ElasticSearch 数据聚合、自动补全(自定义分词器)、数据同步
文章目录
- 数据聚合
- 一、聚合的种类
- 二、DSL实现聚合
- 1、Bucket(桶)聚合
- 2、Metrics(度量)聚合
- 三、RestAPI实现聚合
- 自动补全
- 一、拼音分词器
- 二、自定义分词器
- 三、自动补全查询
- 四、实现搜索款自动补全(例酒店信息)
- 数据同步
- 双写一致性
数据聚合
一、聚合的种类
官方文档 => 聚合 https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html
聚合:对文档信息的统计、分类、运算。类似mysql sum、avg、count
- 桶(Bucket)聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组(相当于mysql group by)
- Date Histogram:按照日期阶梯分组,例如一周一组,一月一组
- 度量(metric)聚合:用来计算一些值,最大值、平均值、最小值等。
- Avg:平均值
- Max:最大值
- Min:最小值
- Stats:同时求max、min、avg、sum等
- 管道(pipeline)聚合:以其他聚合结果为基础继续做集合
二、DSL实现聚合
1、Bucket(桶)聚合

_count:默认是按照文档数量的降序排序
GET /hotel/_search
{"size": 0,"aggs": {"brandAgg": {"terms": {"field": "brand","size": 20,"order": {"_count": "asc"}}}}
}
上面使用的bucket聚合,会扫描索引库所有的文档进行聚合。可以限制扫描的范围:利用query条件即可。
GET /hotel/_search
{"query": {"range": {"price": {"lt": 200 # 只对价位低于200的聚合}}}, "size": 0,"aggs": {"brandAgg": {"terms": {"field": "brand","size": 20,"order": {"_count": "asc"}}}}
}
2、Metrics(度量)聚合

聚合的嵌套,先对外层进行聚合,在对内存进行聚合
注意嵌套查询:写在外层查询括号内,而非并立。
GET /hotel/_search
{"size": 0,"aggs": {"brandAgg": {"terms": {"field": "brand","size": 10,"order": {"scoreAgg.avg": "asc"}},"aggs": {"scoreAgg": {"stats": {"field": "score"}}}}}
}三、RestAPI实现聚合

bucket trem聚合(group by),实现品牌、星级、城市聚合的方法
public Map<String, List<String>> filters(RequestParam requestParam) {String[] aggNames = new String[]{"brand","city","starName"};Map<String, List<String>> resultMap = new HashMap<>();SearchRequest searchRequest = new SearchRequest("hotel");// 限定聚合范围BoolQueryBuilder boolQueryBuilder = getBoolQueryBuilder(requestParam);searchRequest.source().query(boolQueryBuilder);// 聚合字段searchRequest.source().size(0);searchRequest.source().aggregation(AggregationBuilders.terms(aggNames[0]).field("brand").size(100));searchRequest.source().aggregation(AggregationBuilders.terms(aggNames[1]).field("city").size(100));searchRequest.source().aggregation(AggregationBuilders.terms(aggNames[2]).field("starName").size(100));try {SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);Aggregations aggregations = searchResponse.getAggregations();for (String aggName : aggNames) {Terms terms = aggregations.get(aggName);List<String> list = new ArrayList<>();for (Terms.Bucket bucket : terms.getBuckets()) {list.add(bucket.getKeyAsString());}resultMap.put(aggName,list);}return resultMap;} catch (IOException e) {e.printStackTrace();return null;}}
自动补全
一、拼音分词器

下载拼音分词器:https://github.com/medcl/elasticsearch-analysis-pinyin/releases/tag/v8.6.0
解压放在plugins目录下(docker挂载的目录),然后重启es

二、自定义分词器


拼音分词器的过滤规则,参照上面下载的链接。
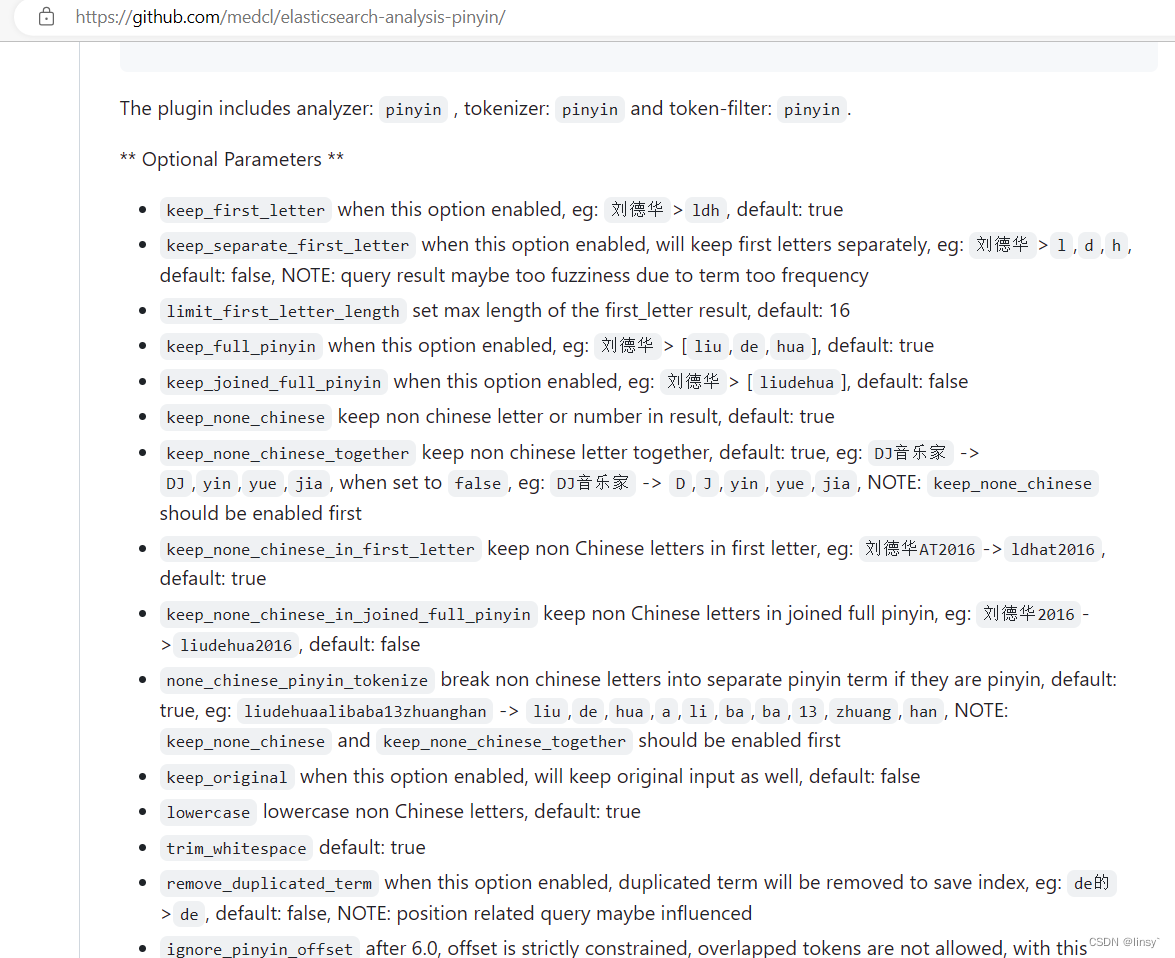
创建一个自定义分词器(text index库),分词器名:my_analyzer
// 自定义拼音分词器 + mapping约束
PUT /test
{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "ik_max_word","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "my_analyzer","search_analyzer": "ik_smart"}}}
}
三、自动补全查询
completion suggester查询:
- 字段类型必须是completion
- 字段值是多词条的数组才有意义

// 自动补全的索引库
PUT test2
{"mappings": {"properties": {"title":{"type": "completion"}}}
}
// 示例数据
POST test2/_doc
{"title": ["Sony", "WH-1000XM3"]
}
POST test2/_doc
{"title": ["SK-II", "PITERA"]
}
POST test2/_doc
{"title": ["Nintendo", "switch"]
}// 自动补全查询
POST /test2/_search
{"suggest": {"title_suggest": {"text": "s", // 关键字"completion": {"field": "title", // 补全字段"skip_duplicates": true, // 跳过重复的"size": 10 // 获取前10条结果}}}
}
四、实现搜索款自动补全(例酒店信息)

在这里插入代码片
构建索引库
// 酒店数据索引库
PUT /hotel
{"settings": {"analysis": {"analyzer": {"text_anlyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword"},"starName":{"type": "keyword"},"business":{"type": "keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart"},"suggestion":{"type": "completion","analyzer": "completion_analyzer"}}}
}
查询测试
GET /hotel/_search
{"query": {"match_all": {}}
}GET /hotel/_search
{"suggest": {"YOUR_SUGGESTION": {"text": "s","completion": {"field": "suggestion","skip_duplicates": true // 跳过重复的}}}
}


public List<String> getSuggestion(String prefix) {SearchRequest request = new SearchRequest("hotel");ArrayList<String> list = new ArrayList<>();try {request.source().suggest(new SuggestBuilder().addSuggestion("OneSuggestion",SuggestBuilders.completionSuggestion("suggestion").prefix(prefix).skipDuplicates(true).size(10)));SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);Suggest suggest = response.getSuggest();CompletionSuggestion oneSuggestion = suggest.getSuggestion("OneSuggestion");List<CompletionSuggestion.Entry.Option> options = oneSuggestion.getOptions();for (CompletionSuggestion.Entry.Option option : options) {String text = option.getText().toString();list.add(text);}} catch (IOException e) {e.printStackTrace();}return list;}
数据同步
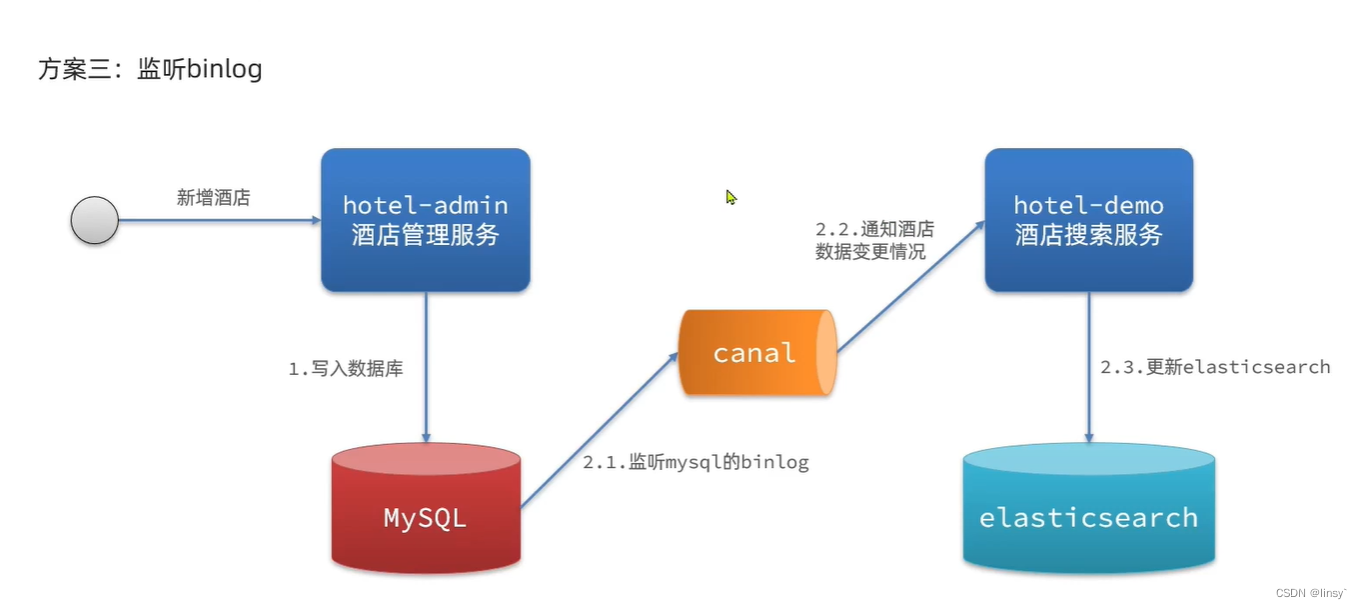
双写一致性
同步调用数据耦合,业务耦合

异步通知:增加实现难度

监听binlog(记录增删改操作):增加mysql压力,中间价搭建
相关文章:
ElasticSearch 数据聚合、自动补全(自定义分词器)、数据同步
文章目录 数据聚合一、聚合的种类二、DSL实现聚合1、Bucket(桶)聚合2、Metrics(度量)聚合 三、RestAPI实现聚合 自动补全一、拼音分词器二、自定义分词器三、自动补全查询四、实现搜索款自动补全(例酒店信息࿰…...

神经网络基础-神经网络补充概念-18-多个样本的向量化
概念 多个样本的向量化通常涉及将一组样本数据组织成矩阵形式,其中每一行代表一个样本,每一列代表样本的特征。这种向量化可以使你更有效地处理和操作多个样本,特别是在机器学习和数据分析中。 代码实现 import numpy as np# 多个样本的数…...

*看门狗1
//while部分是我们在项目中具体需要写的代码,这部分的程序可以用独立看门狗来监控 //如果我们知道这部分代码的执行时间,比如是500ms,那么我们可以设置独立看门狗的 //溢出时间是600ms,比500ms多一点,如果要被监控的程…...
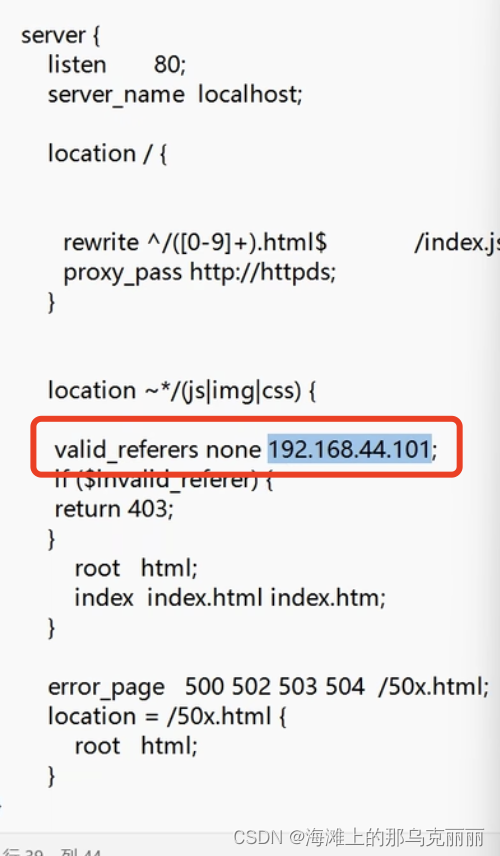
nginx防盗链
防盗链介绍 通过二次访问,请求头中带有referer,的方式不允许访问静态资源。 我们只希望用户通过反向代理服务器才可以拿到我们的静态资源,不希望别的服务器通过二次请求拿到我们的静态资源。 盗链是指在自己的页面上展示一些并不在自己服务…...
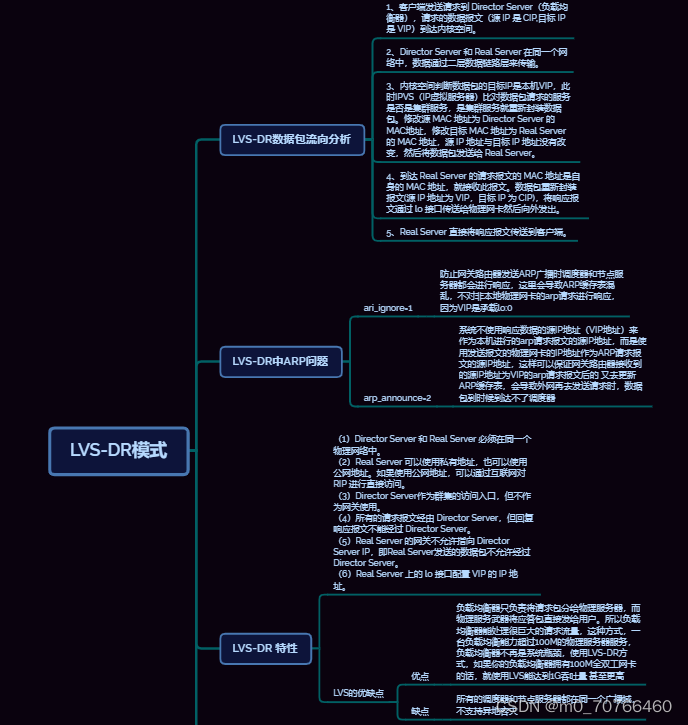
8月16日上课内容 第二章 部署LVS-DR群集
本章结构: 数据包流向分析: 数据包流向分析: (1)客户端发送请求到 Director Server(负载均衡器),请求的数据报文(源 IP 是 CIP,目标 IP 是 VIP)到达内核空间。 …...
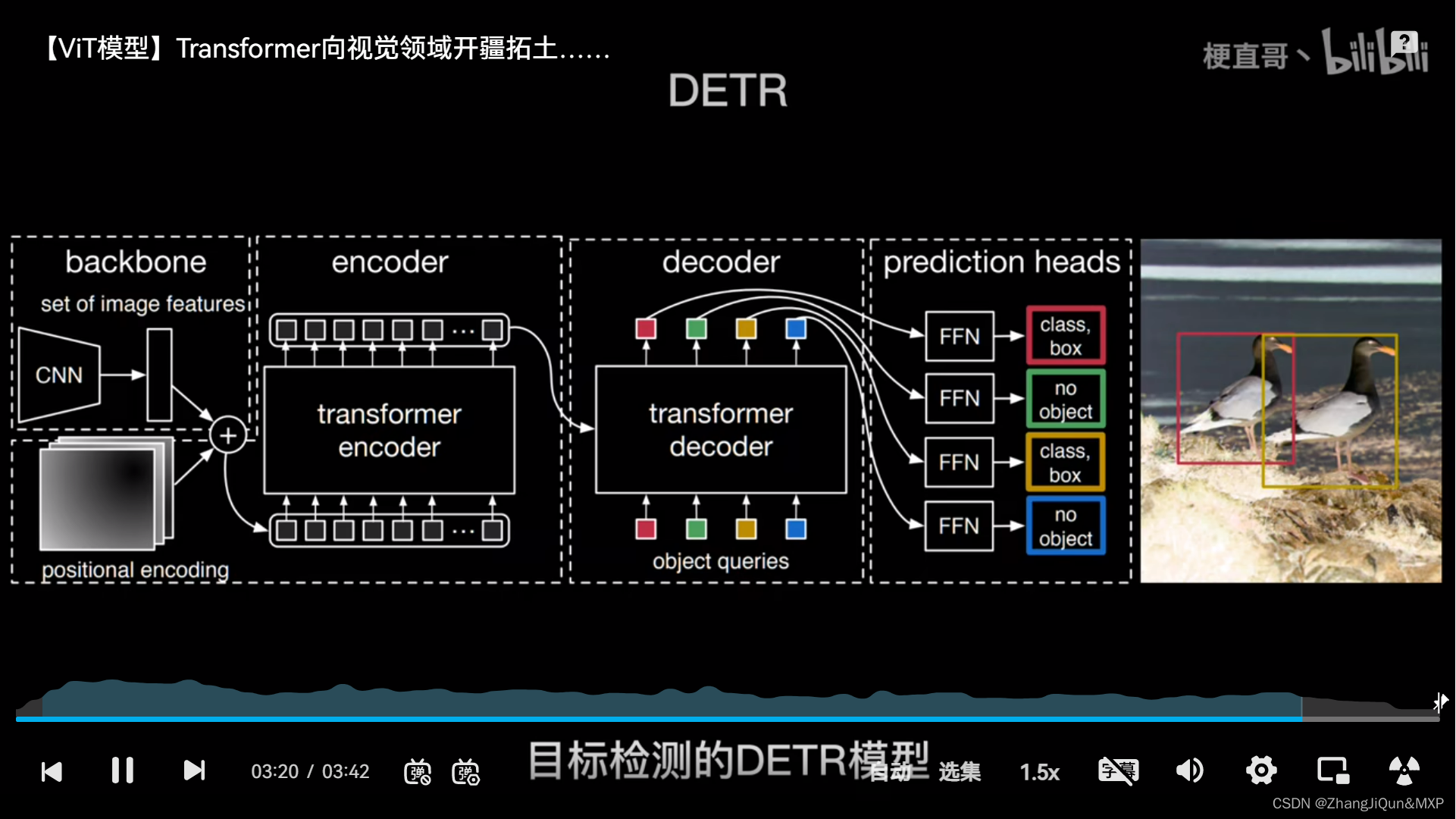
ViT模型架构和CNN区别
目录 Vision Transformer如何工作 ViT模型架构 ViT工作原理解析 步骤1:将图片转换成patches序列 步骤2:将patches铺平 步骤3:添加Position embedding 步骤4:添加class token 步骤5:输入Transformer Encoder 步…...
发布python模仿2023年全国职业的移动应用开发赛项样式开发的开源的新闻api,以及安卓接入案例代码
python模仿2023年全国职业的移动应用开发赛项样式开发的开源的新闻api,以及原生安卓接入案例代码案例 源码地址:keyxh/newsapi: python模仿2023年全国职业的移动应用开发赛项样式开发的开源的新闻api,以及安卓接入案例代码 (github.com) 目录 1.环境配…...

adb command
查看屏幕分辨率 adb shell wm size 查看dpi adb shell dumpsys window | grep ‘dpi’ WIFI调试: adb tcpip 5555adb connect 设备ip 注意,USB拔插会断掉,所以插上USB后再 adb connect 设备ip。【注意】华为手机自建热点的ip一般是192.1…...
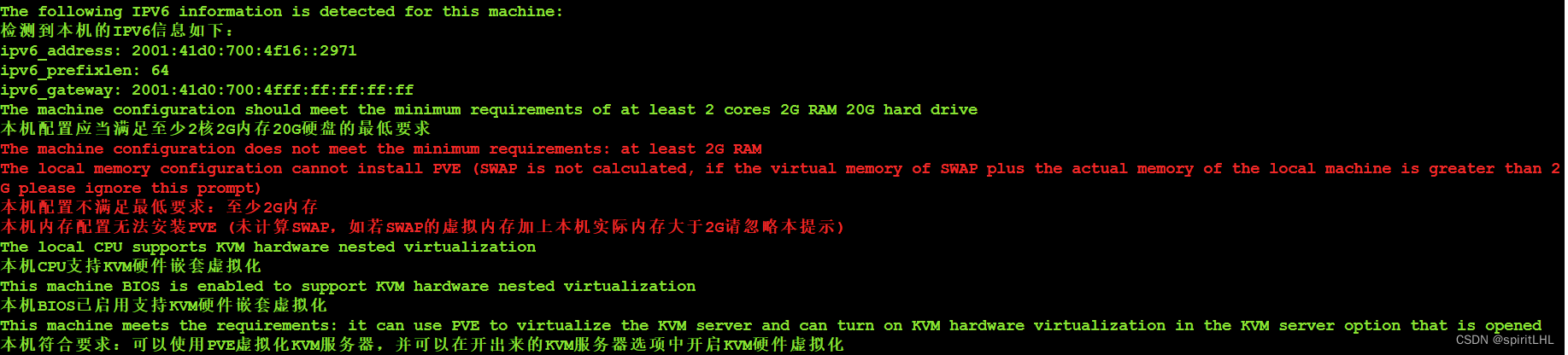
在ARM服务器上一键安装Proxmox VE(以在Oracle Cloud VPS上为例)(甲骨文)
前言 如题,具体用到的说明文档如下 virt.spiritlhl.net 具体流程 首先是按照说明,先得看看自己的服务器符不符合安装 Proxmox VE的条件 https://virt.spiritlhl.net/guide/pve_precheck.html#%E5%90%84%E7%A7%8D%E8%A6%81%E6%B1%82 有提到硬件和软…...
)
KMP算法(JS)
KMP算法 什么时KMP算法 KMP算法是一种改进的字符串匹配算法 由D.E.Knuth,J.H.Morris和 V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。 KMP的主要思想是当出现字符串不匹配时,可以知道…...
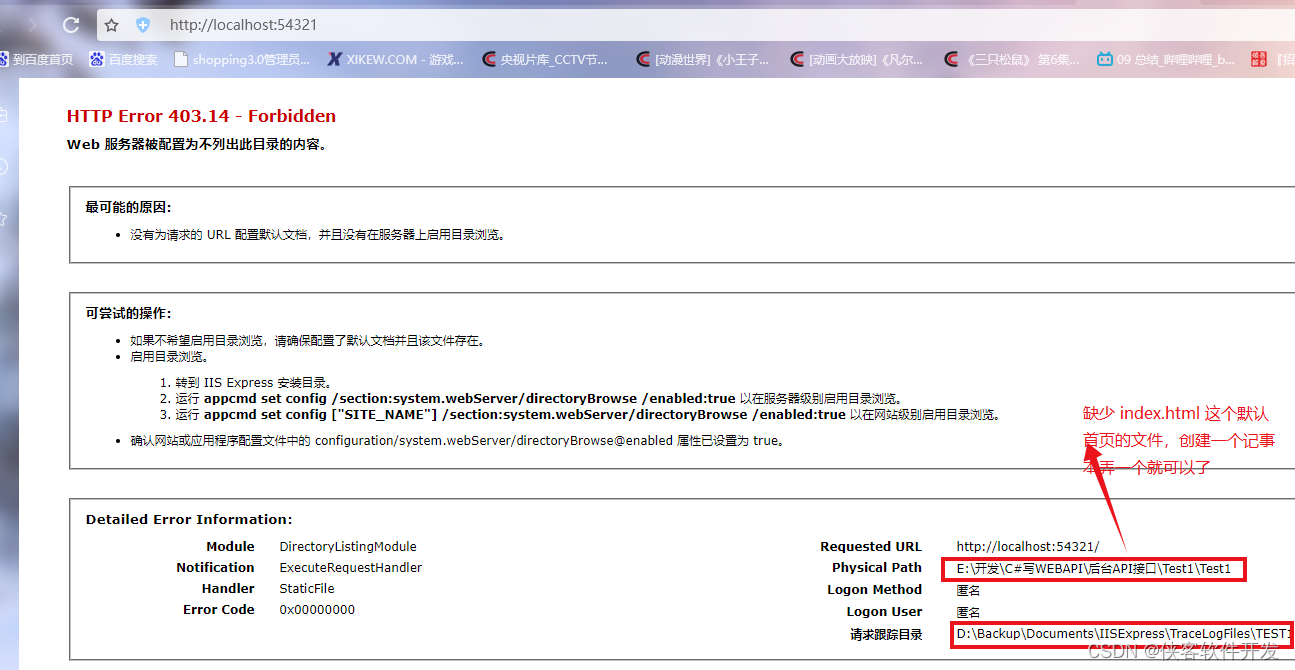
恢复NuGet包_解决:System.BadImageFormatException:无法加载文件或程序集
C#工程 主要是开发了一个 web api接口,这个工程源码去年还可以的,今年换了一个电脑打开工程就报错。 错误提示如下: 在 Microsoft.CodeAnalysis.CSharp.CommandLine.Program.Main(String[] args) Test1 System.BadImageFormatEx…...
Django学习笔记(2)
创建app 属于自动执行了python manage.py 直接在里面运行startapp app01就可以创建app01的项目了 之后在setting.py中注册app01 INSTALLED_APPS ["django.contrib.admin","django.contrib.auth","django.contrib.contenttypes","django.c…...

高德地图开发者平台Python应用实践:快速入门周边商业环境信息查询
高德地图开发平台提供了丰富的API接口,可以方便地进行地图数据的开发和分析。在商业分析数据采集中,使用高德地图开发平台的周边查询功能可以快速获取周边商圈、小区等信息,为商业决策提供数据支持。 针对您的需求,我建议采用以下…...

【ES6】—let 声明方式
一、不属于顶层对象window let 关键字声明的变量,不会挂载到window的属性 var a 5 console.log(a) console.log(window.a) // 5 // 5 // 变量a 被挂载到window属性上了 , a window.alet b 6 console.log(b) console.log(window.b) // 6 // undefin…...

【数据分析入门】Jupyter Notebook
目录 一、保存/加载二、适用多种编程语言三、编写代码与文本3.1 编辑单元格3.2 插入单元格3.3 运行单元格3.4 查看单元格 四、Widgets五、帮助 Jupyter Notebook是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。 …...

反射知识总结
1、反射概述 反射是指对于任何一个Class类,在"运行的时候"都可以直接得到这个类全部成分。在运行时,可以直接得到这个类的构造器对象:Constructor在运行时。可以直接得到这个类的成员变量对象:Field在运行时,…...
MongoDB 安装 linux
本文介绍一下MongoDB的安装教程。 系统环境:CentOS7.4 可以用 cat /etc/redhat-release 查看本机的系统版本号 一、MongoDB版本选择 当前最新的版本为7.0,但是由于7.0版本安装需要升级glibc2.25以上,所以这里我暂时不安装该版本。我们选择的是6.0.9版本…...
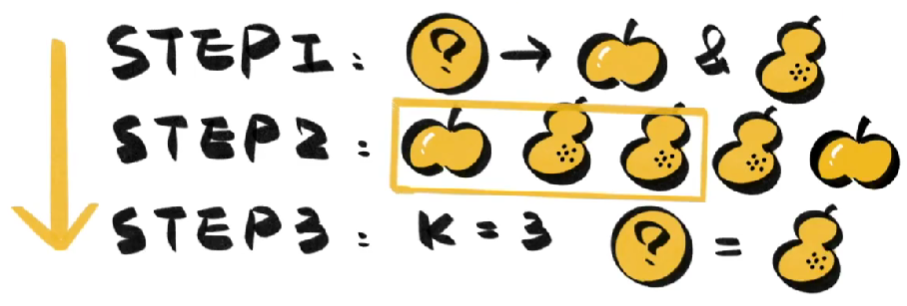
什么是KNN( K近邻算法)
什么是KNN( K近邻算法) 虽然名字中有NN,KNN并不是哪种神经网络,它全名K-Nearest-Neighbors:K近邻算法,是机器学习中常用的分类算法。 物以类聚,人以群分。KNN的基础思想很简单,要判断一个新数据的类别&…...

Linux查看命令总结
1.动态实时查找命令 使用以下命令的前提是需要在找到日志位置 tail -f server.log 实时展示日志末尾内容,默认最后10行,相当于增加参数 -n 10 tail -n filename; tail命令扩展 查看日志最后20行内容并实时更新日志 tail -f -n 20 server.log或者 tail -fn 20 ser…...

npm报错 Cannot find module ‘@vuepress\core\node_m
通常是由于缺少依赖包或者依赖包版本不兼容引起的。可以尝试以下步骤来解决这个问题: 确保您的项目的依赖包是最新的,可以运行 npm update 命令来更新依赖包。 如果更新依赖包后仍然有问题,可以尝试删除 node_modules 文件夹,并重…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...

通过MicroSip配置自己的freeswitch服务器进行调试记录
之前用docker安装的freeswitch的,启动是正常的, 但用下面的Microsip连接不上 主要原因有可能一下几个 1、通过下面命令可以看 [rootlocalhost default]# docker exec -it freeswitch fs_cli -x "sofia status profile internal"Name …...