基于Mysql+Vue+Django的协同过滤和内容推荐算法的智能音乐推荐系统——深度学习算法应用(含全部工程源码)+数据集
目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- Python 环境
- MySQL环境
- VUE环境
- 模块实现
- 1. 数据请求和储存
- 2. 数据处理
- 计算歌曲、歌手、用户相似度
- 计算用户推荐集
- 3. 数据存储与后台
- 4. 数据展示
- 系统测试
- 工程源代码下载
- 其它资料下载

前言
本项目以丰富的网易云音乐数据为基础,运用协同过滤和内容推荐算法作为核心方法,旨在为不同用户量身定制音乐推荐。
首先,我们充分利用网易云音乐的大量用户数据,包括用户的收听历史、喜好歌手、喜欢的歌曲等信息。通过协同过滤算法,我们可以分析不同用户之间的相似性,找到具有相近音乐口味的用户群体。
其次,我们引入内容推荐算法,从音乐的特征、流派、歌手风格等方面进行深入分析。这种算法能够更精准地为用户推荐符合其喜好和兴趣的音乐作品。
综合协同过滤和内容推荐的结果,我们为每位用户打造个性化的音乐推荐列表。这样,不同用户将能够在网易云音乐平台上获得与其音乐喜好相符的歌曲,从而提升他们的音乐体验。
本项目的目标是充分发挥大数据分析和智能推荐算法的优势,为网易云音乐的用户提供更加个性化、多样化的音乐推荐服务。这将为用户带来更多的音乐发现和享受,同时也促进了音乐平台的发展和用户满意度的提升。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。
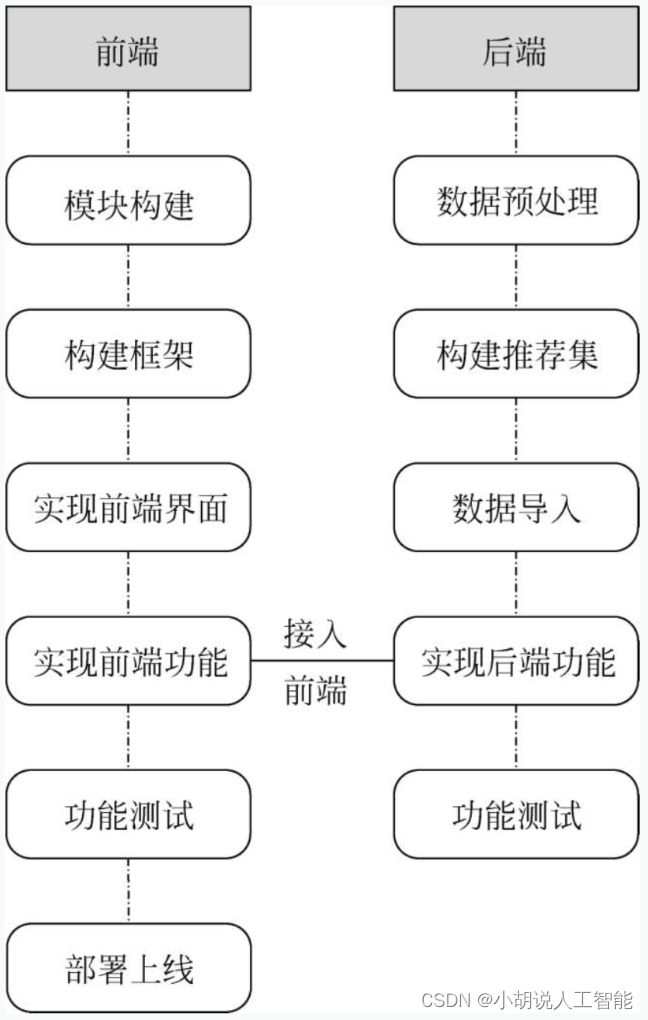
系统流程图
系统流程如图所示。
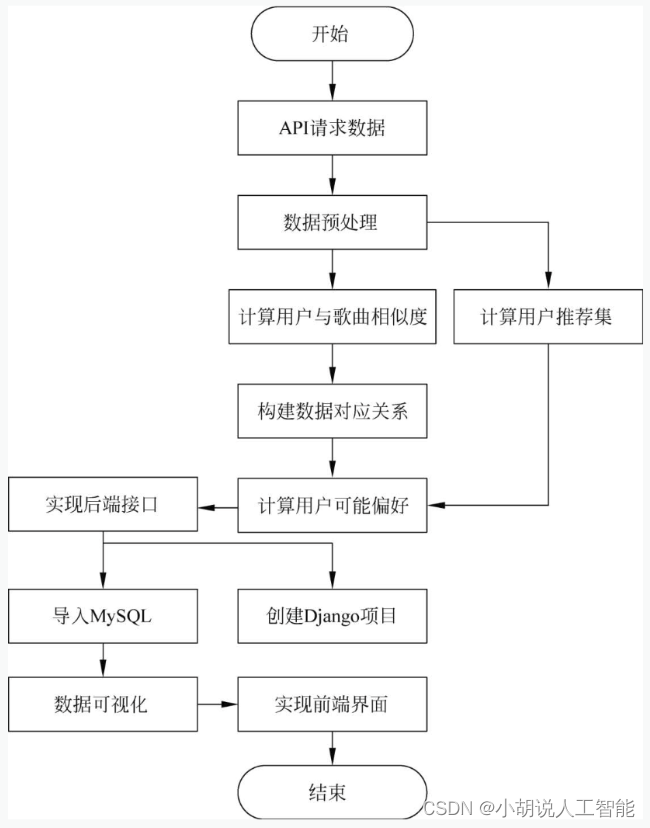
运行环境
本部分包括 Python 环境、MySQL 环境和 VUE 环境。
Python 环境
需要Python 3.6以上运行环境,推荐使用PyCharm IDE。Python 包和对应的版本MusicRecSys/MusicRec/z-others/files/requirement.txt文件中,安装命令为:
pip install -r requirement.txt
需要安装的依頼包为: Django 2.1、PyMySQL 0.9.2、jieba 0.39、xlrd 1.1.0、gensim 3.6.0
查看本机的IP地址,修改MusicRecSys/MusicRec/Music Rec/settings.py文件中的ALLOWED_HOSTS 为本地IP地址和MySQL配置信息。
进入MusicRecSys/MusicRec, 执行pythonmanage.pyrunserver0.0.0.0: 8000。
Django后台访问地址为http://127.0.0.1:8000/admin/(admin, admin)
MySQL环境
安装MySQL最新版本和Navicat可视化工具,在命令行中创建并连接本机用户的数据库,下载地址为https://pan.baidu.com/s/1dYtKQxnoSZywuRfgCOfPRQ, 提取码为:qw8k
新建musicrec数据库,导入文件MusicRecSys/MusicRec/z-others/fles/musicrec.sql
VUE环境
安装node.js 10.13以上版本和npm包管理器(可以安装淘宝镜像cnpm提高速度),推荐使用VSCODEIDE。
修改MusicRecSys/MusicRec-Vue/config/index.js中的serverUrl为本机IP地址。
修改MusicRecSys/MusicRec-Vue/src/assets/js/linkBase.js中的serverUrl为本机IP地址。
进入MusicRecSys/MusicRec-Vue,执行npminstall/npmrundev自动安装所需要的依赖包并用webpack打包运行。
在浏览器中输入http://127.0.0.1:8001, 访问项目界面。
模块实现
本项目包括包括4个模块:数据请求及存储、数据处理、数据存储与后台、数据展示,下面分别介绍各模块的功能及相关代码。
1. 数据请求和储存
通过请求获取音乐和用户相关的所有数据。网易云API地址为https://api.imjad.cn。选择歌单数据作为出发点,是因为歌单与用户、歌曲、歌手都有联系,包含数据的维度最广,并且是用户的主观行为。歌单URL如下所示。
https://music163.com/playlist?id=2308644764
https://music163.com/playlist?id=2470855457
https://music163.com/playlist?id=2291941158
https://music163.com/playlist?id=2452844647
通过URL处理得到歌单ID,请求所需要的数据,存储每一步请求失败的数据,在后续数据处理时跳过这些请求失败的数据URL。
1)歌单信息
歌单信息如图所示。

歌单信息包含歌单ID、创建者ID、名字、创建时间、更新时间,包含音乐数、播放次数、分享次数、评论次数、收藏次数、标签和歌单封面等。
2)创建者信息
创建者信息如图所示。
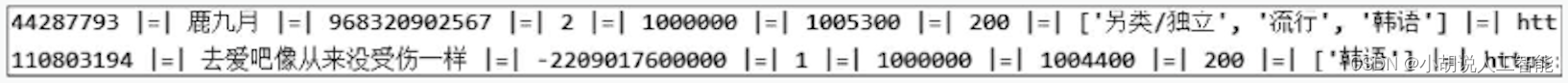
创建者信息包含用户ID、昵称、生日、性别、省份、城市、类型、标签、头像链接、用户状态、账号状态、djStatus、vipStatus、 签名。
3)歌曲音乐信息
歌曲ID信息如图所示。

歌曲信息如图所示。

歌曲信息包含歌曲ID、歌名、专辑ID、出版时间、歌手信息、总评论数、热门评论数、大小、歌曲链接。
4)歌曲对应的歌手信息
歌手信息如图所示。

歌手信息包含歌手ID、歌名、音乐作品数、MV作品数、专辑数、头像链接等,其数据文件结构如图所示。

最终获得所需的基础数据和请求失败的数据,获取歌单信息并存储的相关代码如下:
import requests
import traceback
#获取每个歌单的信息类
class PlayList:def __init__(self):self.playlist_file = "./data/playlist_url/playlist_id_name_all.txt"#获取出错的歌单ID保存文件self.error_id_file = "./data/error_playlist_ids.txt"#歌单创造者信息self.creator_mess = "./data/user_mess/"#每个歌单的json信息self.playlist_mess = "./data/playlist_mess/"#歌单包含的歌曲ID信息self.trackid_mess = "./data/song_mess/"self.ids_list = self.getIDs()self.url = "https://api.imjad.cn/cloudmusic/?type=playlist&id="#获得的歌单信息出错的歌单IDself.error_id = list()#由歌单url 获取歌单IDdef getIDs(self):print("根据歌单链接获取歌单ID ...")ids_list = list()for line in open(self.playlist_file,"r",encoding="utf-8").readlines():try:id = line.strip().split("\t")[0].split("id=")[1]ids_list.append(id)except Exception as e:print(e)passprint("获取歌单ID完成 ...")return ids_list
#获取每个歌单的具体信息url #https://api.imjad.cn/cloudmusic/?type=playlist&id=2340739428def getEveryPlayListMess(self):print("获取每个歌单的具体信息")i = 0while self.ids_list.__len__() !=0 :i += 1id = self.ids_list.pop()url = self.url + str(id)try:print("%s - 歌单ID为:%s" % (i,id))r = requests.get(url)#解析信息self.getFormatPlayListMess(r.json())except Exception as e:#将出错ID写入记录及写入文件,出错时进行跳过print(e)traceback.print_exc()print("歌单ID为:%s 获取出错,进行记录" % id)self.error_id.append(id)pass#breakself.writeToFile(self.error_id_file,",".join(self.error_id))print("歌单信息获取完毕,写入文件: %s" % self.playlist_mess)#每个歌单的内容进行格式化处理写入文件#需要获取的信息: 歌单信息、创建者信息、歌单音乐信息def getFormatPlayListMess(self,json_line):#创建者信息:用户ID、昵称、生日、性别、省份、城市、类型、标签、头像链接、用户状态、账号状态、djStatus,vipStatus、签名creator = json_line["playlist"]["creator"]c_list = (str(creator["userId"]),str(creator["nickname"]),str(creator["birthday"]),str(creator["gender"]),str(creator["province"]),str(creator["city"]),str(creator["userType"]),str(creator["expertTags"]),str(creator["avatarUrl"]),str(creator["authStatus"]),str(creator["accountStatus"]),str(creator["djStatus"]),str(creator["vipType"]),str(creator["signature"]).replace("\n",""))self.writeToFile(self.creator_mess + "user_mess_all.txt"," |=| ".join(c_list))#歌单信息#歌单ID、创建者ID、名字、创建时间、更新时间、播放次数、分享次数、评论次数、收藏次数、标签、歌单封面、描述playlist = json_line["playlist"]p_list = [str(playlist["id"]),str(playlist["userId"]),str(playlist["name"]).replace("\n",""),str(playlist["createTime"]),str(playlist["updateTime"]),str(playlist["trackCount"]),str(playlist["playCount"]),str(playlist["shareCount"]),str(playlist["commentCount"]),str(playlist["subscribedCount"]),str(playlist["tags"]),str(playlist["coverImgUrl"]),str(playlist["description"]).replace("\n","")]self.writeToFile(self.playlist_mess + "pl_mess_all.txt"," |=| ".join(p_list))#歌单包含的歌曲信息t_list = list()trackids = json_line["playlist"]["trackIds"]for one in trackids:t_list.append(str(one["id"]))self.writeToFile(self.trackid_mess + "ids_all1.txt",str(playlist["id"])+"\t"+",".join(t_list))#写入文件def writeToFile(self,filename,one):fw = open(filename,"a",encoding="utf8")fw.write(str(one) + "\n")fw.close()
if __name__ == "__main__": #主函数print("开始获取歌单信息 ..")pl = PlayList()pl.getEveryPlayListMess()print("歌单信息获取完毕 ... Bye !")
2. 数据处理
本部分包含计算歌曲、歌手、用户相似度和计算用户推荐集。
计算歌曲、歌手、用户相似度
用户在创建歌单时指定了标签,系统认为用户对该标签有偏好,遍历用户创建的所有歌单,会给出标签向量。
例如,若系统中有3个标签(日语、嘻哈、沉默),用户张三在歌单中使用的标签为日语和嘻哈,则其对应的标签向量为[1,1,0],根据用户的标签向量使用杰卡德距离算法计算用户相似度。歌单、歌手、歌曲的相似计算逻辑与用户相似度的计算逻辑相同。相关代码如下:
#计算用户相似度,全量用户存储数据量大,所以这里只存储了20个用户,并且要求相似度大于0.8
def getUserSim(self):sim = dict()if os.path.exists("./data/user_sim.json"): #路径sim = json.load(open("./data/user_sim.json","r",encoding="utf-8"))else:i = 0for use1 in self.userTags.keys():sim[use1] = dict()for use2 in self.userTags.keys():if use1 != use2:j_len = len (self.userTags[use1] & self.userTags[use2] )if j_len !=0:result = j_len / len(self.userTags[use1] | self.userTags[use2])if sim[use1].__len__() < 20 or result > 0.8:sim[use1][use2] = resultelse:#找到最小值并删除minkey = min(sim[use1], key=sim[use1].get)del sim[use1][minkey]i += 1print(str(i) + "\t" + use1)json.dump(sim, open("./data/user_sim.json","w",encoding="utf-8"))print("用户相似度计算完毕!")return sim
#将计算出的相似度转成导入mysql的格式
def transform(self):fw = open("./data/user_sim.txt","a",encoding="utf-8")for u1 in self.sim.keys():for u2 in self.sim[u1].keys():fw.write(u1 + "," + u2 + "," + str(self.sim[u1][u2]) + "\n")fw.close()print("Over!")
计算用户推荐集
本部分主要介绍用户的协同过滤算法,为用户产生歌曲推荐,与歌单、用户、歌手的推荐算法相似。
(1)创建RecSong类
相关代码如下:
class RecSong:def __init__(self):self.playlist_mess_file = "../tomysql/data/pl_mess_all.txt"self.playlist_song_mess_file = "../tomysql/data/pl_sing_id.txt"self.song_mess_file = "../tomysql/data/song_mess_all.txt"
# 在__init__(self)中指定了所使用的文件
2)构建用户和歌曲的对应关系
用户创建了歌单,歌单中包含歌曲。当用户将一首歌曲归档到歌单中,则认为该首歌曲的评分值为1;如果对同一首歌多次归档,则每次归档评分值加1。相关代码如下:
#加载数据 =>用户对歌曲的对应关系
def load_data(self):#所有用户user_list = list()#歌单和歌曲对应关系playlist_song_dict = dict()for line in open(self.playlist_song_mess_file, "r", encoding="utf-8"):#歌单 \t 歌曲splaylist_id, song_ids = line.strip().split("\t")playlist_song_dict.setdefault(playlist_id, list())for song_id in song_ids.split(","):playlist_song_dict[playlist_id].append(song_id)#print(playlist_sing_dict)print("歌单和歌曲对应关系!")#用户和歌曲对应关系user_song_dict = dict()for line in open(self.playlist_mess_file, "r", encoding="utf-8"):pl_mess_list = line.strip().split(" |=| ")playlist_id, user_id = pl_mess_list[0], pl_mess_list[1]if user_id not in user_list:user_list.append(user_id)user_song_dict.setdefault(user_id, {})for song_id in playlist_song_dict[playlist_id]:user_song_dict[user_id].setdefault(song_id, 0)user_song_dict[user_id][song_id] += 1#print(user_song_dict)print("用户和歌曲对应信息统计完毕 !")return user_song_dict, user_list
3)计算用户相似度
为用户推荐歌曲采用的是基于协同过滤算法,需要计算出用户相似度。计算分为两步:构建倒排表和构建相似度矩阵,计算公式为:
w u v = ∑ i ∈ N ( u ) ∩ N ( v ) 1 lg ( 1 + ∣ N ( i ) ∣ ) ∣ N ( u ) ∥ N ( v ) ∣ {w_{u v}}=\frac{\sum_{i \in N(u) \cap N(v)} \frac{1}{\lg (1+|N(i)|)}}{\sqrt{|N(u) \| N(v)|}} wuv=∣N(u)∥N(v)∣∑i∈N(u)∩N(v)lg(1+∣N(i)∣)1
相关代码如下:
#计算用户之间的相似度,采用惩罚热门商品和优化复杂度的算法
def UserSimilarityBest(self):#得到每个item被哪些user评价过tags_users = dict()for user_id, tags in self.user_song_dict.items():for tag in tags.keys():tags_users.setdefault(tag,set())if self.user_song_dict[user_id][tag] > 0:tags_users[tag].add(user_id)#构建倒排表C = dict()N = dict()for tags, users in tags_users.items():for u in users:N.setdefault(u,0)N[u] += 1C.setdefault(u,{})for v in users:C[u].setdefault(v, 0)if u == v:continueC[u][v] += 1 / math.log(1+len(users))#构建相似度矩阵W = dict()for u, related_users in C.items():W.setdefault(u,{})for v, cuv in related_users.items():if u==v:continueW[u].setdefault(v, 0.0)W[u][v] = cuv / math.sqrt(N[u] * N[v])print("用户相似度计算完成!")return W
4)计算用户对歌曲的可能偏好
遍历所有的相似用户,对于未产生过归档行为的歌曲,计算用户对他们的偏好。相关代码如下:
#为每个用户推荐歌曲
def recommend_song(self):#记录用户对歌手的评分user_song_score_dict = dict()if os.path.exists("./data/user_song_prefer.json"):user_song_score_dict = json.load(open("./data/user_song_prefer.json", "r", encoding="utf-8"))print("用户对歌手的偏好从文件加载完毕!")return user_song_score_dictfor user in self.user_song_dict.keys():print(user)user_song_score_dict.setdefault(user, {})#遍历所有用户for user_sim in self.user_sim[user].keys():if user_sim == user:continuefor song in self.user_song_dict[user_sim].keys():user_song_score_dict[user].setdefault(song,0.0)user_song_score_dict[user][song] += self.user_sim[user][user_sim] * self.user_song_dict[user_sim][song]json.dump(user_song_score_dict, open("./data/user_song_prefer.json", "w", encoding="utf-8"))print("用户对歌曲的偏好计算完成!")return user_song_score_dict
5)写入文件
对每首歌曲的偏好进行排序,将用户最可能产生归档行为的前100首歌曲写入文件,便于导入数据库,供系统使用。相关代码如下:
#写入文件
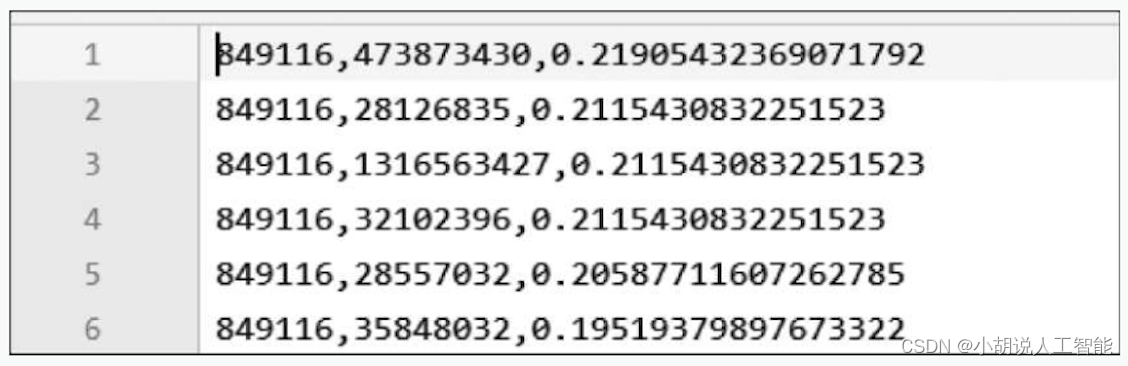
def write_to_file(self):fw = open("./data/user_song_prefer.txt","a",encoding="utf-8")for user in self.user_song_score_dict.keys():sort_user_song_prefer = sorted(self.user_song_score_dict[user].items(), key=lambda one:one[1], reverse=True)for one in sort_user_song_prefer[:100]:fw.write(user+','+one[0]+','+str(one[1])+'\n')fw.close()print("写入文件完成")
user_song_prefer.txt文件内容如图所示。
同样,歌单、歌手、用户的推荐结果也通过类似的方式进行计算。
3. 数据存储与后台
在PyCharm中创建新的Django项目及5个模板,即主页、歌单、歌手、歌曲和用户。模板为文本文件,用于分离表现形式和内容。下面以歌单模板为例,介绍各文件用途。Django项目结构如图所示。
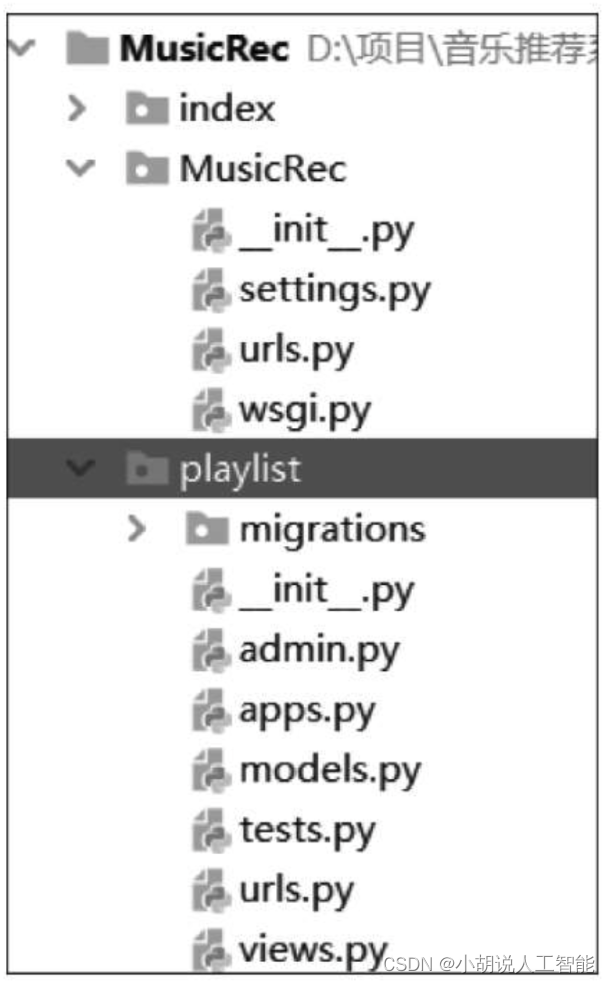
部分文件数据大,使用Navicat软件工具导入,其余部分使用Python代码连接数据库导入。以歌单信息导入数据库为例,Django中创建的Model层相关代码如下:
#歌单信息:歌单ID、创建者ID、名字、创建时间、更新时间、包含音乐数
#播放次数、分享次数、评论次数、收藏次数、标签、歌单封面、描述
class PlayList(models.Model):pl_id = models.CharField(blank=False, max_length=64, verbose_name="ID", unique=True)pl_creator = models.ForeignKey(User, related_name="创建者信息", on_delete=False)pl_name = models.CharField(blank=False, max_length=64, verbose_name="歌单名字")pl_create_time = models.DateTimeField(blank=True, verbose_name="创建时间")pl_update_time = models.DateTimeField(blank=True, verbose_name="更新时间")pl_songs_num = models.IntegerField(blank=True,verbose_name="包含音乐数")pl_listen_num = models.IntegerField(blank=True,verbose_name="播放次数")pl_share_num = models.IntegerField(blank=True,verbose_name="分享次数")pl_comment_num = models.IntegerField(blank=True,verbose_name="评论次数")pl_follow_num = models.IntegerField(blank=True,verbose_name="收藏次数")pl_tags = models.CharField(blank=True, max_length=1000, verbose_name="歌单标签")pl_img_url = models.CharField(blank=True, max_length=1000, verbose_name="歌单封面")pl_desc = models.TextField(blank=True, verbose_name="歌单描述")def __str__(self):return self.pl_idclass Meta:db_table = 'playList'verbose_name_plural = "歌单信息"
#歌单信息写入数据库
def playListMessToMysql(self):i=0for line in open("./data/pl_mess_all.txt", "r", encoding="utf-8"):pl_id, pl_creator, pl_name, pl_create_time, pl_update_time, pl_songs_num, pl_listen_num, \pl_share_num, pl_comment_num, pl_follow_num, pl_tags, pl_img_url, pl_desc = line.split(" |=| ")try:user = User.objects.filter(u_id=pl_creator)[0]except:user = User.objects.filter(u_id=pl_creator)[0]pl = PlayList(pl_id = pl_id,pl_creator = user,pl_name = pl_name,pl_create_time = self.TransFormTime(int(pl_create_time)/1000),pl_update_time = self.TransFormTime(int(pl_update_time)/1000),pl_songs_num = int (pl_songs_num),pl_listen_num = int( pl_listen_num ),pl_share_num = int( pl_share_num) ,pl_comment_num = int (pl_comment_num),pl_follow_num = int(pl_follow_num),pl_tags = str(pl_tags).replace("[","").replace("]","").replace("\'",""),pl_img_url = pl_img_url,pl_desc = pl_desc)pl.save()i+=1print(i)
执行完毕后,在数据库可视化管理软件Navicat和Django自带的后台管理中可查看对应的数据表,如图1和图2所示。


最终得到全部数据表,如下两图所示。


4. 数据展示
前端实现的功能包括:用户登录和选择偏好歌曲、歌手;为你推荐(用户行为不同,推荐也不同) ;进入各页面时基于内容的推荐算法为用户推荐歌单,协同过滤算法为用户推荐歌曲、歌手;单击时获取详细信息,提供单个歌单、歌曲、歌手、用户的推荐;个性化排行榜(将相似度由大到小排序);我的足迹,展示用户在站内的行为(单击时记录)。
(1)Django后台处理前端请求获取推荐标签,View层相关代码。
#首页推荐标签
"""由于标签个数原因,且歌单、歌手、歌曲共用一套标签,这里标签推荐基于1)用户进入系统时的选择2)用户在站内产生的单击行为3)热门标签进行补数
"""
def GetRecTags(request, base_click):#从接口中获取传入的歌手和歌曲IDsings = request.session["sings"].split(",")songs = request.session["songs"].split(",")#歌手标签sings_tags = getSingRecTags(sings, base_click)#歌曲标签songs_tags,pl_tags = getSongAndPlRecTags(songs, base_click)return {"code": 1,"data": {"playlist": {"cateid": 2, "tags": list(pl_tags)},"song": {"cateid": 3, "tags": list(songs_tags)},"sing": {"cateid": 4, "tags": list(sings_tags)},}}
#获得歌曲、歌单标签推荐
def getSongAndPlRecTags(songs, base_click):song_tags = list()pl_tags = list()#base_click =1 表示用户是在站内产生行为后返回推荐,此时用户行为对象对应的标签排序在前#否则基于用户选择的标签排序在前if base_click == 1: #表示前端是基于单击行为进入为你推荐模块click_songs = UserBrowse.objects.filter(click_cate="3").values("click_id")if click_songs.__len__() != 0:for one in click_songs:filter_one = SongTag.objects.filter(song_id=one["click_id"])if filter_one.__len__() != 0 and filter_one[0].tag not in song_tags:song_tags.append(filter_one[0].tag)#歌单tagpl_one = PlayListToSongs.objects.filter( song_id=filter_one[0].song_id )if pl_one.__len__() !=0:for pl_tag_one in PlayListToTag.objects.filter(pl_id=pl_one[0].song_id):if pl_tag_one.tag not in pl_tags:pl_tags.append(pl_tag_one.tag)if songs.__len__() != 0: #表示前端选择了相关歌曲for sing in songs:choose_one = SongTag.objects.filter(song_id=sing)if choose_one.__len__() != 0 and choose_one[0].tag not in song_tags:song_tags.append(choose_one[0].tag)#歌单tagpl_one= layListToSongs.objects.filter(song_id=choose_one[0].song_id)if pl_one.__len__() != 0:for pl_tag_one in PlayListToTag.objects.filter(pl_id=pl_one[0].song_id):if pl_tag_one.tag not in pl_tags:pl_tags.append(pl_tag_one.tag)#print("songs_tags_by_click %s" % songs_tags_by_click)#print("pl_tags_by_click %s" % pl_tags_by_click)else: #表示用户是首次进入为你推荐模块if songs.__len__() != 0: #表示前端选择了相关歌曲for sing in songs:choose_one = SongTag.objects.filter(song_id=sing)if choose_one.__len__() != 0 and choose_one[0].tag not in song_tags:song_tags.append(choose_one[0].tag)#歌单tagpl_one = PlayListToSongs.objects.filter(song_id=choose_one[0].song_id)if pl_one.__len__() != 0:for pl_tag_one in PlayListToTag.objects.filter(pl_id=pl_one[0].song_id):if pl_tag_one.tag not in pl_tags:pl_tags.append(pl_tag_one.tag)#print("songs_tags_by_choose: %s" % songs_tags_by_choose)#print("pl_tags_by_choose: %s" % pl_tags_by_choose)#如果click和choose的tag不够以hot来补充if song_tags.__len__() < 15:hot_tag_dict = dict()for one in SongTag.objects.all():hot_tag_dict.setdefault(one.tag, 0)hot_tag_dict[one.tag] += 1tag_dict_song = sorted(hot_tag_dict.items(), key=lambda k: k[1], reverse=True)[:15-song_tags.__len__()]for one in tag_dict_song:if one[0] not in song_tags:song_tags.append(one[0])#print("songs_tags_by_hot: %s" % songs_tags_by_hot)#如果 click 和 choose的tag不够,以 hot来补充if pl_tags.__len__() < 15:hot_tag_dict = dict()for one in PlayListToTag.objects.all():hot_tag_dict.setdefault(one.tag, 0)hot_tag_dict[one.tag] += 1tag_dict_pl = sorted(hot_tag_dict.items(), key=lambda k: k[1], reverse=True)[:15-pl_tags.__len__()]for one in tag_dict_pl:if one[0] not in pl_tags:pl_tags.append(one[0])#print("pl_tags_by_hot: %s" % pl_tags_by_hot)return song_tags,pl_tags
(2)进入各页面是基于内容的推荐算法给用户推荐歌单、协同过滤算法推荐歌曲、歌手,这里以歌单为例:
def rec_right_playlist(request): #推荐歌单user = request.GET.get("username")u_id = User.objects.filter(u_name=user)[0].u_idrec_all = UserPlayListRec.objects.filter(user=u_id).order_by("-sim")[:12]_list = list()for rec in rec_all:one = PlayList.objects.filter(pl_id=rec.related)[0]_list.append({"pl_id": one.pl_id,"pl_creator": one.pl_creator.u_name,"pl_name": one.pl_name,"pl_img_url": one.pl_img_url})return {"code": 1,"data": {"recplaylist": _list}}
(3)单击时获取详细信息,并基于标签进行单个歌单、歌曲、歌手、用户的推荐,这里以用户为例:
def all(request):#接口传入的tag参数tag = request.GET.get("tag")#接口传入的page参数_page_id = int(request.GET.get("page"))print("Tag : %s, page_id: %s" % (tag,_page_id))_list = list()#全部用户if tag == "all":sLists = User.objects.all().order_by("-u_id")#拼接用户信息for one in sLists[(_page_id - 1) * 30:_page_id * 30]:_list.append({"u_id": one.u_id,"u_name": one.u_name,"u_img_url": one.u_img_url})#指定标签下的用户else:sLists = UserTag.objects.filter(tag=tag).values("user_id").order_by("user_id")for sid in sLists[(_page_id - 1) * 30:_page_id * 30]:one = User.objects.filter(u_id=sid["user_id"])if one.__len__() == 1:one = one[0]else:continue_list.append({"u_id": one.u_id,"u_name": one.u_name,"u_img_url": one.u_img_url})total = sLists.__len__()return {"code": 1,"data": {"total": total,"sings": _list,"tags": getAllUserTags()}}
#获取所有用户标签
def getAllUserTags():tags = set()for one in UserTag.objects.all().values("tag").distinct().order_by("user_id"):tags.add(one["tag"])return list(tags)
def one(request): #处理用户请求u_id = request.GET.get("id")one = User.objects.filter(u_id=u_id)[0]
wirteBrowse(user_name=request.GET.get("username"),click_id=u_id,click_cate="5", user_click_time=getLocalTime(), desc="查看用户")return JsonResponse({"code": 1,"data": [{"u_id": one.u_id,"u_name": one.u_name,"u_birthday":one.u_birthday,"u_gender":one.u_gender,"u_province":one.u_province,"u_city":one.u_city,"u_tags":one.u_tags,"u_img_url": one.u_img_url,"u_sign":one.u_sign,"u_rec": getRecBasedOne(u_id),"u_playlist":getUserCreatePL(u_id)}]})
#获取单个用户的推荐
def getRecBasedOne(u_id):result = list()sim_users = UserSim.objects.filter(user_id=u_id).order_by("-sim").values("sim_user_id")[:10]for user in sim_users:one = User.objects.filter(u_id= user["sim_user_id"])[0]result.append({"id": one.u_id,"name": one.u_name,"img_url": one.u_img_url,"cate":"5"})return result
#获取用户创建的歌单
def getUserCreatePL(uid):pls = PlayList.objects.filter(pl_creator__u_id=uid)result = list()for one in pls:result.append({"pl_id": one.pl_id,"pl_name":one.pl_name,"pl_creator": one.pl_creator.u_name,"pl_create_time": one.pl_create_time,"pl_img_url": one.pl_img_url,"pl_desc":one.pl_desc})return result
#用户浏览信息进行记录
"""user_name = models.CharField(blank=False, max_length=64, verbose_name="用户名")click_id = models.CharField(blank=False, max_length=64, verbose_name="ID")click_cate = models.CharField(blank=False, max_length=64, verbose_name="类别")user_click_time = models.DateTimeField(blank=False, verbose_name="浏览时间")desc = models.CharField(blank=False, max_length=1000, verbose_name="备注",default="Are you ready!")
"""
def wirteBrowse(user_name="",click_id="",click_cate="",user_click_time="",desc=""):if "12797496" in click_id: click_id = "12797496"UserBrowse(user_name=user_name,click_id=click_id,click_cate=click_cate,user_click_time = user_click_time,desc=desc).save()print("用户【 %s 】的行为记录【 %s 】写入数据库" % (user_name, desc))
#获取当前格式化的系统时间
def getLocalTime():return time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
系统测试
本部分包括系统流程和测试效果。
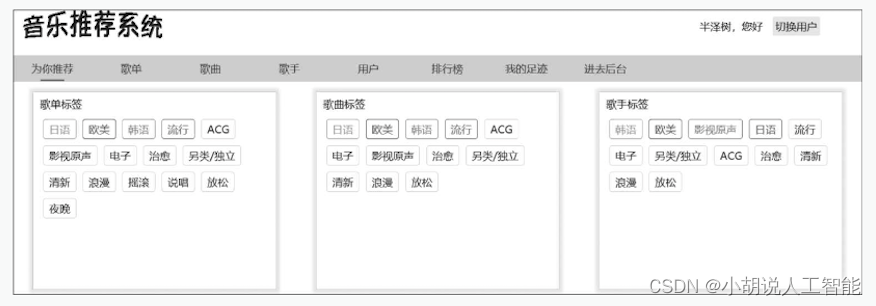
(1)选择用户进入系统。每次随机从数据库中返回部分作为系统用户,使用不同的用户是为了区分行为偏好,如图所示。

(2)选择歌手、歌曲(3个及以上,可以跳过)。用户与系统交互的过程,解决系统的冷启动。当然用户也可以不选择歌手,直接跳过,此时系统中“为你推荐歌手标签部分为热度标签数据。界面如下两图所示。


(3)根据用户创建歌单的偏好,推荐用户偏好的歌单、歌曲的。单击标签可以查看相应标签下的所有歌曲,分别进入歌单、歌曲、歌手推荐页面,如图所示。
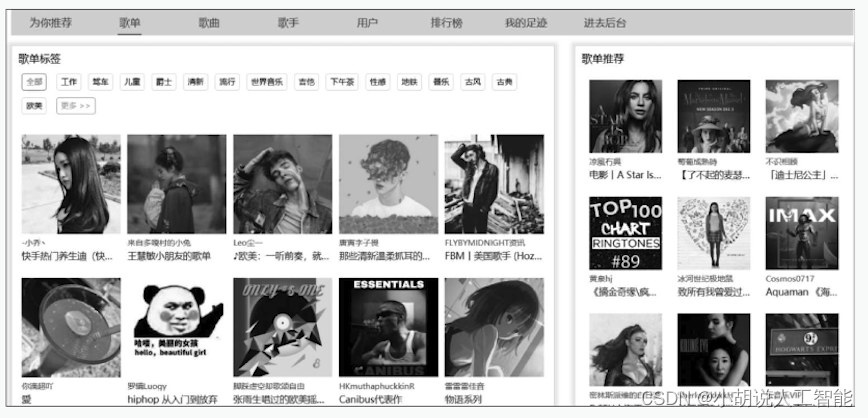
(4)歌单推荐页面。左侧为按照标签分类的全部歌单,右侧为基于内容的推荐算法为用户推荐的歌单,如图所示。
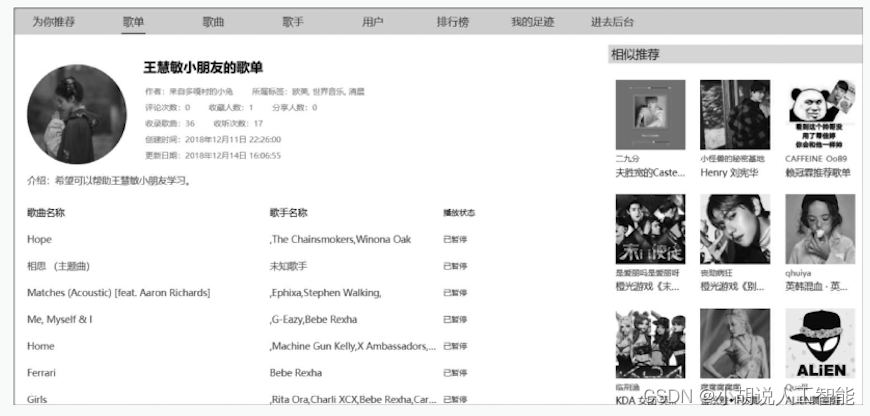
(5) 歌单详情页。包含歌单的详细信息和歌单内的歌曲,右侧为基于标签相似度提供的歌单推荐,如图所示。
(6) 歌曲推荐页面。左侧为按照标签分类的全部歌曲,右侧为基于协同过滤算法为用户推荐的歌曲,如图所示。
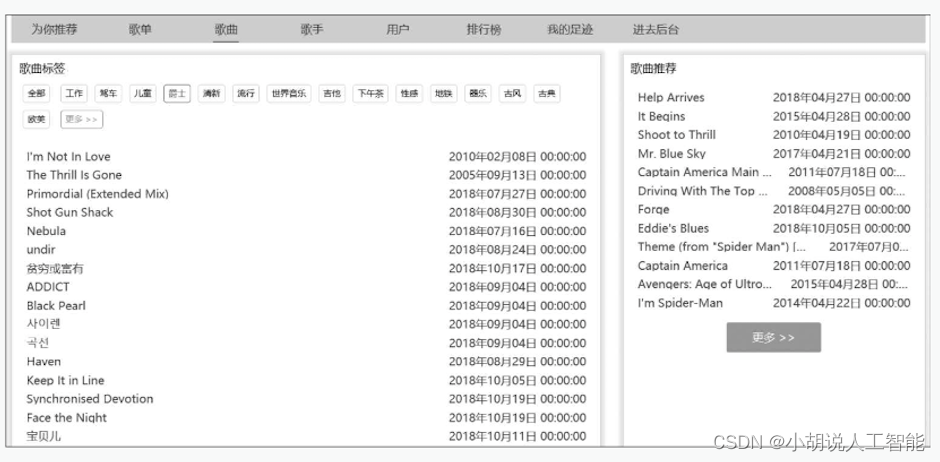
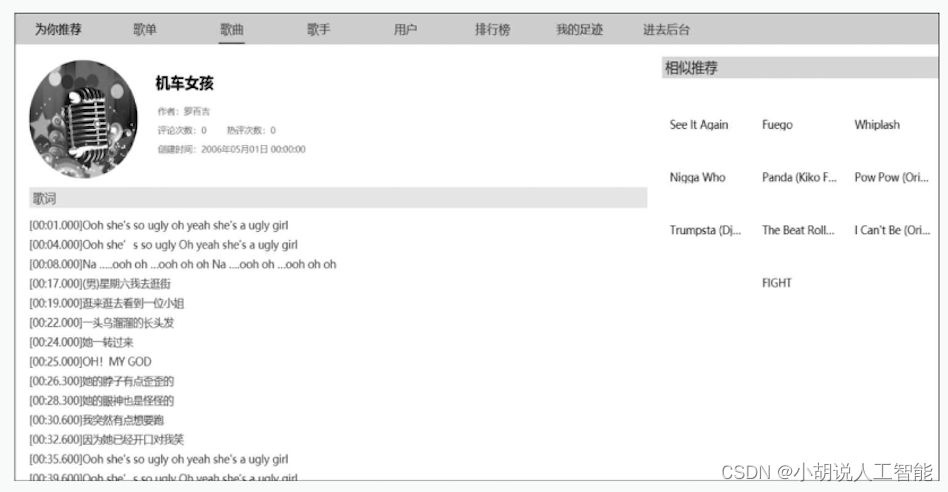
(7)歌曲详情页。包含歌曲的信息和歌词,右侧为基于标签相似度提供的歌单推荐,如图所示 。
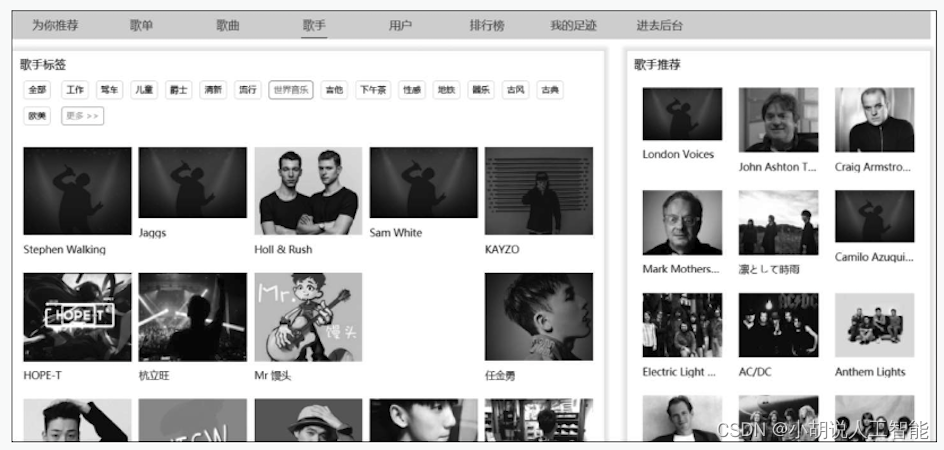
(8)歌手推荐页面。左侧为按照标签分类的全部歌手,右侧为基于协同过滤算法为用户推荐的歌曲,如图所示。
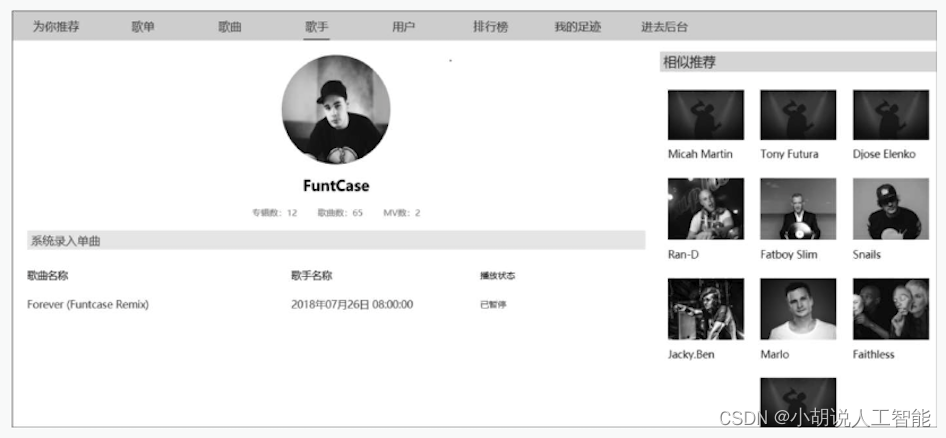
(9)歌手详情页。包含歌手的信息和歌曲,右侧为基于标签相似度提供的歌手推荐,如图所示。
(10)用户推荐页面。左侧为按照标签分类的全部用户,右侧为基于协同过滤算法为用户推荐的用户,如图所示。
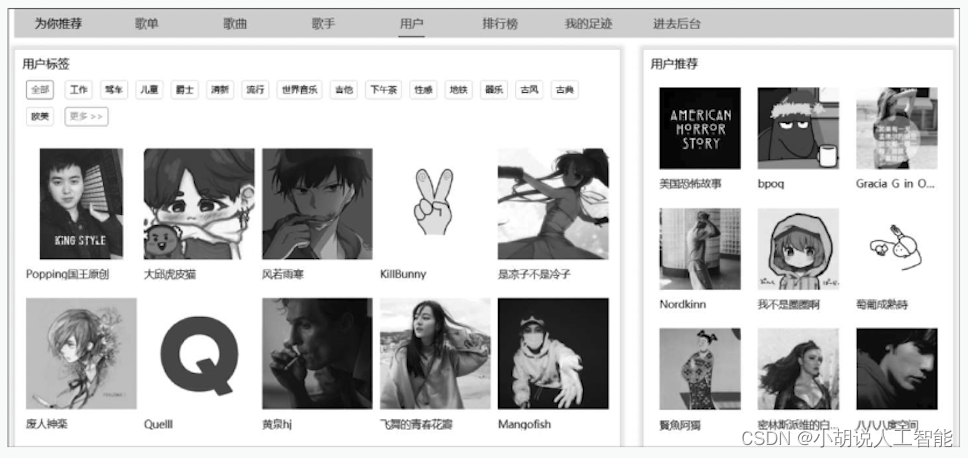
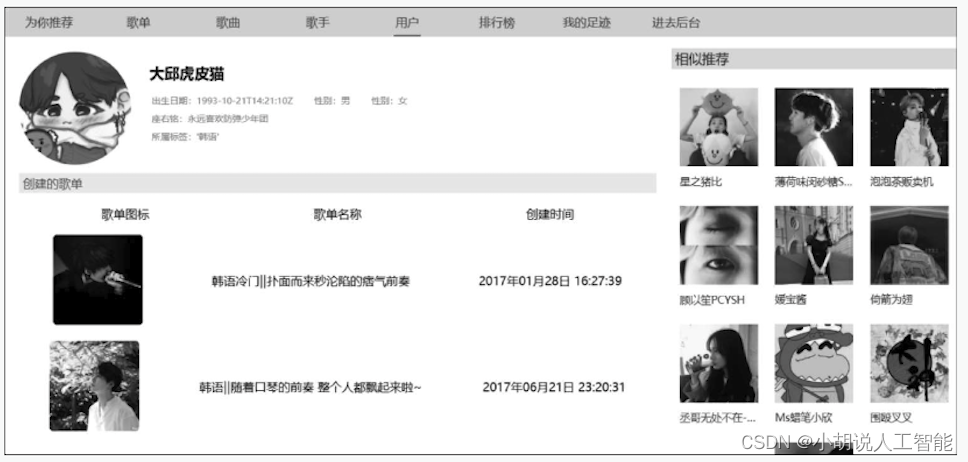
(11) 用户详情页。包含用户的信息和创建的歌单,右侧为基于标签相似度提供的推荐,如图所示 。
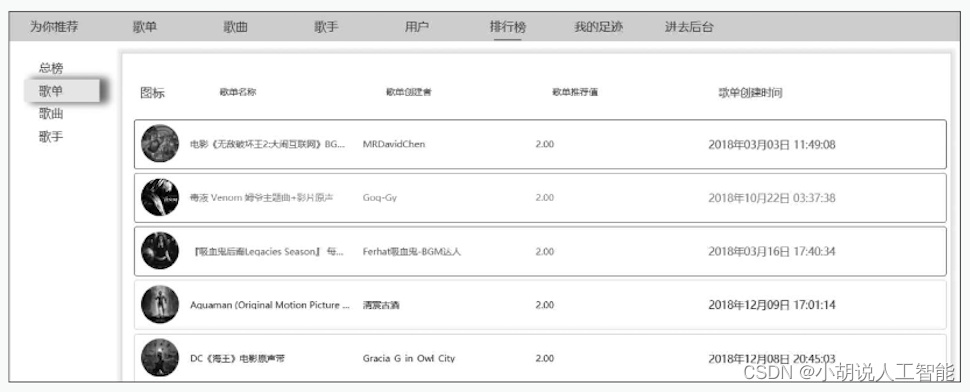
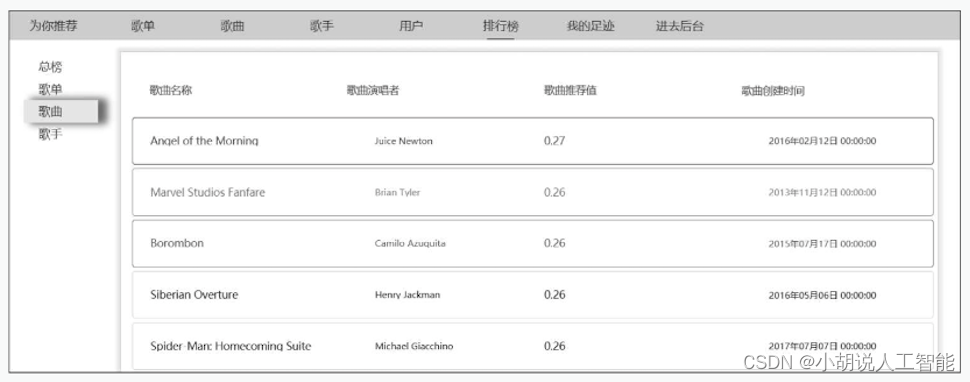
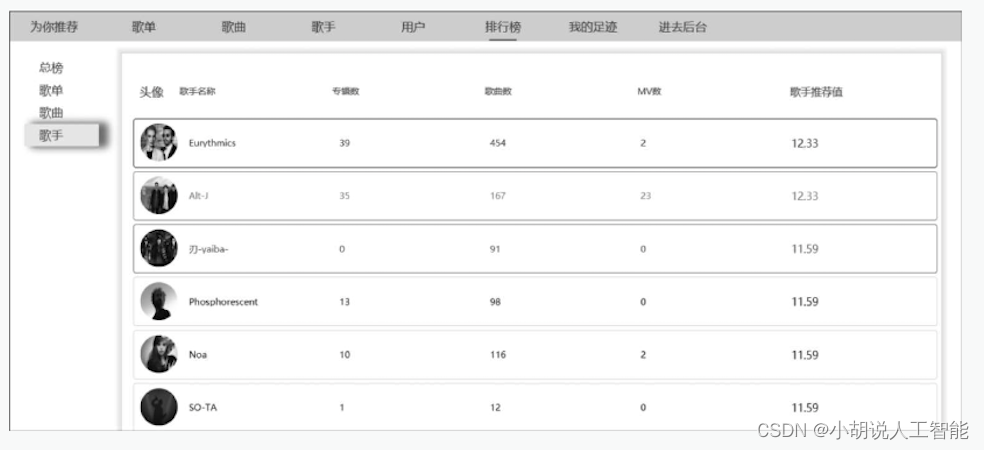
(12) 个性化排行榜。基于用户的偏好程度(协同过滤算法计算的结果)进行排序展示,不同用户看到的显示界面不同,如图5~图8所示。

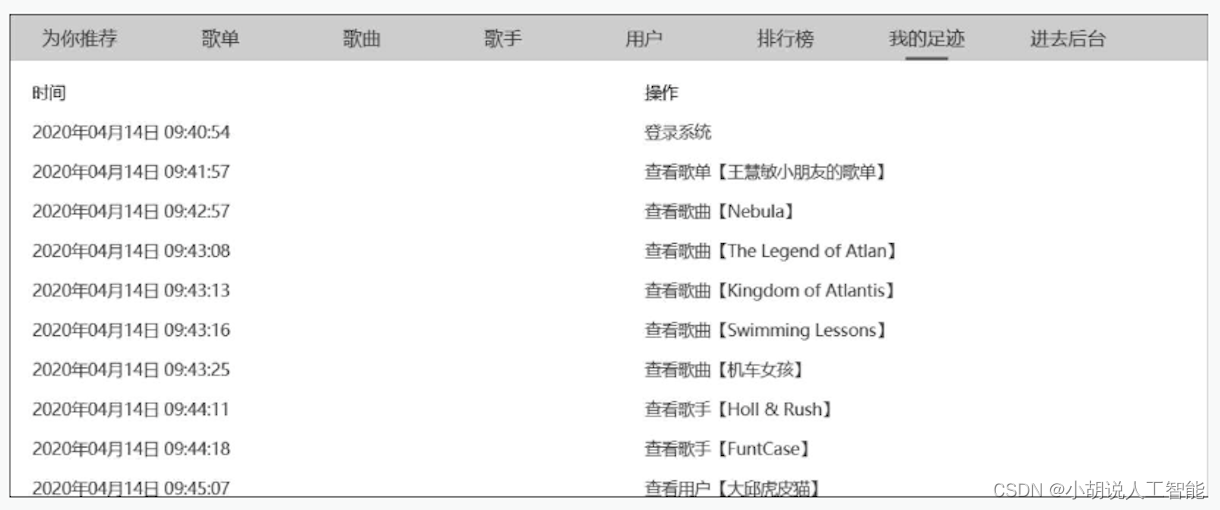
(13) 我的足迹。浏览歌单、歌曲、歌手时用户在系统中产生的行为记录,如图所示。
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
相关文章:
基于Mysql+Vue+Django的协同过滤和内容推荐算法的智能音乐推荐系统——深度学习算法应用(含全部工程源码)+数据集
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境MySQL环境VUE环境 模块实现1. 数据请求和储存2. 数据处理计算歌曲、歌手、用户相似度计算用户推荐集 3. 数据存储与后台4. 数据展示 系统测试工程源代码下载其它资料下载 前言 本项目以丰富的网易云音乐数据为基…...
Python Web开发 Django 简介
今天来为大家介绍 Python 另一个 Web 开发框架 Django,它是一个基于 Python 定制的开源 Web 应用框架,最早源于一个在线新闻 Web 网站,后于2005年开源。Django 的功能大而全,它提供的一站式解决的思路,能让开发者不用在…...

HAproxy搭建web集群
目录 一、HAproxy 概述 二、HAproxy 主要特性 三、HAproxy 负载均衡策略(八种) 四、LVS、Nginx、HAproxy区别 Nginx LVS HAproxy 五、HAproxy部署实战 问题总结: 一、HAproxy 概述 HAProxy是可提供高可用性、负载均衡以及基于TCP和HTTP应用的代理࿰…...

临时用工小程序:一款便捷的用工管理软件
随着企业对人力资源需求的不断增长,临时用工需求也日益旺盛。为了满足这一需求,我们研发了一款名为“临时用工小程序”的软件系统,旨在帮助企业实现临时用工的高效管理。 一、技术栈介绍 后端技术栈 本系统采用Java语言作为开发语言&#…...
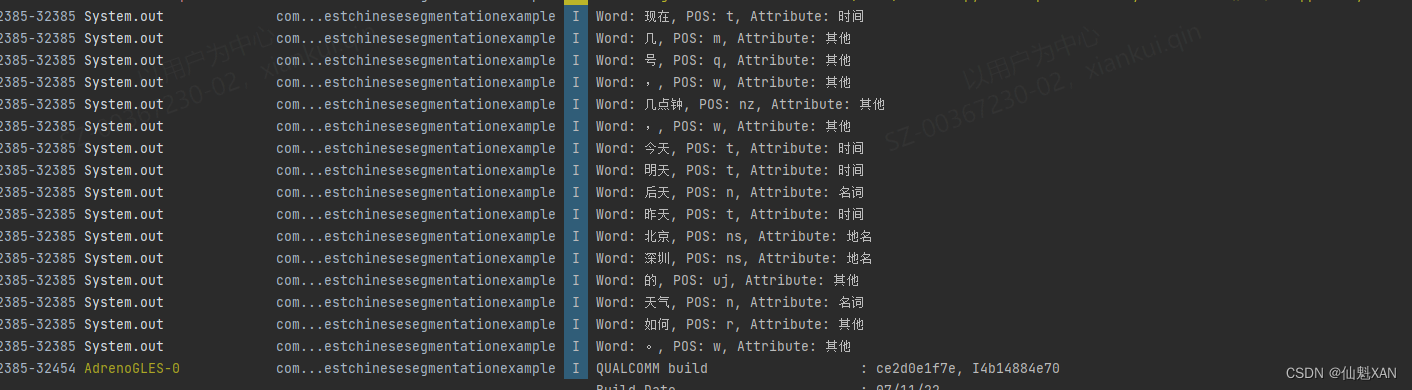
Android Studio 之 Android 中使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理
Android Studio 之 Android 中使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理 目录 Android Studio 之 Android 中使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理 一、简单介绍 二、实现原理…...
)
CSDN编程题-每日一练(2023-08-20)
CSDN编程题-每日一练(2023-08-19) 一、题目名称:等差数列二、题目名称:喜水青蛙三、题目名称:括号匹配一、题目名称:等差数列 时间限制:1000ms内存限制:256M 题目描述: 给定一已排序的正整数组成的数组,求需要在中间至少插入多少个数才能将其补全成为一等差数列。 “…...
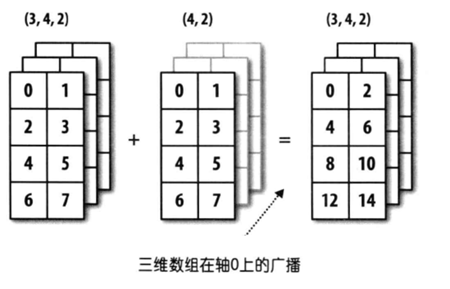
大数据:NumPy进阶应用详解
专栏介绍 结合自身经验和内部资料总结的Python教程,每天3-5章,最短1个月就能全方位的完成Python的学习并进行实战开发,学完了定能成为大佬!加油吧!卷起来! 全部文章请访问专栏:《Python全栈教…...
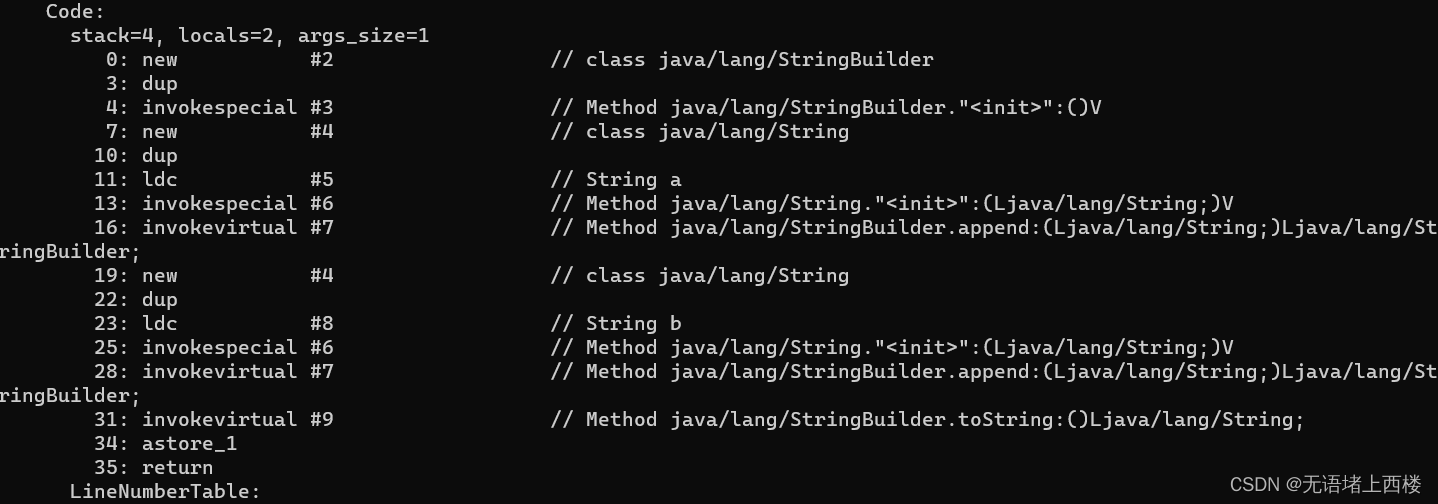
new String创建几个对象
在java17中 : 问题1:new String("abc")会产生多少个对象? 分两种情况: 情况1: 如果”abc”这个字符串常量不存在,则创建两个对象,分别是“abc”这个字符串常量,以及ne…...
【路由协议】使用按需路由协议和数据包注入的即时网络模拟传递率(PDR)、总消耗能量和节点消耗能量以及延迟研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

c#实现依赖注入
当谈到C#中的依赖注入(Dependency Injection,DI)时,我们可以使用一个简单的示例来说明它是如何工作的。依赖注入是一种设计模式,用于将依赖关系从一个类传递到另一个类,以实现松耦合和可测试性。 假设我们有一个简单的订单处理应用程序,其中包含两个主要类:OrderServi…...

算法通关村十一关 | 位运算实现加法和乘法
1.位实现加法和乘法 在计算机中,位运算的效率要比加减乘除的效率更高,因此在高性能软件中源码中大量使用,计算机里各种运算基本上都是位运算。 学习下面内容之前建议先学习位运算规则:算法通关村十一关 | 位运算的规则_我爱学算…...
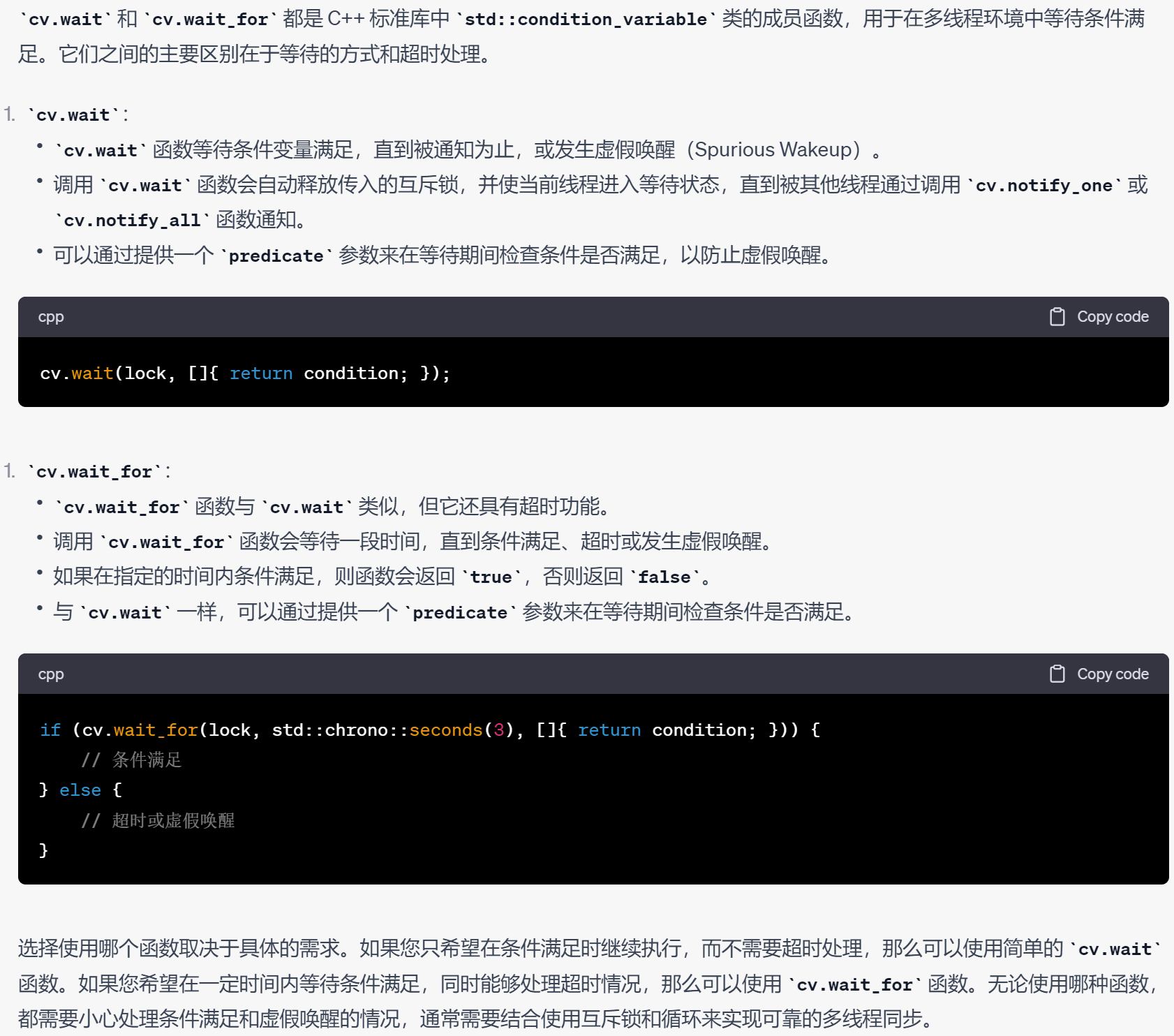
C++笔记之条件变量(Condition Variable)与cv.wait 和 cv.wait_for的使用
C笔记之条件变量(Condition Variable)与cv.wait 和 cv.wait_for的使用 参考博客:C笔记之各种sleep方法总结 code review! 文章目录 C笔记之条件变量(Condition Variable)与cv.wait 和 cv.wait_for的使用1.条件变量&…...

Dubbo之DubboBootstrap源码解析
功能描述 DubboBootstrap是Dubbo的启动类,包含服务启动、初始化、预处理配置、销毁清理等核心功能 功能分析 核心DubboBootstrap类分析 主要成员变量分析 private static volatile DubboBootstrap instance; //缓存者启动类的实例对象,以static形式…...
SpringBoot + Vue 微人事 项目 (第八天)
基础信息设置 在该页面添加一个大div,然后添加一个tab选项卡,Element UI里面有 把代码复制到大div里面,把里面的label和name属性改成我们想要的,再把tab-click"handleClick"去掉 <div><el-tabs v-model"a…...
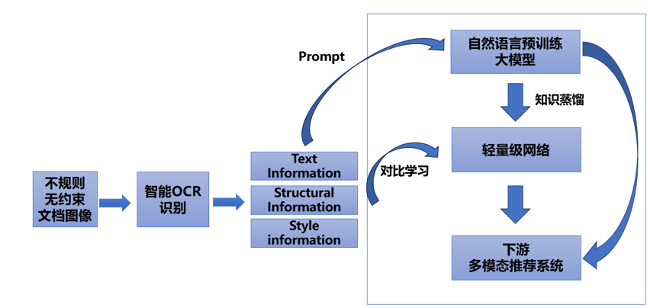
人工智能引领图文扫描新趋势
1. 背景和影响 近日,中国大学生服务外包创新创业大赛决赛在江南大学圆满落幕。为满足现代服务产业企业的现实需求,本次竞赛内容设计充分聚焦企业发展中所面临的技术、管理等现实问题,与产业的结合度更紧密,智能文字识别技术是大赛…...

ChatGPT在智能城市规划和交通优化中的应用如何?
智能城市规划和交通优化是应对城市化挑战、提高城市可持续性的重要领域。在这方面,ChatGPT作为一种强大的自然语言处理模型,可以发挥重要作用,帮助实现更智能、高效的城市规划和交通管理。本文将详细探讨ChatGPT在智能城市规划和交通优化中的…...

探索Perfetto:开源性能追踪工具的未来之光
探索Perfetto:开源性能追踪工具的未来之光 1. 引言 A. 介绍Perfetto的背景和作用 随着移动应用、桌面软件和嵌入式系统的不断发展,软件性能优化变得愈发重要。在这个背景下,Perfetto作为一款开源性能追踪工具,日益引起了开发者…...

A*算法图文详解
基本概念 A*算法最早于1964年在IEEE Transactions on Systems Science and Cybernetics中的论文《A Formal Basis for the Heuristic Determination of Minimum Cost Paths》中首次提出。其属于一种经典的启发式搜索方法,所谓启发式搜索,就在于当前搜索…...

[MySQL] — 数据类型和表的约束
目录 数据类型 数据类型分类 数值类型 tinyint类型 bit类型 小数类型 float decimal 字符串类型 char varchar char和varchar的区别 日期和时间类型 enum 和 set 表的约束 空属性 默认值 列描述 zeorfill 主键 创建表时在字段上指定主键 删除主键: 追…...

JetBrains IDE远程开发功能可供GitHub用户使用
JetBrains与GitHub去年已达成合作,提供GitHub Codespaces 与 JetBrains Gateway 之间的集成。 GitHub Codespaces允许用户创建安全、可配置、专属的云端开发环境,此集成意味着您可以通过JetBrains Gateway使用在 GitHub Codespaces 中运行喜欢的IDE进行…...

正点原子 STM32MP257 同构多核架构下的 ADC 电压采集与处理应用开发实战
在嵌入式系统中,ADC模拟电压的读取是常见的需求。如何高效、并发、且可控地完成数据采集与处理?本篇文章通过双线程分别绑定在 Linux 系统的不同 CPU 核心上,采集 /sys/bus/iio 接口的 ADC 原始值与缩放系数 scale,并在另一个核上…...

基于OpenClaw构建开源项目与Docker镜像自动化监控方案
1. 项目概述 作为一个常年泡在开源社区和容器生态里的开发者,我深知“追新”的痛。今天这个项目发布了v2.0,明天那个镜像更新了安全补丁,手动去GitHub和Docker Hub一个个检查,效率低不说,还容易遗漏关键更新。为了解决…...

Hermit:项目级环境隔离工具,告别开发环境冲突
1. 项目概述:从“隐士”到现代开发者的效率革命如果你和我一样,常年与终端为伴,每天在多个项目、不同编程语言和工具链之间切换,那你一定对那种“环境错乱”的痛楚深有体会。前一秒还在用 Python 3.11 调试一个数据脚本࿰…...

基于Chrome DevTools协议实现AI与浏览器实时交互的实践指南
1. 项目概述:让AI与你的浏览器实时对话如果你正在探索如何让AI助手(比如Claude、GPTs或者你自己开发的智能体)不只是处理静态文本,而是能“看到”并操作你正在浏览的真实网页,那么你很可能已经接触过“浏览器自动化”这…...

为AI编程助手构建持久化项目记忆库:告别上下文遗忘,提升团队协作效率
1. 项目概述:为AI编程助手构建持久化项目记忆库如果你和我一样,每天都要和Claude Code、Cursor这些AI编程助手打交道,肯定遇到过这个烦人的问题:每次新开一个对话,AI就像得了失忆症,完全不记得你刚才在做什…...

DS4Windows终极指南:让PS4/PS5手柄在Windows上完美工作的完整教程
DS4Windows终极指南:让PS4/PS5手柄在Windows上完美工作的完整教程 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows DS4Windows是一款功能强大的开源工具,专门解决Pl…...

UE Viewer技术深度解析:如何逆向工程实现跨版本虚幻引擎资源查看
UE Viewer技术深度解析:如何逆向工程实现跨版本虚幻引擎资源查看 【免费下载链接】UEViewer Viewer and exporter for Unreal Engine 1-4 assets (UE Viewer). 项目地址: https://gitcode.com/gh_mirrors/ue/UEViewer UE Viewer(又称Umodel&#…...

Flutter+开源鸿蒙实战|城市共享驿站智能存取系统 Day6 全局UI精细化美化+通用组件封装+反馈设置模块+隐私弹窗+鸿蒙打包签名适配+项目整体重构
Flutter开源鸿蒙实战|城市共享驿站智能存取系统 Day6 全局UI精细化美化通用组件封装反馈设置模块隐私弹窗鸿蒙打包签名适配项目整体重构 欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net <!-- Schema.org 结构化数据 --> &…...

秋招编程面试,应届生必备的面试技巧,通过率直接翻倍
文章目录前言一、2026秋招编程面试新趋势:别再用老方法准备,踩坑就出局1.1 八股文不再是核心,底层理解才是硬通货1.2 代码手撕重思路轻结果,工程思维成加分项1.3 项目经历拒绝烂大街,真实落地细节把控是关键二、简历优…...

Qt QColumnView实战:手把手教你打造一个macOS Finder风格的文件浏览器
Qt QColumnView实战:从零构建macOS风格文件浏览器 在桌面应用开发中,文件浏览器的实现一直是开发者面临的经典挑战。传统方案往往采用QTreeView或QListView,但它们难以还原macOS Finder那种优雅的列式导航体验。这正是QColumnView的用武之地—…...