3D- vista:预训练的3D视觉和文本对齐Transformer
论文:https://arxiv.org/abs/2308.04352
代码: GitHub - 3d-vista/3D-VisTA: Official implementation of ICCV 2023 paper "3D-VisTA: Pre-trained Transformer for 3D Vision and Text Alignment"
摘要
三维视觉语言基础(3D- vl)是一个新兴领域,旨在将三维物理世界与自然语言联系起来,这对实现具身智能至关重要。目前的3D-VL模型严重依赖于复杂的模块、辅助损耗和优化技巧,这需要一个简单而统一的模型。在本文中,我们提出了3D- vista,一个预训练的3D视觉和文本对齐转换器,可以很容易地适应各种下游任务。3D-VisTA简单地利用self attention层进行单模态建模和多模态融合,而无需任何复杂的特定任务设计。为了进一步提高其在3D- vl任务上的性能,我们构建了ScanScribe,这是第一个用于3D- vl预训练的大规模3D场景文本对数据集。ScanScribe包含2,995个RGBD扫描,用于源自ScanNet和3R-Scan数据集的1,185个独特的室内场景,以及从现有3D-VL任务,模板和GPT-3生成的配对278K场景描述。3D-VisTA通过屏蔽语言/对象建模和场景文本匹配在ScanScribe上进行预训练。它在各种3D-VL任务上实现了最先进的结果,从视觉基础和密集的字幕到问题回答和情境推理。此外,3D-VisTA展示了卓越的数据效率,即使在下游任务微调期间注释有限也能获得强大的性能。
背景
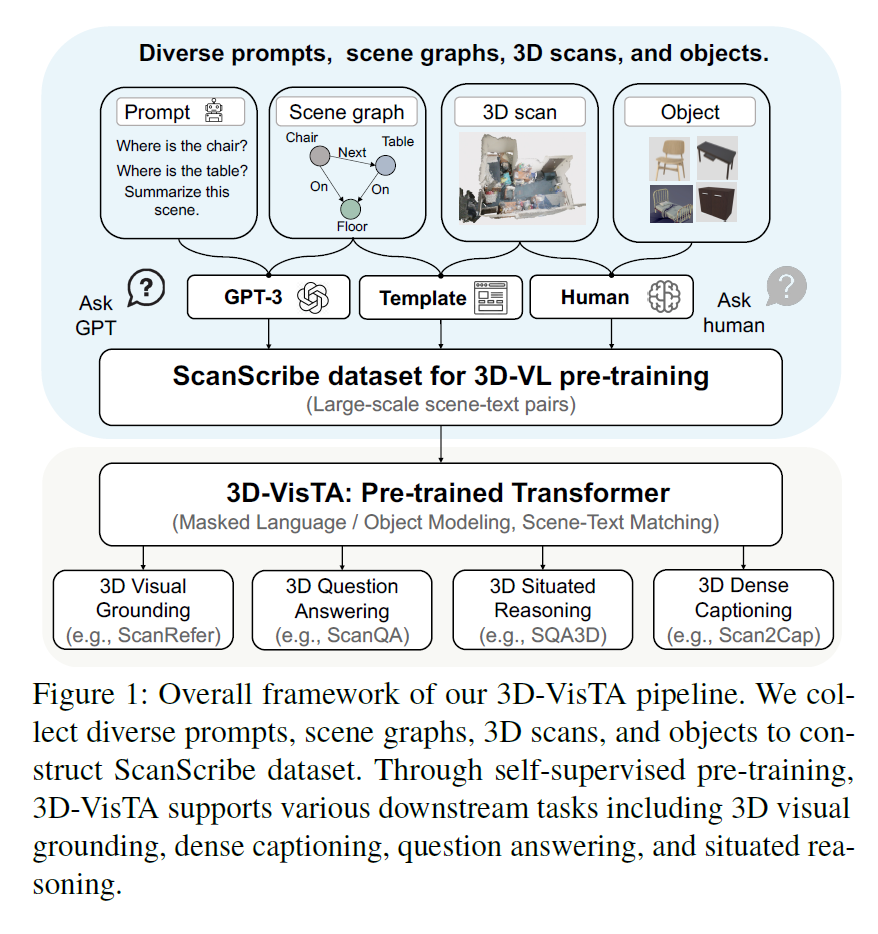
1.
将三维物理世界与自然语言结合起来是实现具身人工智能的关键一步[18,26,37],智能体可以在现实世界中理解并进一步执行人类指令[5,29]。最近,3D视觉语言(3D- vl)任务引起了越来越多的关注[19],包括3D视觉基础(3D visual grounding)[8,1]、密集字幕(dense captioning)[11]、语法学习(grammar learning)[23]、问题回答(question answering)[3,56]和情境推理(situated reasoning )[36]。
然而,大多数为3D-VL开发的模型只关注这些3D-VL任务中的一个或两个,并采用特定的任务设计[7,3,36,35,10]。
例如,3D-SPS[35]和BUTD-DETR[27]通过关注VL特征,对每一层的物体进行检测,逐步发现目标物体。3DVG[55]、MVT[24]和ViL3DRel[10]通过在模型设计中明确地注入空间关系信息,改善了三维视觉基础。
3DJCG[7]通过共享的3D对象建议模块shared 3D object proposal module[16]和两个独立的任务头two separate task-specific heads[7],共同学习3D密集字幕和视觉接地(dense captioning and visual grounding)。
此外,训练这些模型通常需要手动指定辅助损耗(例如,3D物体检测/分类和文本分[35,24,7,3,36])或优化技巧(例如,知识蒸馏[4,53])。
缺乏一个简单而统一的方法会造成严重的开发通用3D-VL模型的差距。
为了填补这一空白,我们引入了3D-VisTA,一个基于transformer的模型的3D视觉和文本对齐,可以易于适应各种下游任务。与之前的在设计复杂的任务特定模块的模型中,我们简单地使用一个普通的self attention transformer[46]对于单模态建模和多模态融合3 d-vista。作为一般做法进一步加强三维空间理解[10,55,7],我们明确的将成对的空间关系编码成为对象间的self attention权重用于3D对象建模。
2.
受NLP[15、41、42、6、52、31]、CV[22、17、21、25、38]和2D-VL[30、2、34、40]中大规模预训练成功的启发,我们提出在3D场景文本数据上预训练3D- vista,以期在3D- vl任务上获得更好的性能。为此,我们构建了ScanScribe,这是第一个用于3D- vl预训练的大规模3D场景文本对数据集。
我们在提议的ScanScribe数据集上预训练3D-VisTA。我们的预训练任务包括掩码语言建模、掩码对象建模和场景文本匹配。值得注意的是,类似的目标在2D-VL中被广泛采用,但在3D-VL领域却很少被探索。所提出的预训练过程有效地学习了三维点云和文本之间的对齐,从而消除了下游任务微调中对辅助损失和优化技巧的需要。
贡献
1)提出3D- vista,一个简单而统一的transformer,用于对齐3D视觉和文本。所建议的Transformer只是利用了自注意机制,没有任何复杂的特定于任务的设计。
2)构建了ScanScribe,这是一个大规模3D- vl预训练数据集,包含278K 3D场景文本对,用于1,185个独特室内场景的2,995个RGB-D扫描。
3)提出了一种基于掩码语言/对象建模和场景文本匹配的自监督预训练方案。它有效地学习了三维点云和文本对齐,进一步简化和提高了下游任务的微调。
4)对3D-VisTA进行微调,并在各种3D-VL任务上实现最先进的性能,从视觉基础和密集字幕到问题回答和情境推理。3D-VisTA还展示了卓越的数据效率,即使在有限的注释下也能获得强大的结果。
相关工作
3D Vision-language Learning 3D视觉语言学习
在这一新兴领域,Chen等人[8]和Achlioptas等人[1]同时引入了scanreference和ReferIt3D数据集,用于对自然语言基于3D对象属性和关系进行基准测试。除了3D视觉基础,Azuma等人[3]开发了一个名为ScanQA的3D问答数据集,该数据集需要一个模型来回答关于给定3D场景的物体及其关系的问题。最近,Ma等人[36]提出了一种称为SQA3D的情境推理任务,用于3D场景中的具体化场景理解。
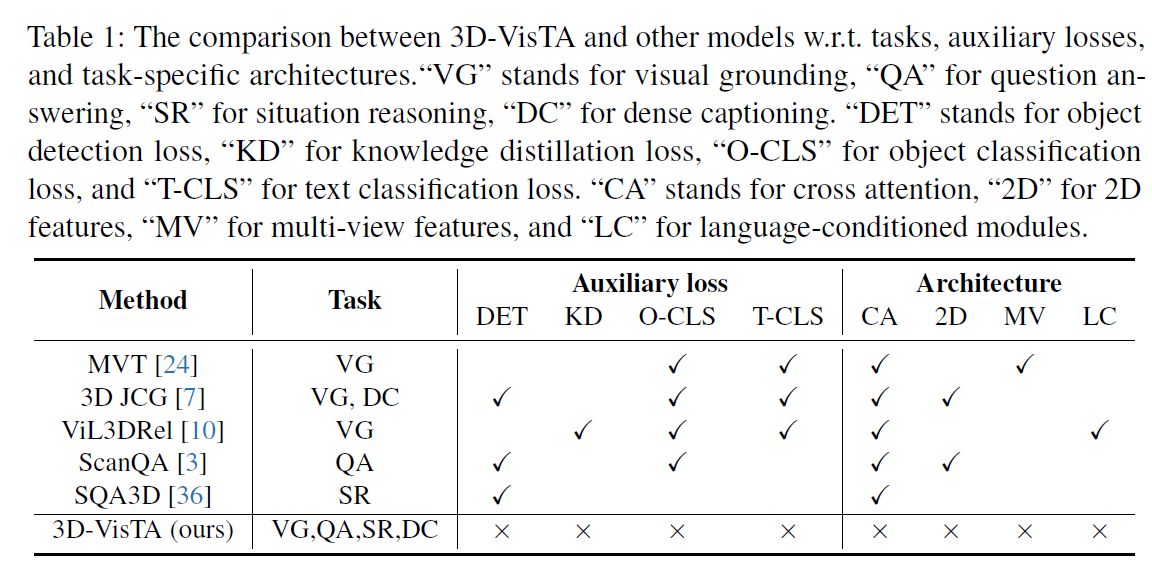
针对这些基准[8,1,35,27,55,24,10,20,43]几个模型已经提出了。值得注意的是,3D-SPS[35]和BUTD-DETR[27]利用交叉注意机制和语言引导逐步发现目标对象。3DVG[55]、MVT[24]和ViL3DRel[10]通过将空间关系信息明确地注入其模型来解决3D视觉接地问题。尽管这些工作在连接3D视觉和语言方面取得了令人印象深刻的成果,但它们仍然严重依赖于模型设计中的特定任务知识[55,24,10]和复杂的优化技术[10,27,35]。相比之下,我们的3D-VisTA通过一个简单的基于transformer的架构统一了视觉基础、问答和定位推理。训练3D-VisTA也很简单,不需要任何辅助损失或复杂的优化技术。3DVisTA与其他3D-VL模型在任务、辅助Loss、架构等方面的详细对比见表1。
Large-scale Pre-training 大规模预训练
近年来,大规模预训练已成为自然语言处理(NLP)、计算机视觉(CV)和2D视觉与语言(2D- vl)领域的基石。引入基于transformer的架构[47],特别是BERT[15]和GPT[41,42,6],已经导致了各种NLP任务的显着改进。这些模型的成功导致了更先进的预训练技术的发展,如XLNet[52]和RoBERTa[31]。这些模型在广泛的NLP任务上取得了最先进的性能,包括文本分类、问题回答和语言生成。CV中最成功的预训练方法是ImageNet[14]预训练,它已被用作广泛的下游任务(如目标检测和图像分割)的起点。最近,引入基于transformer的模型,如ViT[17]和Swin Transformer[32],已经导致各种CV任务的显着改进。
由于预训练技术,2D-VL领域也取得了重大进展。
特别是ViLBERT[34]和LXMERT[45]模型的引入,在视觉问答和图像字幕等任务上取得了最先进的性能。最近,CLIP的发展[40],ALIGN[50]和Flamingo[2]表明,对图像-文本对进行大规模预训练可以更好地进行跨模态理解,并以zero-shot 或few-shot的方式出现上下文学习。
大规模预训练在3D-VL中却很少被探索。[7,9]探索了视觉基础和密集字幕的多任务学习,然后在每个任务上进一步微调他们的模型。由于缺乏大规模的预训练数据集,3D-VL预训练的探索可能会受到阻碍。因此,我们构建了ScanScribe,这是第一个用于3D- vl预训练的大规模3D场景文本对数据集。
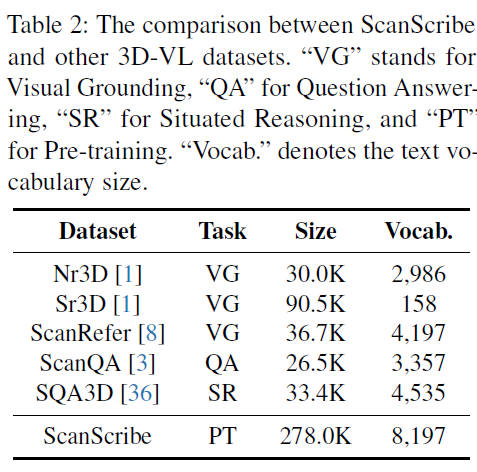
如表2所示,ScanScribe比现有的3D-VL数据集大得多,文本也更多样化。在ScanScribe上预训练3D-VisTA已经导致了3D-VL任务的显着改进,因此我们相信ScanScribe可以在未来推动3D-VL预训练的探索。
方法
3D-VisTA
如图2所示,3D-VisTA以一对场景点云和句子作为输入。首先通过文本编码模块对句子进行编码,然后通过场景编码模块对点云进行处理。然后通过多模态融合模块将文本和3D对象标记融合,以捕获3D对象和文本之间的对应关系。3D-VisTA使用自我监督学习进行预训练,可以很容易地对各种下游任务进行微调。
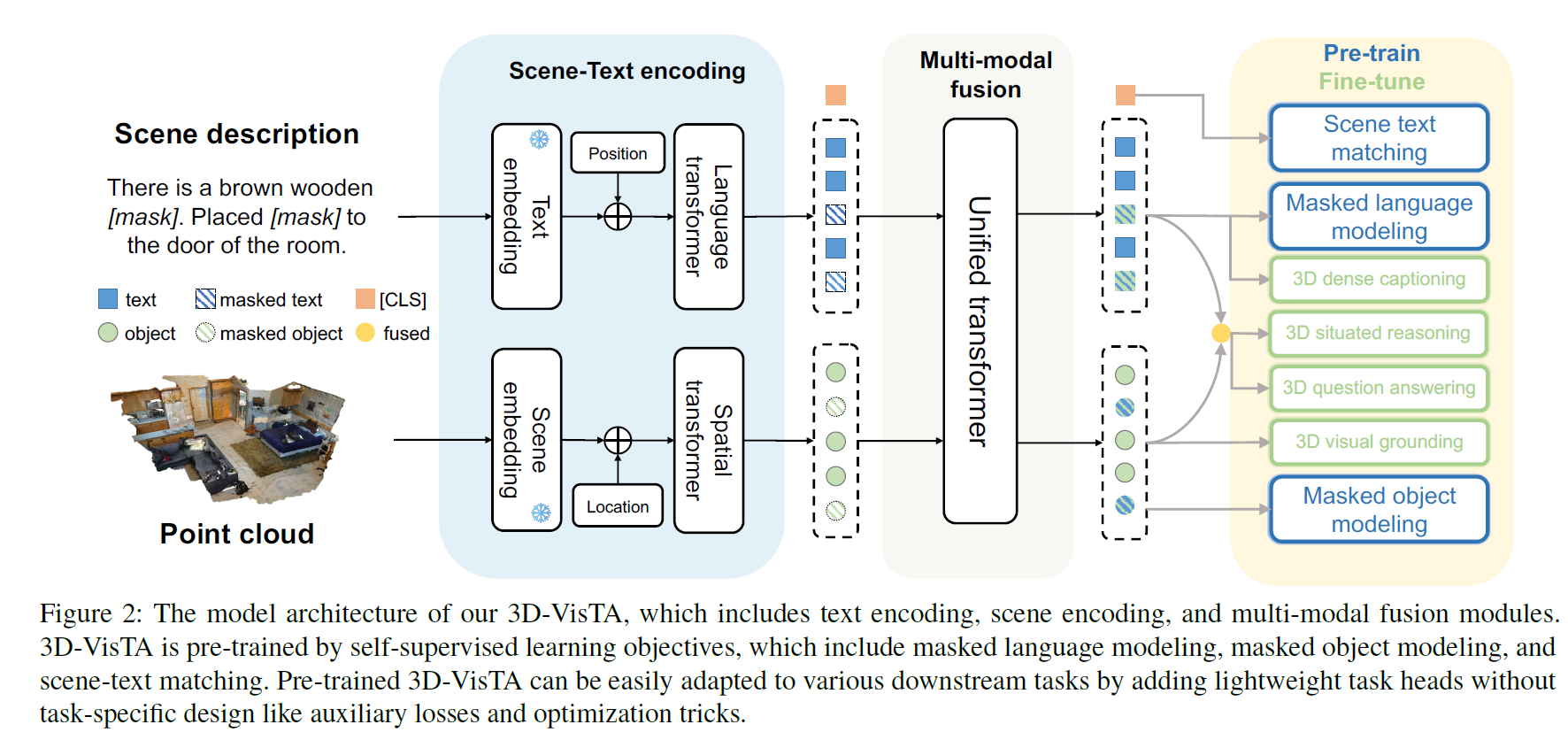
Text Encoding 文本编码
我们采用四层Transformer将句子S编码为文本标记{wcls,w1,w2,···,wM}序列,其中wcls为特殊分类标记([CLS]), M为句子长度。该文本编码模块由预训练BERT的前四层进行初始化[15]。?
Scene Encoding 场景编码
给定一个3D场景的点云,我们首先使用分割蒙版将场景分解成一包(bag)物体。
分割掩码既可以从ground truth中获得,也可以从实例分割模型中获得[16,28,44]。
1)对于每个对象,我们采样1024个点,并将其坐标归一化为单位球。
2)将目标点云输入PointNet++[39]获取其点特征和语义类。我们将点特征fi、嵌入语义类ci和位置li(即3D位置、长度、宽度、高度)组合为对象标记i的表示。其中Wc和Wl是附加的投影矩阵,将ci和li映射到与fi相同的维度↓
![]()
3)为了进一步提供对象的上下文表示,我们通过将对象token注入四层Transformer来捕获对象到对象的交互。受前人研究[55,24,10]的启发,我们将对象的成对空间关系明确编码到Transformer中(图2中的spatial Transformer)。
我们按照[10]定义了对象对i, j的成对空间特征↓
其中dij是欧几里得距离θh, θv是连接两个物体i,j中心的直线的水平线和对顶角
![]()
两两空间特征S = [sij]∈RN×N×5用于调节Transformer中自关注层的关注权重:
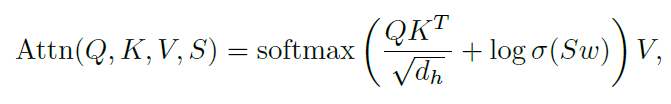
其中w∈R5用于将空间特征映射到注意分数,σ为sigmoid函数。
Multi-modal Fusion 多模态融合
我们简单地将文本和3D对象标记连接起来(?如何连接?直接相加还是相乘?看代码),并将它们发送到l层变压器(图2中的统一变压器)进行多模态融合。可学习的type embeddings 被添加到token中,以区分文本和3D对象。对于[CLS]、文本标记和3D对象标记,我们将多模态融合模块的输出分别表示为{wcls,w1:M, o1:N}。
Self-supervised Pre-training 自监督预训练
为了以自监督的方式学习3D场景和文本对齐,我们通过以下代理任务对3D- vista进行3D场景-文本对的预训练:
Masked Language Modeling (MLM)
Masked Object Modeling (MOM)
Scene-Text Matching (STM)
Downstream Task Finetuning
预训练的3D-VisTA可以很容易地适应各种
3D-VL任务通过添加轻量级任务头。更具体地说,我们在以下任务上微调3D-VisTA↓
3D Visual Grounding
3D Dense Captioning
3D Question Answering
3D Situated Reasoning
ScanScribe
scanscribe是我们建立的一个大规模的三维场景文本对数据集
如表3所示,ScanScribe中三维场景文本对的构建包括两部分:
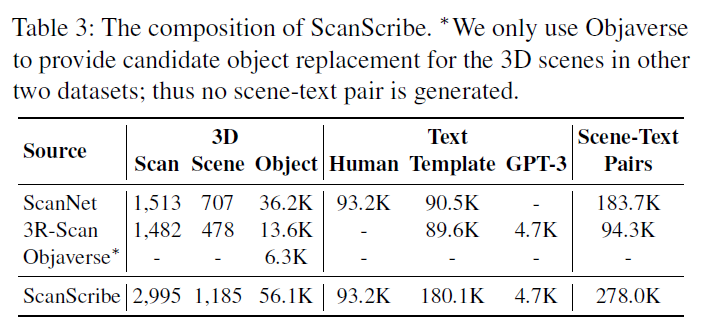
3D场景:
我们从ScanNet[12]和3R-Scan[48]收集室内场景的RGB-D扫描。为了增加这些场景中3D对象的多样性,每个场景中10%的对象实例根据类别随机替换为Objaverse 3D对象数据库[13]中的对象。对于每个ScanNet和3R-Scan对象类别,我们从Objaverse下载大约40个对象实例作为候选对象替换。因此,我们收集了1,185个室内场景的2,995个RGB-D扫描,其中包含56.1K唯一对象实例
文本:
对于来自ScanNet的扫描,我们将基于ScanNet的现有数据集中的文本转换为场景描述,包括来自ScanQA[3]的问答对和来自Scan- reference[8]和refit3d[1]的引用表达式。对于来自3RScan的扫描,我们同时采用模板和GPT-3[6],基于它们的场景图注释生成场景描述[51]。
具体地说,对于每个对象,我们首先从场景图中提取所有的〈object, relation, neighbor〉三元组。然后我们使用模板“This is a object, a neighbor is relation to object” 来生成描述。
注意,在基于模板的生成中,我们只选择邻居少于7个的对象。
我们进一步探索使用GPT-3生成带有如下提示“object is relation to neighbor...(repeat until all the neighbors have been used). Where is object? or Summarize the scene.”最终,对收集到的3D场景生成278K的场景描述。
这个貌似就可以解决我LISA:通过大语言模型进行推理分割_Scabbards_的博客-CSDN博客中如何用gpt3生成/改写提示的疑问了
实验
实现细节
预训练运行30个epoch,批大小为128。
AdamW[33]优化器,β1 = 0.9, β2 = 0.98。学习率设为1e−4,预热3000步,余弦衰减。
在预训练过程中,我们使用ground-truth segmentation masks生成对象级点云。
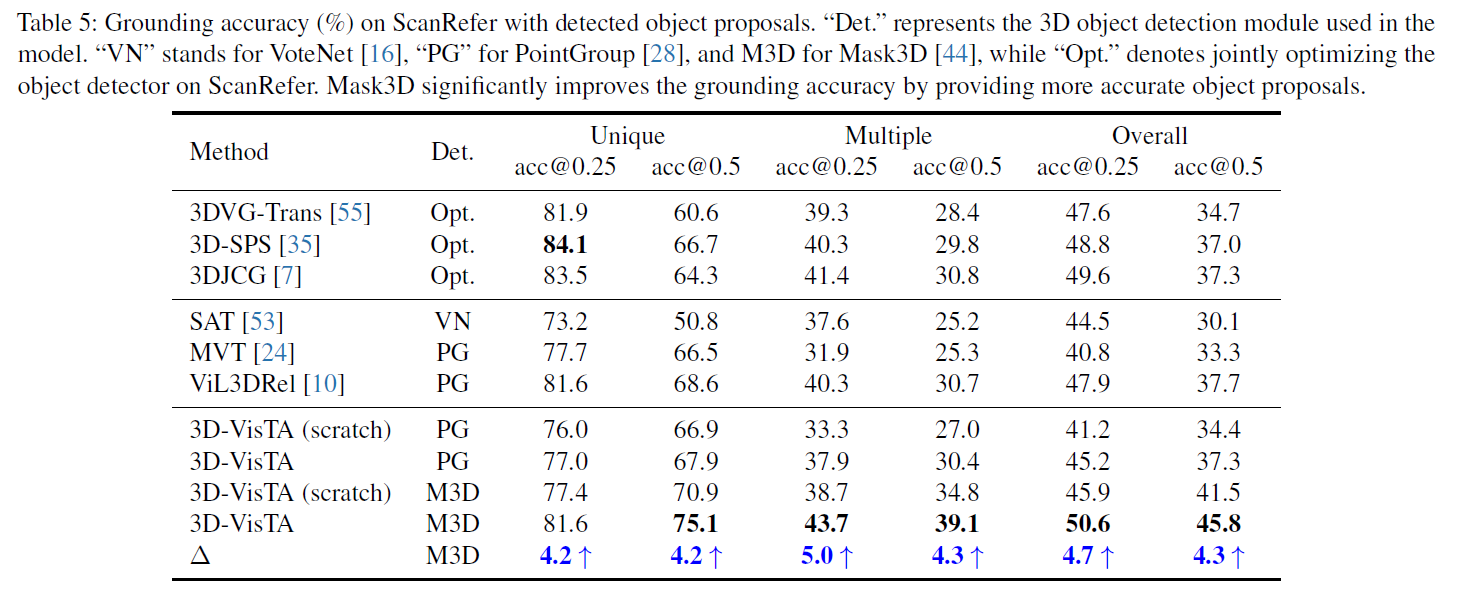
在微调过程中,我们使用ground-truth mask或Mask3d[44],这取决于任务设置。在scanreference数据集上,我们还合并了PointGroup[28]与之前的方法进行比较。
在消融实验中,为了简单起见,我们在所有任务中都使用ground-truth masks。
预训练和微调都在单个NVIDIA A100 80GB GPU上进行。
实验结果
1.即使从头开始训练,3D-VisTA也可以通过SOTA方法获得具有竞争力的性能。
2.ScanScribe上的预训练显着提高了3D-VisTA的性能。
3.预训练的3D-VisTA在性能上大大优于SOTA。
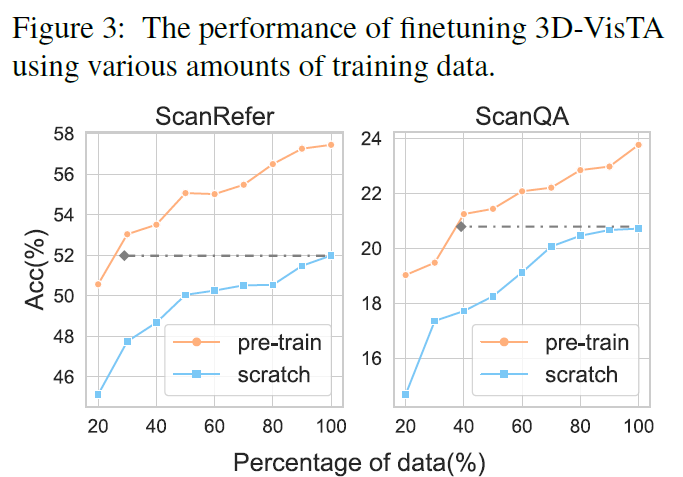
4.在有限注释的下游任务上微调3D-VisTA可以获得强大的结果。


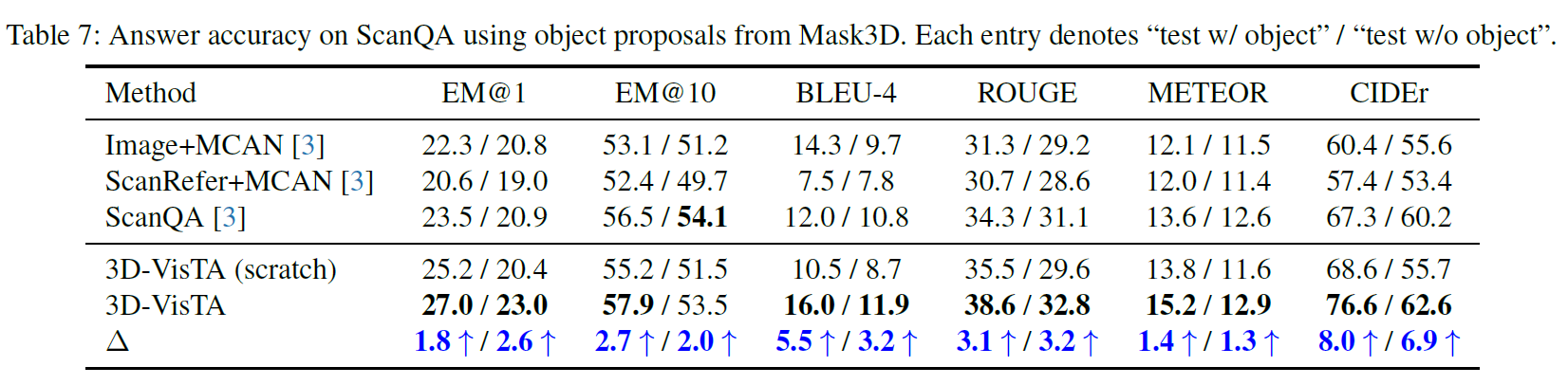
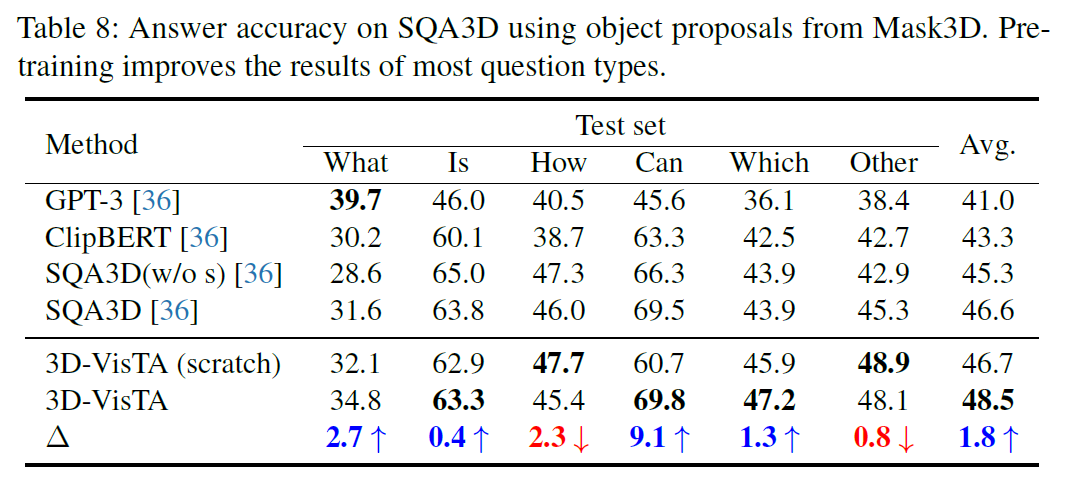
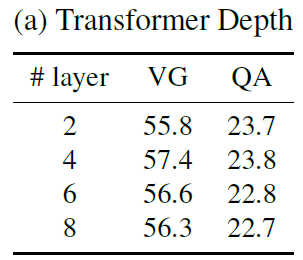
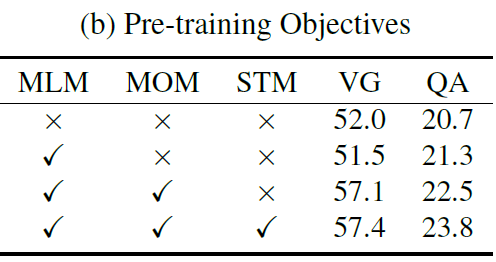
消融实验
Transformer Depth
Pre-training Objectives
Pre-training Data
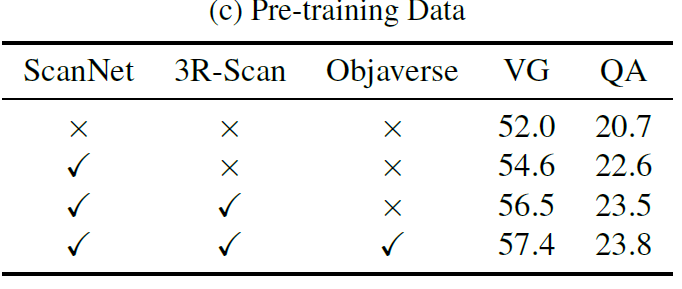
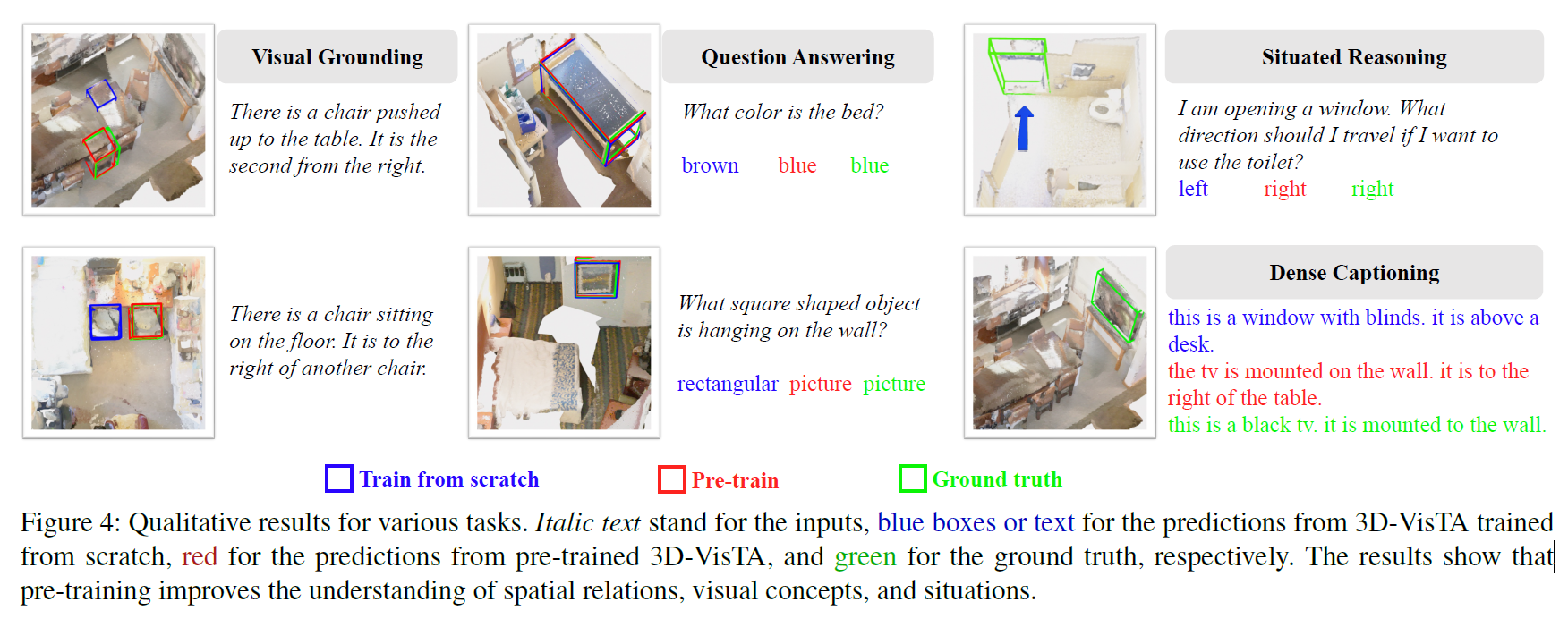
定性研究和附加结果
我们进行额外的研究,以更好地理解预训练是如何帮助的。
如图4所示,预训练提高了3D-VisTA在视觉基础上的空间理解能力,使其更符合人类对空间关系的先验观点和推理。当模型需要将目标对象与同一类的多个实例区分开来时,这非常有用。预训练还有助于更好地理解颜色和形状等视觉概念,以及回答问题和情境推理的情况。
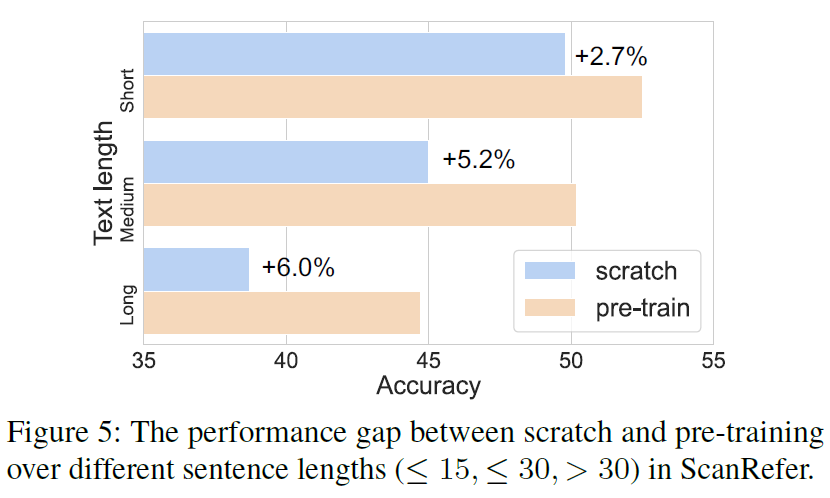
此外,预训练增强了长文本与3D场景对齐的能力,如图5所示,较长查询的改进幅度更大。
未来工作
目前,3D- vista使用离线3D物体检测模块,这可能是进一步改进的瓶颈。在预训练阶段共同优化目标检测模块是一个有趣的未来方向。此外,对于大规模3D-VL预训练,ScanScribe的数据量仍然不足,因此,扩大预训练数据集和模型大小是进一步提高3D-VL学习的一个有希望的方向。
相关文章:
3D- vista:预训练的3D视觉和文本对齐Transformer
论文:https://arxiv.org/abs/2308.04352 代码: GitHub - 3d-vista/3D-VisTA: Official implementation of ICCV 2023 paper "3D-VisTA: Pre-trained Transformer for 3D Vision and Text Alignment" 摘要 三维视觉语言基础(3D- vl)是一个新兴领域&…...
SAP ABAP 直接把内表转换成PDF格式(smartform的打印函数输出OTF格式数据)
直接上代码: REPORT zcycle055.DATA: lt_tab TYPE TABLE OF zpps001. DATA: ls_tab TYPE zpps001.ls_tab-werks 1001. ls_tab-gamng 150.00. ls_tab-gstrp 20201202. ls_tab-aufnr 000010000246. ls_tab-auart 标准生产. ls_tab-gltrp 20201205. ls_tab-matn…...
侯捷 C++ part2 兼谈对象模型笔记——7 reference、const、new/delete
7 reference、const、new/delete 7.1 reference x 是整数,占4字节;p 是指针占4字节(32位);r 代表x,那么r也是整数,占4字节 int x 0; int* p &x; // 地址和指针是互通的 int& r x;…...

C++学习笔记总结练习:primer 学习日志
文章目录 针对自己的引言学习内容c语言基础知识1.为什么要声明变量2.cout ,cin3.c 不容许一个函数定义嵌套到另一个函数的定义中。4.编译指令using5.c基本类型长度6.在定义常量时尽可能使用const 关键字而不用#define9.前缀递增符与后缀递增符的区别10.c中的cctype库11.c 中的s…...
发布一个开源的新闻api(整理后就开源)
目录 说明: 基础说明 其他说明: 通用接口: 登录: 注册: 更改密码(需要token) 更换头像(需要token) 获取用户列表(需要token): 上传文件(5000端口): 获取文件(5000端口)源码文件,db文件均不能获取: 验证token(需要token): 获取系统时间: 文件…...

3d max省时插件CG MAGIC功能中的材质参数可一键优化!
渲染的最终结果就是为了让渲染效果更加真实的体现。 对于一些操作上,可能还是费些时间,VRay可以说是在给材质做加法的路上越走越远,透明度、凹凸、反射等等参数细节越做越多。 对于材质参数调节的重要性大家都心里有数的。 VRay材质系统的每…...

什么是变量提升(hoisting)?它在JavaScript中是如何工作的?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 变量提升(Hoisting)⭐ 变量提升的示例:⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅&…...

.git内存清理方式
查看前15个大文件 git rev-list --objects --all | grep "$(git verify-pack -v .git/objects/pack/*.idx | sort -k 3 -n | tail -15 | awk {print$1})"删除文件夹(public/housimg文件夹目录) git filter-branch --tree-filter rm -rf publ…...

i.MX6ULL开发板无法进入NFS挂载文件系统的解决办法
问题 使用NFS网络挂载文件系统后卡住无法进入系统。 解决办法 此处不详细讲述NFS安装流程 查看板卡挂载在/home/etc/rc.init下的自启动程序 进入到../../home/etc目录下,查看rc.init文件,首先从第一行排查,查看/home/etc/netcfg文件代码内容&…...

七夕特辑——3D爱心(可监听鼠标移动)
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...
C++函数模板和类模板
C另一种编程思想称为泛型编程,主要利用的技术是模板 C提供两种模板机制:函数模板和类模板 C提供了模板(template)编程的概念。所谓模板,实际上是建立一个通用函数或类, 其类内部的类型和函数的形参类型不具体指定, 用…...

【Unity】编辑器下查找制定文件下的所有特定资源
需求上很简单,就是在编辑器下,找到某个制定文件下的所有特定资源(UnityEngine.Object)。Unity 没有提供专门的 API,我一开始想在网上搜索代码,发现没有现成可以直接用的。 功能实现本身并不复杂,…...
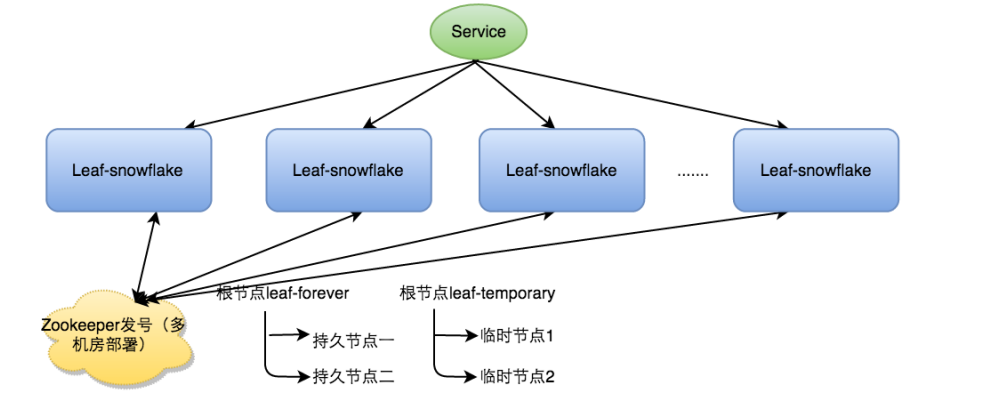
分布式唯一ID实战
目录 一、UUID二、数据库方式1、数据库生成之简单方式2、数据库生成 - 多台机器和设置步长,解决性能问题3、Leaf-segment 方案实现4、双 buffer 优化5、Leaf高可用容灾 三、基于Redis实现分布式ID四、雪花算法1、雪花算法介绍2、 雪花算法生产环境架构:3…...

el-element日期时间组件限制可选时间范围
<el-date-pickerv-model"formData.meetingTime"type"datetime"value-format"yyyy-MM-dd HH:mm:ss"style"width: 100%"placeholder"请选择日期"clearable:picker-options"pickerOptions"></el-date-picke…...

【李沐】3.3线性回归的简洁实现
1、生成数据集 import numpy as np import torch from torch.utils import data from d2l import torch as d2l true_w torch.tensor([2, -3.4]) # 定义真实权重 true_w,其中 [2, -3.4] 表示两个特征的权重值 true_b 4.2 # 定义真实偏差 true_b,表示…...

Ghost-free High Dynamic Range Imaging withContext-aware Transformer
Abstract 高动态范围(HDR)去鬼算法旨在生成具有真实感细节的无鬼HDR图像。 受感受野局部性的限制,现有的基于CNN的方法在大运动和严重饱和度的情况下容易产生重影伪影和强度畸变。 本文提出了一种新的上下文感知视觉转换器(CA-VIT)用于高动态…...

过来,我告诉你个秘密:送给程序员男友最好的礼物,快教你对象学习磁盘分区啦!小点声哈,别让其他人学会了!
[原文连接:来自给点知识](过来,我告诉你个秘密:送给程序员男友最好的礼物,快教你对象学习磁盘分区啦!小点声哈,别让其他人学会了!) 再唱不出那样的歌曲 听到都会红着脸躲避 虽然会经常忘了我依然爱着你 …...

Cadence+硬件每日学习十个知识点(38)23.8.18 (Cadence的使用,界面介绍)
文章目录 1.Cadence有共享数据库的途径2.Cadence启动3.Cadence界面菜单简介(file、edit、view、place、options)4.Cadence界面的图标简介5.我的下载资源有三本书 1.Cadence有共享数据库的途径 答: AD缺少共享数据库的途径,目前我…...
React Native Expo项目,复制文本到剪切板
装包: npx expo install expo-clipboard import * as Clipboard from expo-clipboardconst handleCopy async (text) > {await Clipboard.setStringAsync(text)Toast.show(复制成功, {duration: 3000,position: Toast.positions.CENTER,})} 参考链接:…...
React源码解析18(5)------ 实现函数组件【修改beginWork和completeWork】
摘要 经过之前的几篇文章,我们实现了基本的jsx,在页面渲染的过程。但是如果是通过函数组件写出来的组件,还是不能渲染到页面上的。 所以这一篇,主要是对之前写得方法进行修改,从而能够显示函数组件,所以现…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...
)
安卓基础(aar)
重新设置java21的环境,临时设置 $env:JAVA_HOME "D:\Android Studio\jbr" 查看当前环境变量 JAVA_HOME 的值 echo $env:JAVA_HOME 构建ARR文件 ./gradlew :private-lib:assembleRelease 目录是这样的: MyApp/ ├── app/ …...