Datawhale Django后端开发入门 TASK03 QuerySet和Instance、APIVIew

一、QuerySet
QuerySet 是 Django 中的一个查询集合,它是由 Model.objects 方法返回的,并且可以用于生成数据库中所有满足一定条件的对象的列表。
QuerySet 在 Django 中表示从数据库中获取的对象集合,它是一个可迭代的、类似列表的对象集合。主要特点包括:- 从 Model.objects 获得,表示数据库中所有该 Model 的对象集合。
- 可以添加过滤条件来限制查询结果,如 .filter()、`.exclude()`、`.order_by()` 等。
- 惰性执行,创建 QuerySet 不会立即执行查询,只有在需要求值时才查询数据库。- 可遍历,可以用在 for 循环中进行迭代。- 可切片,使用索引切片来获取一个子集。
- 支持链式调用过滤方法,每个过滤调用返回一个新的 QuerySet。
- 可以获取单个元素,如 .get() 返回单个匹配的对象。
- 支持转换为其他对象列表,如 .values()。
- 可以转为字符串执行原始 SQL 查询。所以 QuerySet 是从数据库中获取模型对象数据的一个强大而灵活的接口。正确使用可以最大限度减少数据库查询,提高效率。每个 QuerySet 包含多个 Model 实例(Instance),表示满足查询条件的所有对象实例。
1.filter()方法接收的参数有:- 字段名,比如:.filter(name='John')
- 查询表达式,比如: .filter(age__gt=18)
- Q对象,用于复杂查询,比如:
from django.db.models import Qqueryset.filter(Q(age__gt=18) & Q(name='John'))关键字参数,比如:.filter(name='John', age__gt=18)filter()会基于给定的参数生成一个新的过滤后的QuerySet。例如:
Article.objects.filter(published=True) # 已发布文章Article.objects.filter(title__contains='Django') # 标题包含Django的文章Article.objects.filter(Q(title__contains='Django') | Q(title__contains='Python'))
# 标题包含Django或Python的文章重要的是,filter()并不会立即执行查询,只是返回一个新的QuerySet,真正的数据库查询会在需要求值的时候发生。我们可以多次调用filter()来链式过滤,每个filter()调用会基于前一个QuerySet然后返回一个新的QuerySet。
2.get()
get()方法与filter()有些类似,主要区别在于:
(1. get()用来获取单个对象,而filter()获取一个对象集合(queryset)。
(2. get()只能返回一个满足条件的对象实例,如果不存在会引发模型类的DoesNotExist异常。
(3. get()无法链接调用,只能获取单个对象。例如:
# 获取id=1的文章
article = Article.objects.get(id=1) # 查询标题包含'Python'的文章,如果不存在会报错
article = Article.objects.get(title__contains='Python')# filter()返回满足条件的所有文章
articles = Article.objects.filter(title__contains='Python')所以get()主要用于根据过滤条件获取单个对象,这对于获取某个具体模型实例很有用,但需要注意如果不存在会引发异常。而filter()用于获取多个满足条件的对象,这对获取一个QuerySet集合并对其进一步处理很有用。需要根据具体场景选择使用get()还是filter()。
3.all()
Django中的`Model.objects.all()`方法返回该模型的全部对象集合。它相当于没有任何过滤条件的`filter()`查询:
Article.objects.all()
# 等同于
Article.objects.filter()all()返回的是一个包含该模型所有对象的QuerySet。我们可以在`all()`的基础上进一步链式过滤:
Article.objects.all().filter(published=True) all()对于获取某个模型的全部数据很有用。当然,如果数据量很大,我们可能需要限制返回的数据条数,以提高性能。另外,all()每次都会查询数据库。如果需要多次使用全部数据集,可以考虑使用缓存或预取相关对象:prefetch_related()。所以在合适的时候使用`all()`可以方便地获取模型的全部实例,但需要注意数据量大小和重复查询的问题。
4.delete()
delete()方法将删除QuerySet中的所有对象,并返回删除的对象数量。
@action(detail=False, methods=['get','post'])def delete_example(self, request):name = request.data.get('name')# 删除名称为 'name' 的商品categories_to_delete = GoodsCategory.objects.filter(name=name)# 使用delete()方法删除对象deleted_count= categories_to_delete.delete()print(f"Deleted {deleted_count} categories.") 主要流程是:1. 通过filter()筛选出需要删除的对象集合2. 在这个QuerySet上调用delete()方法实现删除3. delete()方法会删除QuerySet中的所有对象,并返回删除的对象数量所以delete()为批量删除QuerySet中的对象提供了很好的便利。注意delete()会立即执行删除操作,不像filter()那样是延迟执行。另外,delete()默认不会触发模型的delete()方法,如果需要调用可以设置:
categories_to_delete.delete(keep_parents=False)这样会为每个对象调用delete()方法。delete()方法非常适合批量删除不需要的对象,可以用来定期清理数据库。但需要注意确保筛选条件正确,避免误删除。
5.update()
update() 方法将对QuerySet进行筛选,获取需要更新的对象集合,然后执行数据库更新操作。基本语法如下:
queryset.update(字段1=值1, 字段2=值2...)这将设置指定的字段到相应的值。例如:
Article.objects.filter(published=True).update(status='p')
# 将已发布文章的状态都设为'p'Article.objects.filter(id__in=[1,2,3]).update(views=F('views') + 1)
# 对id为1,2,3的文章浏览量增1update()默认只会更新指定的字段。需要注意,update()同样会立即执行更新,并返回更新的行数。update()提供了一个非常高效的批量更新对象方法,可以避免大量的单个对象更新开销。但同样需要确保更新条件的准确性。
6.create()
create() 方法是 save() 方法的快捷方式,用于创建并保存一个新的对象。
@action(detail=False, methods=['get','post'])def create_example(self, request):name = request.data.get('name')# 使用create()方法创建新的商品分类对象created_category = GoodsCategory.objects.create(name)print("Created category:", created_category) 主要的用法是:
GoodsCategory.objects.create(name='名称', field1='值1',...)这将实例化GoodsCategory,为其设置指定的字段值,然后直接保存到数据库中。与下面的用法等价:
category = GoodsCategory(name='名称', field1='值1',...)
category.save()所以create()方法对于快速创建对象非常方便,尤其是在数据初始化或者测试中可以减少代码量。需要注意:- create()参数必须提供对象必填字段的值
- create()会自动保存对象,无需再调用save()
- 创建成功后会返回新创建的对象实例综上,create()是save()方法的一个非常好用的封装,可以简化对象创建的代码。
7.count()
Django QuerySet 中的 count() 方法可以用来返回满足指定查询条件的对象的总数。count() 方法会执行查询,获取匹配查询(filters)的对象数目。使用方式:
Article.objects.filter(published=True).count() # 返回已发布文章数Article.objects.filter(title__contains='Django').count() # 返回标题包含'Django'的文章数Article.objects.filter(published=True).count() # 返回已发布文章数 Article.objects.filter(title__contains='Django').count() # 返回标题包含'Django'的文章数
count()会执行查询数据库的COUNT操作,性能上比提取所有对象再计算列表长度要更高效,尤其是数据量很大的时候。我们可以像链式调用filter()一样,链式调用count()来获取不同条件下的数量:
Article.objects.filter(published=True).filter(views__gt=10).count()
# 返回已发布且浏览量大于10的文章数。需要注意,使用count()之后再继续链式过滤就不会生效了。所以count()为我们提供了一个简单直观的方式来获取查询集大小。可以用来判断是否有匹配的对象,或者计算比较不同查询的结果数目。
8.order_by()
Django QuerySet 中order_by()方法用于对返回的对象进行排序。order_by()的常见用法:
# 按发布日期升序排序
Article.objects.order_by('publish_date') # 按浏览量降序排序
Article.objects.order_by('-views')# 先按发布日期降序,再按标题升序
Article.objects.order_by('-publish_date', 'title')默认order_by()是按升序排列的,如果需要降序,可以在参数字段名前加一个负号-。可以传递多个字段名来先后进行排序,如上面的例子。order_by()通常用在需要排序的查询中,比如获取最新文章:
latest_articles = Article.objects.order_by('-publish_date')[:10] 需要注意order_by()通常应该放在链式查询的最后,因为它会改变查询结果的顺序。order_by()非常实用,可以帮助我们按任意字段排序查询集,灵活地获取需要的数据。
9.values()
在Django中,values()方法可以用来获取QuerySet中的对象的指定字段的值,返回一个ValueQueryset,里面是以字典形式包含指定字段值的对象。那么
Map.objects.all().values().first()的作用就是:
(1. Map.objects.all() 返回Map模型的全部对象的QuerySet
(2. 在这个QuerySet上调用`.values()`,不指定任何字段,那么会返回包含每个对象的所有字段及值的字典。
(3. 最后调用.first()返回第一个对象的字段字典。例如,如果Map模型有字段id, name, address,那么它类似于:
{'id': 1,'name': 'John','address': '123 Main St'
}如果我们只需要名称和地址:
Map.objects.all().values('name', 'address').first()那么得到的是:
{'name': 'John','address': '123 Main St'
}这可以避免提取整个对象然后访问字段,提高效率。所以values()方法非常适合只需要获取对象某些字段的值而不需要模型对象实例的时候使用。
二、Instance
创建一个对象:Obj = Model(attr1=val1, attr2=val2),Obj.save()
更新一个对象:Obj = Model.objects.get(id=xxx),Obj.attr1 = val1,Obj.save()
删除一个对象:Obj = Model.objects.get(id=xxx),Obj.delete()Django模型实例(Instance)表示的是数据库中一个模型对象的一行记录。它可以完成如下操作:
1. 创建对象实例可以通过Model类直接创建:
obj = Model(attr1=val1, attr2=val2)
obj.save()或者使用objects管理器的create()方法:
obj = Model.objects.create(attr1=val1, ...)2. 更新对象实例先获取实例,修改字段后保存:
obj = Model.objects.get(id=1)
obj.attr1 = new_value
obj.save()3. 删除对象实例获取实例后调用delete():
obj = Model.objects.get(id=1)
obj.delete()所以Django模型实例表示单个对象,主要用于对象的CRUD操作。它和QuerySet的区别在于是一个对象 VS 一组对象。
QuerySet 适用于需要查找多个对象或进行聚合操作的场景,而 Instance 适用于单独对象的创建、修改和删除操作。
三、APIView(在 view.py 中)
APIview 是 Django REST Framework 提供的一个视图类。它和 Django 中的 view 类有些相似,但是又有一些不同之处。APIview 可以处理基于 HTTP 协议的请求,并返回基于内容协商的响应,它旨在提供一个易于使用且灵活的方式来构建 API 视图。
- APIView继承自Django的View类,提供了许多处理HTTP请求的方法,比如get、post等。
- APIView实现了内容协商,可以根据请求头中的Accept信息自动返回JSON或其他格式。
- APIView具有请求解析器,可以解析请求的数据,并将请求数据绑定到请求对象上。- APIView可以轻松地构建基于类的视图逻辑,通过继承和组合来重用通用逻辑。
- APIView支持基于函数的视图行为,可以使用@action装饰器来实现。
- APIView比Django的View类更偏向于构建Web API。它提供了对请求和响应的更多控制能力。
- APIView需要与序列化器Serializer配合使用,来序列化复杂数据。
总结起来,APIView是一个专门用来构建Web API的类,它建立在Django的通用View组件之上,提供了对requests和responses的控制,内容协商等功能,以及对Serializer的集成,可以更便捷地构建灵活的API。
这里是一个使用APIView的代码示例:(可与项目给出的示例做对比补充)
from rest_framework.views import APIView
from rest_framework.response import Responseclass HelloView(APIView):def get(self, request):content = {'message': 'Hello, World!'}return Response(content)def post(self, request):name = request.data.get('name')content = {'message': 'Hello, {}!'.format(name)}return Response(content)这个示例中定义了一个简单的HelloView,继承自APIView。
- get() 方法处理GET请求,返回一个字典作为响应数据。
- post() 方法处理POST请求,从请求数据中获取name参数,返回个性化的问候信息。
- APIView会自动根据请求方法调用对应的get或post方法。
- 返回Response对象,APIView会处理内容协商,转换数据格式。这样,就可以快速构建一个支持GET/POST的API端点了。我们还可以利用APIView提供的其他功能,比如解析器、身份验证等来构建更强大的API。APIView作为Django REST framework的基础,提供了简洁而不失灵活性的API视图构建方式。
# 面向对象编程
from django.shortcuts import render
from rest_framework.decorators import api_view
from .models import *
from rest_framework.response import Response
from rest_framework.views import APIView
#### APIViewclass GetGoods(APIView):def get(self, request):data = Goods.objects.all()serializer = GoodsSerializer(instance=data, many=True)print(serializer.data)return Response(serializer.data)def post(self, request):# 从请求数据中提取字段request_data = {"category": request.data.get("Goodscategory"),"number": request.data.get("number"),"name": request.data.get("name"),"barcode": request.data.get("barcode"),"spec": request.data.get("spec"),"shelf_life_days": request.data.get("shelf_life_days"),"purchase_price": request.data.get("purchase_price"),"retail_price": request.data.get("retail_price"),"remark": request.data.get("remark"),}# 使用 create() 方法创建新的商品对象new_goods = Goods.objects.create(**request_data)# 对创建的对象进行序列化,并作为响应返回serializer = GoodsSerializer(instance=new_goods)return Response(serializer.data)# 面向对象编程class FilterGoodsCategoryAPI(APIView):# request 表示当前的请求对象# self 表示当前实例对象def get(self, request, format=None):print(request.method)return Response('ok')def post(self, request, format=None):print(request.method)return Response('ok')def put(self, request, format=None):print(request.method)return Response('ok')实现了一个简单的商品信息获取接口。主要逻辑是:
1. 从Goods模型中获取所有商品对象数据
2. 用GoodsSerializer序列化器对商品数据进行序列化
3. 将序列化后的数据通过Response返回这样就实现了一个获取所有商品信息的API端点。
需要注意的是:
- APIView会自动根据请求方法调用对应的方法处理器,如这里的get()来处理GET请求。
- 数据需要序列化后才能作为JSON响应返回,这里使用rest_framework的Serializer完成。
- Response包含了内容协商、状态码等响应处理功能。
使用APIView的优点是:
- 继承APIView就直接拥有了请求调度、响应处理等功能- 可以通过面向对象的方式组织视图逻辑,扩展灵活- 结合Serializer可以快速实现序列化与响应总之,这是一个典型的使用APIView构建API的示例,利用其提供的封装与便利性来简化视图开发。
def post(self, request):# 从请求数据中提取字段request_data = {"category": request.data.get("Goodscategory"),"number": request.data.get("number"),"name": request.data.get("name"),"barcode": request.data.get("barcode"),"spec": request.data.get("spec"),"shelf_life_days": request.data.get("shelf_life_days"),"purchase_price": request.data.get("purchase_price"),"retail_price": request.data.get("retail_price"),"remark": request.data.get("remark"),}这个post方法实现了从请求数据中提取需要的参数来创建商品的功能。主要逻辑:
1. 从request.data中获取前端传来的各个字段的数据
2. 将获取到的数据保存到一个字典request_data中
3. request_data中的key就是模型的字段名,value是从请求中获取到的值
4. 这样就可以直接用这个request_data字典来创建商品实例:
goods = Goods.objects.create(**request_data)这种字典参数的解包语法可以直接把字典的值赋给模型的对应字段。
5. 最后可能需要返回创建好的商品数据给前端:
serializer = GoodsSerializer(goods)
return Response(serializer.data)这样,我们就可以通过接受用户输入的数据来创建新的商品,并返回结果。这种从请求中提取参数,然后直接解包传递的方式可以简化创建对象的代码。配合DRF的Serializer来序列化和响应数据,可以快速构建出创建对象的API。
# 面向对象编程class FilterGoodsCategoryAPI(APIView):# request 表示当前的请求对象# self 表示当前实例对象def get(self, request, format=None):print(request.method)return Response('ok')def post(self, request, format=None):print(request.method)return Response('ok')def put(self, request, format=None):print(request.method)return Response('ok')实现了一个商品分类过滤的API视图,演示了APIView中如何根据不同的HTTP方法来处理不同的业务逻辑。
主要逻辑:
- 定义了FilterGoodsCategoryAPI类,继承APIView
- 分别实现了get(), post(), put()方法来处理不同的HTTP请求方法
- 在每个方法内部,打印了request.method,用于验证接收到的请求方法
- 然后直接返回字符串'ok'作为响应这样,当一个GET请求发送到这个视图的时候,会调用get()方法,并在终端打印输出“GET”。对于POST或PUT请求,也会分别调用对应的方法,并打印“POST”或“PUT”。APIView会自动根据请求方法将不同的请求分发到对应方法进行处理。我们可以在每个方法内实现真正的业务逻辑,比如获取分类、添加商品等。这种面向对象的类视图可以帮助我们更好地组织代码,利用APIView的请求分发来处理不同的请求与业务逻辑。
所以这是一个使用APIView的典型示例,演示了其根据请求方法调度到对应方法的功能。
未完待续
相关文章:
Datawhale Django后端开发入门 TASK03 QuerySet和Instance、APIVIew
一、QuerySet QuerySet 是 Django 中的一个查询集合,它是由 Model.objects 方法返回的,并且可以用于生成数据库中所有满足一定条件的对象的列表。 QuerySet 在 Django 中表示从数据库中获取的对象集合,它是一个可迭代的、类似列表的对象集合。主要特点…...

Python 网页解析中级篇:深入理解BeautifulSoup库
在Python的网络爬虫中,BeautifulSoup库是一个重要的网页解析工具。在初级教程中,我们已经了解了BeautifulSoup库的基本使用方法。在本篇文章中,我们将深入学习BeautifulSoup库的进阶使用。 一、复杂的查找条件 在使用find和find_all方法查找…...
IDEA 如何制作代码补丁?IDEA 生成 patch 和使用 patch
什么是升级补丁? 比如你本地修复的 bug,需要把增量文件发给客户,很多场景下大家都需要手工整理修改的文件,并整理好目录,这个很麻烦。那有没有简单的技巧呢?看看 IDEA 生成 patch 和使用 patch 的使用。 介…...
Redis专题-秒杀
Redis专题-并发/秒杀 开局一张图,内容全靠“编”。 昨天晚上在群友里看到有人在讨论库存并发的问题,看到这里我就决定写一篇关于redis秒杀的文章。 1、理论部分 我们看看一般我们库存是怎么出问题的 其实redis提供了两种解决方案:加锁和原子操…...
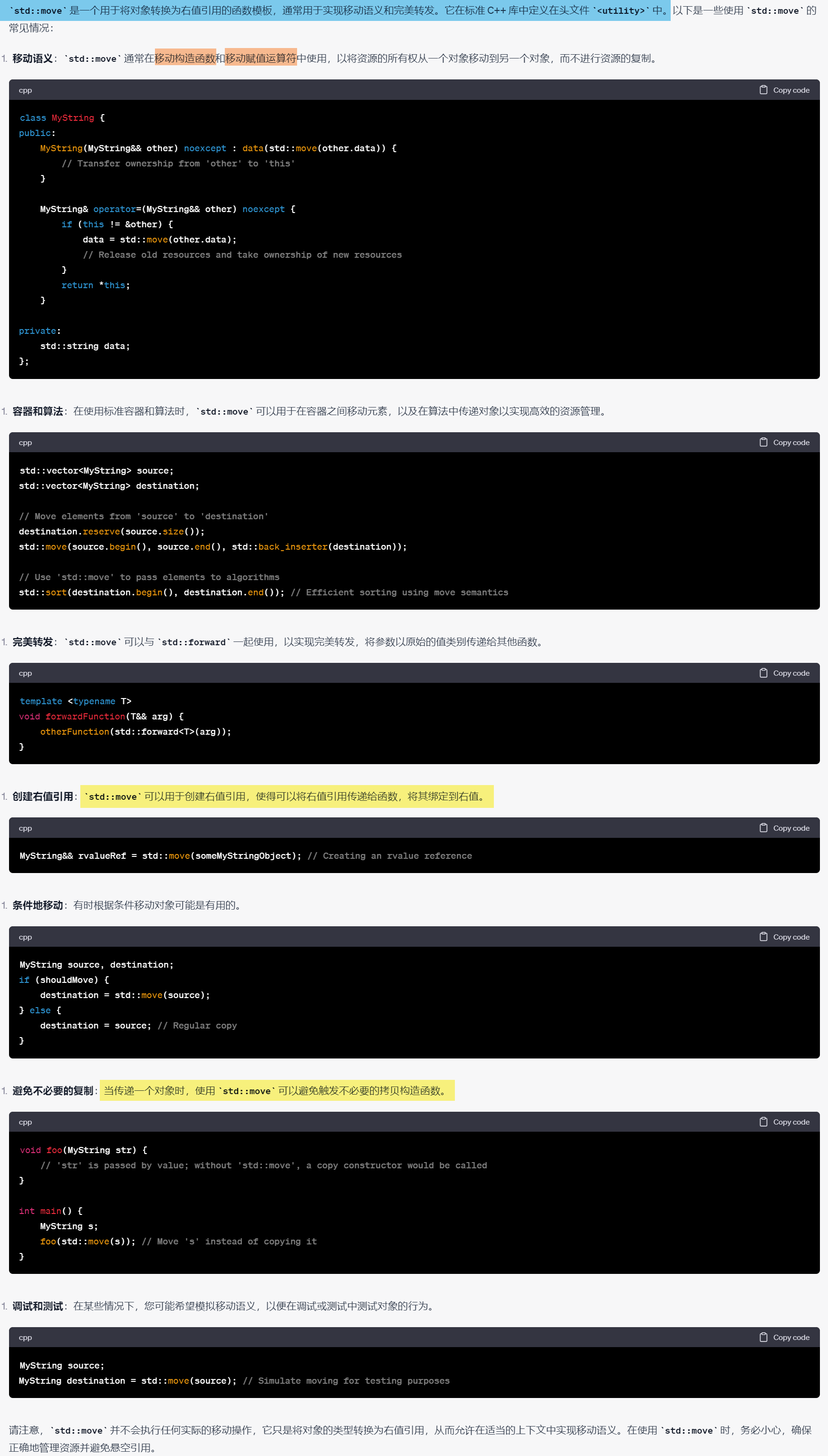
C++笔记之std::move和右值引用的关系、以及移动语义
C笔记之std::move和右值引用的关系、以及移动语义 code review! 文章目录 C笔记之std::move和右值引用的关系、以及移动语义1.一个使用std::move的最简单C例子2.std::move 和 T&& reference_name expression;对比3.右值引用和常规引用的经典对比——移动语义和拷贝语…...

ES6自用笔记
目录 原型链 引用类型:__proto__(隐式原型)属性,属性值是对象函数:prototype(原型)属性,属性值是对象 相关方法 person.prototype.isPrototypeOf(stu) Object.getPrototypeOf(Object)替换已不推荐的Object._ _ proto _ _ Ob…...

【BASH】回顾与知识点梳理(二十九)
【BASH】回顾与知识点梳理 二十九 二十九. 进程和工作管理29.1 什么是进程 (process)进程与程序 (process & program)子进程与父进程:fork and exec:进程呼叫的流程系统或网络服务:常驻在内存的进程 29.2 Linux 的多人多任务环境多人环境…...

Docker的Cgroup资源限制
Docker通过Cgroup来控制容器使用的资源配额,包括 CPU、内存、磁盘三大方面,基本覆盖了常见的资源配颡和使用量控制。 Cgoup 是CotrolGroups 的缩写,是Linux 内核提供的一种可以限制、记录、隔高进程组所使用的物理资源(如CPU、内存…...

AI智能语音机器人的基本业务流程
先画个图,了解下AI语音机器人的基本业务流程。 上图是一个AI语音机器人的业务流程,简单来说就是首先要配置话术,就是告诉机器人在遇到问题该怎么回答,这个不同公司不同行业的差别比较大,所以一般每个客户都会配置其个性…...
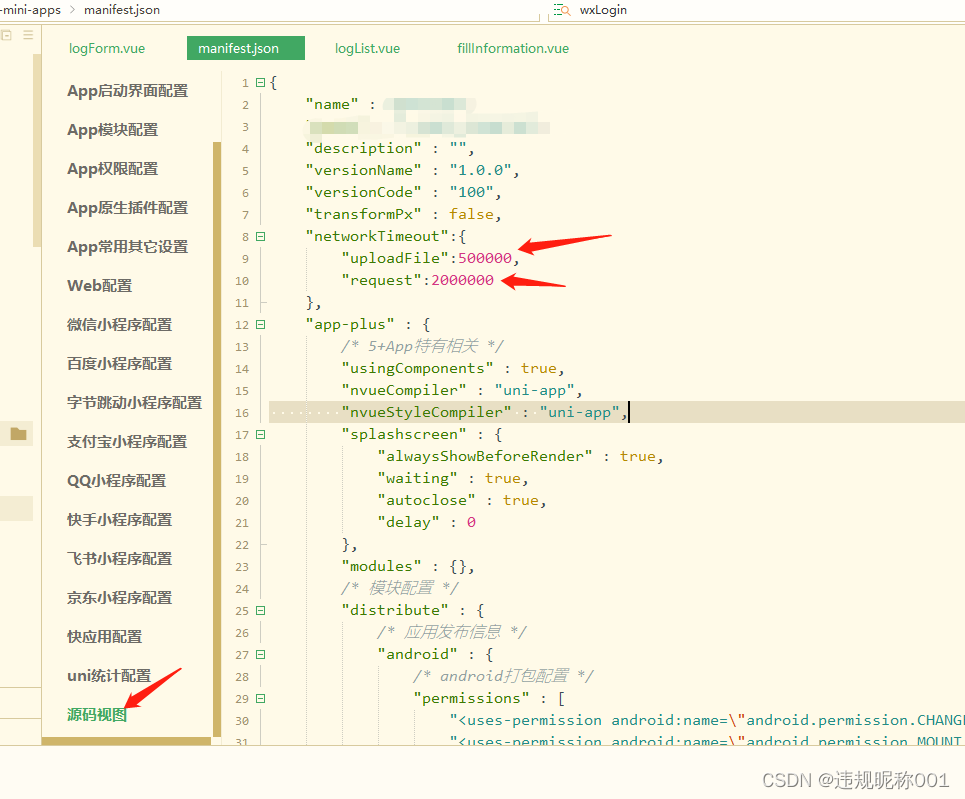
uniapp 上传比较大的视频文件就超时
uni.uploadFile,上传超过10兆左右的文件就报错err:uploadFile:fail timeout,超时 解决: 在manifest.json文件中做超时配置 uni.uploadFile({url: this.action,method: "POST",header: {Authorization: uni.getStorage…...
CSS简介
目录 CSS CSS概念 核心概念 为什么需要CSS 语法 CSS的引入方式 内联样式(行内样式) 内部样式 外部样式(推荐) CSS CSS概念 CSS(Cascading Style Sheets)层叠样式表,又叫级联样式表&am…...
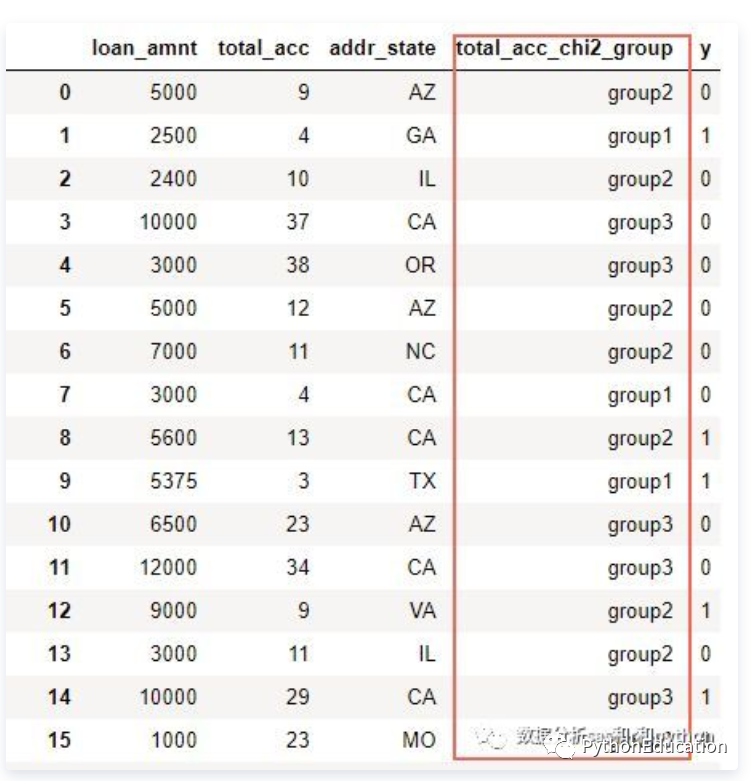
卡方分箱(chi-square)
统计学,风控建模经常遇到卡方分箱算法ChiMerge。卡方分箱在金融信贷风控领域是逻辑回归评分卡的核心,让分箱具有统计学意义(单调性)。卡方分箱在生物医药领域可以比较两种药物或两组病人是否具有显著区别。但很多建模人员搞不清楚…...

深入理解 Flutter 图片加载原理
作者:京东零售 徐宏伟 来源:京东云开发者社区 前言 随着Flutter稳定版本逐步迭代更新,京东APP内部的Flutter业务也日益增多,Flutter开发为我们提供了高效的开发环境、优秀的跨平台适配、丰富的功能组件及动画、接近原生的交互体验…...
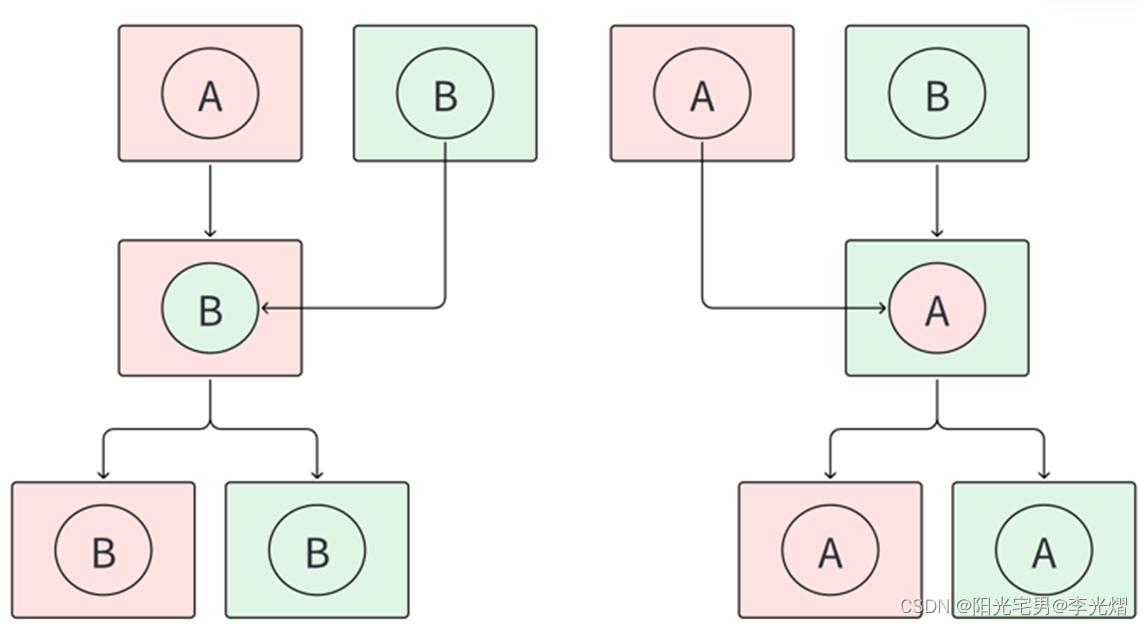
【电子通识】什么是异常分析中的A-B-A方法
工作有了一定的经验之后,在做问题分析的时候,经常会听到别人说把这个部品(芯片/模块)拿去ABA一下,看看跟谁走。那么对于新人来说是否就会问一个问题:什么是ABA呢? A-B-A 交换是一种简单直接的交…...

[Linux] C获取键盘输入值
检测指令:cat /dev/input/event1 | hexdump 当键盘有输入时,会有对应的一堆16进制输出。它其实对应着input_event结构体【24字节】。 struct input_event {struct timeval time;__u16 type;__u16 code;__s32 value; }; #include <st…...

探索Python编程世界:开启你的代码之旅
亲爱的小伙伴们,大家好!很高兴向大家推荐我的新专栏《Python编程指南:从入门到高级》。在这个专栏里,我将带领大家深入探索Python编程的奇妙世界,为您提供有趣、实用、易懂的内容,帮助您在编程的道路上越走…...

金融术语总结
洗钱 将犯罪或其他非法违法行为所获得的违法收入,通过各种手段掩饰、隐瞒、转化,使其在形式上合法化的行为。 存量客户 某个时间段里原先已有的客户,与新增客户相对应。 月活跃用户数量,MAU(Monthly Active User,M…...

Linux驱动开发(Day5)
思维导图: 不同设备号文件绑定:...
[机器学习]特征工程:主成分分析
目录 主成分分析 1、简介 2、帮助理解 3、API调用 4、案例 本文介绍主成分分析的概述以及python如何实现算法,关于主成分分析算法数学原理讲解的文章,请看这一篇: 探究主成分分析方法数学原理_逐梦苍穹的博客-CSDN博客https://blog.csdn.…...
Python爬虫实战案例——第一例
X卢小说登录(包括验证码处理) 地址:aHR0cHM6Ly91LmZhbG9vLmNvbS9yZWdpc3QvbG9naW4uYXNweA 打开页面直接进行分析 任意输入用户名密码及验证码之后可以看到抓到的包中传输的数据明显需要的是txtPwd进行加密分析。按ctrlshiftf进行搜索。 定位来到源代码中断点进行调…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...

Qemu arm操作系统开发环境
使用qemu虚拟arm硬件比较合适。 步骤如下: 安装qemu apt install qemu-system安装aarch64-none-elf-gcc 需要手动下载,下载地址:https://developer.arm.com/-/media/Files/downloads/gnu/13.2.rel1/binrel/arm-gnu-toolchain-13.2.rel1-x…...

BLEU评分:机器翻译质量评估的黄金标准
BLEU评分:机器翻译质量评估的黄金标准 1. 引言 在自然语言处理(NLP)领域,衡量一个机器翻译模型的性能至关重要。BLEU (Bilingual Evaluation Understudy) 作为一种自动化评估指标,自2002年由IBM的Kishore Papineni等人提出以来,…...