计算机竞赛 卷积神经网络手写字符识别 - 深度学习
文章目录
- 0 前言
- 1 简介
- 2 LeNet-5 模型的介绍
- 2.1 结构解析
- 2.2 C1层
- 2.3 S2层
- S2层和C3层连接
- 2.4 F6与C5层
- 3 写数字识别算法模型的构建
- 3.1 输入层设计
- 3.2 激活函数的选取
- 3.3 卷积层设计
- 3.4 降采样层
- 3.5 输出层设计
- 4 网络模型的总体结构
- 5 部分实现代码
- 6 在线手写识别
- 7 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 卷积神经网络手写字符识别 - 深度学习
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate

1 简介
该设计学长使用python基于TensorFlow设计手写数字识别算法,并编程实现GUI界面,构建手写数字识别系统。
这是学长做的深度学习demo,大家可以用于毕业设计。
这里学长不会以论文的形式展现,而是以编程实战完成深度学习项目的角度去描述。
项目要求:主要解决的问题是手写数字识别,最终要完成一个识别系统。
设计识别率高的算法,实现快速识别的系统。
2 LeNet-5 模型的介绍
学长实现手写数字识别,使用的是卷积神经网络,建模思想来自LeNet-5,如下图所示:

2.1 结构解析
这是原始的应用于手写数字识别的网络,我认为这也是最简单的深度网络。
LeNet-5不包括输入,一共7层,较低层由卷积层和最大池化层交替构成,更高层则是全连接和高斯连接。
LeNet-5的输入与BP神经网路的不一样。这里假设图像是黑白的,那么LeNet-5的输入是一个32*32的二维矩阵。同
时,输入与下一层并不是全连接的,而是进行稀疏连接。本层每个神经元的输入来自于前一层神经元的局部区域(5×5),卷积核对原始图像卷积的结果加上相应的阈值,得出的结果再经过激活函数处理,输出即形成卷积层(C层)。卷积层中的每个特征映射都各自共享权重和阈值,这样能大大减少训练开销。降采样层(S层)为减少数据量同时保存有用信息,进行亚抽样。
2.2 C1层
第一个卷积层(C1层)由6个特征映射构成,每个特征映射是一个28×28的神经元阵列,其中每个神经元负责从5×5的区域通过卷积滤波器提取局部特征。一般情况下,滤波器数量越多,就会得出越多的特征映射,反映越多的原始图像的特征。本层训练参数共6×(5×5+1)=156个,每个像素点都是由上层5×5=25个像素点和1个阈值连接计算所得,共28×28×156=122304个连接。
2.3 S2层
S2层是对应上述6个特征映射的降采样层(pooling层)。pooling层的实现方法有两种,分别是max-pooling和mean-
pooling,LeNet-5采用的是mean-
pooling,即取n×n区域内像素的均值。C1通过2×2的窗口区域像素求均值再加上本层的阈值,然后经过激活函数的处理,得到S2层。pooling的实现,在保存图片信息的基础上,减少了权重参数,降低了计算成本,还能控制过拟合。本层学习参数共有1*6+6=12个,S2中的每个像素都与C1层中的2×2个像素和1个阈值相连,共6×(2×2+1)×14×14=5880个连接。
S2层和C3层连接
S2层和C3层的连接比较复杂。C3卷积层是由16个大小为10×10的特征映射组成的,当中的每个特征映射与S2层的若干个特征映射的局部感受野(大小为5×5)相连。其中,前6个特征映射与S2层连续3个特征映射相连,后面接着的6个映射与S2层的连续的4个特征映射相连,然后的3个特征映射与S2层不连续的4个特征映射相连,最后一个映射与S2层的所有特征映射相连。
此处卷积核大小为5×5,所以学习参数共有6×(3×5×5+1)+9×(4×5×5+1)+1×(6×5×5+1)=1516个参数。而图像大小为28×28,因此共有151600个连接。
S4层是对C3层进行的降采样,与S2同理,学习参数有16×1+16=32个,同时共有16×(2×2+1)×5×5=2000个连接。
C5层是由120个大小为1×1的特征映射组成的卷积层,而且S4层与C5层是全连接的,因此学习参数总个数为120×(16×25+1)=48120个。
2.4 F6与C5层
F6是与C5全连接的84个神经元,所以共有84×(120+1)=10164个学习参数。
卷积神经网络通过通过稀疏连接和共享权重和阈值,大大减少了计算的开销,同时,pooling的实现,一定程度上减少了过拟合问题的出现,非常适合用于图像的处理和识别。
3 写数字识别算法模型的构建
3.1 输入层设计
输入为28×28的矩阵,而不是向量。

3.2 激活函数的选取
Sigmoid函数具有光滑性、鲁棒性和其导数可用自身表示的优点,但其运算涉及指数运算,反向传播求误差梯度时,求导又涉及乘除运算,计算量相对较大。同时,针对本文构建的含有两层卷积层和降采样层,由于sgmoid函数自身的特性,在反向传播时,很容易出现梯度消失的情况,从而难以完成网络的训练。因此,本文设计的网络使用ReLU函数作为激活函数。
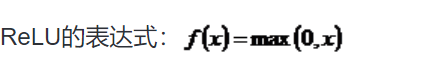
3.3 卷积层设计
学长设计卷积神经网络采取的是离散卷积,卷积步长为1,即水平和垂直方向每次运算完,移动一个像素。卷积核大小为5×5。
3.4 降采样层
学长设计的降采样层的pooling方式是max-pooling,大小为2×2。
3.5 输出层设计
输出层设置为10个神经网络节点。数字0~9的目标向量如下表所示:

4 网络模型的总体结构

5 部分实现代码
使用Python,调用TensorFlow的api完成手写数字识别的算法。
注:我的程序运行环境是:Win10,python3.。
当然,也可以在Linux下运行,由于TensorFlow对py2和py3兼容得比较好,在Linux下可以在python2.7中运行。
#!/usr/bin/env python2# -*- coding: utf-8 -*-"""@author: 丹成学长 Q746876041"""#import modulesimport numpy as npimport matplotlib.pyplot as plt#from sklearn.metrics import confusion_matriximport tensorflow as tfimport timefrom datetime import timedeltaimport mathfrom tensorflow.examples.tutorials.mnist import input_datadef new_weights(shape):return tf.Variable(tf.truncated_normal(shape,stddev=0.05))def new_biases(length):return tf.Variable(tf.constant(0.1,shape=length))def conv2d(x,W):return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')def max_pool_2x2(inputx):return tf.nn.max_pool(inputx,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')#import datadata = input_data.read_data_sets("./data", one_hot=True) # one_hot means [0 0 1 0 0 0 0 0 0 0] stands for 2print("Size of:")print("--Training-set:\t\t{}".format(len(data.train.labels)))print("--Testing-set:\t\t{}".format(len(data.test.labels)))print("--Validation-set:\t\t{}".format(len(data.validation.labels)))data.test.cls = np.argmax(data.test.labels,axis=1) # show the real test labels: [7 2 1 ..., 4 5 6], 10000valuesx = tf.placeholder("float",shape=[None,784],name='x')x_image = tf.reshape(x,[-1,28,28,1])y_true = tf.placeholder("float",shape=[None,10],name='y_true')y_true_cls = tf.argmax(y_true,dimension=1)# Conv 1layer_conv1 = {"weights":new_weights([5,5,1,32]),"biases":new_biases([32])}h_conv1 = tf.nn.relu(conv2d(x_image,layer_conv1["weights"])+layer_conv1["biases"])h_pool1 = max_pool_2x2(h_conv1)# Conv 2layer_conv2 = {"weights":new_weights([5,5,32,64]),"biases":new_biases([64])}h_conv2 = tf.nn.relu(conv2d(h_pool1,layer_conv2["weights"])+layer_conv2["biases"])h_pool2 = max_pool_2x2(h_conv2)# Full-connected layer 1fc1_layer = {"weights":new_weights([7*7*64,1024]),"biases":new_biases([1024])}h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64])h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,fc1_layer["weights"])+fc1_layer["biases"])# Droupout Layerkeep_prob = tf.placeholder("float")h_fc1_drop = tf.nn.dropout(h_fc1,keep_prob)# Full-connected layer 2fc2_layer = {"weights":new_weights([1024,10]),"biases":new_weights([10])}# Predicted classy_pred = tf.nn.softmax(tf.matmul(h_fc1_drop,fc2_layer["weights"])+fc2_layer["biases"]) # The output is like [0 0 1 0 0 0 0 0 0 0]y_pred_cls = tf.argmax(y_pred,dimension=1) # Show the real predict number like '2'# cost function to be optimizedcross_entropy = -tf.reduce_mean(y_true*tf.log(y_pred))optimizer = tf.train.AdamOptimizer(learning_rate=1e-4).minimize(cross_entropy)# Performance Measurescorrect_prediction = tf.equal(y_pred_cls,y_true_cls)accuracy = tf.reduce_mean(tf.cast(correct_prediction,"float"))with tf.Session() as sess:init = tf.global_variables_initializer()sess.run(init)train_batch_size = 50def optimize(num_iterations):total_iterations=0start_time = time.time()for i in range(total_iterations,total_iterations+num_iterations):x_batch,y_true_batch = data.train.next_batch(train_batch_size)feed_dict_train_op = {x:x_batch,y_true:y_true_batch,keep_prob:0.5}feed_dict_train = {x:x_batch,y_true:y_true_batch,keep_prob:1.0}sess.run(optimizer,feed_dict=feed_dict_train_op)# Print status every 100 iterations.if i%100==0:# Calculate the accuracy on the training-set.acc = sess.run(accuracy,feed_dict=feed_dict_train)# Message for printing.msg = "Optimization Iteration:{0:>6}, Training Accuracy: {1:>6.1%}"# Print it.print(msg.format(i+1,acc))# Update the total number of iterations performedtotal_iterations += num_iterations# Ending timeend_time = time.time()# Difference between start and end_times.time_dif = end_time-start_time# Print the time-usageprint("Time usage:"+str(timedelta(seconds=int(round(time_dif)))))test_batch_size = 256def print_test_accuracy():# Number of images in the test-set.num_test = len(data.test.images)cls_pred = np.zeros(shape=num_test,dtype=np.int)i = 0while i < num_test:# The ending index for the next batch is denoted j.j = min(i+test_batch_size,num_test)# Get the images from the test-set between index i and jimages = data.test.images[i:j, :]# Get the associated labelslabels = data.test.labels[i:j, :]# Create a feed-dict with these images and labels.feed_dict={x:images,y_true:labels,keep_prob:1.0}# Calculate the predicted class using Tensorflow.cls_pred[i:j] = sess.run(y_pred_cls,feed_dict=feed_dict)# Set the start-index for the next batch to the# end-index of the current batchi = jcls_true = data.test.clscorrect = (cls_true==cls_pred)correct_sum = correct.sum()acc = float(correct_sum) / num_test# Print the accuracymsg = "Accuracy on Test-Set: {0:.1%} ({1}/{2})"print(msg.format(acc,correct_sum,num_test))# Performance after 10000 optimization iterationsoptimize(num_iterations=10000)print_test_accuracy()savew_hl1 = layer_conv1["weights"].eval()saveb_hl1 = layer_conv1["biases"].eval()savew_hl2 = layer_conv2["weights"].eval()saveb_hl2 = layer_conv2["biases"].eval()savew_fc1 = fc1_layer["weights"].eval()saveb_fc1 = fc1_layer["biases"].eval()savew_op = fc2_layer["weights"].eval()saveb_op = fc2_layer["biases"].eval()np.save("savew_hl1.npy", savew_hl1)np.save("saveb_hl1.npy", saveb_hl1)np.save("savew_hl2.npy", savew_hl2)np.save("saveb_hl2.npy", saveb_hl2)np.save("savew_hl3.npy", savew_fc1)np.save("saveb_hl3.npy", saveb_fc1)np.save("savew_op.npy", savew_op)np.save("saveb_op.npy", saveb_op)运行结果显示:测试集中准确率大概为99.2%。

查看混淆矩阵

6 在线手写识别
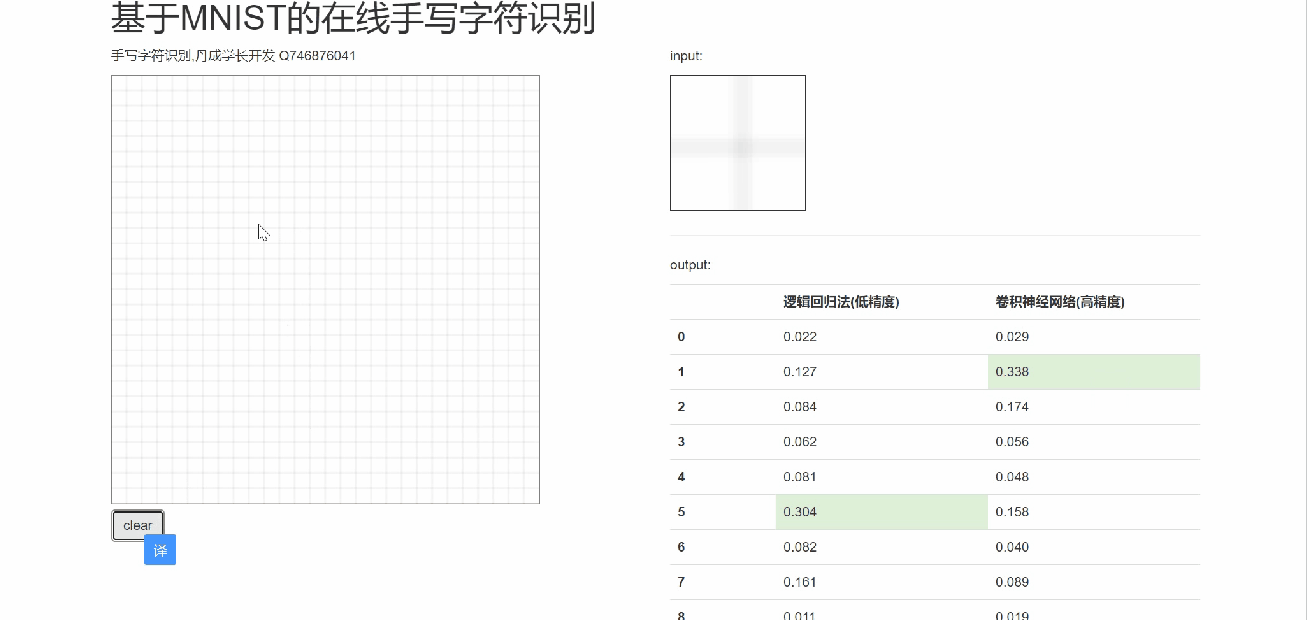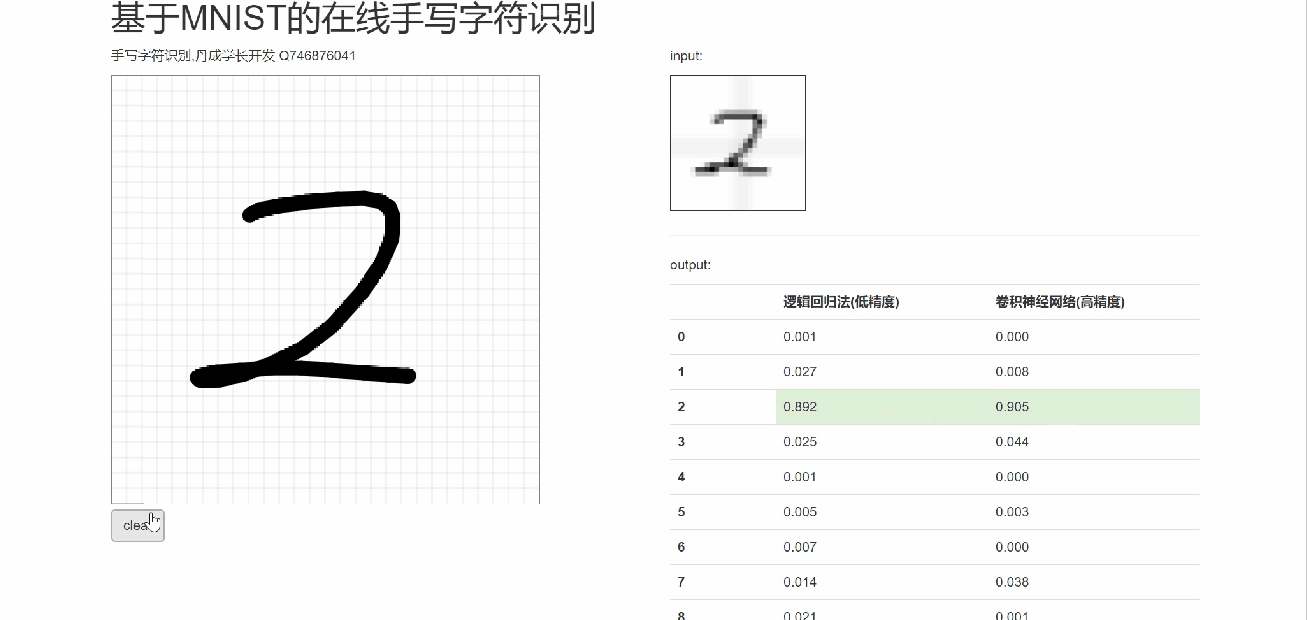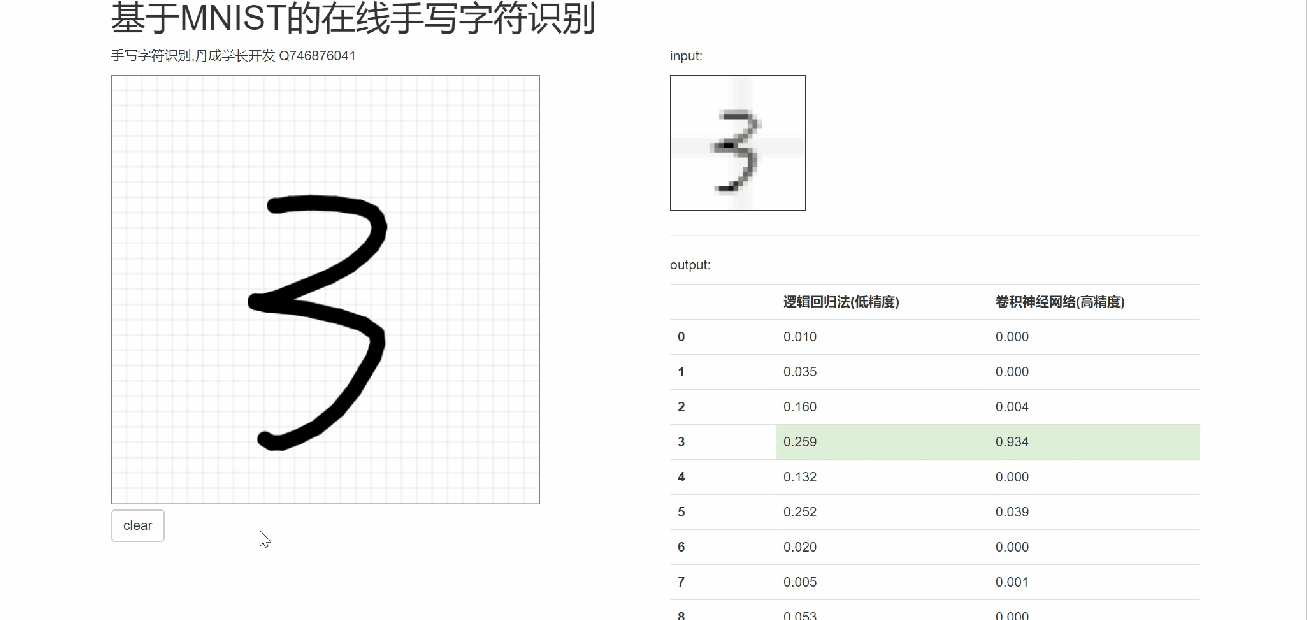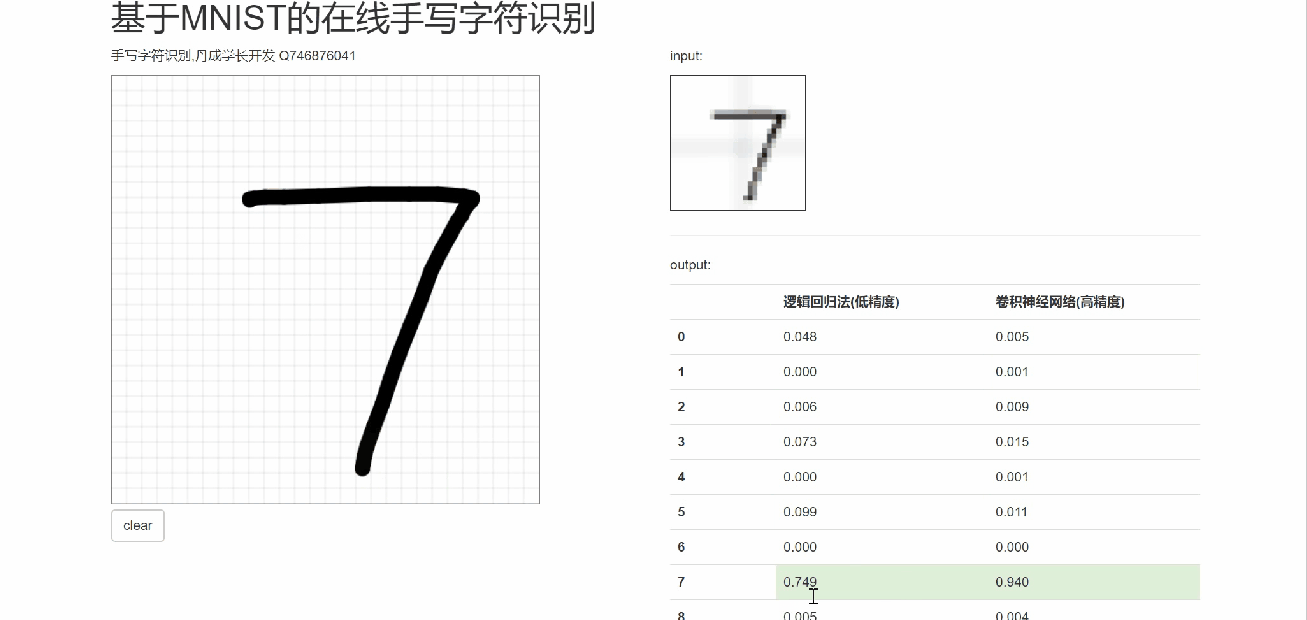
7 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
计算机竞赛 卷积神经网络手写字符识别 - 深度学习
文章目录 0 前言1 简介2 LeNet-5 模型的介绍2.1 结构解析2.2 C1层2.3 S2层S2层和C3层连接 2.4 F6与C5层 3 写数字识别算法模型的构建3.1 输入层设计3.2 激活函数的选取3.3 卷积层设计3.4 降采样层3.5 输出层设计 4 网络模型的总体结构5 部分实现代码6 在线手写识别7 最后 0 前言…...

[Go版]算法通关村第十三关白银——数组实现加法和幂运算
目录 数组实现加法专题题目:数组实现整数加法思路分析:复杂度:Go代码 题目:字符串加法思路分析:复杂度:Go代码 题目:二进制加法思路分析:复杂度:Go代码 幂运算专题题目&a…...
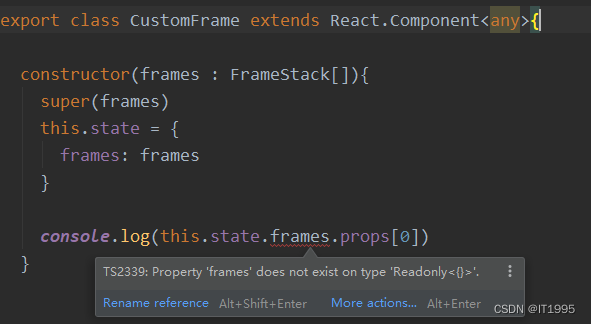
React笔记[tsx]-解决Property ‘frames‘ does not exist on type ‘Readonly<{}>‘
浏览器报错如下: 编辑器是这样的: 原因是React.Component<any>少了后面的any,改成这样即可: export class CustomFrame extends React.Component<any, any>{............ }...

ThinkPHP6.0+ 使用Redis 原始用法
composer 安装 predis/predis 依赖,或者安装php_redis.dll的扩展。 我这里选择的是predis/predis 依赖。 composer require predis/predis 进入config/cache.php 配置添加redis缓存支持 示例: <?php// -----------------------------------------…...

SRM系统询价竞价管理:优化采购流程的全面解析
SRM系统的询价竞价管理模块是现代企业采购管理中的重要工具。通过该模块,企业可以实现供应商的询价、竞价和合同管理等关键环节的自动化和优化。 一、概述 SRM系统是一种用于管理和优化供应商关系的软件系统。它通过集成各个环节,包括供应商信息管理、询…...

c++选择题笔记
局部变量能否和全局变量重名?可以,局部变量会屏蔽全局变量。在使用全局变量时需要使用 ":: "。拷贝构造函数:参数为同类型的对象的常量引用的构造函数函数指针:int (*f)(int,int) & max; 虚函数:在基类…...

Android2:构建交互式应用
一。创建项目 项目名Beer Adviser 二。更新布局 activity_main.xml <?xml version"1.0" encoding"utf-8"?><LinearLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"…...

ChatGLM-6B微调记录
目录 GLM-130B和ChatGLM-6BChatGLM-6B直接部署基于PEFT的LoRA微调ChatGLM-6B GLM-130B和ChatGLM-6B 对于三类主要预训练框架: autoregressive(无条件生成),GPT的训练目标是从左到右的文本生成。autoencoding(语言理解…...

Linux Kernel 4.12 或将新增优化分析工具
到 7 月初,Linux Kernel 4.12 预计将为修复所有安全漏洞而奠定基础,另外新增的是一个分析工具,对于开发者优化启动时间时会有所帮助。 新的「个别任务统一模型」(Per-Task Consistency Model)为主要核心实时修补&#…...
【30天熟悉Go语言】10 Go异常处理机制
作者:秃秃爱健身,多平台博客专家,某大厂后端开发,个人IP起于源码分析文章 😋。 源码系列专栏:Spring MVC源码系列、Spring Boot源码系列、SpringCloud源码系列(含:Ribbon、Feign&…...

飞机打方块(四)游戏结束
一、游戏结束显示 1.新建节点 1.新建gameover节点 2.绑定canvas 3.新建gameover容器 4.新建文本节点 2.游戏结束逻辑 Barrier.ts update(dt: number) {//将自身生命值取整let num Math.floor(this.num);//在Label上显示this.num_lb.string num.toString();//获取GameCo…...

保研之旅1:西北工业大学电子信息学院夏令营
💥💥💞💞欢迎来到本博客❤️❤️💥💥 本人持续分享更多关于电子通信专业内容以及嵌入式和单片机的知识,如果大家喜欢,别忘点个赞加个关注哦,让我们一起共同进步~ &#x…...

[WMCTF 2023] crypto
似乎退步不了,这个比赛基本不会了,就作了两个简单题。 SIGNIN 第1个是签到题 from Crypto.Util.number import * from random import randrange from secret import flagdef pr(msg):print(msg)pr(br"""........ …...
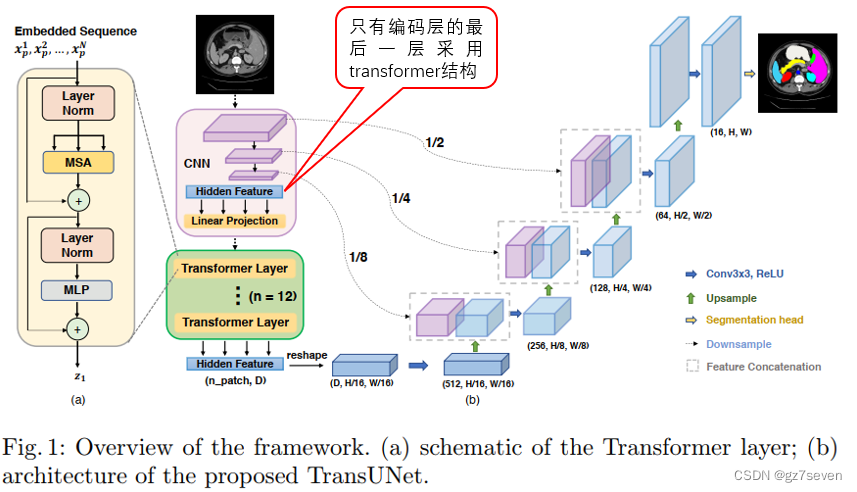
图像分割unet系列------TransUnet详解
图像分割unet系列------TransUnet详解 1、TransUnet结构2、我关心的问题3、总结与展望TransUnet发表于2021年,它是对UNet非常重要的改进,专为医学图像分割任务设计,特别用于在医学图像中分割器官或病变等解剖结构。 1、TransUnet结构 TransUNet在U-Net模型的基础上引入了混合…...
ASCII码-shellcode的技巧
网上已经有成熟的工具了,所以就简单记录一下工具怎么用吧 https://github.com/TaQini/alpha3 https://github.com/veritas501/ae64.git https://github.com/rcx/shellcode_encoder 结合题目来看吧,没有开启NX保护,基本这类型题目九成九都…...

spring cloud 之 dubbo nacos整合
整体思路: 搭建本地nacos服务,详见docker安装nacos_xgjj68163的博客-CSDN博客 共三个工程,生产者服务、消费者服务、生产者和消费者共同依赖的接口工程(打成jar,供生产者和消费者依赖); …...
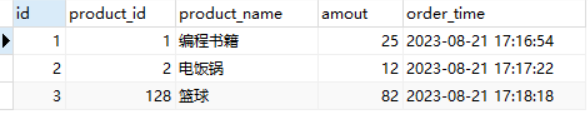
MySQL如何进行表之间的关联更新
在实际编程工作或运维实践中,对MySQL数据库表进行关联更新是一种比较常见的应用场景,比如在电商系统中,订单表里保存了商品名称的信息(冗余字段设计),但如果商品名称发生变化,则需要通过关联商品…...
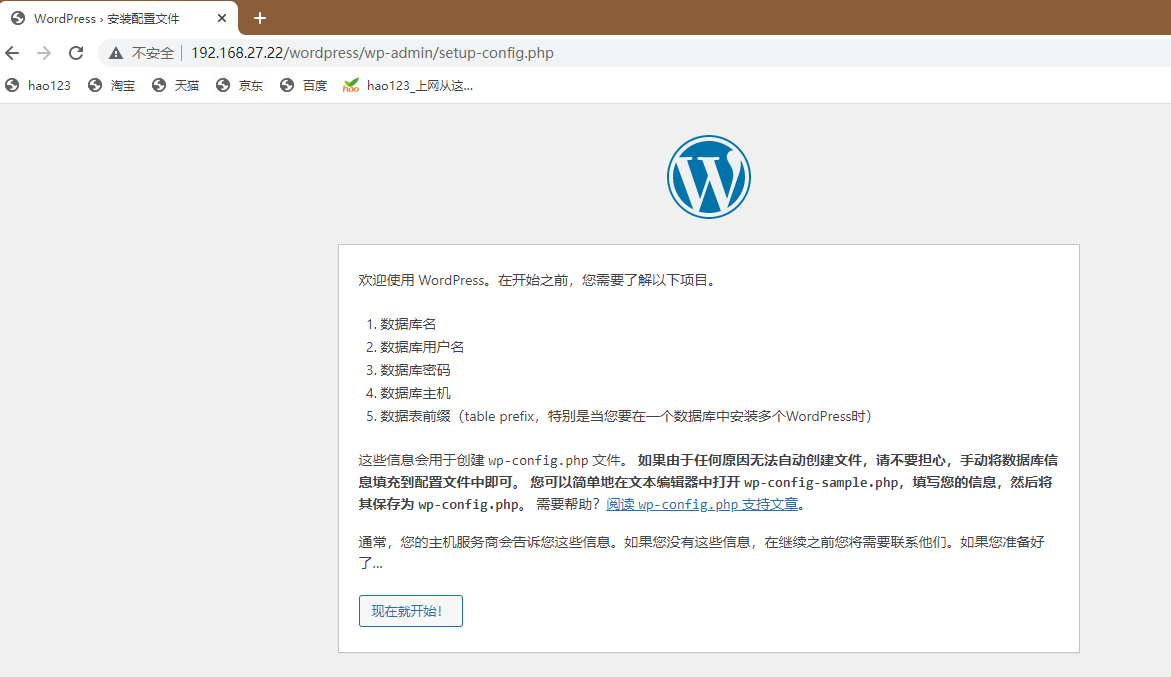
Docker创建 LNMP 服务+Wordpress 网站平台
Docker创建 LNMP 服务Wordpress 网站平台 一.环境及准备工作 1.项目环境 公司在实际的生产环境中,需要使用 Docker 技术在一台主机上创建 LNMP 服务并运行 Wordpress 网站平台。然后对此服务进行相关的性能调优和管理工作。 容器 系统 IP地址 软件 nginx centos…...
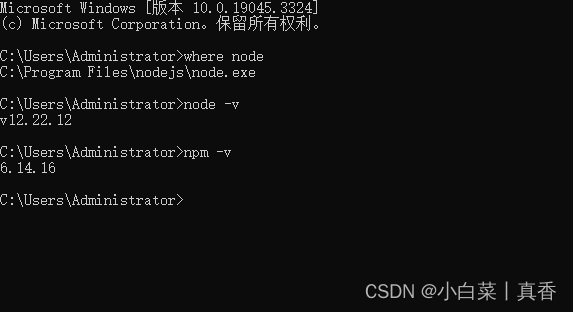
node没有自动安装npm时,如何手动安装 npm
之前写过一篇使用 nvm 管理 node 版本的文章,node版本管理(Windows) 有时候,我们使用 nvm 下载 node 时,node 没有自动下载 npm ,此时就需要我们自己手动下载 npm 1、下载 npm下载地址:&…...
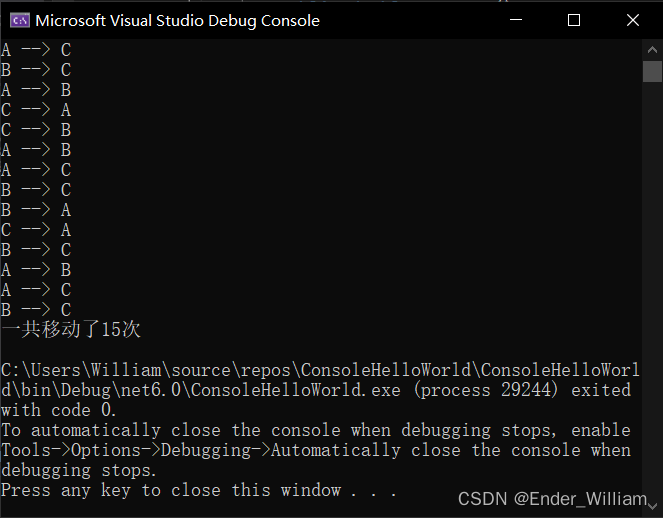
C# 使用递归方法实现汉诺塔步数计算
C# 使用递归方法实现汉诺塔步数计算 Part 1 什么是递归Part 2 汉诺塔Part 3 程序 Part 1 什么是递归 举一个例子:计算从 1 到 x 的总和 public int SumFrom1ToX(int x) {if(x 1){return 1;}else{int result x SumFrom1ToX_2(x - 1); // 调用自己return result…...

Linux环境下Python段错误全解析:从内存管理到线程安全的避坑手册
Linux环境下Python段错误全解析:从内存管理到线程安全的避坑手册 当你在深夜调试一个复杂的Python项目时,突然看到屏幕上跳出"Segmentation fault (core dumped)"的提示,那种感觉就像在高速公路上爆胎——明明代码逻辑看起来没问题…...

终极Win11Debloat优化指南:简单4步让你的Windows 11飞起来
终极Win11Debloat优化指南:简单4步让你的Windows 11飞起来 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter an…...
Hunyuan-MT-7B效果实测:Pixel Language Portal对中文网络用语、方言、谐音梗的跨维转码能力分析
Hunyuan-MT-7B效果实测:Pixel Language Portal对中文网络用语、方言、谐音梗的跨维转码能力分析 1. 引言:当翻译遇上像素冒险 在数字时代的语言交流中,传统翻译工具往往显得生硬而缺乏温度。Pixel Language Portal(像素语言跨维…...

避坑指南:在K210上跑人脸68关键点,这些细节让你的疲劳检测更准
K210人脸疲劳检测实战:68关键点调优与工程化避坑指南 当你在车载监控或工业安全场景部署基于K210的疲劳检测系统时,是否遇到过这些情况?明明按照开源代码跑通了68关键点检测,但实际场景中闭眼判断总是不准;白天阳光直射…...

别再手算LLC参数了!用Mathcad Prime 8.0自动生成增益曲线,附我验证过的产品级模板
告别手工计算:用Mathcad Prime 8.0打造智能LLC设计工作流 深夜的办公室里,电源工程师小王盯着屏幕上密密麻麻的公式叹了口气——这已经是本周第三次因为手工计算LLC谐振参数出错导致样机测试失败了。在中小型电源企业,像小王这样的场景每天都…...

Lingbot-Depth-Pretrain-ViTL-14 Anaconda环境搭建:创建隔离的Python开发与推理环境
Lingbot-Depth-Pretrain-ViTL-14 Anaconda环境搭建:创建隔离的Python开发与推理环境 你是不是也遇到过这种情况:好不容易跟着教程跑通了一个AI项目,结果过两天想跑另一个项目时,发现各种库版本冲突,报错满天飞&#x…...

3个高效构建Web可视化应用的Meta2d.js核心方案:从问题到实践指南
3个高效构建Web可视化应用的Meta2d.js核心方案:从问题到实践指南 【免费下载链接】meta2d.js The meta2d.js is real-time data exchange and interactive web 2D engine. Developers are able to build Web SCADA, IoT, Digital twins and so on. Meta2d.js是一个实…...

深度学习音高检测:5个技巧掌握CREPE实时音高追踪
深度学习音高检测:5个技巧掌握CREPE实时音高追踪 【免费下载链接】crepe CREPE: A Convolutional REpresentation for Pitch Estimation -- pre-trained model (ICASSP 2018) 项目地址: https://gitcode.com/gh_mirrors/cr/crepe CREPE(Convoluti…...

微信小程序数据绑定与渲染全解析:从入门到精通
微信小程序数据绑定与渲染实战指南:解锁高效开发密码 微信小程序开发中,数据绑定与渲染机制是构建动态界面的核心。不同于传统网页开发,小程序采用独特的双线程架构,数据通信需要特殊处理。本文将深入剖析数据绑定的底层原理&…...
)
保姆级教程:用ESP32-P4和ST7703屏打造24fps高清视频轮播器(附完整代码)
ESP32-P4与ST7703屏实战:24fps高清视频轮播系统全流程解析 当一块性能强劲的嵌入式开发板遇到高分辨率显示屏,会碰撞出怎样的火花?本文将带您从零构建一个基于ESP32-P4和ST7703屏幕的高清视频轮播系统,实现稳定的24fps播放效果。不…...