Robust Self-Augmentation for Named Entity Recognition with Meta Reweighting
摘要
- 近年来,自我增强成为在低资源场景下提升命名实体识别性能的研究热点。
- Token substitution and mixup (token替换和表征混合)是两种有效提升NER性能的自增强方法。
- 明显,自增强方法得到的增强数据可能由潜在的噪声。
- 先前的研究针对特定的自增强方法设计特定的基于规则约束来降低噪声。
- 在这篇文章中,我们反思了这两个典型的针对NER的自增强方法。提出来提出了一个联合的 meta-reweighting 的策略去实现自然整合。
- 我们的方法很容易扩展到其他自增强方法,
- Experiments on different Chinese and English NER benchmarks。我们的方法可以有效的提升自增强方法的表现。
介绍
-
NER目的是从一些无结构文本中提取预训练命名实体。是NLP的一个基础任务。几十年来,都已经被广泛的研究。
-
近期,supervised sequence labeling neural models推动NER不断取得效果。
-
基于神经网络的方法推动NER任务不断取得更好的表现,但是其通常需要大规模标注数据,这在真实场景中是不现实的,
-
the low-resource setting with only a small amount of annotated corpus available普遍应用是更加切合实际的,
-
The major motivation is to generate a pseudo training example set deduced from the original gold-labeled training data automatically
- a pseudo training example set: 伪训练示例集。
- 由原始的基于标签的训练数据集自动推导。
-
a token-level task,
- token substitution.
- mixup.
- the ground-level inputs and the high-level hidden representations (低层次的输入和高层次的隐藏表示)
数据自增强是一个小样本任务可行的解法,对于 token-level 的 NER 任务,token 替换和表征混合是常用的方法。但自增强也有局限性,我们需要为每种特定的自增强方法单独进行一些设计来降低自增强所带来的噪声,缓解噪声对效果的影响。本文提出了 meta-reweighting 框架将各类方法联合起来。
尽管如此,我们尝试放宽前人方法中的约束,得到更多的伪训练示例。这样必然会产生更多低质量增强样本。这可能会降低模型的效果。此,我们提出 meta reweighting 策略来控制增强样本的质量。同时,使用 example reweighting 机制可以很自然的将两种方法结合在一起。
数据集
最后,on several Chinese and English NER benchmark datasets
our Approach
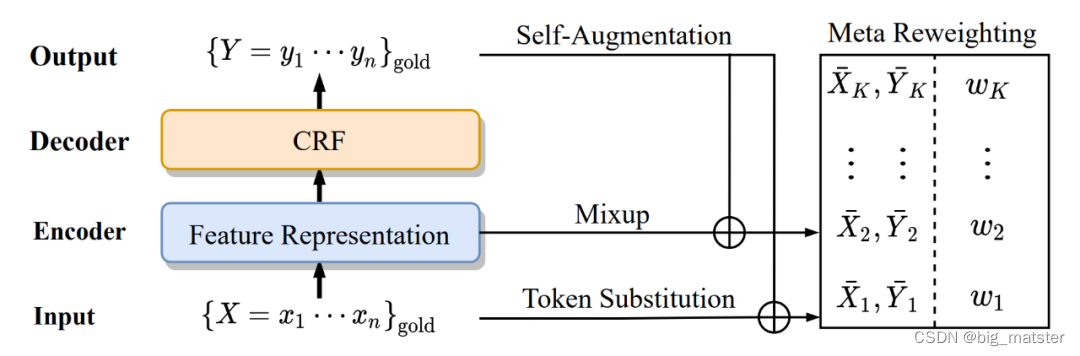
Baseline model
基准模型架构 BERT-BiLSTM-CRF
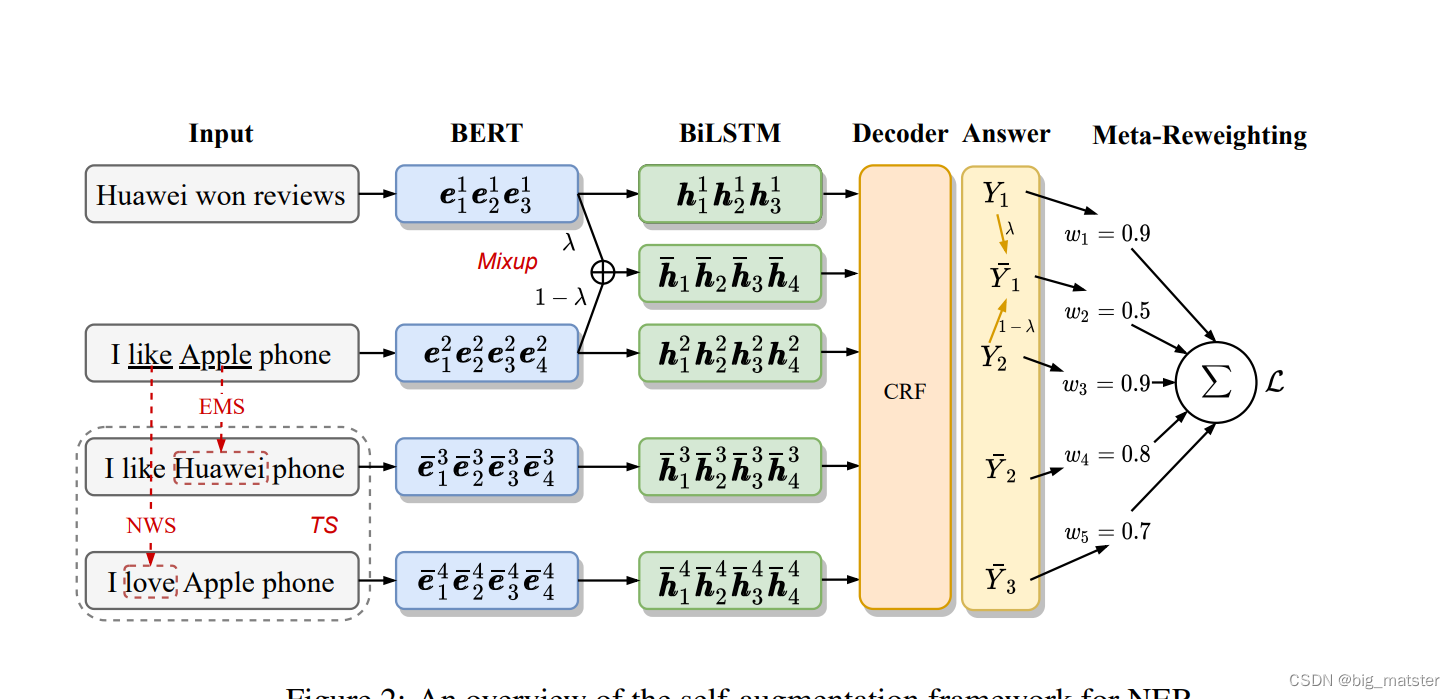
input representation
- 输入序列 X=(x1,x2,⋯,xN)X = (x_1,x_2,\cdots,x_N)X=(x1,x2,⋯,xN) of length n
- 使用预训练BERT,将其转换为 sequential hidden vectors
e1,e2,⋯,eN=BERT(x)e_1,e_2,\cdots,e_N = BERT(x)e1,e2,⋯,eN=BERT(x)
BiLSTM encoding
h1,h2,⋯,hn=BiLSTM(e1,e2,⋯,eN)h_1,h_2,\cdots,h_n = BiLSTM(e_1,e_2,\cdots,e_N)h1,h2,⋯,hn=BiLSTM(e1,e2,⋯,eN)
CRF decoding
最后解码过程使用 CRF 进行解码,先将得到的表征过一层线性层作为初始的标签分数,定义一个标签转移矩阵 TTT 来建模标签之间的依赖关系**。对于一个标签序列 ,其分数 计算如下:
oi=whi+b,o_i = wh_i + b,oi=whi+b,
s(Y∣X)=∑i=1n(Tyi−1,yi+oi[yi])s(Y|X) = \sum^n_{i = 1}(T_{y_{i -1},y_i} + o_i[y_i])s(Y∣X)=i=1∑n(Tyi−1,yi+oi[yi])
标签转移矩阵TTT
其中W,b,TW,b,TW,b,T都是模型参数,最后使用维比特算法**得到最佳的标签序列,训练的损失函数采用句子级别的交叉熵损失,
对于给定的监督样本对(X,Y)(X,Y)(X,Y),其条件概率P(Y∣X)P(Y|X)P(Y∣X)计算公式如下:
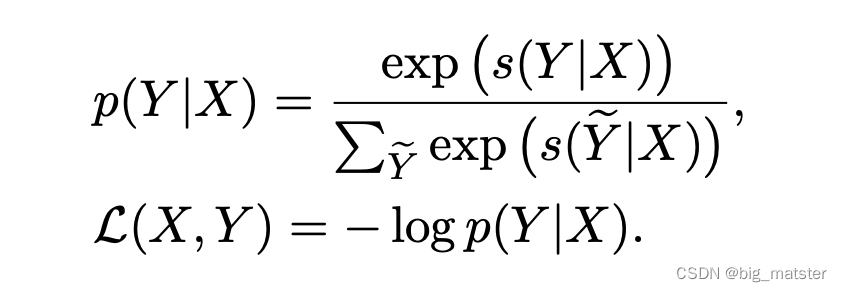
自增强方法
- 自增强方法减少了大规模的人工标注需求,这能够被应用在
- the input level and the representation level.
- Token substitution and mixup 是命名实体识别的两个有效的方法,因此,我们去尝试扩展这两个有效的方法。
Token Substitution
tokentokentoken替换是在原始的训练文本中对部分tokentokentoken进行替换得到伪样本,本文通过构建同义词词典来进行token替换。
asynonymdictionarya synonym dictionaryasynonymdictionary:同一词词典。
词典中即包含实体词也包含大量的普通词,遵循前人的设置,我们将所有属于同一实体类型的词当做同义词。 并且添加到实体词典中,作者将其称为entity mention substitution (EMS)。同时我们也将将 token 替换扩展到了“O”类型中,作者将其称为 normal word substitution (NWS)。作者使用word2vecword2vecword2vec方法,在 wikidata 上通过余弦相似度找到 k 个最近邻的词作为“O”类型词的同义词。
这里作者设置了参数,来平衡 EMS 和 NWS 的比率,在 entity diversity 和 context diversity 之间达到更好的 trade-off。
Mixup for CRF
不同与tokentokentoken替换在原始文本上做增强,mixup 是在表征上进行处理。
-
heuristic rules 启发式算法。
本文将mixup方法扩展到CRF层。 -
the gold-labeled training set 给出示例 (X1,Y1)(X_1,Y_1)(X1,Y1)和 (X2,X2)(X_2,X_2)(X2,X2)
-
the linear interpolation: 线性插值法。
-
形式上,给定一个样本对,首先用BERTBERTBERT得到其向量和,然后通过参数将两个样本混合。
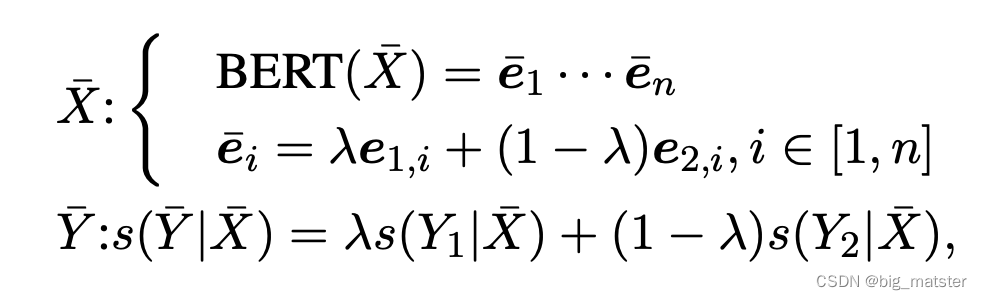
损失函数可以被计算为:
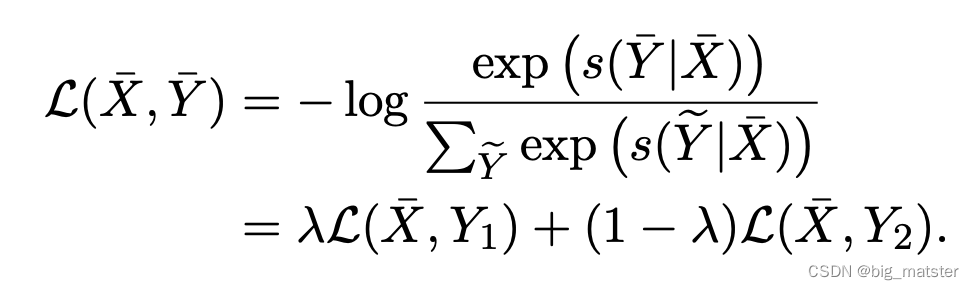
重点关注mixup和词替换方法。
Meta Reweighting
- 自增强技术可以有效的产生大量的伪样本,
- 如何控制增强示例的质量是一个不容忽视的挑战。
- sentence-level classification task: 句子级别的分类任务。
- the semantics of the context. 上下文信息.
作者使用 meta reweighting 策略为 mini batch 中的训练数据分配样本级的权重。 - Intuitively 直觉上看。
- the meta-data set, 标注样本
- the example-wise weights: 样本级别权重。
在少样本设置中,我们希望少量的标注样本能够引导增强样本进行模型参数更新,觉上看,如果增强样本的数据分布和其梯度下降的方向与标注样本相似,说明模型能够从增强样本中学到更多有用的信息。
算法流程如下:

实验
数据集采用 OntoNotes 4、OntoNotes 5、微博和 CoNLL03,所有数据集均采用 BIOES 标注方式。
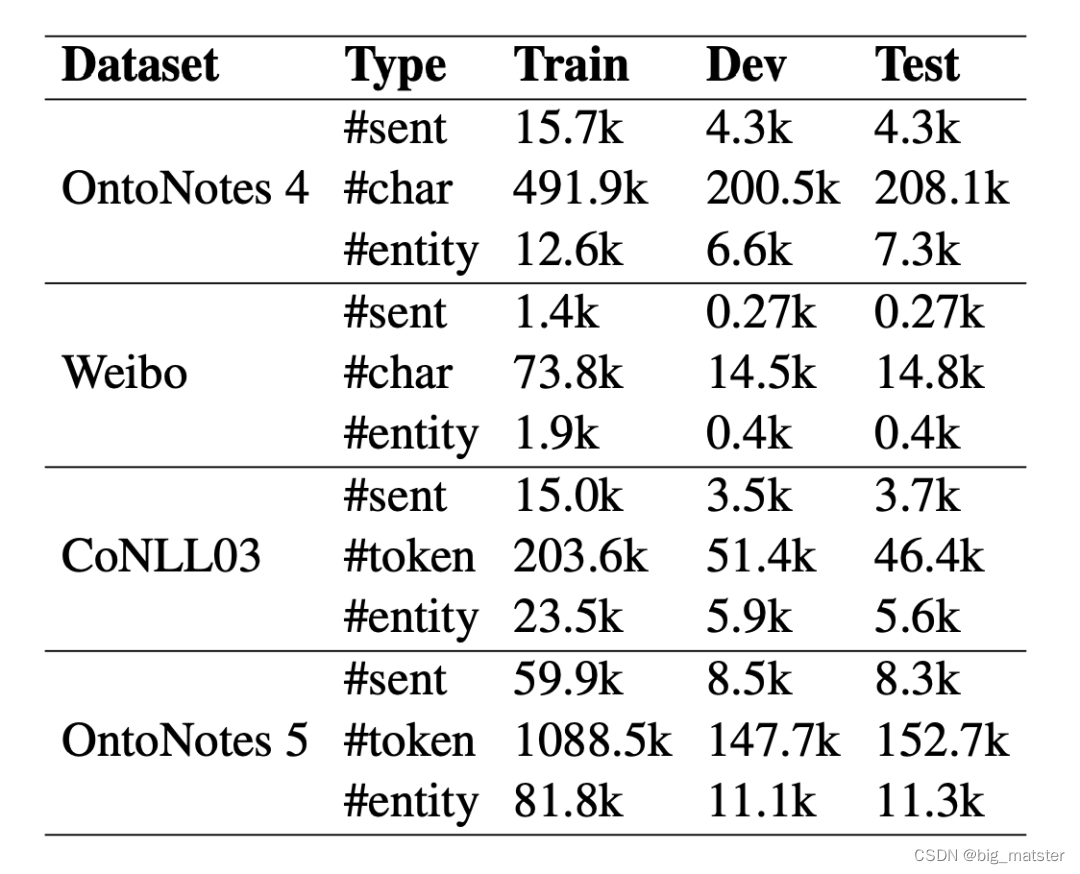
执行细节
- Gradient clipping 梯度裁剪
- manual annotations 手工标注
- sophisticated model architecture 复杂的模型架构。
运行模型
the BiLSTM-CRF mode
pre-trained BERT
自增强主流的方法
- token substitution
- paraphrasing
- mixup
文章灵感激发
- Many previous studies have explored the example weighting mechanism in domain adaption looked into the example weighting methods for cross-domain tasks。
- Ren et al. (2018) adapted the MAML algorithm (Finn et al., 2017) and proposed a meta-learning algorithm to automatically weight training examples of the noisy label using a small unbiased validation set.
-
结论
- 本文提出了 meta reweighting 策略来增强伪样本的效果。是一篇很有启发性的文章,从梯度的角度出发,结合类似于 MAML 中 gradient by gradient 的思想,用标注样本来指导伪样本训练,为伪样本的损失加权,对伪样本的梯度下降的方向进行修正使其与标注样本更加相似。
经验
- 同一个技术,使用的跟前人不一样,就叫做创新。
- 罗列常见的数据增强方法,换种方法后续都能发文章。
- 借鉴其他领域的主流方法,换个话题用到之知识图谱中,比如,领域自适应中的the example weighting mechanism,应用到命名实体识别中。
- 现在做的小步骤,都是复现代码,然后再代码上做微小的改动。
- 继续的多调试代码,反复读文章,将文章精度、读烂读透都行啦的理由与打算。
相关文章:
Robust Self-Augmentation for Named Entity Recognition with Meta Reweighting
摘要 近年来,自我增强成为在低资源场景下提升命名实体识别性能的研究热点。Token substitution and mixup (token替换和表征混合)是两种有效提升NER性能的自增强方法。明显,自增强方法得到的增强数据可能由潜在的噪声。先前的研究…...

Java基础-xml
1.xml 1.1概述 万维网联盟(W3C) 万维网联盟(W3C)创建于1994年,又称W3C理事会。1994年10月在麻省理工学院计算机科学实验室成立。 建立者: Tim Berners-Lee (蒂姆伯纳斯李)。 是Web技术领域最具权威和影响力的国际中立性技术标准机构。 到目前为止&#…...

TCP的Nagle算法和delayed ack---延时发送和延时应答与稍带应答选项
本文目录提高TCP的网络利用率的二个思考解决方案:Nagle算法和delayed ack(延时发送和延时应答与稍带应答选项)Nagle算法和delayed ack算法同时启动可能会导致的问题提高TCP的网络利用率的二个思考 我们都知道,TCP是一个基于字节流…...
智能拣配单解决方案
电子货架标签系统(ESLs),是一种放置在货架上、可替代传统纸质价格标签的电子显示装置, 每一个电子货架标签通过有线或者无线网络与商场计算机数据库相连, 并将最新的商品价格通过电子货架标签上的屏显示出来。 电子…...

如何防御入侵服务器
根据中华人民共和国刑法: 第二百八十六条违反国家规定,对计算机信息系统功能进行删除、修改、增加、干扰,造成计算机信息系统不能正常运行,后果严重的,处五年以下有期徒刑或者拘役;后果特别严重的ÿ…...
[软件工程导论(第六版)]第4章 形式化说明技术(课后习题详解)
文章目录1. 举例对比形式化方法和欠形式化方法的优缺点。2. 在什么情况下应该使用形式化说明技术?使用形式化说明技术时应遵守哪些准则?3. 一个浮点二进制数的构成是:一个可选的符号(+或-)&…...
Premiere基础操作
一:设置缓存二:ctrI导入素材三:导入图像序列四:打开吸附。打开吸附后素材会对齐。五:按~键可以全屏窗口。六:向前选择轨道工具。在时间线上点击,向前选中时间线上素材。向后选择轨道工具&#x…...
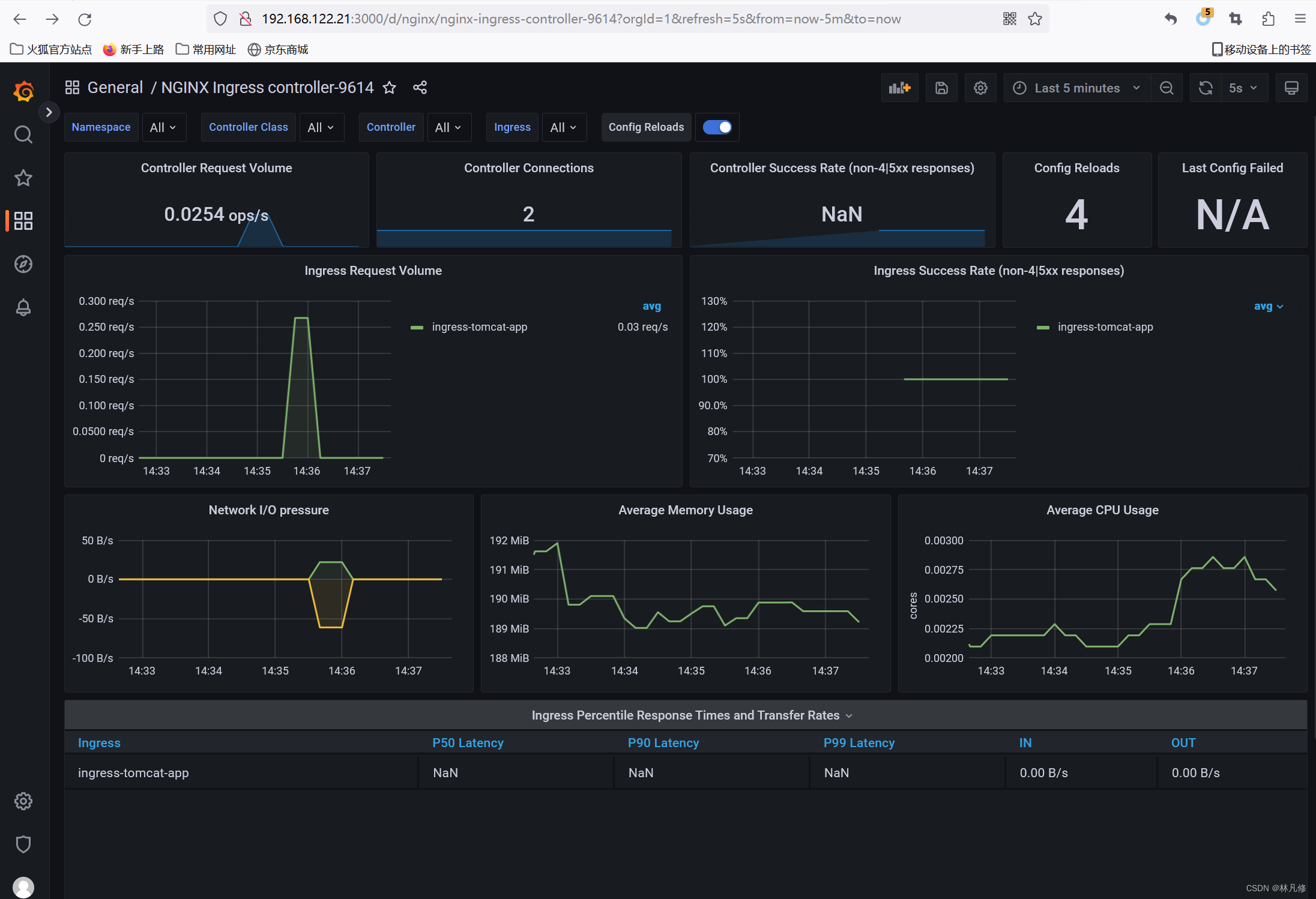
Prometheus监控案例-tomcat、mysql、redis、haproxy、nginx
监控tomcat tomcat自身并不能提供监控指标数据,需要借助第三方exporter实现:https://github.com/nlighten/tomcat_exporter 构建镜像 基于tomcat官方镜像,重新制作一个镜像,将tomcat-exporter和tomcat整合到一起。Ddockerfile如…...
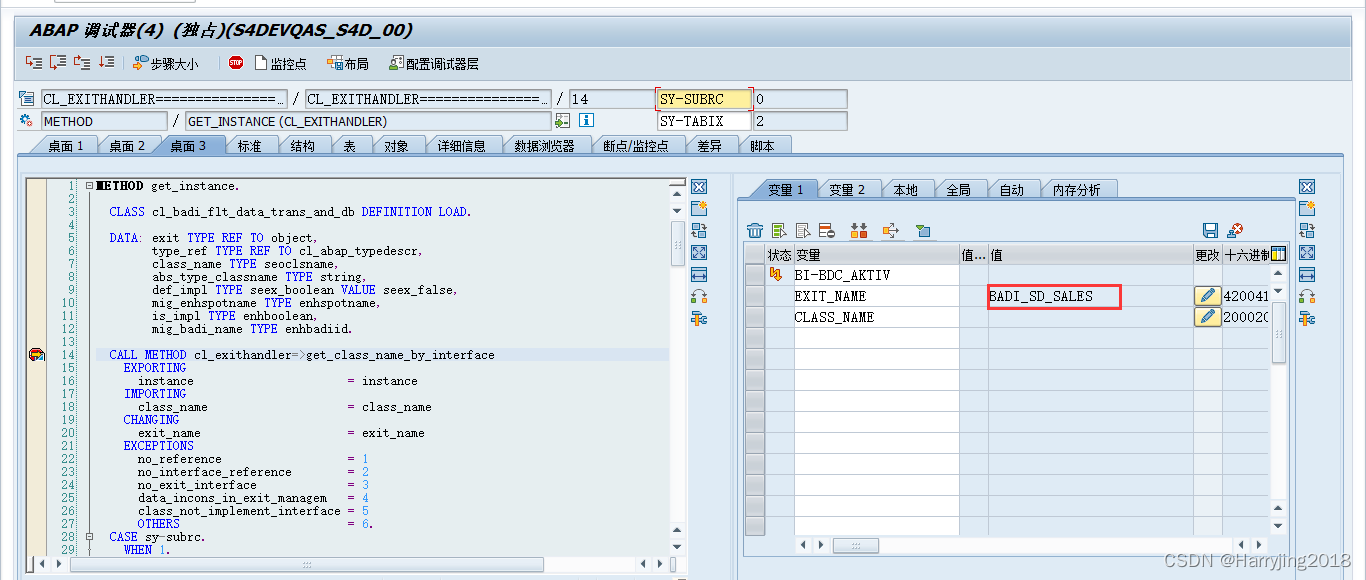
如何寻找SAP中的增强
文章目录0 简介1 寻找一代增强2 寻找二代增强2.2 在包里也可以看到2.3 在出口对象里输入包的名字也可以找到2.4 通过以下函数可以发现已有的增强2.5 也可以在cmod里直接找2.6 总结3 寻找第三代增强0 简介 在SAP中,对原代码的修改最不容易的是找增强,以下…...

算法刷题打卡第95天: 最大平均通过率
最大平均通过率 难度:中等 一所学校里有一些班级,每个班级里有一些学生,现在每个班都会进行一场期末考试。给你一个二维数组 classes ,其中 classes[i] [passi, totali] ,表示你提前知道了第 i 个班级总共有 totali…...
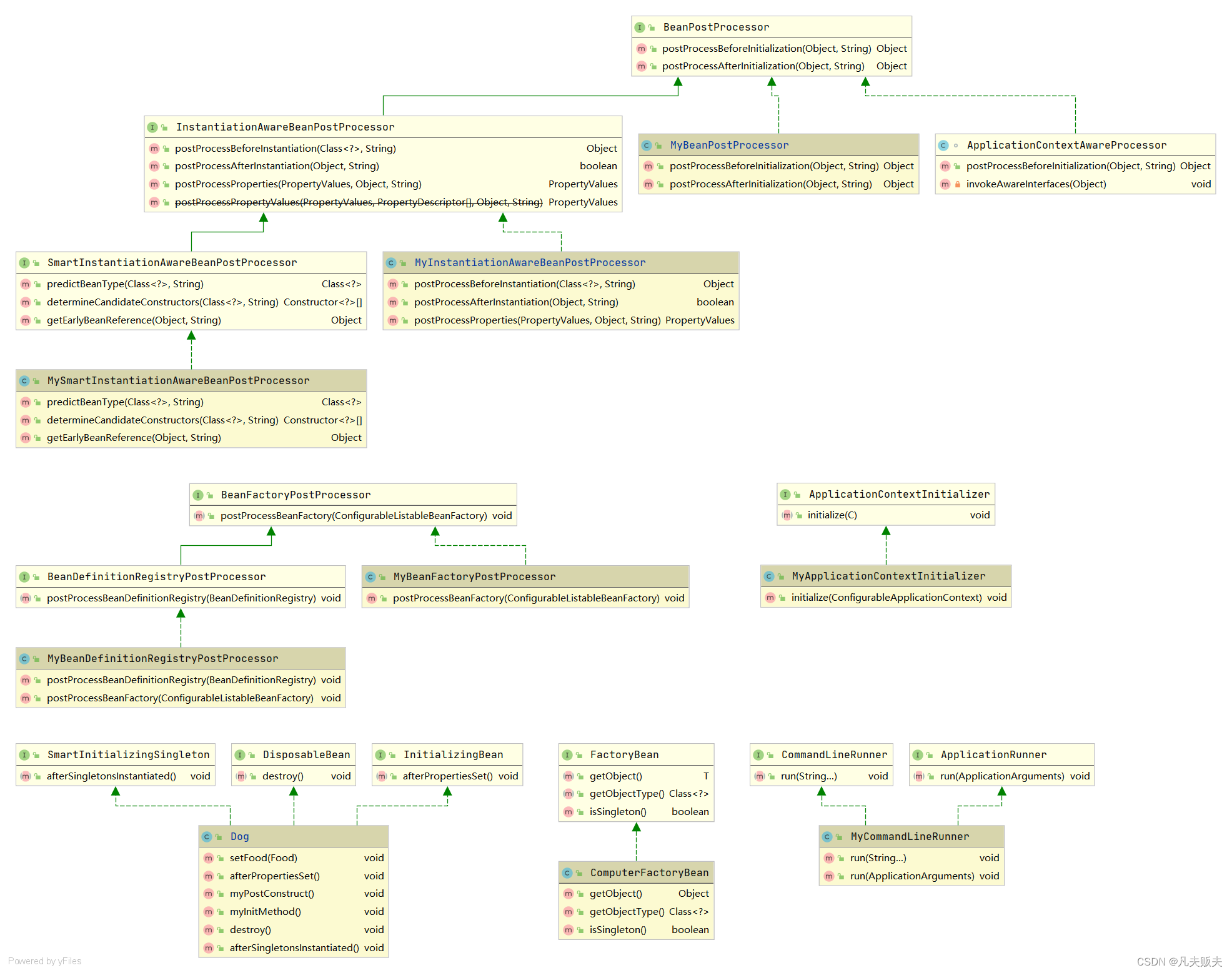
Springboot扩展点系列之终结篇:Bean的生命周期
前言关于Springboot扩展点系列已经输出了13篇文章,分别梳理出了各个扩展点的功能特性、实现方式和工作原理,为什么要花这么多时间来梳理这些内容?根本原因就是这篇文章:Spring bean的生命周期。你了解Spring bean生命周期…...
OnGUI Color 控件||Unity 3D GUI 简介||OnGUI TextField 控件
Unity 3D Color 控件与 Background Color 控件类似,都是渲染 GUI 颜色的,但是两者不同的是 Color 不但会渲染 GUI 的背景颜色,同时还会影响 GUI.Text 的颜色。具体使用时,要作如下定义:public static var color:Color;…...

【日刻一诗】
日刻一诗 1)LeetCode总结(线性表)_链表类 2)LeetCode总结(线性表)_栈队列类 3)LeetCode总结(线性表)_滑动窗口 4)LeetCode总结(线性表&#x…...
设计模式 状态机
前言 本文梳理状态机概念,在实操中状态机和状态模式类似,只是被封装起来,可以很方便的实现状态初始化和状态转换。 概念 有限状态机(finite-state machine)又称有限状态自动机(英语:finite-s…...

React源码分析(二)渲染机制
准备工作 为了方便讲解,假设我们有下面这样一段代码: function App(){const [count, setCount] useState(0)useEffect(() > {setCount(1)}, [])const handleClick () > setCount(count > count)return (<div>勇敢牛牛, <sp…...

Object.defineProperty 和 Proxy 的区别
区别:Object.defineProperty是一个用来定义对象的属性或者修改对象现有的属性的函数,,而 Proxy 是一个用来包装普通对象的对象的对象。Object.defineProperty是vue2响应式的原理, Proxy 是vue3响应式的原理1)参数不同Object.defineProperty参数obj: 要定…...

Python基础4——面向对象
目录 1. 认识对象 2. 成员方法 2.1 成员方法的定义语法 3. 构造方法 4. 其他的一些内置方法 4.1 __str__字符串方法 4.2 __lt__小于符号比较方法 4.3 __le__小于等于符号比较方法 4.4 __eq__等号比较方法 5. 封装特性 6. 继承特性 6.1 单继承 6.2 多继承 6.3 pas…...

Hive 核心知识点灵魂 16 问
本文目录 No1. 请谈一下 Hive 的特点No2. Hive 底层与数据库交互原理?No3. Hive 的 HSQL 转换为 MapReduce 的过程?No4. Hive 的两张表关联,使用 MapReduce 怎么实现?No5. 请说明 hive 中 Sort By,Order By࿰…...

聊聊探索式测试与敏捷实践
这是鼎叔的第五十二篇原创文章。行业大牛和刚毕业的小白,都可以进来聊聊。欢迎关注本专栏和微信公众号《敏捷测试转型》,大量原创思考文章陆续推出。探索式测试在敏捷测试象限中处于右上角,即面向业务且评价产品,这篇补充一下探索…...

社区宠物诊所管理系统
目录第一章概述 PAGEREF _Toc4474 \h 21.1引言 PAGEREF _Toc29664 \h 31.2开发背景 PAGEREF _Toc3873 \h 3第二章系统总体结构及开发 PAGEREF _Toc19895 \h 32.1系统的总体设计 PAGEREF _Toc6615 \h 32.2开发运行环境 PAGEREF _Toc13054 \h 3第三章数据库设计 PAGEREF _Toc2852…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...

python爬虫——气象数据爬取
一、导入库与全局配置 python 运行 import json import datetime import time import requests from sqlalchemy import create_engine import csv import pandas as pd作用: 引入数据解析、网络请求、时间处理、数据库操作等所需库。requests:发送 …...