大文本的全文检索方案附件索引
一、简介
Elasticsearch附件索引是需要插件支持的功能,它允许将文件内容附加到Elasticsearch文档中,并对这些附件内容进行全文检索。本文将带你了解索引附件的原理和使用方法,并通过一个实际示例来说明如何在Elasticsearch中索引和检索文件附件。
索引附件的核心原理是通过Ingest Attachment Processor将文件内容转换成Elasticsearch文档中的字段。该插件使用Apache Tika来提取文档中的附件内容,并将其转换为可索引的文本。
二、环境
version: '3.8'
services:cerebro:image: lmenezes/cerebro:0.8.3container_name: cerebroports:- "9000:9000"command:- -Dhosts.0.host=http://eshot:9200networks:- elastickibana:image: docker.elastic.co/kibana/kibana:8.1.3container_name: kibanaenvironment:- I18N_LOCALE=zh-CN- XPACK_GRAPH_ENABLED=true- TIMELION_ENABLED=true- XPACK_MONITORING_COLLECTION_ENABLED="true"- ELASTICSEARCH_HOSTS=http://eshot:9200- server.publicBaseUrl=http://192.168.160.234:5601ports:- "5601:5601"networks:- elasticeshot:image: elasticsearch:8.1.3container_name: eshotenvironment:- node.name=eshot- cluster.name=es-docker-cluster- discovery.seed_hosts=eshot,eswarm,escold- cluster.initial_master_nodes=eshot,eswarm,escold- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"- xpack.security.enabled=false- node.attr.node_type=hotulimits:memlock:soft: -1hard: -1volumes:- D:\zuiyuftp\docker\es8.1\eshot\data:/usr/share/elasticsearch/data- D:\zuiyuftp\docker\es8.1\eshot\logs:/usr/share/elasticsearch/logs- D:\zuiyuftp\docker\es8.1\eshot\plugins:/usr/share/elasticsearch/pluginsports:- 9200:9200networks:- elasticeswarm:image: elasticsearch:8.1.3container_name: eswarmenvironment:- node.name=eswarm- cluster.name=es-docker-cluster- discovery.seed_hosts=eshot,eswarm,escold- cluster.initial_master_nodes=eshot,eswarm,escold- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"- xpack.security.enabled=false- node.attr.node_type=warmulimits:memlock:soft: -1hard: -1volumes:- D:\zuiyuftp\docker\es8.1\eswarm\data:/usr/share/elasticsearch/data- D:\zuiyuftp\docker\es8.1\eswarm\logs:/usr/share/elasticsearch/logs- D:\zuiyuftp\docker\es8.1\eshot\plugins:/usr/share/elasticsearch/pluginsnetworks:- elasticescold:image: elasticsearch:8.1.3container_name: escoldenvironment:- node.name=escold- cluster.name=es-docker-cluster- discovery.seed_hosts=eshot,eswarm,escold- cluster.initial_master_nodes=eshot,eswarm,escold- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"- xpack.security.enabled=false- node.attr.node_type=coldulimits:memlock:soft: -1hard: -1volumes:- D:\zuiyuftp\docker\es8.1\escold\data:/usr/share/elasticsearch/data- D:\zuiyuftp\docker\es8.1\escold\logs:/usr/share/elasticsearch/logs- D:\zuiyuftp\docker\es8.1\eshot\plugins:/usr/share/elasticsearch/pluginsnetworks:- elastic# volumes:
# eshotdata:
# driver: local
# eswarmdata:
# driver: local
# escolddata:
# driver: localnetworks:elastic:driver: bridge三、安装 ingest-attachment 插件
首先创建一个处理文本的管道,指定读取文档中content字段的内容进行处理
PUT _ingest/pipeline/attachment
{"description" : "Extract attachment information","processors" : [{"attachment" : {"field" : "content"}}]
}
我们的elasticsearch版本是8.1,所以默认还是没有内置的,需要手动添加一下,因为我是docker启动的,所以进入到docker容器内部,执行如下命令进行安装
./bin/elasticsearch-plugin install ingest-attachment
安装完成之后进行重启elasticsearch集群进行激活插件的启用
我这边是三个节点,在hot节点下安装完成之后只会在当前节点下有此插件
现在插件已经安装好了,继续执行刚才的定义文本处理通道进行创建
PUT _ingest/pipeline/attachment
{"description" : "Extract attachment information","processors" : [{"attachment" : {"field" : "content"}}]
}
在上面的定义中指定的attachment的过滤字段是content,所以我们在写入elasticsearch索引内容时,文件的内容需要保存到content字段中
四、添加测试数据
下面我们创建一个保存文档详细信息的索引,比如文件题名,类型,文件内容等字段
PUT /zfc-doc-000003
{"mappings": {"properties": {"id":{"type": "keyword"},"title":{"type": "text","analyzer": "ik_max_word"},"content": {"type": "text","analyzer": "ik_max_word"}}}
}
通过上面两步的操作之后我们的测试环境就算搭建完成了,下面就可以进行大文本内容的读取测试了,首先我们还是准备几个测试的文本文件,比如txt,doc,pdf等类型的纯文本文件
下面使用python脚本写入索引内容,首先安装一下elasticsearch的相关依赖
pip install elasticsearch
下面是读取文件夹C://Users//zuiyu//Documents//mydoc//20230806//demo//1下的所有文本文件保存到elasticsearch的索引zfc-doc-000003中的python脚本,保存为txt.py后面会用到
import os
from elasticsearch import Elasticsearch
import base64
# 定义Elasticsearch客户端连接
es = Elasticsearch("http://localhost:9200")
# 定义索引名称
index_name = "zfc-doc-000003"
# 定义文件夹路径
folder_path = "C://Users//zuiyu//Documents//mydoc//20230806//demo//1"
# 遍历文件夹下的所有文件
for root, dirs, files in os.walk(folder_path):
for filename in files:
# 构建文件的完整路径
file_path = os.path.join(root, filename)
# 读取文件内容,并以字节类型(bytes-like)返回
with open(file_path, "rb") as file:
file_content = file.read()
# 使用base64.b64encode()函数将文件内容转换为base64编码
base64_content = base64.b64encode(file_content).decode("utf-8")
# 构建索引文档
document_body = {
"title": filename, # 使用文件名作为文档标题
"content": base64_content # 将base64编码后的内容保存到字段 "content" 中
}
# 执行索引操作,并指定pipeline为 "attachment"
es.index(index=index_name, body=document_body, pipeline="attachment")
print("所有文件已成功保存到Elasticsearch索引中。")
该脚本中需要注意的点有如下三个
1、elasticsearch服务器地址
2、需要读取的文件夹地址
3、保存的索引名称与保存文本内容的字段名称
4、指定创建的pipeline
C://Users//zuiyu//Documents//mydoc//20230806//demo//1文件夹下有三个文件用来做测试,他们的文本内容分别如下图所示
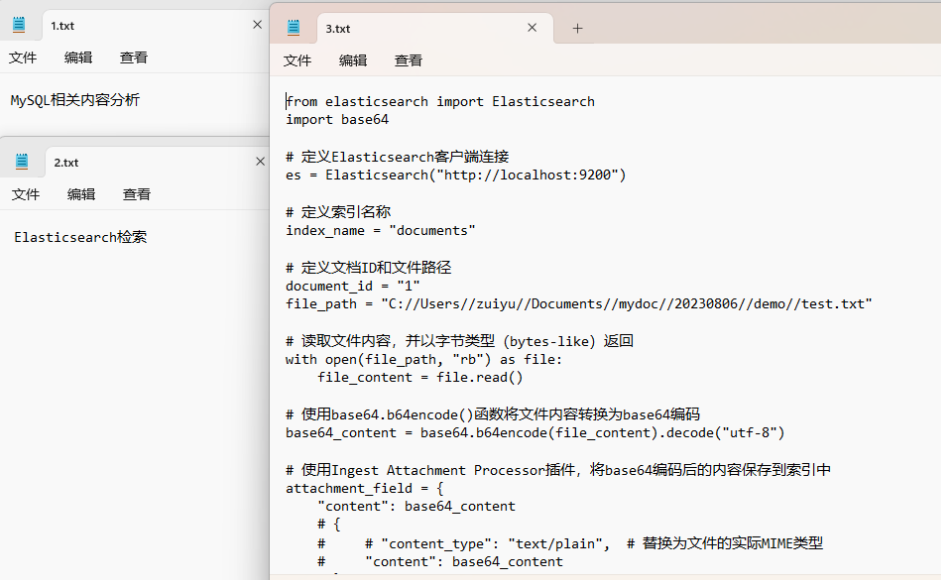
其中为了方便测试,1.txt与2.txt仅有一句话
下面执行python脚本txt.py保存到elasticsearch的zfc-doc-000003中,并指定使用pipeline为attachment
python txt.py
脚本执行成功之后的截图如下图所示,输出所有文件已成功保存到Elasticsearch索引中。即为成功导入

下面我们进行检索验证,因为上面咱们创建的索引中,文本内容是保存到content字段中的,所以我们对content字段进行分词检索(content使用的是ik分词器,不是很了解的可以参考之前的文章进行一下安装)
1、首先检索条件是内容,预期结果是返回第一个文档与第三个文档
2、再次检索mysql,返回第一个文档
通过上面两个小例子,可以验证出来的结论就是,我们在文本内容过大需要对内容进行检索时,可以使用提前指定的pipeline进行预处理
五、设置读取文本范围
在Elasticsearch中,Ingest Attachment Processor插件的indexed_chars参数默认值是100000,表示将文本内容的前100000保存在索引字段中
如果将其设置为-1,Elasticsearch会保存所有文本内容。这可能会导致索引文档过大,对性能和资源造成影响,特别是当处理大文本时。
为了避免索引文档过大的问题,我们可以根据实际情况设置indexed_chars参数,将其设置为较小的值,限制保存的字符数。这样可以减小索引文档的大小,降低Elasticsearch的负担。
假如限制保存的字符数为50000,可以如下设置:
PUT _ingest/pipeline/attachment
{
"description": "Pipeline for processing attachments",
"processors": [
{
"attachment": {
"field": "content",
"indexed_chars": 50000
}
}
]
}
这样,只有前50000个字符会被保存在content字段中,而超过这个字符数的部分则会被截断,不会保存在索引中。
如果想单独设定某个文档的取值范围,也可以在索引的文档中指定字段值,举例如下
PUT _ingest/pipeline/attachment_max
{"description" : "Extract attachment information","processors" : [{"attachment" : {"field" : "content","indexed_chars": 6,"indexed_chars_field" : "max_size",}}]
}
PUT /zfc-doc-000005
{"mappings": {"properties": {"id":{"type": "keyword"},"title":{"type": "text","analyzer": "ik_max_word"},"content": {"type": "text","analyzer": "ik_max_word"}}}
}
POST zfc-doc-000005/_doc?pipeline=attachment_max
{"id":"10",
"content":"5Litc2FkZ+eahOmqhOWCsuWIu+W9leacuuWNoea0m+aWr+Wkp+iSnOS7t+agvOWWgOS7gOinieW+l+aWr+WNoeaLiemjkuWNjg==","max_size":10
}
POST zfc-doc-000005/_doc?pipeline=attachment_max
{"id":"11","content":"5Litc2FkZ+eahOmqhOWCsuWIu+W9leacuuWNoea0m+aWr+Wkp+iSnOS7t+agvOWWgOS7gOinieW+l+aWr+WNoeaLiemjkuWNjg=="
}
GET zfc-doc-000005/_search
{"query": {"term": {"id": {"value": "11"}}}
}
使用"indexed_chars_field" : "max_size",指定文档中的字段,根据文档中的max_size字段来决定要取多少文本索引到字段中,如果文档中没有指定max_size则使用pipeline中指定的indexed_chars大小
六、移除二进制源文本
除了使用上述指定读取文本文件的指定长度,还可以使用另一个参数 "remove_binary": true控制来判断是否保存二进制编码的文本
PUT _ingest/pipeline/attachment_max
{"description" : "Extract attachment information","processors" : [{"attachment" : {"field" : "content","remove_binary": true}}]
}
remove_binary 设置为true即不保存原始二进制文本,只会保存解析之后的结果,这种处理方式可以大大的减少存储空间
七、优点
-
轻量化索引文档:使用Ingest Attachment Processor处理文本内容时,只会将文本的元数据(例如文件路径或URL)以及转换后的attachment类型的内容保存在索引文档中,而不是保存整个文本内容。这样可以显著减小索引文档的大小,节省存储空间,并提高索引和检索的性能。
-
全文搜索功能:通过Pipeline中的Ingest Attachment Processor处理文本内容后,Elasticsearch可以支持全文搜索功能,可以对文本进行全文检索,查找包含指定关键词的文档。
-
灵活的数据处理:Pipeline机制允许在文本内容存储到Elasticsearch之前进行预处理。可以通过Pipeline添加其他处理器来进行数据转换、清理或提取。
-
易于维护和扩展:使用Pipeline可以将数据处理逻辑与索引操作解耦,使代码结构更清晰,易于维护和扩展。如果以后有其他数据处理需求,只需要修改Pipeline而不需要修改索引操作。
-
可以实现附件类型:使用Ingest Attachment Processor可以将文本内容转换为attachment类型,这是Elasticsearch内置的一种特殊数据类型,支持对文档内容的索引和全文检索。
八、缺点
-
存储需求:虽然使用attachment类型可以减小索引文档的大小,但是仍然需要在Elasticsearch中存储文本内容的转换结果。对于大量大文本内容的情况,仍需要较大的存储空间,并且最好使用
"remove_binary": true移除二进制文本。 -
内存消耗:在处理大文本内容时,Ingest Attachment Processor需要将文本内容暂存到内存中进行处理,因此会消耗较多的内存资源。如果处理大量大文本,可能导致内存压力增加,影响性能。
-
处理性能:虽然使用Pipeline可以在索引之前进行预处理,但Ingest Attachment Processor的处理速度仍然会受到限制。在处理大量大文本内容时,可能导致处理速度较慢,影响索引性能。
-
不适用于实时场景:由于Ingest Attachment Processor处理文本内容需要较多的计算和存储资源,适用于离线或批处理的场景。对于实时索引或对性能要求较高的场景,可能需要考虑其他方案。
-
不支持所有文件类型:虽然attachment类型支持多种文件类型,但仍有一些特殊文件类型可能不受支持。在使用Pipeline中的Ingest Attachment Processor处理文本内容时,需要注意文件类型的兼容性。
-
额外的配置和维护:使用Pipeline需要额外的配置和维护,需要定义处理器、设置参数等
-
依赖插件:Ingest Attachment Processor是Elasticsearch的一个插件,需要确保插件的版本与Elasticsearch版本兼容
九、总结
使用Pipeline中的Ingest Attachment Processor处理文本内容可以在不影响检索功能的前提下,优化索引文档的大小,提高索引和检索的性能,并灵活地处理和扩展数据。这是处理大文本内容时的一种高效和可靠的方式。虽然Pipeline中的Ingest Attachment Processor处理大文本内容是一种高效和灵活的方式,但仍然存在一些挑战和限制。在实际使用中,需要综合考虑实际需求、资源限制和性能要求,选择合适的处理方案。如果处理大量大文本或对性能要求较高,可能需要考虑其他优化措施或方案。
十、需要注意的点
-
索引性能:处理大文本时,Pipeline的执行可能会占用较多的CPU和内存资源,特别是在处理多个大文本时。这可能会对Elasticsearch的索引性能和整体系统性能造成影响。在处理大文本之前,建议评估系统的性能和资源利用情况,确保系统有足够的资源来执行处理。
-
超时设置:Pipeline的执行可能需要一定的时间,尤其是在处理大文本时。如果Pipeline的执行时间超过了Elasticsearch的默认超时设置,可能会导致任务失败。你可以通过设置
timeout参数来延长超时时间,确保Pipeline有足够的时间来执行。 -
错误处理:在Pipeline的处理过程中,可能会出现各种错误,例如文本解析错误、索引失败等。你需要注意适当处理这些错误,以避免任务失败导致整个操作中断。可以使用适当的异常处理机制,或者使用Elasticsearch的Bulk API来进行批量索引,确保部分文档处理失败时,不会影响其他文档的索引。
-
内存管理:处理大文本时,可能会产生较大的临时数据,需要注意内存的管理和及时释放。确保处理过程中不会产生内存泄漏或内存溢出问题。
-
文件路径安全性:如果使用文件路径来索引文本内容,需要注意文件路径的安全性。确保文件路径是合法的、可信的,并限制访问范围,避免可能的安全风险。
-
版本兼容性:使用Pipeline时,需要注意插件的版本与Elasticsearch的版本兼容性。确保使用的Pipeline插件与Elasticsearch版本兼容,并定期升级插件以保持稳定性和安全性。
总的来说,处理大文本时,需要综合考虑性能、资源利用、错误处理等方面的问题,合理设计和优化Pipeline的处理过程。在实际应用中,可以进行压力测试和性能测试,找到最合适的处理方案,确保系统能够稳定高效地处理大文本内容。
参考链接
https://www.elastic.co/guide/en/elasticsearch/reference/8.9/attachment.html
如果感觉本文对你有所帮助欢迎点赞评论转发收藏。如果你想了解更多关于ES的骚操作,更多实战经验,欢迎关注。
原文链接:
https://mp.weixin.qq.com/s?__biz=MzIwNzYzODIxMw==&mid=2247486041&idx=1&sn=08e3b981c512a8a24afd3778cd3f231a&chksm=970e11f3a07998e5f7bbe017409944e4b57a0d800b2a149f7c291091f5b2b32b6493c3586257#rd
本文由 mdnice 多平台发布
相关文章:
大文本的全文检索方案附件索引
一、简介 Elasticsearch附件索引是需要插件支持的功能,它允许将文件内容附加到Elasticsearch文档中,并对这些附件内容进行全文检索。本文将带你了解索引附件的原理和使用方法,并通过一个实际示例来说明如何在Elasticsearch中索引和检索文件附…...
35_windows环境debug Nginx 源码-CLion配置CMake和启动
文章目录 生成 CMakeLists.txt 组态档35_windows环境debug Nginx 源码-CLion配置CMake和启动生成 CMakeLists.txt 组态档 修改auto目录configure文件,在 . auto/make 上边增加 . auto/cmake, 大概在 106 行。在 auto 目录下创建cmake 文件其内容如下: #!/usr/bin/env bash NG…...

收集的一些比较好的git网址
1、民间故事 https://github.com/folkstory/lingqiu/blob/master/%E4%BC%A0%E8%AF%B4%E9%83%A8%E5%88%86/%E4%BA%BA%E7%89%A9%E4%BC%A0%E8%AF%B4/%E2%80%9C%E6%B5%B7%E5%BA%95%E6%8D%9E%E6%9C%88%E2%80%9D%E7%9A%84%E6%AD%A6%E4%B8%BE.md 2、童话故事 https://gutenberg.org/c…...
容斥原理 博弈论(多种Nim游戏解法)
目录 容斥原理容斥原理的简介能被整除的数(典型例题)实现思路代码实现扩展:用DPS实现 博弈论博弈论中的相关性质博弈论的相关结论先手必败必胜的证明Nim游戏(典型例题)代码实现 台阶-Nim游戏(典型例题&…...
【C++】函数指针
2023年8月18日,周五上午 今天在B站看Qt教学视频的时候遇到了 目录 语法和typedef或using结合我的总结 语法 返回类型 (*指针变量名)(参数列表)以下是一些示例来说明如何声明不同类型的函数指针: 声明一个不接受任何参数且返回void的函数指针…...

VBA技术资料MF45:VBA_在Excel中自定义行高
【分享成果,随喜正能量】可以不光芒万丈,但不要停止发光。有的人陷入困境,不是被人所困,而是自己束缚自己,这时"解铃还须系铃人",如果自己无法放下,如何能脱困? 。 我给V…...

【Git】Git中的钩子
Git Book——Git的自定义钩子 Git中的钩子分为两大类: 1、客户端钩子:由诸如提交和合并这样的操作所调用 2、服务端钩子:由诸如接收被推送的提交这样的联网操作 客户端钩子: 提交工作流钩子 pre-commit:在提交信息前…...
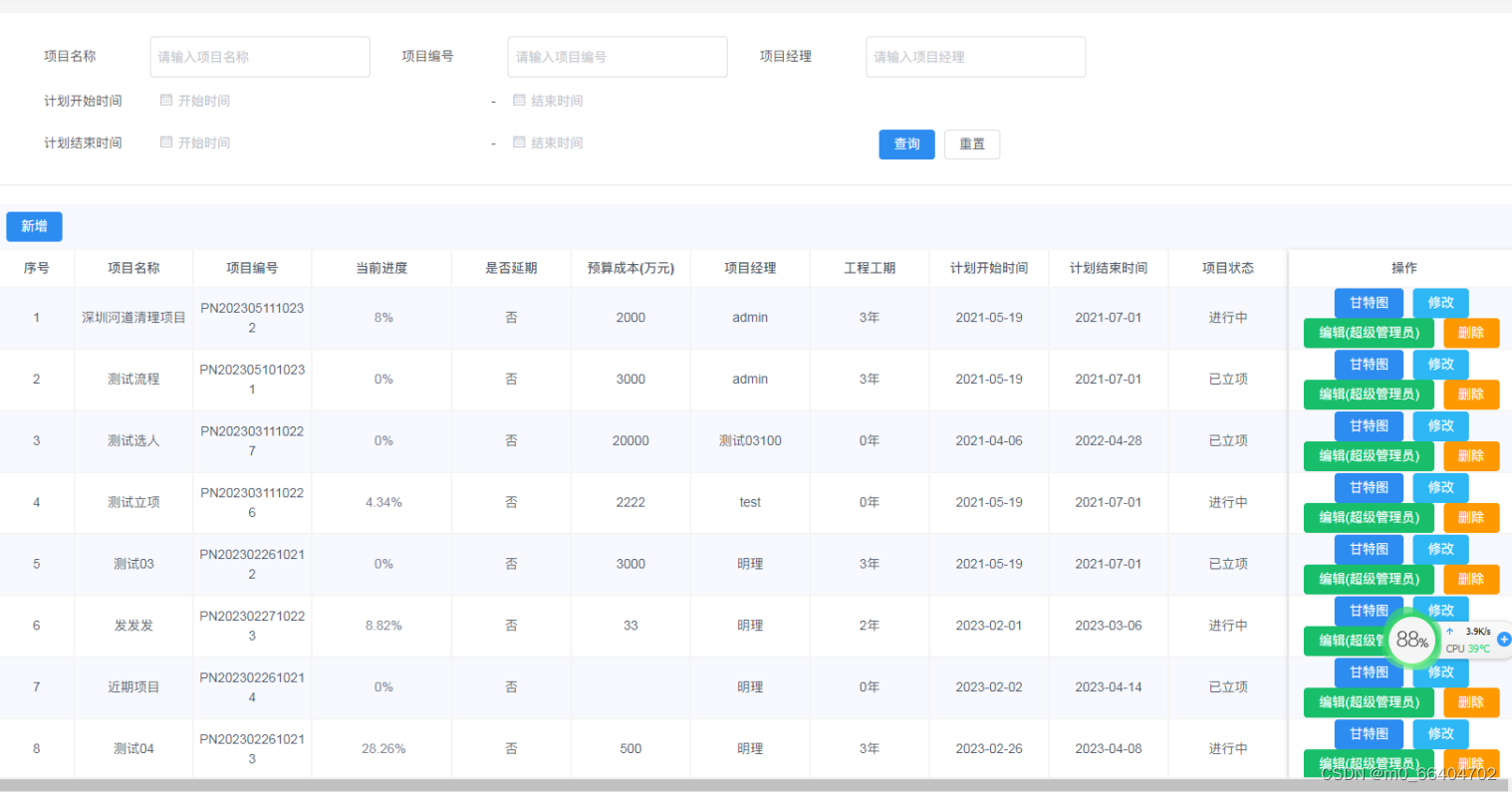
java 工程管理系统源码+项目说明+功能描述+前后端分离 + 二次开发 em
Java版工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离 功能清单如下: 首页 工作台:待办工作、消息通知、预警信息,点击可进入相应的列表 项目进度图表:选择(总体或单个)项目显…...

Java # JVM
一、1.8之前 运行时数据区(进程共享) 运行时常量池为什么要有方法区: jvm完成类装载后,需要将class文件中的常量池转入内存,保存在方法区中为什么是常量: 常量对象操作较多,为了避免频繁创建和…...
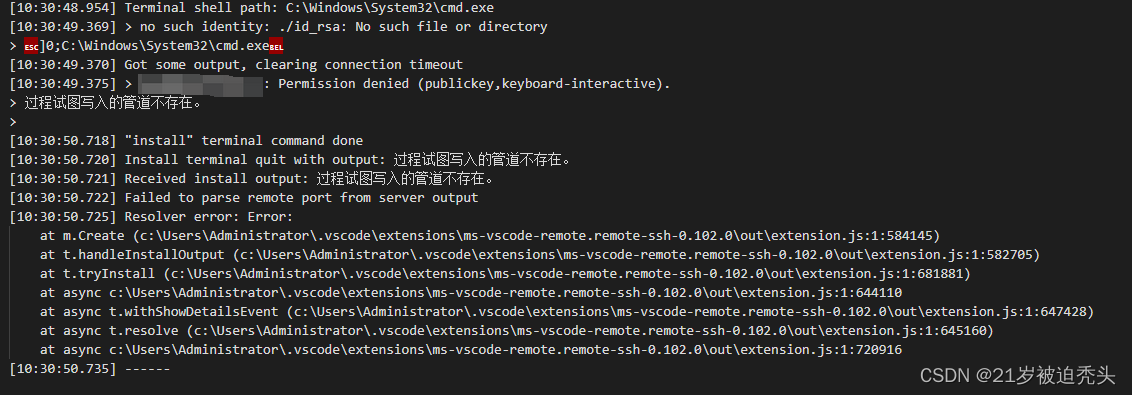
vscode远程连接Linux失败,提示过程试图写入的管道不存在(三种解决办法)
vscode报错如下: 一、第一种情况 原因是本地的known_hosts文件记录服务器信息与现服务器的信息冲突了,导致连接失败。 解决方案就是把本地的known_hosts的原服务器信息全部删掉,然后重新连接。 二、第二种情况 在编写配置文件config时&…...
elaticsearch(1)
1.简介 Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。 Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引…...
使用pnpm workspace管理Monorepo架构
在开发项目的过程中,我们需要在一个仓库中管理多个项目,每个项目有独立的依赖、脚手架,这种形式的项目结构我们称之为Monorepo,pnpm workspace就是管理这类项目的方案之一。 一、pnpm简介 1、pnpm概述 pnpm代表performance npm…...
Ubuntu16.04-ros-kinetic环境搭建笔记=1=
tips:搬运资料,留个记录 安装Ubuntu Ubuntu官网下载地址 安装 虚拟机安装Ubuntu 最好断网安装Ubuntu,可以节约时间 Ubuntu基础设置 Ubuntu换国内源 换成清华源 sudo apt upgradeVMwareTool安装 把这个压缩包拖到桌面,否则只读…...

应用层自定义协议(组织数据的格式)
概念 在进行网络传输数据的时候,通常是将要传输的数据组织成一个字符串,再将字符串转换为一个字节流进行网络传输数据,而数据组织的格式是多种多样的,我们只需要保证,客户端和服务器对于字符串的组织和解析统一即可 现…...

5种常见的3D游戏艺术风格及工具栈
在游戏开发领域,3D 艺术风格已成为为玩家创造身临其境、引人入胜的体验的重要组成部分。 随着技术的进步,创造令人惊叹的 3D 视觉效果的可能性已经大大扩展,为游戏开发人员提供了广泛的选择。 在本文中,我们将探讨当今游戏开发中…...
【玩转Linux操作】crond的基本操作
🎊专栏【玩转Linux操作】 🍔喜欢的诗句:更喜岷山千里雪 三军过后尽开颜。 🎆音乐分享【Counting Stars 】 欢迎并且感谢大家指出小吉的问题🥰 文章目录 🍔概述🍔命令⭐常用选项 🍔练…...

设置Linux 静态IP
LInux虚拟机默认的IP地址是动态获取的 作为服务器,我们一般还需要把IP地址设置为静态的 设置静态IP vim /etc/sysconfig/network-scripts/ifcfg-ens33 TYPEEthernet PROXY_METHODnone BROWSER_ONLYno # BOOTPROTOdhcp 动态获取 BOOTPROTOstatic IPADDR"192.16…...
JMeter接口自动化测试实例—JMeter引用javaScript
Jmeter提供了JSR223 PreProcessor前置处理器,通过该工具融合了Java 8 Nashorn 脚本引擎,可以执行js脚本以便对脚本进行前置处理。其中比较典型的应用就是通过执行js脚本对前端数据进行rsa加密,如登录密码加密。但在这里我就简单的应用javaScr…...
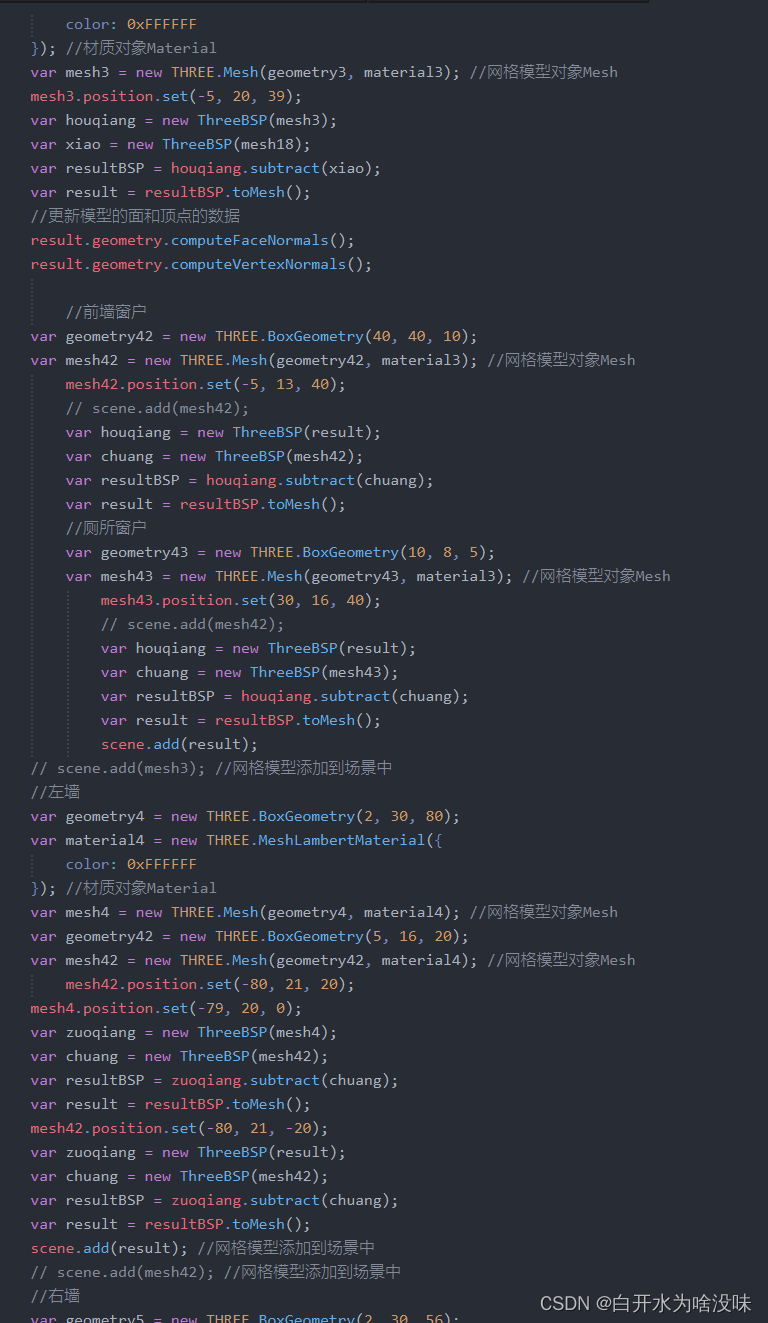
javascript期末作业【三维房屋设计】 【源码+文档下载】
1、引入three.js库 官网下载three.js 库 放置目录并引用 引入js文件: 设置场景(scene) (1)创建场景对象 (2)设置透明相机 1,透明相机的优点 透明相机机制更符合于人的视角,在场景预览和游戏场景多有使用…...

数组详解
1. 一维数组的创建和初始化 1.1 数组的创建 数组是一组相同类型元素的集合。 数组的创建方式: type_t arr_name [const_n]; //type_t 是指数组的元素类型 //const_n 是一个常量表达式,用来指定数组的大小 数组创建的实例: //代码1 int a…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...