【大虾送书第六期】搞懂大模型的智能基因,RLHF系统设计关键问答
目录
✨1、RLHF是什么?
✨2、RLHF适用于哪些任务?
✨3、RLHF和其他构建奖励模型的方法相比有何优劣?
✨4、什么样的人类反馈才是好的反馈
✨5、RLHF算法有哪些类别,各有什么优缺点?
✨6、RLHF采用人类反馈会带来哪些局限?
✨7、如何降低人类反馈带来的负面影响?
✨8、文末福利
🦐博客主页:大虾好吃吗的博客
🦐专栏地址:免费送书活动专栏地址
RLHF(Reinforcement Learning with Human Feedback,人类反馈强化学习)虽是热门概念,并非包治百病的万用仙丹。本问答探讨RLHF的适用范围、优缺点和可能遇到的问题,供RLHF系统设计者参考。

1、RLHF是什么?
强化学习利用奖励信号训练智能体。有些任务并没有自带能给出奖励信号的环境,也没有现成的生成奖励信号的方法。为此,可以搭建奖励模型来提供奖励信号。在搭建奖励模型时,可以用数据驱动的机器学习方法来训练奖励模型,并且由人类提供数据。我们把这样的利用人类提供的反馈数据来训练奖励模型以用于强化学习的系统称为人类反馈强化学习,示意图如下。
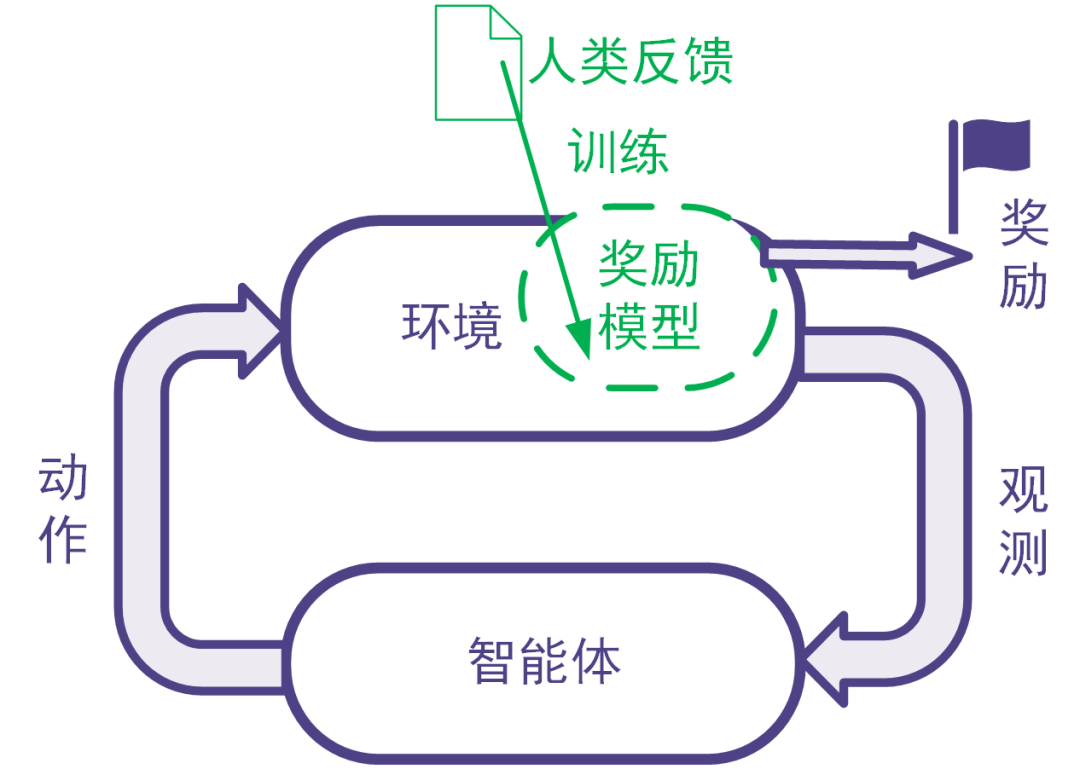
图: 人类反馈强化学习:用人类反馈的数据训练奖励模型,用奖励模型生成奖励信号
2、RLHF适用于哪些任务?
RLHF适合于同时满足下面所有条件的任务:
要解决的任务是一个强化学习任务,但是没有现成的奖励信号并且奖励信号的确定方式事先不知道。为了训练强化学习智能体,考虑构建奖励模型来得到奖励信号。
反例:比如电动游戏有游戏得分,那样的游戏程序能够给奖励信号,那我们直接用游戏程序反馈即可,不需要人类反馈。
反例:某些系统奖励信号的确定方式是已知的,比如交易系统的奖励信号可以由赚到的钱完全确定。这时直接可以用已知的数学表达式确定奖励信号,不需要人工反馈。不采用人类反馈的数据难以构建合适的奖励模型,而且人类的反馈可以帮助得到合适的奖励模型,并且人类来提供反馈可以在合理的代价(包括成本代价、时间代价等)内得到。如果用人类反馈得到数据与其他方法采集得到数据相比不具有优势,那么就没有必要让人类来反馈。
3、RLHF和其他构建奖励模型的方法相比有何优劣?
奖励模型可以人工指定,也可以通过有监督模型、逆强化学习等机器学习方法来学习。RLHF使用机器学习方法学习奖励模型,并且在学习过程中采用人类给出的反馈。
比较人工指定奖励模型与采用机器学习方法学习奖励模型的优劣:这与对一般的机器学习优劣的讨论相同。机器学习方法的优点包括不需要太多领域知识、能够处理非常复杂的问题、能够处理快速大量的高维数据、能够随着数据增大提升精度等等。机器学习算法的缺陷包括其训练和使用需要数据时间空间电力等资源、模型和输出的解释型可能不好、模型可能有缺陷、覆盖范围不够或是被攻击(比如大模型里的提示词注入)。
比较采用人工反馈数据和采用非人工反馈数据的优劣:人工反馈往往更费时费力,并且不同人在不同时候的表现可能不一致,并且人还会有意无意地犯错,或是人类反馈的结果还不如用其他方法生成数据来的有效,等等。我们在后文会详细探讨人工反馈的局限性。采用机器收集数据等非人工反馈数据则对收集的数据类型有局限性。有些数据只能靠人类收集,或是用机器难以收集。这样的数据包括是主观的、人文的数据(比如判断艺术作品的艺术性),或是某些机器还做不了的事情(比如玩一个AI暂时还不如人类的游戏)。
4、什么样的人类反馈才是好的反馈
好的反馈需要够用:反馈数据可以用来学成奖励模型,并且数据足够正确、量足够大、覆盖足够全面,使得奖励模型足够好,进而在后续的强化学习中得到令人满意的智能体。
这个部分涉及的评价指标包括:对数据本身的评价指标(正确性、数据量、覆盖率、一致性),对奖励模型及其训练过程的评价指标、对强化学习训练过程和训练得到的智能体的评价指标。好的反馈需要是可得的反馈。反馈需要可以在合理的时间花费和金钱花费的情况下得到,并且在成本可控的同时不会引发其他风险(如法律上的风险)。
涉及的评价指标包括:数据准备时间、数据准备涉及的人员数量、数据准备成本、是否引发其他风险的判断。
5、RLHF算法有哪些类别,各有什么优缺点?
RLHF算法有以下两大类:用监督学习的思路训练奖励模型的RLHF、用逆强化学习的思路训练奖励模型的RLHF。
1. 在用监督学习的思路训练奖励模型的RLHF系统中,人类的反馈是奖励信号或是奖励信号的衍生量(如奖励信号的排序)。
直接反馈奖励信号和反馈奖励信号衍生量各有优缺点。这个优点在于获得奖励参考值后可以直接把它用作有监督学习的标签。缺点在于不同人在不同时候给出的奖励信号可能不一致,甚至矛盾。反馈奖励信号的衍生量,比如奖励模型输入的比较或排序。有些任务给出评价一致的奖励值有困难,但是比较大小容易得多。但是没有密集程度的信息。在大量类似情况导致某部分奖励对应的样本过于密集的情况下,甚至可能不收敛。
一般认为,采用比较类型的反馈可以得到更好的性能中位数,但是并不能得到更好的性能平均值。
2. 在用逆强化学习的思路训练奖励模型的RLHF系统中,人类的反馈并不是奖励信号,而是使得奖励更大的奖励模型输入。即人类给出了较为正确的数量、文本、分类、物理动作等,告诉奖励模型在这时候奖励应该比较大。这其实就是逆强化学习的思想。
这种方法与用监督学习训练奖励模型的RLHF相比,其优点在于,训练奖励模型的样本点不再拘泥于系统给出的需要评判的样本。因为系统给出的需要评估奖励的样本可能具有局限性(因为系统没有找到最优的区间)。
在系统搭建初期,还可以将用户提供的参考答案用于把最初的强化学习问题转化成模仿学习问题。
这类设计还可以根据反馈的类型进一步分类,一类是让人类独立给出专家意见,另一类是在让人类在已有数据的基础上进行改进。让人类提供意见就类似于让人类提供模仿学习里的专家策略(当然可能略有不同,毕竟奖励模型的输入不只有动作)。让用户在已有的参考内容上修改可以减少人类每个标注的成本,但是已有的参考内容可能会干扰到人类的独立判断(这个干扰可能是正面的也可能是负面的)。
6、RLHF采用人类反馈会带来哪些局限?
前面已经提到,人类反馈可能更费时费力,并且不一定能够保证准确性和一致性。除此之外,下面几点会导致奖励模型不完整不正确,导致后续强化学习训练得到的智能体行为不能令人满意。
1.提供人类反馈的人群可能有偏见或局限性。
这个问题和数理统计里的对样本进行抽样方法可能遇到的问题类型。为RLHF系统提供反馈的人群可能并不是最佳的人群。有的时候出于成本、可得性等因素,会选择人力成本低的团队,但是这样的团队可能在专业度不够,或是有着不同的法律、道德和宗教观念,包括歧视性信息。反馈人中可能有恶意者,会提供有误导性的反馈。
2.人的决策可能没有机器决策那么高明。
在一些问题上,机器可以比人做的更好,比如对于象棋围棋等棋盘游戏,真人就比不过人工智能程序。在一些问题上,人能够处理的信息没有数据驱动的程序处理的信息全面。比如对于自动驾驶的应用,人类只能根据二维画面和声音进行决策,而程序能够处理连续时间内三维空间的信息。所以在理论上人类反馈的质量是不如程序的。
3.没有将提供反馈的人的特征引入到系统。
每个人都是独一无二的:每个人有自己的成长环境、宗教信仰、道德观念、学习和工作经历、知识储备等,我们不可能把每个人的所有特征都引入到系统。在这种情况下,如果忽略不同的人之间在某个特征维度上的差别,那么就会损失到许多有效信息,导致奖励模型性能下降。
以大规模语言模型为例,用户可以通过提示工程指定模型以某种特定的角色或沟通方式来沟通,比如有时要求语言模型的输出文字更有礼貌更客套多奉承套,有时需要输出文字内容掷地有声言之有物少客套;有时要求输出文字更有创造性,有时要求输出文字尊重事实更严谨;有时要求输出简洁扼要,有时要求输出详尽完备提供更多细节;有时要求输出中立客观仅在纯自然科学范围内讨论,有时要求输出多考虑人文社会的环境背景。而提供反馈数据的人的不同身份背景和沟通习惯可能正好对应于不同情况下的输出要求。这种情况下,反馈人的特性就非常重要。
4.人性可能导致数据集不完美。
比如语言模型可能会通过拍马屁、戴高帽等行为获得高分评价,但是这样的高分评价可能并没有真正解决问题,有违系统设计的初衷。看似得分很高,但是高得分可能是通过避免争议性话题或是拍马屁拍出来的,而不是真正解决了需要解决问题,没有达到系统设计的初衷。
此外,人类提供反馈还有其他非技术上面的风险,比如泄密等安全性风险、监管法律风险等。
7、如何降低人类反馈带来的负面影响?
针对人类反馈费时费力且可能导致奖励模型不完整不正确的问题,可以在收集人类反馈数据的同时就训练奖励模型、训练智能体,并全面评估奖励模型和智能体,以便于尽早发现人类反馈的缺陷。发现缺陷后,及时进行调整。
针对人类反馈中出现的反馈质量问题以及错误反馈,可以对人类反馈进行校验和审计,如引入已知奖励的校验样本来校验人类反馈的质量,或为同一样本多次索取反馈并比较多次反馈的结果等。
针对反馈人的选择不当的问题,可以在有效控制人力成本的基础上,采用科学的方法选定提供反馈的人。可以参考数理统计里的抽样方法,如分层抽样、整群抽样等,使得反馈人群更加合理。
对于反馈数据中未包括反馈人特征导致奖励模型不够好的问题,可以收集反馈人的特征,并将这些特征用于奖励模型的训练。比如,在大规模语言模型的训练中可以记录反馈人的职业背景(如律师、医生等),并在训练奖励模型时加以考虑。当用户要求智能体像律师一样工作时,更应该利用由律师提供的数据学成的那部分奖励模型来提供奖励信号;当用户要求智能体像医生一样工作时,更应该利用由医生提供的数据学成的那部分奖励模型来提供奖励信号。
另外,在整个系统的实施过程中,可以征求专业人士意见,以减小其中法律和安全风险。
延伸阅读
1、理论完备,涵盖强化学习主干理论和常见算法,带你参透ChatGPT技术要点;
2、实战性强,每章都有编程案例,深度强化学习算法提供TenorFlow和PyTorch对照实现;
3、配套丰富,逐章提供知识点总结,章后习题形式丰富多样。还有Gym源码解读、开发环境搭建指南、习题答案等在线资源助力自学。
本文内容摘编自《强化学习:原理与Python实战》,经出版方授权发布。(ISBN:978-7-111-72891-7)
8、文末福利
- 本次送书三本
- 活动时间:截止到2023-08-25 10:00
- 参与方式:关注博主文章下方公众号,编辑发送信息(第六期)点击链接即可抽
相关文章:

【大虾送书第六期】搞懂大模型的智能基因,RLHF系统设计关键问答
目录 ✨1、RLHF是什么? ✨2、RLHF适用于哪些任务? ✨3、RLHF和其他构建奖励模型的方法相比有何优劣? ✨4、什么样的人类反馈才是好的反馈 ✨5、RLHF算法有哪些类别,各有什么优缺点? ✨6、RLHF采用人类反馈会带来哪些局…...

超越函数界限:探索JavaScript函数的无限可能
🎬 岸边的风:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 📚 前言 📘 1. 函数的基本概念 📟 1.1 函数的定义和调用 📟 1.2 …...
PHP实现轻量级WEB服务器接收HTTP提交的RFID刷卡信息并回应驱动读卡器显示播报语音
本示例使用的读卡器:RFID网络WIFI无线TCP/UDP/HTTP可编程二次开发读卡器POE供电语音-淘宝网 (taobao.com) <?php mb_http_output(utf-8); $port88; $socket socket_create(AF_INET, SOCK_STREAM, SOL_TCP); $bool socket_bind($socket, "0.0.0.0",…...

Neo4j之with基础
WITH 语句在 Cypher 查询中用于将之前的查询结果传递给后续的查询操作。它可以用来控制查询的流程,并且常常与其他语句如 MATCH、RETURN、CREATE、DELETE 等一起使用。以下是一些常用的示例和解释: 基本用法: MATCH (p:Person) WITH p RETU…...

60页数字政府智慧政务大数据资源平台项目可研方案PPT
导读:原文《60页数字政府智慧政务大数据资源平台项目可研方案PPT》(获取来源见文尾),本文精选其中精华及架构部分,逻辑清晰、内容完整,为快速形成售前方案提供参考。 项目需求分析 项目建设原则和基本策略…...

循环神经网络RNN完全解析:从基础理论到PyTorch实战
目录 一、循环神经网络全解1.1 什么是循环神经网络网络结构工作原理数学模型RNN的优缺点总结 1.2 循环神经网络的工作原理RNN的时间展开数学表述信息流动实现示例梯度问题:梯度消失和爆炸总结 1.3 循环神经网络的应用场景文本分析与生成1.3.1 自然语言处理1.3.2 机器…...

【SA8295P 源码分析】52 - 答疑之 QNX 创建镜像、Android修改CMDLINE
【SA8295P 源码分析】52 - 答疑之 QNX 创建镜像、Android修改CMDLINE 一、QNX 侧创建 img 镜像二、QNX 侧指定只编译某一个版本三、Android定制修改selinux权限,user版本采用enforcing,userdebug版本permissive系列文章汇总见:《【SA8295P 源码分析】00 - 系列文章链接汇总》…...

网络安全法律
立法的必要性:网络渗透,网络入侵,网络诈骗,网上钓鱼侵犯知识产权,宣传恐怖主义,极端主义等伤害共鸣利益的行为越发猖狂 信息系统运维安全管理规定(范文)| 资料 过程: 14-16 草案初…...
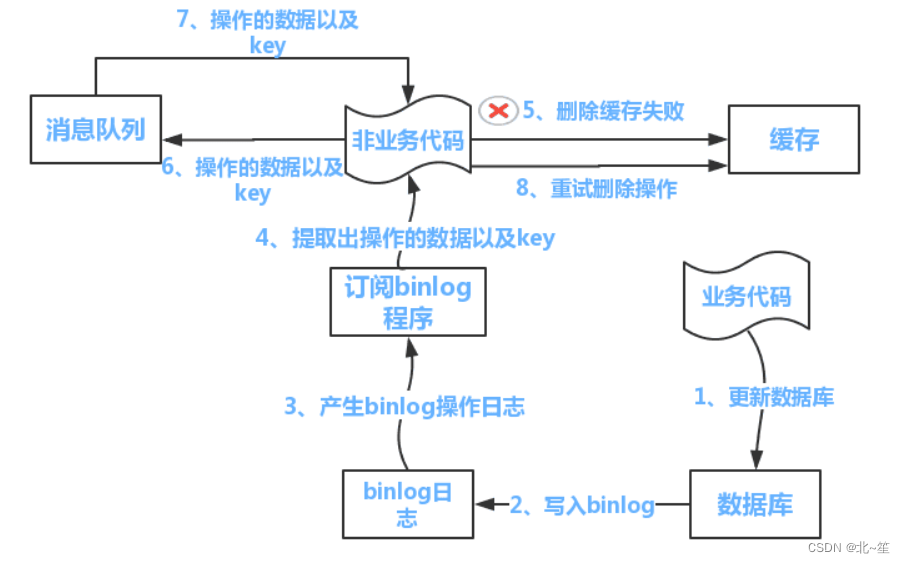
Redis缓存问题(穿透, 击穿, 雪崩, 污染, 一致性)
目录 1.什么是Redis缓存问题? 2.缓存穿透 3.缓存击穿 4.缓存雪崩 5.缓存污染(或满了) 5.1 最大缓存设置多大 5.2 缓存淘汰策略 6.数据库和缓存一致性 6.1 4种相关模式 6.2 方案:队列重试机制 6.3 方案:异步更新缓…...

网络时代拟态环境的复杂化
信息在网络上的制作、编码、传播机制和传统媒介有本质的区别,即传播者和 受传者的角色交叉,而且互联网本身可看作另一个有别于现实环境的虚拟世界,因 此网络媒介所营造出的拟态环境在一定程度上独立于传统大众传播的拟态环境。 一个是传统…...

湘潭大学 湘大 XTU OJ 1055 整数分类 题解(非常详细)
链接 整数分类 题目 Description 按照下面方法对整数x进行分类:如果x是一个个位数,则x属于x类;否则将x的各位上的数码累加,得到一个新的x,依次迭代,可以得到x的所属类。比如说24,246&#…...

什么是视频的编码和解码
这段描述中,视频解码能力和视频编码能力指的是不同的处理过程。视频解码是将压缩过的视频数据解开并还原为可播放的视频流,而视频编码是将原始视频数据压缩成更小的尺寸,以减少存储空间和传输带宽。在这个上下文中,解码能力和编码…...

LeetCode 2681. Power of Heroes【排序,数学,贡献法】2060
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...
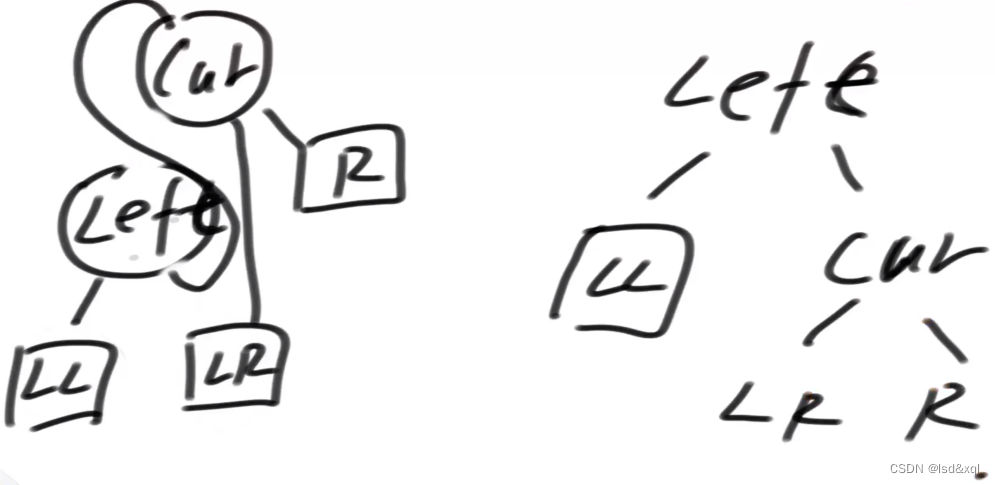
AVL树的讲解
算法拾遗三十八AVL树 AVL树AVL树平衡性AVL树加入节点AVL删除节点AVL树代码 AVL树 AVL树具有最严苛的平衡性,(增、删、改、查)时间复杂度为O(logN),AVL树任何一个节点,左树的高度和右树的高度差…...

Unity 之 Input类
文章目录 总述具体介绍 总述 Input 类是 Unity 中用于处理用户输入的重要工具,它允许您获取来自键盘、鼠标、触摸屏和控制器等设备的输入数据。通过 Input 类,您可以轻松地检测按键、鼠标点击、鼠标移动、触摸、控制器按钮等用户输入事件。以下是关于 I…...
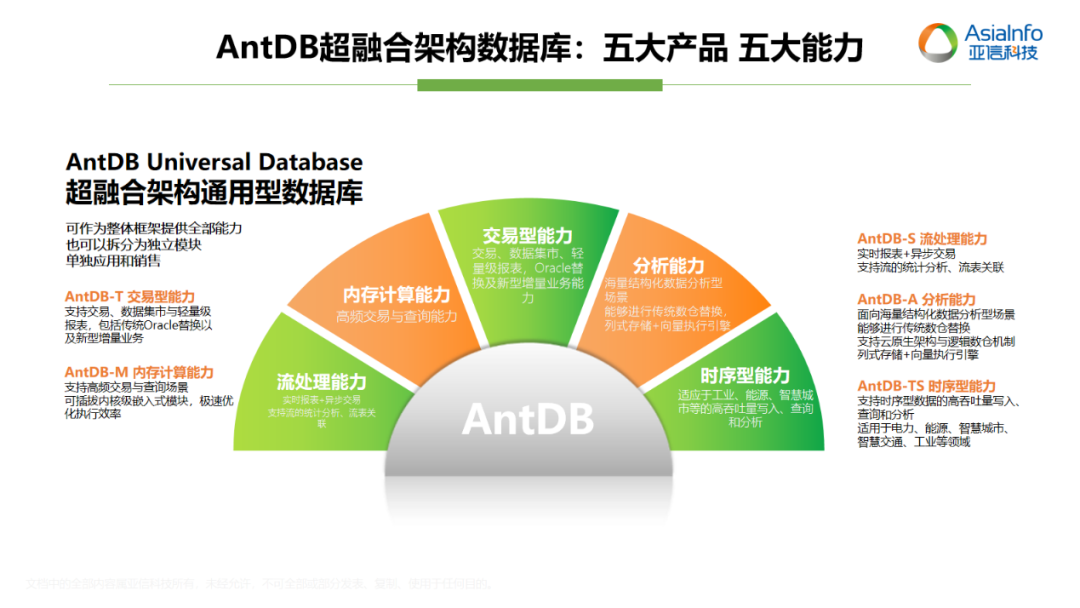
亚信科技AntDB数据库连年入选《中国DBMS市场指南》代表厂商
近日,全球权威ICT研究与顾问咨询公司Gartner发布了2023年《Market Guide for DBMS, China》(即“中国DBMS市场指南”),该指南从市场份额、技术创新、研发投入等维度对DBMS供应商进行了调研。亚信科技是领先的数智化全栈能力提供商…...
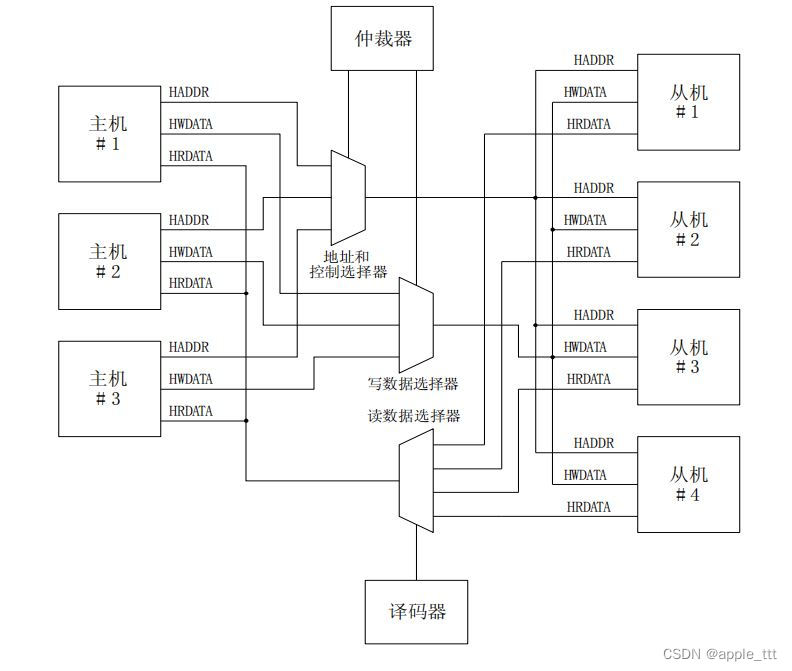
AMBA总线协议(3)——AHB(一)
目录 一、前言 二、什么是AHB总线 1、概述 2、一个典型的基于AHB总线的微处理器架构 3、基本的 AHB 传送特性 三、AMBA AHB总线互联 四、小结 一、前言 在之前的文章中我们初步的了解了一下AMBA总线中AHB,APB,AXI的信号线及其功能,从本文开始我们…...

Git commit与pull的先后顺序
Git commit与pull的先后顺序_git先pull再commit_Mordor Java Girl的博客-CSDN博客 编辑yucoang2020.04.21 回复 28 先pull再commit的话, 你的commit也就不再纯粹了. 这一个commit不再是"你所编辑的xxx功能, 而是"别人所编辑的你所编辑的xxx". 我认为提交历…...
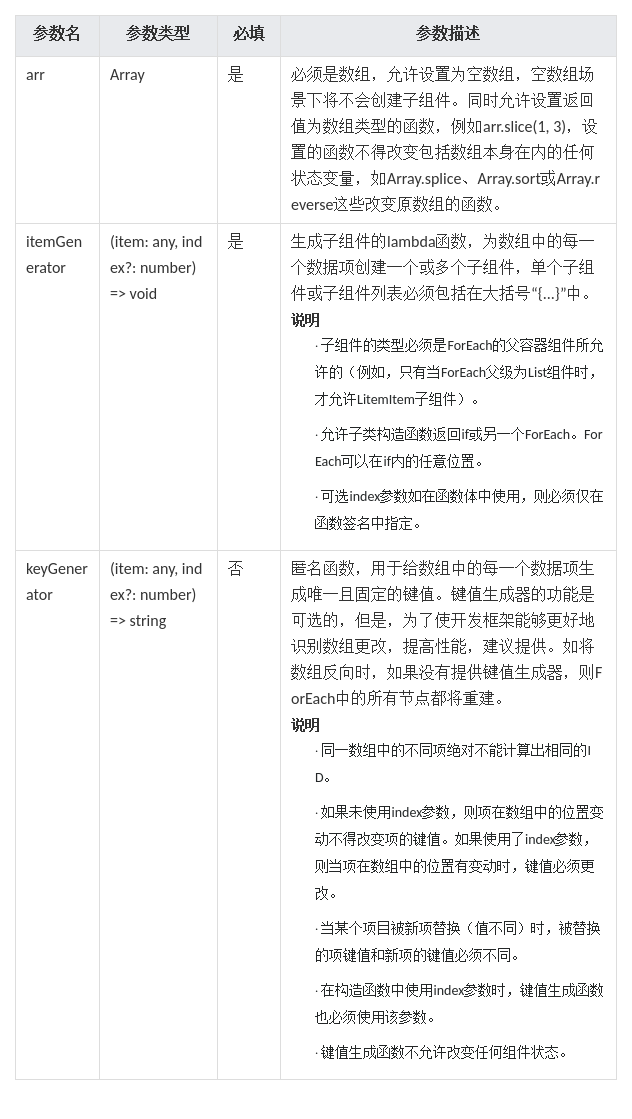
HarmonyOS/OpenHarmony应用开发-ArkTS语言渲染控制ForEach循环渲染
ForEach基于数组类型数据执行循环渲染。说明,从API version 9开始,该接口支持在ArkTS卡片中使用。 一、接口描述 ForEach(arr: any[], itemGenerator: (item: any, index?: number) > void,keyGenerator?: (item: any, index?: number) > stri…...

Powered by Paraverse | 平行云助力彼真科技打造演出“新物种”
01 怎么看待虚拟演出 彼真科技 我们怎么看待虚拟演出? 虚拟演出给音乐人或者音乐行业带来了哪些新的机会?通过呈现一场高标准的虚拟演出,我们的能力延伸点在哪里? 先说一下我们认知里的虚拟演出的本质: 音乐演出是一…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...