【论文速递】NAACL2022-DEGREE: 一种基于生成的数据高效事件抽取模型
【论文速递】NAACL2022-DEGREE: 一种基于生成的数据高效事件抽取模型
【论文原文】:DEGREE A Data-Efficient Generation-Based Event Extraction Mode
【作者信息】:I-Hung Hsu , Kuan-Hao Huang, Elizabeth Boschee , Scott Miller , Prem Natarajan , Kai-Wei Chang , Nanyun Peng!
论文:https://arxiv.org/pdf/2108.12724.pdf
代码:https://github.com/PlusLabNLP/DEGREE
博主关键词:少样本事件抽取,提示学习,标签语义
推荐论文:Event Extraction by Answering (Almost) Natural Questions、Retrieval-Augmented Generative Question Answering for Event Argument Extraction
摘要
事件抽取需要专家进行高质量的人工标注,这通常很昂贵。因此,学习一个仅用少数标记示例就能训练的数据高效事件抽取模型已成为一个至关重要的挑战。在本文中,我们关注低资源端到端事件抽取,并提出了DEGREE,这是一个数据高效模型,将事件抽取表述为一个条件生成问题。给定一篇文章和一个手动设计的提示,DEGREE学会将文章中提到的事件总结成一个遵循预定义模式的自然句子。然后用确定性算法从生成的句子中抽取出最终的事件预测。DEGREE有三个优势,训练数据少,学得好。首先,我们设计的提示(prompts)为DEGREE提供语义指导,以利用标签语义,从而更好地捕获事件论元。此外,DEGREE能够使用额外的弱监督信息,例如提示中编码的事件描述。最后,DEGREE以端到端的方式联合学习触发词和论元,这鼓励模型更好地利用它们之间的共享知识和依赖关系。实验结果表明,DEGREE算法在低资源事件抽取方面具有良好的性能。
1、简介
事件抽取(EE)旨在从给定的段落中抽取事件,每个事件由一个触发词和几个具有特定角色的参与者(论元)组成。例如,在图1中,Justice:Execute事件是由单词“execution”触发的,该事件包含三个论元角色,包括执行执行的Agent(Indonesia)、被执行的Person(convicts)和事件发生的Place(文中未提到)。之前的工作通常将EE分为两个子任务:(1)事件检测,它识别事件触发词及其类型;(2)事件论元抽取,它抽取给定事件触发词的论元及其角色。EE已被证明有益于广泛的应用,例如,构建知识图谱,问答,以及其他下游研究。

大多数先前关于EE的工作依赖于大量的标注数据进行训练。但是,获得高质量的事件标注的成本很高。例如,使用最广泛的EE数据集之一ACE 2005语料库需要语言学专家进行两轮标注。高昂的标注成本使得这些模型难以扩展到新的领域和新的事件类型。因此,如何学习仅用少量标注示例的数据训练高效EE模型是一个至关重要的挑战。
在本文中,我们专注于低资源事件抽取,其中只有少量的训练示例可用于训练。我们提出了DEGREE (Data-Efficient GeneRation-Based Event Extraction,基于数据高效生成的事件抽取),这是一种基于生成的模型,它将段落和手动设计的提示(prompt)作为输入,并学习按照预定义的模板将文章总结成自然的句子,如图2所示。然后可以使用确定性算法从生成的句子中抽取事件触发词和论元。
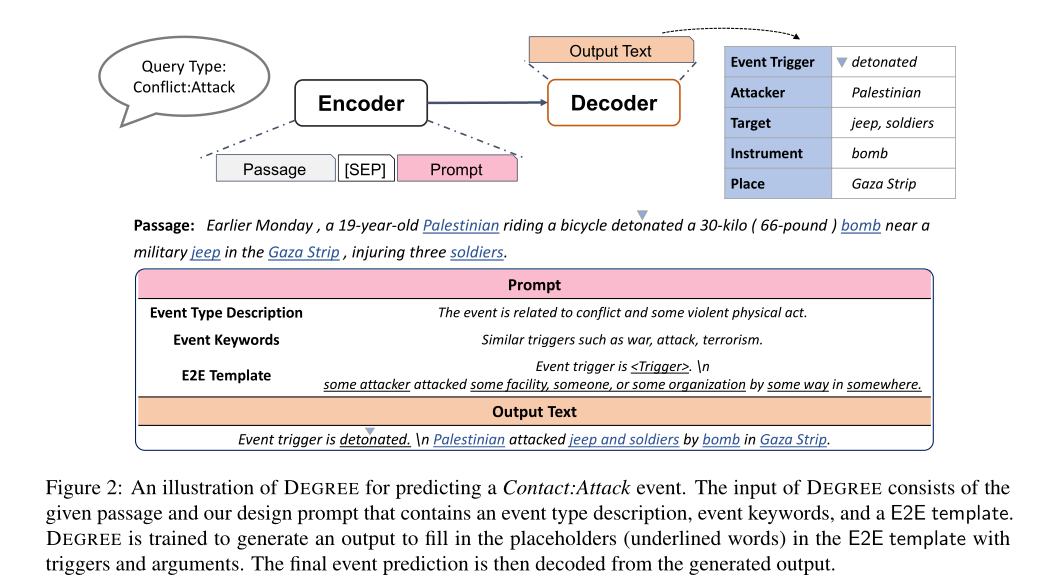
DEGREE具有以下优势,训练数据少,学得好。首先,框架通过提示中设计的模板提供标签语义。如图2中的示例所示,提示符中的单词“somewhere”指导模型预测与角色Place的位置相似的单词。此外,该模板的句子结构和“攻击”一词描述了角色“attacker”和角色“target”之间的语义关系。有了这些指导,DEGREE可以用更少的训练示例做出更准确的预测。其次,提示(prompt)可以包含关于任务的附加弱监督信号,例如事件描述和类似的关键字。这些资源通常很容易获得。例如,在我们的实验中,我们从标注指南中获取信息,标注指南随数据集一起提供。这些信息有助于DEGREE在资源不足的情况下学习。最后,DEGREE设计用于端到端事件抽取,可以同时解决事件检测和事件论元抽取问题。利用两个任务之间的共享知识和依赖关系使我们的模型数据效率更高。
现有的EE研究通常只具备上述一两个优点。例如,以前基于分类的模型很难对标签语义和其他弱监督信号进行编码。最近提出的基于生成的事件抽取模型以管道方式解决了这一问题;因此,他们**(生成的事件抽取模型)不能利用子任务之间的共享知识**。此外,它们生成的输出不是自然句子,这阻碍了标签语义的利用。因此,我们的DEGREE模型在低资源事件抽取方面可以获得比以前的方法更好的性能,我们将在第3节中演示。
我们的贡献可归纳如下:
- 我们提出了DEGREE,这是一种基于生成的事件抽取模型,通过更好地结合标签语义和子任务之间的共享知识,可以用更少的数据进行更好的学习(第2节)。
- ACE 2005和ERE-EN的实验证明了DEGREE在低资源环境下的强大表现(第3节)。
- 我们在低资源和高资源环境下进行了全面的消融研究,以更好地理解我们模型的优缺点(第4节)。
3、实验
我们进行了低资源事件抽取的实验,以研究DEGREE的表现。
3.1 实验设置
数据集:ACE 2005(ACE05-E、ACE05-E+)、ERE-EN。
低资源下的数据划分设置:我们生成不同比例(1%,2%,3%,5%,10%,20%,30%,50%)的训练数据来研究训练集大小的影响,并使用原始开发集和测试集进行评估。附录C列出了更多关于数据划分生成过程和数据统计的详细信息。
评估指标:Trigger F1-score、Argument F1-score。
对比baseline:OneIE、BERT_QA、TANL、Text2Event.
3.2 主要的结果
表2给出了三个训练数据占比不同的数据集的触发词分类F1-scores和论元分类F1-scores。结果如图3所示。由于我们的任务是端到端事件抽取,所以在比较模型时,论元分类F1-score是我们考虑的更重要的度量。
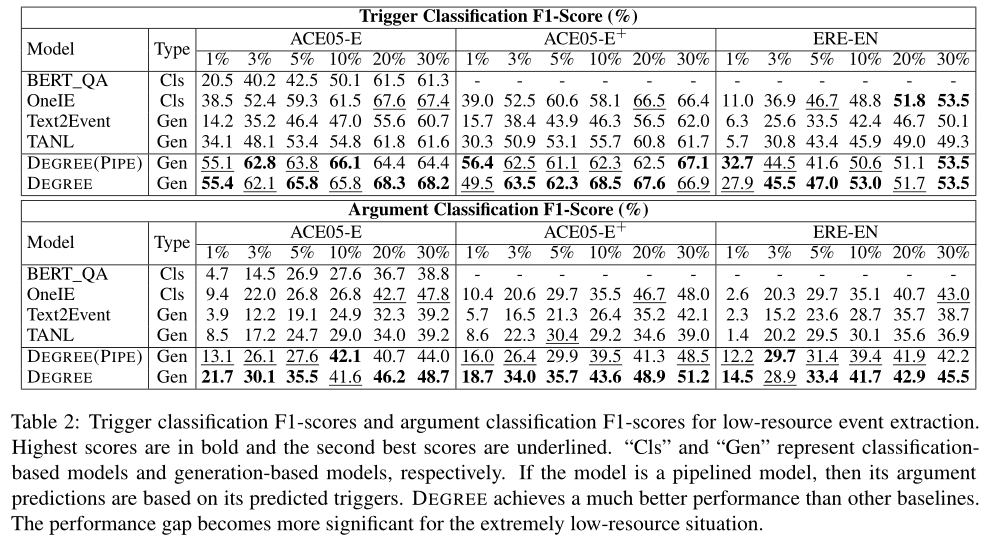
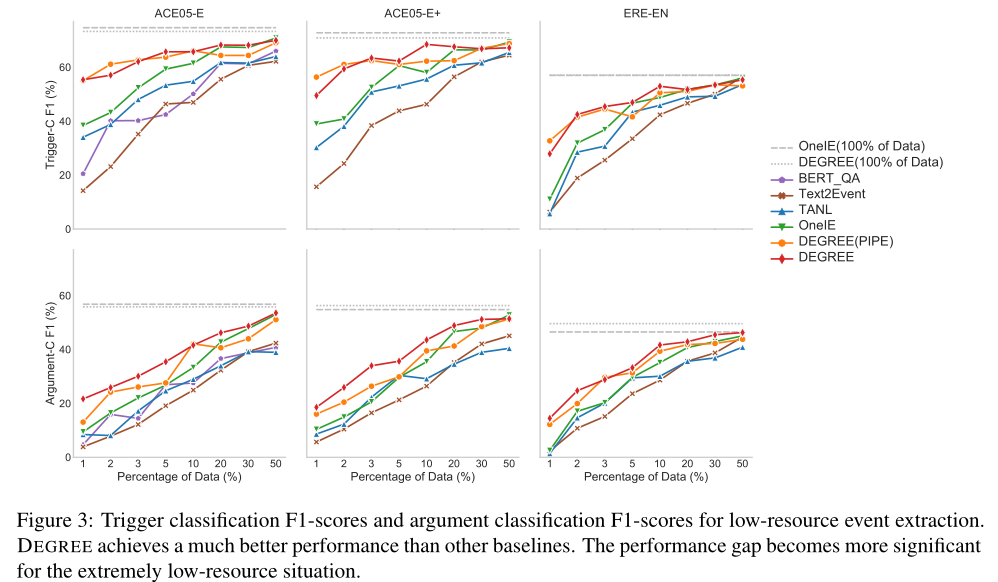
从图3和表2中,我们可以观察到,当使用不到10%的训练数据时,DEGREE和DEGREE(PIPE)都优于所有其他基线。在极低数据的情况下,性能差距变得更加显著。例如,当只有1%的训练数据可用时,DEGREE和DEGREE(PIPE)在触发词分类F1分数上取得了超过15分的提高,在论元分类F1分数上取得了超过5分的提高。这证明了我们设计的有效性。基于生成的模型,经过精心设计的提示,能够利用标签语义和额外的弱监督信号,从而帮助在低资源条件下的学习。
另一个有趣的发现是,DEGREE和DEGREE(PIPE)似乎更有利于预测论元,而不是预测触发词。例如,最强的基线OneIE需要20%的训练数据来实现对DEGREE和DEGREE(PIPE)的触发词预测的竞争性能;然而,它需要大约50%的训练数据才能在预测论点方面达到竞争性表现。原因是,对于论元预测来说,捕获依赖关系的能力比触发词预测更重要,因为与触发词相比,论元通常是相互强烈依赖的。因此,我们的论元预测模型的改进更为显著。
此外,我们观察到,在低资源设置下,DEGREE略优于DEGREE(PIPE)。这为在低资源环境中联合预测触发词和论元的好处提供了经验证据。
【论文速递 | 精选】

相关文章:
【论文速递】NAACL2022-DEGREE: 一种基于生成的数据高效事件抽取模型
【论文速递】NAACL2022-DEGREE: 一种基于生成的数据高效事件抽取模型 【论文原文】:DEGREE A Data-Efficient Generation-Based Event Extraction Mode 【作者信息】:I-Hung Hsu , Kuan-Hao Huang, Elizabeth Boschee ÿ…...

C++类和对象(下)
✨个人主页: Yohifo 🎉所属专栏: C修行之路 🎊每篇一句: 图片来源 I do not believe in taking the right decision. I take a decision and make it right. 我不相信什么正确的决定。我都是先做决定,然后把…...
Java常见的六种线程池、线程池-四种拒绝策略总结
点个关注,必回关 一、线程池的四种拒绝策略: CallerRunsPolicy - 当触发拒绝策略,只要线程池没有关闭的话,则使用调用线程直接运行任务。 一般并发比较小,性能要求不高,不允许失败。 但是,由于…...

Node=>Express中间件分类 学习4
1.中间件分类 应用级别的中间件路由级别的中间件错误级别的中间件Express 内置的中间件第三方的中间件 通过app.use()或app.get()或app.post()绑定到app实力上的中间件,叫做应用级别的中间件 …...

在阿里当外包,是一种什么工作体验?
上周和在阿里做外包的朋友一起吃饭,朋友吃着吃着,就开启了吐槽模式。 他一边喝酒一边说,自己现在做着这份工作,实在看不到前途。 看他状态不佳,问了才知道,是手上的项目太磨人。 他们现在做的项目&#…...
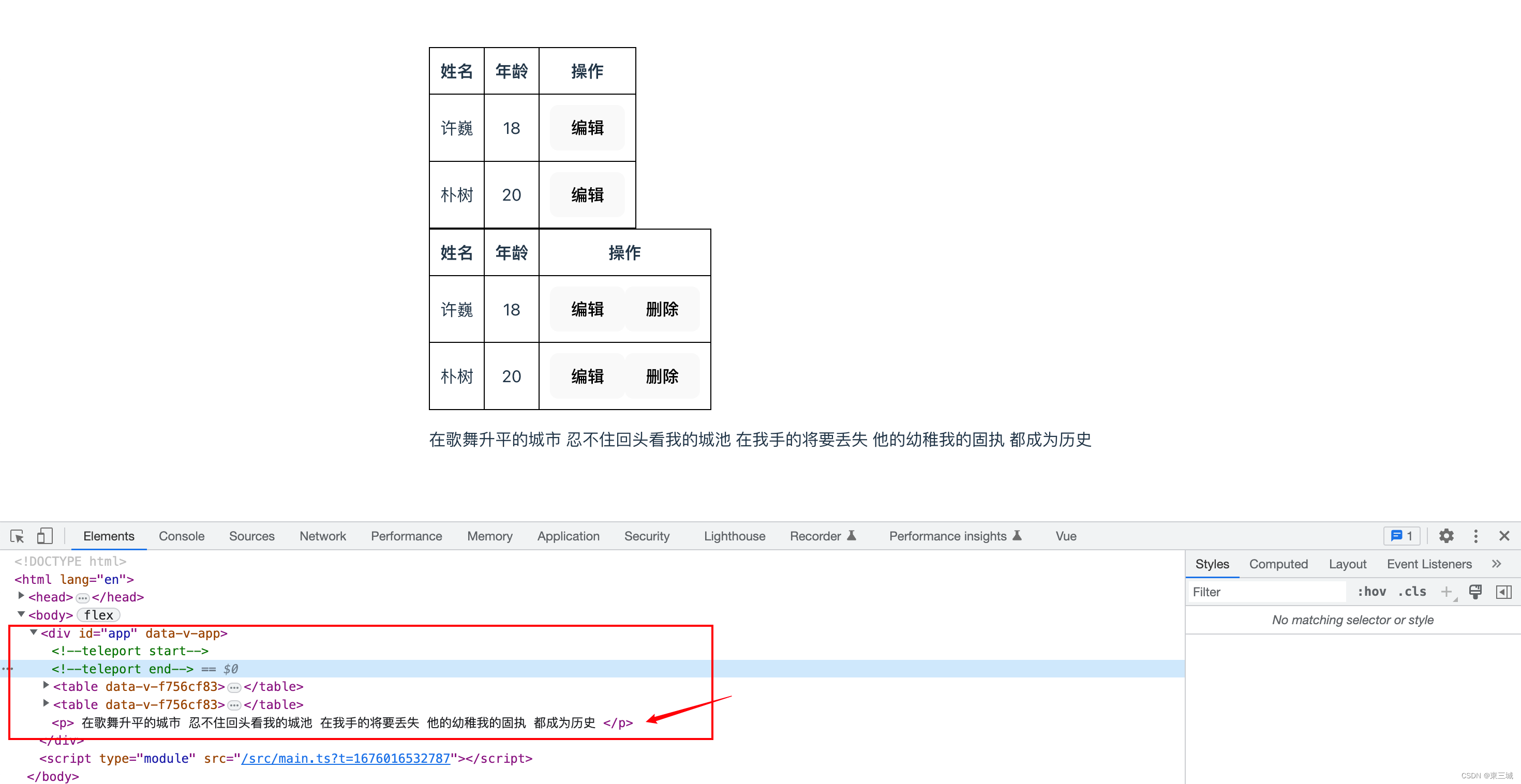
Vue3快速入门【二】
Vue3快速入门一、传值父传子,子传父v-model二、插槽2.1、匿名插槽2.2、具名插槽2.3、插槽作用域2.4、插槽作用域案例2.4.1、初始布局2.4.2、插槽使用2.4.3、点击编辑按钮获取本行数据(插槽作用域的使用)2.4.4、类型书写优化2.4.5、全局接口抽…...

C++-类和对象(上)
类和对象(上)一,构造函数1,概念2,特性二,析构函数1,概念2,特性三,拷贝构造1,概念2,特性四,运算符重载1,概念2,…...
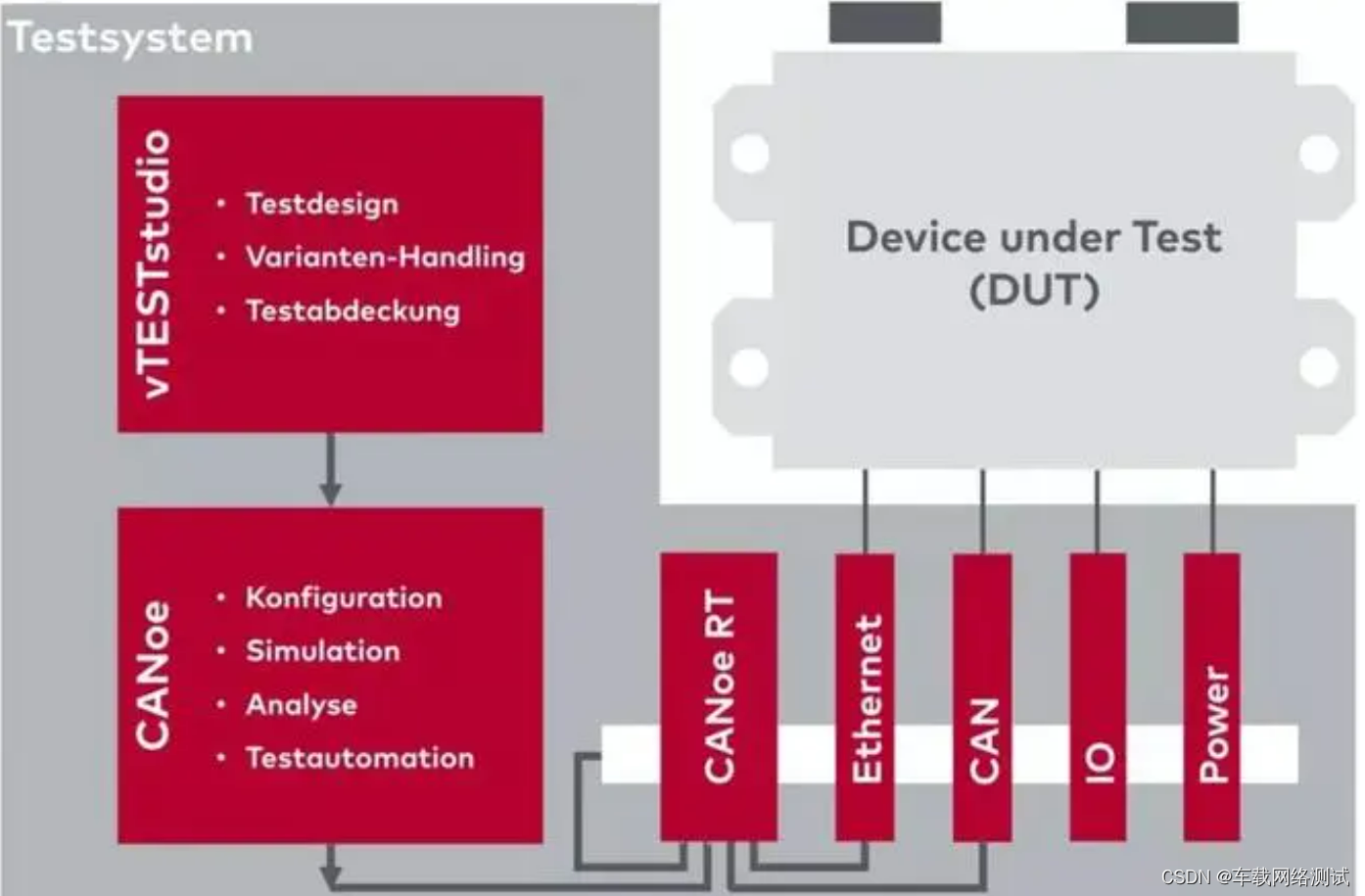
CAPL(vTESTStudio) - DoIP - TCP接收_04
TCP接收 函数介绍 TcpOpen函数...

联合培养博士经历对于国内就业有优势吗?
2023年国家留学基金委(CSC)申请在即,很多在读博士在关心申报的同时,也对联培经历能否有助于国内就业心中存疑,故此知识人网小编重点解答此问题。之前,我们在“CSC联合培养-国内在读博士出国的绝佳选择”一文…...
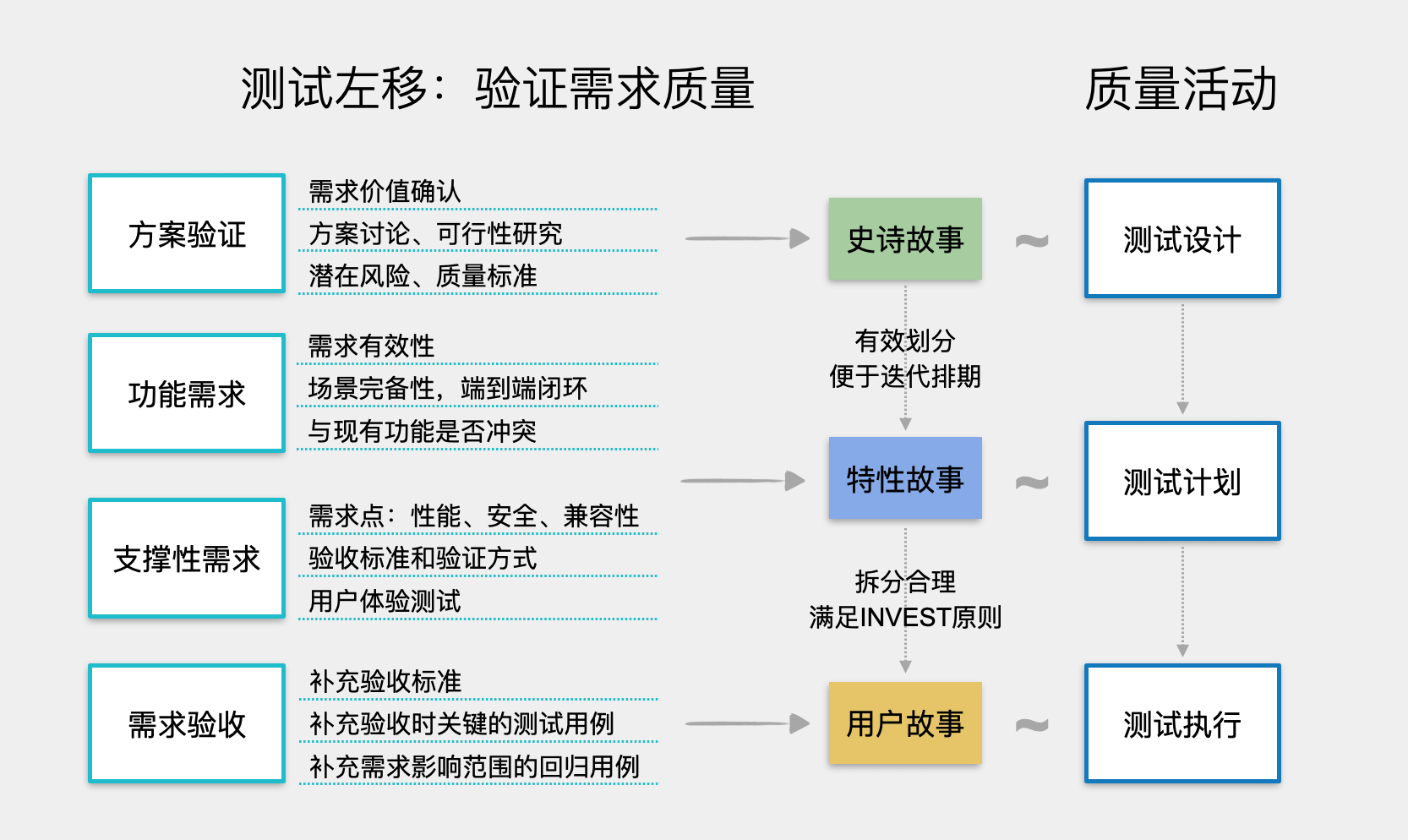
测试左移之需求质量
测试左移的由来 缺陷的修复成本逐步升高 下面是质量领域司空见惯的一张图,看图说话,容易得出:大部分缺陷都是早期引入的,同时大部分缺陷都是中晚期发现的,而缺陷发现的越晚,其修复成本就越高。因此&#…...

【数据结构初阶】第三节.顺序表详讲
文章目录 前言 一、顺序表的概念 二、顺序表功能接口概览 三、顺序表基本功能的实现 四、四大功能 1、增加数据 1.1 头插法: 1.2 尾插法 1.3 指定下标插入 2、删除数据 2.1 头删 2.2 尾删 2.3 指定下标删除 2.4 删除首次出现的指定元素 3、查找数据…...

新手小白适合做跨境电商吗?
今天的跨境电商已经逐渐成熟,靠运气赚钱的时代早已过去,馅饼不可能从天上掉下来,尤其是你想做一个没有货源的小白劝你醒醒。做跨境电商真的不容易,要想做,首先要分析自己是否适合做。米贸搜整理了以下资料,…...

Python搭建自己[IP代理池]
IP代理是什么:ip就是访问网页数据服务器位置信息,每一个主机或者网络都有一个自己IP信息为什么要使用代理ip:因为在向互联网发送请求中,网页端会识别客户端是真实用户还是爬虫程序,在今天以互联网为主导的世界中&#…...
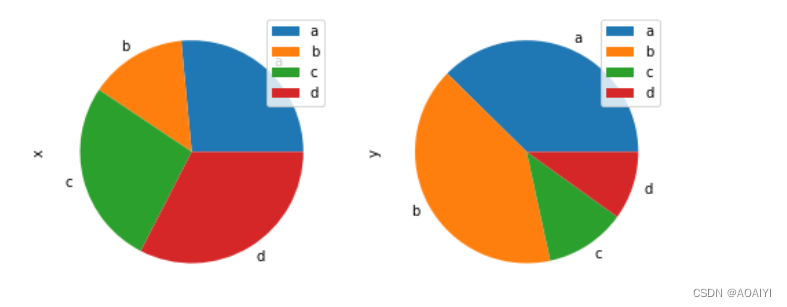
pandas——plot()方法可视化
pandas——plot()方法可视化 作者:AOAIYI 创作不易,如果觉得文章不错或能帮助到你学习,记得点赞收藏评论哦 在此,感谢你的阅读 文章目录pandas——plot()方法可视化一、实验目的二、实验原理三、实验环境四、实验内容五、实验步骤…...
)
【Three.js基础】坐标轴辅助器、requestAnimationFrame处理动画、Clock时钟、resize页面尺寸(二)
🐱 个人主页:不叫猫先生 🙋♂️ 作者简介:前端领域新星创作者、阿里云专家博主,专注于前端各领域技术,共同学习共同进步,一起加油呀! 💫系列专栏:vue3从入门…...
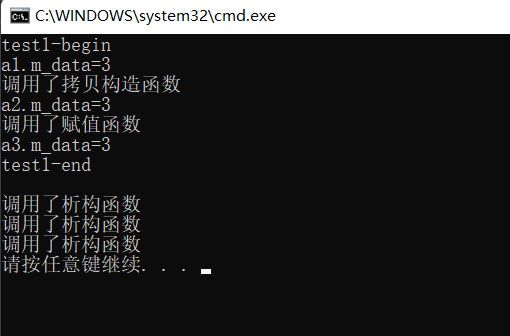
C++之完美转发、移动语义(forward、move函数)
完美转发1. 在函数模板中,可以将自己的参数“完美”地转发给其它函数。所谓完美,即不仅能准确地转发参数的值,还能保证被转发参数的左、右值属性不变。2. C11标准引入了右值引用和移动语义,所以,能否实现完美转发&…...
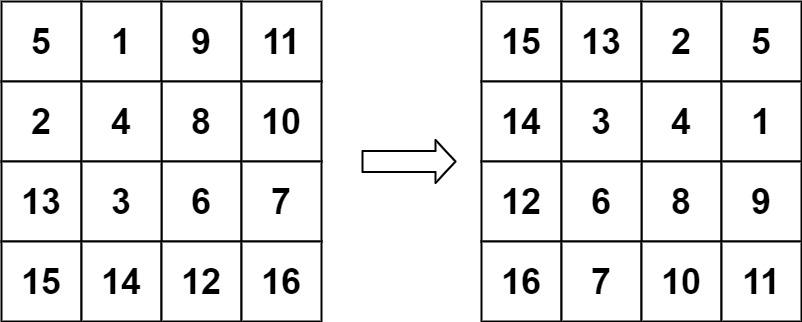
LeetCode刷题系列 -- 48. 旋转图像
给定一个 n n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。示例 1:输入:matrix [[1,2,3],[4,5,6],[7,8,9]]输出&#…...

在多线程环境下使用哈希表
一.HashTable和HashMapHashTable是JDK1.0时创建的,其在创建时考虑到了多线程情况下存在的线程安全问题,但是其解决线程安全问题的思路也相对简单:在其众多实现方法上加上synchronized关键字(效率较低),保证…...
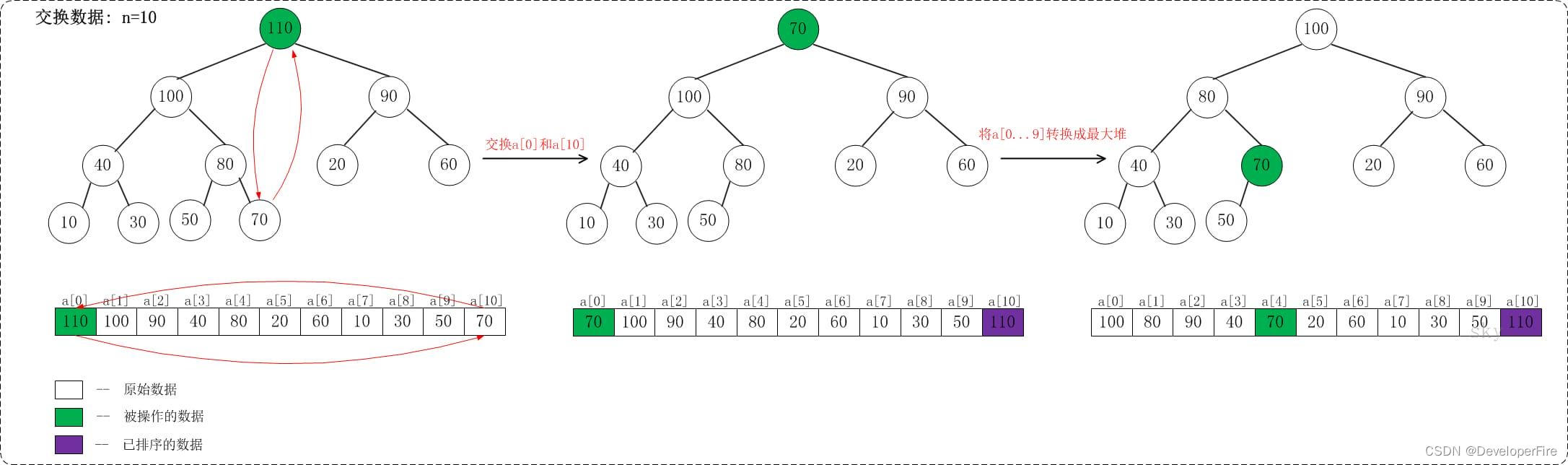
【排序算法】堆排序(Heap Sort)
堆排序是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序介绍学习堆排序之前,有必要了解堆!若…...
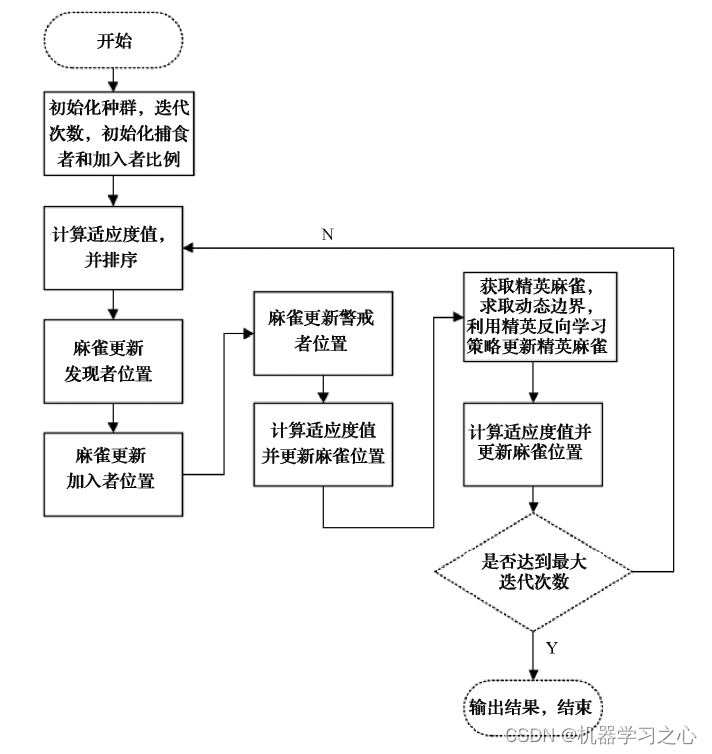
分类预测 | Matlab实现SSA-RF和RF麻雀算法优化随机森林和随机森林多特征分类预测
分类预测 |Matlab实现SSA-RF和RF麻雀算法优化随机森林和随机森林多特征分类预测 目录分类预测 |Matlab实现SSA-RF和RF麻雀算法优化随机森林和随机森林多特征分类预测分类效果基本介绍模型描述程序设计参考资料分类效果 基本介绍 Matlab实现SSA-RF和RF麻雀算法优化随机森林和随机…...

Python 3.7 + XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程
Python 3.7 XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程在机器学习领域,XGBoost因其出色的性能和可解释性成为众多数据科学家的首选工具。本文将带您完整走过多分类任务的全流程,从原始数据到可解释的预测模型,每个…...

Vue3 图片标框功能实现方案
基于 Vue3 组合式 API 的图片标框(画框、标注、选框)完整实现,核心逻辑封装在 GetBoxes 组件里,复制就能用 一、功能说明 ✅ 在图片上鼠标拖拽画矩形框 ✅ 实时显示框坐标(x, y, width, height) ✅ 支持多…...

FeHelper前端助手:30+开发工具集,让你的浏览器变身效率神器
FeHelper前端助手:30开发工具集,让你的浏览器变身效率神器 【免费下载链接】FeHelper 😍FeHelper--Web前端助手(Awesome!Chrome & Firefox & MS-Edge Extension, All in one Toolbox!) 项目地址:…...

搞定这 5 个全栈电商项目,面试别再用 Todo-List 凑数了
找独立开发练手项目或者写简历项目时,最忌讳两件事:一是太简单(纯前端 Mock 数据,点两下就没了),二是太假(一上来就硬套微服务、消息队列、高并发,结果自己根本Hold不住)…...

内存占用3KB!极致瘦身释放MCU无限可能
极致小体积,给工业领域带来了无限的可能:更低硬件成本,更小芯片体积,更低功耗,更高可靠性,让每一颗小MCU都拥有大系统的完整能力。 https://www.bilibili.com/video/BV1eZLi6PEjc/?spm_id_from333.1387.ho…...

使用TaotokenCLI工具一键配置开发环境中的API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境中的API密钥 在团队协作或个人开发中,为每个项目或成员手动配置大模型API密钥和…...

别急着扔!12年老ThinkPad X230升级SSD和内存后,Win10流畅得像新电脑
12年老ThinkPad X230重生指南:极简升级打造流畅办公利器每次打开抽屉看到那台积灰的ThinkPad X230,总有种说不出的情感。这款2012年问世的经典商务本,曾陪伴无数人度过加班到凌晨的夜晚。如今性能确实有些力不从心,但直接丢弃又觉…...

Unity Visual Scripting不是拖拽玩具:中阶开发者的编程范式重构指南
1. 为什么Unity官方Visual Scripting不是“拖拽完就能跑”的玩具,而是一套需要重新理解的编程范式很多人第一次点开Unity的Visual Scripting(VS)面板时,看到那些五颜六色的节点和丝滑的连线,下意识觉得:“这…...

深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南
深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今网络设备管理领域,获取设备完整控制…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...