Flink流批一体计算(14):PyFlink Tabel API之SQL查询
举个例子
查询 source 表,同时执行计算
# 通过 Table API 创建一张表:
source_table = table_env.from_path("datagen")
# 或者通过 SQL 查询语句创建一张表:
source_table = table_env.sql_query("SELECT * FROM datagen")
result_table = source_table.select(source_table.id + 1, source_table.data)Table API 查询
Table 对象有许多方法,可以用于进行关系操作。
这些方法返回新的 Table 对象,表示对输入 Table 应用关系操作之后的结果。
这些关系操作可以由多个方法调用组成,例如 table.group_by(...).select(...)。
Table API 文档描述了流和批处理上所有支持的 Table API 操作。
以下示例展示了一个简单的 Table API 聚合查询:
from pyflink.table import Environmentsettings, TableEnvironment
# 通过 batch table environment 来执行查询
env_settings = Environmentsettings.in_batch_mode()
table_env = TableEnvironment.create(env_settings)
orders = table_env.from_elements([('Jack', 'FRANCE', 10), ('Rose', 'ENGLAND', 30), ('Jack', 'FRANCE', 20)],['name', 'country', 'revenue'])
# 计算所有来自法国客户的收入
revenue = orders \.select(orders.name, orders.country, orders.revenue) \.where(orders.country == 'FRANCE') \.group_by(orders.name) \.select(orders.name, orders.revenue.sum.alias('rev_sum'))
revenue.to_pandas()Table API 也支持行操作的 API, 这些行操作包括 Map Operation, FlatMap Operation, Aggregate Operation 和 FlatAggregate Operation.
以下示例展示了一个简单的 Table API 基于行操作的查询
from pyflink.table import Environmentsettings, TableEnvironment
from pyflink.table import DataTypes
from pyflink.table.udf import udf
import pandas as pd# 通过 batch table environment 来执行查询
env_settings = Environmentsettings.in_batch_mode()
table_env = TableEnvironment.create(env_settings)
orders = table_env.from_elements([('Jack', 'FRANCE', 10), ('Rose', 'ENGLAND', 30), ('Jack', 'FRANCE', 20)], ['name', 'country', 'revenue'])
map_function = udf(lambda x: pd.concat([x.name, x.revenue * 10], axis=1),result_type=DataTypes.ROW([DataTypes.FIELD("name", DataTypes.STRING()),DataTypes.FIELD("revenue", DataTypes.BIGINT())]),func_type="pandas")
orders.map(map_function).alias('name', 'revenue').to_pandas()SQL 查询
Flink 的 SQL 基于 Apache Calcite,它实现了标准的 SQL。SQL 查询语句使用字符串来表达。SQL 支持Flink 对流和批处理。
下面示例展示了一个简单的 SQL 聚合查询:
from pyflink.table import Environmentsettings, TableEnvironment# 通过 stream table environment 来执行查询env_settings = Environmentsettings.in_streaming_mode()table_env = TableEnvironment.create(env_settings)table_env.execute_sql("""CREATE TABLE random_source (id BIGINT,data TINYINT) WITH ('connector' = 'datagen','fields.id.kind'='sequence','fields.id.start'='1','fields.id.end'='8','fields.data.kind'='sequence','fields.data.start'='4','fields.data.end'='11')""")table_env.execute_sql("""CREATE TABLE print_sink (id BIGINT,data_sum TINYINT) WITH ('connector' = 'print')""")table_env.execute_sql("""INSERT INTO print_sinkSELECT id, sum(data) as data_sum FROM(SELECT id / 2 as id, data FROM random_source)WHERE id > 1GROUP BY id""").wait()Table API 和 SQL 的混合使用
Table API 中的 Table 对象和 SQL 中的 Table 可以自由地相互转换。
下面例子展示了如何在 SQL 中使用 Table 对象:
create_temporary_view(view_path, table) 将一个 `Table` 对象注册为一张临时表,类似于 SQL 的临时表。
# 创建一张 sink 表来接收结果数据
table_env.execute_sql("""CREATE TABLE table_sink (id BIGINT,data VARCHAR) WITH ('connector' = 'print')
""")
# 将 Table API 表转换成 SQL 中的视图
table = table_env.from_elements([(1, 'Hi'), (2, 'Hello')], ['id', 'data'])
table_env.create_temporary_view('table_api_table', table)
# 将 Table API 表的数据写入结果表
table_env.execute_sql("INSERT INTO table_sink SELECT * FROM table_api_table").wait()下面例子展示了如何在 Table API 中使用 SQL 表:
sql_query(query) 执行一条 SQL 查询,并将查询的结果作为一个 `Table` 对象。
# 创建一张 SQL source 表
table_env.execute_sql("""CREATE TABLE sql_source (id BIGINT,data TINYINT) WITH ('connector' = 'datagen','fields.id.kind'='sequence','fields.id.start'='1','fields.id.end'='4','fields.data.kind'='sequence','fields.data.start'='4','fields.data.end'='7')
""")# 将 SQL 表转换成 Table API 表
table = table_env.from_path("sql_source")
# 或者通过 SQL 查询语句创建表
table = table_env.sql_query("SELECT * FROM sql_source")
# 将表中的数据写出
table.to_pandas()优化
数据倾斜
当数据发生倾斜(某一部分数据量特别大),虽然没有GC(Gabage Collection,垃圾回收),但是task执行时间严重不一致。
- 需要重新设计key,以更小粒度的key使得task大小合理化。
- 修改并行度。
- 调用rebalance操作,使数据分区均匀。
缓冲区超时设置
由于task在执行过程中存在数据通过网络进行交换,数据在不同服务器之间传递的缓冲区超时时间可以通过setBufferTimeout进行设置。
当设置“setBufferTimeout(-1)”,会等待缓冲区满之后才会刷新,使其达到最大吞吐量;当设置“setBufferTimeout(0)”时,可以最小化延迟,数据一旦接收到就会刷新;当设置“setBufferTimeout”大于0时,缓冲区会在该时间之后超时,然后进行缓冲区的刷新。
示例可以参考如下:
env.setBufferTimeout(timeoutMillis);
env.generateSequence(1,10).map(new MyMapper()).setBufferTimeout(timeoutMillis);相关文章:
:PyFlink Tabel API之SQL查询)
Flink流批一体计算(14):PyFlink Tabel API之SQL查询
举个例子 查询 source 表,同时执行计算 # 通过 Table API 创建一张表: source_table table_env.from_path("datagen") # 或者通过 SQL 查询语句创建一张表: source_table table_env.sql_query("SELECT * FROM datagen&quo…...
JRebel插件扩展-mac版
前言 上一篇分享了mac开发环境的搭建,但是欠了博友几个优化的债,今天先还一个,那就是idea里jRebel插件的扩展。 一、场景回眸 这个如果在win环境那扩展是分分钟,一个exe文件点点就行。现在在mac环境就没有这样的dmg可以执行的&…...

C语言中常见的一些语法概念和功能
常用代码: 程序入口:int main() 函数用于定义程序的入口点。 输出:使用 printf() 函数可以在控制台打印输出。 输入:使用 scanf() 函数可以接收用户的输入。 条件判断:使用 if-else 语句可以根据条件执行不同的代码…...

Python土力学与基础工程计算.PDF-钻探泥浆制备
Python 求解代码如下: 1. rho1 2.5 # 黏土密度,单位:t/m 2. rho2 1.0 # 泥浆密度,单位:t/m 3. rho3 1.0 # 水的密度,单位:t/m 4. V 1.0 # 泥浆容积,单位:…...
【机器学习】— 2 图神经网络GNN
一、说明 在本文中,我们探讨了图神经网络(GNN)在推荐系统中的潜力,强调了它们相对于传统矩阵完成方法的优势。GNN为利用图论来改进推荐系统提供了一个强大的框架。在本文中,我们将在推荐系统的背景下概述图论和图神经网…...

QT的布局与间隔器介绍
布局与间隔器 1、概述 QT中使用绝对定位的布局方式,无法适用窗口的变化,但是,也可以通过尺寸策略来进行 调整,使得 可以适用窗口变化。 布局管理器作用最主要用来在qt设计师中进行控件的排列,另外,布局管理…...

深入浅出Pytorch函数——torch.nn.Linear
分类目录:《深入浅出Pytorch函数》总目录 对输入数据做线性变换 y x A T b yxA^Tb yxATb 语法 torch.nn.Linear(in_features, out_features, biasTrue, deviceNone, dtypeNone)参数 in_features:[int] 每个输入样本的大小out_features :…...

Vue3.2+TS的defineExpose的应用
defineExpose通俗来讲,其实就是讲子组件的方法或者数据,暴露给父组件进行使用,这样对组件的封装使用,有很大的帮助,那么defineExpose应该如何使用,下面我来用一些实际的代码,带大家快速学会defi…...

牛客网Python入门103题练习|【08--元组】
⭐NP62 运动会双人项目 描述 牛客运动会上有一项双人项目,因为报名成功以后双人成员不允许被修改,因此请使用元组(tuple)进行记录。先输入两个人的名字,请输出他们报名成功以后的元组。 输入描述: 第一…...
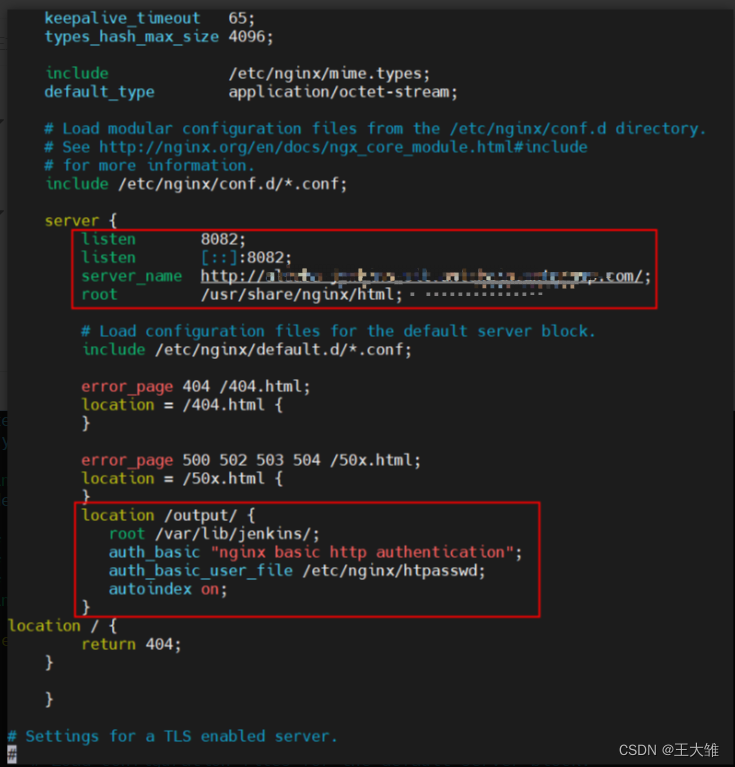
Jenkins改造—nginx配置鉴权
先kill掉8082的端口进程 netstat -natp | grep 8082 kill 10256 1、下载nginx nginx安装 EPEL 仓库中有 Nginx 的安装包。如果你还没有安装过 EPEL,可以通过运行下面的命令来完成安装 sudo yum install epel-release 输入以下命令来安装 Nginx sudo yum inst…...
VisionOS平台概述)
(二)VisionOS平台概述
2.VisionOS平台概述 1. VisionOS平台概述 Unity 对VisionOS的支持将 Unity 编辑器和运行时引擎的全部功能与RealityKit提供的渲染功能结合起来。Unity 的核心功能(包括脚本、物理、动画混合、AI、场景管理等)无需修改即可支持。这允许游戏和应用程序逻…...

菜单中的类似iOS中开关的样式
背景是我们有需求,做类似ios中开关的按钮。github上有一些开源项目,比如 SwitchButton, 但是这个项目中提供了很多选项,并且实际使用中会出现一些奇怪的问题。 我调整了下代码,把无关的功能都给删了,保留核…...

Vue 2 动态组件和异步组件
先阅读 【Vue 2 组件基础】中的初步了解动态组件。 动态组件与keep-alive 我们知道动态组件使用is属性和component标签结合来切换不同组件。 下面给出一个示例: <!DOCTYPE html> <html><head><title>Vue 动态组件</title><scri…...
MongoDB升级经历(4.0.23至5.0.19)
MongoDB从4.0.23至5.0.19升级经历 引子:为了解决MongoDB的两个漏洞决定把MongoDB升级至最新版本,期间也踩了不少坑,在这里分享出来供大家学习与避坑~ 1、MongoDB的两个漏洞 漏洞1:MongoDB Server 安全漏洞(CVE-2021-20330) 漏洞2…...
iPhone上的个人热点丢失了怎么办?如何修复iPhone上不见的个人热点?
个人热点功能可将我们的iPhone手机转变为 Wi-Fi 热点,有了Wi-Fi 热点后就可以与附近的其他设备共享其互联网连接。 一般情况下,个人热点打开就可以使用,但也有部分用户在升级系统或越狱后发现 iPhone 的个人热点消失了。 iPhone上的个人热点…...
AI 媒人:为什么图形神经网络比 MLP 更好?
一、说明 G拉夫神经网络(GNN)!想象他们是人工智能世界的媒人,通过探索他们的联系,不知疲倦地帮助数据点找到朋友和人气。数字派对上的终极僚机。 现在,为什么这些GNN如此重要,你问?好…...

信息学奥赛一本通 1984:【19CSPJ普及组】纪念品 | 洛谷 P5662 [CSP-J2019] 纪念品
【题目链接】 ybt 1984:【19CSPJ普及组】纪念品 洛谷 P5662 [CSP-J2019] 纪念品 【题目考点】 1. 动态规划:完全背包 【解题思路】 由于小伟每天都可以买卖物品无限次,我们可以假想每天开始时,他把所有的商品都卖出ÿ…...

JVM——JVM参数指南
文章目录 1.概述2.堆内存相关2.1.显式指定堆内存–Xms和-Xmx2.2.显式新生代内存(Young Ceneration)2.3.显示指定永久代/元空间的大小 3.垃圾收集相关3.1.垃圾回收器3.2.GC记录 1.概述 在本篇文章中,你将掌握最常用的 JVM 参数配置。如果对于下面提到了一些概念比如…...

马上七夕到了,用各种编程语言实现10种浪漫表白方式
目录 1. 直接表白:2. 七夕节表白:3. 猜心游戏:4. 浪漫诗句:5. 爱的方程式:6. 爱心Python:7. 心形图案JavaScript 代码:8. 心形并显示表白信息HTML 页面:9. Java七夕快乐:…...
Spring Clould 注册中心 - Eureka,Nacos
视频地址:微服务(SpringCloudRabbitMQDockerRedis搜索分布式) Eureka 微服务技术栈导学(P1、P2) 微服务涉及的的知识 认识微服务-服务架构演变(P3、P4) 总结: 认识微服务-微服务技…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...
CSS | transition 和 transform的用处和区别
省流总结: transform用于变换/变形,transition是动画控制器 transform 用来对元素进行变形,常见的操作如下,它是立即生效的样式变形属性。 旋转 rotate(角度deg)、平移 translateX(像素px)、缩放 scale(倍数)、倾斜 skewX(角度…...

根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的----NTFS源代码分析--重要
根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的 第一部分: 0: kd> g Breakpoint 9 hit Ntfs!ReadIndexBuffer: f7173886 55 push ebp 0: kd> kc # 00 Ntfs!ReadIndexBuffer 01 Ntfs!FindFirstIndexEntry 02 Ntfs!NtfsUpda…...

论文阅读笔记——Muffin: Testing Deep Learning Libraries via Neural Architecture Fuzzing
Muffin 论文 现有方法 CRADLE 和 LEMON,依赖模型推理阶段输出进行差分测试,但在训练阶段是不可行的,因为训练阶段直到最后才有固定输出,中间过程是不断变化的。API 库覆盖低,因为各个 API 都是在各种具体场景下使用。…...