Hive 核心知识点灵魂 16 问
本文目录
- No1. 请谈一下 Hive 的特点
- No2. Hive 底层与数据库交互原理?
- No3. Hive 的 HSQL 转换为 MapReduce 的过程?
- No4. Hive 的两张表关联,使用 MapReduce 怎么实现?
- No5. 请说明 hive 中 Sort By,Order By,Cluster By,Distrbute By 各代表什么意思?
- No6. 写出 hive 中 split、coalesce 及 collect_list 函数的用法(可举例)?
- No7. Hive 有哪些方式保存元数据,各有哪些特点?
- No.8 内部表和外部表的区别,以及各自的使用场景
- No9. Hive 中的压缩格式 TextFile、SequenceFile、RCfile 、ORCfile 各有什么区别 ?
- 1. TextFile
- 2. SequenceFile
- 3. RCFile
- 4. ORCFile
- No10. 所有的 Hive 任务都会有 MapReduce 的执行吗?
- No11. Hive 的函数:UDF、UDAF、UDTF 的区别?
- No12. 说说对 Hive 桶表的理解?
- No13. Hive 表关联查询,如何解决数据倾斜的问题?
- No14. 了解过 Hive 的哪些窗口函数
- No.15 小文件是如何产生的,解决方案
- No.16 Tez 引擎优点
1请谈一下 Hive 的特点
hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 sql 查询功能,可以将 sql 语句转换为MapReduce 任务进行运行。
其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开发专门的 MapReduce 应用,十分适合数据仓库的统计分析,但是 Hive 不支持实时查询。
2Hive 底层与数据库交互原理?
由于 Hive 的元数据可能要面临不断地更新、修改和读取操作,所以它显然不适合使用 Hadoop 文件系统进行存储。
目前 Hive 将元数据存储在 RDBMS 中,比如存储在 MySQL、Derby 中。元数据信息包括:存在的表、表的列、权限和更多的其他信息。
3Hive 的 HSQL 转换为 MapReduce 的过程?
HiveSQL -> AST(抽象语法树) -> QB(查询块) -> OperatorTree(操作树)-> 优化后的操作树 -> mapreduce 任务树 -> 优化后的 mapreduce 任务树
过程描述如下:
SQL Parser:Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将 SQL 转化为抽象语法树 AST Tree;
Semantic Analyzer:遍历 AST Tree,抽象出查询的基本组成单元 QueryBlock;
Logical plan:遍历 QueryBlock,翻译为执行操作树 OperatorTree;
Logical plan optimizer: 逻辑层优化器进行 OperatorTree 变换,合并不必要的 ReduceSinkOperator,减少 shuffle 数据量;
Physical plan:遍历 OperatorTree,翻译为 MapReduce 任务;
Logical plan optimizer:物理层优化器进行 MapReduce 任务的变换,生成最终的执行计划;
4Hive 的两张表关联,使用 MapReduce 怎么实现?
如果其中有一张表为小表,直接使用 map 端 join 的方式(map 端加载小表)进行聚合。
如果两张都是大表,例如分别是客户表和订单表 。那么采用联合 key,联合 key 的第一个组成部分是 join on 中的公共字段,第二部分是一个 flag,0 代表表 A,1 代表表 B,由此让 Reduce 区分客户信息和订单信息;在 Mapper 中同时处理两张表的信息,将 join on 公共字段相同的数据划分到同一个分区中,进而传递到一个 Reduce 中,然后在 Reduce 中实现聚合。
5请说明 hive 中 Sort By,Order By,Cluster By,Distrbute By 各代表什么意思?
order by:会对输入做全局排序,因此只有一个 reducer(多个 reducer 无法保证全局有序)。只有一个 reducer,会导致当输入规模较大时,需要较长的计算时间 。
sort by:分区内有序,不是全局排序,其在数据进入 reducer 前完成排序
distribute by:按照指定的字段对数据进行划分输出到不同的 reduce 中 ,结合 sory by 使用
cluster by:当Distribute by和Sorts by字段相同时,可以使用Cluster by方式。Cluster by除了具有Distribute by的功能外还兼具Sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
6写出 hive 中 split、coalesce 及 collect_list 函数的用法(可举例)?
split 将字符串转化为数组,即:split('a,b,c,d' , ',') ==> ["a","b","c","d"]
coalesce(T v1, T v2, …) 返回参数中的第一个非空值;如果所有值都为 NULL,那么返回 NULL。
collect_list 列出该字段所有的值,不去重 => select collect_list(id) from table
7Hive 有哪些方式保存元数据,各有哪些特点?
Hive 支持三种不同的元存储服务器,分别为:内嵌式元存储服务器、本地元存储服务器、远程元存储服务器,每种存储方式使用不同的配置参数 。
内嵌式元存储主要用于单元测试,在该模式下每次只有一个进程可以连接到元存储,Derby 是内嵌式元存储的默认数据库 。
在本地模式下,每个 Hive 客户端都会打开到数据存储的连接并在该连接上请求 SQL 查询 。
在远程模式下,所有的 Hive 客户端都将打开一个到元数据服务器的连接,该服务器依次查询元数据,元数据服务器和客户端之间使用 Thrift 协议通信 。
8内部表和外部表的区别,以及各自的使用场景
- 内部表
如果 Hive 中没有特别指定,则默认创建的表都是管理表,也称内部表。由Hive负责管理表中的数据,管理表不共享数据。删除管理表时,会删除管理表中的数据和元数据信息 。
- 外部表
当一份数据需要被共享时,可以创建一个外部表指向这份数据 。
删除该表并不会删除掉原始数据,删除的是表的元数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据 。当表结构或者分区数发生变化时,需要进行一步修复的操作。
9Hive 中的压缩格式 TextFile、SequenceFile、RCfile 、ORCfile 各有什么区别 ?
1. TextFile
默认格式,存储方式为行存储,数据不做压缩,磁盘开销大,数据解析开销大。可结合 Gzip、Bzip2 使用(系统自动检查,执行查询时自动解压),但使用 这种方式,压缩后的文件不支持 split,Hive 不会对数据进行切分,从而无法对数据进行并行操作。并且在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比 SequenceFile 高几十倍 。
2. SequenceFile
SequenceFile 是 Hadoop API 提供的一种二进制文件支持,存储方式为行存储,其具有使用方便、可分割、可压缩的特点。
SequenceFile 支持三种压缩选择:NONE,RECORD,BLOCK。Record 压缩率低,一般建议使用 BLOCK 压缩。
优势是文件和 hadoop api 中的 MapFile 是相互兼容的 。
3、RCFile
存储方式:数据按行分块,每块按列存储。结合了行存储和列存储的优点:
首先,RCFile 保证同一行的数据位于同一节点,因此元组重构的开销很低 ;
其次,像列存储一样,RCFile 能够利用列维度的数据压缩,并且能跳过不必要的列读取;
4、ORCFile
存储方式:数据按行分块 每块按照列存储。
压缩快、快速列存取。
效率比 rcfile 高,是 rcfile 的改良版本。
总结:
相比 TEXTFILE 和 SEQUENCEFILE,RCFILE 由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。
数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE 相比其余两种格式具有较明显的优势。
10所有的 Hive 任务都会有 MapReduce 的执行吗?
不是,从 Hive0.10.0 版本开始,对于简单的不需要聚合的类似 SELECT from LIMIT n 语句,不需要起 MapReduce job,直接通过 Fetch task 获取数据。
11Hive 的函数:UDF、UDAF、UDTF 的区别?
UDF:单行进入,单行输出
UDAF:多行进入,单行输出
UDTF:单行输入,多行输出
12说说对 Hive 桶表的理解?
桶表是对数据进行哈希取值,然后放到不同文件中存储 。
数据加载到桶表时,会对字段取 hash 值,然后与桶的数量取模。把数据放到对应的文件中。物理上,每个桶就是表(或分区)目录里的一个文件,一个作业产生的桶(输出文件)和 reduce 任务个数相同 。
桶表专门用于抽样查询,是很专业性的,不是日常用来存储数据的表,需要抽样查询时,才创建和使用桶表。
13 Hive 表关联查询,如何解决数据倾斜的问题?
定位原因:
map 输出数据按 key Hash 的分配到 reduce 中,由于 key 分布不均匀、业务数据本身的特点、建表时考虑不周、某些 SQL 语句本身就有数据倾斜等原因造成的 reduce 上的数据量差异过大。
如何避免:
对于 key 为空产生的数据倾斜,可以对其赋予一个随机值
解决方案:
(1)参数调节:
hive.map.aggr = true
hive.groupby.skewindata=true
有数据倾斜的时候进行负载均衡,当选项设定位 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;
第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作
(2)SQL语句调节:
① 选用 join key 分布最均匀的表作为驱动表。做好列裁剪和 filter 操作,以达到两表做 join 的时候,数据量相对变小的效果。
② 大小表 Join:使用 map join 让小的维度表(1000 条以下的记录条数)先进内存。在map 端完成 reduce。
③ 大表 Join 大表:把空值的 key 变成一个字符串加上随机数,把倾斜的数据分到不同的 reduce 上,由于 null 值关联不上,处理后并不影响最终结果。
④ count distinct 大量相同特殊值:count distinct 时,将值为空的情况单独处理,如果是计算 count distinct, 可以不用处理,直接过滤,在最后结果中加 1。如果还有其他计算,需要进行 group by,可以先将值为空的记录单独处理,再和其他计算结果进行 union。
更多调优技巧可以 关注 大数据梦想家 公众号,后台回复 “hive调优” 即可解锁 “hive 性能调优指南” .pdf
14了解过 Hive 的哪些窗口函数
1)Rank
(1)RANK() 排序相同时会重复,总数不会变
(2)DENSE_RANK() 排序相同时会重复,总数会减少
(3)ROW_NUMBER() 会根据顺序计算
2) OVER()
指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而 变化
(1)CURRENT ROW:当前行
(2) n PRECEDING:往前 n 行数据
(3) n FOLLOWING:往后 n 行数据
(4) UNBOUNDED :起 点 , UNBOUNDED PRECEDING 表 示 从 前 面 的 起 点 , UNBOUNDED FOLLOWING 表示到后面的终点
(5) LAG(col,n) :往前第 n 行数据
(6) LEAD(col,n):往后第 n 行数据
(7) NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从 1 开始,对于每一行,NTILE 返回此行所属的组的编号。注意:n 必须为 int 类型。
15小文件是如何产生的,解决方案
定位原因:
(1)动态分区插入数据,产生大量的小文件,从而导致 map 数量剧增;
(2)reduce 数量越多,小文件也越多(reduce 的个数和输出文件是对应的)
(3)数据源本身就包含大量的小文件。
解决方案:
(1)在 Map 执行前合并小文件,减少 Map 数: CombineHiveInputFormat 具有对小文件 进行合并的功能(系统默认的格式)。HiveInputFormat 没有对小文件合并功能。
(2)merge
SET hive.merge.mapfiles = true;
-- 默认 true,在 map-only 任务结束时合并 小文件
SET hive.merge.mapredfiles = true;
-- 默认 false,在 map-reduce 任务结 束时合并小文件
SET hive.merge.size.per.task = 268435456;
-- 默认 256M
SET hive.merge.smallfiles.avgsize = 16777216;
-- 当输出文件的平均大小 小于 16m 该值时,启动一个独立的 map-reduce 任务进行文件 merge
(3)开启 JVM 重用
set mapreduce.job.jvm.numtasks=10
16 Tez 引擎优点
Tez 可以将多个有依赖的作业转换为一个作业,这样只需写一次 HDFS,且中间节点较少,从而大大提升作业的计算性能。
Mr/tez/spark 区别:
Mr 引擎:多 job 串联,基于磁盘,落盘的地方比较多。虽然慢,但一定能跑出结果。一般处理,周、月、年指标 。
Spark 引擎:虽然在 Shuffle 过程中也落盘,但是并不是所有算子都需要 Shuffle,尤其 是多算子过程,中间过程不落盘 DAG 有向无环图。兼顾了可靠性和效率。一般处理天指标。
Tez 引擎:完全基于内存。注意:如果数据量特别大,慎重使用。容易 OOM。一般用于快速出结果,数据量比较小的场景。
相关文章:

Hive 核心知识点灵魂 16 问
本文目录 No1. 请谈一下 Hive 的特点No2. Hive 底层与数据库交互原理?No3. Hive 的 HSQL 转换为 MapReduce 的过程?No4. Hive 的两张表关联,使用 MapReduce 怎么实现?No5. 请说明 hive 中 Sort By,Order By࿰…...

聊聊探索式测试与敏捷实践
这是鼎叔的第五十二篇原创文章。行业大牛和刚毕业的小白,都可以进来聊聊。欢迎关注本专栏和微信公众号《敏捷测试转型》,大量原创思考文章陆续推出。探索式测试在敏捷测试象限中处于右上角,即面向业务且评价产品,这篇补充一下探索…...

社区宠物诊所管理系统
目录第一章概述 PAGEREF _Toc4474 \h 21.1引言 PAGEREF _Toc29664 \h 31.2开发背景 PAGEREF _Toc3873 \h 3第二章系统总体结构及开发 PAGEREF _Toc19895 \h 32.1系统的总体设计 PAGEREF _Toc6615 \h 32.2开发运行环境 PAGEREF _Toc13054 \h 3第三章数据库设计 PAGEREF _Toc2852…...

Vue项目创建首页发送axios请求
这是个全新的Vue项目,引入了ElementUI 将App.vue里的内容干掉,剩如下 然后下面的三个文件也可以删掉了 在views文件下新建Login.vue组件 到router目录下的index.js 那么现在的流程大概是这样子的 启动 写登陆页面 <template><div><el-form :ref"form"…...

Nginx
NginxNginxNginx可以从事的用途Nginx安装Nginx自带常用命令Nginx启动Nginx停止Nginx重启Nginx配置概要第一部分:全局块第二部分:events 块:第三部分:http块:Nginx Nginx是一个高性能的http和反向代理服务器࿰…...
2049. 统计最高分的节点数目
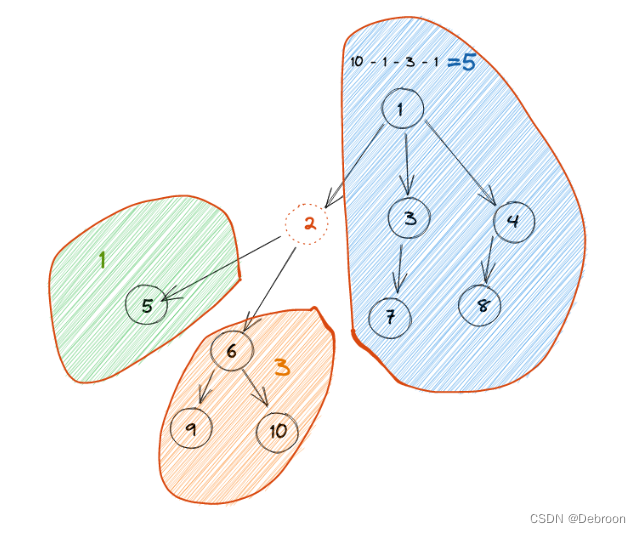
2049. 统计最高分的节点数目题目算法设计:深度优先搜索题目 传送门:https://leetcode.cn/problems/count-nodes-with-the-highest-score/ 算法设计:深度优先搜索 这题的核心是计算分数。 一个节点的分数 左子树节点数 右子树节点数 除自…...

Docker 架构简介
Docker 架构 Docker 包括三个基本概念: 镜像(Image):Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像 ubuntu:16.04 就包含了完整的一套 Ubuntu16.04 最小系统的 root 文件系统。容器&am…...
玄子Share-BCSP助学手册-JAVA开发
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b2gPyAnt-1676810001349)(./assets/%E7%8E%84%E5%AD%90Share%E4%B8%89%E7%89%88.jpg)] 玄子Share-BCSP助学手册-JAVA开发 前言: 此文为玄子,复习BCSP一二期后整理的文章&#x…...

利用React实现多个场景下的鼠标跟随框提示框
前言 鼠标跟随框的作用如下图所示,可以在前端页面上,为我们后续的鼠标操作进行提示说明,提升用户的体验。本文将通过多种方式去实现,从而满足不同场景下的需求。 实现原理 实现鼠标跟随框的原理很简单,就是监听鼠标在…...
【安全知识】——如何绕过cdn获取真实ip
作者名:白昼安全主页面链接: 主页传送门创作初心: 以后赚大钱座右铭: 不要让时代的悲哀成为你的悲哀专研方向: web安全,后渗透技术每日鸡汤: 现在的样子是你想要的吗?cdn简单来说就是…...
JavaScript内存泄露和垃圾回收机制
1、是什么?内存泄露(Memory leak)是在计算机科学中,由于疏忽或错误造成程序未能释放已经不再使用的内存。并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,导致在释放该段内…...

Kubernetes02:知识图谱
Kubernetes01:知识图谱 MESOS APACHE 分布式资源管理框架 2019-5 Twitter 》 Kubernetes Docker Swarm 2019-07 阿里云宣布 Docker Swarm 剔除 Kubernetes Google 10年容器化基础架构 borg Go语言 Borg 特点 轻量级:消耗资源小 开源 弹性伸缩 负载均…...
nginx-服务器banner泄漏风险
http { server_tokens off; # 隐藏Nginx版本号 .... }...
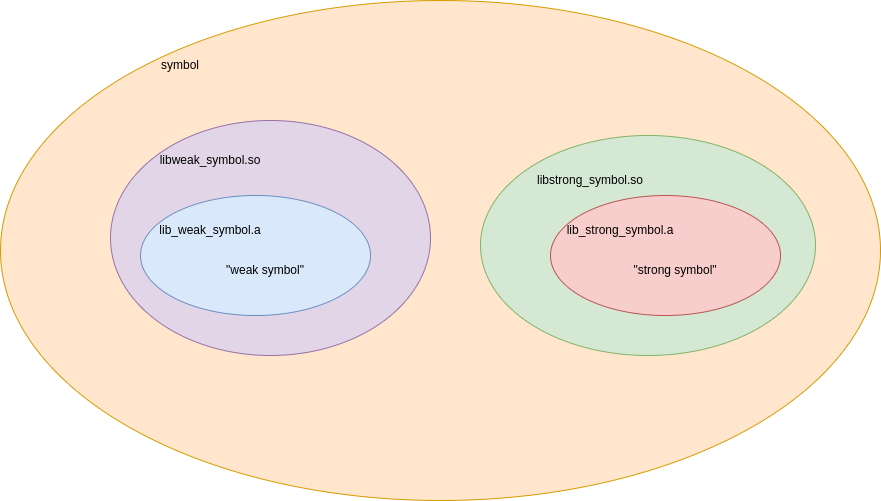
GCC 同名符号冲突解决办法
一、绪论 作为 C/C 的开发者,大多数都会清楚课本上动态库以及静态库的优缺点,在教科书上谈及到动态库的一个优点是可以节约磁盘和内存的空间,多个可执行程序通过动态库加载的方式共用一段代码段 ;而时至今日,再看看上…...

下一代视频编码技术2023
下一代视频编码技术 下面将从这两个角度来介绍华为云视频在下一代视频编码技术上的一些工作。这些技术得益于华为2012 媒体技术院全力支持。 2.1 下一代视频编码标准技术 从上图可以看出,下一代的视频编码标准大概分为三个阵营或者三个类型: 国际标准…...
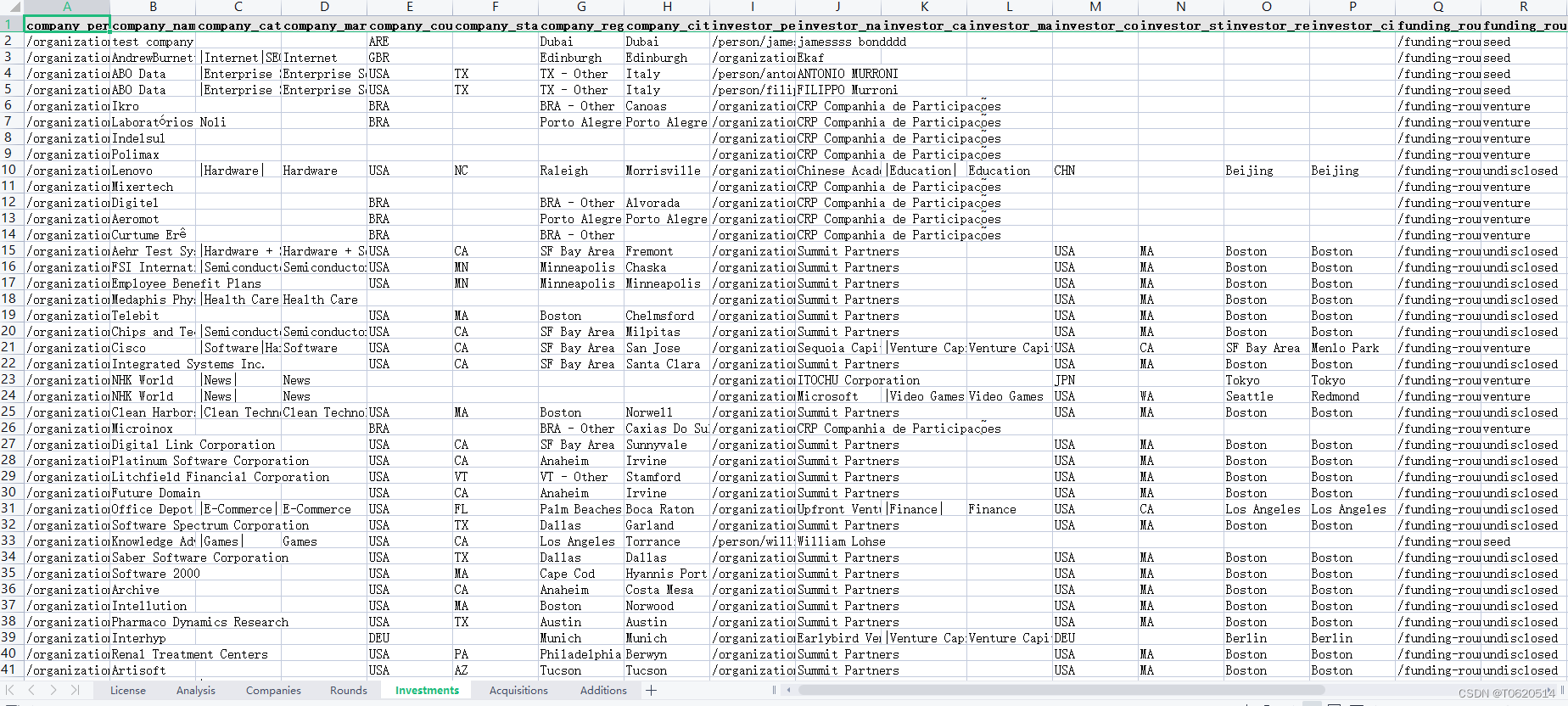
最新最全中小微企业研究数据:海量创业公司信息与获取投资信息(1985-2021年)
一、企业获取投资名单&资方信息 数据来源:搜企网、企查查、天眼查 时间跨度:1985年8月-2021年9月 区域范围:全国范围 数据字段:企业名称、时间、获得投资金额以及投资方信息 部分数据: DateCompany_nameUnit…...

springboot数据源浅析
DataSourceAutoConfiguration分析 SpringBoot有一个自动配置DataSourceAutoConfiguration 为数据源配置 /META-INF/spring.factories文件找到DataSourceAutoConfiguration配置类 一、先来看下DataSourceAutoConfiguration配置类生效的时机,观察源码发现 Configura…...

2022黑马Redis跟学笔记.实战篇(七)
2022黑马Redis跟学笔记.实战篇 七4.11.附近的店铺功能4.11.1. GEO数据结构的基本用法1. 附近商户-导入店铺数据到GEO4.11.2. 获取附近的店铺1. 附近商户-实现附近商户功能4.9. 签到功能4.9.1.BitMap原理1. 用户签到-BitMap功能演示4.9.2.实现签到功能4.9.3.实现补签功能4.9.4.统…...
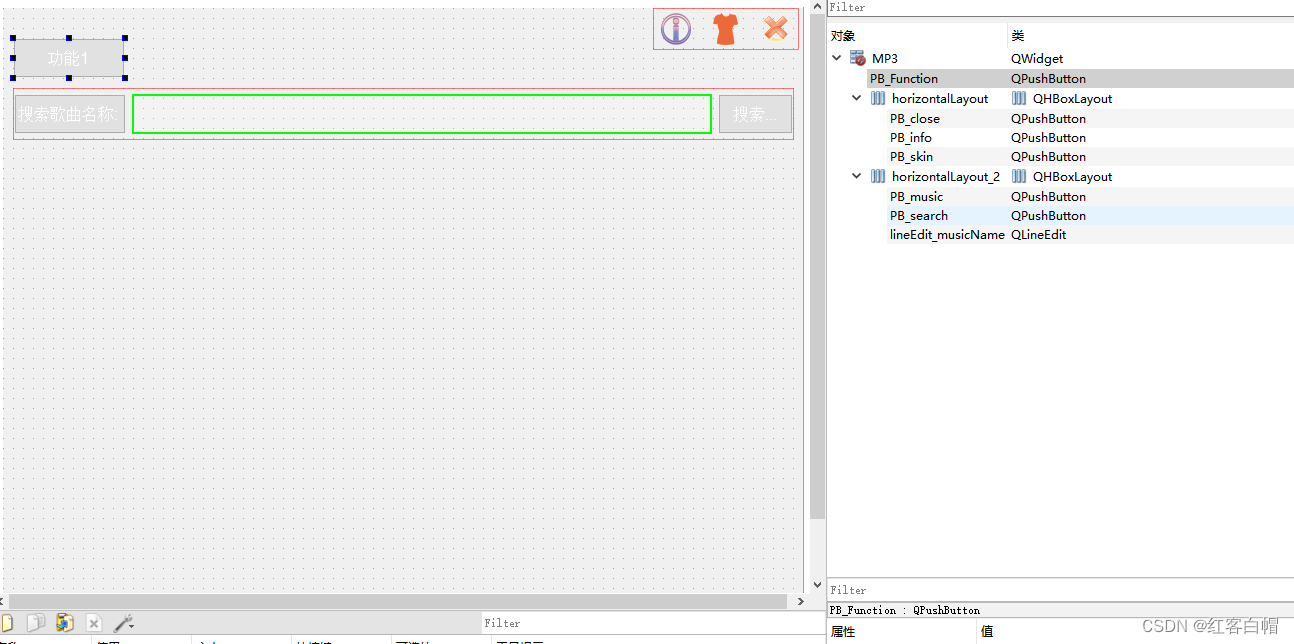
QT mp3音乐播放器实现框架,Qt鼠标事件,网络编程,QSqlite,Json解析,HTTP请求等
QT mp3音乐播放器实现框架,Qt鼠标事件,网络编程,QSqlite,Json解析,HTTP请求等框架搭建UI设计mp3.hmp3.cpp隐藏窗口标题 最大化 最小化 关闭框架搭建 .pro添加 # 网络 添加多媒体 数据库 QT network multimedia sql添加头…...
硬件学习 软件Cadence day04 PCB 封装绘制
1.文章内容: 1. 贴片式电容 PCB 封装绘制 (型号 c0603 ) 2. 贴片式电阻 PCB 封装绘制 (型号 r0603 ) 3. 安规式电容 PCB 封装绘制 (这个就是 有一个电容,插入一个搞好的孔里面 …...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

让回归模型不再被异常值“带跑偏“,MSE和Cauchy损失函数在噪声数据环境下的实战对比
在机器学习的回归分析中,损失函数的选择对模型性能具有决定性影响。均方误差(MSE)作为经典的损失函数,在处理干净数据时表现优异,但在面对包含异常值的噪声数据时,其对大误差的二次惩罚机制往往导致模型参数…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...