【Python机器学习】实验14 手写体卷积神经网络(PyTorch实现)
文章目录
- LeNet-5网络结构
- (1)卷积层C1
- (2)池化层S1
- (3)卷积层C2
- (4)池化层S2
- (5)卷积层C3
- (6)线性层F1
- (7)线性层F2
- 1. 数据的下载
- 2. 定义模型
- 3. 新建模型
- 4. 从数据集中分批量读取数据
- 5. 定义损失函数
- 6. 定义优化器
- 7. 开始训练
- 8. 测试和保存模型
- 9. 手写体图片的可视化
- 10. 多幅图片的可视化
- 思考题
- 11. 读取测试集的图片预测值(神经网络的输出为10)
- 12. 采用pandas可视化数据
- 13. 对预测错误的样本点进行可视化
- 14. 看看错误样本被预测为哪些数据
LeNet-5网络结构
LeNet-5是卷积神经网络模型的早期代表,它由LeCun在1998年提出。该模型采用顺序结构,主要包括7层(2个卷积层、2个池化层和3个全连接层),卷积层和池化层交替排列。以mnist手写数字分类为例构建一个LeNet-5模型。每个手写数字图片样本的宽与高均为28像素,样本标签值是0~9,代表0至9十个数字。
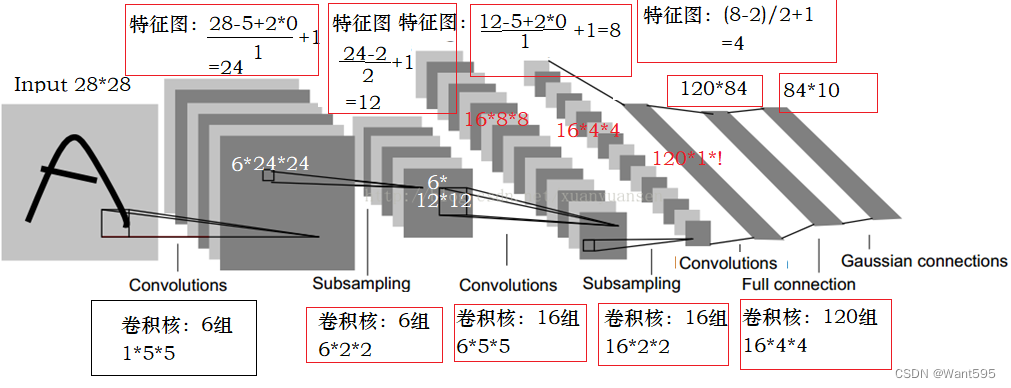
图1. LeNet-5模型
下面详细解析LeNet-5模型的正向传播过程。
(1)卷积层C1
C1层的输入数据形状大小为 R 1 × 28 × 28 \mathbb{R}^{1 \times 28 \times 28} R1×28×28,表示通道数量为1,行与列的大小都为28。输出数据形状大小为 R 6 × 24 × 24 \mathbb{R}^{6 \times 24 \times 24} R6×24×24,表示通道数量为6,行与列维都为24。
卷积核。L1层的卷积核形状大小 R 6 × 1 × 5 × 5 \mathbb{R}^{6 \times 1 \times 5 \times 5} R6×1×5×5为,偏置项形状大小为6。
这里有两个问题很关键:一是,为什么通道数从1变成了6呢?原因是模型的卷积层L1设定了6个卷积核,每个卷积核都与输入数据发生运算,最终分别得到6组数据。二是,为什么行列大小从28变成了24呢?原因是每个卷积核的行维与列维都为5,卷积核(5×5)在输入数据(28×28)上移动,且每次移动步长为1,那么输出数据的行列大小分别为28-5+1=24。
(2)池化层S1
L2层的输入数据大小要和L1层的输出数据大小保持一致。输入数据形状大小为 R 6 × 24 × 24 \mathbb{R}^{6 \times 24 \times 24} R6×24×24,表示通道数量为6,行与列的大小都为24。L2层的输出数据形状大小为 R 6 × 12 × 12 \mathbb{R}^{6 \times 12 \times 12} R6×12×12,表示通道数量为6,行与列维都为12。
为什么行列大小从24变成了12呢?原因是池化层中的过滤器形状大小为2×2,其在输入数据(24×24)上移动,且每次移动步长(跨距)为2,每次选择4个数(2×2)中最大值作为输出,那么输出数据的行列大小分别为24÷2=12。
(3)卷积层C2
L3层的输入数据形状大小为 R 6 × 12 × 12 \mathbb{R}^{6 \times 12 \times 12} R6×12×12,表示通道数量为6,行与列的大小都为12。L3层的输出数据形状大小为 R 16 × 8 × 8 \mathbb{R}^{16 \times 8 \times 8} R16×8×8,表示通道数量为16,行与列维都为8。
卷积核。L3层的卷积核形状大小为 R m × 16 × 6 × 5 × 5 \mathbb{R}^{m \times 16 \times 6 \times 5 \times 5} Rm×16×6×5×5,偏置项形状大小为16。
(4)池化层S2
L4层的输入数据形状大小与L3层的输出数据大小一致。L4层的输入数据形状大小为 R 16 × 8 × 8 \mathbb{R}^{16 \times 8 \times 8} R16×8×8,表示通道数量为16,行与列的大小都为8。L4层的输出数据形状大小为 R 16 × 4 × 4 \mathbb{R}^{16 \times 4 \times 4} R16×4×4,表示通道数量为16,行与列维都为4。
(5)卷积层C3
由于L5层是线性层,其输入大小为一维,所以需要把L4层的输出数据大小进行重新划分。L4层的输出形状大小为 R 16 × 4 × 4 \mathbb{R}^{16 \times 4 \times 4} R16×4×4,则L5层的一维输入形状大小为16×4×4=256。L4层的一维输出大小为120。
(6)线性层F1
L6层的输入特征数量为120。L6层的输出特征数量为84。
(7)线性层F2
L7层的输入特征数量为84。L7层的输出特征数量为10。
由于是分类问题,我们选择交叉熵损失函数。交叉熵主要用于衡量估计值与真实值之间的差距。交叉熵值越小,模型预测效果越好。
E ( y i , y ^ i ) = − ∑ j = 1 q y j i l n ( y ^ j i ) E(\mathbf{y}^{i},\mathbf{\hat{y}}^{i})=-\sum_{j=1}^{q}\mathbf{y}_{j}^{i}ln(\mathbf{\hat{y}}_{j}^{i}) E(yi,y^i)=−j=1∑qyjiln(y^ji)
其中, y i ∈ R q \mathbf{y}^{i} \in \mathbb{R}^{q} yi∈Rq为真实值, y j i y_{j}^{i} yji是 y i \mathbf{y}^{i} yi中的元素(取值为0或1), j = 1 , . . . , q j=1,...,q j=1,...,q。 y ^ i ∈ R q \mathbf{\hat{y}^{i}} \in \mathbb{R}^{q} y^i∈Rq是预测值(样本在每个类别上的概率)。
定义好了正向传播过程之后,接着随机化初始参数,然后便可以计算出每层的结果,每次将得到m×10的矩阵作为预测结果,其中m是小批量样本数。接下来进行反向传播过程,预测结果与真实结果之间肯定存在差异,以缩减该差异作为目标,计算模型参数梯度。进行多轮迭代,便可以优化模型,使得预测结果与真实结果之间更加接近。
1. 数据的下载
from torchvision.datasets import MNIST
import torch
import torchvision.transforms as transforms
train_dataset=MNIST(root="./data/",train=True,transform=transforms.ToTensor(),download=True)
test_dataset=MNIST(root="./data/",train=False,transform=transforms.ToTensor())
len(train_dataset),len(test_dataset)
(60000, 10000)
train_dataset[0][0].shape
torch.Size([1, 28, 28])
train_dataset[0][0].shape
torch.Size([1, 28, 28])
train_dataset[0][1]
5
2. 定义模型
from torch import nn
nn.Conv2d?
class Lenet5(nn.Module):def __init__(self):super(Lenet5,self).__init__()#1+ 28-5/(1)==24self.features=nn.Sequential(#定义第一个卷积层nn.Conv2d(in_channels=1,out_channels=6,kernel_size=(5,5),stride=1),nn.ReLU(),nn.AvgPool2d(kernel_size=2,stride=2),#6*12*12#定义第二个卷积层nn.Conv2d(in_channels=6,out_channels=16,kernel_size=(5,5),stride=1),#1+12-5/(1)=16*8*8nn.ReLU(),nn.MaxPool2d(kernel_size=2,stride=2),#1+(8-2)/(2)=4#16*4*4)#定义全连接层self.classfier=nn.Sequential(nn.Linear(in_features=256,out_features=120),nn.ReLU(),nn.Linear(in_features=120,out_features=84),nn.ReLU(),nn.Linear(in_features=84,out_features=10), )def forward(self,x):x=self.features(x)x=torch.flatten(x,1)result=self.classfier(x)return result
3. 新建模型
model=Lenet5()
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model=model.to(device)
4. 从数据集中分批量读取数据
from torch.utils.data import DataLoader
DataLoader?
from torch.utils.data import DataLoader
batch_size=32
train_loader=DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
test_loader=DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False)
5. 定义损失函数
from torch import optim
loss_fun=nn.CrossEntropyLoss()
loss_lst=[]
6. 定义优化器
optimizer=optim.SGD(params=model.parameters(),lr=0.001,momentum=0.9)
7. 开始训练
import time
start_time=time.time()
#训练的迭代次数
for i in range(10):loss_i=0for j,(batch_data,batch_label) in enumerate(train_loader):#清空优化器的梯度optimizer.zero_grad()#模型前向预测pred=model(batch_data)loss=loss_fun(pred,batch_label)loss_i+=lossloss.backward()optimizer.step()if (j+1)%200==0:print("第%d次训练,第%d批次,损失为%.2f"%(i,j,loss_i/200))loss_i=0
end_time=time.time()
print("共训练了%d 秒"%(end_time-start_time))
第0次训练,第199批次,损失为2.30
第0次训练,第399批次,损失为2.29
第0次训练,第599批次,损失为2.28
第0次训练,第799批次,损失为2.23
第0次训练,第999批次,损失为1.86
第0次训练,第1199批次,损失为0.81
第0次训练,第1399批次,损失为0.55
第0次训练,第1599批次,损失为0.46
第0次训练,第1799批次,损失为0.40
第1次训练,第199批次,损失为0.33
第1次训练,第399批次,损失为0.29
第1次训练,第599批次,损失为0.27
第1次训练,第799批次,损失为0.28
第1次训练,第999批次,损失为0.25
第1次训练,第1199批次,损失为0.22
第1次训练,第1399批次,损失为0.23
第1次训练,第1599批次,损失为0.22
第1次训练,第1799批次,损失为0.19
第2次训练,第199批次,损失为0.17
第2次训练,第399批次,损失为0.17
第2次训练,第599批次,损失为0.16
第2次训练,第799批次,损失为0.17
第2次训练,第999批次,损失为0.15
第2次训练,第1199批次,损失为0.15
第2次训练,第1399批次,损失为0.14
第2次训练,第1599批次,损失为0.14
第2次训练,第1799批次,损失为0.13
第3次训练,第199批次,损失为0.12
第3次训练,第399批次,损失为0.13
第3次训练,第599批次,损失为0.12
第3次训练,第799批次,损失为0.12
第3次训练,第999批次,损失为0.13
第3次训练,第1199批次,损失为0.12
第3次训练,第1399批次,损失为0.10
第3次训练,第1599批次,损失为0.11
第3次训练,第1799批次,损失为0.10
第4次训练,第199批次,损失为0.11
第4次训练,第399批次,损失为0.10
第4次训练,第599批次,损失为0.10
第4次训练,第799批次,损失为0.08
第4次训练,第999批次,损失为0.09
第4次训练,第1199批次,损失为0.09
第4次训练,第1399批次,损失为0.10
第4次训练,第1599批次,损失为0.08
第4次训练,第1799批次,损失为0.08
第5次训练,第199批次,损失为0.09
第5次训练,第399批次,损失为0.07
第5次训练,第599批次,损失为0.09
第5次训练,第799批次,损失为0.08
第5次训练,第999批次,损失为0.08
第5次训练,第1199批次,损失为0.08
第5次训练,第1399批次,损失为0.08
第5次训练,第1599批次,损失为0.07
第5次训练,第1799批次,损失为0.08
第6次训练,第199批次,损失为0.08
第6次训练,第399批次,损失为0.07
第6次训练,第599批次,损失为0.07
第6次训练,第799批次,损失为0.07
第6次训练,第999批次,损失为0.08
第6次训练,第1199批次,损失为0.07
第6次训练,第1399批次,损失为0.07
第6次训练,第1599批次,损失为0.07
第6次训练,第1799批次,损失为0.08
第7次训练,第199批次,损失为0.07
第7次训练,第399批次,损失为0.07
第7次训练,第599批次,损失为0.07
第7次训练,第799批次,损失为0.06
第7次训练,第999批次,损失为0.07
第7次训练,第1199批次,损失为0.06
第7次训练,第1399批次,损失为0.06
第7次训练,第1599批次,损失为0.07
第7次训练,第1799批次,损失为0.06
第8次训练,第199批次,损失为0.05
第8次训练,第399批次,损失为0.05
第8次训练,第599批次,损失为0.06
第8次训练,第799批次,损失为0.06
第8次训练,第999批次,损失为0.07
第8次训练,第1199批次,损失为0.06
第8次训练,第1399批次,损失为0.07
第8次训练,第1599批次,损失为0.06
第8次训练,第1799批次,损失为0.05
第9次训练,第199批次,损失为0.05
第9次训练,第399批次,损失为0.05
第9次训练,第599批次,损失为0.05
第9次训练,第799批次,损失为0.05
第9次训练,第999批次,损失为0.05
第9次训练,第1199批次,损失为0.06
第9次训练,第1399批次,损失为0.05
第9次训练,第1599批次,损失为0.05
第9次训练,第1799批次,损失为0.05
共训练了148 秒
8. 测试和保存模型
len(test_dataset)
10000
correct=0
for batch_data,batch_label in test_loader:pred_test=model(batch_data)pred_result=torch.max(pred_test.data,1)[1]correct+=(pred_result==batch_label).sum()
print("准确率为:%.2f%%"%(correct/len(test_dataset)))
准确率为:0.98%
#保存模型
torch.save(model, './model-cifar10.pth')
9. 手写体图片的可视化
from torchvision import transforms as T
import torch
import numpy as np
from PIL import Image
normalize = T.Normalize(mean=[127.5, 127.5, 127.5], std=[127.5, 127.5, 127.5])
arr1=np.random.rand(300, 320, 3) * 255
fake_img = T.ToPILImage()(arr1.astype("uint8"))
fake_img.show()
fake_img = normalize(T.ToTensor()(arr1))
print(fake_img.shape)
print(fake_img)
torch.Size([3, 300, 320])
tensor([[[-0.9172, -0.8087, 0.5650, ..., 0.5297, 0.8186, 0.3312],[-0.3795, -0.7144, 0.7482, ..., 0.7777, 0.0563, 0.9862],[ 0.4713, 0.1514, 0.1433, ..., 0.1218, 0.5960, 0.0122],...,[ 0.7886, -0.8431, 0.2048, ..., 0.0880, 0.8566, -0.7309],[-0.5249, -0.2610, 0.6604, ..., -0.5265, -0.8607, 0.8407],[-0.0764, -0.6659, -0.7282, ..., 0.6114, -0.8531, 0.8591]],[[-0.7804, -0.9011, 0.7292, ..., -0.7269, 0.4730, -0.4985],[ 0.5025, -0.9715, -0.5368, ..., -0.3784, 0.2336, -0.7914],[-0.3683, 0.5105, 0.4923, ..., 0.4562, 0.1588, 0.0781],...,[-0.7712, 0.4029, 0.5997, ..., 0.6086, -0.6148, 0.8007],[ 0.9939, 0.0161, -0.9449, ..., -0.6050, -0.3625, 0.0129],[-0.2682, -0.1006, -0.7786, ..., 0.0569, 0.0279, -0.3509]],[[-0.9476, 0.3883, 0.4793, ..., -0.2685, 0.9854, 0.9068],[ 0.4380, 0.1821, -0.1389, ..., -0.8316, 0.5408, -0.2924],[-0.3324, -0.8534, -0.9868, ..., -0.8449, -0.3564, -0.9859],...,[ 0.9973, 0.4672, -0.4873, ..., -0.5094, -0.6851, 0.2794],[ 0.9954, 0.8549, 0.1814, ..., -0.7077, -0.7606, 0.4524],[ 0.6209, 0.5317, -0.1966, ..., -0.8245, -0.8593, -0.1789]]],dtype=torch.float64)
len(train_dataset)
60000
train_dataset[0][0].shape
torch.Size([1, 28, 28])
import matplotlib.pyplot as plt
plt.imshow(train_dataset[3][0][0],cmap="gray")
<matplotlib.image.AxesImage at 0x217dc3c6bd0>
10. 多幅图片的可视化
from matplotlib import pyplot as plt
plt.figure(figsize=(20,15))
cols=10
rows=10
for i in range(0,rows):for j in range(0,cols):idx=j+i*colsplt.subplot(rows,cols,idx+1) plt.imshow(train_dataset[idx][0][0])plt.axis('off')

import numpy as np
img10 = np.stack(list(train_dataset[i][0][0] for i in range(10)), axis=1).reshape(28,280)
plt.imshow(img10)
plt.axis('off')
(-0.5, 279.5, 27.5, -0.5)

img100 = np.stack(tuple(np.stack(tuple(train_dataset[j*10+i][0][0] for i in range(10)), axis=1).reshape(28,280) for j in range(10)),axis=0).reshape(280,280)
plt.imshow(img100)
plt.axis('off')
(-0.5, 279.5, 279.5, -0.5)

思考题
- 测试集中有哪些识别错误的手写数字图片? 汇集整理并分析原因?
11. 读取测试集的图片预测值(神经网络的输出为10)
#导入模型
model1=torch.load('./model-cifar10.pth')
pre_result=torch.zeros(len(test_dataset),10)
for i in range(len(test_dataset)):pre_result[i,:]=model1(torch.reshape(test_dataset[i][0],(-1,1,28,28)))
pre_result
tensor([[-1.8005, -0.1725, 1.4765, ..., 13.5399, -0.6261, 3.8320],[ 4.3233, 7.6017, 16.5872, ..., -0.0560, 5.2066, -7.0792],[-2.1821, 9.3779, 0.7749, ..., 1.8749, 1.6951, -2.9422],...,[-5.5755, -2.2075, -9.2250, ..., -0.2451, 3.3703, 1.2951],[ 0.5491, -7.7018, -5.8288, ..., -7.6734, 9.3946, -1.9603],[ 3.5516, -8.2659, -0.5965, ..., -8.5934, 1.0133, -2.2048]],grad_fn=<CopySlices>)
pre_result.shape
torch.Size([10000, 10])
pre_result[:5]
tensor([[-1.8005e+00, -1.7254e-01, 1.4765e+00, 3.0824e+00, -2.5454e+00,-7.6911e-01, -1.2368e+01, 1.3540e+01, -6.2614e-01, 3.8320e+00],[ 4.3233e+00, 7.6017e+00, 1.6587e+01, 3.6477e+00, -6.6674e+00,-6.0579e+00, -1.5660e+00, -5.5983e-02, 5.2066e+00, -7.0792e+00],[-2.1821e+00, 9.3779e+00, 7.7487e-01, -3.0049e+00, 1.3374e+00,-1.6613e+00, 8.8544e-01, 1.8749e+00, 1.6951e+00, -2.9422e+00],[ 1.3456e+01, -9.9020e+00, 2.8586e+00, -2.2105e+00, -1.8515e+00,1.7651e-03, 4.7584e+00, -1.3772e+00, -2.2127e+00, 1.5543e+00],[-2.9573e+00, -2.5707e+00, -3.5142e+00, -1.7487e+00, 1.2020e+01,-8.8355e-01, -1.0698e+00, 6.3823e-01, -3.5542e-01, 3.6258e+00]],grad_fn=<SliceBackward0>)
#显示这10000张图片的标签
label_10000=[test_dataset[i][1] for i in range(10000)]
label_10000
[7,2,1,0,4,1,4,9,5,9,0,6,9,0,1,5,9,7,3,4,9,6,6,5,4,0,7,4,0,1,3,1,3,4,7,2,7,1,2,1,1,7,4,2,3,5,1,2,4,4,6,3,5,5,6,0,4,1,9,5,7,8,9,3,7,4,6,4,3,0,7,0,2,9,1,7,3,2,9,7,7,6,2,7,8,4,7,3,6,1,3,6,9,3,1,4,1,7,6,9,6,0,5,4,9,9,2,1,9,4,8,7,3,9,7,4,4,4,9,2,5,4,7,6,7,9,0,5,8,5,6,6,5,7,8,1,0,1,6,4,6,7,3,1,7,1,8,2,0,2,9,9,5,5,1,5,6,0,3,4,4,6,5,4,6,5,4,5,1,4,4,7,2,3,2,7,1,8,1,8,1,8,5,0,8,9,2,5,0,1,1,1,0,9,0,3,1,6,4,2,3,6,1,1,1,3,9,5,2,9,4,5,9,3,9,0,3,6,5,5,7,2,2,7,1,2,8,4,1,7,3,3,8,8,7,9,2,2,4,1,5,9,8,7,2,3,0,4,4,2,4,1,9,5,7,7,2,8,2,6,8,5,7,7,9,1,8,1,8,0,3,0,1,9,9,4,1,8,2,1,2,9,7,5,9,2,6,4,1,5,8,2,9,2,0,4,0,0,2,8,4,7,1,2,4,0,2,7,4,3,3,0,0,3,1,9,6,5,2,5,9,2,9,3,0,4,2,0,7,1,1,2,1,5,3,3,9,7,8,6,5,6,1,3,8,1,0,5,1,3,1,5,5,6,1,8,5,1,7,9,4,6,2,2,5,0,6,5,6,3,7,2,0,8,8,5,4,1,1,4,0,3,3,7,6,1,6,2,1,9,2,8,6,1,9,5,2,5,4,4,2,8,3,8,2,4,5,0,3,1,7,7,5,7,9,7,1,9,2,1,4,2,9,2,0,4,9,1,4,8,1,8,4,5,9,8,8,3,7,6,0,0,3,0,2,6,6,4,9,3,3,3,2,3,9,1,2,6,8,0,5,6,6,6,3,8,8,2,7,5,8,9,6,1,8,4,1,2,5,9,1,9,7,5,4,0,8,9,9,1,0,5,2,3,7,8,9,4,0,6,3,9,5,2,1,3,1,3,6,5,7,4,2,2,6,3,2,6,5,4,8,9,7,1,3,0,3,8,3,1,9,3,4,4,6,4,2,1,8,2,5,4,8,8,4,0,0,2,3,2,7,7,0,8,7,4,4,7,9,6,9,0,9,8,0,4,6,0,6,3,5,4,8,3,3,9,3,3,3,7,8,0,8,2,1,7,0,6,5,4,3,8,0,9,6,3,8,0,9,9,6,8,6,8,5,7,8,6,0,2,4,0,2,2,3,1,9,7,5,1,0,8,4,6,2,6,7,9,3,2,9,8,2,2,9,2,7,3,5,9,1,8,0,2,0,5,2,1,3,7,6,7,1,2,5,8,0,3,7,2,4,0,9,1,8,6,7,7,4,3,4,9,1,9,5,1,7,3,9,7,6,9,1,3,7,8,3,3,6,7,2,8,5,8,5,1,1,4,4,3,1,0,7,7,0,7,9,4,4,8,5,5,4,0,8,2,1,0,8,4,5,0,4,0,6,1,7,3,2,6,7,2,6,9,3,1,4,6,2,5,4,2,0,6,2,1,7,3,4,1,0,5,4,3,1,1,7,4,9,9,4,8,4,0,2,4,5,1,1,6,4,7,1,9,4,2,4,1,5,5,3,8,3,1,4,5,6,8,9,4,1,5,3,8,0,3,2,5,1,2,8,3,4,4,0,8,8,3,3,1,7,3,5,9,6,3,2,6,1,3,6,0,7,2,1,7,1,4,2,4,2,1,7,9,6,1,1,2,4,8,1,7,7,4,8,0,7,3,1,3,1,0,7,7,0,3,5,5,2,7,6,6,9,2,8,3,5,2,2,5,6,0,8,2,9,2,8,8,8,8,7,4,9,3,0,6,6,3,2,1,3,2,2,9,3,0,0,5,7,8,1,4,4,6,0,2,9,1,4,7,4,7,3,9,8,8,4,7,1,2,1,2,2,3,2,3,2,3,9,1,7,4,0,3,5,5,8,6,3,2,6,7,6,6,3,2,7,8,1,1,7,5,6,4,9,5,1,3,3,4,7,8,9,1,1,6,9,1,4,4,5,4,0,6,2,2,3,1,5,1,2,0,3,8,1,2,6,7,1,6,2,3,9,0,1,2,2,0,8,9,...]
import numpy as np
pre_10000=pre_result.detach()
pre_10000
tensor([[-1.8005, -0.1725, 1.4765, ..., 13.5399, -0.6261, 3.8320],[ 4.3233, 7.6017, 16.5872, ..., -0.0560, 5.2066, -7.0792],[-2.1821, 9.3779, 0.7749, ..., 1.8749, 1.6951, -2.9422],...,[-5.5755, -2.2075, -9.2250, ..., -0.2451, 3.3703, 1.2951],[ 0.5491, -7.7018, -5.8288, ..., -7.6734, 9.3946, -1.9603],[ 3.5516, -8.2659, -0.5965, ..., -8.5934, 1.0133, -2.2048]])
pre_10000=np.array(pre_10000)
pre_10000
array([[-1.8004757 , -0.17253768, 1.4764961 , ..., 13.539932 ,-0.6261405 , 3.832048 ],[ 4.323273 , 7.601658 , 16.587166 , ..., -0.05598306,5.20656 , -7.0792093 ],[-2.1820781 , 9.377863 , 0.7748679 , ..., 1.8749483 ,1.6950815 , -2.9421623 ],...,[-5.575542 , -2.2075167 , -9.225033 , ..., -0.24509335,3.3702612 , 1.2950805 ],[ 0.5491407 , -7.7017508 , -5.8287773 , ..., -7.6733685 ,9.39456 , -1.9602803 ],[ 3.5516088 , -8.265893 , -0.59651583, ..., -8.593432 ,1.0132635 , -2.2048213 ]], dtype=float32)
12. 采用pandas可视化数据
import pandas as pd
table=pd.DataFrame(zip(pre_10000,label_10000))
table
| 0 | 1 | |
|---|---|---|
| 0 | [-1.8004757, -0.17253768, 1.4764961, 3.0824265... | 7 |
| 1 | [4.323273, 7.601658, 16.587166, 3.6476722, -6.... | 2 |
| 2 | [-2.1820781, 9.377863, 0.7748679, -3.0049446, ... | 1 |
| 3 | [13.455704, -9.902006, 2.8586285, -2.2104588, ... | 0 |
| 4 | [-2.9572597, -2.5707455, -3.5142026, -1.748683... | 4 |
| ... | ... | ... |
| 9995 | [-2.5784128, 10.5256405, 23.895123, 8.827512, ... | 2 |
| 9996 | [-2.773907, 0.56169015, 1.6811254, 15.230703, ... | 3 |
| 9997 | [-5.575542, -2.2075167, -9.225033, -5.60418, 1... | 4 |
| 9998 | [0.5491407, -7.7017508, -5.8287773, 2.2394006,... | 5 |
| 9999 | [3.5516088, -8.265893, -0.59651583, -4.034732,... | 6 |
10000 rows × 2 columns
table[0].values
array([array([ -1.8004757 , -0.17253768, 1.4764961 , 3.0824265 ,-2.545419 , -0.76911056, -12.368087 , 13.539932 ,-0.6261405 , 3.832048 ], dtype=float32) ,array([ 4.323273 , 7.601658 , 16.587166 , 3.6476722 , -6.6673512 ,-6.05786 , -1.5660243 , -0.05598306, 5.20656 , -7.0792093 ],dtype=float32) ,array([-2.1820781, 9.377863 , 0.7748679, -3.0049446, 1.3374403,-1.6612737, 0.8854448, 1.8749483, 1.6950815, -2.9421623],dtype=float32) ,...,array([-5.575542 , -2.2075167 , -9.225033 , -5.60418 , 17.216341 ,2.8671436 , 1.0113716 , -0.24509335, 3.3702612 , 1.2950805 ],dtype=float32) ,array([ 0.5491407, -7.7017508, -5.8287773, 2.2394006, -7.533697 ,13.003905 , 6.1807218, -7.6733685, 9.39456 , -1.9602803],dtype=float32) ,array([ 3.5516088 , -8.265893 , -0.59651583, -4.034732 , 1.3853229 ,6.1974382 , 16.321545 , -8.593432 , 1.0132635 , -2.2048213 ],dtype=float32) ],dtype=object)
table["pred"]=[np.argmax(table[0][i]) for i in range(table.shape[0])]
table
| 0 | 1 | pred | |
|---|---|---|---|
| 0 | [-1.8004757, -0.17253768, 1.4764961, 3.0824265... | 7 | 7 |
| 1 | [4.323273, 7.601658, 16.587166, 3.6476722, -6.... | 2 | 2 |
| 2 | [-2.1820781, 9.377863, 0.7748679, -3.0049446, ... | 1 | 1 |
| 3 | [13.455704, -9.902006, 2.8586285, -2.2104588, ... | 0 | 0 |
| 4 | [-2.9572597, -2.5707455, -3.5142026, -1.748683... | 4 | 4 |
| ... | ... | ... | ... |
| 9995 | [-2.5784128, 10.5256405, 23.895123, 8.827512, ... | 2 | 2 |
| 9996 | [-2.773907, 0.56169015, 1.6811254, 15.230703, ... | 3 | 3 |
| 9997 | [-5.575542, -2.2075167, -9.225033, -5.60418, 1... | 4 | 4 |
| 9998 | [0.5491407, -7.7017508, -5.8287773, 2.2394006,... | 5 | 5 |
| 9999 | [3.5516088, -8.265893, -0.59651583, -4.034732,... | 6 | 6 |
10000 rows × 3 columns
13. 对预测错误的样本点进行可视化
mismatch=table[table[1]!=table["pred"]]
mismatch
| 0 | 1 | pred | |
|---|---|---|---|
| 247 | [-0.28747877, 1.9184055, 8.627771, -3.1354206,... | 4 | 2 |
| 340 | [-5.550468, 1.6552217, -0.96347404, 9.110174, ... | 5 | 3 |
| 449 | [-6.0154114, -3.7659, -2.7571707, 14.220249, -... | 3 | 5 |
| 582 | [-1.4626387, 1.3258317, 10.138913, 5.996572, -... | 8 | 2 |
| 659 | [-3.1300178, 8.830592, 8.781635, 5.6512327, -3... | 2 | 1 |
| ... | ... | ... | ... |
| 9768 | [2.6190603, -5.539648, 3.0145228, 4.8416886, -... | 2 | 3 |
| 9770 | [7.0385275, -9.72994, 0.03886398, -0.3356622, ... | 5 | 6 |
| 9792 | [-0.84618676, -0.038114145, -4.388391, 0.12577... | 4 | 9 |
| 9904 | [1.6193992, -7.525599, 2.833153, 3.7744582, -2... | 2 | 8 |
| 9982 | [0.8662107, -7.932593, -0.3750058, 1.9749051, ... | 5 | 6 |
158 rows × 3 columns
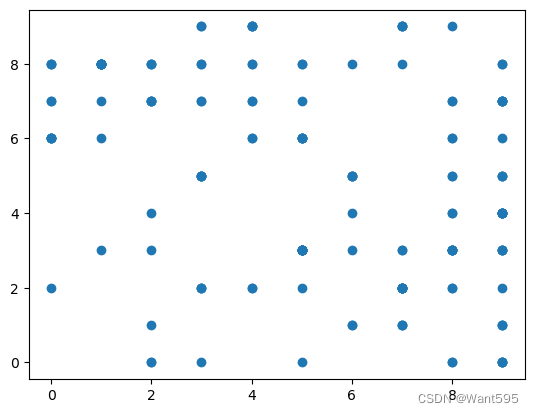
from matplotlib import pyplot as plt
plt.scatter(mismatch[1],mismatch["pred"])
<matplotlib.collections.PathCollection at 0x217dc403490>
14. 看看错误样本被预测为哪些数据
mismatch[mismatch[1]==8].sort_values("pred").index
Int64Index([4807, 2896, 582, 6625, 7220, 3871, 4123, 1878, 1319, 2179, 4601,4956, 3023, 9280, 8408, 6765, 4497, 1530, 947],dtype='int64')
table.iloc[4500,:]
0 [-4.9380565, 6.2523484, -1.2272537, 0.32682633...
1 9
pred 1
Name: 4500, dtype: object
idx_lst=mismatch[mismatch[1]==8].sort_values("pred").index.values
idx_lst,len(idx_lst)
(array([4807, 2896, 582, 6625, 7220, 3871, 4123, 1878, 1319, 2179, 4601,4956, 3023, 9280, 8408, 6765, 4497, 1530, 947], dtype=int64),19)
mismatch[mismatch[1]==8].sort_values("pred")
| 0 | 1 | pred | |
|---|---|---|---|
| 4807 | [5.3192024, -4.2546616, 3.6083155, 3.8956034, ... | 8 | 0 |
| 2896 | [7.4840407, -8.972937, 0.9461607, 1.6278361, -... | 8 | 0 |
| 582 | [-1.4626387, 1.3258317, 10.138913, 5.996572, -... | 8 | 2 |
| 6625 | [-5.413072, 2.7984824, 6.0430045, 2.3938487, 0... | 8 | 2 |
| 7220 | [-3.1443837, -3.4629154, 4.8560658, 12.752452,... | 8 | 3 |
| 3871 | [0.1749076, -5.8143945, 3.083826, 8.113558, -5... | 8 | 3 |
| 4123 | [-3.8682778, -2.290763, 6.1067047, 10.920237, ... | 8 | 3 |
| 1878 | [-2.8437655, -2.4290323, 3.1861248, 9.739316, ... | 8 | 3 |
| 1319 | [3.583813, -6.279593, -0.21310738, 7.2746606, ... | 8 | 3 |
| 2179 | [-0.57300043, -3.8434098, 8.02766, 12.139142, ... | 8 | 3 |
| 4601 | [-9.5640745, -2.1305811, -5.2161045, 2.3105593... | 8 | 4 |
| 4956 | [-7.5286517, -4.080871, -6.850239, -2.9094412,... | 8 | 4 |
| 3023 | [-2.6319933, -11.065216, -1.3231966, 0.0415189... | 8 | 5 |
| 9280 | [-1.9706918, -11.544259, -0.51283014, 3.955923... | 8 | 5 |
| 8408 | [1.0573181, -3.7079592, 0.34973174, -0.3489528... | 8 | 6 |
| 6765 | [2.8831, -2.6855779, 0.39529848, -1.855415, -2... | 8 | 6 |
| 4497 | [-4.830113, -0.28656, 4.911254, 4.4041815, -2.... | 8 | 7 |
| 1530 | [-4.4495664, -2.5381584, 5.4418654, 9.994939, ... | 8 | 7 |
| 947 | [-2.8835857, -8.3713045, -1.5150836, 3.1263702... | 8 | 9 |
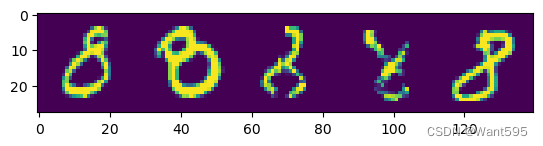
import numpy as np
img=np.stack(list(test_dataset[idx_lst[i]][0][0] for i in range(5)),axis=1).reshape(28,28*5)
plt.imshow(img)
<matplotlib.image.AxesImage at 0x217dc28e9d0>
#显示3行
import numpy as np
img30=np.stack(tuple(np.stack(tuple(test_dataset[idx_lst[i+j*5]][0][0] for i in range(5)),axis=1).reshape(28,28*5) for j in range(3)),axis=0).reshape(28*3,28*5)
plt.imshow(img30)
plt.axis('off')
(-0.5, 139.5, 83.5, -0.5)

arr2=table.iloc[idx_lst[:30],2].values
arr2
array([0, 0, 2, 2, 3, 3, 3, 3, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 9],dtype=int64)
相关文章:
【Python机器学习】实验14 手写体卷积神经网络(PyTorch实现)
文章目录 LeNet-5网络结构(1)卷积层C1(2)池化层S1(3)卷积层C2(4)池化层S2(5)卷积层C3(6)线性层F1(7)线性层F2 …...
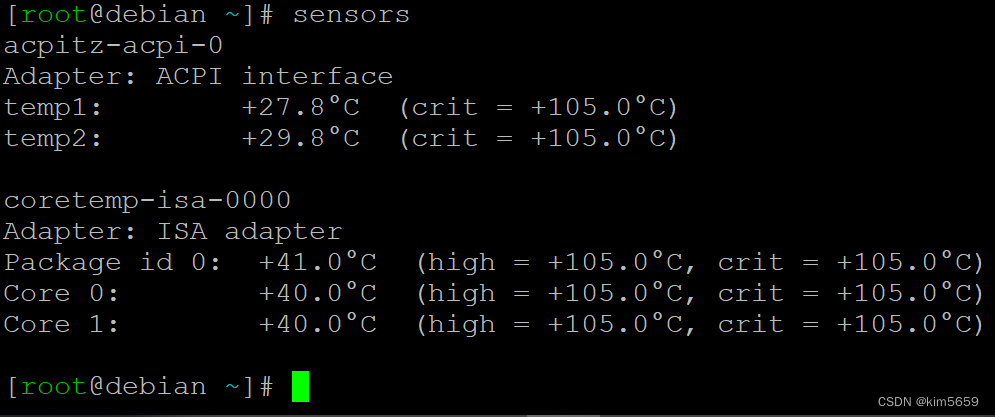
Debian查询硬件状态
很早以前写过一个查询树霉派硬件状态的文章,用是Python写的一个小程序。里面用到了vcgencmd这个测温度的内部命令,但这个命令在debian里面没有,debian里只有lm_sensors的外部命令,需要安装:apt-get install lm_sensors…...
)
除自身以外数组的乘积(c语言详解)
题目:除自身外数组的乘积 给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据保证数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请不要使用除…...

ONES × 鲁邦通|打造研发一体化平台,落地组织级流程规范
近日,ONES 签约工业互联网行业领先的解决方案提供商——鲁邦通,助力鲁邦通优化组织级流程规范,落地从需求到交付的全生命周期线上化管理。 依托于 ONES 一站式研发管理平台,鲁邦通在软硬件设计开发、项目管理和精益生产等方面的数…...
【GaussDB】 SQL 篇
建表语句 表的分类 普通的建表语句 复制表内容 只复制表结构 create table 新表名(like 源表名 including all); 如果希望注释被复制的话要指定including comments 复制索引、主键约束和唯一约束,那么需要指定including indexes including constraints …...
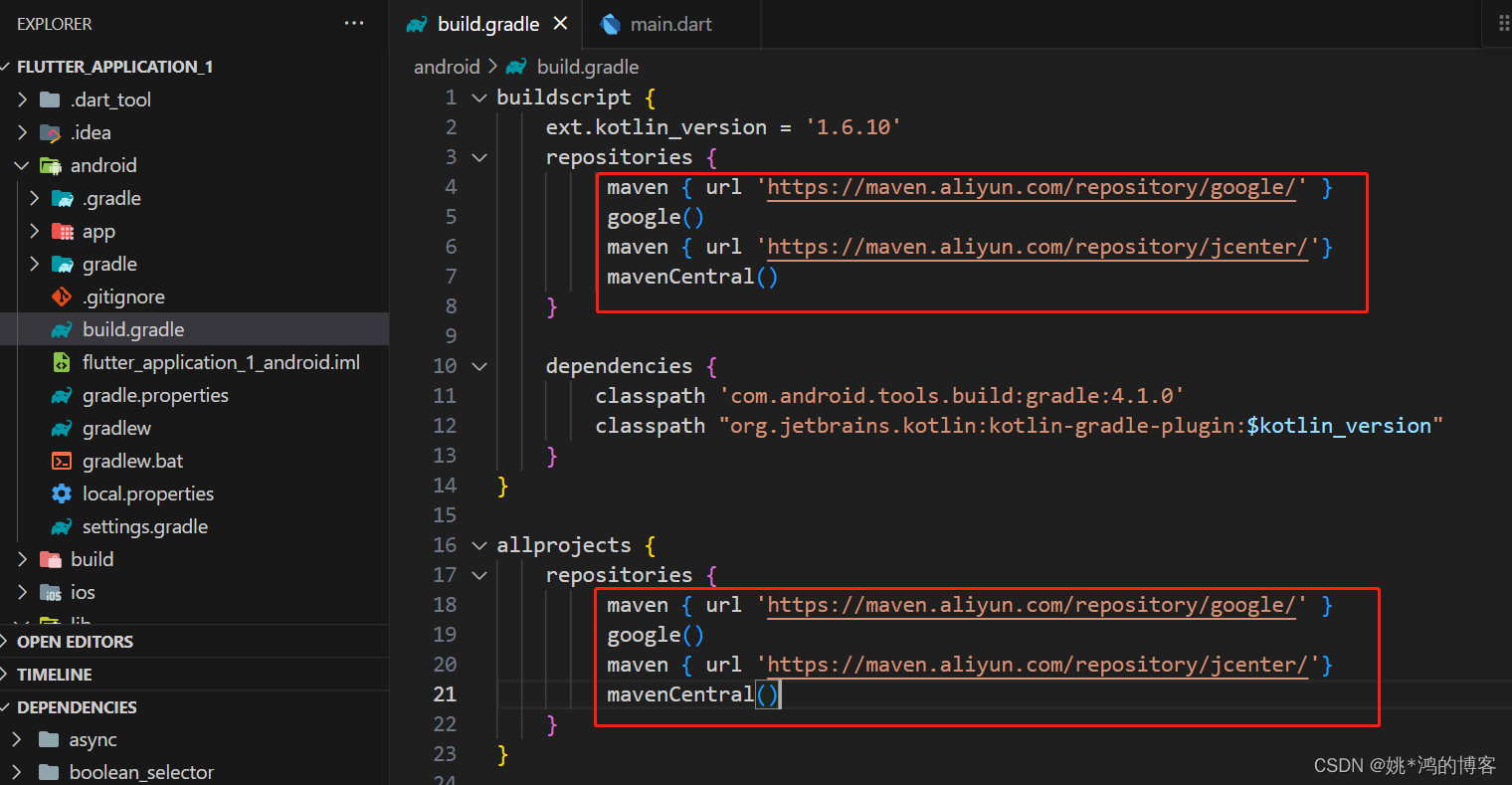
rn和flutter出现“Running Gradle task ‘assembleDebug
在第一次运行rn和flutter时,会卡在Running Gradle task assembleDebug,可以使用阿里的镜像,如下图: maven { url https://maven.aliyun.com/repository/google/ } google() maven { url https://maven.aliyun.com/repository/jcen…...

Shell脚本基础( 四: sed编辑器)
目录 1 简介 1.1 sed编辑器的工作流程 2 sed 2.1 基本用法 2.2 sed基本格式 2.2.1 sed支持正则表达式 2.2.2 匹配正则表达式 2.2.3 奇数偶数表示 2.2.4 -d选项删除 2.2.5 -i修改文件内容 2.2.6 -a 追加 2.3 搜索替代 2.4 变量 1 简介 sed是一种流编辑器,…...
微信消息没通知iphone can‘t show notifications
小虎最近手机微信消息没通知,本来以为要卸载,但是发现原来是多客户端登录导致消息被其他平台截取,所有没有通知。 解决方法 小虎是在手机和电脑端同时登录的,所有退出电脑端后手机新消息就有提示了。可能是一个bug。...

Linux Kernel:pid与namespace
环境: Kernel Version:Linux-5.10 ARCH:ARM64 一:前言 Linux内核涉及进程和程序的所有算法都围绕task_struct数据结构建立,具体可看另一篇文章: Linux Kernel:thread_info与task_struct 同时Linux提供了资源限制(resource limit, rlimit)机制,对进程使用系统资源施…...
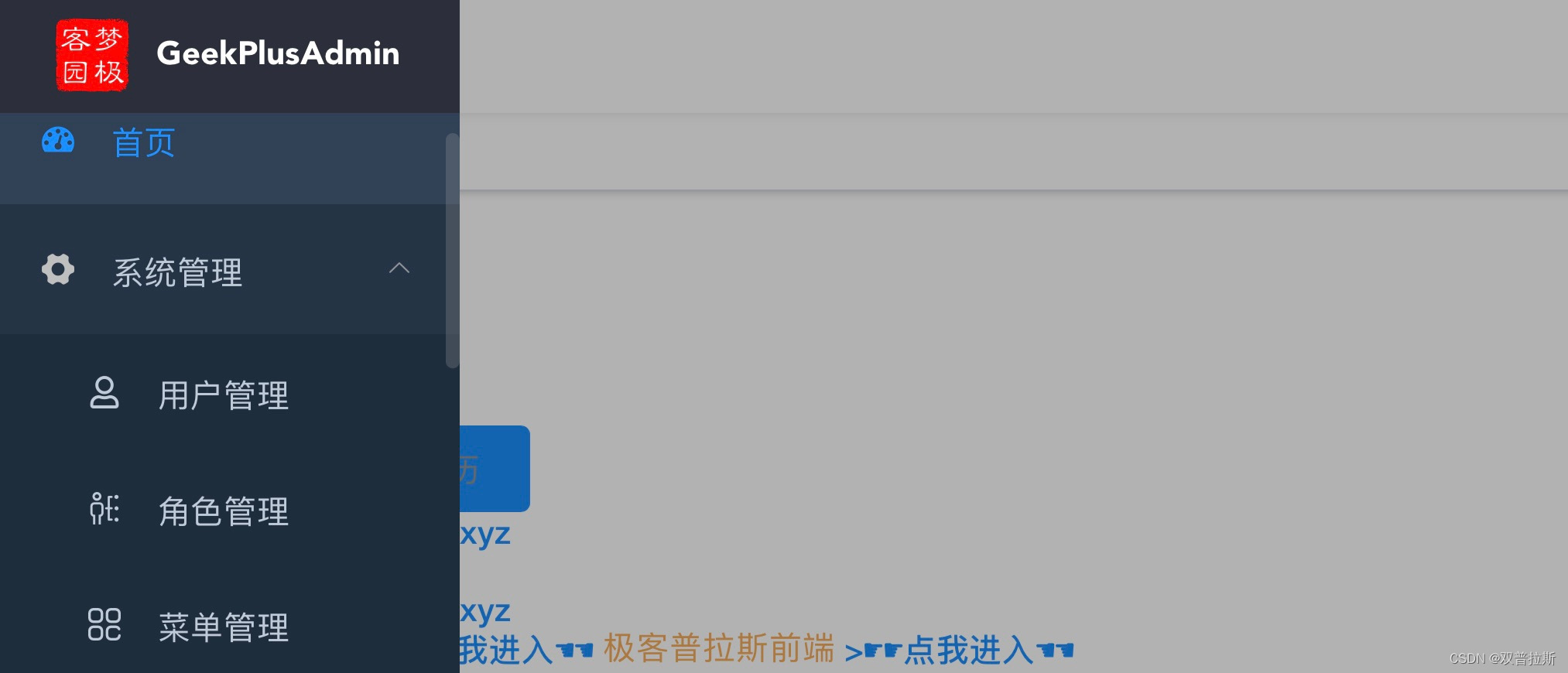
开源后台管理系统Geekplus Admin
本系统采用前后端分离开发模式,后端采用springboot开发技术栈,mybatis持久层框架,redis缓存,shiro认证授权框架,freemarker模版在线生成代码,websocket消息推送等,后台管理包含用户管理…...
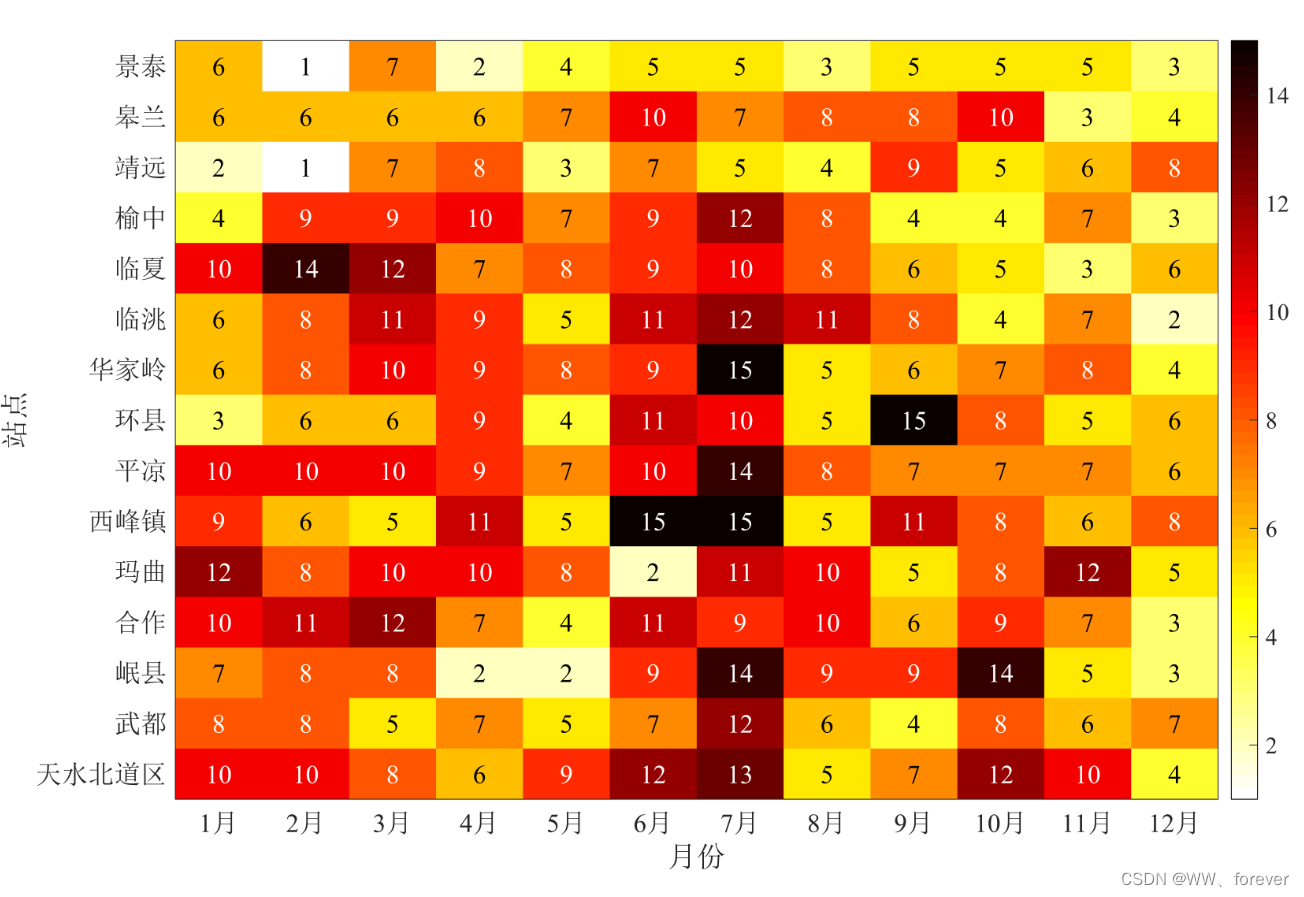
【MATLAB基础绘图第16棒】绘制热图(Heatmap)
热图(Heatmap) 热图的主要作用是直观展示重点研究对象的差异情况,多用于经济学与工学差异性分析之中。 heatmap函数创建热图 语法 hheatmap(tbl,xvar,yvar) hheatmap(tbl,xvar,yvar,ColorVariable,cvar) hheatmap(cdata) hheatmap(xvalue…...
数据库--SQL关键字的执行顺序
数据库相关链接: 数据库--数据类型:http://t.csdn.cn/RtqMD 数据库--三大范式、多表查询、函数sql:http://t.csdn.cn/udJSG 数据库--MySQL增删改查:http://t.csdn.cn/xkiti 一、一条sql语句通常包括: select fro…...

如何优雅地处理Java多线程编程中的共享资源问题,以确保线程安全和高性能?
文章目录 🎉欢迎来到Java面试技巧专栏~如何优雅地处理Java多线程编程中的共享资源问题? ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页:IT陈寒的博客🎈该系列文章专栏:Java面试技巧文章作者技术和水平有限&…...
每天一道leetcode:剑指 Offer 64. 求1+2+…+n(中等递归)
今日份题目: 求 12...n ,要求不能使用乘除法、for、while、if、else、switch、case等关键字及条件判断语句(A?B:C)。 示例1 输入: n 3 输出: 6 示例2 输入: n 9 输出: 45 提示 1 < n < 10000 题目思路 使用递归…...
服务器安装centos7踩坑
1、制作启动工具 下载iso https://developer.aliyun.com/mirror/?spma2c6h.25603864.0.0.20387abbo2RFbn http://mirrors.aliyun.com/centos/7.9.2009/isos/x86_64/?spma2c6h.25603864.0.0.1995f5ad4AhJaW下载 UltraISO https://cn.ultraiso.net/插入u盘启动 到了如图所示页面…...
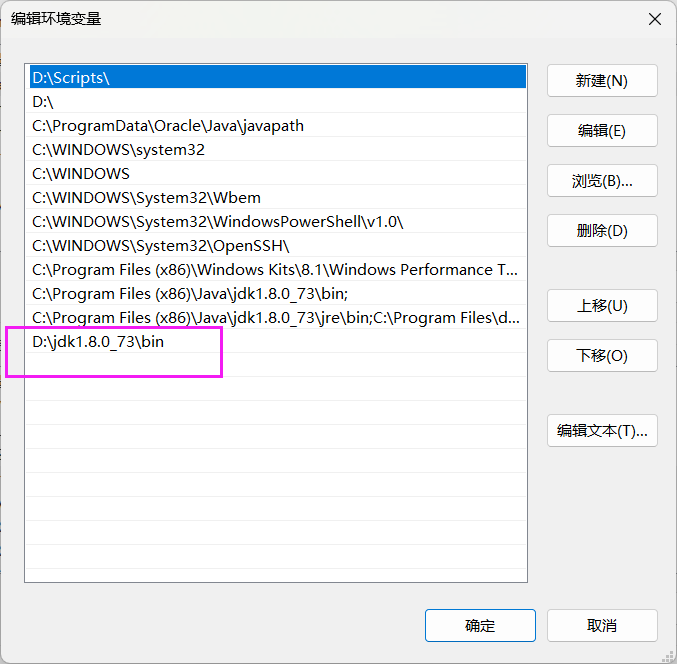
Java | IDEA中 jconsole 不是内部或外部命令,也不是可运行的程序
解决办法: 1.先将Terminal的Shell path 修改为C:\WINDOWS\system32\cmd.exe 2.在检查环境变量中的ComSpec的值 3.找到自己电脑下载的jdk的bin的地址 4.将jdk的bin地址加入到系统变量path中...

将Swift Package构建为通用二进制文件 Universal Binary
将Swift软件包构建为通用二进制文件 因此,在苹果在WWDC 2020期间宣布他们将把Mac从英特尔处理器过渡到苹果硅之后,现在是时候让每个人都准备好他们的软件了。 对大多数人来说,这次过渡可能更容易一些,特别是那些已经在iOS上支持a…...
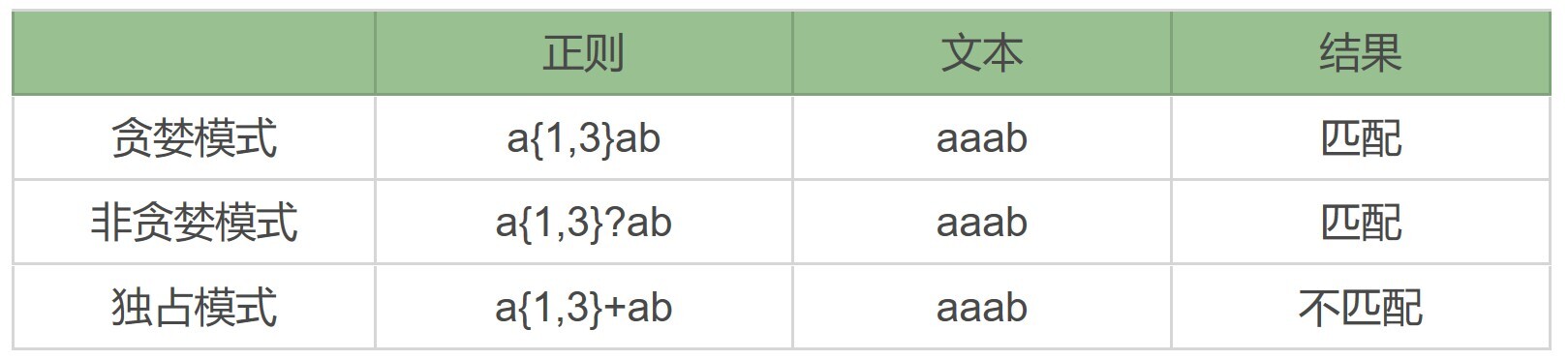
正则表达式:贪婪与非贪婪模式
正则中的三种模式,贪婪匹配、非贪婪匹配和独占模式。 在这 6 种元字符中,我们可以用 {m,n} 来表示 (*)()(?) 这 3 种元字符: 贪婪模式,简单说就是尽可能进行…...
)
UVa247 Calling Circles(Floyd warshall算法)
题意 给定两个人相互打电话,如果a打给b,b打给c,c打给a,则说a,b,c在同一电话圈中。给出n个人的m次通话,输出所有的电话圈 思路 用graph[u][v]1表示u和v之间有打电话。在使用floyd算法计算所有的点对之间的值。graph[u][v]1表示u,v之间有直接…...
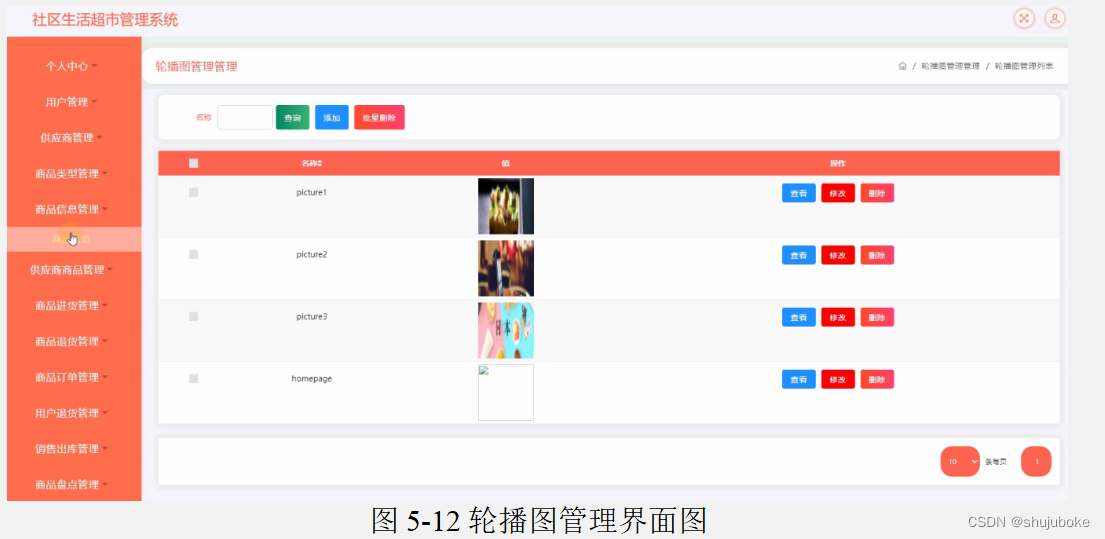
Java项目之基于ssm框架的社区生活超市管理系统(附源码)
基于ssm框架的社区生活超市管理系统设计与实现(程序源码毕业论文) 大家好,今天给大家介绍基于ssm框架的社区生活超市管理系统设计与实现,本论文只截取部分文章重点,文章末尾附有本毕业设计完整源码及论文的获取方式。更…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

C++八股 —— 单例模式
文章目录 1. 基本概念2. 设计要点3. 实现方式4. 详解懒汉模式 1. 基本概念 线程安全(Thread Safety) 线程安全是指在多线程环境下,某个函数、类或代码片段能够被多个线程同时调用时,仍能保证数据的一致性和逻辑的正确性…...

Kafka入门-生产者
生产者 生产者发送流程: 延迟时间为0ms时,也就意味着每当有数据就会直接发送 异步发送API 异步发送和同步发送的不同在于:异步发送不需要等待结果,同步发送必须等待结果才能进行下一步发送。 普通异步发送 首先导入所需的k…...