Spark MLlib机器学习库(一)决策树和随机森林案例详解
Spark MLlib机器学习库(一)决策树和随机森林案例详解
1 决策树预测森林植被
1.1 Covtype数据集
数据集的下载地址: https://www.kaggle.com/datasets/uciml/forest-cover-type-dataset
该数据集记录了美国科罗拉多州不同地块的森林植被类型,每个样本包含了描述每块土地的若干特征,包括海拔、坡度、到水源的距离、遮阳情况和土壤类型,并且给出了地块对应的已知森林植被类型。
很自然地,我们把该数据解析成 DataFrame,因为 DataFrame 就是 Spark 针对表格数据的抽象,它有定义好的模式,包括列名和列类型。
package com.yydsimport org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.sql.functions._
import org.apache.spark.ml.classification.{DecisionTreeClassificationModel, DecisionTreeClassifier}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.mllib.evaluation.MulticlassMetrics
import org.apache.spark.ml.{Model, Pipeline, PipelineModel, Transformer}
import org.apache.spark.ml.tuning.{ParamGridBuilder, TrainValidationSplit, TrainValidationSplitModel}object DecisionTreeTest {Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)def main(args: Array[String]): Unit = {// 构建SparkSession实例对象,通过建造者模式创建val spark: SparkSession = {SparkSession.builder().appName(this.getClass.getSimpleName.stripSuffix("$")).master("local[1]").config("spark.sql.shuffle.partitions", "3").getOrCreate()}// 利用Spark内置的读取CSV数据功能val dataWithHeader = spark.read.option("inferSchema", "true") // 数据类型推断.option("header", "true") // 表头解析.csv("D:\\kaggle\\covtype\\covtype.csv")// 检查一下列名,可以清楚地看到,有些特征确实是数值型。// 但是“荒野区域(Wilderness_Area)”有些不同,因为它横跨4列,每列要么为 0,要么为 1。// 实际上荒野区域是一个类别型特征,而非数值型。采用了one-hot编码// 同样,Soil_Type(40列)也是one-hot编码。dataWithHeader.printSchema()dataWithHeader.show(10)}}
解释一下one-hot编码
one-hot编码:一个有N个不同取值的类别型特征可以变成 N 个数值型特征,变换后的每个数值型特征的取值为 0 或 1。在这 N 个特征中,有且只有一个取值为 1,其他特征取值都为 0。比如,类别型特征“天气”可能的取值有“多云”“有雨”或“晴朗”。
在one-hot 编码中,它就变成了 3 个数值型特征:
多云用 1,0,0 表示,
有雨用 0,1,0 表示,
晴朗用 0,0,1 表示。不过,这并不是将分类特性编码为数值的唯一方法。
另一种可能的编码方式是为类别型特征的每个可能取值分配一个不同数值,比如多云 1.0、有雨 2.0 等。目标“Cover_Type”本身也是
类别型值,用 1~7 编码。在编码过程中,将类别型特征当成数值型特征时要小心。类别型特征值原本是没有大小顺序可言的,但被编码为数值之后,它们就“显得”有大小顺序
了。被编码后的特征若被视为数值,算法在一定程度上会假定有雨比多云大,而且大两倍,这样就可能导致不合理的结果。
1.2 建立决策树模型
1.2.1 原始特征组合为特征向量
// 划分训练集和测试集val Array(trainData, testData) = dataWithHeader.randomSplit(Array(0.9, 0.1))trainData.cache()testData.cache() // 输入的DataFrame包含许多列,每列对应一个特征,可以用来预测目标列。// Spark MLlib 要求将所有输入合并成一列,该列的值是一个向量。// 我们可以利用VectorAssembler将特征转换为向量val inputCols: Array[String] = trainData.columns.filter(_ != "Cover_Type")val assembler: VectorAssembler = new VectorAssembler().setInputCols(inputCols) // 除了目标列以外,所有其他列都作为输入特征,因此产生的DataFrame有一个新的“featureVector”.setOutputCol("featureVector")val assembledTrainData: DataFrame = assembler.transform(trainData)assembledTrainData.select(col("featureVector")).show(10,truncate = false)
+----------------------------------------------------------------------------------------------------+
|featureVector |
+----------------------------------------------------------------------------------------------------+
|(54,[0,1,2,3,4,5,6,7,8,9,13,15],[1859.0,18.0,12.0,67.0,11.0,90.0,211.0,215.0,139.0,792.0,1.0,1.0]) |
|(54,[0,1,2,3,4,5,6,7,8,9,13,15],[1860.0,18.0,13.0,95.0,15.0,90.0,210.0,213.0,138.0,780.0,1.0,1.0]) |
|(54,[0,1,2,3,4,5,6,7,8,9,13,15],[1861.0,35.0,14.0,60.0,11.0,85.0,218.0,209.0,124.0,832.0,1.0,1.0]) |
|(54,[0,1,2,3,4,5,6,7,8,9,13,15],[1866.0,23.0,14.0,85.0,16.0,108.0,212.0,210.0,133.0,819.0,1.0,1.0]) |
|(54,[0,1,2,3,4,5,6,7,8,9,13,15],[1867.0,20.0,15.0,108.0,19.0,120.0,208.0,206.0,132.0,808.0,1.0,1.0])|
|(54,[0,1,2,3,4,5,6,7,8,9,13,15],[1868.0,27.0,16.0,67.0,17.0,95.0,212.0,204.0,125.0,859.0,1.0,1.0]) |
|(54,[0,1,2,3,4,5,6,7,8,9,13,18],[1871.0,22.0,22.0,60.0,12.0,85.0,200.0,187.0,115.0,792.0,1.0,1.0]) |
|(54,[0,1,2,3,4,5,6,7,8,9,13,15],[1871.0,36.0,19.0,134.0,26.0,120.0,215.0,194.0,107.0,797.0,1.0,1.0])|
|(54,[0,1,2,3,4,5,6,7,8,9,13,15],[1871.0,37.0,19.0,120.0,29.0,90.0,216.0,195.0,107.0,759.0,1.0,1.0]) |
|(54,[0,1,2,3,4,5,6,7,8,9,13,18],[1872.0,12.0,27.0,85.0,25.0,60.0,182.0,174.0,118.0,577.0,1.0,1.0]) |
+----------------------------------------------------------------------------------------------------+
-
输出看起来不是很像一串数字,这是因为它显示的是向量的原始表示,也就是 Sparse Vector(稀疏向量) 的实例,这样做可以节省存储空间。由于这 54 个值中的大多数值都是 0,它仅存储非零值及其索引。
-
VectorAssembler是当前 Spark MLlib
管道(Pipeline)API 中的一个 Transformer 示例。 VectorAssembler可以将一个 DataFrame 转换成另外一个 DataFrame,并且可以和其他 Transformer 组合成一个管道。在后面,我们将这些转换操作将连接成一个真正的管道。
1.2.2 构建决策树
val classifier = new DecisionTreeClassifier().setSeed(Random.nextLong()) // 随机数种子.setLabelCol("Cover_Type") // 目标列.setFeaturesCol("featureVector") // 准换后的特征列.setPredictionCol("prediction") // 预测列的名称// DecisionTreeClassificationModel本身就是一个转换器// 它可以将一个包含特征向量的 DataFrame 转换成一个包含特征向量及其预测结果的 DataFrameval model: DecisionTreeClassificationModel = classifier.fit(assembledTrainData)println(model.toDebugString)
DecisionTreeClassificationModel: uid=dtc_54cb31909b32, depth=5, numNodes=51, numClasses=8, numFeatures=54If (feature 0 <= 3048.5)If (feature 0 <= 2559.5)If (feature 10 <= 0.5)If (feature 0 <= 2459.5)If (feature 3 <= 15.0)Predict: 4.0Else (feature 3 > 15.0)Predict: 3.0Else (feature 0 > 2459.5)If (feature 17 <= 0.5)Predict: 2.0Else (feature 17 > 0.5)Predict: 3.0Else (feature 10 > 0.5)If (feature 9 <= 5129.0)Predict: 2.0Else (feature 9 > 5129.0)If (feature 5 <= 569.5)Predict: 2.0Else (feature 5 > 569.5)Predict: 5.0......
依据上面模型表示方式的输出信息,我们可以发现模型的一些树结构。它由一系列针对特征的嵌套决策组成,这些决策将特征值与阈值相比较。
构建决策树的过程中,决策树能够评估输入特征的重要性。也就是说,它们可以评估每个输入特征对做出正确预测的贡献值。从模型中很容易获得这个信息。
// 把列名及其重要性(越高越好)关联成二元组,并按照重要性从高到低排列输出。
// Elevation 似乎是绝对重要的特征;其他的大多数特征在预测植被类型时几乎没有任何作用!
model.featureImportances.toArray.zip(inputCols).sorted.reverse.foreach(println)
(0.8066003452907752,Elevation)
(0.04178573786315329,Horizontal_Distance_To_Hydrology)
(0.03280245080822316,Wilderness_Area1)
(0.030257284101934206,Soil_Type4)
(0.02562302586398405,Hillshade_Noon)
(0.023493741973492223,Soil_Type2)
(0.016910986928613186,Soil_Type32)
(0.011741228151910562,Wilderness_Area3)
(0.005884894981433861,Soil_Type23)
(0.0027811902118641293,Hillshade_9am)
(0.0021191138246161745,Horizontal_Distance_To_Roadways)
(0.0,Wilderness_Area4)
(0.0,Wilderness_Area2)
(0.0,Vertical_Distance_To_Hydrology)
(0.0,Soil_Type9)
......
1.2.3 预测
// 比较一下模型预测值与正确的覆盖类型val predictions = model.transform(assembledTrainData)predictions.select("Cover_Type", "prediction", "probability").show(10, truncate = false)

-
输出还包含了一个
probability列,它给出了模型对每个可能的输出的准确率的估计。 -
尽管只有 7 种可能的结果,而概率向量实际上有 8 个值。向量中索引 1~7 的值分别表示结果为 1~7 的概率。然而,索引 0 也有一个值,它总是显示概率为“0.0”。我们可以忽略它,因为 0 根本就不是一个有效的结果。
-
决策树分类器的实现有几个超参数需要调整,这段代码中使用的都是默认值。
1.2.4 评估模型训练
// 评估训练质量val evaluator = new MulticlassClassificationEvaluator().setLabelCol("Cover_Type").setPredictionCol("prediction")println("准确率:" + evaluator.setMetricName("accuracy").evaluate(predictions))println("f1值:" + evaluator.setMetricName("f1").evaluate(predictions))
准确率:0.7007016671765066
f1值:0.6810479157002327
混淆矩阵
单个的准确率可以很好地概括分类器输出的好坏,然而有时候混淆矩阵(confusion matrix)会更有效。
混淆矩阵是一个 N× N 的表, N 代表可能的目标值的个数。因为我们的目标值有 7 个分类,所以是一个 7× 7 的矩阵,每一行代表数据的真实归属类别,每一列按顺序依次代表预测值。第 i 行和第 j 列的条目表示数据中真正归属第 i 个类别却被预测为第 j 个类别的数据总量。因此,正确的预测是沿着对角线计算的,而非对角线元素代表错误预测。
// 混淆矩阵,Spark 提供了用于计算混淆矩阵的代码;不幸的是,这个代码是基于操作 RDD的旧版 MLlib API 实现的val predictionRDD = predictions.select("prediction", "Cover_Type").as[(Double,Double)] // 转换成 Dataset,需要导入隐式准换 import spark.implicits._.rdd // 准换为rddval multiclassMetrics = new MulticlassMetrics(predictionRDD)println("混淆矩阵:")println(multiclassMetrics.confusionMatrix)
混淆矩阵:
130028.0 55161.0 187.0 0.0 0.0 0.0 5175.0
50732.0 196315.0 7163.0 53.0 0.0 0.0 762.0
0.0 2600.0 29030.0 600.0 0.0 0.0 0.0
0.0 0.0 1487.0 967.0 0.0 0.0 0.0
12.0 7743.0 755.0 0.0 0.0 0.0 0.0
0.0 3478.0 11812.0 387.0 0.0 0.0 0.0
7923.0 193.0 60.0 0.0 0.0 0.0 10275.0
对角线上的次数多是好的。但也确实出现了一些分类错误的情况,比如分类器甚至没有将任何一个样本类别预测为 5。
// 当然,计算混淆矩阵之类,也可以直接使用 DataFrame API 中一些通用的操作,而不再需要依赖专门的方法。// 透视Pivot// 透视操作简单直接,逻辑如下// 1、按照不需要转换的字段分组,本例中是Cover_Type;// 2、使用pivot函数进行透视,透视过程中可以提供第二个参数来明确指定使用哪些数据项;// 3、汇总数字字段val confusionMatrix = predictions.groupBy("Cover_Type").pivot("prediction", (1 to 7)) //透视可以视为一个聚合操作,通过该操作可以将一个(实际当中也可能是多个)具有不同值的分组列转置为各个独立的列.count().na.fill(0.0) // 用 0 替换 null.orderBy("Cover_Type")confusionMatrix.show()
+----------+------+------+-----+---+---+---+-----+
|Cover_Type| 1| 2| 3| 4| 5| 6| 7|
+----------+------+------+-----+---+---+---+-----+
| 1|130028| 55161| 187| 0| 0| 0| 5175|
| 2| 50732|196315| 7163| 53| 0| 0| 762|
| 3| 0| 2600|29030|600| 0| 0| 0|
| 4| 0| 0| 1487|967| 0| 0| 0|
| 5| 12| 7743| 755| 0| 0| 0| 0|
| 6| 0| 3478|11812|387| 0| 0| 0|
| 7| 7923| 193| 60| 0| 0| 0|10275|
+----------+------+------+-----+---+---+---+-----+
70% 的准确率是用默认超参数取得的。如果在决策树构建过程中试试超参数的其他值,准确率还可以提高。
1.3 决策树的超参数
决策树的重要的超参数如下:
-
最大深度
- 最大深度只是对决策树的层数做出限制,它是分类器为了对样本进行分类所做的一连串判
断的最大次数。限制判断次数有利于避免对训练数据产生过拟合。
- 最大深度只是对决策树的层数做出限制,它是分类器为了对样本进行分类所做的一连串判
-
最大桶数
-
决策树算法负责为每层生成可能的决策规则,这些决策规则类似“重量≥ 100”或者“重量≥ 500”。
-
决策总是采用相同形式:对数值型特征, 决策采用特征≥值的形式;对类别型特征,决策采用特征在(值 1, 值 2,…)中的形式。因此,要尝试的决策规则集合实际上是可以嵌入决策规则中的一系列值。
-
Spark MLlib 的实现把决策规则集合称为“桶”(bin)。
桶的数目越多,需要的处理时间越多,但找到的决策规则可能更优。
-
-
不纯性度量
-
好规则把训练集数据的目标值分为相对是同类或“纯”(pure)的子集。
-
选择最好的规则也就意味着最小化规则对应的两个子集的不纯性(impurity)。
-
不纯性有两种常用的度量方式:
Gini不纯度(spark默认参数)或熵
-
-
最小信息增益
- 利于避免过拟合
1.4 决策树超参数调优
采用哪个不纯性度量所得到的决策树的准确率更高,或者最大深度或桶数取多少合适,我们可以让 Spark 来尝试这些值的许多组合。
首先,有必要构建一个管道,用于封装与上面相同的两个步骤。创建 VectorAssembler 和DecisionTreeClassifier,然后将这两个 Transformer 串起来,我们就可以得到一个单独的Pipeline 对象,这个 Pipeline 对象可以将前面的两个操作表示成一个 。
val newAssembler = new VectorAssembler().setInputCols(inputCols).setOutputCol("featureVector")// 在这里我们先不设置超参数val newClassifier = new DecisionTreeClassifier().setSeed(Random.nextLong()).setLabelCol("Cover_Type").setFeaturesCol("featureVector").setPredictionCol("prediction")// 组合为Pipelineval pipeline = new Pipeline().setStages(Array(newAssembler, newClassifier))// 使用 SparkML API 内建支持的 ParamGridBuilder 来测试超参数的组合val paramGrid = new ParamGridBuilder() // 4个超参数来说,每个超参数的两个值都要构建和评估一个模型,共计16种超参数组合,会训练出16个模型.addGrid(newClassifier.impurity, Seq("gini", "entropy")).addGrid(newClassifier.maxDepth, Seq(1, 20)).addGrid(newClassifier.maxBins, Seq(40, 300)).addGrid(newClassifier.minInfoGain, Seq(0.0, 0.05)).build()// 设定评估指标 准确率val multiclassEval = new MulticlassClassificationEvaluator().setLabelCol("Cover_Type").setPredictionCol("prediction").setMetricName("accuracy")// 这里也可以用 CrossValidator 执行完整的 k 路交叉验证,但是要额外付出 k 倍的代价,并且在大数据的情况下意义不大。// 所以在这里 TrainValidationSplit 就够用了val validator = new TrainValidationSplit().setSeed(Random.nextLong()).setEstimator(pipeline) // 管道.setEvaluator(multiclassEval) // 评估器.setEstimatorParamMaps(paramGrid) // 超参数组合.setTrainRatio(0.9) // 训练数据实际上被TrainValidationSplit 划分成90%与10%的两个子集val validatorModel: TrainValidationSplitModel = validator.fit(trainData)// validator 的结果包含它找到的最优模型。val bestModel = validatorModel.bestModel// 打印最优模型参数// 手动从结果 PipelineModel 中提取 DecisionTreeClassificationModel 的实例,然后提取参数println(bestModel.asInstanceOf[PipelineModel].stages.last.extractParamMap)
{dtc_1d4212c56614-cacheNodeIds: false,dtc_1d4212c56614-checkpointInterval: 10,dtc_1d4212c56614-featuresCol: featureVector,dtc_1d4212c56614-impurity: entropy,dtc_1d4212c56614-labelCol: Cover_Type,dtc_1d4212c56614-leafCol: ,dtc_1d4212c56614-maxBins: 40,dtc_1d4212c56614-maxDepth: 20,dtc_1d4212c56614-maxMemoryInMB: 256,dtc_1d4212c56614-minInfoGain: 0.0,dtc_1d4212c56614-minInstancesPerNode: 1,dtc_1d4212c56614-minWeightFractionPerNode: 0.0,dtc_1d4212c56614-predictionCol: prediction,dtc_1d4212c56614-probabilityCol: probability,dtc_1d4212c56614-rawPredictionCol: rawPrediction,dtc_1d4212c56614-seed: 2458929424685097192
}
这包含了很多拟合模型的信息:
-
“熵”作为不纯度的度量是最有效的
-
最大深度 20 比 1 好,也在我们意料之中。
-
最好的模型仅拟合到 40 个桶(bin),这一点倒可能让人有些意外,但这也可能意味着 40 个桶已经“足够好了”,而不是说拟合到 40 个桶比300 个桶“更好”。
-
最后, minInfoGain 的值为 0,这比不为零的最小值要更好,因为这可能意味着模型更容易欠拟(underfit),而不是过拟合(overfit)
超参数和评估结果分别用 getEstimatorParamMaps 和 validationMetrics获得
// 超参数和评估结果分别用 getEstimatorParamMaps 和 validationMetrics 获得。// 我们可以获取每一组超参数和其评估结果val paramsAndMetrics = validatorModel.validationMetrics.zip(validatorModel.getEstimatorParamMaps).sortBy(-_._1)paramsAndMetrics.foreach { case (metric, params) =>println(metric)println(params)println()}
0.9083158925519863
{dtc_5c5081d572b6-impurity: entropy,dtc_5c5081d572b6-maxBins: 40,dtc_5c5081d572b6-maxDepth: 20,dtc_5c5081d572b6-minInfoGain: 0.0
}
......
// 这个模型在交叉验证集中达到的准确率是多少?最后,在测试集中能达到什么样的准确率?println("交叉验证集上最大准确率:" + validatorModel.validationMetrics.max)println("测试集上的准确率:" + multiclassEval.evaluate(bestModel.transform(testData)))
交叉验证集上最大准确率:0.9083158925519863
测试集上的准确率:0.9134603776838838
2 随机森林
-
在决策树的每层,算法并不会考虑所有可能的决策规则。如果在每层上都要考虑所有可能的决策规则,算法的运行时间将无法想象。对一个有 N 个取值的类别型特征,总共有 2^N –2 个可能的决策规则(除空集和全集以外的所有子集)。即使对于一个一般大的 N,这也将创建数十亿候选决策规则。
-
决策树在选择规则的过程中也涉及一些随机性;每次只考虑随机选择少数特征,而且只考虑训练数据中一个
随机子集。在牺牲一些准确率的同时换回了速度的大幅提升,但也意味着每次决策树算法构造的树都不相同。 -
但是树应该不止有一棵,而是有很多棵,每一棵都能对正确目标值给出合理、独立且互不相同的估计。这些树的集体平均预测应该比任一个体预测更接近正确答案。正是由于决策树构建过程中的随机性,才有了这种独立性,这就是
随机决策森林的关键所在。 -
随机决策森林的预测只是所有决策树预测的加权平均。
- 对于类别型目标,这就是得票最多的类别,或有决策树概率平均后的最大可能值。
- 随机决策森林和决策树一样也支持回归问题,这时森林做出的预测就是每棵树预测值的平均。
package com.yydsimport org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.{Model, Pipeline, PipelineModel, Transformer}
import org.apache.spark.ml.tuning.{ParamGridBuilder, TrainValidationSplit, TrainValidationSplitModel}
import org.apache.spark.ml.classification.RandomForestClassifier
import org.apache.spark.ml.classification.RandomForestClassificationModel
import scala.util.Randomobject ForestModelTest {Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)def main(args: Array[String]): Unit = {// 构建SparkSession实例对象,通过建造者模式创建val spark: SparkSession = {SparkSession.builder().appName(this.getClass.getSimpleName.stripSuffix("$")).master("local[1]").config("spark.sql.shuffle.partitions", "3").getOrCreate()}// 利用Spark内置的读取CSV数据功能val dataWithHeader: DataFrame = spark.read.option("inferSchema", "true") // 数据类型推断.option("header", "true") // 表头解析.csv("D:\\kaggle\\covtype\\covtype.csv")// 划分训练集和测试集val Array(trainData, testData) = dataWithHeader.randomSplit(Array(0.9, 0.1))trainData.cache()testData.cache()// 输入的特征列val inputCols: Array[String] = trainData.columns.filter(_ != "Cover_Type")val newAssembler = new VectorAssembler().setInputCols(inputCols).setOutputCol("featureVector")// 随机森林分类器val newClassifier = new RandomForestClassifier().setSeed(Random.nextLong()).setLabelCol("Cover_Type").setFeaturesCol("featureVector").setPredictionCol("prediction")// 组合为Pipelineval pipeline = new Pipeline().setStages(Array(newAssembler, newClassifier))// 使用 SparkML API 内建支持的 ParamGridBuilder 来测试超参数的组合val paramGrid = new ParamGridBuilder() // 4个超参数来说,每个超参数的两个值都要构建和评估一个模型,共计16种超参数组合,会训练出16个模型.addGrid(newClassifier.impurity, Seq("gini", "entropy")).addGrid(newClassifier.maxDepth, Seq(1, 20)).addGrid(newClassifier.maxBins, Seq(40, 300)).addGrid(newClassifier.numTrees, Seq(10, 20)) // 要构建的决策树的个数.build()// 设定评估指标 准确率val multiclassEval = new MulticlassClassificationEvaluator().setLabelCol("Cover_Type").setPredictionCol("prediction").setMetricName("accuracy")// 这里也可以用 CrossValidator 执行完整的 k 路交叉验证,但是要额外付出 k 倍的代价,并且在大数据的情况下意义不大。// 所以在这里 TrainValidationSplit 就够用了val validator = new TrainValidationSplit().setSeed(Random.nextLong()).setEstimator(pipeline) // 管道.setEvaluator(multiclassEval) // 评估器.setEstimatorParamMaps(paramGrid) // 超参数组合.setTrainRatio(0.9) // 训练数据实际上被TrainValidationSplit 划分成90%与10%的两个子集val validatorModel: TrainValidationSplitModel = validator.fit(trainData)// validator 的结果包含它找到的最优模型。val bestModel = validatorModel.bestModel// 打印最优模型参数// 手动从结果 PipelineModel 中提取 DecisionTreeClassificationModel 的实例,然后提取参数println(bestModel.asInstanceOf[PipelineModel].stages.last.extractParamMap)// 随机森林分类器有另外一个超参数:要构建的决策树的个数。// 与超参数 maxBins 一样,在某个临界点之前,该值越大应该就能获得越好的效果。然而,代价是构造多棵决策树的时间比建造一棵的时间要长很多倍。val forestModel = bestModel.asInstanceOf[PipelineModel].stages.last.asInstanceOf[RandomForestClassificationModel]// 我们对于特征的理解更加准确了println("特征重要性:")println(forestModel.featureImportances.toArray.zip(inputCols).sorted.reverse.foreach(println))// 这个模型在交叉验证集中达到的准确率是多少?最后,在测试集中能达到什么样的准确率?println("交叉验证集上最大准确率:" + validatorModel.validationMetrics.max)println("测试集上的准确率:" + multiclassEval.evaluate(bestModel.transform(testData)))// 预测// 得到的“最优模型”实际上是包含所有操作的整个管道,其中包括如何对输入进行转换以适于模型处理,以及用于预测的模型本身。// 它可以接受新的 DataFrame 作为输入。它与我们刚开始时使用的 DataFrame 数据的唯一区别就是缺少“Cover_Type”列bestModel.transform(testData.drop("Cover_Type")).select("prediction").show(10)}}
相关文章:
Spark MLlib机器学习库(一)决策树和随机森林案例详解
Spark MLlib机器学习库(一)决策树和随机森林案例详解 1 决策树预测森林植被 1.1 Covtype数据集 数据集的下载地址: https://www.kaggle.com/datasets/uciml/forest-cover-type-dataset 该数据集记录了美国科罗拉多州不同地块的森林植被类型,每个样本…...
CI/CD入门(二)
CI/CD入门(二) 目录 CI/CD入门(二) 1、代码上线方案 1.1 早期手动部署代码1.2 合理化上线方案1.3 大型企业上线制度和流程1.4 php程序代码上线的具体方案1.5 Java程序代码上线的具体方案1.6 代码上线解决方案注意事项2、理解持续集成、持续交付、持续部署 2.1 持续集成2.2 持续…...
)
【BASH】回顾与知识点梳理(三十五)
【BASH】回顾与知识点梳理 三十五 三十五. 二十七至三十四章知识点总结及练习35.1 总结35.2 练习RAIDLVMsystemd 35.3 简答题 该系列目录 --> 【BASH】回顾与知识点梳理(目录) 三十五. 二十七至三十四章知识点总结及练习 35.1 总结 Quota 可公平的分…...
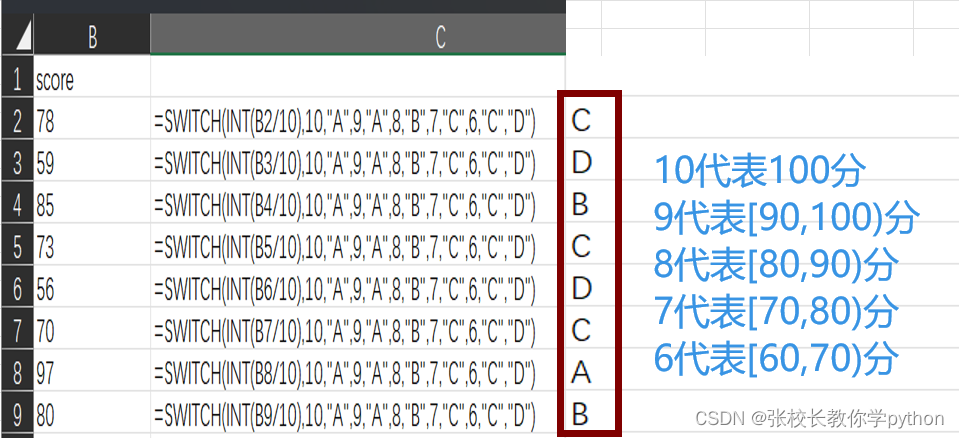
excel逻辑函数篇2
1、IF(logical_test,[value_if_true],[value_if_false]):判断是否满足某个条件,如果满足返回一个值,如果不满足则返回另一个值 if(条件,条件成立返回的值,条件不成立返回的值) 2、IFS(logical_test1,value_if_true1,…):检查是否…...

设计模式详解-解释器模式
类型:行为型模式 实现原理:实现了一个表达式接口,该接口使用标识来解释语言中的句子 作用:给定一个语言,定义它的文法表示,并定义一个解释器,这个解释器来解释。 主要解决:一些重…...

如何在React项目中动态插入HTML内容
React是一种流行的JavaScript库,用于构建用户界面。它提供了一种声明式的方法来创建可复用的组件,使得开发者能够更轻松地构建交互性的Web应用程序。在React中,我们通常使用JSX语法来描述组件的结构和行为。 在某些情况下,我们可…...
十六、Spring Cloud Sleuth 分布式请求链路追踪
目录 一、概述1、为什么出出现这个技术?需要解决哪些问题2、是什么?3、解决 二、搭建链路监控步骤1、下载运行zipkin2、服务提供者3、服务调用者4、测试 一、概述 1、为什么出出现这个技术?需要解决哪些问题 2、是什么? 官网&am…...

ElasticSearch DSL语句(bool查询、算分控制、地理查询、排序、分页、高亮等)
文章目录 DSL 查询种类DSL query 基本语法1、全文检索2、精确查询3、地理查询4、function score (算分控制)5、bool 查询 搜索结果处理1、排序2、分页3、高亮 RestClient操作 DSL 查询种类 查询所有:查询所有数据,一般在测试时使…...
)
【考研数学】概率论与数理统计 | 第一章——随机事件与概率(2,概率基本公式与事件独立)
文章目录 引言四、概率基本公式4.1 减法公式4.2 加法公式4.3 条件概率公式4.4 乘法公式 五、事件的独立性5.1 事件独立的定义5.1.1 两个事件的独立5.1.2 三个事件的独立 5.2 事件独立的性质 写在最后 引言 承接上文,继续介绍概率论与数理统计第一章的内容。 四、概…...

SpringBoot整合RabbitMQ,笔记整理
1创建生产者工程springboot-rabbitmq-produce 2.修改pom.xml文件 <!--父工程--> <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.6.0</version><r…...
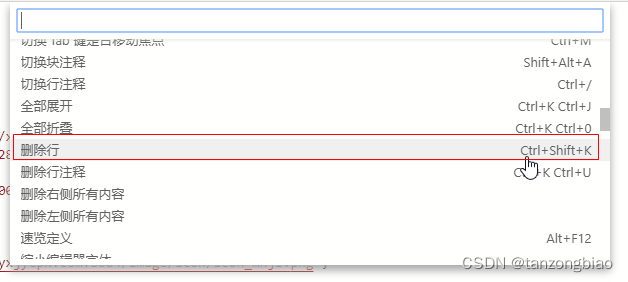
搜狗拼音暂用了VSCode及微信小程序开发者工具快捷键Ctrl + Shit + K 搜狗拼音截图快捷键
修改搜狗拼音的快捷键 右键--更多设置--属性设置--按键--系统功能快捷键--系统功能快捷键设置--取消Ctrl Shit K的勾选--勾选截屏并设置为Ctrl Shit A 微信开发者工具设置快捷键 右键--Command Palette--删除行 微信开发者工具快捷键 删除行:Ctrl Shit K 或…...

Python包sklearn画ROC曲线和PR曲线
前言 关于ROC和PR曲线的介绍请参考: 机器学习:准确率(Precision)、召回率(Recall)、F值(F-Measure)、ROC曲线、PR曲线 参考: Python下使用sklearn绘制ROC曲线(超详细) Python绘图|Python绘制ROC曲线和PR曲线 源码 …...

snpEff变异注释的一点感想
snpEff变异注释整成人生思考 1.介绍2.安装过程以及构建物种参考数据库3.坑货来了4.结果文件判读5.小tips 1.介绍   SnpEff(Snp Effect)是一个用于预测基因组变异(例如单核苷酸变异、插入、缺失等)对基因功能的影响的生物…...

“保姆级”考研下半年备考时间表
7月-8月 确定考研目标与备考计划 暑假期间是考研复习的关键时期,需要复习的主要内容有:重点关注重要的学科和专业课程,复习相关基础知识和核心概念。制定详细的复习计划并合理安排每天的学习时间,增加真题练习熟悉考试题型和答题技…...

具有弱监督学习的精确3D人脸重建:从单幅图像到图像集的Python实现详解
随着深度学习和计算机视觉技术的飞速发展,3D人脸重建技术在多个领域获得了广泛应用,例如虚拟现实、电影特效、生物识别等。但是,由单幅图像实现高精度的3D人脸重建仍然是一个巨大的挑战。在本文中,我们将探讨如何利用弱监督学习进…...

查询投稿会议的好用网址
会议伴侣 https://www.myhuiban.com/ 艾思科蓝 https://www.ais.cn/...

一元三次方程的解
一元三次方程的解法,点击跳转知乎原文地址 (一)一元三次方程降阶 一元三次方程原型: a x 3 b x 2 c x d 0 a x^3 b x^2 cx d 0 ax3bx2cxd0 代换削元。最简单的方法是线性变化削元。假设x my n, 带入后可以削去未知数…...
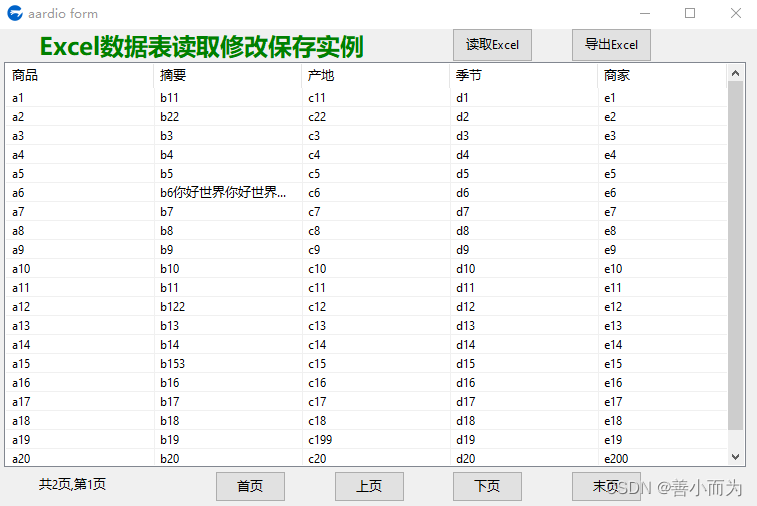
aardio开发语言Excel数据表读取修改保存实例练习
import win.ui; /*DSG{{*/ var winform win.form(text"aardio form";right759;bottom479) winform.add( buttonEnd{cls"button";text"末页";left572;top442;right643;bottom473;z6}; buttonExcelRead{cls"button";text"读取Exce…...
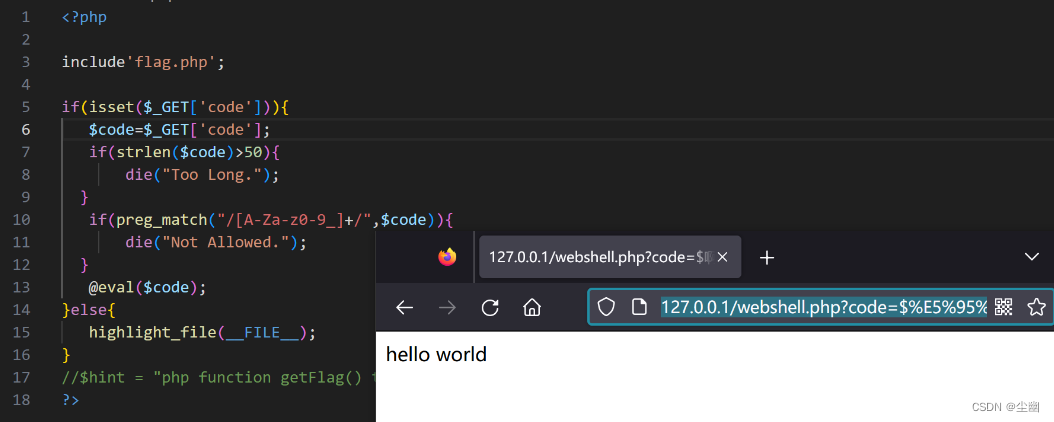
webshell绕过
文章目录 webshell前置知识进阶绕过 webshell 前置知识 <?phpecho "A"^""; ?>运行结果 可以看到出来的结果是字符“!”。 为什么会得到这个结果?是因为代码的“A”字符与“”字符产生了异或。 php中,两个变…...
Spring Boot 统一功能处理
目录 1.用户登录权限效验 1.1 Spring AOP 用户统一登录验证的问题 1.2 Spring 拦截器 1.2.1 自定义拦截器 1.2.2 将自定义拦截器加入到系统配置 1.3 拦截器实现原理 1.3.1 实现原理源码分析 2. 统一异常处理 2.1 创建一个异常处理类 2.2 创建异常检测的类和处理业务方法 3. 统一…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...

【网络安全】开源系统getshell漏洞挖掘
审计过程: 在入口文件admin/index.php中: 用户可以通过m,c,a等参数控制加载的文件和方法,在app/system/entrance.php中存在重点代码: 当M_TYPE system并且M_MODULE include时,会设置常量PATH_OWN_FILE为PATH_APP.M_T…...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...
)
华为OD最新机试真题-数组组成的最小数字-OD统一考试(B卷)
题目描述 给定一个整型数组,请从该数组中选择3个元素 组成最小数字并输出 (如果数组长度小于3,则选择数组中所有元素来组成最小数字)。 输入描述 行用半角逗号分割的字符串记录的整型数组,0<数组长度<= 100,0<整数的取值范围<= 10000。 输出描述 由3个元素组成…...