【大数据】Flink 详解(五):核心篇 Ⅳ
Flink 详解(五):核心篇 Ⅳ
45、Flink 广播机制了解吗?

从图中可以理解 广播 就是一个公共的共享变量,广播变量存于 TaskManager 的内存中,所以广播变量不应该太大,将一个数据集广播后,不同的 Task 都可以在节点上获取到,每个节点只存一份。 如果不使用广播,每一个 Task 都会拷贝一份数据集,造成内存资源浪费。
46、Flink 反压了解吗?
反压(backpressure)是实时计算应用开发中,特别是流式计算中,十分常见的问题。反压意味着数据管道中某个节点成为瓶颈,下游处理速率跟不上上游发送数据的速率,而需要对上游进行限速。由于实时计算应用通常使用消息队列来进行生产端和消费端的解耦,消费端数据源是 pull-based 的,所以反压通常是从某个节点传导至数据源并降低数据源(比如 Kafka consumer)的摄入速率。
简单来说就是 下游处理速率跟不上上游发送数据的速率,下游来不及消费,导致队列被占满后,上游的生产会被阻塞,最终导致数据源的摄入被阻塞。
47、Flink 反压的影响有哪些?
反压会影响到两项指标:checkpoint 时长和 state 大小。
(1)前者是因为 checkpoint barrier 是不会越过普通数据的,数据处理被阻塞也会导致 checkpoint barrier 流经整个数据管道的时长变长,因而 checkpoint 总体时间(End to End Duration)变长。
(2)后者是因为为保证 EOS(Exactly-Once-Semantics,准确一次),对于有两个以上输入管道的 Operator,checkpoint barrier 需要对齐(Alignment),接受到较快的输入管道的 barrier 后,它后面数据会被缓存起来但不处理,直到较慢的输入管道的 barrier 也到达,这些被缓存的数据会被放到 state 里面,导致 state 变大。
这两个影响对于生产环境的作业来说是十分危险的,因为 checkpoint 是保证数据一致性的关键,checkpoint 时间变长有可能导致 checkpoint 超时失败,而 state 大小同样可能拖慢 checkpoint 甚至导致 OOM (使用 Heap-based StateBackend)或者物理内存使用超出容器资源(使用 RocksDBStateBackend)的稳定性问题。
48、Flink 反压如何解决?
Flink 社区提出了 FLIP-76,引入了非对齐检查点(unaligned checkpoint)来解耦 Checkpoint 机制与反压机制。
要解决反压首先要做的是定位到造成反压的节点,这主要有两种办法:
- 通过 Flink Web UI 自带的反压监控面板
- Flink Task Metrics
(1)反压监控面板
Flink Web UI 的反压监控提供了 SubTask 级别的反压监控,原理是通过周期性对 Task 线程的栈信息采样,得到线程被阻塞在请求 Buffer(意味着被下游队列阻塞)的频率来判断该节点是否处于反压状态。默认配置下,这个频率在 0.1 0.1 0.1 以下则为 OK, 0.1 0.1 0.1 至 0.5 0.5 0.5 为 LOW,而超过 0.5 0.5 0.5 则为 HIGH。

(2)Task Metrics
Flink 提供的 Task Metrics 是更好的反压监控手段。
- 如果一个 Subtask 的发送端 Buffer 占用率很高,则表明它被下游反压限速了。
- 如果一个 Subtask 的接受端 Buffer 占用很高,则表明它将反压传导至上游。
49、Flink 支持的数据类型有哪些?
Flink 支持的数据类型如下图所示:

从图中可以看到 Flink 类型可以分为基础类型(Basic)、数组(Arrays)、复合类型(Composite)、辅助类型(Auxiliary)、泛型和其它类型(Generic)。Flink 支持任意的 Java 或是 Scala 类型。
50、Flink 如何进行序列和反序列化的?
所谓序列化和反序列化的含义:
- 序列化:就是将一个内存对象转换成二进制串,形成网络传输或者持久化的数据流。
- 反序列化:将二进制串转换为内存对。
TypeInformation 是 Flink 类型系统的核心类 。
在 Flink 中,当数据需要进行序列化时,会使用 TypeInformation 的生成序列化器接口调用一个 createSerialize() 方法,创建出 TypeSerializer,TypeSerializer 提供了序列化和反序列化能力。
Flink 的序列化过程如下图所示:

对于大多数数据类型 Flink 可以自动生成对应的序列化器,能非常高效地对数据集进行序列化和反序列化 ,如下图:

比如,BasicTypeInfo、WritableTypeIno ,但针对 GenericTypeInfo 类型,Flink 会使用 Kyro 进行序列化和反序列化。其中,Tuple、Pojo 和 CaseClass 类型是复合类型,它们可能嵌套一个或者多个数据类型。在这种情况下,它们的序列化器同样是复合的。它们会将内嵌类型的序列化委托给对应类型的序列化器。
通过一个案例介绍 Flink 序列化和反序列化:

如上图所示,当创建一个 Tuple3 对象时,包含三个层面,一是 int 类型,一是 double 类型,还有一个是 Person。Person 对象包含两个字段,一是 int 型的 id,另一个是 String 类型的 name。
- 在序列化操作时,会委托相应具体序列化的序列化器进行相应的序列化操作。从图中可以看到 Tuple3 会把
int类型通过IntSerializer进行序列化操作,此时int只需要占用四个字节。 Person类会被当成一个Pojo对象来进行处理,PojoSerializer序列化器会把一些属性信息使用一个字节存储起来。同样,其字段则采取相对应的序列化器进行相应序列化,在序列化完的结果中,可以看到所有的数据都是由MemorySegment去支持。
MemorySegment 具有什么作用呢?
MemorySegment 在 Flink 中会将对象序列化到预分配的内存块上,它代表 1 1 1 个固定长度的内存,默认大小为 32 k b 32\ kb 32 kb。MemorySegment 代表 Flink 中的一个最小的内存分配单元,相当于是 Java 的一个 byte 数组。每条记录都会以序列化的形式存储在一个或多个 MemorySegment 中。
51、为什么 Flink 使用自主内存,而不用 JVM 内存管理?
因为在内存中存储大量的数据(包括缓存和高效处理)时,JVM 会面临很多问题,包括如下:
- Java 对象存储密度低。Java 的对象在内存中存储包含 3 3 3 个主要部分:对象头、实例数据、对齐填充部分。例如,一个只包含
boolean属性的对象占 16 16 16byte:对象头占 8 8 8byte, boolean 属性占 1 1 1byte,为了对齐达到 8 8 8 的倍数额外占 7 7 7byte。而实际上只需要 1 1 1 个bit( 1 / 8 1/8 1/8 字节)就够了。 - Full GC 会极大地影响性能。尤其是为了处理更大数据而开了很大内存空间的 JVM 来说,GC(
Garbage Collection)会达到秒级甚至分钟级。 - OOM 问题影响稳定性。内存溢出(
OutOfMemoryError)是分布式计算框架经常会遇到的问题, 当 JVM 中所有对象大小超过分配给 JVM 的内存大小时,就会发生OutOfMemoryError错误, 导致 JVM 崩溃,分布式框架的健壮性和性能都会受到影响。 - 缓存未命中问题。CPU 进行计算的时候,是从 CPU 缓存中获取数据。现代体系的 CPU 会有多级缓存,而加载的时候是以 Cache Line 为单位加载。如果能够将对象连续存储, 这样就会大大降低 Cache Miss。使得 CPU 集中处理业务,而不是空转。
52、那 Flink 自主内存是如何管理对象的?
Flink 并不是将大量对象存在堆内存上,而是将对象都序列化到一个预分配的内存块上, 这个内存块叫做 MemorySegment,它代表了一段固定长度的内存(默认大小为 32 32 32 KB),也是 Flink 中最小的内存分配单元,并且提供了非常高效的读写方法,很多运算可以直接操作二进制数据,不需要反序列化即可执行。每条记录都会以序列化的形式存储在一个或多个 MemorySegment 中。如果需要处理的数据多于可以保存在内存中的数据,Flink 的运算符会将部分数据溢出到磁盘。
53、Flink 内存模型介绍一下?
Flink 总体内存类图如下:

主要包含 JobManager 内存模型和 TaskManager 内存模型。
(1)JobManager 内存模型

在 1.10 1.10 1.10 中,Flink 统一了 TM(TaskManager)端的内存管理和配置,相应的在 1.11 1.11 1.11 中,Flink 进一步对 JM(JobManager)端的内存配置进行了修改,使它的选项和配置方式与 TM 端的配置方式保持一致。

(2)TaskManager 内存模型
Flink 1.10 1.10 1.10 对 TaskManager 的内存模型和 Flink 应用程序的配置选项进行了重大更改, 让用户能够更加严格地控制其内存开销。


-
JVM Heap(JVM 堆内存)
- Framework Heap Memory(框架堆上内存):Flink 框架本身使用的内存,即 TaskManager 本身所占用的堆上内存,不计入 Slot 的资源中。 配置参数:
taskmanager.memory.framework.heap.size = 128MB,默认 128 128 128 MB。 - Task Heap Memory(Task 堆上内存):Task 执行用户代码时所使用的堆上内存。配置参数:
taskmanager.memory.task.heap.size。
- Framework Heap Memory(框架堆上内存):Flink 框架本身使用的内存,即 TaskManager 本身所占用的堆上内存,不计入 Slot 的资源中。 配置参数:
-
Off-Heap Mempry(堆外内存)
- DirectMemory(直接内存)
- Framework Off-Heap Memory(框架堆外内存):Flink 框架本身所使用的内存,即 TaskManager 本身所占用的对外内存,不计入 Slot 资源。配置参数:
taskmanager.memory.framework.off-heap.size = 128MB,默认 128 128 128 MB。 - Task Off-Heap Memory(Task 堆外内存):Task 执行用户代码所使用的对外内存。配置参数:
taskmanager.memory.task.off-heap.size = 0,默认 0 0 0。 - Network Memory(网络缓冲内存):网络数据交换所使用的堆外内存大小,如网络数据交换缓冲区。
- Framework Off-Heap Memory(框架堆外内存):Flink 框架本身所使用的内存,即 TaskManager 本身所占用的对外内存,不计入 Slot 资源。配置参数:
- Managed Memory(管理内存):Flink 管理的堆外内存,用于排序、哈希表、缓存中间结果及 RocksDB State Backend 的本地内存。
- DirectMemory(直接内存)
-
JVM Specific Memory(JVM 本身使用的内存)
- JVM Metaspace(JVM 元空间)
- JVM Overhead(JVM 执行开销):JVM 执行时自身所需要的内容,包括线程堆栈、IO、 编译缓存等所使用的内存。配置参数:
taskmanager.memory.jvm-overhead.min = 192MB,taskmanager.memory.jvm-overhead.max = 1GB,taskmanager.memory.jvm-overhead.fraction = 0.1。
-
总体内存
-
总进程内存:Flink Java 应用程序(包括用户代码)和 JVM 运行整个进程所消耗的总内存。总进程内存 = Flink 使用内存 + JVM 元空间 + JVM 执行开销。配置项:
taskmanager.memory.process.size: 1728m。 -
Flink 总内存:仅 Flink Java 应用程序消耗的内存,包括用户代码,但不包括 JVM 为其运行而分配的内存。Flink 使用内存 = 框架堆内外 +
task堆内外 +network+manage。
-
54、Flink 如何进行资源管理的?
Flink在资源管理上可以分为两层:集群资源 和 自身资源。集群资源支持主流的资源管理系统,如 Yarn、Mesos、K8s 等,也支持独立启动的 Standalone 集群。自身资源涉及到每个子 task 的资源使用,由 Flink 自身维护。
一、集群架构剖析
Flink 的运行主要由 客户端 、一个 JobManager(后文简称 JM)和 一个以上的 TaskManager(简称 TM 或 Worker)组成。

- 客户端:客户端主要用于提交任务到集群,在 Session 或 Per Job 模式中,客户端程序还要负责解析用户代码,生成 JobGraph;在 Application 模式中,直接提交用户
jar和执行参数即可。客户端一般支持两种模式:detached模式,客户端提交后自动退出;attached模式,客户端提交后阻塞等待任务执行完毕再退出。 - JobManager:JM 负责决定应用何时调度
task,在task执行结束或失败时如何处理,协调检查点、故障恢复。该进程主要由下面几个部分组成:- ResourceManager:负责资源的申请和释放、管理
slot(Flink 集群中最细粒度的资源管理单元)。Flink 实现了多种 RM 的实现方案以适配多种资源管理框架,如Yarn、Mesos、K8s或Standalone。在Standalone模式下,RM 只能分配slot,而不能启动新的 TM。注意:这里所说的 RM 跟Yarn的 RM 不是一个东西,这里的 RM 是 JM 中的一个独立的服务。 - Dispatcher:提供 Flink 提交任务的
rest接口,为每个提交的任务启动新的 JobMaster,为所有的任务提供 Web UI,查询任务执行状态。 - JobMaster:负责管理执行单个 JobGraph,多个任务可以同时在一个集群中启动,每个都有自己的 JobMaster。注意这里的 JobMaster 和 JobManager 的区别。
- ResourceManager:负责资源的申请和释放、管理
- TaskManager:TM 也叫做
worker,用于执行数据流图中的任务,缓存并交换数据。集群至少有一个 TM,TM 中最小的资源管理单元是slot,每个slot可以执行一个task,因此 TM 中slot的数量就代表同时可以执行任务的数量。
二、Slot 与资源管理
每个 TM 是一个独立的 JVM 进程,内部基于独立的线程执行一个或多个任务。TM 为了控制每个任务的执行资源,使用 task slot 来进行管理。每个 task slot 代表 TM 中的一部分固定的资源,比如一个 TM 有 3 3 3 个 slot,每个 slot 将会得到 TM 的 1 / 3 1/3 1/3 内存资源。不同任务之间不会进行资源的抢占,注意 GPU 目前没有进行隔离,目前 slot 只能划分内存资源。
比如下面的数据流图,在扩展成并行流图后,同一个 task 可能分拆成多个任务并行在集群中执行。操作链可以把多个不同的任务进行合并,从而支持在一个线程中先后执行多个任务,无需频繁释放申请线程。同时操作链还可以统一缓存数据,增加数据处理吞吐量,降低处理延迟。
在 Flink 中,想要不同子任务合并需要满足几个条件:
- 下游节点的入边是 1 1 1(保证不存在数据的
shuffle); - 子任务的上下游不为空;
- 连接策略总是
ALWAYS; - 分区类型为
ForwardPartitioner; - 并行度一致;
- 当前 Flink 开启
Chain特性。

在集群中的执行图可能如下:

Flink 也支持 slot 的共享,即把不同任务根据任务的依赖关系分配到同一个 slot 中。这样带来几个好处:方便统计当前任务所需的最大资源配置(某个子任务的最大并行度);避免 slot 的过多申请与释放,提升 slot 的使用效率。

通过 slot 共享,就有可能某个 slot 中包含完整的任务执行链路。
三、应用执行
一个 Flink 应用就是用户编写的 main 函数,其中可能包含一个或多个 Flink 的任务。这些任务可以在本地执行,也可以在远程集群启动,集群既可以长期运行,也支持独立启动。下面是目前支持的任务提交方案:
- Session 集群
- 生命周期:集群事先创建并长期运行,客户端提交任务时与该集群连接。即使所有任务都执行完毕,集群仍会保持运行,除非手动停止。因此集群的生命周期与任务无关。
- 资源隔离:TM 的
slot由 RM 申请,当上面的任务执行完毕会自动进行释放。由于多个任务会共享相同的集群,因此任务间会存在竞争,比如网络带宽等。如果某个 TM 挂掉,上面的所有任务都会失败。 - 其他方面:拥有提前创建的集群,可以避免每次使用的时候过多考虑集群问题。比较适合那些执行时间很短,对启动时间有比较高的要求的场景,比如交互式查询分析。
- Per Job 集群
- 生命周期:为每个提交的任务单独创建一个集群,客户端在提交任务时,直接与 ClusterManager 沟通申请创建 JM 并在内部运行提交的任务。TM 则根据任务运行需要的资源延迟申请。一旦任务执行完毕,集群将会被回收。
- 资源隔离:任务如果出现致命问题,仅会影响自己的任务。
- 其他方面:由于 RM 需要申请和等待资源,因此启动时间会稍长,适合单个比较大、长时间运行、需要保证长期的稳定性、不在乎启动时间的任务。
- Application 集群
- 生命周期:与 Per Job 类似,只是
main方法运行在集群中。任务的提交程序很简单,不需要启动或连接集群,而是直接把应用程序打包到资源管理系统中并启动对应的 EntryPoint,在 EntryPoint 中调用用户程序的main方法,解析生成 JobGraph,然后启动运行。集群的生命周期与应用相同。 - 资源隔离:RM 和 Dispatcher 是应用级别。
- 生命周期:与 Per Job 类似,只是
相关文章:
【大数据】Flink 详解(五):核心篇 Ⅳ
Flink 详解(五):核心篇 Ⅳ 45、Flink 广播机制了解吗? 从图中可以理解 广播 就是一个公共的共享变量,广播变量存于 TaskManager 的内存中,所以广播变量不应该太大,将一个数据集广播后࿰…...

设计模式-建造者模式
核心思想 抽取共同的行为,允许使用者指定复杂对象的类型和内容,不需要了解内部的构建细节使用多个简单的行为构建一个复杂的对象,将对象的构建过程和它的表示分离,同样的构建过程可以创建不同的表示 优缺点 优点 使用者不需要知…...

flutter 设置app图标
使用插件 flutter_launcher_icons 在 pubspec.yaml 配置文件中 加入 dev_dependencies dev_dependencies: flutter_launcher_icons: "^0.13.1" 准备好app得 icon 图标 其中icon的名字为icon.png 创建assets文件夹 和子文件夹icon iamge 配置静态资源路径 完整配置…...

守护网络安全:深入了解DDOS攻击防护手段
ddos攻击防护手段有哪些?在数字化快速发展的时代,网络安全问题日益凸显,其中分布式拒绝服务(DDOS)攻击尤为引人关注。这种攻击通过向目标网站或服务器发送大量合法或非法的请求,旨在使目标资源无法正常处理其他用户的请求,从而达…...
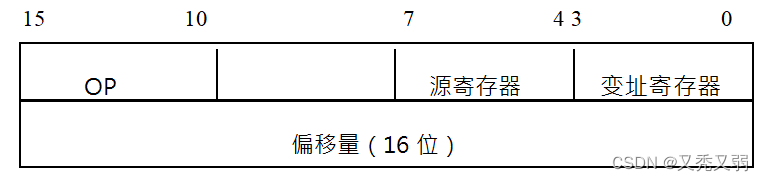
计组 | 寻址方式
目录 一、知识点 1.寻址方式什么? 2.根据操作数所在的位置,都有哪些寻址方式? 3.直接寻址 4.立即寻址 5.隐含寻址 6.相对寻址 7.寄存器 8.寄存器-寄存器型(RR)、寄存器-存储器型(RS)和…...

matlab工具箱Filter Designer设计butterworth带通滤波器
1、在matlab控制界面输入fdatool; 2、在显示的界面中选择合适的参数;本实验中采样频率是200,低通30hz,高通60hz,点击butterworth滤波器。 3、点击设计滤波器按钮后,在生成的界面点击红框按钮,可生成simulink模型到当前…...
)
Python学习笔记第六十天(Matplotlib Pyplot)
Python学习笔记第六十天 Matplotlib Pyplot后记 Matplotlib Pyplot Pyplot 是 Matplotlib 的子库,提供了和 MATLAB 类似的绘图 API。 Pyplot 是常用的绘图模块,能很方便让用户绘制 2D 图表。 Pyplot 包含一系列绘图函数的相关函数,每个函数…...

服务器自动备份、打包、传输脚本
备份脚本 #!/bin/bash #author cheng #备份服务器自动打包归档每天的备份文件 Path/backhistory Host$(hostname) Date$(date %F) Dest${Host}_${Date}#创建目录 mkdir -p ${Path}/${Dest}#打包文件到目录 cd / && \#结合autoback.sh脚本,它往那个地方备&a…...

Docker 的数据管理 网络通信
目录 1.管理容器数据的方式 数据卷 数据卷的容器 2.操作命令 3.Docker 镜像的创建 1.管理容器数据的方式 数据卷 可以独立于容器生命周期存储的机制 可提供持久化 数据共享 docker run -v /var/www:/data1 --name web1 -it centos:7 /bin/bash 数据卷的容器 用来提供持久化数…...

目标检测YOLO实战应用案例100讲-基于孤立森林算法的高光谱遥感图像异常目标检测
目录 前言 孤立森林算法的基本理论 2.1 引言 2.2 孤立森林算法的基本思想...
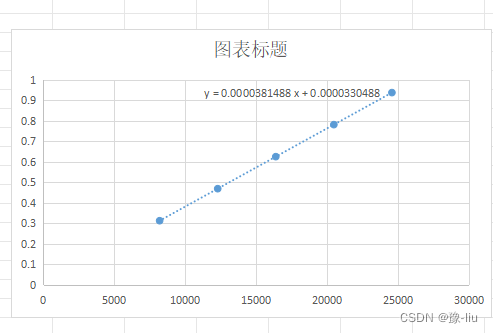
excel中两列数据生成折线图
WPS中excel的两列数据,第一列为x轴,第二列为y轴,生成折线图,并生成拟合函数。 1.选中两列数据,右击选择插入图表,选择XY(散点图),生成散点折线图 2.选中图中散点&#x…...
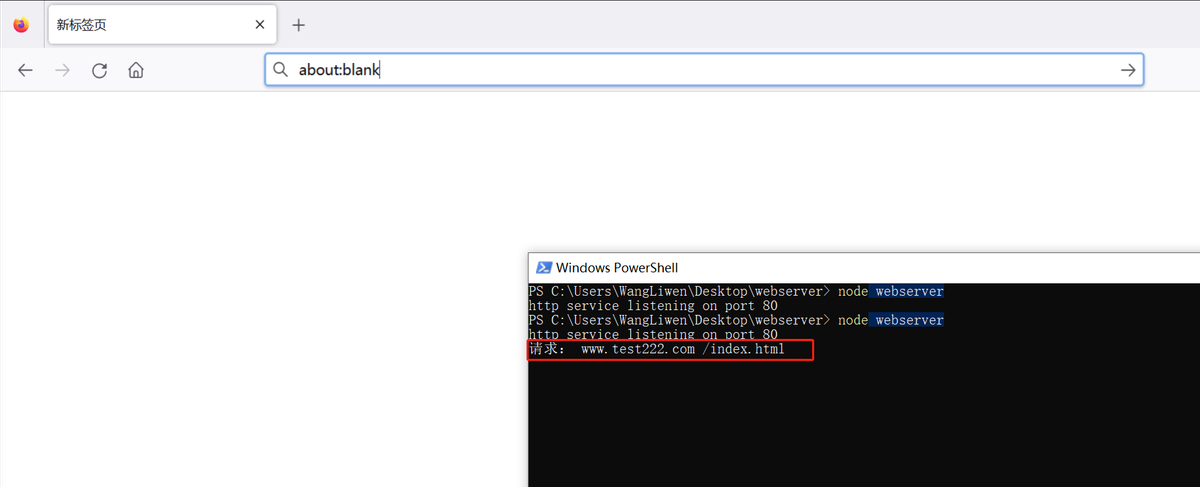
JS加密的域名锁定功能,JShaman支持泛域名
JShaman的域名锁定功能,支持泛域名 JShaman的JS代码混淆加密中,有一项“域名锁定”功能。使用此功能后,代码运行时会检测浏览器地址中的域名信息,如是非指定域名,则不运行,以此防止自己网站的JS代码被复制…...
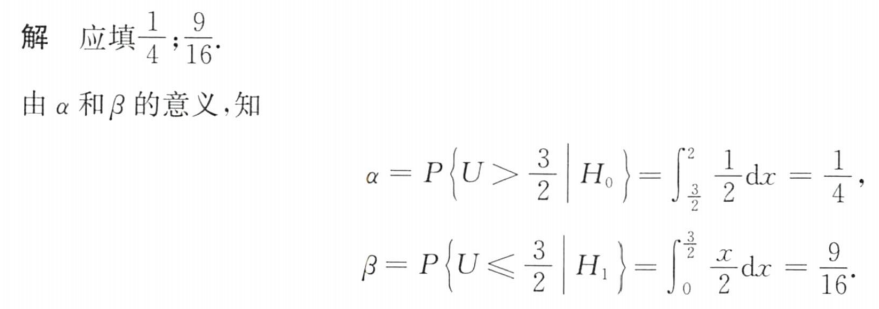
概率论与数理统计:第七章:参数估计 第八章:假设检验
文章目录 Ch7. 参数估计7.1 点估计1.矩估计2.最大似然估计(1)离散型(2)连续型 7.2 评价估计量优良性的标准(1)无偏性 (无偏估计)(2)有效性(3)一致性 7.3 区间估计1.置信区间、置信度2.求μ的置信区间 Ch8. 假设检验1.拒绝域α、接受域1-α、H₀原假设、H₁备择假设2.双边检验、…...

【Kubernetes】Kubernetes的监控工具Promethues
Prometheus 一、Prometheus 概念1. Prometheus 概述2. Prometheus 的监控数据3. Prometheus 的特点4. Prometheus 和 zabbix 区别5. Prometheus 的生态组件5.1 Prometheus server5.2 Client Library5.3 Exporters5.4 Service Discovery5.5 Alertmanager5.6 Pushgateway5.7 Graf…...
【linux】2 Linux编译器-gcc/g++和Linux调试器-gdb
文章目录 一、Linux编译器-gcc/g使用1.1 背景知识1.2 gcc如何完成1.3 函数库1.4 gcc选项 二、linux调试器-gdb使用2.1 背景2.2 开始使用 总结 ヾ(๑╹◡╹)ノ" 人总要为过去的懒惰而付出代价ヾ(๑╹◡╹)ノ" 一、Linux编译器-gcc/g使用 1.1 背景…...
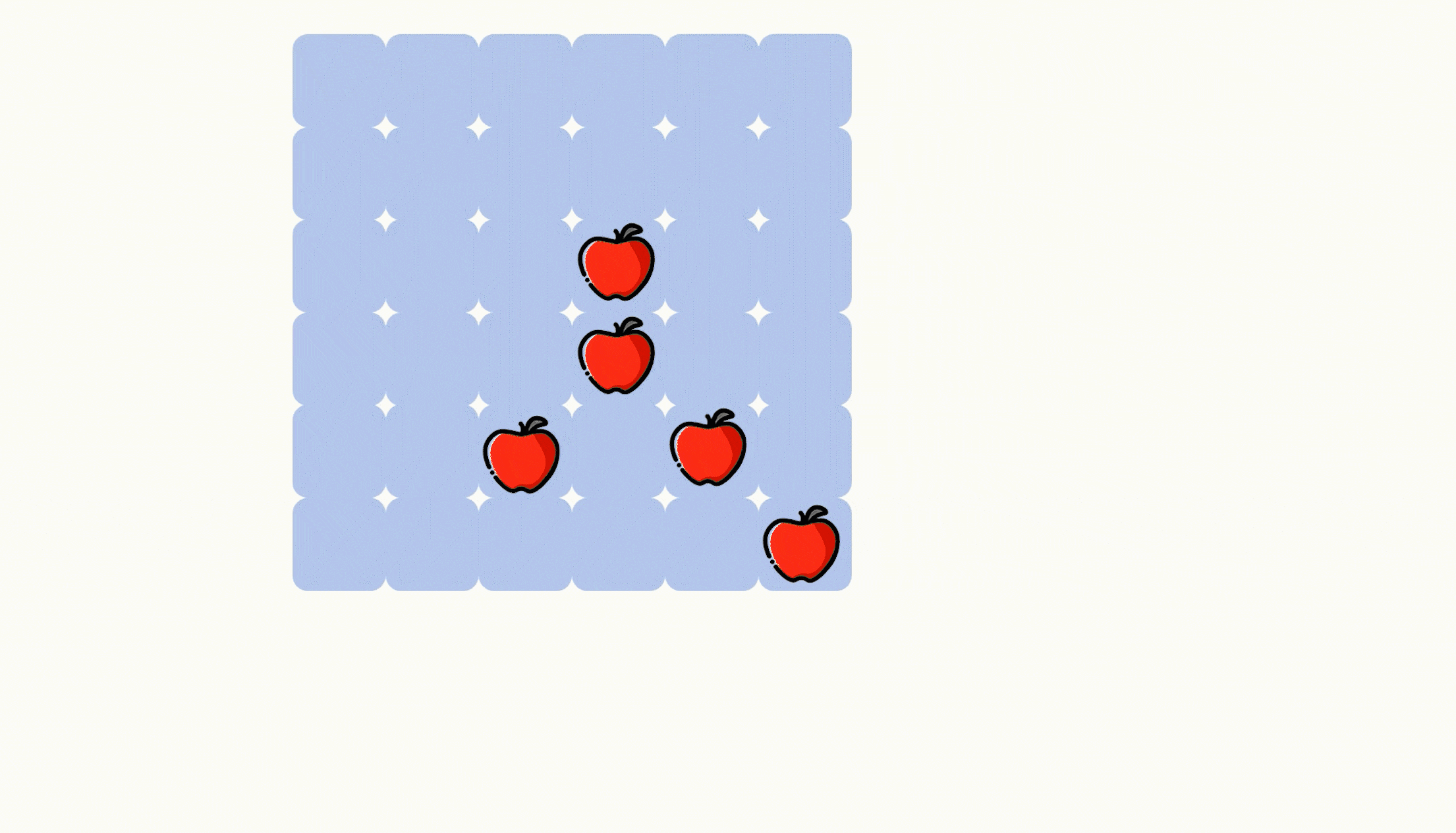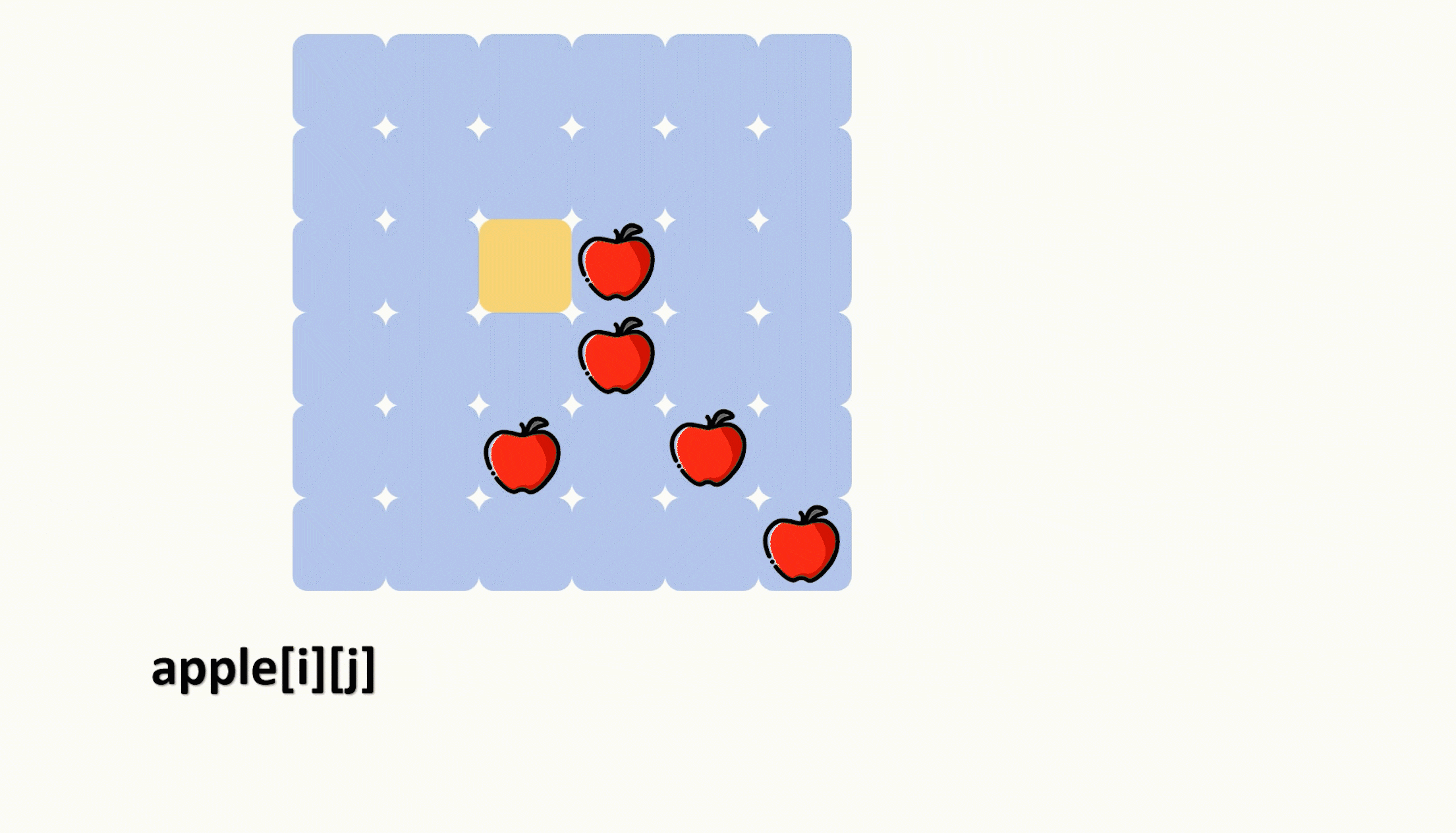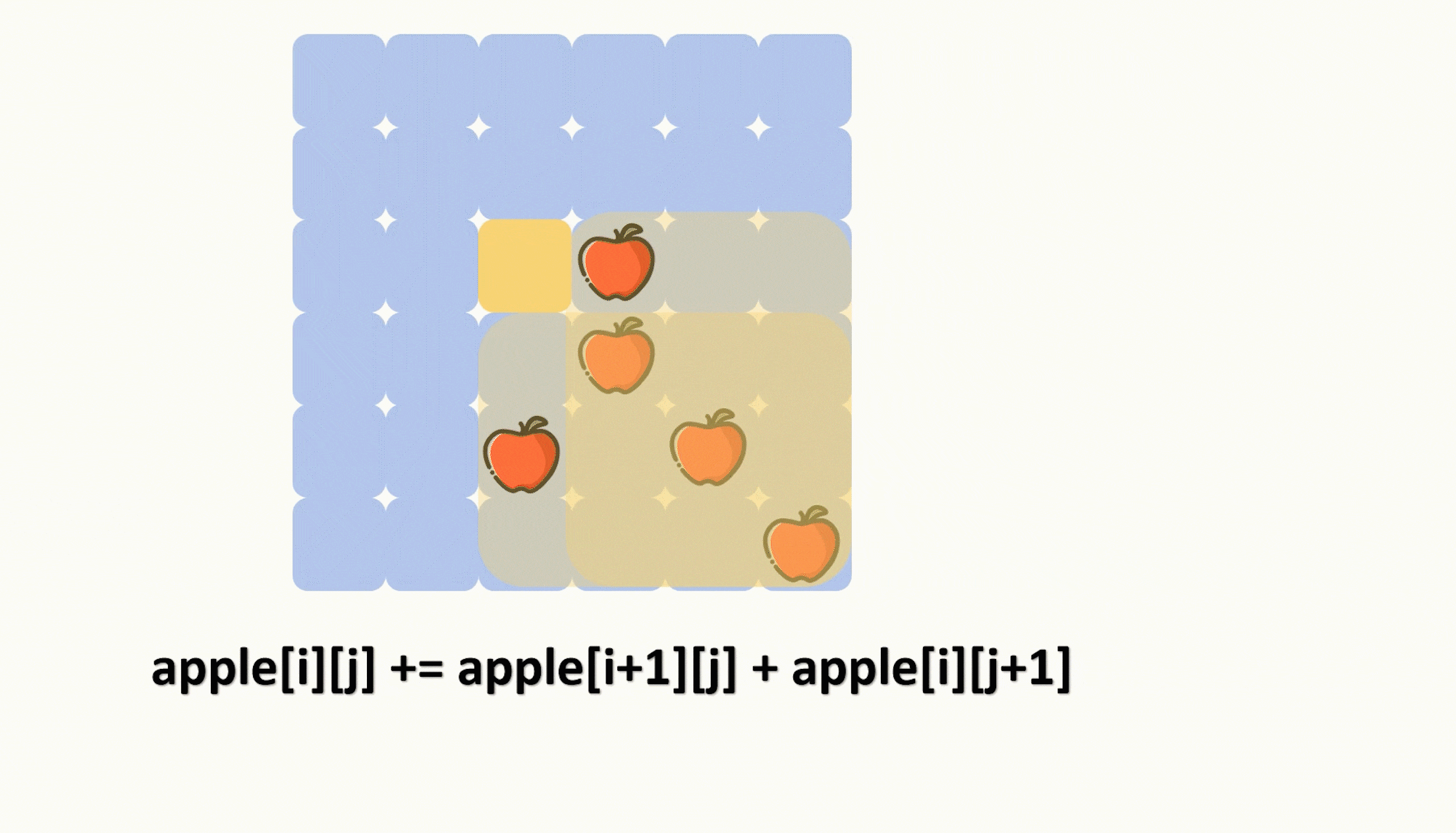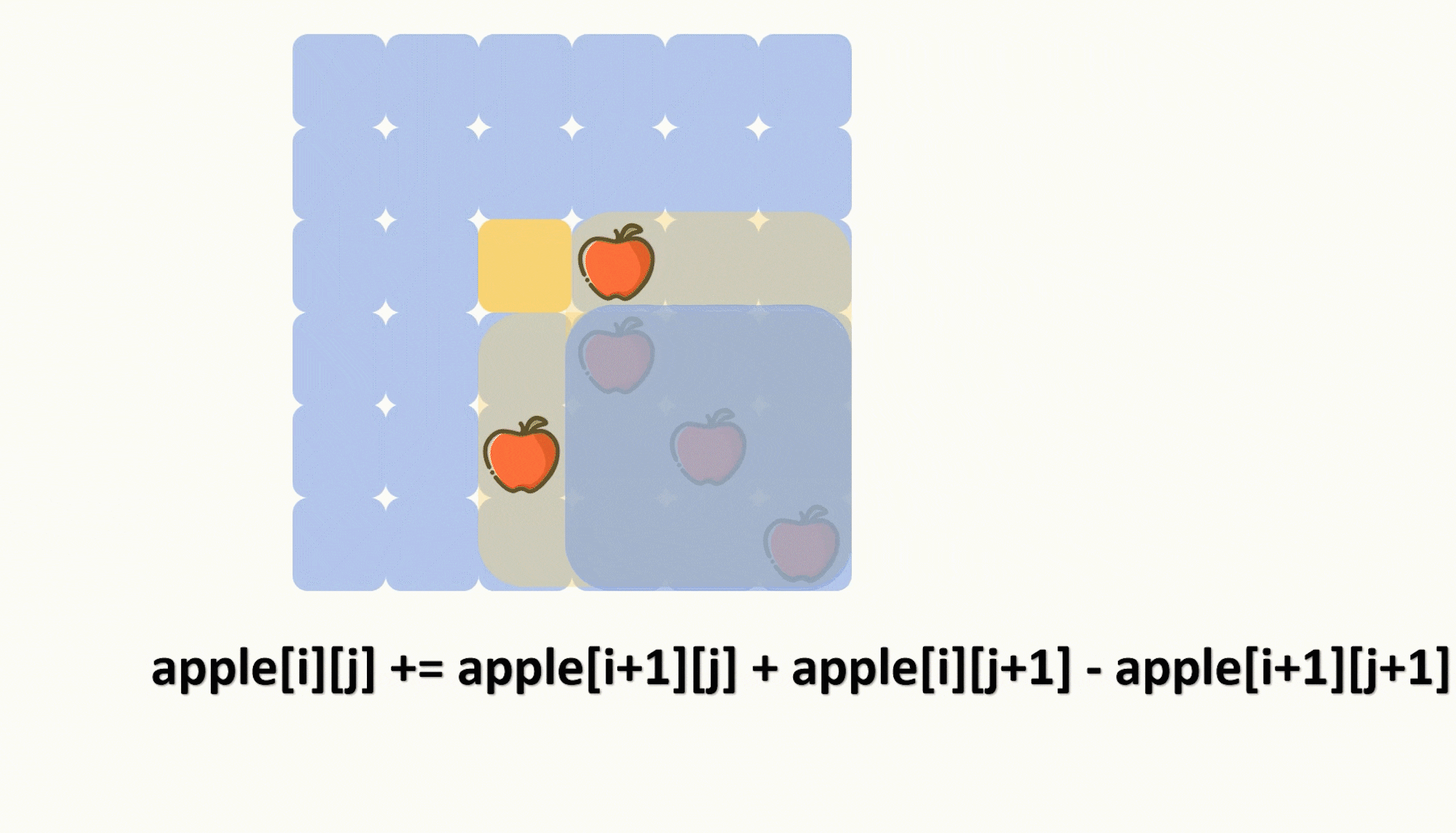
【力扣每日一题】2023.8.17 切披萨的方案数
目录 题目: 示例: 分析: 代码: 题目: 示例: 分析: 题目给我们一个二维数组来表示一个披萨,其中‘A’表示披萨上的苹果。 让我们切k-1刀,把披萨切成 k 份࿰…...

Linux调试器-gdb使用
1. 背景 程序的发布方式有两种, debug 模式和 release 模式 Linux gcc/g 出来的二进制程序,默认是 release 模式 要使用 gdb 调试,必须在源代码生成二进制程序的时候 , 加上 - g 选项 2. 开始使用 gdb binFile 退出: ct…...

linux安装mysql错误处理
linux下mysql的安装与使用 linux安装mysql可有三种方式: 1、yum安装 2、源码安装 3、glibc安装 安装wget yum install -y wget https://blog.csdn.net/darendu/article/details/89874564?utm_sourceapp Linux上error while loading shared libraries问题解决方法…...
Matlab绘制灰度直方图
直方图是根据灰图像绘制的,而不是彩色图像通。查看图像直方图时候,需要先确定图片是否为灰度图,使用MATLAB2019查看图片是否是灰度图片,在读取图片后在MATLAB界面的工作区会显示读取的图像矩阵,如果是,那么…...

http学习笔记1
图解HTTP学习笔记 1.2 HTTP的诞生 CERN(欧洲核子研究组织)的蒂姆 • 伯纳斯 - 李(Tim BernersLee)博士提出了一种能让远隔两地的研究者们共享知识的设想。最初设想的基本理念是:借助多文档之间相互关联形成的超文本&am…...

终极Win11Debloat优化指南:简单4步让你的Windows 11飞起来
终极Win11Debloat优化指南:简单4步让你的Windows 11飞起来 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter an…...

5个步骤掌握MelonLoader:让Unity游戏模组开发变得轻松有趣
5个步骤掌握MelonLoader:让Unity游戏模组开发变得轻松有趣 【免费下载链接】MelonLoader The Worlds First Universal Mod Loader for Unity Games compatible with both Il2Cpp and Mono 项目地址: https://gitcode.com/gh_mirrors/me/MelonLoader 你是否曾…...

云原生图书馆管理系统架构设计:基于SaaS的一站式解决方案与实战案例分析
某中学图书馆数字化改造实战:传统Excel管理迁移至云端系统,借还效率提升300%,系统响应时间降低至200ms以内一、背景:传统图书馆管理的痛点分析1.1 技术债务积累在数字化转型的过程中,许多中小型学校图书馆依然停留在传…...

5分钟搞定!Clipy剪贴板管理神器让Mac效率翻倍
5分钟搞定!Clipy剪贴板管理神器让Mac效率翻倍 【免费下载链接】Clipy Clipboard extension app for macOS. 项目地址: https://gitcode.com/gh_mirrors/cl/Clipy 还在为macOS只能记住最后一次复制内容而烦恼吗?Clipy是一款专为Mac用户设计的剪贴板…...

Mask2Former性能对比分析:R50到Swin-L各主干网络的优劣选择
Mask2Former性能对比分析:R50到Swin-L各主干网络的优劣选择 【免费下载链接】Mask2Former Code release for "Masked-attention Mask Transformer for Universal Image Segmentation" 项目地址: https://gitcode.com/gh_mirrors/ma/Mask2Former Ma…...

用Python+Matplotlib动手验证:标准DH和改进DH建模同一机械臂,结果真的相同吗?
PythonMatplotlib实战:标准DH与改进DH建模机械臂的等价性验证 机械臂运动学建模是机器人学中的基础课题,而Denavit-Hartenberg(DH)参数法则是其中最经典的建模方法之一。标准DH(sDH)与改进DH(mD…...

百考通:AI全流程智能化驱动数据分析,让数据价值高效落地
在数字化浪潮席卷各行各业的今天,数据已成为核心生产要素,但如何从海量数据中挖掘价值、辅助决策,始终是企业与个人面临的核心难题。传统数据分析流程繁琐、技术门槛高、周期漫长,让许多非专业人士望而却步。百考通(ht…...

给客户发固件,别再傻傻传源码了!手把手教你用ESP32 Download Tool烧录PlatformIO生成的bin文件
专业级ESP32固件交付方案:从PlatformIO编译到客户安全烧录全流程 当我们需要将开发完成的ESP32固件交付给客户时,直接发送源代码往往不是最佳选择。这不仅涉及知识产权保护问题,还可能因为客户缺乏开发环境而导致沟通成本激增。本文将详细介绍…...

手把手调参:BLDC有感启动的PWM占空比怎么给?从零到平滑启动的实战避坑指南
手把手调参:BLDC有感启动的PWM占空比实战指南 电机启动瞬间的电流冲击声像极了新手司机的"熄火"与"窜车"——要么纹丝不动,要么突然暴冲。这种尴尬在BLDC电机调试中尤为常见,特别是当负载特性未知时,如何设定…...

暗黑破坏神2终极单机插件:PlugY生存工具包完全指南
暗黑破坏神2终极单机插件:PlugY生存工具包完全指南 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 如果你是一名暗黑破坏神2的单机玩家,是否曾…...