LRU缓存算法
双向链表+哈希表(非线程安全)
https://leetcode.cn/problems/lru-cache/solutions/259678/lruhuan-cun-ji-zhi-by-leetcode-solution/
/*** LRU算法: 哈希表+双向链表实现* 1. 双向链表按照被使用的顺序来存储, 靠近头部的节点是最近使用的, 靠近尾部的节点是最久未使用的* 2. 哈希表存储key和node映射关系, 通过key能快速定位到链表中的节点* @author zhangjunfeng* @date 2023/2/2 16:15*/
public class LRUCache {class DLinkedNode {int key;int value;DLinkedNode prev;DLinkedNode next;public DLinkedNode() {}public DLinkedNode(int _key, int _value) {key = _key;value = _value;}}private Map<Integer, DLinkedNode> cache = new HashMap<>();private int size;private int capacity;private DLinkedNode head, tail;public LRUCache(int _capacity) {this.size = 0;this.capacity = _capacity;head = new DLinkedNode();tail = new DLinkedNode();head.next = tail;tail.prev = head;}/*** 1. 先判断key是否存在, 不存在返回-1* 2. 若key存在, 则key对应的节点就是最近访问节点, 通过哈希表映射到在双向链表中的位置, 然后将节点移动到链表头部* @param key* @return*/public int get(int key) {DLinkedNode node = cache.get(key);if (node == null) {return -1;}// key存在则移动到链表头部, 表示最近访问moveToHead(node);return node.value;}/*** 1. 如果key不存在, 创建一个新节点并在链表头部添加该节点, 判断链表长度是否超出容量限制, 若超出容量, 则删除链表尾部结点* 2. 如果key存在, 覆盖旧值, 将节点移动到头部* @param key* @param value*/public void put(int key, int value) {DLinkedNode node = cache.get(key);if (node == null) {// node不存在, 则创建一个新节点DLinkedNode newNode = new DLinkedNode(key, value);// 添加进哈希表cache.put(key, newNode);// 添加到链表头部, 表示最近访问addToHead(newNode);// 链表长度加1++size;// 如果超出缓存容量if (size > capacity) {// 删除链表最后一个结点, 去掉最长时间未访问的DLinkedNode tail = removeTail();// 去掉哈希表中对应节点cache.remove(tail.key);// 减小链表长度--size;}} else {// 如果缓存中有// 先覆盖旧值node.value = value;// 再将节点移到链表头部, 表示最近访问moveToHead(node);}}/*** 添加一个结点需要修改四条链* @param node*/private void addToHead(DLinkedNode node) {node.prev = head;node.next = head.next;head.next.prev = node;head.next = node;}/*** 删除一个结点需要修改两条链* @param node*/private void removeNode(DLinkedNode node) {node.prev.next = node.next;node.next.prev = node.prev;}/*** 把结点移到头部*/private void moveToHead(DLinkedNode node) {// 先删除节点removeNode(node);// 再将该节点移到头部addToHead(node);}/*** 删除尾结点并返回*/private DLinkedNode removeTail() {DLinkedNode last = tail.prev;removeNode(last);return last;}public void print() {DLinkedNode cur = head.next;while (cur != null && cur.next != null) {System.out.println("key: " + cur.key + "; value: " + cur.value);cur = cur.next;}System.out.println("-----------------");}
}线程安全版本
实现方法
ConcurrentHashMap + ConcurrentLinkedQueue +ReadWriteLock
ConcurrentLinkedQueue简单介绍
ConcurrentLinkedQueue是一个基于单向链表的无界无锁线程安全的队列,适合在高并发环境下使用,效率比较高。 我们在使用的时候,可以就把它理解为我们经常接触的数据结构——队列,不过是增加了多线程下的安全性保证罢了。和普通队列一样,它也是按照先进先出(FIFO)的规则对接点进行排序。 另外,队列元素中不可以放置null元素。
ConcurrentLinkedQueue中最主要的两个方法是:offer(value)和poll(),分别实现队列的两个重要的操作:入队和出队(offer(value)等价于 add(value))。
我们添加一个元素到队列的时候,它会添加到队列的尾部,当我们获取一个元素时,它会返回队列头部的元素。
利用ConcurrentLinkedQueue队列先进先出的特性,每当我们 put/get(缓存被使用)元素的时候,我们就将这个元素存放在队列尾部,这样就能保证队列头部的元素是最近最少使用的。
ReadWriteLock简单介绍
ReadWriteLock 是一个接口,位于java.util.concurrent.locks包下,里面只有两个方法分别返回读锁和写锁:
public interface ReadWriteLock {/*** 返回读锁*/Lock readLock();/*** 返回写锁*/Lock writeLock();
}
ReentrantReadWriteLock 是ReadWriteLock接口的具体实现类。
读写锁还是比较适合缓存这种读多写少的场景。读写锁可以保证多个线程和同时读取,但是只有一个线程可以写入。但是,有一个问题是当读锁被线程持有的时候,读锁是无法被其它线程申请的,会处于阻塞状态,直至读锁被释放。
另外,同一个线程持有写锁时是可以申请读锁,但是持有读锁的情况下不可以申请写锁。
ScheduledExecutorService 简单介绍
ScheduledExecutorService 是一个接口,ScheduledThreadPoolExecutor 是其主要实现类。
ScheduledThreadPoolExecutor 主要用来在给定的延迟后运行任务,或者定期执行任务。 这个在实际项目用到的比较少,因为有其他方案选择比如quartz。但是,在一些需求比较简单的场景下还是非常有用的!
ScheduledThreadPoolExecutor 使用的任务队列 DelayQueue 封装了一个 PriorityQueue,PriorityQueue 会对队列中的任务进行排序,执行所需时间短的放在前面先被执行,如果执行所需时间相同则先提交的任务将被先执行。
原理
LRU缓存指的是当缓存大小已达到最大分配容量的时候,如果再要去缓存新的对象数据的话,就需要将缓存中最近访问最少的对象删除掉以便给新来的数据腾出空间。
ConcurrentHashMap 是线程安全的Map,我们可以利用它缓存 key,value形式的数。ConcurrentLinkedQueue是一个线程安全的基于链表的队列(先进先出),我们可以用它来维护 key 。每当我们put/get(缓存被使用)元素的时候,我们就将这个元素对应的 key 存放在队列尾部,这样就能保证队列头部的元素是最近最少使用的。当我们的缓存容量不够的时候,我们直接移除队列头部对应的key以及这个key对应的缓存即可!
另外,我们用到了ReadWriteLock(读写锁)来保证线程安全。
代码实现
/*** @author shuang.kou* <p>* 使用 ConcurrentHashMap+ConcurrentLinkedQueue+ReadWriteLock实现线程安全的 LRU 缓存* 这里只是为了学习使用,本地缓存推荐使用 Guava 自带的。*/
public class MyLruCache<K, V> {/*** 缓存的最大容量*/private final int maxCapacity;private ConcurrentHashMap<K, V> cacheMap;private ConcurrentLinkedQueue<K> keys;/*** 读写锁*/private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();private Lock writeLock = readWriteLock.writeLock();private Lock readLock = readWriteLock.readLock();public MyLruCache(int maxCapacity) {if (maxCapacity < 0) {throw new IllegalArgumentException("Illegal max capacity: " + maxCapacity);}this.maxCapacity = maxCapacity;cacheMap = new ConcurrentHashMap<>(maxCapacity);keys = new ConcurrentLinkedQueue<>();}public V put(K key, V value) {// 加写锁writeLock.lock();try {//1.key是否存在于当前缓存if (cacheMap.containsKey(key)) {moveToTailOfQueue(key);cacheMap.put(key, value);return value;}//2.是否超出缓存容量,超出的话就移除队列头部的元素以及其对应的缓存if (cacheMap.size() == maxCapacity) {System.out.println("maxCapacity of cache reached");removeOldestKey();}//3.key不存在于当前缓存。将key添加到队列的尾部并且缓存key及其对应的元素keys.add(key);cacheMap.put(key, value);return value;} finally {writeLock.unlock();}}public V get(K key) {//加读锁readLock.lock();try {//key是否存在于当前缓存if (cacheMap.containsKey(key)) {// 存在的话就将key移动到队列的尾部moveToTailOfQueue(key);return cacheMap.get(key);}//不存在于当前缓存中就返回Nullreturn null;} finally {readLock.unlock();}}public V remove(K key) {writeLock.lock();try {//key是否存在于当前缓存if (cacheMap.containsKey(key)) {// 存在移除队列和Map中对应的Keykeys.remove(key);return cacheMap.remove(key);}//不存在于当前缓存中就返回Nullreturn null;} finally {writeLock.unlock();}}/*** 将元素添加到队列的尾部(put/get的时候执行)*/private void moveToTailOfQueue(K key) {keys.remove(key);keys.add(key);}/*** 移除队列头部的元素以及其对应的缓存 (缓存容量已满的时候执行)*/private void removeOldestKey() {K oldestKey = keys.poll();if (oldestKey != null) {cacheMap.remove(oldestKey);}}public int size() {return cacheMap.size();}}
并发测试
int threadNum = 10;
int batchSize = 10;
//init cache
MyLruCache<String, Integer> myLruCache = new MyLruCache<>(batchSize * 10);
//init thread pool with 10 threads
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(threadNum);
//init CountDownLatch with 10 count
CountDownLatch latch = new CountDownLatch(threadNum);
AtomicInteger atomicInteger = new AtomicInteger(0);
long startTime = System.currentTimeMillis();
for (int t = 0; t < threadNum; t++) {fixedThreadPool.submit(() -> {for (int i = 0; i < batchSize; i++) {int value = atomicInteger.incrementAndGet();myLruCache.put("id" + value, value);}latch.countDown();});
}
//wait for 10 threads to complete the task
latch.await();
fixedThreadPool.shutdown();
System.out.println("Cache size:" + myLruCache.size());//Cache size:100
long endTime = System.currentTimeMillis();
long duration = endTime - startTime;
System.out.println(String.format("Time cost:%dms", duration));//Time cost:511ms
线程安全并且带有过期时间
实际上就是在我们上面时间的LRU缓存的基础上加上一个定时任务去删除缓存,单纯利用 JDK 提供的类,我们实现定时任务的方式有很多种:
Timer:不被推荐,多线程会存在问题。ScheduledExecutorService:定时器线程池,可以用来替代TimerDelayQueue:延时队列quartz:一个很火的开源任务调度框架,很多其他框架都是基于quartz开发的,比如当当网的elastic-job就是基于quartz二次开发之后的分布式调度解决方案- …
最终我们选择了 ScheduledExecutorService,主要原因是它易用(基于DelayQueue做了很多封装)并且基本能满足我们的大部分需求。
我们在我们上面实现的线程安全的 LRU 缓存基础上,简单稍作修改即可!我们增加了一个方法:
private void removeAfterExpireTime(K key, long expireTime) {scheduledExecutorService.schedule(() -> {//过期后清除该键值对cacheMap.remove(key);keys.remove(key);}, expireTime, TimeUnit.MILLISECONDS);
}
我们put元素的时候,如果通过这个方法就能直接设置过期时间。
完整源码
/*** @author shuang.kou* <p>* 使用 ConcurrentHashMap+ConcurrentLinkedQueue+ReadWriteLock+ScheduledExecutorService实现线程安全的 LRU 缓存* 这里只是为了学习使用,本地缓存推荐使用 Guava 自带的,使用 Spring 的话,推荐使用Spring Cache*/
public class MyLruCacheWithExpireTime<K, V> {/*** 缓存的最大容量*/private final int maxCapacity;private ConcurrentHashMap<K, V> cacheMap;private ConcurrentLinkedQueue<K> keys;/*** 读写锁*/private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();private Lock writeLock = readWriteLock.writeLock();private Lock readLock = readWriteLock.readLock();private ScheduledExecutorService scheduledExecutorService;public MyLruCacheWithExpireTime(int maxCapacity) {if (maxCapacity < 0) {throw new IllegalArgumentException("Illegal max capacity: " + maxCapacity);}this.maxCapacity = maxCapacity;cacheMap = new ConcurrentHashMap<>(maxCapacity);keys = new ConcurrentLinkedQueue<>();scheduledExecutorService = Executors.newScheduledThreadPool(3);}public V put(K key, V value, long expireTime) {// 加写锁writeLock.lock();try {//1.key是否存在于当前缓存if (cacheMap.containsKey(key)) {moveToTailOfQueue(key);cacheMap.put(key, value);return value;}//2.是否超出缓存容量,超出的话就移除队列头部的元素以及其对应的缓存if (cacheMap.size() == maxCapacity) {System.out.println("maxCapacity of cache reached");removeOldestKey();}//3.key不存在于当前缓存。将key添加到队列的尾部并且缓存key及其对应的元素keys.add(key);cacheMap.put(key, value);if (expireTime > 0) {removeAfterExpireTime(key, expireTime);}return value;} finally {writeLock.unlock();}}public V get(K key) {//加读锁readLock.lock();try {//key是否存在于当前缓存if (cacheMap.containsKey(key)) {// 存在的话就将key移动到队列的尾部moveToTailOfQueue(key);return cacheMap.get(key);}//不存在于当前缓存中就返回Nullreturn null;} finally {readLock.unlock();}}public V remove(K key) {writeLock.lock();try {//key是否存在于当前缓存if (cacheMap.containsKey(key)) {// 存在移除队列和Map中对应的Keykeys.remove(key);return cacheMap.remove(key);}//不存在于当前缓存中就返回Nullreturn null;} finally {writeLock.unlock();}}/*** 将元素添加到队列的尾部(put/get的时候执行)*/private void moveToTailOfQueue(K key) {keys.remove(key);keys.add(key);}/*** 移除队列头部的元素以及其对应的缓存 (缓存容量已满的时候执行)*/private void removeOldestKey() {K oldestKey = keys.poll();if (oldestKey != null) {cacheMap.remove(oldestKey);}}private void removeAfterExpireTime(K key, long expireTime) {scheduledExecutorService.schedule(() -> {//过期后清除该键值对cacheMap.remove(key);keys.remove(key);}, expireTime, TimeUnit.MILLISECONDS);}public int size() {return cacheMap.size();}}
测试效果:
MyLruCacheWithExpireTime<Integer,String> myLruCache = new MyLruCacheWithExpireTime<>(3);
myLruCache.put(1,"Java",3;
myLruCache.put(2,"C++",3;
myLruCache.put(3,"Python",1500);
System.out.println(myLruCache.size());//3
Thread.sleep(2;
System.out.println(myLruCache.size());//2
资料来自
- https://zhuanlan.zhihu.com/p/135936339
相关文章:

LRU缓存算法
双向链表哈希表(非线程安全) https://leetcode.cn/problems/lru-cache/solutions/259678/lruhuan-cun-ji-zhi-by-leetcode-solution/ /*** LRU算法: 哈希表双向链表实现* 1. 双向链表按照被使用的顺序来存储, 靠近头部的节点是最近使用的, 靠近尾部的节…...

@Configuration注解
Configuration注解介绍 Configuration注解,用于标注一个类是一个spring的配置类(同时,也是一个bean),配置类中可以使用ComponentScan、Import、ImportResource 和 Bean等注解的方式定义beanDefinition。 Target(Elem…...

基于springboot+vue的食疗系统
基于springbootvue的食疗系统 ✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景介绍&…...
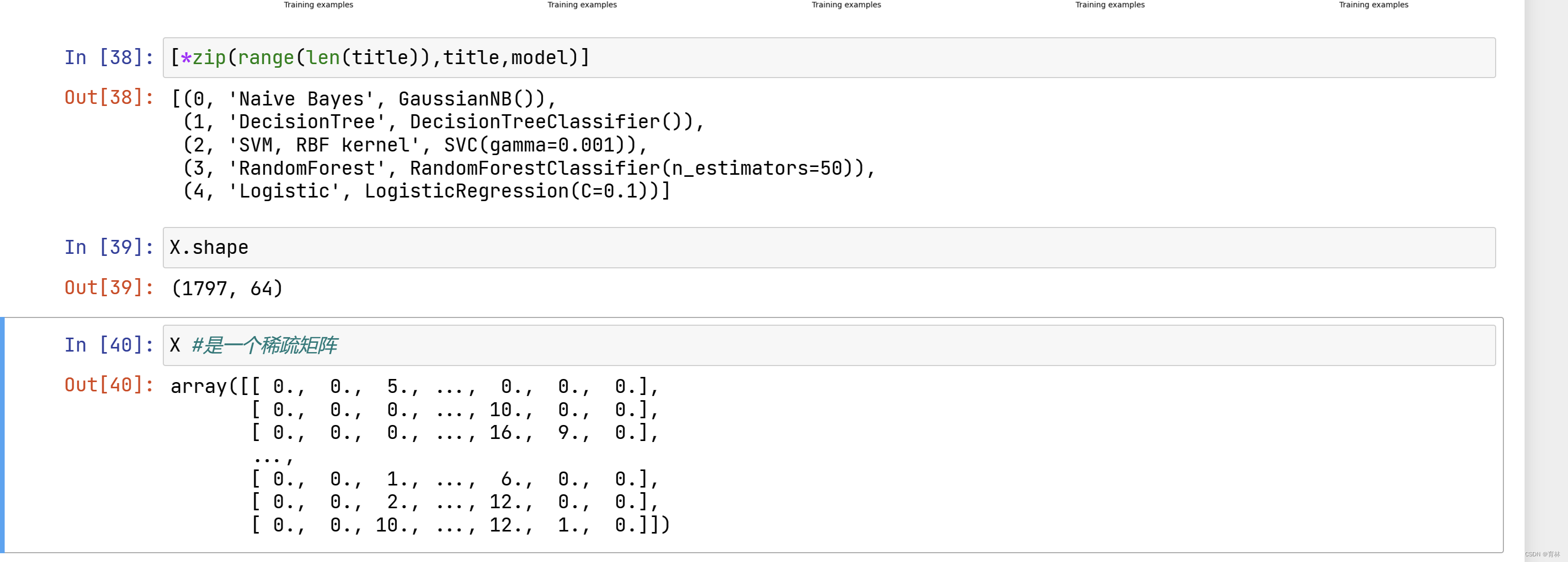
sklearn学习-朴素贝叶斯
文章目录一、概述1、真正的概率分类器2、sklearn中的朴素贝叶斯二、不同分布下的贝叶斯1、高斯朴素贝叶斯GaussianNB2、探索贝叶斯:高斯朴素贝叶斯擅长的数据集3、探索贝叶斯:高斯朴素贝叶斯的拟合效果与运算速度总结一、概述 1、真正的概率分类器 算法…...

分享112个HTML艺术时尚模板,总有一款适合您
分享112个HTML艺术时尚模板,总有一款适合您 112个HTML艺术时尚模板下载链接:https://pan.baidu.com/s/1D3-mfPOud-f3vy9yLl-bmw?pwdfph2 提取码:fph2 Python采集代码下载链接:采集代码.zip - 蓝奏云 时尚平面模特网站模板 潮…...

用GDB远程调试运行于QEMU的程序
1. 前言 限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。 2. 测试环境 本文使用 Ubuntu 16.04.4 LTS QEMU 环境进行调试。 3. 用 GDB 调试 QEMU 内程序 3.1 编写用来调试的程序 我们用 ARM32 来进行调试…...
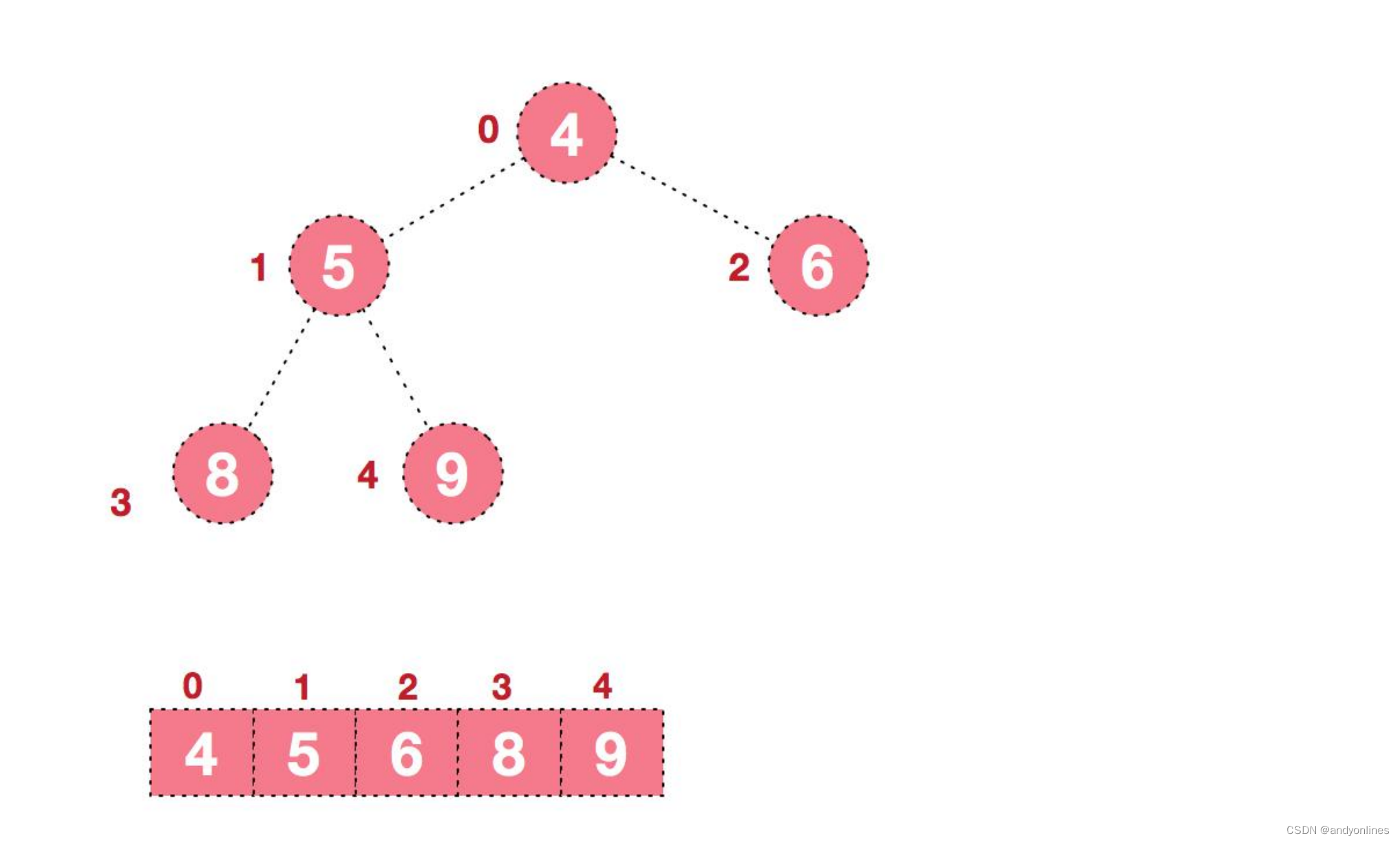
20 堆排序
文章目录1 堆排序的概念2 堆排序基本思想3 堆排序步骤图解说明4 堆排序的代码实现1 堆排序的概念 1) 堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为 O(nlogn)…...
2023最新文件快递柜系统网站源码 | 匿名口令分享 | 临时文件分享
内容目录一、详细介绍二、效果展示1.部分代码2.效果图展示三、学习资料下载一、详细介绍 2023最新文件快递柜系统网站源码 | 匿名口令分享 | 临时文件分享 很多时候,我们都想将一些文件或文本传送给别人,或者跨端传递一些信息,但是我们又不…...
)
分片策略(二)
分片策略 基本概念 分片键 用于分片的字段,是将数据库或表拆分的字段,比如,我可以使用user_id作为分片键将用户数据分到不同的表中,这里的user_id就是分片键,除了这种单字段分片,ShardingSphere还支持多…...
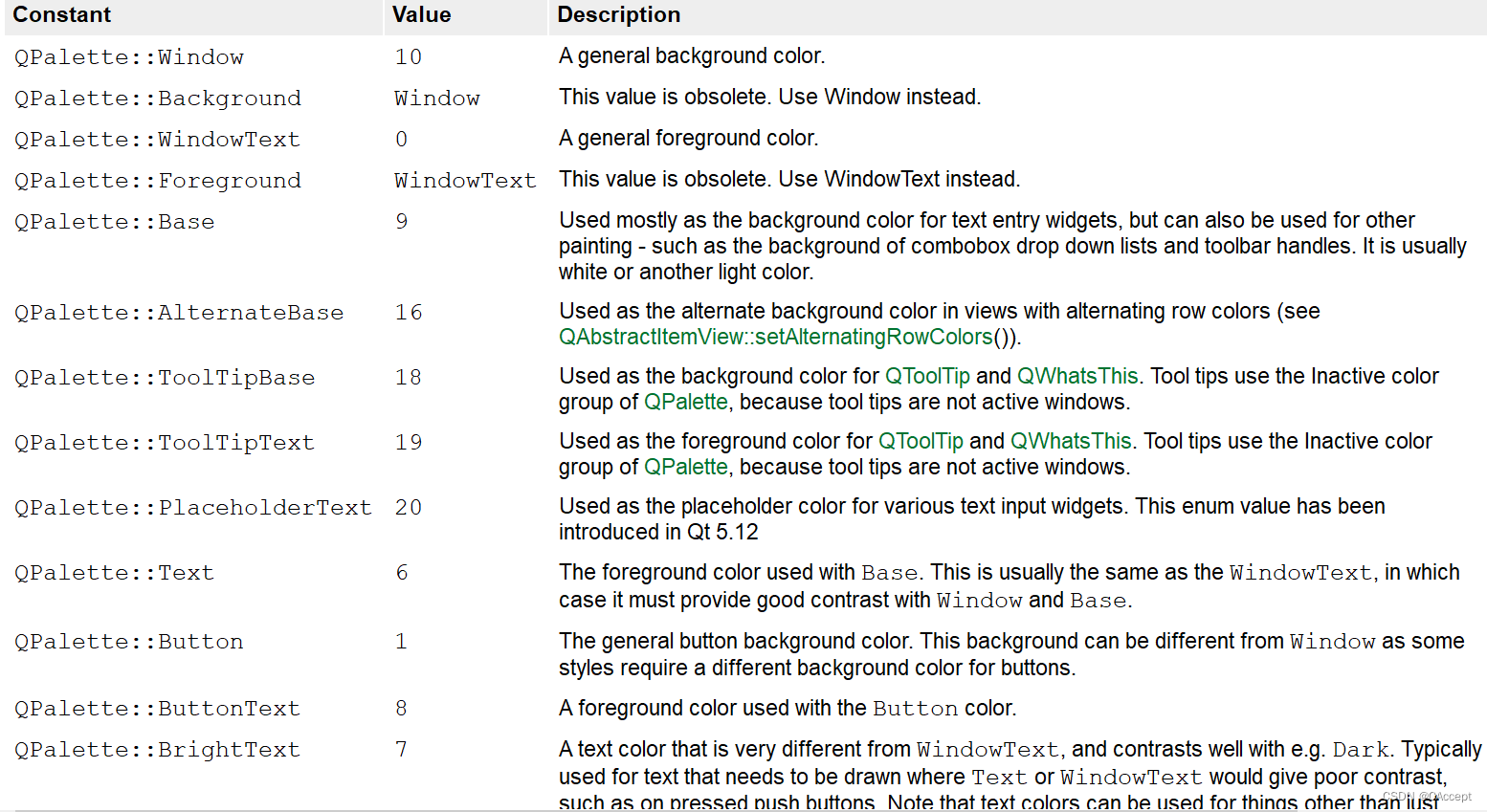
Qt之调色板类QPalette的使用
文章目录QPalette调色板类前言代码知识点讲解QPalette调色板类 前言 Qt提供的调色板类QPalette专门用于管理部件的外观显示,相当于部件或对话框的调色板,管理他们所有的颜色信息。每个部件都包含一个QPalette对象,在显示时,按照…...
Kotlin 32. Kotlin 多语言支持
Kotlin 多语言支持 对于 Kotlin 来说,当我们新建一个项目时,会默认在 values/ 文件夹下,生成一个 strings.xml 文件。比如说, <resources><string name"app_name">exampleNewProject</string> <…...
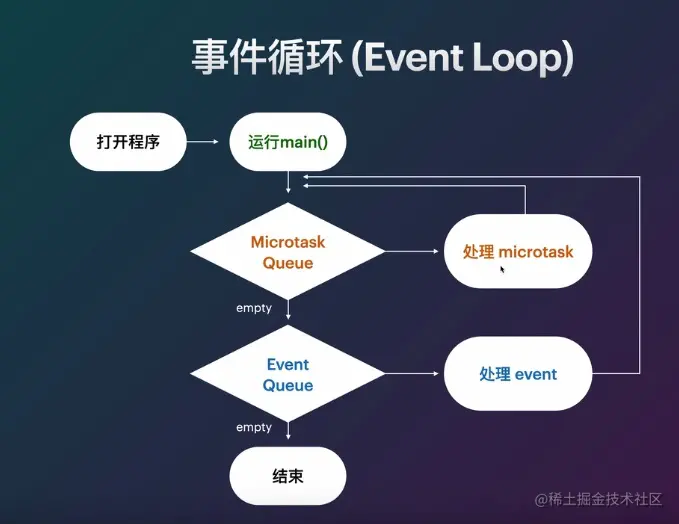
【Flutter入门到进阶】Dart进阶篇---DartVM单线程设计原理
1 虚拟机的指令执行设计 1.1 虚拟机的分类 基于栈的虚拟机,比如JVM虚拟机 基于寄存器的虚拟机,比如Dalvik虚拟机 1.2 虚拟机的概念 首先问一个基本的问题,作为一个虚拟机,它最基本的要实现哪些功能? 他应该能够模拟…...
的交集)
Dem和NvM(NVRAM Manager)的交集
NVRAM(NvM)提供了在NVRAM中存储数据Block的机制。 NVRAM Block(最大大小取决于配置)被分配给Dem,并由Dem实现事件状态信息和相关数据的永久存储(例如通电复位)。 ECU 状态管理器(Ec…...

AI神经网络CNN/RNN/DNN/SNN的区别对比
@版权声明: 本文由 ChatGpt 创作; BiliBili: https://www.bilibili.com/video/BV17D4y1P7pM/?share_source=copy_web&vd_source=6d217e0ff6387a749dc570aba51d36fd 引言 随着人工智能技术的发展,神经网络作为人工智能的核心技术之一,被广泛应用于图像识别、语音识别、…...

【JavaWeb】一文学会JPA
✅✅作者主页:🔗孙不坚1208的博客 🔥🔥精选专栏:🔗JavaWeb从入门到精通(持续更新中) 📋📋 本文摘要:本篇文章主要介绍JPA的概念、注解实现ORM规范…...
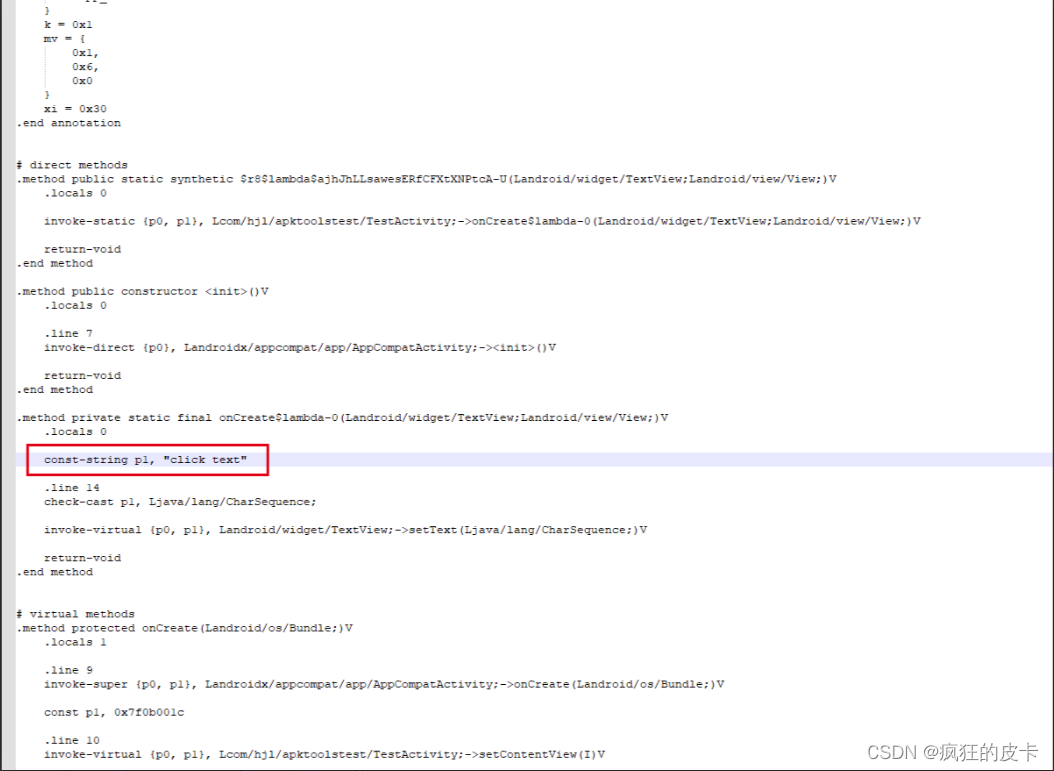
【安卓逆向】APK修改与反编译回编译
【安卓逆向】反编译修改APK回编译使用工具流程步骤Apktool相关安装与使用常用命令备查APK签名命令备查实战练习反编译查看修改的地方使用Apktool反编译得到产物文件夹并进行修改回编APK实用场景在日常开发我们可能需要替换某些资源或者修改某些代码,但是我们没有源码…...

【计组笔记04】计算机组成原理之多模块存储器、Cache高速缓存存储器、Cache地址映射
这篇文章,主要介绍计算机组成原理之多模块存储器、Cache高速缓存存储器、Cache地址映射。 目录 一、双口RAM和多模块存储器 1.1、存取周期 1.2、双口RAM 1.3、多模块存储器...

英语基础-状语的应用
1. 非谓语动词作状语 1. 试着翻译下列句子 当他是一个小孩子的时候,他很喜欢玩电脑游戏。 When he was a child, he liked playing computer games. 如果他通过考试,他妈妈就会给他买一台新电脑。 If he passes the examination, his mother will b…...
)
发表论文需要注意的两点(建议收藏)
在学习人工智能的过程中,论文有着重要的作用,无论是深入学术科研,还是毕业找工作,都离不开发表论文这一步骤,所以今天就和大家分享一些关于论文发表的经验,希望对大家有所帮助。 为什么要早点发表论文&…...

ISTQB-TM-大纲
1. 测试过程 1.1 简介 在 ISTQB 软件测试基础级认证大纲中已描述了基本的测试过程包括以下活动: 计划和控制分析和设计实施和执行评估出口准则和报告测试结束活动 基础级大纲认同这些活动虽然有逻辑顺序,但过程中的某些活动可能重叠,或并行…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...