Python 3 使用HBase 总结
HBase 简介和安装
请参考文章:HBase 一文读懂
Python3 HBase API
HBase 前期准备
1 安装happybase库操作hbase
安装该库 pip install happybase2 确保 Hadoop 和 Zookeeper 可用并开启
确保Hadoop 正常运行
确保Zookeeper 正常运行3 开启HBase thrift服务
使用命令开启
$HBASE_HOME/bin/hbase-daemon.sh start thrift4、使用jps 命令查看thrift 服务 是否正常启动
[root@Hadoop3-master bin]# jps
69760 Worker
120160 ResourceManager
81811 QuorumPeerMain
119541 DataNode
93143 Jps
56695 Worker
119387 NameNode
119802 SecondaryNameNode
92890 ThriftServer
69549 Master
69759 Worker
[root@Hadoop3-master bin]#HappyBase 简介
Happybase是Python通过Thrift访问HBase的库,实现起来方便、快捷。
HappyBase 核心类

Centos 操作指令
[root@Hadoop3-master bin]# ./zkServer.sh start #启动 ZooKeeper
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@Hadoop3-master bin]# hbase-daemon.sh start thrift #开启守护hbase 线程并开启thrift 服务
running thrift, logging to /usr/local/hbase/logs/hbase-root-thrift-Hadoop3-master.out
[root@Hadoop3-master bin]# jps #hadoop 3 服务/Hbase 服务
69760 Worker
120160 ResourceManager
81811 QuorumPeerMain
119541 DataNode
93143 Jps
56695 Worker
119387 NameNode
119802 SecondaryNameNode
92890 ThriftServer
69549 Master
69759 Worker
[root@Hadoop3-master bin]# HBase 伪集群/单机版本遇到问题总结
ERROR: KeeperErrorCode = NoNode for /hbase/master
造成此类问题的原因是:使用HBase 自带ZooKeeper 分布式调度框架造成,由于我的环境是单机版本,我的大致设置是使用独立ZooKeeper 服务。如下是我hbase-site.xml 和hbase-env.sh 相关配置
hbase-env.sh:
export HBASE_MANAGES_ZK=false # 推荐不使用HBash 自带zookeeper
hbase-site.xml:配置Hadoop 3 存储地址、ZooKeeper 服务地址和端口
<property><name>hbase.rootdir</name><value>hdfs://Hadoop3-master:9000/hbase</value></property><!--必须设置为True,否则无法连接ZooKeeper--><property><name>hbase.cluster.distributed</name><value>true</value></property><!-- zk 端口 --><property><name>hbase.zookeeper.property.clientPort</name><value>2181</value></property><!-- hbase 依赖 zk的地址 --><property><name>hbase.zookeeper.quorum</name><value>Hadoop3-master</value></property>
Zookeeper:Unable to read additional data from client sessionid 0x00, likely client has closed socket
报错信息:
EndOfStreamException: Unable to read additional data from client sessionid0x6362257b44e5068d, likely client has closed socket
具体原因:客户端连接Zookeeper时,配置的超时时长过短。
解决办法:调整zoo.cfg 超时参数值
[root@Hadoop3-master conf]# vi /usr/local/zookeeper/conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=10000
将超时时间由原来的2 秒修改为10 秒
HRegionServer: Failed construction RegionServer
2023-08-16 11:47:22,026 ERROR [main] regionserver.HRegionServer: Failed construction RegionServer
java.lang.StackOverflowErrorat org.apache.zookeeper.ZooKeeper.exists(ZooKeeper.java:2000)
原因:ZooKeeper 存储HBase 信息异常
解决办法:使用zkCli.sh 删除/hbase 节点数据
[root@Hadoop3-master bin]# ./zkCli.sh
Connecting to localhost:2181
******
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0] ls /
[hbase, zookeeper]
[zk: localhost:2181(CONNECTED) 5] deleteall /hbase
[zk: localhost:2181(CONNECTED) 6] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 7] quitWATCHER::WatchedEvent state:Closed type:None path:null
2023-08-16 14:18:58,892 [myid:] - INFO [main:ZooKeeper@1288] - Session: 0x10002e674ad0027 closed
2023-08-16 14:18:58,893 [myid:] - INFO [main-EventThread:ClientCnxn$EventThread@568] - EventThread shut down for session: 0x10002e674ad0027
2023-08-16 14:18:58,895 [myid:] - INFO [main:ServiceUtils@45] - Exiting JVM with code 0
Thriftpy2.transport.base.TTransportException: TTransportException(type=1, message="Could not connect to ('*.*.*.*', 9090)")
原因:HBase 没有启动thrift 守护进程服务。
解决办法:开启HBase thrift 守护进程服务。
[root@Hadoop3-master bin]# ./hbase-daemon.sh start thrift
running thrift, logging to /usr/local/hbase/logs/hbase-root-thrift-Hadoop3-master.out
[root@Hadoop3-master bin]# jps
69760 Worker
128612 QuorumPeerMain
70406 SecondaryNameNode
59081 HRegionServer
69549 Master
70190 DataNode
76078 ThriftServer
56695 Worker
70040 NameNode
70744 ResourceManager
58845 HMaster
69759 Worker
76286 Jps
[root@Hadoop3-master bin]#
通过jsp 指令查看是否包含ThriftServer 标识符 。
HBase Shell 及其常用命令
hbase shell是一个命令行工具。在linux上,输入命令: . /hbase shell
HBase Shell
- version:显示当前hbase的版本号
- status:显示各主节点的状态,之后可以加入参数
- whoami:显示当前用户名
- 退出shell模式:exit或quit.
[test@cs010 bin]$ ./hbase shell
//version显示当前hbase版本号
hbase(main):001:0> version
1.4.12, r6ae4a77408ad35d6a7a4e5cebfd401fc4b72b5ec, Sun Nov 24 13:25:41 CST 2019
//status显示各主节点的状态
hbase(main):002:0> status
1 active master, 0 backup masters, 1 servers, 1 dead, 7.0000 average load
//whoami显示当前用户名
hbase(main):003:0> whoami
test(auth:SIMPLE)groups: test表和列族操作
Hbase的表结构(schema)只有表名和列族两项内容.但列族的属性很多,在修改和建立表结构时,可以对列族的数量和属性进行设定.
HBase Shell操作表命令:
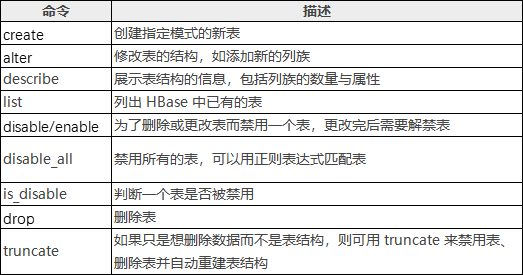
创建表
//创建表,必须指明两个参数:表名和列族的名字
1. create 'table1','basic' //建立表名为table1,含有一个列族basic
2. create 'table1','basic','advanced' //建立表名为table1,建立了2个列族basic,advanced.
3. create 'table2','basic',MAX_FILESIZE=>'134217728' //对表中所有列族设定,所有分区单次持久化的最大值为128MB
4. create 'TABLE1','basic' //hbase区分大小写,与第一个table1是2张不同的表
5. create 'table1',{NAME => 'basic',VERSION => 5,BLOCKCACHE => true}
//大括号内是对列族basic进行描述,定义了VERSION=>5,表示对于同一个cell,保留最近的5个历史版本,BLOCKCACHE赋值为true,允许读取数据时进行缓存.其他未指定的参数,采用默认值
//大括号中的语法,NAME和VERSION为参数名,不需要用括号引用.//创建命名空间
create_namespace 'bigdata'//命名空间下创建表
create 'bigdata:student','info'//命名空间下删除表,如果有表,需要先删除表drop_namespace 'bigdata'查看表名列表
//list命令查看当前所有表名
list//list命令查看当前命名空间
list_space//exists 命令查看此表是否存在
exists 'table_test1'eg:
hbase(main):010:0> list
TABLE
table_test1
1 row(s) in 0.0060 secondshbase(main):043:0> list_namespace
NAMESPACE
default
1 row(s) in 0.0190 secondshbase(main):011:0> exists 'table_test1'
Table table_test1 does exist
0 row(s) in 0.0070 seconds描述表结构
//描述表结构 describe命令查看指定表的列族信息,包括有多少个列族、每个列族的参数信息
describe 'table_test1'//描述命名空间下的表结构describe 'bigdata:table_test1'
eg:
hbase(main):013:0> describe 'table_test1'
Table table_test1 is ENABLED
table_test1
COLUMN FAMILIES DESCRIPTION
{NAME => 'test001', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER',COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE =>'65536', REPLICATION_SCOPE => '0'}
{NAME => 'test002', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER',COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE =>'65536', REPLICATION_SCOPE => '0'}
2 row(s) in 0.0250 seconds修改表结构
//修改表结构,alter命令,比如增加列族或修改列族参数.
//eg:表table_test1中新增列族test002
1. alter 'table_test1','test001','test002' //新增列族test002
2. alter 'table_test1','test002' //新增列族test002
3. alter 'table_test1','test001',{NAME=> 'test002',IN_MEMORY =>true} //新增列族test002//修改列族名称,该列族下已存有数据,需要对数据进行修改
4. alter 'table_test1',{NAME=> 'test001',IN_MEMORY =>true}//删除一个列族,以及其中的数据(前提是至少要有一个列族)
5. alter 'table_test1','delete'=>'test001'
6. alter 'table_test1',{NAME=> 'test002',METHOD=>'delete'}eg:
[haishu@cs010 bin]$ . /hbash shell
hbase(main):001:0> list
TABLE
table_test1
1 row(s) in 0.1710 secondshbase(main):002:0> alter 'table_test1','delete'=>'test001'
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 1.9480 secondshbase(main):003:0> alter 'table_test1',{NAME=>'test002',METHOD=>'delete'}
Updating all regions with the new schema...
1/1 regions updated.
Done.
0 row(s) in 1.8710 seconds删除表
//先禁用表,再删除表
disable 'table1' //禁用表table1
is_disable 'table1'//查看是否禁用成功
drop 'table1'//删除表//顺序完成禁用、删除表、删除所有数据、重新建立空表,即清空表中所有的数据
truncate 'table1'数据更新
HBase Shell 增删改查命令:

数据插入
//数据插入,参数依次显示为:表名、行键名称、列族:列的名称、单元格的值、时间戳或数据版本号,数值越大表示时间或版本越新,如果省略,默认显示当前时间戳
put 'table_test','001','basic:test001','micheal jordan',1
put 'table_test','002','basic:test002','kobe'数据更新
//数据更新,put语句行键、列族已存在,但不考虑时间戳。建表时设定VERSIONS=>n,则用户可以查询到同一个cell,最新的n个数据版本
put 'table_test','001','basic:test001','air jordan',2数据删除
HBase 的删除操作并不会立即将数据从磁盘上删除,删除操作主要是对要被删除的数据打上标记。
当执行删除操作时,HBase 新插入一条相同的 KeyValue 数据,但是使 keytype=Delete,这便意味着数据被删除了,直到发生 Major compaction 操作时,数据才会被真正的从磁盘上删除,删除标记也会从StoreFile删除。
//数据删除,用delete,必须指明表名和列族名称
delete 'table_test','001','basic'
delete 'table_test','002','basic:test002'
delete 'table_test','002','basic:test002',2
//如果指明了版本,默认删除的是所有版本<=2的数据
//delete命令的最小粒度是cell,且不能跨列族删除。//删除表中所有列族在某个行键上的数据,即删除一个逻辑行,则需要使用deleteall命令
deleteall 'table_test','001'
deleteall 'table_test','002',1
//hbase并不能做实时删除数据,当hbase删除数据时,可以看作为这条数据put了新的版本,有一个删除标记(tombstone)计数器
//incr命令可以将cell的数值在原值上加入指定数值
incr 'table_test','001','basic:scores',10//get_counter命令可以查看计数器的当前值
get_counter 'table_test','001','basic:scores' 数据查询
hbase有2种基本的数据查询方法:
1.get:按行键获取一条数据
2.scan:扫描一个表,可以指定行键范围或使用过滤器限制范围。
3.count:采用count指令计算表的逻辑行数
//get命令的必选参数为表名和行键名
get 'table_test','001'
//可选项,指明列族名称、时间戳的范围、数据版本数、使用过滤器
get 'table_test','001',{COLUMN=>'basic'}
get 'table_test','001',{COLUMN=>'basic',TIMERANGE=>[1,21]}
get 'table_test','001',{COLUMN=>'basic',VERSIONS=>3}
get 'table_test','001',{COLUMN=>'basic',TIMERANG=>[1,2],VERSION=>3}
get 'table_test','001',{FILTER=>"ValueFilter(=,'binary:Michael Jordan 1')"}//scan数据扫描,不指定行键,hbase只能通过全表扫描的方式查询数据
scan 'table_test'
//指定列族名称
scan 'table_test' ,{COLUMN =>'basic'}
//指定列族和列名
scan 'table_test' ,{COLUMN =>'basic:name'}
//指定输出行数
scan 'table_test' ,{LIMIT => 1}
//指定行键的范围,中间用逗号隔开
scan 'table_test' ,{LIMIT =>'001',LIMIT => '003'}
//指定时间戳或时间范围
scan 'table_test' ,{TIMESTAMP => 1}
scan 'table_test' ,{TIMESTAMP => [1,3]}
//使用过滤器
scan 'table_test' ,FILTER=>"RowFilter(=,substring:0')"
//指定对同一个键值返回的最多历史版本数量
scan 'table_test' ,{version=> 1}//采用count指令可以计算表的逻辑行数
count 'table_test' 过滤查询
无论是在get方法还是scan方法,均可以使用过滤器(filter)来显示扫描或输出的范围。
//过滤器进行过滤查询,配合比较运算符或比较器共同使用:>、<、=、>=、<=、!= show_filters
比较器:
- BinaryComparator:完整字节比较器,如:binary:001,表示用字典顺序依次比较数据的所有字节。
- BinaryPrefixComparator:前缀字节比较器,如:binaryprefix:001,表示用字典顺序依次比较数据的前3个字节。
- RegexStringComparator:正则表达式比较器,如regexstring:a*c,表示字符串'a'开头,'c'结构的所有字符串。只可以用=或!=两种运算符。
- SubstringComparator:子字符串比较器,如substring:00.只可以用=或!=两种运算符。
- BitComparator:比特位比较器。只可以用=或!=两种运算符。
- NullComparator:空值比较器。
//比较器语法使用,用FILTER=> "过滤器(比较方式)"的方式指明所使用的过滤方法
//在语法格式上,过滤的方法用双引号引用,而比较方式用小括号引用
scan 'table_test',FILTER=>"RowFilter(=,'substring:0')"
scan 'table_test',{FILTER=>"RowFilter(=,'substring:0')"}
过滤器的用途:
- 行键过滤器
- 列族和列过滤器
- 值过滤器
- 其他过滤器
行键过滤器:
//行键过滤器,RowFilter:可以配合比较器及运算符,实现行键字符串的比较和过滤。
//需求:显示行键前缀为0开头的键值对,进行子串过滤只能用=或!=两种方式,不支持采用大于或小于
scan 'table_test',FILTER=>"RowFilter(=,'Substring:0')"
scan 'table_test',FILTER=>"RowFilter(>=,'BinaryPrefix:0')"
//行键前缀比较器,PrefixFilter:比较行键前缀(等值比较)的命令
scan 'table_test',FILTER=>"PrefixFilter('0')"
//KeyOnlyFilter:只对cell的键进行过滤和显示,不显示值,扫描效率比RowFilter高
scan 'table_test',{FILTER=>"KeyOnlyFilter()"}//FirstKeyFilter:只扫描相同键的第一个cell,其键值对都会显示出来,如果有重复的行键则跳过。可以用来实现对行键(逻辑行)的计数,和其他计数方式相比。
scan 'table_test',{FILTER=>"FirstKeyFilter()"}//InclusiveStopFilter:使用STARTROW和ENDROW进行设定范围的scan时,结果会包含STARTROW行,但不包括ENDROW,使用该过滤器替代ENDROW条件
scan 'table_test',{STARTROW=>'001',ENDROW=>'002'}
scan 'table_test',{STARTROW=>'001',FILTER=>"InclusiveStopFilter ('binary:002')",ENDROW=>'002'}列族和列过滤器:
//列族和列过滤器
//列族过滤器:FamilyFilter
scan 'table_test',FILTER=>"FamilyFilter(=,'substring:test001')"
//列名(列标识符)过滤器:QualifierFilter
scan 'table_test',FILTER=>"QualifierFilter(=,'substring:test001')"
//列名前缀过滤器:ColumnPrefixFilter
scan 'table_test',FILTER=>"ColumnPrefixFilter('f')"
//指定多个前缀的ColumnPrefixFilter:MultipleColumnPrefixFilter
scan 'table_test',FILTER=>"MultipleColumnPrefixFilter('f','l')"
//时间戳过滤器:TimestampsFilter
scan 'table_test',{FILTER=>"TimestampsFilter(1,2)"}
//列名范围过滤器:ColumnRangeFilter
scan 'table_test',{FILTER=>"ColumnRangeFilter('f',false,'lastname',true)"}
//参考列过滤器:DependentColumnFilter,设定一个参考列(即列名),如果某个逻辑行包含该列,则返回该行中和参考列时间戳相同的所有键值对
//过滤器参数中,第一项是需要过滤数据的列族名,第二项是参考列名,第三项是false说明扫描包含"basic:firstname",如果是true则说明在basic列族的其他列中进行扫描。
scan 'table_test',{FILTER=>"DependentColumnFilter('basic','firstname',false)"}值过滤器:
/ValueFilter:值过滤器,get或者scan方法找到符合值条件的键值对,变量=值:Michael Jordanget 'table_test','001',{FILTER=>"ValueFilter(=,'binary:Michael Jordan')"} scan 'table_test',{FILTER=>"ValueFilter(=,'binary:Michael Jordan')"}
//SingleColumnValueFilter:在指定的列族和列中进行比较的值过滤器,使用该过滤器时尽量在前面加上一个独立的列名限定
scan 'table_test',{ COLUMN => 'basic:palyername' , FILTER => "SingleColumnValueExcludeFilter('basic','playername',=,'binary:Micheal Jordan 3')"}
//SingleColumnValueExcludeFilter:和SingleColumnValueFilter类似,但功能正好相反,即排除匹配成功的值
scan 'table_test', FILTER => "SingleColumnValueExcludeFilter( 'basic' , 'playername' ,=,'binary:Micheal Jordan 3')"
SingleColumnValueFilter和SingleColumnValueExcludeFilter区别: Value = "Micheal Jordan "的键值对,或者返回除此之外的其他所有键值对。
//其他过滤器
1. ColumnCountGetFilter:限制每个逻辑行最多返回多少个键值对(cell),一般用get,不用scan.
2. PageFilter:对显示结果按行进行分页显示
3. ColumnPaginationFilter:对显示结果按列进行分页显示
4. 自定义过滤器:hbase允许采用Java编程的方式开发新的过滤器
eg: scan 'table_test', FILTER => "ColumnPrefixFilter( 'first' ) AND ValueFilter(=, 'substring:kobe')"eg:
hbase(main):012:0> get 'Test','002',{FILTER=>"ValueFilter(=,'binary:test004')"}
COLUMN CELL
zhangsan:wendy001 timestamp=1587208488702, value=test004
zhangsan:wendy002 timestamp=1587208582262, value=test004
1 row(s) in 0.0100 secondshbase(main):013:0> scan 'Test',{FILTER=>"ValueFilter(=,'binary:test004')"}
ROW COLUMN+CELL
001 column=zhangsan:wendy001, timestamp=1587208452109, value=test004
002 column=zhangsan:wendy001, timestamp=1587208488702, value=test004
002 column=zhangsan:wendy002, timestamp=1587208582262, value=test004
2 row(s) in 0.0100 secondshbase(main):018:0> scan 'Test',{ COLUMN => 'zhangsan:wendy002' , FILTER => "SingleColumnValueExcludeFilter('zhangsan','wendy002',=,'binary:test004')"}
ROW COLUMN+CELL
0 row(s) in 0.0040 secondshbase(main):019:0> scan 'Test',{COLUMN=>'zhangsan:wendy002',FILTER=>"SingleColumnValueFilter('zhangsan','wendy002',=,'binary:test004')"}
ROW COLUMN+CELL
002 column=zhangsan:wendy002, timestamp=1587208582262, value=test004
1 row(s) in 0.0060 seconds快照操作
快照:一种不复制数据就能建立表副本的方法,可以用于数据恢复,构建每日、每周或每月的数据报告,并在测试中使用等。
快照前提:Hbase的配置文件hbase-site.xml中配置hbase.snpashot.enabled属性为true。一般情况下,HBase的默认选项即为true。
//建立表的快照p1
snapshot 'test001','p1'
//显示快照列表
List_snapshots
//删除快照
delete_snapshot 'p1'
PS:注意删除快照后,原表的数据仍然存在。删除原表,快照的数据也仍然存在。//通过快照生成新表play_1,注意用此种方法生成新表,不会发生数据复制,只会进行元数据操作
clone_snapshot 'p1','play_1'
//快照恢复原表格,将抛弃快照之后的所有变化
restore_snapshot 'p1'//利用快照实现表改名,方法:制作一个快照,再将快照生成为新表,最后将不需要的旧表和快照删除
snapshot 'player','p1'
clone_snapshot 'p1','play_1'
disable 'player'
drop 'player'
delete_snapshot 'p1'批量导入导出
场景:put方法用于逐条采集数据,但如果需要将大量数据一次性写入HBase,则需要进行批量操作。此外,如果需要将数据备份到HDFS等位置,也需要进行批量操作,基于hadoopde的MapReduce方法实现,而数据的导入源头和备份目的,通常是在HDFS之上。
批量导入数据,有两种方式:
1、第一种是并行化的数据插入,利用MapReduce等方式将数据发给多个RegionServer。
2、第二种是根据表信息直接将原始数据转换成HFile,并将数据复制到HDFS的相应位置,再将文件中的数据纳入管理。
方法1,利用ImportTsv类方法:将存储在HDFS上的文本文件导入到HBase的指定表,TXT文件当中应当有明确的列分隔符,比如利用'\t'(TAB键)分割的TSV格式,或逗号分割的CSV格式。
原理:执行机制是扫描整个文件,逐条将数据写入。使用MapReduce方法在多个节点上启动多个进程,同时读取多个HDFS上的文件分块。数据根据所属分区不同,被发向不同的Regionserver,利用分布式并行读写的方式,加快数据导入的速度。
//在linux的命令行通过HBase指令调用ImportTsv类
//player为表名,hdfs://namenode:8020/input/为导入文件所在的目录,这里不需要指定文件名,导入时会遍历目录中的所有文件。
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns= HBASE_ROW_KEY,basic:playername,advance:scores -Dimporttsv.skip.bad.lines =true player hdfs://namenode:8020/input/
//-Dimporttsv.columns=HBASE_ROW_KEY,参数依次为:第一个关键字HBASE_ROW_KEY是指定文本文件中的行键,第二个是写入列族basic下名为playername的列,第三个是写入advance列族下的scores列,这一参数一般为必选项。
//-Dimporttsv.skip.bad.lines=true表示略过无效的行,如果设置为false,则遇到无效行会导入报告失败 //可选参数
//-Dimporttsv.separator=',',用逗号作为分隔符,也可以指定为其他形式的分隔符,例如'\0',默认情况下分隔符为'\t'。
//-Dimporttsv.timestamp =1298529542218,导入时使用指定的时间戳,如果不指定则采用当前时间。 方法二,利用bulk-load方法:直接将原始数据转换成HFile,并将数据复制到HDFS的相应位置,再将文件中的数据纳入管理,分为2个步骤。
//前提:表结构已经建立好,并且在命令中指定了表名,因为要根据表结构和分区状况准备文件
//第一步:利用ImportTsv生成文件
//第二步:复制//第一步:利用ImportTsv生成文件
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns= HBASE_ROW_KEY,basic:playername,advance:scores -Dimporttsv.skip.bad.lines =true -Dimporttsv.bulk.output=hdfs://namenode:8020/bulkload/ player hdfs://namenode:8020/input/
//-Dimporttsv.bulk.output 参数,设定了HDFS路径,准备好HFile文件的存放地址:hdfs://namenode:8020/bulkload/,由于MapReduce的特性,该路径不能提前存在
//第二步:复制,利用MapReduce实现,参数为HFile文件所在路径和表名。
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles
hdfs://namenode:8020/bulkload player方法三,从关系型数据库中导入数据到HBase:Hadoop系列组件中,有名为Sqoop的组件可以实现Hadoop、Hive、HBase等大数据工具与关系型数据库(例如MySQL、Oracle)之间的数据导入、导出。
Sqoop分为1和2两个版本,Sqoop1使用较为简单,Sqoo2则继承了更多功能,架构也更复杂。
//以sqoop1为例,其安装过程基本为解压。
//访问MySQL等数据库,则需要自行下载数据库连接组件(mysql-connector-java-x.jar),并复制到其lib目录中。
sqoop import --connect jdbc:mysql://node1:3306/database1 --table table1 --hbase-table player --column-family f1 --hbase-row-key playername --hbase-create-table --username 'root' -password '123456'
//从mysql中导入数据(import),之后指明了作为数据源的mysql的访问地址(node1)、端口(3306)、数据库名(database1)、表名(table1)。
//数据导入名为player的HBase表,并存入名为f1的列族,列名则和MySQL中保持一致,行键为MySQL表中名为playername的列。
//--hbase-create-table :HBase中建立这个表,最后指明了访问mysql的用户名和密码。备份和恢复
HBase支持将表或快照复制到HDFS,支持将数据复制到其他HBase集群,以实现数据备份和恢复功能。有四种方式:
//Export、Import、ExportSnapshot、CopyTable
//Export:将HBase的数据导出到HDFS。目的;备份,文件并不能直接以文本方式查看。
//参数中<tablename>为表名,<outputdir>为HDFS路径。
hbase org.apache.hadoop.hbase.mapreduce.Export <tablename> <outputdir>//Import:导出的数据可以恢复到HBase。
hbase org.apache.hadoop.hbase.mapreduce.Import <tablename> <outputdir>//ExportSnapshot
hbase org.apache.hadoop.hbase.mapreduce.ExportSnapshot -snapshot <snapshot name> -copy-to <outputdir>
//snapshot 快照名 ;outputdir为HDFS路径,导出的快照文件可以利用Import方法恢复到表中。//CopyTable:可以将一个表的内容复制到新表中,新表和原表可以在同一个集群内,也可以在不同的集群上。复制过程利用MapReduce进行。
//前提:新表已经建立起来
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=<NEW_TABLE_NAME> -peer.adr=<zookeeper_peer:2181:/hbase> <TABLE_NAME>
//--new.name=<NEW_TABLE_NAME>参数描述新表的名字,如果不指定则默认和原表名相同。
//-peer.adr=<zookeeper_peer:2181:/hbase>参数指向目标集群Zookeeper服务中的hbase数据入口(包括meta表的地址信息等)//CopyTable帮助
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --helpHappyBase API 实践
连接HBase
# _*_ coding : UTF-8_*_
# 开发者 : zhuozhiwengang
# 开发时间 : 2023/8/14 22:56
# 文件名称 : python_hbase_1.py
# 开发工具 : PyCharm
import happybasecon = happybase.Connection('192.168.43.11')
con.open() # 打开传输
print(con.tables()) # 输出所有表名
con.close() # 关闭传输效果截图:

表操作
创建表
# _*_ coding : UTF-8_*_
# 开发者 : zhuozhiwengang
# 开发时间 : 2023/8/16 15:11
# 文件名称 : python_hbase_2
# 开发工具 : PyCharm
import happybasecon = happybase.Connection('192.168.43.11') # 默认9090端口
con.open() # 打开thrift传输,TCP连接families = {'wangzherongyao': dict(max_versions=2), # 设置最大版本为2'hepingjingying': dict(max_versions=1, block_cache_enabled=False),'xiaoxiaole': dict(), # 使用默认值.版本默认为3
}
con.create_table('games', families) # games是表名,families是列簇,列簇使用字典的形式表示,每个列簇要添加配置选项,配置选项也要用字典表示print(con.tables()) # 输出表
con.close() # 关闭传输
配置选项:
- max_versions (int类型)
- compression (str类型)
- in_memory (bool类型)
- bloom_filter_type (str类型)
- bloom_filter_vector_size (int类型)
- bloom_filter_nb_hashes (int类型)
- block_cache_enabled (bool类型)
- time_to_live (int类型)
启动或禁用表
温馨提示:设置或者删除表时,必须得先禁用表,再删除。只能禁用或启动一次,不能重复,否则报错。
# _*_ coding : UTF-8_*_
# 开发者 : zhuozhiwengang
# 开发时间 : 2023/8/16 15:15
# 文件名称 : python_hbase_3
# 开发工具 : PyCharm
# 禁用表
import happybasecon = happybase.Connection('192.168.43.11') # 默认9090端口
con.open() # 打开thrift传输,TCP连接con.disable_table('games') # 禁用表,games代表表名
print(con.is_table_enabled('games')) # 查看表的状态,False代表禁用,True代表启动
print(con.tables()) # 即使禁用了该表,该表还是存在的,只是状态改变了con.close() # 关闭传输
效果截图:

# _*_ coding : UTF-8_*_
# 开发者 : zhuozhiwengang
# 开发时间 : 2023/8/16 15:16
# 文件名称 : python_hbase_4
# 开发工具 : PyCharm# 启动表
import happybasecon = happybase.Connection('192.168.43.11') # 默认9090端口
con.open() # 打开thrift传输,TCP连接con.enable_table('games') # 启动该表
print(con.is_table_enabled('games')) # 查看表的状态,False代表禁用,True代表启动
print(con.tables()) # 即使禁用了该表,该表还是存在的,只是状态改变了con.close() # 关闭传输
效果截图:

删除表
删除一个表要先将该表禁用,之后才能删除。HappyBase 的delete_table函数不但可以禁用表还可以删除表。如果前面已经禁用了该表,delete_table函数就可以不用加第二个参数,默认为False
# _*_ coding : UTF-8_*_
# 开发者 : zhuozhiwengang
# 开发时间 : 2023/8/16 15:20
# 文件名称 : python_hbase_5.py
# 开发工具 : PyCharm
import happybasecon = happybase.Connection('192.168.43.11') # 默认9090端口
con.open() # 打开thrift传输,TCP连接con.delete_table('games', disable=True) # 第一个参数表名,第二个参数表示是否禁用该表print(con.tables())con.close()效果截图:

数据操作
建立数据
注意:如果写数据时没有这个列名,就新建这样的列名,再写数据。
在 hbase shell 中,使用put命令,一次只能写入一个单元格,而happybase库的put函数能写入多个。
# _*_ coding : UTF-8_*_
# 开发者 : zhuozhiwengang
# 开发时间 : 2023/8/16 15:24
# 文件名称 : python_hbase_6.py
# 开发工具 : PyCharmimport happybasecon = happybase.Connection('192.168.43.11') # 默认9090端口
con.open() # 打开传输biao = con.table('games') # games是表名,table('games')获取某一个表对象wangzhe = {'wangzherongyao:名字': '别出大辅助','wangzherongyao:等级': '30','wangzherongyao:段位': '最强王者',
}
biao.put('0001', wangzhe) # 提交数据,0001代表行键,写入的数据要使用字典形式表示# 下面是查看信息,如果不懂可以继续看下一个
one_row = biao.row('0001') # 获取一行数据,0001是行键
for value in one_row.keys(): # 遍历字典print(value.decode('utf-8'), one_row[value].decode('utf-8')) # 可能有中文,使用encode转码con.close() # 关闭传输
效果截图:

查看操作
下面连接之后,就创建一个表对象,然后对这个表对象进行操作,这里演示了多种查看操作,第一个是查看一行的数据,第二个是查看一个单元格的数据,因为我存储时使用了中文,在hbase中存储的不是中文,而是utf-8的编码,这里接收了hbase传过来的编码数据之后对它进行解码,第三个是获取多行的数据,第四个是使用扫描器获取整个表的数据。
# _*_ coding : UTF-8_*_
# 开发者 : zhuozhiwengang
# 开发时间 : 2023/8/16 15:34
# 文件名称 : python_hbase_7.py
# 开发工具 : PyCharm
import happybasecon = happybase.Connection('192.168.43.11') # 默认9090端口
con.open() # 打开传输biao = con.table('games') # games是表名,table('games')获取某一个表对象print('-----------------------第一个-----------------------------')
one_row = biao.row('0001') # 获取一行数据,0001是行键
for value in one_row.keys(): # 遍历字典print(value.decode('utf-8'), one_row[value].decode('utf-8')) # 可能有中文,使用encode内置函数转码print('-----------------------第二个-----------------------------')
print(biao.cells('0001', 'wangzherongyao:段位')[0].decode('utf-8')) # 获取一个单元格信息,返回列表,转码输出,0001是行键,wangzherongyao是列簇名,是列名print('-----------------------第三个-----------------------------')
for key, value in biao.rows(['0001', '0002']): # 获取多行的数据,列表或元组中可以写入多个行键# print(key, '<=====>', value) # 由于0002我没有写入数据,就查不到,也不返回信息for index in value.keys(): # 遍历字典print(key.decode('utf-8'), index.decode('utf-8'), value[index].decode('utf-8')) # 可能有中文,使用encode转码print('-----------------------第四个----------------------------')
for rowkey, liecu in biao.scan(): # 获取扫描器对象,该对象是可迭代对象。扫描器记录了一个表的结构# print(rowkey, '<=====>', liecu)for index in liecu.keys(): # 遍历字典print(rowkey.decode('utf-8'), index.decode('utf-8'), liecu[index].decode('utf-8')) # 可能有中文,使用encode转码con.close() # 关闭传输
效果截图:
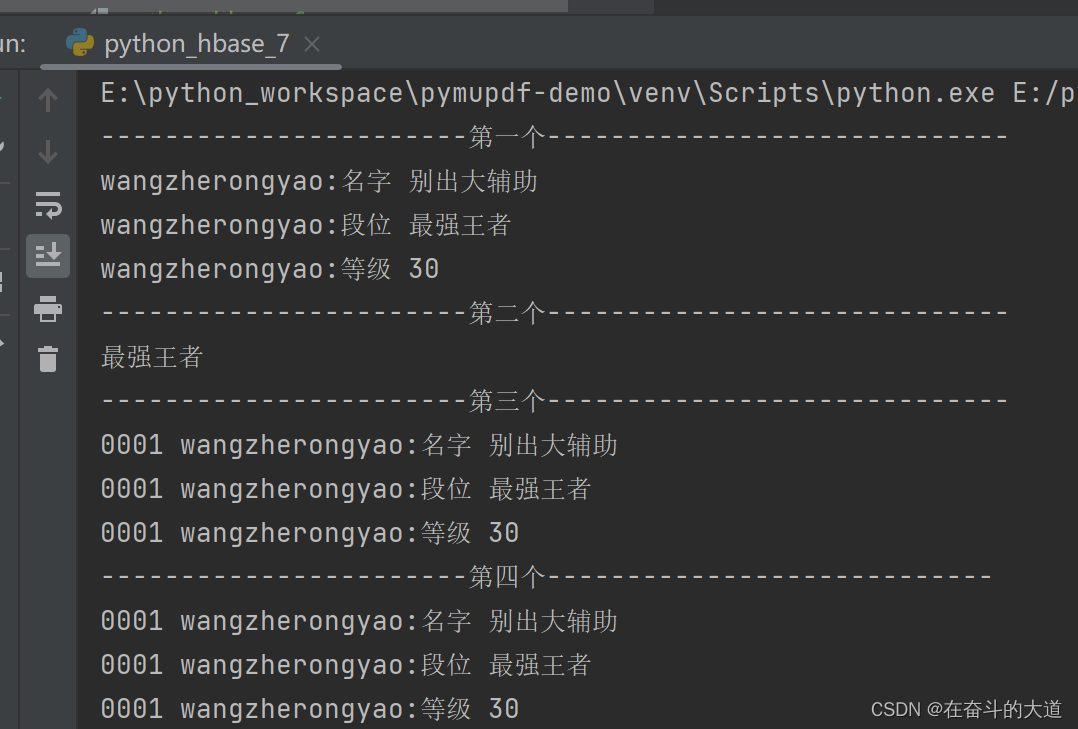
删除数据
# _*_ coding : UTF-8_*_
# 开发者 : zhuozhiwengang
# 开发时间 : 2023/8/16 15:38
# 文件名称 : python_hbase_8.py
# 开发工具 : PyCharmimport happybasecon = happybase.Connection('192.168.43.11') # 默认9090端口
con.open() # 打开传输biao = con.table('games') # games是表名,table('games')获取某一个表对象biao.delete('0003', ['wangzherongyao:段位']) # 删除一个单元格信息
# biao.delete('0003', ['wangzherongyao:名字', 'wangzherongyao:等级']) # 删除多个单元个信息
# biao.delete('0003', ['wangzherongyao']) # 删除一列簇信息
# biao.delete('0003') # 删除一整行信息# 查看数据,看看是否还在
for rowkey, liecu in biao.scan(): # 获取扫描器对象,该对象是可迭代对象。扫描器记录了一个表的结构# print(rowkey, '<=====>', liecu)for index in liecu.keys(): # 遍历字典print(rowkey.decode('utf-8'), index.decode('utf-8'), liecu[index].decode('utf-8')) # 可能有中文,使用encode转码
con.close() # 关闭传输前面说过,删除是根据时间戳来删除最近的版本,再次查看时显示的下一个时间戳最近的版本,那么下面测试一下是不是这样。
# _*_ coding : UTF-8_*_
# 开发者 : zhuozhiwengang
# 开发时间 : 2023/8/16 15:45
# 文件名称 : python_hbase_9
# 开发工具 : PyCharm
import happybasecon = happybase.Connection('192.168.43.11') # 默认9090端口
con.open() # 打开传输biao = con.table('games') # games是表名,table('games')获取某一个表对象
biao.put('0001', {'wangzherongyao:段位': '最强王者'})
biao.put('0001', {'wangzherongyao:段位': '永恒钻石V'})
biao.put('0001', {'wangzherongyao:段位': '尊贵铂金I'}) # 重复写三个值
print(biao.cells('0001', 'wangzherongyao:段位')) # 查看单元格的数据显示为最后一个时间戳的版本,即尊贵铂金Ibiao.delete('0001', ['wangzherongyao:段位']) # 删除单元格的信息,按照正常的理论查看时显示永恒钻石V
print(biao.cells('0001', 'wangzherongyao:段位')) # 查看单元格的信息,显示为空con.close() # 关闭传输问题描述:使用happybase.delete 删除指定单元格数据 ,清空了全部指定单元格记录。按照理论应该删除最近一条单元格记录。
原因:happybase库的 delete 函数封装的是 hbase shell 中的 deleteall 函数,所以调用要delete函数时要谨慎。
批处理
batch()函数可以创建一个可执行对象,然后在进行批处理操作,其实该函数返回了Batch对象,Batch对象支持上下文管理协议,可以执行批量写put操作、批量删delete操作,然后还要使用发送send函数提交到服务器
参考文章:HBase Shell 及其命令操作
HappyBase 官方文档
相关文章:
Python 3 使用HBase 总结
HBase 简介和安装 请参考文章:HBase 一文读懂 Python3 HBase API HBase 前期准备 1 安装happybase库操作hbase 安装该库 pip install happybase2 确保 Hadoop 和 Zookeeper 可用并开启 确保Hadoop 正常运行 确保Zookeeper 正常运行3 开启HBase thrift服务 使用命…...

Maven方式构建SpringBoot项目
目录 1、创建maven项目 2、添加springboot相关依赖 3、配置启动端口 4、修改APP文件 5、配置controller 6、启动应用 1、创建maven项目 项目如下: 2、添加springboot相关依赖 <parent><groupId>org.springframework.boot</groupId><arti…...
不花一分钱,利用免费电脑软件将视频MV变成歌曲音频MP3
教程 1.点击下载电脑软件下载地址,点击下载,安装。(没有利益关系,没有打广告,只是单纯教学) 2.安装完成后,点击格式工厂 3.然后如图所示依次,点击【音频】->【-MP3】 3.然后点击…...
触达用户的几种方式)
运营知识之用户运营(一)触达用户的几种方式
运营知识之用户运营(一)触达用户的几种方式 APP推送短信(DeepLink/Deferred DeepLink):短信拉起app电子邮件 EDM电话/外呼(人工、AI)电话外呼加短信(操作步骤短链)微信生…...

cocos creator pageView 循环展示 广告牌功能
在使用 creator pageView 滑动到最大或者最小为止的时候 滑动不了没法流畅的运行到最开始或者最后那个界面 循环展示 1.策划大人有需要就是要循环流畅的展示 解决方案: 做预制件的时候 最第一个界面之前 做一个最后的界面放到最前边去 比如 1,2,3,4,5,6,7,8 修改成 8,1…...
PyTorch Lightning:通过分布式训练扩展深度学习工作流
一、介绍 欢迎来到我们关于 PyTorch Lightning 系列的第二篇文章!在上一篇文章中,我们向您介绍了 PyTorch Lightning,并探讨了它在简化深度学习模型开发方面的主要功能和优势。我们了解了 PyTorch Lightning 如何为组织和构建 PyTorch 代码提…...

无涯教程-Perl - splice函数
描述 此函数从LENGTH元素的OFFSET元素中删除ARRAY元素,如果指定,则用LIST替换删除的元素。如果省略LENGTH,则从OFFSET开始删除所有内容。 语法 以下是此函数的简单语法- splice ARRAY, OFFSET, LENGTH, LISTsplice ARRAY, OFFSET, LENGTHsplice ARRAY, OFFSET返回值 该函数…...
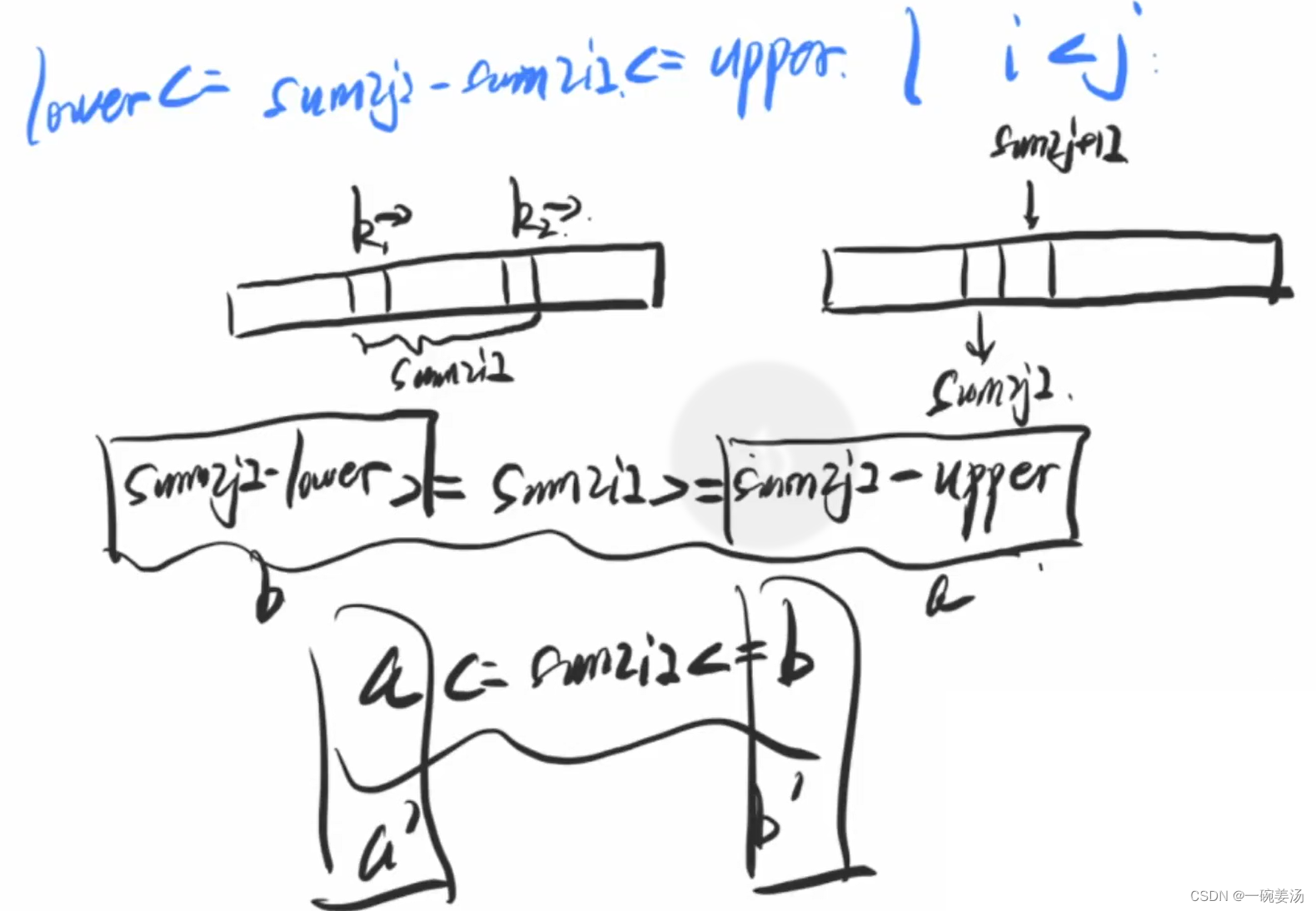
归并排序:从二路到多路
前言 我们所熟知的快速排序和归并排序都是非常优秀的排序算法。 但是快速排序和归并排序的一个区别就是:快速排序是一种内部排序,而归并排序是一种外部排序。 简单理解归并排序:递归地拆分,回溯过程中,将排序结果进…...

【Vue】运行项目报错 This dependency was not found
背景 运行Vue 项目报错,提示This dependency was not found;然后我根据提示 执行 npm install --save vue/types/umd ,执行后发现错误,我一开始一直以为是我本地装不上这个依赖。后来找了资料后,看到应该是自己的代码里面随意的i…...

Shell编程之正则表达式
文本处理器:三剑客:grep查找sed awk shell正则表达式由一类特殊字符以及文本字符所编写的一种模式,处理文本当中的内容,其中的一些字符不表示字符的字面含义表示一种控制或者通配的功能 通配符:匹配文件名和目录名&a…...
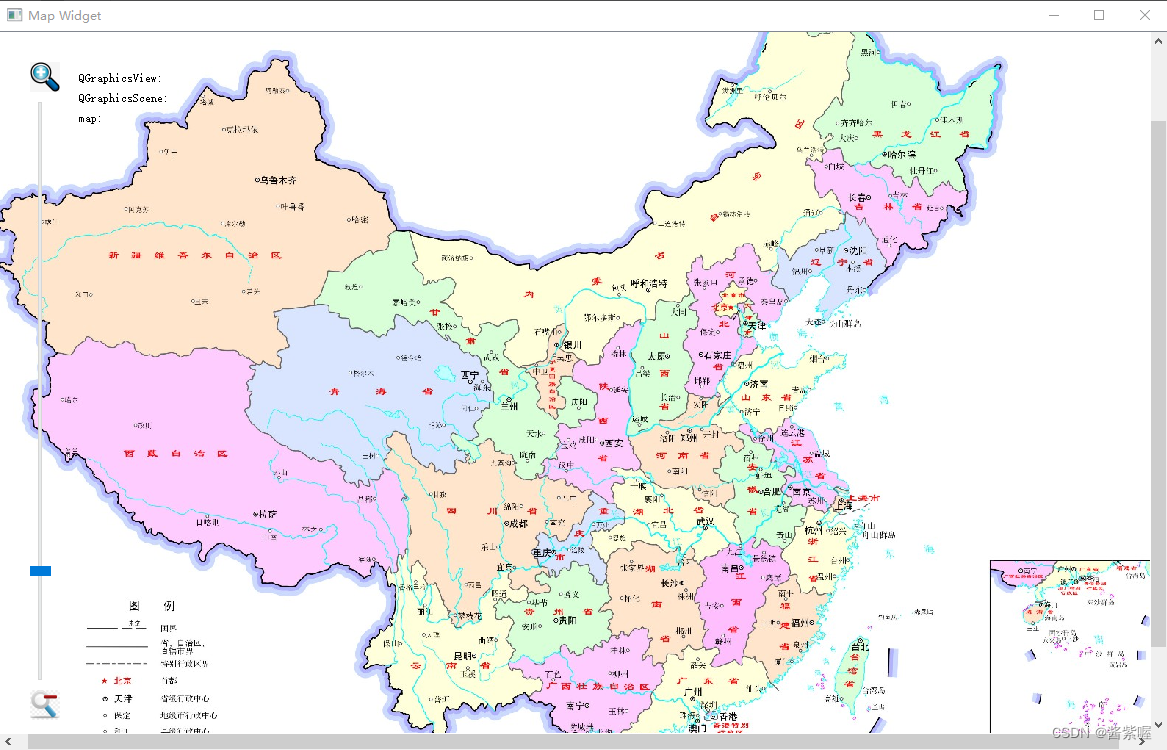
QGraphicsView 实例3地图浏览器
主要介绍Graphics View框架,实现地图的浏览、放大、缩小,以及显示各个位置的视图、场景和地图坐标 效果图: mapwidget.h #ifndef MAPWIDGET_H #define MAPWIDGET_H #include <QLabel> #include <QMouseEvent> #include <QGraphicsView&…...
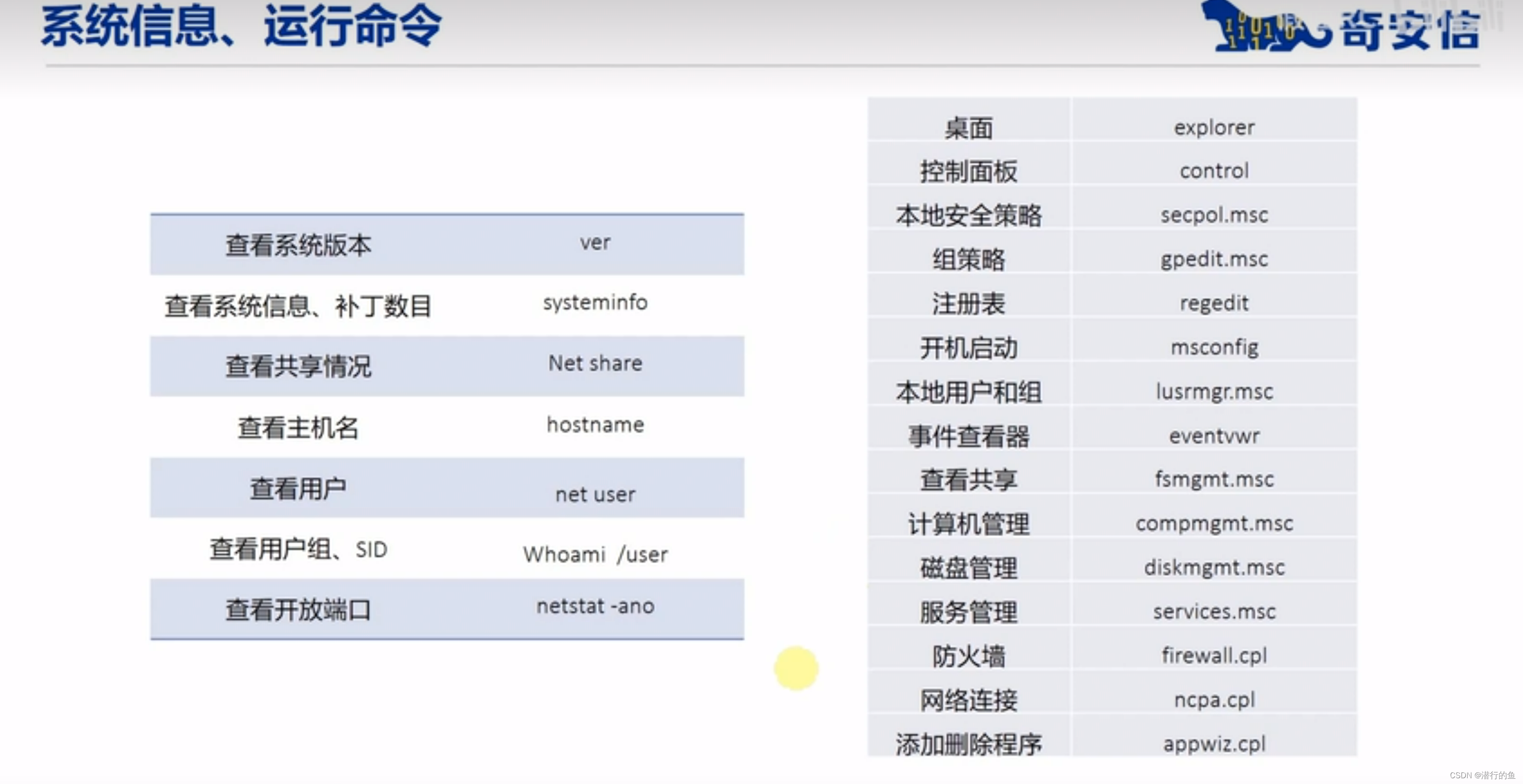
Windows基础安全知识
目录 常用DOS命令 ipconfig ping dir cd net user 常用DOS命令 内置账户访问控制 Windows访问控制 安全标识符 访问控制项 用户账户控制 UAC令牌 其他安全配置 本地安全策略 用户密码策略复杂性要求 强制密码历史: 禁止密码重复使用 密码最短使用期限…...

自定义注解和自定义注解处理器来扫描所有带有某个特定注解的Controller层
在Spring Boot中,您可以使用自定义注解和自定义注解处理器来扫描所有带有某个特定注解的Controller层。 以下是一个简单的示例,演示如何实现这个功能: 首先,创建自定义注解 CustomAnnotation ,用于标记需要被扫描的C…...

浏览器渲染原理 - 输入url 回车后发生了什么
目录 渲染时间点渲染流水线1,解析(parse)HTML1.1,DOM树1.2,CSSOM树1.3,解析时遇到 css 是怎么做的1.4,解析时遇到 js 是怎么做的 2,样式计算 Recalculate style3,布局 la…...

大文本的全文检索方案附件索引
一、简介 Elasticsearch附件索引是需要插件支持的功能,它允许将文件内容附加到Elasticsearch文档中,并对这些附件内容进行全文检索。本文将带你了解索引附件的原理和使用方法,并通过一个实际示例来说明如何在Elasticsearch中索引和检索文件附…...
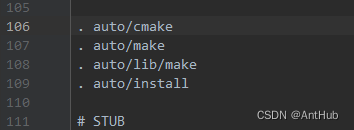
35_windows环境debug Nginx 源码-CLion配置CMake和启动
文章目录 生成 CMakeLists.txt 组态档35_windows环境debug Nginx 源码-CLion配置CMake和启动生成 CMakeLists.txt 组态档 修改auto目录configure文件,在 . auto/make 上边增加 . auto/cmake, 大概在 106 行。在 auto 目录下创建cmake 文件其内容如下: #!/usr/bin/env bash NG…...

收集的一些比较好的git网址
1、民间故事 https://github.com/folkstory/lingqiu/blob/master/%E4%BC%A0%E8%AF%B4%E9%83%A8%E5%88%86/%E4%BA%BA%E7%89%A9%E4%BC%A0%E8%AF%B4/%E2%80%9C%E6%B5%B7%E5%BA%95%E6%8D%9E%E6%9C%88%E2%80%9D%E7%9A%84%E6%AD%A6%E4%B8%BE.md 2、童话故事 https://gutenberg.org/c…...
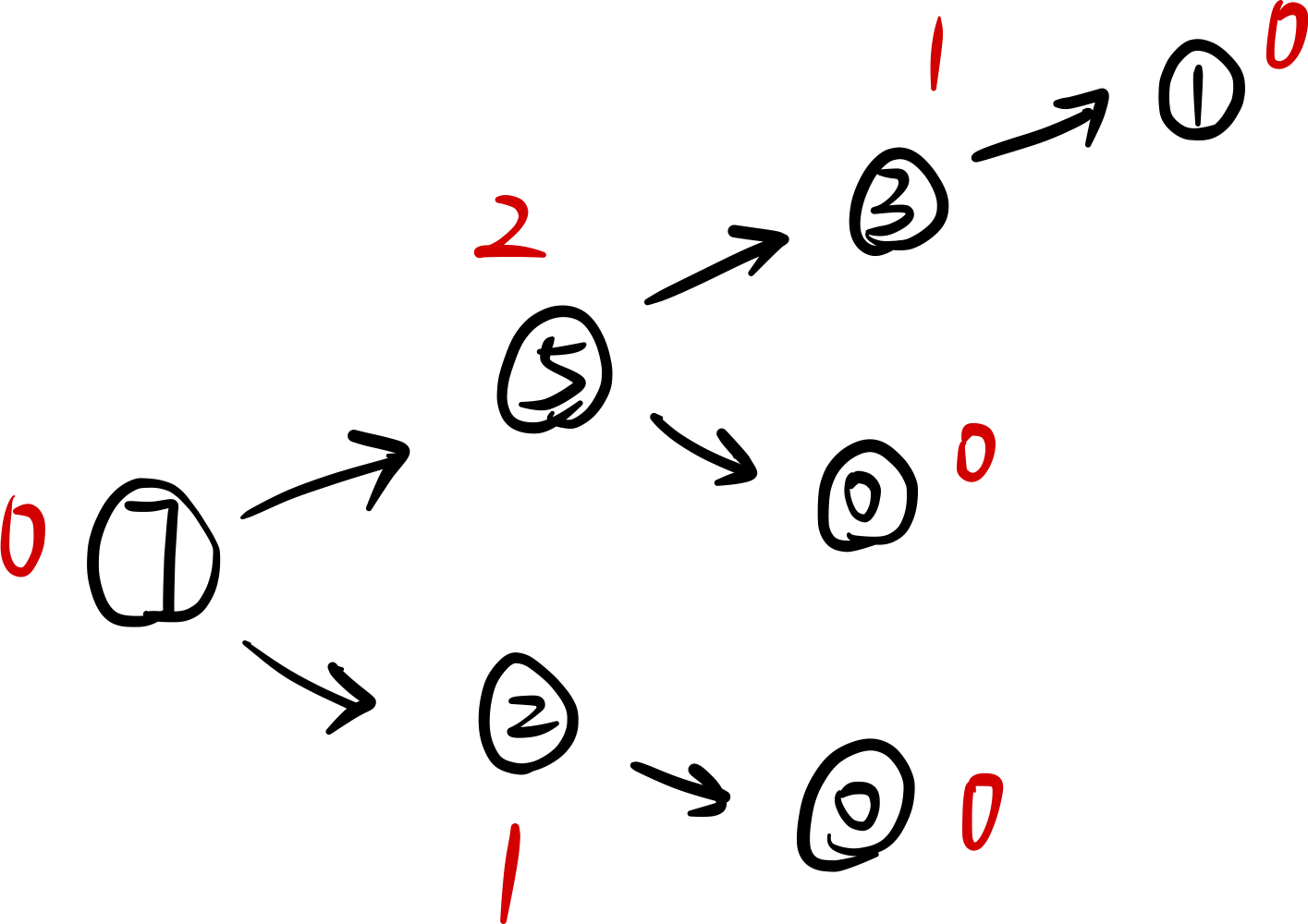
容斥原理 博弈论(多种Nim游戏解法)
目录 容斥原理容斥原理的简介能被整除的数(典型例题)实现思路代码实现扩展:用DPS实现 博弈论博弈论中的相关性质博弈论的相关结论先手必败必胜的证明Nim游戏(典型例题)代码实现 台阶-Nim游戏(典型例题&…...
【C++】函数指针
2023年8月18日,周五上午 今天在B站看Qt教学视频的时候遇到了 目录 语法和typedef或using结合我的总结 语法 返回类型 (*指针变量名)(参数列表)以下是一些示例来说明如何声明不同类型的函数指针: 声明一个不接受任何参数且返回void的函数指针…...

VBA技术资料MF45:VBA_在Excel中自定义行高
【分享成果,随喜正能量】可以不光芒万丈,但不要停止发光。有的人陷入困境,不是被人所困,而是自己束缚自己,这时"解铃还须系铃人",如果自己无法放下,如何能脱困? 。 我给V…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

Go 语言并发编程基础:无缓冲与有缓冲通道
在上一章节中,我们了解了 Channel 的基本用法。本章将重点分析 Go 中通道的两种类型 —— 无缓冲通道与有缓冲通道,它们在并发编程中各具特点和应用场景。 一、通道的基本分类 类型定义形式特点无缓冲通道make(chan T)发送和接收都必须准备好࿰…...

LOOI机器人的技术实现解析:从手势识别到边缘检测
LOOI机器人作为一款创新的AI硬件产品,通过将智能手机转变为具有情感交互能力的桌面机器人,展示了前沿AI技术与传统硬件设计的完美结合。作为AI与玩具领域的专家,我将全面解析LOOI的技术实现架构,特别是其手势识别、物体识别和环境…...

土建施工员考试:建筑施工技术重点知识有哪些?
《管理实务》是土建施工员考试中侧重实操应用与管理能力的科目,核心考查施工组织、质量安全、进度成本等现场管理要点。以下是结合考试大纲与高频考点整理的重点内容,附学习方向和应试技巧: 一、施工组织与进度管理 核心目标: 规…...