那么每次都要实例这个任务类,始终打印为: 1private static int num = 1;public static void main(String[] args) throws SchedulerException {SchedulerFactory schedulerfactory = new StdSchedulerFactory();
// Scheduler scheduler = schedulerfactory.getScheduler();Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();scheduler.start();JobDetail job = JobBuilder.newJob(HelloJob.class).withIdentity("jobName", "jobGroupName").usingJobData(COUNT,num).build();// 各种builder 的基本使用SimpleScheduleBuilder simpleScheduleBuilder = SimpleScheduleBuilder.simpleSchedule().repeatForever().withIntervalInSeconds(3);CronScheduleBuilder cronScheduleBuilder = CronScheduleBuilder.cronSchedule("*/3 * * * * ?");CalendarIntervalScheduleBuilder calendarIntervalScheduleBuilder = CalendarIntervalScheduleBuilder.calendarIntervalSchedule().withInterval(3, DateBuilder.IntervalUnit.SECOND);DailyTimeIntervalScheduleBuilder dailyTimeIntervalScheduleBuilder = DailyTimeIntervalScheduleBuilder.dailyTimeIntervalSchedule().withIntervalInSeconds(3);Trigger trigger = TriggerBuilder.newTrigger().withIdentity("jobName", "jobGroupName").withSchedule(dailyTimeIntervalScheduleBuilder).startNow().build();scheduler.scheduleJob(job, trigger);}// 保存在JobDataMap传递的参数@PersistJobDataAfterExecution@DisallowConcurrentExecutionpublic static class HelloJob implements Job{@Overridepublic void execute(JobExecutionContext context) throws JobExecutionException {JobDataMap jobDataMap = context.getJobDetail().getJobDataMap();int count = jobDataMap.getInt(COUNT);System.out.println("=========="+ LocalDateTimeUtils.formatDateTimeNow()+",count="+count);jobDataMap.put(COUNT,++num);}}
}
是不是感觉很简单,自己定义一个类,然后实现Job接口,重写execute(JobExecutionContext context) 方法,然后使用调度器去调度一下即可。 简单玩完了,和springboot整合一波。
二、与Springboot整合
这个才是重点,Springboot基本是一个Java程序猿必备的技能了。什么框架都得和它整一下。
1、引入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
spring官方自己都帮我们搞好了一些配置。
2、配置application.yml
如下:
spring:datasource:url: jdbc:mysql://localhost:3306/quartz?serverTimezone=GMT&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&allowMultiQueries=trueusername: rootpassword: rootdriver-class-name: com.mysql.cj.jdbc.Drivertype: com.alibaba.druid.pool.DruidDataSourcedruid:initialSize: 5minIdle: 5maxActive: 30max-wait: 6000pool-prepared-statements: truemax-pool-prepared-statement-per-connection-size: 20time-between-eviction-runs-millis: 60000min-evictable-idle-time-millis: 300000#validation-query: SELECT 1 FROM DUALtest-while-idle: truetest-on-borrow: falsetest-on-return: falsestat-view-servlet:enabled: trueurl-pattern: /druid/*#login-username: admin#login-password: adminfilter:stat:log-slow-sql: trueslow-sql-millis: 1000merge-sql: falsewall:config:multi-statement-allow: truequartz:job-store-type: jdbc #数据库方式#是否等待任务执行完毕后,容器才会关闭wait-for-jobs-to-complete-on-shutdown=false#配置的job是否覆盖已经存在的JOB信息overwrite-existing-jobs: falsejdbc:initialize-schema: ALWAYS #不初始化表结构properties:org:quartz:scheduler:instanceId: AUTO #默认主机名和时间戳生成实例ID,可以是任何字符串,但对于所有调度程序来说,必须是唯一的 对应qrtz_scheduler_state INSTANCE_NAME字段#instanceName: clusteredScheduler #quartzSchedulerjobStore:class: org.quartz.impl.jdbcjobstore.JobStoreTX #持久化配置driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate #我们仅为数据库制作了特定于数据库的代理useProperties: false #以指示JDBCJobStore将JobDataMaps中的所有值都作为字符串,因此可以作为名称 - 值对存储而不是在BLOB列中以其序列化形式存储更多复杂的对象。从长远来看,这是更安全的,因为您避免了将非String类序列化为BLOB的类版本问题。tablePrefix: qrtz_ #数据库表前缀misfireThreshold: 60000 #在被认为“失火”之前,调度程序将“容忍”一个Triggers将其下一个启动时间通过的毫秒数。默认值(如果您在配置中未输入此属性)为60000(60秒)。clusterCheckinInterval: 5000 #设置此实例“检入”*与群集的其他实例的频率(以毫秒为单位)。影响检测失败实例的速度。isClustered: true #打开群集功能threadPool: #连接池class: org.quartz.simpl.SimpleThreadPoolthreadCount: 10threadPriority: 5threadsInheritContextClassLoaderOfInitializingThread: true
- 这里打算搞个集群版的,就算你部署多台服务器,定时任务会自己负载均衡,不会每台服务器都执行。
- 表的生成,其实可以修改配置,启动的时候自己在数据库生成表。操作方法:
- 修改:spring.quartz.jdbc.initialize-schema: ALWAYS、说明一下
- 这里有3个值可选:ALWAYS(每次都生成)、EMBEDDED(仅初始化嵌入式数据源)、NEVER(不初始化数据源)。
- 表生成之后,再改为never即可。注意一点就是我测试了下,发现只有使用druid数据库连接池才会自动生成表。
3、表的说明
会自动生成的表如下:
//以Blob 类型存储的触发器。
qrtz_blob_triggers//存放日历信息, quartz可配置一个日历来指定一个时间范围。
qrtz_calendars//存放cron类型的触发器。
qrtz_cron_triggers
//存储已经触发的trigger相关信息,trigger随着时间的推移状态发生变化,直到最后trigger执行完成,从表中被删除。
qrtz_fired_triggers //存放一个jobDetail信息。
qrtz_job_details//job**监听器**。
qrtz_job_listeners//Quartz提供的锁表,为多个节点调度提供分布式锁,实现分布式调度,默认有2个锁
qrtz_locks//存放暂停掉的触发器。
qrtz_paused_trigger_graps//存储所有节点的scheduler,会定期检查scheduler是否失效
qrtz_scheduler_state//存储SimpleTrigger
qrtz_simple_triggers//触发器监听器。
qrtz_trigger_listeners//触发器的基本信息。
qrtz_triggers//存储CalendarIntervalTrigger和DailyTimeIntervalTrigger两种类型的触发器
qrtz_simprop_triggers
重要表字段解析
CREATE TABLE `qrtz_job_details` (`SCHED_NAME` varchar(120) COLLATE utf8_bin NOT NULL COMMENT '调度器名,集群环境中使用,必须使用同一个名称——集群环境下”逻辑”相同的scheduler,默认为QuartzScheduler',`JOB_NAME` varchar(200) COLLATE utf8_bin NOT NULL COMMENT '集群中job的名字',`JOB_GROUP` varchar(200) COLLATE utf8_bin NOT NULL COMMENT '集群中job的所属组的名字',`DESCRIPTION` varchar(250) COLLATE utf8_bin DEFAULT NULL COMMENT '描述',`JOB_CLASS_NAME` varchar(250) COLLATE utf8_bin NOT NULL COMMENT '集群中个note job实现类的完全包名,quartz就是根据这个路径到classpath找到该job类',`IS_DURABLE` varchar(1) COLLATE utf8_bin NOT NULL COMMENT '是否持久化,把该属性设置为1,quartz会把job持久化到数据库中',`IS_NONCONCURRENT` varchar(1) COLLATE utf8_bin NOT NULL COMMENT '是否并行,该属性可以通过注解配置',`IS_UPDATE_DATA` varchar(1) COLLATE utf8_bin NOT NULL,`REQUESTS_RECOVERY` varchar(1) COLLATE utf8_bin NOT NULL COMMENT '当一个scheduler失败后,其他实例可以发现那些执行失败的Jobs,若是1,那么该Job会被其他实例重新执行,否则对应的Job只能释放等待下次触发',`JOB_DATA` blob COMMENT '一个blob字段,存放持久化job对象',PRIMARY KEY (`SCHED_NAME`,`JOB_NAME`,`JOB_GROUP`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='存储每一个已配置的 Job 的详细信息';CREATE TABLE `qrtz_triggers` (`SCHED_NAME` varchar(120) COLLATE utf8_bin NOT NULL COMMENT '调度器名,和配置文件org.quartz.scheduler.instanceName保持一致',`TRIGGER_NAME` varchar(200) COLLATE utf8_bin NOT NULL COMMENT '触发器的名字',`TRIGGER_GROUP` varchar(200) COLLATE utf8_bin NOT NULL COMMENT '触发器所属组的名字',`JOB_NAME` varchar(200) COLLATE utf8_bin NOT NULL COMMENT 'qrtz_job_details表job_name的外键',`JOB_GROUP` varchar(200) COLLATE utf8_bin NOT NULL COMMENT 'qrtz_job_details表job_group的外键',`DESCRIPTION` varchar(250) COLLATE utf8_bin DEFAULT NULL COMMENT '描述',`NEXT_FIRE_TIME` bigint(13) DEFAULT NULL COMMENT '下一次触发时间',`PREV_FIRE_TIME` bigint(13) DEFAULT NULL COMMENT '上一次触发时间',`PRIORITY` int(11) DEFAULT NULL COMMENT '线程优先级',`TRIGGER_STATE` varchar(16) COLLATE utf8_bin NOT NULL COMMENT '当前trigger状态',`TRIGGER_TYPE` varchar(8) COLLATE utf8_bin NOT NULL COMMENT '触发器类型',`START_TIME` bigint(13) NOT NULL COMMENT '开始时间',`END_TIME` bigint(13) DEFAULT NULL COMMENT '结束时间',`CALENDAR_NAME` varchar(200) COLLATE utf8_bin DEFAULT NULL COMMENT '日历名称',`MISFIRE_INSTR` smallint(2) DEFAULT NULL COMMENT 'misfire处理规则,1代表【以当前时间为触发频率立刻触发一次,然后按照Cron频率依次执行】,2代表【不触发立即执行,等待下次Cron触发频率到达时刻开始按照Cron频率依次执行�】,-1代表【以错过的第一个频率时间立刻开始执行,重做错过的所有频率周期后,当下一次触发频率发生时间大于当前时间后,再按照正常的Cron频率依次执行】',`JOB_DATA` blob COMMENT 'JOB存储对象',PRIMARY KEY (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`),KEY `SCHED_NAME` (`SCHED_NAME`,`JOB_NAME`,`JOB_GROUP`),CONSTRAINT `qrtz_triggers_ibfk_1` FOREIGN KEY (`SCHED_NAME`, `JOB_NAME`, `JOB_GROUP`) REFERENCES `qrtz_job_details` (`SCHED_NAME`, `JOB_NAME`, `JOB_GROUP`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='存储已配置的 Trigger 的信息';CREATE TABLE `qrtz_cron_triggers` (`SCHED_NAME` varchar(120) COLLATE utf8_bin NOT NULL COMMENT '集群名',`TRIGGER_NAME` varchar(200) COLLATE utf8_bin NOT NULL COMMENT '调度器名,qrtz_triggers表trigger_name的外键',`TRIGGER_GROUP` varchar(200) COLLATE utf8_bin NOT NULL COMMENT 'qrtz_triggers表trigger_group的外键',`CRON_EXPRESSION` varchar(200) COLLATE utf8_bin NOT NULL COMMENT 'cron表达式',`TIME_ZONE_ID` varchar(80) COLLATE utf8_bin DEFAULT NULL COMMENT '时区ID',PRIMARY KEY (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`),CONSTRAINT `qrtz_cron_triggers_ibfk_1` FOREIGN KEY (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`) REFERENCES `qrtz_triggers` (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='存放cron类型的触发器';CREATE TABLE `qrtz_scheduler_state` (`SCHED_NAME` varchar(120) COLLATE utf8_bin NOT NULL COMMENT '调度器名称,集群名',`INSTANCE_NAME` varchar(200) COLLATE utf8_bin NOT NULL COMMENT '集群中实例ID,配置文件中org.quartz.scheduler.instanceId的配置',`LAST_CHECKIN_TIME` bigint(13) NOT NULL COMMENT '上次检查时间',`CHECKIN_INTERVAL` bigint(13) NOT NULL COMMENT '检查时间间隔',PRIMARY KEY (`SCHED_NAME`,`INSTANCE_NAME`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='调度器状态';CREATE TABLE `qrtz_fired_triggers` (`SCHED_NAME` varchar(120) COLLATE utf8_bin NOT NULL COMMENT '调度器名称,集群名',`ENTRY_ID` varchar(95) COLLATE utf8_bin NOT NULL COMMENT '运行Id',`TRIGGER_NAME` varchar(200) COLLATE utf8_bin NOT NULL COMMENT '触发器名',`TRIGGER_GROUP` varchar(200) COLLATE utf8_bin NOT NULL COMMENT '触发器组',`INSTANCE_NAME` varchar(200) COLLATE utf8_bin NOT NULL COMMENT '集群中实例ID',`FIRED_TIME` bigint(13) NOT NULL COMMENT '触发时间',`SCHED_TIME` bigint(13) NOT NULL COMMENT '计划时间',`PRIORITY` int(11) NOT NULL COMMENT '线程优先级',`STATE` varchar(16) COLLATE utf8_bin NOT NULL COMMENT '状态',`JOB_NAME` varchar(200) COLLATE utf8_bin DEFAULT NULL COMMENT '任务名',`JOB_GROUP` varchar(200) COLLATE utf8_bin DEFAULT NULL COMMENT '任务组',`IS_NONCONCURRENT` varchar(1) COLLATE utf8_bin DEFAULT NULL COMMENT '是否并行',`REQUESTS_RECOVERY` varchar(1) COLLATE utf8_bin DEFAULT NULL COMMENT '是否恢复',PRIMARY KEY (`SCHED_NAME`,`ENTRY_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='存储与已触发的 Trigger 相关的状态信息,以及相联 Job 的执行信息';CREATE TABLE `qrtz_simple_triggers` (`SCHED_NAME` varchar(120) COLLATE utf8_bin NOT NULL COMMENT '调度器名,集群名',`TRIGGER_NAME` varchar(200) COLLATE utf8_bin NOT NULL COMMENT '触发器名',`TRIGGER_GROUP` varchar(200) COLLATE utf8_bin NOT NULL COMMENT '触发器组',`REPEAT_COUNT` bigint(7) NOT NULL COMMENT '重复次数',`REPEAT_INTERVAL` bigint(12) NOT NULL COMMENT '重复间隔',`TIMES_TRIGGERED` bigint(10) NOT NULL COMMENT '已触发次数',PRIMARY KEY (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`),CONSTRAINT `qrtz_simple_triggers_ibfk_1` FOREIGN KEY (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`) REFERENCES `qrtz_triggers` (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='存储简单的 Trigger,包括重复次数,间隔,以及已触的次数';
4、怎么使用
- 当我们引入spring-boot-starter-quartz的依赖后,springboot在启动的时候会自动加载配置类:
- org.springframework.boot.autoconfigure.quartz.QuartzAutoConfiguration。
会帮我们初始化好调度器,源码:SchedulerFactoryBean实现InitializingBean,重写afterPropertiesSet()
里面就有了。 - 而且Scheduler,Spring默认是帮我们启动的,不需要手动启动。
使用如下:
@Autowired
private Scheduler scheduler;
spring会自己注入,通过工厂类SchedulerFactoryBean的getObject()方法。 搞个基本的增删改查,很简单,代码也没怎么优化,就这样吧。
@Component
public class JobService {@Autowiredprivate Scheduler scheduler;/*** 增加一个job** @param jobClass* 任务实现类* @param jobName* 任务名称(建议唯一)* @param jobGroupName* 任务组名* @param cron* 时间表达式 (如:0/5 * * * * ? )* @param jobData* 参数*/public void addJob(Class<? extends Job> jobClass, String jobName, String jobGroupName, String cron, Map jobData,Date endTime)throws SchedulerException {// 创建jobDetail实例,绑定Job实现类// 指明job的名称,所在组的名称,以及绑定job类// 任务名称和组构成任务keyJobDetail jobDetail = JobBuilder.newJob(jobClass).withIdentity(jobName, jobGroupName).build();// 设置job参数if (jobData != null && jobData.size() > 0) {jobDetail.getJobDataMap().putAll(jobData);}// 定义调度触发规则// 使用cornTrigger规则// 触发器keyTrigger trigger = TriggerBuilder.newTrigger().withIdentity(jobName, jobGroupName).startAt(DateBuilder.futureDate(1, DateBuilder.IntervalUnit.SECOND)).withSchedule(CronScheduleBuilder.cronSchedule(cron)).startNow().build();if(endTime!=null){trigger.getTriggerBuilder().endAt(endTime);}// 把作业和触发器注册到任务调度中scheduler.scheduleJob(jobDetail, trigger);}public Trigger getTrigger(String jobName, String jobGroupName) throws SchedulerException {return scheduler.getTrigger(TriggerKey.triggerKey(jobName, jobGroupName));}/*** 删除任务一个job** @param jobName* 任务名称* @param jobGroupName* 任务组名*/public void deleteJob(String jobName, String jobGroupName) {try {scheduler.deleteJob(JobKey.jobKey(jobName, jobGroupName));} catch (Exception e) {e.printStackTrace();}}/*** 暂停一个job** @param jobName* @param jobGroupName*/public void pauseJob(String jobName, String jobGroupName) {try {JobKey jobKey = JobKey.jobKey(jobName, jobGroupName);scheduler.pauseJob(jobKey);} catch (SchedulerException e) {e.printStackTrace();}}/*** 恢复一个job** @param jobName* @param jobGroupName*/public void resumeJob(String jobName, String jobGroupName) {try {JobKey jobKey = JobKey.jobKey(jobName, jobGroupName);scheduler.resumeJob(jobKey);} catch (SchedulerException e) {e.printStackTrace();}}/*** 立即执行一个job** @param jobName* @param jobGroupName*/public void runJobNow(String jobName, String jobGroupName) {try {JobKey jobKey = JobKey.jobKey(jobName, jobGroupName);scheduler.triggerJob(jobKey);} catch (SchedulerException e) {e.printStackTrace();}}/*** 修改 一个job的 时间表达式** @param jobName* @param jobGroupName* @param cron*/public void updateJob(String jobName, String jobGroupName, String cron,Map jobData) {try {TriggerKey triggerKey = TriggerKey.triggerKey(jobName, jobGroupName);Trigger trigger = scheduler.getTrigger(triggerKey);if(trigger instanceof CronTrigger){CronTrigger cronTrigger = (CronTrigger) trigger;cronTrigger = cronTrigger.getTriggerBuilder().withIdentity(triggerKey).withSchedule(CronScheduleBuilder.cronSchedule(cron)).build();}else {// 这里其实可以删掉在添加即可,懒得写了throw new RuntimeException("格式转换错误");}// 设置job参数if (jobData != null && jobData.size() > 0) {trigger.getJobDataMap().putAll(jobData);}// 重启触发器scheduler.rescheduleJob(triggerKey, trigger);} catch (SchedulerException e) {e.printStackTrace();}}
}
- 和上面得基本demo没什么两样,就是scheduler 并不需要我们去创建了。
- 当部署多个服务时,也不会重复执行。且任务会负载均衡分配。
5、时间演练
Quartz 提供了下一次运行的时间,我们可以通过下一次运行的时间,比对是否符合我们的预期
public class Test {public static void main(String[] args) throws ParseException, SchedulerException {String cron = "0/10 * * * * ?";CronExpression cronExpression = new CronExpression(cron);Date nextValidTimeAfter = cronExpression.getNextValidTimeAfter(new Date());System.out.println("nextValidTimeAfter=" + nextValidTimeAfter);nextValidTimeAfter = cronExpression.getNextValidTimeAfter(nextValidTimeAfter);System.out.println("nextValidTimeAfter=" + nextValidTimeAfter);nextValidTimeAfter = cronExpression.getNextValidTimeAfter(nextValidTimeAfter);System.out.println("nextValidTimeAfter=" + nextValidTimeAfter);CalendarIntervalTrigger calendarIntervalTrigger =newTrigger().withIdentity("trigger3", "group1").withSchedule(calendarIntervalSchedule().withIntervalInWeeks(3)).build();Date nextFireTime = calendarIntervalTrigger.getFireTimeAfter(new Date());System.out.println("nextFireTime=" + DateUtils.formatTime(nextFireTime));nextFireTime = calendarIntervalTrigger.getFireTimeAfter(nextFireTime);System.out.println("nextFireTime=" + DateUtils.formatTime(nextFireTime));nextFireTime = calendarIntervalTrigger.getFireTimeAfter(nextFireTime);System.out.println("nextFireTime=" + DateUtils.formatTime(nextFireTime));nextFireTime = calendarIntervalTrigger.getFireTimeAfter(nextFireTime);System.out.println("nextFireTime=" + DateUtils.formatTime(nextFireTime));}
}
每个 Tigger 都有一个Date getFireTimeAfter(Date afterTime) 的方法,返回的就是下一次运行的时间。
相关文章:

Quartz与SpringBoot 搞定任务调度
一、Quartz简介 Quartz是OpenSymphony开源组织在Job scheduling领域又一个开源项目,它可以与J2EE与J2SE应用程序相结合也可以单独使用。Quartz可以用来创建简单或为运行十个,百个,甚至是好几万个Jobs这样复杂的程序。Jobs可以做成标准的Java…...
SciencePlots绘图
简介 使用Python作为核心开发工具的机器学习和深度学习研究者自然会希望使用Matplotlib进行科研图表的绘制,但是Matplotlib默认的样式并不适合科研论文的出版,而SciencePlots就是为此定制的一系列科研绘图样式库,可以绘制很合适科研图表。 …...

【Spark分布式内存计算框架——Spark SQL】12. External DataSource(下)rdbms 数据
6.7 rdbms 数据 回顾在SparkCore中读取MySQL表的数据通过JdbcRDD来读取的,在SparkSQL模块中提供对应接口,提供三种方式读取数据: 方式一:单分区模式 方式二:多分区模式,可以设置列的名称,作为…...

【React】React入门--更改状态、属性、表单的非受控组件和受控组件
🎀个人主页:努力学习前端知识的小羊 感谢你们的支持:收藏🎄 点赞🍬 加关注🪐 文章目录setState属性(props)属性vs状态非受控组件受控组件setState this.state是纯js对象,在vue中,dat…...
0216-0218复习:继承
目录 继承 一、基本介绍 二、示意图 三、基本语法 四、入门案例 父类 子类1 子类2 main方法 五、继承细节 第一条 第二条 第三条 第四条 编辑 第五条 第六条 第七条 第八条 第九条 第十条 六、继承本质 七、练习题 第三题 继承 一、基本介绍 继承可以…...
【数据库】HNU数据库系统期末考试复习重点
前言 今天刚结束考试,考的范围基本没有超过这套重点内容,觉得整理的这份资料还算比较有用,遂睡前整理了下分享给大家,希望能帮到要准备数据库期末又时间紧张的学弟学妹~ 文章参考: 1.课程老师发《数据库期末考试复习…...

SCI论文写作常见连词及适用情况
And:用于连接同类或相似的词、短语或句子,表达并列关系。Moreover:用于连接两个相似或相关的想法,表达附加的信息或思想。Furthermore:用于连接两个相似或相关的想法,表达更进一步的信息或思想。In additio…...
Spring中的数据校验--进阶
分组校验 场景描述 在实际开发中经常会遇到这种情况:添加用户时,id是由后端生成的,不需要校验id是否为空,但是修改用户时就需要校验id是否为空。如果在接收参数的User实体类的id属性上添加NotNull,显然无法实现。这时…...
多种方法解决谷歌(chrome)、edge、火狐等浏览器F12打不开调试页面或调试模式(面板)的问题。
文章目录1. 文章引言2. 解决问题3. 解决该问题的其他方法1. 文章引言 不论是前端开发者,还是后端开发者,我们在调试web项目时,偶尔弹出相关错误。 此时,我们需要打开浏览器的调试模式,如下图所示: 通过浏…...

默认生成的接口实现方法体的问题
随着集成开发环境越来越强大,编程开发工作也变得越来越高效,很多的代码都不需要逐字输入,可以利用代码生成和自动补全来辅助开发。但是这样的便利也可能引起一些疏忽,本文就Java开发中默认生成的接口实现方法来谈谈以前遇到的问题…...

【OJ】十级龙王间的决斗
📚Description: 在《驯龙高手2》,最精彩的高潮出现在两只阿尔法决斗的时候。 驯龙高手中的十星龙王又称喷冰龙,有且只有两只,是最大型的龙,所有其他龙都要膜拜它(当然,幼龙除外)&…...

java 自定义注解
文章目录前言Annotation包自定义注解自定义注解示例参考文章:java 自定义注解 用处_java注解和自定义注解的简单使用参考文章:java中自定义注解的作用和写法前言 在使用Spring Boot的时候,大量使用注解的语法去替代XML配置文件,十…...

产品经理知识体系:2.如何进行商业需求分析?
商业需求分析 思考 笔记 用户细分: 核心用户、用户分级 用户关系: 如何维护用户关系、维护等成本 关系和商业模式的整合 核心价值: 解决什么问题,满足什么需求,最终带给用户什么价值 渠道通道: 如何触达…...

EditPlus正则表达式替换字符串详解
正则表达式是一个查询的字符串,它包含一般的字符和一些特殊的字符,特殊字符可以扩展查找字符串的能力,正则表达式在查找和替换字符串的作用不可忽视,它能很好提高工作效率。EditPlus的查找,替换,文件中查找…...

Go基础-环境安装
文章目录1 Go?Golang?2 下载Go3 windows安装4 测试是否成功1 Go?Golang? Go也称为Golang,是Google开发的一个开源的编译型的静态语言。 Golang的主要关注点是高可用、高并发和高扩展性,Go语言定位是系统级编程语言,对web程序具有很好的支…...

《NFL橄榄球》:纽约巨人·橄榄1号位
纽约巨人(New York Giants)是美国全国橄榄球联盟在新泽西州东卢瑟福的一支球队。巨人是在1925年作为五个成员之一加入国家美式橄榄球联盟。 在2018年时,球队市值为33亿美元,在世界前50名球队中并列第8名,同时在NFL高居…...

2023/02/18 ES6数组的解读
1 扩展运算符 扩展运算符(spread)是三个点(…). 它好比 rest 参数的逆运算,将一个数组转为用逗号分隔的参数序列. console.log(...[1, 2, 3]) // 1 2 3console.log(1, ...[2, 3, 4], 5) // 1 2 3 4 5该运算符主要用于…...
Ubuntu 20 安装包下载(清华镜像)
Ubuntu 20 安装包下载在国内推荐使用清华大学镜像 清华镜像地址:https://mirrors.tuna.tsinghua.edu.cn/ 在搜索框中输入Ubuntu,然后点击Ubuntu -release,这里面有近几年的Ubuntu镜像 点击你想下载的版本,我选择的是20.0413点击…...
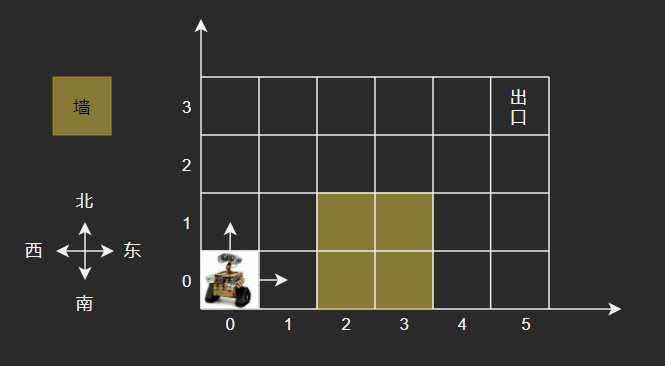
华为OD机试 - 机器人走迷宫(JS)
机器人走迷宫 题目 房间有X*Y的方格组成,例如下图为6*4的大小。每一个放个以坐标(x,y)描述。 机器人固定从方格(0,0)出发,只能向东或者向北前进, 出口固定为房间的最东北角,如下图的方格(5,3)。 用例保证机器人可以从入口走到出…...

字节二面:10Wqps超高流量系统,如何设计?
超高流量系统设计思路 前言 在40岁老架构师 尼恩的**读者交流群(50)**中,大流量、高并发的面试题是一个非常、非常高频的交流话题。最近,有小伙伴面试字节时,遇到一个面试题: 10Wqps超高流量系统,该如何设计…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

java 实现excel文件转pdf | 无水印 | 无限制
文章目录 目录 文章目录 前言 1.项目远程仓库配置 2.pom文件引入相关依赖 3.代码破解 二、Excel转PDF 1.代码实现 2.Aspose.License.xml 授权文件 总结 前言 java处理excel转pdf一直没找到什么好用的免费jar包工具,自己手写的难度,恐怕高级程序员花费一年的事件,也…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...

c# 局部函数 定义、功能与示例
C# 局部函数:定义、功能与示例 1. 定义与功能 局部函数(Local Function)是嵌套在另一个方法内部的私有方法,仅在包含它的方法内可见。 • 作用:封装仅用于当前方法的逻辑,避免污染类作用域,提升…...