【1-3章】Spark编程基础(Python版)
课程资源:(林子雨)Spark编程基础(Python版)_哔哩哔哩_bilibili
第1章 大数据技术概述(8节)
第三次信息化浪潮:以物联网、云计算、大数据为标志
(一)大数据
大数据时代到来的原因:
- 技术支撑:存储设备(价格下降)、CPU计算能力(多核CPU)、网络带宽(单机不能够完成海量数据的存储和处理,借助网络分布式的集群运算)
- 数据产生方式的变革:运营式系统阶段(如超市购物在数据库系统中生成购物信息) —> 用户原创内容阶段 —> 感知式系统阶段(物联网感知终端,如传感器、摄像头、RFID)
大数据4V特性:
- 大量化Volume:数据量大(摩尔定律:人类在最近两年产生的数据量相当于之前产生的全部数据量)
- 快速化Velocity:处理速度快(一秒定律:数据从生成到决策响应仅需1s,1s的响应才能够具备它相应的商业价值)
- 多样化Variety:数据类型繁多,非结构化数据(存储于非关系型数据库中)& 结构化数据(具有规范行和列,存储于关系型数据库中)
- 价值密度低Value:但单点价值高
大数据影响:
- 对科学研究的影响:科学研究的四种范式分别为 实验-理论-计算(事先知道问题)-数据(从数据中发现问题)
- 对思维方式的影响:全样而非抽样(存储和算力均提升了)、效率而非精确(全样分析不存在误差放大问题,故不再苛求精确度)、相关而非因果
大数据关键技术:
- 数据采集
- 数据存储与管理(核心一):分布式存储(解决数据存储问题),如GFS/HDFS、BigTable/HBase、NoSQL(键值、列族、图形、文档数据库)、NewSQL(如SQL Azure)
- 数据处理与分析(核心二):分布式处理(解决数据高效计算问题),如MapReduce、Spark、Flink
- 数据隐私与安全
大数据计算模式:
- 企业不同应用场景对应不同计算模式
- 典型计算模式:
- 批处理计算(大规模数据的批量处理,MapReduce/Spark)
- 流计算(流数据的实时计算,实时处理实时响应,秒级/毫秒级,Storm/Flume)
- 图计算(大规模图结构数据的处理,如地理信息系统、社交网络数据,Pregel/GraphX)
- 查询分析计算(大规模数据的存储管理和查询分析,Dremel/Hive/Cassandra)

(二)代表性大数据技术
Hadoop、Spark、Flink、Beam
1、Hadoop
不是单一软件,是一个生态系统
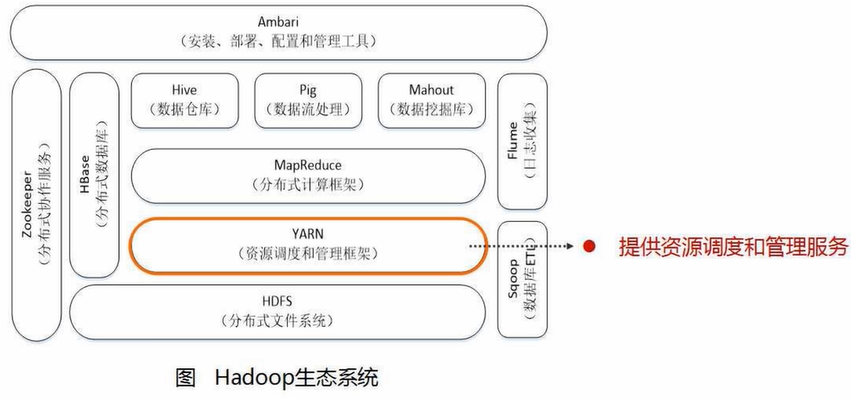
- HDFS:分布式文件系统,非结构化数据存储【Hadoop关键技术之一】
- YARN:资源调度和管理框架,分配计算所需的内存和CPU资源
- MapReduce:分布式计算框架【Hadoop关键技术之二】
- Hive:数据仓库,本身并不存储数据,数据存储在HDFS里。本质是一个编程接口,提供SQL查询分析(查询时写的是SQL语句,将SQL语句转成MapReduce程序,对底层数据进行查询分析)
- Pig:数据流处理。数据清洗、转换、加载(Pig Latin语言),一般和Hive组合使用
- Mahout:数据挖掘和机器学习算法库。实现常用的数据挖掘算法,如分类、聚类、回归等(单机版—>分布式)。用MapReduce实现的算法库,只需调接口、传参数,减少工作量
- Ambari:自动安装、部署、配置、管理Hadoop集群
- ZooKeeper:分布式协作服务,负责分布式协调一致性。如协调共享加锁、选管家等
- Hbase:分布式数据库。HDFS面向批处理,HBase面向实时计算
- Flume:日志采集工具
- Sqoop:ETL(抽取Extract,转换Transform,加载Load),将历史保存在关系型数据库中的数据抽取出来,保存到HDFS中,反之亦可。完成Hadoop系统组件之间的互通,即Hadoop与关系型数据库数据之间的导入导出
MapReduce:编程容易,屏蔽底层分布式并行编程细节(写MR程序跟写单机程序差别不大,自动分发任务到不同机器,并收集结果)。核心策略为分而治之,即把一个大的任务拆分成很多子任务,分发到不同机器上并行执行(只有满足分而治之的任务才能用MapReduce,如词频统计)

YARN(Yet Another Resource Negotiator):Hadoop2.0才出现。资源调度管理框架,实现“一个集群多个框架”
- 离线批处理:MapReduce
- 实时交互式查询分析:Impala
- 流式数据实时分析:Storm
- 迭代计算:Spark
以前为了防止资源打架,会独立部署各个计算框架(如1000台机器指定300台部署MapReduce计算框架,300台部署Spark计算框架,以此类推),但这导致开发成本高、集群资源利用率低、底层数据无法共享和无缝集成,YARN的出现解决了这一问题

2、Spark
不是单一软件,是一个生态系统
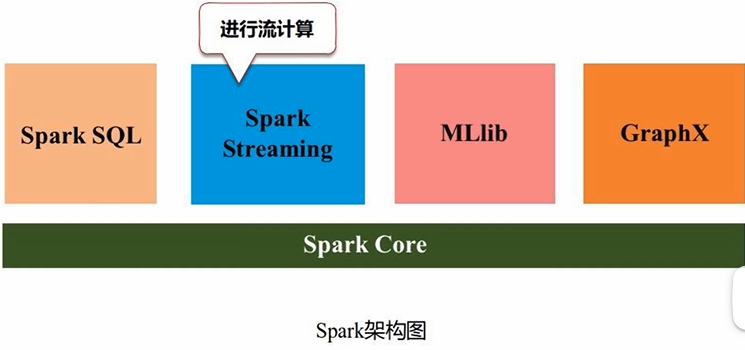
- Spark Core:完成RDD应用开发。满足企业批处理的需求
- Spark SQL:查询分析计算,分析关系数据
- Spark Streaming:流计算(Structured Streaming:结构化数据流)
- MLlib:机器学习算法库
- GraphX:编写图计算应用程序
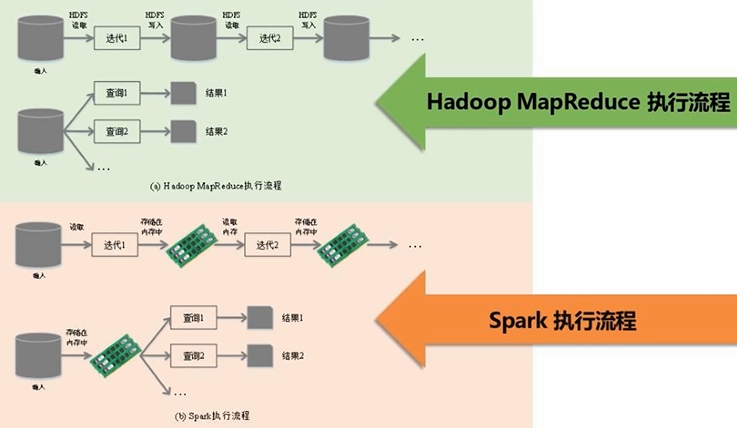
Hadoop vs Spark,Hadoop存在以下缺点(主要是其中MapReduce的缺点):
- 表达能力有限。MapReduce把复杂业务逻辑拆分成Map函数和Reduce函数,降低了分布式应用开发的复杂性,同时也限制了表达能力
- 磁盘IO开销大。MapReduce是基于磁盘开发的,不同阶段的衔接&中间结果的存储均涉及读写磁盘。如逻辑斯蒂回归、模拟退火算法、遗传算法等迭代算法都需要使用MapReduce进行反复迭代(读写磁盘),效率低
- 延迟高。任务分解为多个map和多个reduce,完成全部map任务才能进入reduce阶段,涉及任务之间的衔接开销,难以胜任多阶段的、比较复杂的计算任务,尤其是迭代式的计算
Spark有以下优点:
- Spark本质上计算模式也属于MapReduce,但它的操作不再局限于map和reduce,如filter过滤、groupBy分组、join连接等等,操作类型更多,表达能力更强
- Spark提供内存计算,把计算的中间结果放到内存中,高效提高迭代计算
- Spark是基于有向无环图DAG的任务调度机制(好于MapReduce的执行机制),流水线优化,使得很多数据可以一条线地执行下去,不用落磁盘进行读写,可以大大加快执行速度
Q:Spark会取代Hadoop吗?
- Hadoop有两大核心:存储框架HDFS(分布式文件系统)、分布式计算框架MapReduce
- Spark是一个单纯的计算框架,本身不具备存储能力,一般和HDFS组合使用(数据保存在HDFS中,借助于Spark计算)。Spark取代的是Hadoop里的计算框架MapReduce,而不是Hadoop
3、Flink
不是单一软件,是一个生态系统(批处理、查询分析、流计算、图计算、机器学习算法库也都有)。Flink是和Spark同一类型的计算框架

本质区别:Spark是基于RDD的批处理模型,Flink是基于一行行的流处理模型(实时性好于Spark Streaming)
4、Beam
Google提出,统一编程接口Beam SDK,自动翻译成其他引擎。但目前主流:Hadoop+Spark
第二章 Spark的设计与运行原理(8节)
(一)Spark概述
背景:MapReduce磁盘读写、IO开销大 ——> 提出Spark:基于内存的计算框架,构建大型的、低延迟的数据分析应用程序
- 三大分布式计算系统开源项目:Hadoop、Spark、Storm
Spark优点:
- 运行速度快:基于内存的计算,数据很少落磁盘,循环数据流;DAG有向无环图执行引擎,优化执行过程,实现流水线优化
- 容易使用:支持Java、Scala、R、Python四种编程语言,其中Scala可通过Spark Shell进行交互式编程
- 通用性:不是单一组件,是一个完整的生态系统、完整的解决方案、技术软件栈
- SQL查询:Spark SQL
- 流式计算:Spark Streaming
- 机器学习:Spark MLlib
- 图算法组件:Spark的GraphX
- 运行模式多样:
- 单机/集群(本地集群/云端集群)都支持
- 可访问多种数据源:分布式文件系统HDFS、数据库Cassandra、分布式数据库HBase、数据仓库Hive等(Spark是计算框架,本身不存储数据)
Spark vs Hadoop(主要是其中MapReduce的缺点):
- MapReduce缺点:表达能力有限、磁盘IO开销大、延迟高
- Spark优点:
- 操作类型更多,表达能力更强;
- 内存计算,高效提高迭代运算(内存计算的意思是,能够不落磁盘尽量不落磁盘,而不是所有数据都在内存中运行,如shuffle必须要落磁盘);
- DAG有向无环图任务调度执行机制

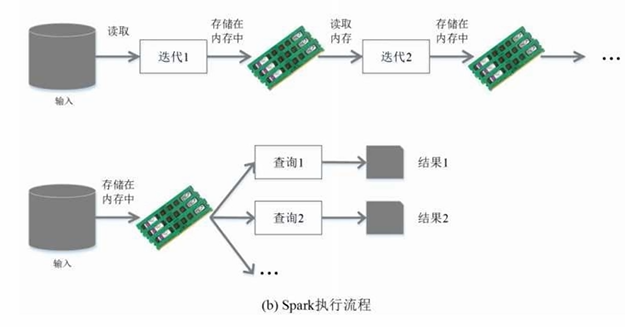
(二)Spark生态系统
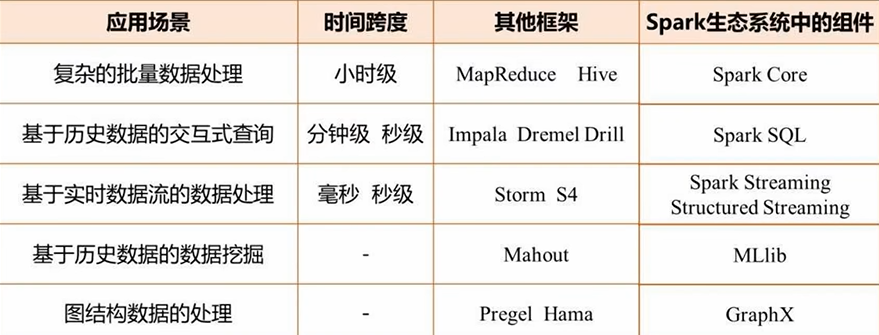
三大典型应用场景:

- 批处理:MapReduce
- 交互查询:数据仓库Impala
- 流处理:Storm
问题:(1)无法无缝共享,需要进行数据格式转换;(2)维护成本较高;(3)资源利用不充分,无法做统一的资源管理分配
Spark一个软件栈满足不同应用场景需求,如SQL即席查询、实时流式计算、机器学习、图计算。Spark中各个组件可借助于Yarn进行统一资源调度分配管理
伯克利数据分析软件栈BDAS(Berkeley Data Analytics Stack):
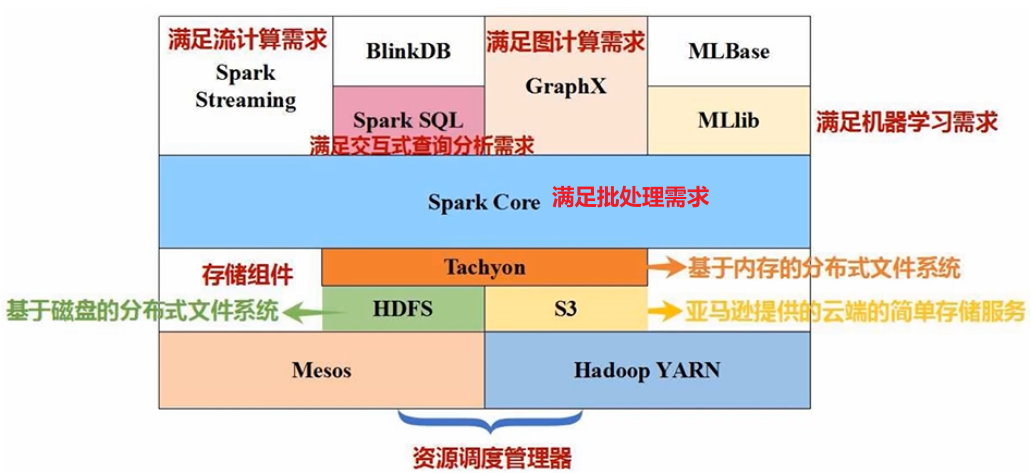

Spark的生态系统(技术软件栈,一站式服务):
(三)Spark运行架构
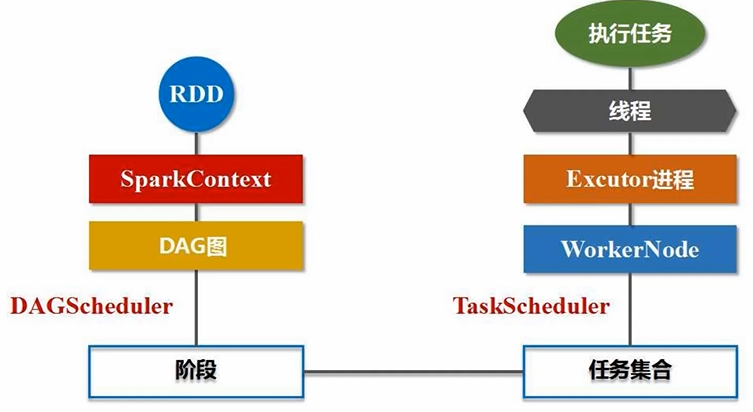
1、基本概念
RDD:弹性分布式数据集。分布式内存的一个抽象概念(整个Spark编程最核心的数据抽象),提供了一种高度受限的共享内存模型
- 弹性:数据可大可小、分区数目动态可变化
- 分布式:分布式保存在多台机器的内存中
DAG:有向无环图。反映RDD之间的依赖关系,RDD操作会形成DAG
Executor:运行在工作节点(WorkerNode,从节点)的一个进程(一个进程会派生出很多线程),负责运行具体的任务/Task
应用/Application:用户编写的Spark应用程序
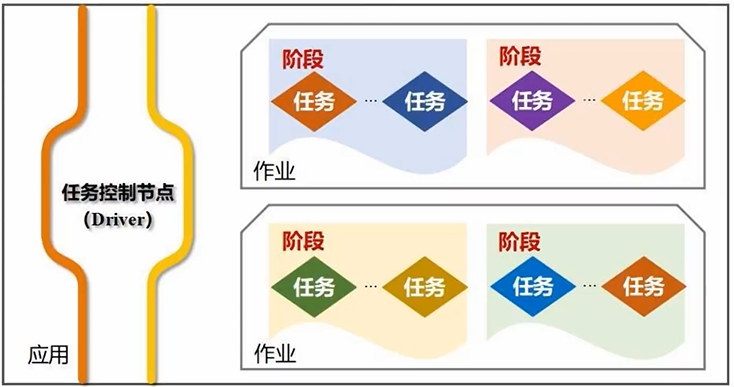
任务/Task:运行在Executor进程上的工作单元(任务控制节点Driver Program)
作业/Job:一个Job包含多个RDD及作用于相应RDD上的各种操作。一个Spark应用程序提交后,就是分解成1到多个Job去完成的
阶段/Stage:作业的基本调度单位。每个Job会被分解成多组Task,每一组Task的集合叫Stage
2、架构设计

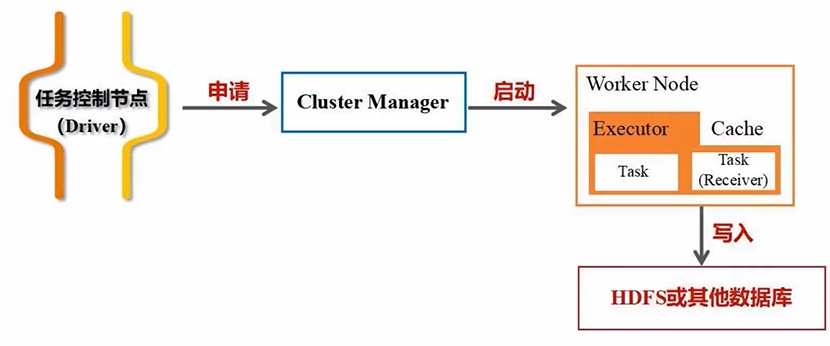
执行应用时,Driver会向集群资源管理器申请资源,并启动Executor进程,向进程发送应用程序的代码和文件,应用程序会在进程上派发出线程去执行任务,执行结束后将结果返回给Driver,提交给用户/HDFS/关系型数据库等
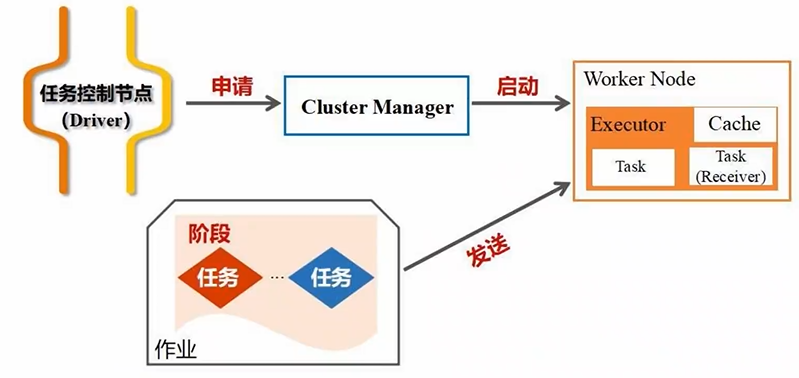

分布式系统的两种架构:对等架构P2P;一主多从架构(Spark、Hadoop都是这种)
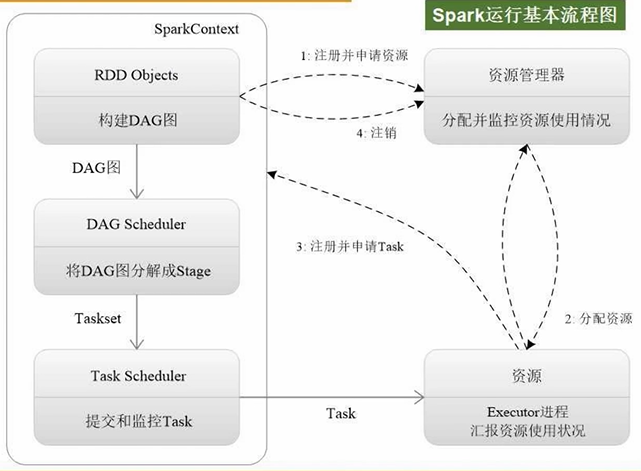
3、Spark运行基本流程
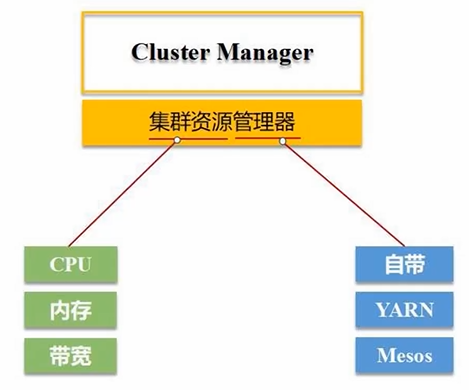
- 为Application构建基本的运行环境(Driver节点生成SparkContext对象,负责整个任务的调度、监控、执行、失败恢复、结果汇总等)
- 运行Executor进程必须要有相关的内存、CPU资源。SparkContext向资源管理器申请资源,进行任务的分配和监控
- 集群资源管理器Cluster Manager接到申请后,为Executor进程分配CPU、内存资源,此时Worker Node上的Executor进程就可以启动了,可以派生出很多线程去执行任务
- 任务是怎么来的呢?SparkContext根据提交的代码(针对RDD的操作)生成DAG图,交给DAG Scheduler将DAG图分解成Stage,每个Stage包含很多Task
- Task任务如何分发呢?Task Scheduler会把每个阶段的任务分发给不同节点来处理(分发基本原则:计算向数据靠拢,尽量减小数据的移动开销,优先把计算分发到数据所在的节点,实现数据的本地化处理)
- 线程执行完任务后,把结果反馈给Task Scheduler,再反馈给DAG Scheduler,运行结束后写入数据并释放资源
4、RDD的设计与运行原理
MapReduce不适合处理迭代场景(如逻辑斯蒂回归、模拟退火算法、遗传算法),中间结果反复读写磁盘,磁盘IO开销太大(反复读写工作子集+序列化和反序列化开销)
- 序列化:把内存中的对象转化为可保存和传输的格式,如Java对象转化为二进制或字符串
- 反序列化:从可保存和传输的格式生成对象
RDD为了避免这些问题而出现,提供了抽象的数据结构:把具体应用逻辑表达为RDD转换,不同RDD转换之间的依赖关系即DAG图,优化实现数据的管道化(流水线化)处理,即一个操作结束后数据不需要落磁盘,马上输入给下一个操作,避免数据落地
- 一个RDD就是一个数据分布式对象的集合,本质上是一个只读的分区记录集合,可以分布式保存在很多机器上(若干分区,每个分区放在不同机器上,每个分区都是一个数据片段),分布式并行处理,高效并行计算
- RDD加载高度受限(只读)的共享内存模型,生成内存当中的数据集合,创建后就不能修改了。转化过程中可以修改,即通过生成新的RDD来完成一个数据修改的目的
- RDD提供了丰富的操作类型,分为两大类:动作类型操作Action、转换类型操作Transformation。均支持粗粒度修改(一次只能针对RDD全集进行转换),不支持细粒度修改(不适合数据库对单条进行修改、不适合网页爬虫)
- 高度受限的共享内存模型会不会影响表达能力?由于RDD提供的转换操作(map、filter、groupBy、join)十分丰富,可以将其组合实现很多功能。实践证明,Spark能力非常强大,虽是高度受限的共享内存模型,但不会影响表达能力。Spark提供了RDD的API,程序员可以通过调用API实现对RDD的各种操作
RDD典型执行过程如下:
- RDD读入外部数据源进行创建,如从底层分布式文件系统读取数据即可完成创建、生成RDD
- RDD经过一系列转换Transformation操作,每一次都会产生不同的RDD供给下一个转换操作使用。一系列转换操作后有一个动作类型操作Action,动作类型操作计算得到结果(转换类型操作不会计算得到结果)

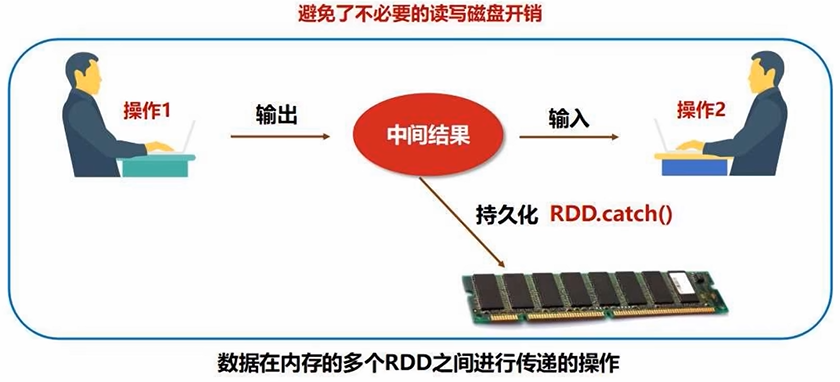
(1)惰性调用机制:前面对RDD的转换操作不会真正执行转换,只会记录转换轨迹,并不会真正发生计算。只有遇到第一个动作类型的操作,才会触发计算,执行从头到尾操作(从磁盘读取数据到输出)

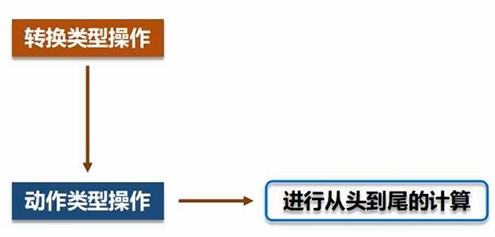
(2)管道化/流水线优化:转换过程中数据不用落地磁盘,直接把一个操作的输出,给另一个操作作为输入,避免了不必要的读写磁盘开销,也无需保存中间结果
(3)MapReuce写代码时,若应用复杂则需要写入非常复杂的代码;但Spark每个操作都很简单,串联起来的操作集合可以完成非常复杂的功能
Spark特性:
- 高效的容错性:现有容错机制是数据复制(数据备份)、记录日志(如关系数据库,操作写入日志,操作失败可回滚等),但这两种方式开销太大。Spark有天然容错性,恢复数据可通过DAG图寻亲,DAG图即血缘关系图
- 中间结果持久化内存:而不是到磁盘,没有频繁写磁盘,而且数据是在内存的多个RDD之间进行传递,避免了磁盘IO开销,同时也避免了不必要的序列化和反序列化开销
RDD运行原理(RDD之间的依赖关系):一个RDD应用会分成多个作业,一个作业会被分成很多阶段,为什么要分成多个阶段?以什么为依据拆分多个阶段?(看依赖关系是宽依赖还是窄依赖)
- 宽依赖:划分成多个阶段,包含shuffle操作(一个父RDD的分区对应多个子RDD的分区,如groupByKey、join)
- 窄依赖:不划分阶段,没有包含shuffle操作(一个父RDD的分区对应一个子RDD的分区,如map、filter;或多个父RDD的分区对应一个子RDD的分区,如join、union)
是否包含shuffle操作是划分宽窄依赖的依据
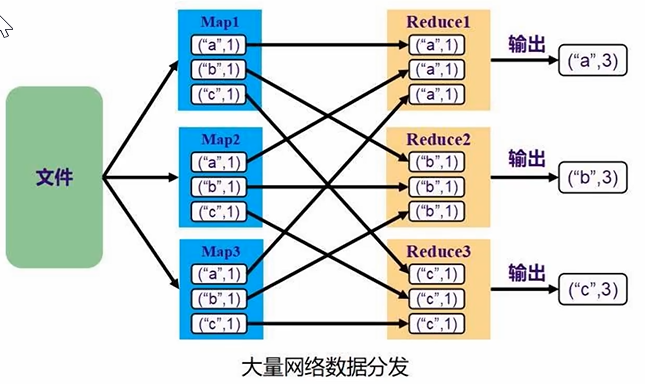
文件保存在HDFS中,进行多任务执行、分区处理。只要发生了shuffle操作,一定发生了来回交互的数据的分发。shuffle操作在网络中大规模地来回传输数据,不同节点之间互相传数据
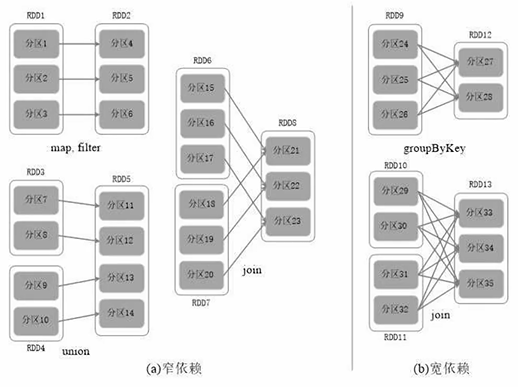
宽依赖需要分拆成两阶段,窄依赖不用。窄依赖能够有利于作业优化,即进行流水线优化(中间不落磁盘,不join);宽依赖不能进行流水线优化(只要发生shuffle一定会写磁盘,即落地等待)
Spark优化原理:fork/join机制(从一个RDD到另一个RDD的转换都是一个fork+一个join)。fork即并行执行分区转换,结果汇总是join
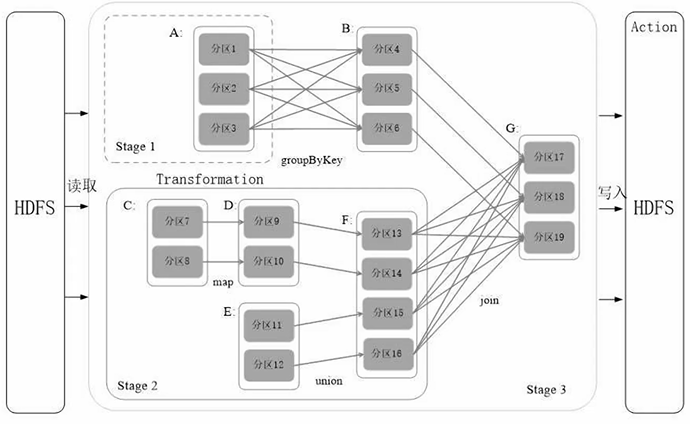
DAG有向无环图反向解析:遇到窄依赖就不断添加,形成管道化流水线处理;遇到宽依赖就断开,生成新的阶段Stage,因为要发生等待洗牌(宽依赖生成不同阶段,窄依赖不断加入阶段)
- 阶段Stage内部都是可以并行、流水线化处理;阶段之间都是发生了等待
(四)Spark部署方式
支持单机部署和集群部署。集群部署有以下三种:
- StandAlone模式:使用Spark自带的集群资源管理器来管理整个CPU、内存资源调度。效率不高
- Mesos模式:使用Mesos作为集群资源管理器。性能匹配好
- Spark on Yarn:用的最多
Hadoop包含存储框架HDFS、HBase、计算框架MapReduce等。Spark和Hadoop并不对等,而是可能取代MapReduce。Hadoop的HDFS、HBase会继续发挥存储功能,存储数据拿给计算框架Spark来计算分析,它们共同来满足企业的相关应用场景需求
第3章 Spark环境搭建和使用方法(5节)
(一)安装Spark
分布式计算框架,存储需要Hadoop,运行在Linux系统上;Spark底层最终编译成Java字节码运行,故需要Java环境(Spark 2.4.0需要Java 8以上或JDK 1.8以上;Hadoop 2.7.1)
安装Hadoop教程(包含了安装Java):Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0(2.7.1)/Ubuntu14.04(16.04)_厦大数据库实验室博客
安装Spark:Apache Spark™ - Unified Engine for large-scale data analytics
# 解压安装包spark-2.4.0-bin-without-hadoop.tgz至路径/usr/local
# usr是unix software resource
sudo tar -zxf ~/Downloads/spark-2.4.0-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-2.4.0-bin-without-hadoop/ ./spark # 更改文件夹名
sudo chown -R hadoop ./spark # 此处hadoop为系统用户名,把spark目录权限赋予hadoop用户# 配置Spark的classpath,这样Spark才能跟Hadoop挂接起来
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh # 拷贝配置文件vim ./conf/spark-env.sh
# 编辑该配置文件,在第一行加上如下一行内容
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)# 保存配置文件后,就可以用Spark去访问。若需要使用HDFS中的文件,则在使用Spark前需要启动Hadoop# 启动Spark Shell(Scala语言)
cd /usr/local/spark
bin/spark-shellSpark与Hadoop如何交互?Spark部署模式:
- Local模式/单机模式:把Hadoop配置成伪分布式模式(把NameNode和DataNode都放在一台笔记本电脑上)。注:HDFS的NameNode(数据目录)和DataNode(具体存储数据),一般为一主多从架构,即一个NameNode,其余全为DataNode
- 三种集群模式:
- Standalone模式:使用Spark自带的集群资源管理器,效率低
- Yarn模式:由Hadoop Yarn为Spark进行CPU和内存资源的调度
- Mesos模式:使用Mesos作为集群资源管理器
Spark单机版和Hadoop伪分布式可以交互,访问HDFS文件;Spark集群部署模式也是可以和Hadoop集群部署模式相互访问
(二)在PySpark中运行代码
PySpark是一个交互式的执行环境。Spark Shell也是一个交互式的执行环境,但它是Scala语言
开机启动进入Linux环境,Shell中输入命令,进入PySpark环境:
pyspark --master <master-url> # url不同,分别进入不同环境# 直接pyspark回车,为local[*]模式Spark的运行模式取决于传递给 SparkContext 的 master-url 的值。Master URL可以是以下任一种形式:
- local:本地运行模式。用一个worker线程本地化运行spark(完全不并行,单线程)
- local[*]:也是单机环境,但不是单线程(本地化,但有一定的并行程度)。使用逻辑CPU个数(整个物理CPU个数*每个CPU核数)数量的线程来本地化运行spark
- local[K]:使用K个worker线程本地化运行spark(理想情况下,K应根据运行机器的CPU核数设定)
- spark://HOST:PORT:集群模式。HOST为主机名(如localhost),PORT是端口号(默认端口是7077)。连接到指定的Spark standalone master
- mesos://HOST:PORT:连接到指定的mesos集群,默认接口是5050
取决于运行Spark时的driver节点(SparkContext)建在哪里:
- yarn-client:集群模式,资源调度管理器为yarn。用在程序开发人员调试程序时用,以客户端模式连接YARN集群,集群的位置可以在HADOOP_CONF_DIR环境变量中找到
- yarn-cluster:集群模式,资源调度管理器为yarn。用在企业产品生产上线时用,以集群模式连接YARN集群,集群的位置可以在HADOOP_CONF_DIR环境变量中找到
- yarn:默认为yarn-client
在Spark中采用本地模式启动PySpark的命令主要包含以下参数:
- --master:表示当前的pyspark要连接到哪个master。如果是local[*],就是使用本地模式启动pyspark,其中括号内的星号表示需要使用几个CPU核心,也就是启动几个线程模拟Spark集群
- --jars:用于把相关的jar包添加到classpath中。如果有多个jar包,可以使用逗号分隔符连接它们
执行 pyspark --help 命令,获取完整的选项列表:
cd /usr/local/spark
./bin/pyspark --help执行如下命令启动pyspark(默认是local模式):
./bin/pyspark启动pyspark成功后在输出信息的末尾可以看到 >>> 的命令提示符。使用命令 exit() 退出pyspark
(三)开发Spark独立应用程序
编写程序:
# WordCount.py 统计文本文件中包含a的行的个数和b的行的个数
from pyspark import SparkConf, SparkContextconf = SparkConf().setMaster("local").setAppName("My App") # 生成配置的上下文信息
# MasterURL取值为local模式;通过网页查看管理时可以看到应用名称为My Appsc = SparkContext(conf = conf) # 生成SparkContext对象logFile = "file:///usr/local/spark/README.md" # 若是本地文件,是file:///logData = sc.textFile(logFile,2).cache() # 把文本文件加载进来生成RDD
# RDD里包含很多元素,每个元素对应一行文本numAs = logData.filter(lambda line: 'a' in line).count() # 过滤出所有包含单词a的行
# lambda为匿名函数
# 把包含单词a的行全过滤出来,放在一个新的RDD中,再.count()统计numBs = logData.filter(lambda line: 'b' in line).count() # 过滤出所有包含单词b的行print('Lines with a:%s, Lines with b:%s' % (numAs,numBs))
对于这段Python代码,可以直接使用如下命令执行:
cd /usr/local/spark/mycode/python
python3 WordCount.py通过spark-submit运行程序:
spark-submit
--master <master-url>
--deploy-mode <deploy-mode> # 部署模式
... # 其它参数
<application-file> # Python代码文件
[application-arguments] # 传递给主类的主方法的参数执行 spark-submit --help 命令,获取完整的选项列表:
cd /usr/local/spark
./bin/spark-submit --help如上述代码以这种方式运行:
# 通过spark-submit提交到Spark中运行
/usr/local/spark/bin/spark-submit /usr/local/spark/mycode/python/WordCount.py# 在命令中间使用“\”符号,把一行完整命令人为断开成多行进行输入
/usr/local/spark/bin/spark-submit \
/usr/local/spark/mycode/python/WordCount.py为了避免其他多余信息对运行结果干扰,可以修改log4j的日志信息显示级别
从 log4j.rootCategory = INFO, console 改成 log4j.rootCategory = ERROR, console
(四)Spark集群环境搭建
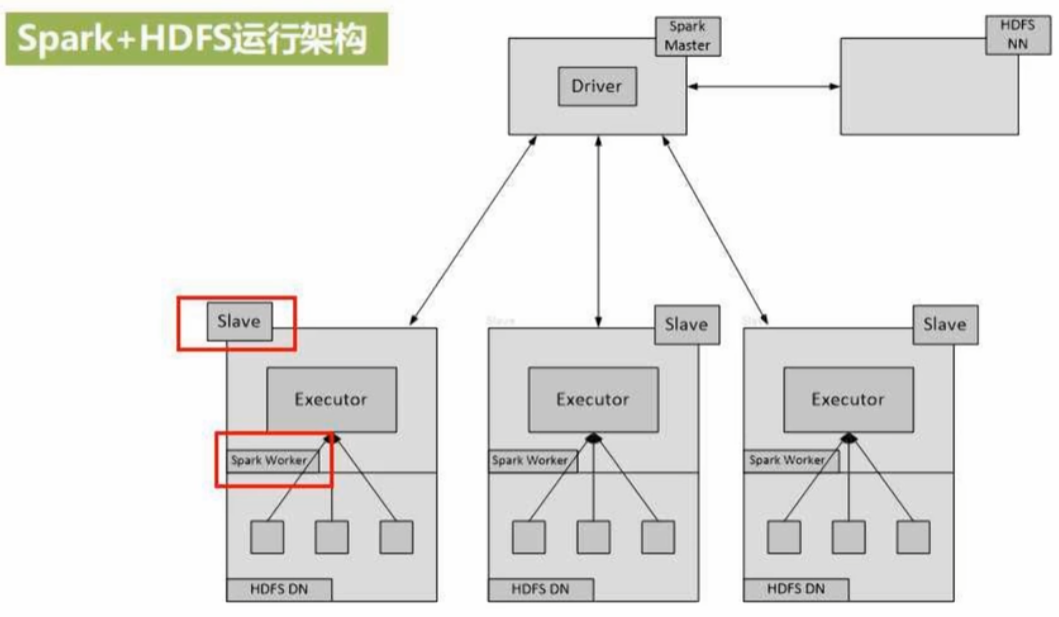
假设有3台机器搭建集群:Master、Slave01、Slave02,且在搭建Spark集群之前,Hadoop集群的构建已经完成(Hadoop 2.7分布式集群环境搭建_厦大数据库实验室博客)

Hadoop集群两大核心组件:NameNode(一个)、DataNode(多个),即一主多从
Spark集群:Driver Node(一个),Worker Node(多个,负责具体任务计算,且实行数据的本地化处理,数据在哪Worker Node就在哪),即一主多从
一台机器上,既部署了Hadoop的DataNode,也部署了Spark的Worker Node,即HDFS里的DataNode和Spark的Worker Node共存。这样Spark的Worker Node可以对Hadoop的DataNode数据进行本地化计算
主节点为master,在master节点上安装Spark,和单机时步骤一样:
# 解压安装包spark-2.4.0-bin-without-hadoop.tgz至路径/usr/local
# usr是unix software resource
sudo tar -zxf ~/Downloads/spark-2.4.0-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-2.4.0-bin-without-hadoop/ ./spark # 更改文件夹名
sudo chown -R hadoop ./spark # 此处hadoop为系统用户名,把spark目录权限赋予hadoop用户再执行以下命令:
# 在master节点主机的终端中执行
vim ~/.bashrc # 隐藏文件# 在.bashrc添加如下配置
export SPARK_HOME = /usr/local/spark
export PATH = $PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin# 运行source命令,使配置生效
source ~/.bashrc接下来配置从节点slaves文件:
# 将slaves.template拷贝到slaves
cd /usr/local/spark
cp ./conf/slaves.template ./conf/slaves# 编辑./conf/slaves,设置WorkerNode,把默认内容localhost替换成如下内容,一行一个
# 主机名称,从节点位于这两个主机上
slave01
slave02# 配置spark-env.sh文件
cp ./conf/spark-env.sh.template ./conf/spark-env.sh # 将spark-env.sh.template拷贝到spark-env.sh# 编辑spark-env.sh,添加如下内容
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath) # 完成Spark和Hadoop的挂接
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop # 说明Hadoop相关配置信息的目录
export SPARK_MASTER_IP=192.168.1.104 # 设置Spark管家节点的IP地址# 将master主机上的/usr/local/spark文件夹复制到各个节点上
cd /usr/local/
tar -zcf ~/spark.master.tar.gz ./spark # 把主节点spark安装目录打包成文件
cd ~
scp ./spark.master.tar.gz slave01:/home/hadoop # 把压缩包拷贝到两个从节点上
scp ./spark.master.tar.gz slave02:/home/hadoop# 在从节点目录下执行解压缩操作
sudo rm -rf /usr/local/spark/
sudo tar -zxf ~/spark.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/spark # 赋权限在master节点主机上运行:
# 首先启动Hadoop集群
# Spark集群与Hadoop集群是搭配使用,Hadoop存数据,Spark计算
cd /usr/local/hadoop/
sbin/start-all.sh# 启动master节点,在master节点主机上运行如下命令
cd /usr/local/spark/
sbin/start-master.sh# 启动所有Slave节点,在master节点主机上运行(启动从节点是在主节点上启动)
sbin/start-slaves.sh# 在master主机上打开浏览器,访问http://master:8080如何关闭Spark集群?
# 关闭master节点(master节点上运行)
sbin/stop-master.sh# 关闭Worker节点(master节点上运行)
sbin/stop-slaves.sh# 关闭Hadoop集群
cd /usr/local/hadoop/
sbin/stop-all.sh(五)在集群上运行Spark应用程序
1、启动Spark集群
以下命令均在master节点上运行:
启动Hadoop集群:
cd /usr/local/hadoop/
sbin/start-all.sh启动Spark的master节点和所有slaves节点:
cd /usr/local/spark/ # 进入spark安装目录
sbin/start-master.sh # 启动主节点
sbin/start-slaves.sh # 启动从节点2、采用独立集群管理器(standalone)
(1)在集群中运行应用程序JAR包:需要把spark://host:port作为主节点参数传递给spark-submit
用一个程序提交给集群去算Π的值:
cd /usr/local/spark/
bin/spark-submit \
--master spark://master:7077 \ # 连接到Standalone独立集群模式,使用自带的集群资源管理器
/usr/local/spark/examples/src/main/python/pi.py 2>&1 | grep "Pi is roughly" # 过滤出有用信息
# 结果为Pi is roughly 3.1415926(2)在集群中运行Pyspark:
cd /usr/local/spark/
bin/pyspark --master spark://master:7077 # Standalone模式连接到Spark集群# 进入交互式运行环境
textFile = sc.textFile("hdfs://master:9000/README.md") # 把底层文件(分布式文件系统hdfs里的文件)加载进来生成RDD
# hdfs是hdfs://,本地文件是file:///
textFile.count() # 统计有多少行
textFile.first() # 取出第一行内容运行后查看集群信息(用户在独立集群管理Web界面查看应用的运行情况):http://master:8080/
3、采用Hadoop YARN管理器
- yarn-client:调试,客户端建指挥所,客户端提交应用程序后不能关闭
- yarn-cluster:集群里建指挥所,客户端提交应用程序后可以关闭客户端
spark-submit:
cd /usr/local/spark/
bin/spark-submit \
--master yarn-client \ # yarn-client用来调试
/usr/local/spark/examples/src/main/python/pi.py确保Hadoop集群已经启动。运行后,根据在shell中得到的输出结果地址查看(tracking URL),复制结果地址到浏览器,点击查看Logs,再点击stdout,即可查看结果
在集群中运行pyspark:也可以用pyspark连接到采用Yarn作为集群管理器的集群上(交互式)
bin/pyspark --master yarn # 默认yarn-client模式# 假设HDFS根目录下已存在一个文件README.md,在pyspark环境中执行相关语句
textFile = sc.textFile("hdfs://master:9000/README.md")
textFile.count() # 统计RDD有多少元素
textFile.first() # 取出第一行内容在Hadoop Yarn集群管理Web界面(http://master:8088/cluster)查看所有应用的运行情况
相关文章:
【1-3章】Spark编程基础(Python版)
课程资源:(林子雨)Spark编程基础(Python版)_哔哩哔哩_bilibili 第1章 大数据技术概述(8节) 第三次信息化浪潮:以物联网、云计算、大数据为标志 (一)大数据 大数据时代到来的原因…...
宇宙原理:黑洞基础。
宇宙原理:黑洞基础TOC 黑洞的数理基础:一个由满数组成的数盘,经过自然演进,将会逐步稀疏化、最终会向纯数方案发展;纯数方案虽然只有{2}、无数(虚拟)、{0,1,2,3}(虚拟)、…...
分类预测 | MATLAB实现SCNGO-CNN-LSTM-Attention数据分类预测
分类预测 | MATLAB实现SCNGO-CNN-LSTM-Attention数据分类预测 目录 分类预测 | MATLAB实现SCNGO-CNN-LSTM-Attention数据分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.SCNGO-CNN-LSTM-Attention数据分类预测程序,改进算法,融合正余弦和…...
Android学习之路(7) Frament
Fragment 表示应用界面中可重复使用的一部分。fragment 定义和管理自己的布局,具有自己的生命周期,并且可以处理自己的输入事件。fragment 不能独立存在。它们必须由 activity 或其他 fragment 托管。fragment 的视图层次结构会成为宿主的视图层次结构的…...

metallb , istio ingress 部署httpbin使用例子
安装metaillb,参考:Kubernetes的负载均衡方案:MetalLB - 文章详情 wget https://raw.githubusercontent.com/metallb/metallb/v0.13.7/config/manifests/metallb-frr.yaml -O metallb.yaml kubectl apply -f metallb-frr.yaml 配置负载均衡ip池 apiVe…...
基于swing的销售管理系统java仓库库存信息jsp源代码mysql
本项目为前几天收费帮学妹做的一个项目,Java EE JSP项目,在工作环境中基本使用不到,但是很多学校把这个当作编程入门的项目来做,故分享出本项目供初学者参考。 一、项目描述 基于swing的销售管理系统 系统有1权限:管…...
FreeCAD傻瓜式教程之约束设定和构建实体、开孔、调整颜色等
本内容基于官方教程中的绘制简单的零件中的体会,在初次绘制的时候,总是无法完成,几经尝试才发现其关键点所在,以此文记录,用以被查资料,同时也希望能够帮到纯白新手快速熟悉该软件的绘图方法。 一、. 打开…...
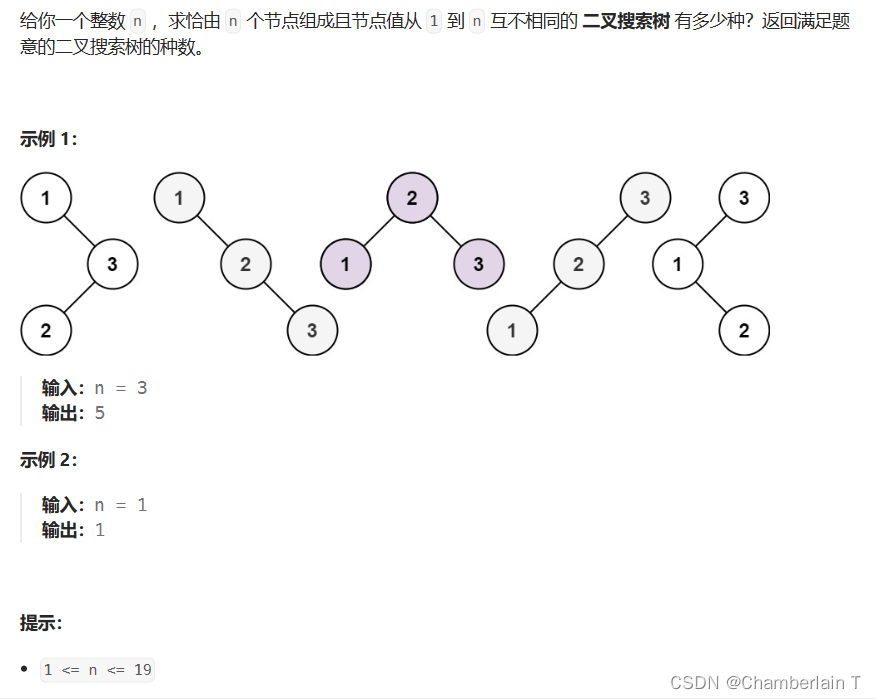
代码随想录算法训练营day41 | 343. 整数拆分,96. 不同的二叉搜索树
目录 343. 整数拆分 96. 不同的二叉搜索树 343. 整数拆分 类型:动态规划 难度:medium 思路: dp[i]所用的拆分方法至少已经拆分了两次,比如dp[2]1,小于2,在大于2的数中,最后的2是不会拆的。 …...

飞天使-k8sv1.14二进制安装
文章目录 安装前准备安装前设置分发脚本 开始安装k8s集群cfssl 安装部署kubectl命令行工具创建admin证书和私钥创建kubeconfig文件部署ETCD集群部署Flannel网络kube-apiserver 高可用KeepLived 部署部署master节点部署高可用kube-controller-manager集群kube-controller-manage…...

TypeScript封装Axios
TypeScript封装Axios Axios的基本使用 因axios基础使用十分简单,可参考axios官方文档,这里不在介绍他基本用法,主要讲解拦截器。 拦截器主要分为两种,请求拦截器和响应拦截器。 请求拦截器:请求发送之前进行拦截&…...

指针(一)【C语言进阶版】
大家好,我是深鱼~ 【前言】: 指针的主题,在初阶指针章节已经接触过了,我们知道了指针的概念: 1.指针就是个变量,用来存放地址,地址的唯一标识一块内存空间(指针变量)&a…...

回归预测 | MATLAB实现SA-BP模拟退火算法优化BP神经网络多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现SA-BP模拟退火算法优化BP神经网络多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现SA-BP模拟退火算法优化BP神经网络多输入单输出回归预测(多指标,多图)效果一览基本介…...
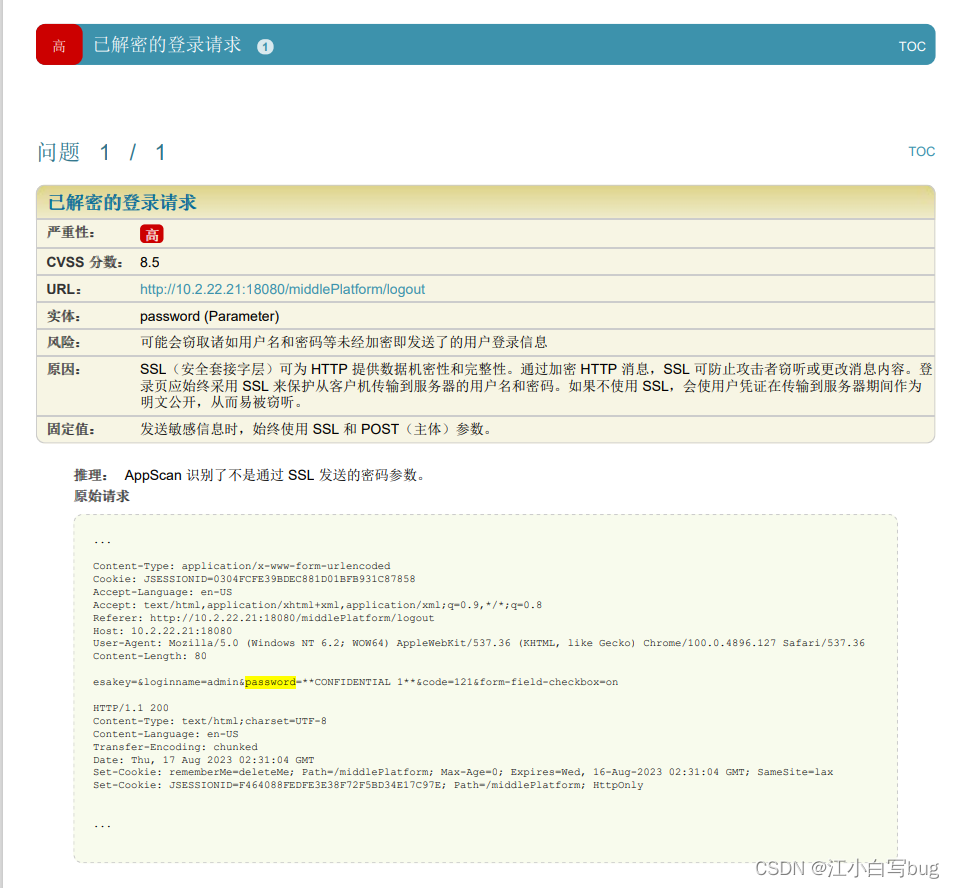
springMVC 已解密的登录请求
问题描述: 解决方案: 1.对用户所输入的密码在页面进行MD5加密并反馈至密码输入框。 2. 手动生成SSL安全访问证书;在此不做介绍,相关方法可通过网上查找; 3. 将产品HTTP访问方式改为SSL安全访问方式;在Ap…...
机器学习赋能乳腺癌预测:如何使用贝叶斯分级进行精确诊断?
一、引言 乳腺癌是女性最常见的恶性肿瘤之一,也会发生在男性身上。每年全球有数百万人被诊断出乳腺癌,对患者的生活和健康造成了巨大的影响。早期的乳腺癌检测和准确的诊断对于提高治疗的成功率至关重要。然而,乳腺癌的早期诊断面临着许多挑战…...

Java后端开发面试题——框架篇
Spring框架中的bean是单例的吗?Spring框架中的单例bean是线程安全的吗? singleton : bean在每个Spring IOC容器中只有一个实例。 prototype:一个bean的定义可以有多个实例。 Spring bean并没有可变的状态(比如Service类和DAO类),…...

【新版】系统架构设计师 - 系统测试与维护
个人总结,仅供参考,欢迎加好友一起讨论 文章目录 架构 - 系统测试与维护考点摘要软件测试软件测试 - 测试类型软件测试 - 静态测试软件测试 - 动态测试软件测试 - 测试阶段软件测试 - 测试阶段 - 单元测试软件测试 - 测试阶段 - 集成测试软件测试 - 测试…...

使用 useEffect 和 reactStrictMode:优化 React 组件的性能和可靠性
使用useEffect和React.StrictMode是一种优化React组件性能和可靠性的常见做法。下面是关于如何使用这两个特性的示例: import React, { useEffect } from react;function MyComponent() {useEffect(() > {// 在组件挂载/更新时执行的副作用代码// 可以进行数据获…...
商业智能BI是什么都不明白,如何实现数字化?
2021年下半年中国商业智能软件市场规模为4.8亿美元,2021年度市场规模达到7.8亿美元,同比增长34.9%,呈现飞速增长的趋势。数字化时代,商业智能BI对于企业的落地应用有着巨大价值,逐渐成为了现代企业信息化、数字化转型中…...
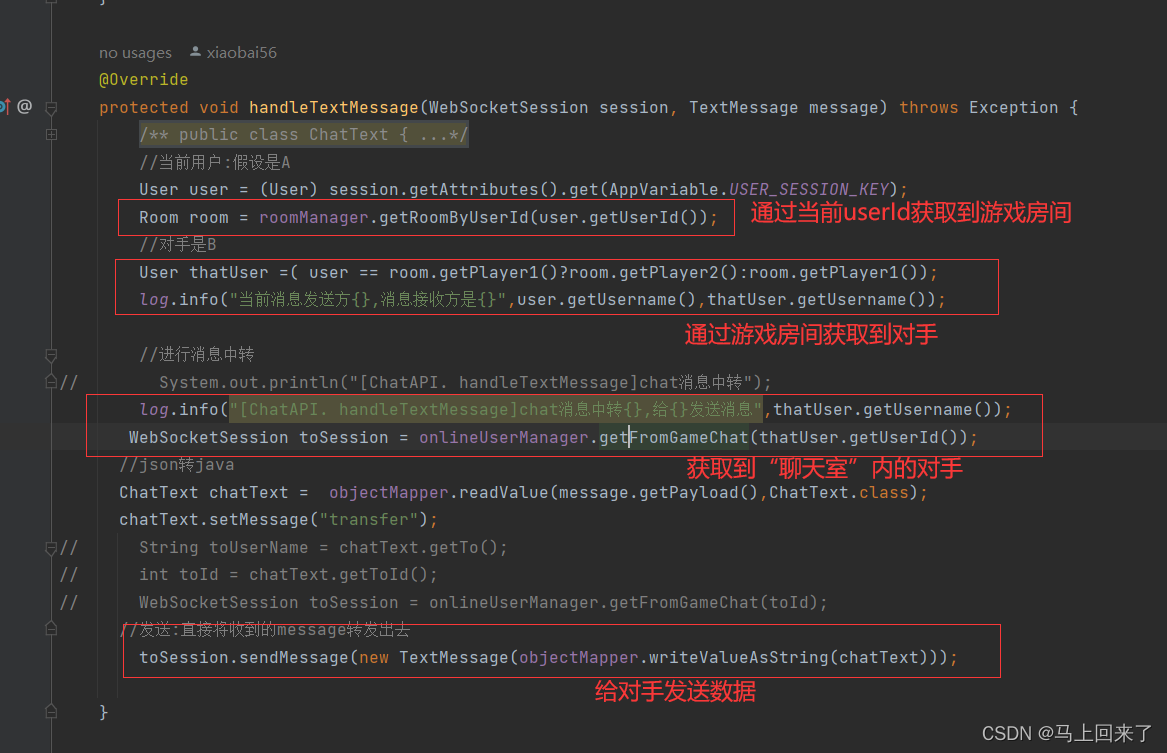
【五子棋】
五子棋 文章目录 五子棋前言一、登录功能二.哈希表管理用户的会话和房间三.基于Websocket连接开发的功能1.匹配功能2.游戏房间3.挑战功能4.人机对战5.聊天功能 前言 这篇博客主要详细介绍我的五子棋项目的核心功能的实现细节,也就是详细介绍五子棋各个功能是如何实…...
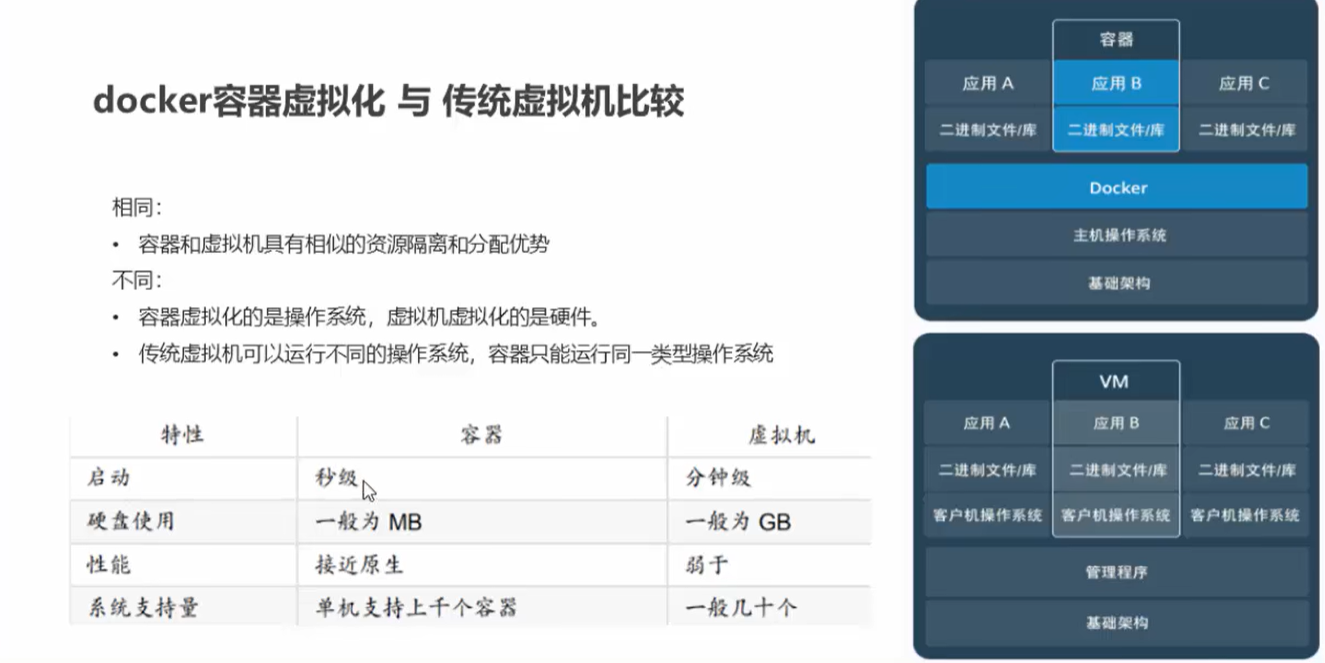
docker 01(初识docker)
一、docker概念 Docker是一个开源的应用容器引擎;诞生于2013年初,基于Go 语言实现,dotCloud公司出品(后改名为Dockerlnc);Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的Linux …...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...

【 java 虚拟机知识 第一篇 】
目录 1.内存模型 1.1.JVM内存模型的介绍 1.2.堆和栈的区别 1.3.栈的存储细节 1.4.堆的部分 1.5.程序计数器的作用 1.6.方法区的内容 1.7.字符串池 1.8.引用类型 1.9.内存泄漏与内存溢出 1.10.会出现内存溢出的结构 1.内存模型 1.1.JVM内存模型的介绍 内存模型主要分…...

wpf在image控件上快速显示内存图像
wpf在image控件上快速显示内存图像https://www.cnblogs.com/haodafeng/p/10431387.html 如果你在寻找能够快速在image控件刷新大图像(比如分辨率3000*3000的图像)的办法,尤其是想把内存中的裸数据(只有图像的数据,不包…...
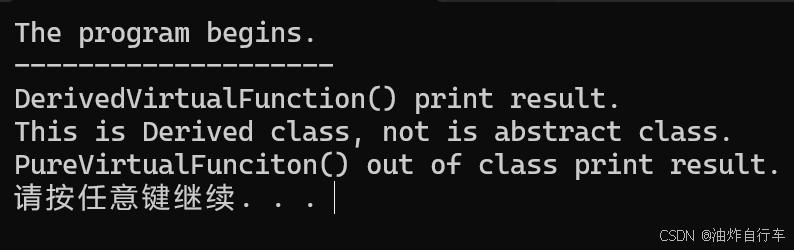
【C++】纯虚函数类外可以写实现吗?
1. 答案 先说答案,可以。 2.代码测试 .h头文件 #include <iostream> #include <string>// 抽象基类 class AbstractBase { public:AbstractBase() default;virtual ~AbstractBase() default; // 默认析构函数public:virtual int PureVirtualFunct…...