大数据分析案例-基于LightGBM算法构建糖尿病确诊预测模型

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
喜欢大数据分析项目的小伙伴,希望可以多多支持该系列的其他文章
| 大数据分析案例-基于随机森林算法预测人类预期寿命 |
| 大数据分析案例-基于随机森林算法的商品评价情感分析 |
| 大数据分析案例-用RFM模型对客户价值分析(聚类) |
| 大数据分析案例-对电信客户流失分析预警预测 |
| 大数据分析案例-基于随机森林模型对北京房价进行预测 |
| 大数据分析案例-基于RFM模型对电商客户价值分析 |
| 大数据分析案例-基于逻辑回归算法构建垃圾邮件分类器模型 |
| 大数据分析案例-基于决策树算法构建员工离职预测模型 |
| 大数据分析案例-基于KNN算法对茅台股票进行预测 |
| 大数据分析案例-基于多元线性回归算法构建广告投放收益模型 |
| 大数据分析案例-基于随机森林算法构建返乡人群预测模型 |
| 大数据分析案例-基于决策树算法构建金融反欺诈分类模型 |
目录
1.项目背景
2.项目简介
2.1项目说明
2.2数据说明
2.3技术工具
3.算法原理
4.项目实施步骤
4.1理解数据
4.2数据预处理
4.3探索性数据分析
4.3.1糖尿病确诊比例
4.3.2查看年龄和IBM的分布
4.3.3分析身体/心里健康对糖尿病的影响
4.3.4分析吸烟对糖尿病的影响
4.3.5饮食对糖尿病的影响
4.3.6喝酒对糖尿病的影响
4.3.7相关性分析
4.4特征工程
4.5模型构建
4.6模型评估
4.7模型预测
5.实验总结
源代码
1.项目背景
糖尿病是一种严重的慢性代谢性疾病,其主要特征是血糖水平持续升高,导致机体内多个系统和器官受损。据世界卫生组织(WHO)的数据,全球有大约4.60亿成年人患有糖尿病,这个数字在过去几十年里持续增长。糖尿病不仅对患者的生活质量造成了严重影响,还会增加心血管疾病、肾脏疾病、神经系统疾病等多种并发症的风险,对医疗资源和社会经济产生了巨大压力。
早期的糖尿病诊断对于控制疾病进程、减少并发症风险具有重要意义。然而,糖尿病的早期症状不明显,很多患者在确诊时已经存在一定的并发症。因此,开发一种准确、可靠的糖尿病确诊预测模型对于早期干预和治疗至关重要。
机器学习和人工智能技术在医疗领域的应用日益广泛,尤其是在疾病诊断、预测和患者管理方面。基于机器学习算法构建糖尿病确诊预测模型,可以利用大量的临床数据和生物指标来辅助医生进行糖尿病的早期筛查和诊断。LightGBM(Light Gradient Boosting Machine)作为一种梯度提升树算法,在处理高维、非线性数据方面具有出色的性能,能够从复杂的数据中挖掘出潜在的模式和关联关系,因此被广泛用于医疗数据分析和预测建模。
2.项目简介
2.1项目说明
本研究旨在基于LightGBM算法构建糖尿病确诊预测模型,通过分析临床数据中的生物特征、生活习惯、家族病史等因素,实现对患病风险的预测。通过该模型,可以为医生提供更多的客观数据支持,帮助其做出更准确的诊断和治疗决策,同时也可以为患者提供个性化的健康管理建议,从而有效降低糖尿病的发病率和并发症风险,改善患者的生活质量。
2.2数据说明
本实验数据集来源于Kaggle,原始数据集共有70692条数据,18列特征变量,具体各变量解释如下:
Age:13级年龄组(1 = 18-24 / 2 = 25-29 / 3 = 30-34 / 4 = 35-39 / 5 = 40-44 / 6 = 45-49 / 7 = 50-54 / 8 = 55-59 / 9 = 60-64 / 10 = 65-69 / 11 = 70-74 / 12 = 75-79 / 13 = 80以上)
Sex:患者的性别(1:男性;0:女)
HighChol:0 =无高胆固醇1 =高胆固醇
CholCheck: 0 = 5年内无胆固醇检查1 = 5年内有胆固醇检查
BMI:身体质量指数
Smoker:你一生中抽过至少100支烟吗?[注:5包= 100支]0 =否1 =是
HeartDiseaseorAttack:冠心病(CHD)或心肌梗死(MI) 0 =否1 =有
PhysActivity:过去30天内的体力活动(不包括作业0 =否1 =有)
Fruits:每天至少吃一次水果0 =不吃1 =吃
Veggies:每天吃蔬菜1次或更多0 =不1 =是
HvyAlcoholConsump:(成年男性>=每周14杯,成年女性>=每周7杯)0 =否1 =是
GenHlth:你认为你的总体健康状况是:1-5级1 =极好2 =很好3 =好4 =一般5 =差
MentHlth:心理健康状况差的天数1-30天
PhysHlth:过去30天内身体疾病或受伤天数1-30
DiffWalk:你走路或爬楼梯有严重困难吗?0 =否1 =是
Stroke:你曾经中风过。0 =否,1 =是
HighBP: 0 =不高,BP 1 =高BP
Diabetes:0 =没有糖尿病,1 =有糖尿病
2.3技术工具
Python版本:3.9
代码编辑器:jupyter notebook
3.算法原理
LightGBM算法基本原理
GBDT算法的基本思想是把上一轮的训练残差作为下一轮学习器训练的输入,即每一次的输入数据都依赖于上一次训练的输出结果。因此,这种训练迭代过程就需要多次对整个数据集进行遍历,当数据集样本较多或者维数过高时会增加算法运算的时间成本,并且消耗更高的内存资源。
而XGBoost算法作为GBDT的一种改进,在训练时是基于一种预排序的思想来寻找特征中的最佳分割点,这种训练方式同样也会导致内存空间消耗极大,例如算法不仅需要保存数据的特征值,还需要保存特征排序的结果;在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大,特别是当数据量级较大时,这种方式会消耗过多时间。
为了对这些问题进行优化,2017年微软公司提出了LightGBM算法(Light Gradient Boosting Machine),该算法也是基于GBDT算法的改进,,但相较于GBDT、XGBoost算法,LightGBM算法有效地解决了处理海量数据的问题,在实际应用中取得出色的效果。LightGBM算法主要包括以下几个特点:直方图算法(寻找最佳分裂点、直方图差加速)、Leaf-wise树生长策略、GOSS、EFB、支持类别型特征、高效并行以及Cache命中率优化等。
(1)直方图Histogram算法(减少大量计算与内存占用)
XGBoost算法在进行分裂时需要预先对每一个特征的原始数据进行预排序,而直方图Histogram算法则是对特征的原始数据进行“分桶#bin”,把数据划分到不同的离散区域中,再对离散数据进行遍历,寻找最优划分点。这里针对特征值划分的每一个“桶”有两层含义,一个是每个“桶”中样本的数量;另一个是每个“桶”中样本的梯度和(一阶梯度和的平方的均值等价于均方损失)。
可以看出,通过直方图算法可以让模型的复杂度变得更低,并且特征“分桶”后仅保存了的离散值,大大降低内存的占用率。其次,这种“分桶”的方式从某种角度来看相当于对模型增加了正则化,可以避免模型出现过拟合。
值得注意的是,直方图算法是使用了bin代替原始数据,相当于增加了正则化,这也意味着有更多的细节特征会被丢弃,相似的数据可能被划分到相同的桶中,所以bin的数量选择决定了正则化的程度,bin越少惩罚越严重,过拟合的风险就越低。
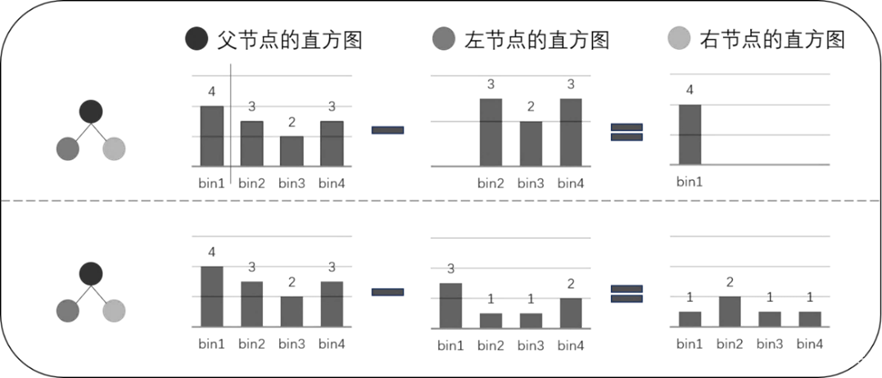
另外,在LightGBM直方图算法中还包括一种直方图作差优化,即LightGBM在得到一个叶子的直方图后,能够通过直方图作差的方式用极小的代价得到其兄弟叶子的直方图,如上图所示,当得到某个叶子的直方图和父节点直方图后,另一个兄弟叶子直方图也能够很快得到,利用这种方式,LightGBM算法速度得到进一步提升。
(2)带深度限制的Leaf-wise的叶子生长策略(减少大量计算、避免过拟合)
GBDT与XGBoost模型在叶子生长策略上均采用按层level-wise分裂的方式,这种方式在分裂时会针对同一层的每一个节点,即每次迭代都要遍历整个数据集中的全部数据,这种方式虽然可以使每一层的叶子节点并行完成,并控制模型的复杂度,但也会产生许多不必要搜索或分裂,从而消耗更多的运行内存,增加计算成本。
而LightGBM算法对其进行了改进,使用了按叶子节点leaf-wise分裂的生长方式,即每次是对所有叶子中分裂增益最大的叶子节点进行分裂,其他叶子节点则不会分裂。这种分裂方式比按层分裂会带来更小的误差,并且加快算法的学习速度,但由于没有对其他叶子进行分裂,会使得分裂结果不够细化,并且在每层中只对一个叶子不断进行分裂将增大树的深度,造成模型过拟合[25]。因此,LightGBM算法在按叶子节点生长过程中会限制树的深度来避免过拟合。
(3)单边梯度采样技术 (减少样本角度)
在梯度提升算法中,每个样本都有不同梯度值,样本的梯度可以反映对模型的贡献程度,通常样本的梯度越大贡献给模型的信息增益越多,而样本的梯度越小,在模型中表现的会越好。
举个例子来说,这里的大梯度样本可以理解为“练习本中的综合性难题”,小梯度样本可以理解为“练习本中的简单题”,对于“简单题”平时做的再多再好,而“难题”却做的很少,在真正的“考试”时还是会表现不好。但并不意味着小梯度样本(“简单题”)就可以直接剔除不用参与训练,因为若直接剔除小梯度样本,数据的分布会发生改变,从而影响模型的预测效果。
因此,LightGBM算法引入了单边梯度采样技术(Gradient-based One-Side Sampling,GOSS),其基本思想就是从减少样本的角度出发,利用样本的梯度大小信息作为样本重要性的考量,保留所有梯度大的样本点(“保留所有难题”),对于梯度小的样本点(“简单题”)按比例进行随机采样,这样既学习了小梯度样本的信息,也学习了大梯度样本的信息(“平时难题都做,简单题做一部分,在面临真正的考试时才可能稳定发挥,甚至超水平发挥”),在不改变原始数据分布的同时,减小了样本数量,提升了模型的训练速度。
(4)互斥特征捆绑(减少特征角度)
高维度的数据通常是非常稀疏的,并且特征之间存在互斥性(例如通过one-hot编码后生成的几个特征不会同时为0),这种数据对模型的效果和运行速度都有一定的影响。
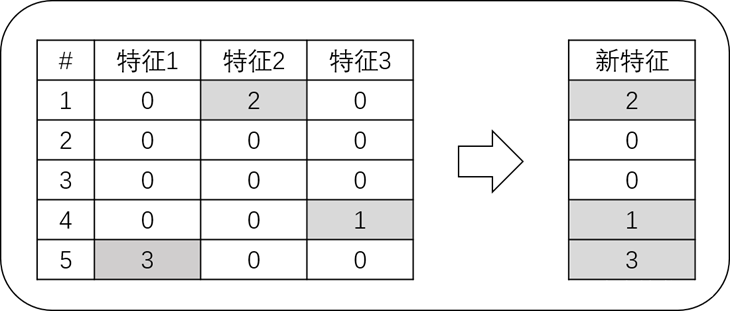
通过互斥特征捆绑算法(Exclusive Feature Bundling,EFB)可以解决高维度数据稀疏性问题,如下图中,设特征1、特征2以及特征3互为互斥的稀疏特征,通过EFB算法,将三个特征捆绑为一个稠密的新特征,然后用这一个新特征替代原来的三个特征,从而实现不损失信息的情况下减少特征维度,避免不必要0值的计算,提升梯度增强算法的速度。
总的来说,LightGBM是一个性能高度优化的GBDT 算法,也可以看成是针对XGBoost的优化算法,可以将LightGBM的优化用公式表达,如下式:LightGBM = XGBoost + Histogram + GOSS + EFB
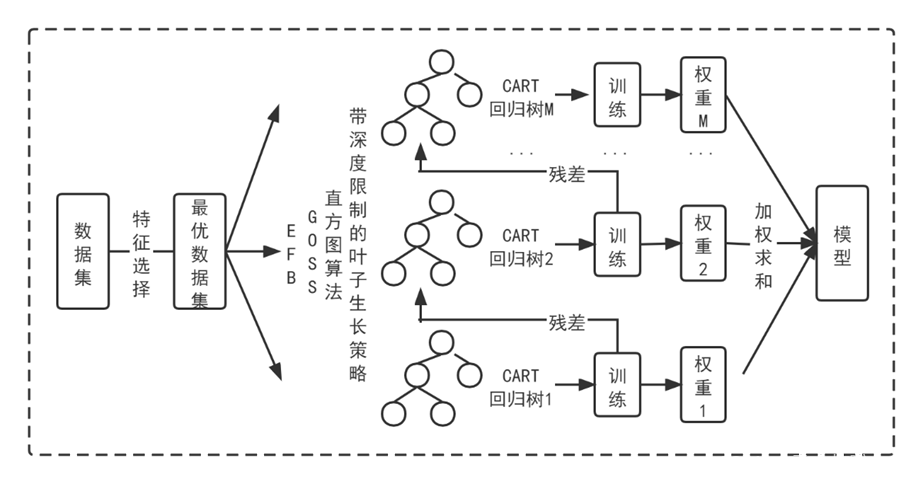
4.项目实施步骤
4.1理解数据
导入数据挖掘常用的第三方库,然后加载数据集

查看数据集大小

查看数据基本信息

查看数值型变量的描述性统计

4.2数据预处理
统计缺失值情况

发现原始数据集中各变量不存在缺失值
检测原始数据集是否存在重复值

结果为True,说明原始数据集存在重复值需要处理

这里我们直接删除即可
4.3探索性数据分析
4.3.1糖尿病确诊比例

可以发现数据集还是平衡的,确诊和非确诊比例几乎相同。
4.3.2查看年龄和IBM的分布


年龄和BMI均为正态分布
4.3.3分析身体/心里健康对糖尿病的影响


总体健康呈正态分布,中位数为3.0
Physical Health仍然很重,但在30时增加
心理健康问题很严重,这意味着更多人的心理健康问题更少
4.3.4分析吸烟对糖尿病的影响


男女比例相对相等,但女性略占优势
吸烟者与非吸烟者的比例相对相等,但非吸烟者占主导地位
更多的人拥有健康的心脏
越来越多的人进行体育锻炼
4.3.5饮食对糖尿病的影响


越来越多的人经常吃水果
越来越多的人经常吃蔬菜
4.3.6喝酒对糖尿病的影响


少量的酗酒者
更多从未经历过中风的人
高血压患者的数量很高
4.3.7相关性分析


4.4特征工程
准备建模用到的数据集,然后拆分数据集为训练集和测试集

4.5模型构建


对比四个模型,我们发现LightGBM算法模型准确率最高,故我们最终选取其作为实验模型。
4.6模型评估



打印特征重要性评分并可视化


可以发现BMI、年龄、身心健康对糖尿病的影响最大,重要性程度最大。
4.7模型预测
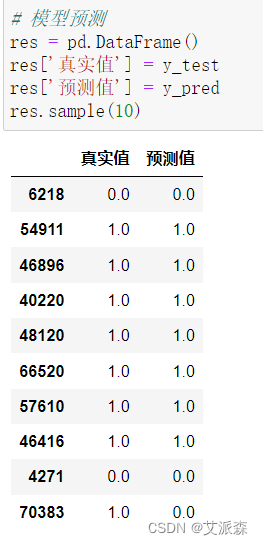
随机抽取10个预测结果来检测模型效果,发现10个中错误一个,模型效果还不错。
5.实验总结
本研究旨在基于LightGBM算法构建糖尿病确诊预测模型,通过分析临床数据中的生物特征、生活习惯、家族病史等因素,实现对糖尿病患病风险的预测。经过数据采集、特征工程和模型训练等一系列步骤,我们得出以下总结:
-
数据收集和预处理: 我们收集了大量包括生物特征、生活习惯、家族病史等信息的临床数据。在数据预处理阶段,我们进行了缺失值填充、特征标准化等操作,确保数据的完整性和一致性。
-
特征工程: 通过对数据进行特征选择和提取,我们选择了对糖尿病预测具有重要影响的特征。这些特征可以包括血糖水平、体质指数、年龄、性别等因素。
-
模型构建和训练: 我们选择了LightGBM作为预测模型,这是一种基于梯度提升树的算法,能够有效处理高维、非线性数据,并能从复杂数据中学习出准确的模式。我们将经过特征工程处理后的数据分为训练集和测试集,利用训练集对模型进行训练,然后通过测试集进行模型的验证和评估。
-
模型评估: 我们使用一系列评估指标如准确率、精确率、召回率、F1-score等来评估模型的性能。通过与其他常见的机器学习算法进行比较,我们验证了LightGBM在糖尿病确诊预测上的优越性。
-
结果分析和应用前景: 实验结果显示,基于LightGBM构建的糖尿病确诊预测模型具有较高的准确率和预测性能,能够在早期辅助医生进行糖尿病的诊断和风险评估。该模型在临床实际中具有重要的应用前景,可以为医生提供更多的决策支持,帮助患者实现早期干预和管理,降低并发症风险,提高生活质量。
总之,本研究为糖尿病预测领域的深入探索提供了有力支持,展示了机器学习在医疗领域的应用潜力。然而,仍需要进一步的临床验证和数据积累,以不断优化模型性能,并确保其在实际应用中的稳定性和可靠性。
心得与体会:
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
源代码
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
import seaborn as sns
sns.set_style('whitegrid')
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
import warnings
warnings.filterwarnings('ignore')df = pd.read_csv('diabetes_data.csv')
df.head()
df.shape
df.info()
df.describe().T
df.isnull().sum() # 统计缺失值情况
any(df.duplicated()) # 检测原始数据是否存在重复值
df.drop_duplicates(inplace=True)
df.shape
df['Diabetes'].value_counts()
# 查看目标变量是否平衡
sns.countplot(x='Diabetes', data=df, palette=("mako"))
plt.title("Balanced data",size=12, fontstyle='italic', weight=900)
plt.ylabel("Total Count", size=16, family='monospace')
plt.show()
# 查看年龄和IBM的分布
fig1, ax = plt.subplots(3, 2, figsize=(16,12))
fig1.suptitle('Age and BMI Histograms')
fig1.delaxes(ax[2,1])
fig1.delaxes(ax[2,0])
fig1.delaxes(ax[1,1])
fig1.delaxes(ax[1,0])
ax[0,0].set_title('Age Description')
sns.histplot(data = df,x = 'Age',color = 'navy',alpha = 1,kde = True, ax = ax[0,0])
ax[0,1].set_title('BMI Description')
sns.histplot(data = df,x = 'BMI',color = 'indigo',alpha = 1,kde = True ,ax = ax[0,1])fig1.tight_layout()
年龄和BMI均为正态分布
# 分析身体/心里健康对糖尿病的影响
fig2, ax = plt.subplots(3, 2, figsize=(16,12))
fig2.suptitle('Health Histograms')
fig2.delaxes(ax[2,1])
fig2.delaxes(ax[2,0])
fig2.delaxes(ax[1,1])
ax[0,0].set_title('General Health Description')
sns.histplot(data = df,x = 'GenHlth',color = 'darkslateblue',alpha = 1,kde = True ,ax = ax[0,0])
ax[0,1].set_title('Pyshical Health Description')
sns.histplot(data = df,x = 'PhysHlth',color = 'navy',alpha = 1,kde = True ,ax = ax[0,1])
ax[1,0].set_title('Mental Health Description')
sns.histplot(data = df,x = 'MentHlth',color = 'navy',alpha = 1,kde = True ,ax = ax[1,0], bins = 12)fig2.tight_layout()
总体健康呈正态分布,中位数为3.0
Physical Health仍然很重,但在30时增加
心理健康问题很严重,这意味着更多人的心理健康问题更少
fig3, ax = plt.subplots(2, 2, figsize=(16,12))fig3.suptitle('General Health')
sns.countplot(x='Sex', data=df, palette=("Blues_d"), ax = ax[0,0])ax[0,0].set_xlabel('Sex (0 = Female & 1 = Male)', size=16, fontstyle='italic', weight=500 )
ax[0,0].set_ylabel('Total Count', size=16, family='monospace')
ax[0,0].set_title('Sex',size=12, fontstyle='italic', weight=900)sns.countplot(x='Smoker', data=df, palette=("Blues_d"),ax = ax[0,1])ax[0,1].set_title('Smokers',size=12, fontstyle='italic', weight=900)
ax[0,1].set_xlabel('Smoker (0 = no & 1 = yes)', size=16, fontstyle='italic', weight=500)
ax[0,1].set_ylabel('Total Count', size=16, family='monospace')sns.countplot(x='HeartDiseaseorAttack', data=df, palette=("Blues_d"),ax = ax[1,0])ax[1,0].set_xlabel('Heart Disease (0 = Healthy Heart & 1 = Has Heart Problem)', size=16, fontstyle='italic', weight=500)
ax[1,0].set_ylabel('Total Count', size=16, family='monospace')
ax[1,0].set_title('Heart Disease or Attack',size=12, fontstyle='italic', weight=900)sns.countplot(x='HeartDiseaseorAttack', data=df, palette=("Blues_d"),ax = ax[1,0])ax[1,0].set_xlabel('Heart Disease (0 = Healthy Heart & 1 = Has Heart Problem)', size=16, fontstyle='italic', weight=500)
ax[1,0].set_ylabel('Total Count', size=16, family='monospace')
ax[1,0].set_title('Heart Disease or Attack',size=12, fontstyle='italic', weight=900)sns.countplot(x='PhysActivity', data=df, palette=("Blues_d"),ax = ax[1,1])ax[1,1].set_xlabel('Physical Activity (0 = Non-Physically Acitve & 1 = Physically Active)', size=16, fontstyle='italic', weight=500)
ax[1,1].set_ylabel('Total Count', size=16, family='monospace')
ax[1,1].set_title('Physical Activity',size=12, fontstyle='italic', weight=900)
fig3.tight_layout()男女比例相对相等,但女性略占优势
吸烟者与非吸烟者的比例相对相等,但非吸烟者占主导地位
更多的人拥有健康的心脏
越来越多的人进行体育锻炼
fig4, ax = plt.subplots(1, 2, figsize=(10,5))fig4.suptitle('Healthy eating')
sns.countplot(x='Fruits', data=df, palette=("Blues_d"), ax = ax[0])
ax[0].set_xlabel('Eats Fruits (0 = Non-Regulary Acitve & 1 = Regularly)', size=9, fontstyle='italic', weight=500)
ax[0].set_ylabel('Total Count', size=9, family='monospace')
ax[0].set_title('Fruit Consumption',size=12, fontstyle='italic', weight=900)
sns.countplot(x='Veggies', data=df, palette=("Blues_d"), ax= ax[1])
ax[1].set_xlabel('Eats Vegtables (0 = Non-Regulary Acitve & 1 = Regularly)', size=9, fontstyle='italic', weight=500)
ax[1].set_ylabel('Total Count', size=9, family='monospace')
ax[1].set_title('Vegtable Consumption',size=12, fontstyle='italic', weight=900)fig4.tight_layout()
越来越多的人经常吃水果
越来越多的人经常吃蔬菜
fig5, ax = plt.subplots(3, 2, figsize=(16,12))fig5.suptitle('Health Disorders')
fig5.delaxes(ax[2,1])
fig5.delaxes(ax[2,0])
fig5.delaxes(ax[1,1])
sns.countplot(x='HvyAlcoholConsump', data=df, palette=("Blues_d"), ax = ax[0,0])
ax[0,0].set_xlabel('Alcohol Consumption (0 = Non-Heavy Active & 1 = Heavy)', size=16, fontstyle='italic', weight=500)
ax[0,0].set_ylabel('Total Count', size=16, family='monospace')
ax[0,0].set_title('Alcohol Consumption',size=12, fontstyle='italic', weight=900)
sns.countplot(x='Stroke', data=df, palette=("Blues_d"), ax = ax[0,1])
ax[0,1].set_xlabel('Stroke (0 = Never Experienced a Stroke & 1 = Has Experienced a Stroke)', size=16, fontstyle='italic', weight=500)
ax[0,1].set_ylabel('Total Count', size=16, family='monospace')
ax[0,1].set_title('Stroke',size=12, fontstyle='italic', weight=900)
sns.countplot(x='HighBP', data=df, palette=("Blues_d"),ax = ax[1,0])
ax[1,0].set_xlabel('Blood-Pressure(0 = Normal Blood-Pressure & 1 = High Blood-Pressure)', size=16, fontstyle='italic', weight=500)
ax[1,0].set_ylabel('Total Count', size=16, family='monospace')
ax[1,0].set_title('Blood-Pressure',size=12, fontstyle='italic', weight=900)
fig5.tight_layout()
少量的酗酒者
更多从未经历过中风的人
高血压患者的数量很高
# 相关系数热力图
plt.figure(figsize=(15,15))
correlation_mat = df.corr()
sns.heatmap(correlation_mat, annot = True)
plt.show()
from sklearn.model_selection import train_test_split
# 准备建模的数据
X = df.drop('Diabetes',axis=1)
y = df['Diabetes']
# 划分数据集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42)
print('训练集大小:',X_train.shape[0])
print('测试集大小:',X_test.shape[0])
# 构建逻辑回归模型
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train,y_train)
print('逻辑回归模型准确率:',lr.score(X_test,y_test))
# 构建KNN模型
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(X_train,y_train)
print('KNN模型准确率:',knn.score(X_test,y_test))
# 构建决策树模型
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier()
tree.fit(X_train,y_train)
print('决策树模型准确率:',tree.score(X_test,y_test))
# 构建lightgbm模型
from lightgbm import LGBMClassifier
gbm = LGBMClassifier()
gbm.fit(X_train,y_train)
print('lightgbm模型准确率:',gbm.score(X_test,y_test))
from sklearn.metrics import f1_score,r2_score,confusion_matrix,classification_report,auc,roc_curve
# 模型评估
y_pred = gbm.predict(X_test)
print('模型的F1值:',f1_score(y_test,y_pred))
print('模型混淆矩阵:','\n',confusion_matrix(y_test,y_pred))
print('模型分类报告:','\n',classification_report(y_test,y_pred))
# 画出ROC曲线
y_prob = gbm.predict_proba(X_test)[:,1]
false_positive_rate, true_positive_rate, thresholds = roc_curve(y_test, y_prob)
roc = auc(false_positive_rate, true_positive_rate)
plt.title('ROC')
plt.plot(false_positive_rate,true_positive_rate, color='red',label = 'AUC = %0.2f' % roc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],linestyle='--')
plt.axis('tight')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
# 特征重要性评分
feat_labels = X_train.columns[0:]
importances = gbm.feature_importances_
indices = np.argsort(importances)[::-1]
index_list = []
value_list = []
for f,j in zip(range(X_train.shape[1]),indices):index_list.append(feat_labels[j])value_list.append(importances[j])
plt.figure(figsize=(10,6))
plt.barh(index_list[::-1],value_list[::-1])
plt.yticks(fontsize=12)
plt.title('feature importance',fontsize=14)
plt.show()
# 模型预测
res = pd.DataFrame()
res['真实值'] = y_test
res['预测值'] = y_pred
res.sample(10)
相关文章:
大数据分析案例-基于LightGBM算法构建糖尿病确诊预测模型
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

Mysql查询重复数据常用方法
在平常的开发工作中,我们经常需要查询数据,比如查询某个表中重复的数据,那么,具体应该怎么实现呢?常用的方法都有哪些呢? 测试表中数据: 1:查询名字重复的数据 having: …...

Go framework-GORM
目录 一、GORM 1、GORM连接数据库 2、单表的增删改查 3、结构体名和表名的映射规则 4、gorm.Model匿名字段 5、结构体标签gorm 6、多表操作 7、常用方法 8、支持原生SQL 9、Gin整合GORM 一、GORM ORM:即Object-Relational Mapping,它的作用是在…...

FirmAE 工具安装(解决克隆失败 网络问题解决)
FirmAE官方推荐使用Ubuntu 18.04系统进行安装部署,FirmAE工具的安装部署十分简单,只需要拉取工具仓库后执行安装脚本即可。 首先运行git clone --recursive https://kgithub.com/pr0v3rbs/FirmAE命令 拉取FirmAE工具仓库,因为网络的问题&…...

css实现九宫格布局
要使用CSS实现九宫格布局,可以创建一个包含九个元素的容器,并使用display: grid属性将其设置为网格布局。然后,使用grid-template-columns和grid-template-rows属性来定义网格的行和列布局。接下来,使用grid-gap属性来设置网格的行…...

linux下系统问题排查基本套路
文章目录 总结常用命令原文GC相关网络TIME_WAITCLOSE_WAIT 总结常用命令 top 查找cpu占用高的进程ps 找到对应进程的pidtop -H -p pid 查找cpu利用率较高的线程printf ‘%x\n’ pid 将线程pid转换为16进制得到 nidjstack pid |grep ‘nid’ -C5 –color 在jstack中找到对应堆栈…...
想解锁禁用的iPhone?除了可以使用电脑之外,这里还有不需要电脑的方法!
多次输入错误的密码后,iPhone将显示“iPhone已禁用”。这种情况看起来很棘手,因为你现在不能用iPhone做任何事情。对于这种情况,我们提供了几种有效的方法来帮助你在最棘手的问题中解锁禁用的iPhone。你可以选择使用或不使用电脑来解锁禁用的iPhone。 一、为什么你的iPhone…...

基于Springboot+Thymeleaf学生在线考试管理系统——LW模板
摘 要 随着当前大数据时代的飞速发展,信息技术以及数据科学不断的普及,教育界也随之更新换代。无粉尘黑板以及电子化考试都已经是在各种学校中普及使用,而且因为操作简单以及对环境没有任何影响,这也将是未来发展的重大趋势。而由…...
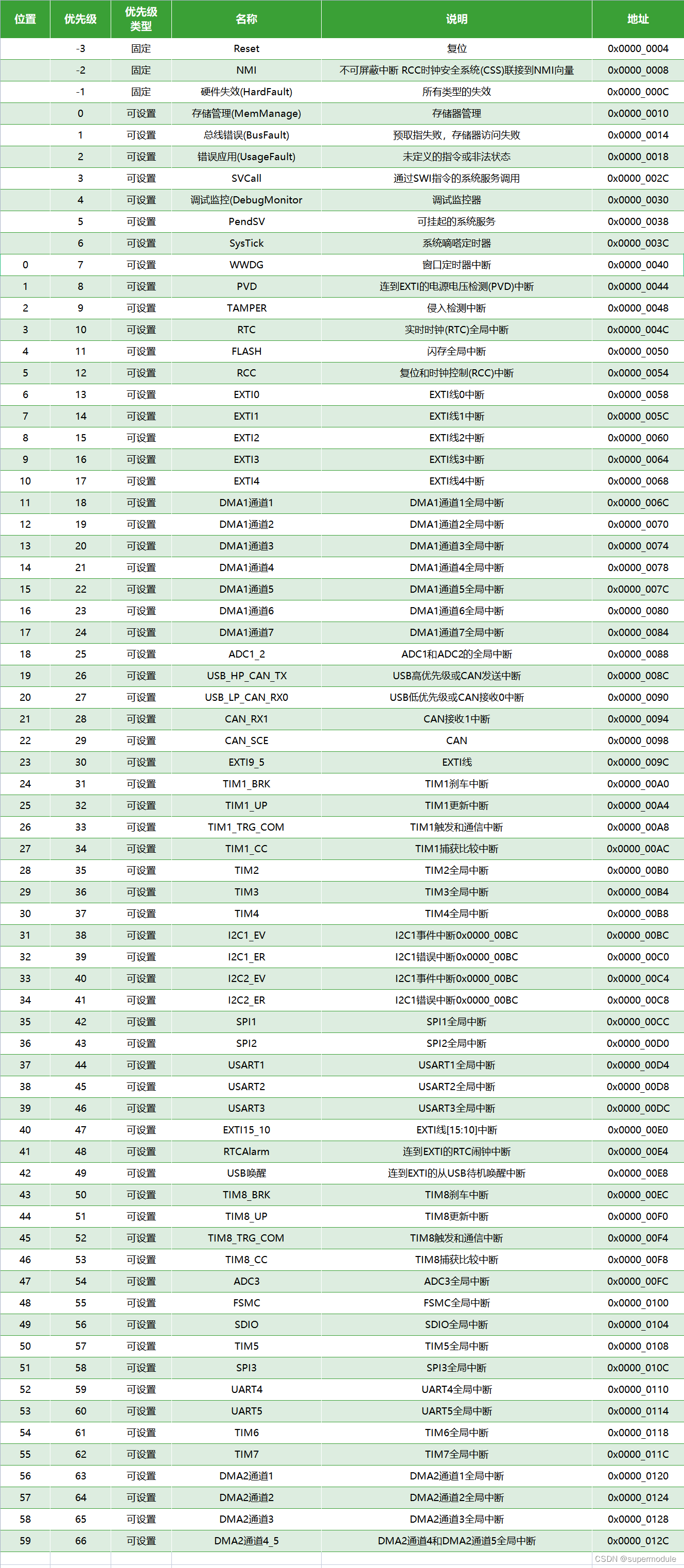
STM32f103c6t6/STM32f103c8t6寄存器开发
目录 资料 寻址区 2区 TIMx RTC WWDG IWDG SPI I2S USART I2C USB全速设备寄存器 bxCAN BKP PWR DAC ADC 编辑 EXTI 编辑 GPIO AFIO SDIO DMA CRC RCC FSMC USB_OTG ETH(以太网) 7区 配置流程 外部中断 硬件中断 例子 点灯 …...

MySQL Connection not available.
Mysql 报错 最近部署在服务器上的mysql总是报这种错。 但是在服务器上,使用命令行是可以登录进mysq的。 cursor db.cursor() File “/home/ubuntu/miniconda3/envs/chatbot_env/lib/python3.9/site-packages/mysql/connector/connection_cext.py”, line 700, in …...

PHP反序列化 字符串逃逸
前言 最近在打西电的新生赛,有道反序列化的题卡了很久,今天在NSS上刷题的时候突然想到做法,就是利用字符串逃逸去改变题目锁死的值,从而实现绕过 为了研究反序列化的字符串逃逸 我们先简单的测试下 原理 <?php class escape…...
DockerFile解析
1. 是什么 Dockerfile是田来构建Docker镜像的文本文件,是由一条条构建镜像所需的指令和参数构成的脚本 1.1 概述 1.2 官网 Dockerfile reference | Docker Documentation 1.3 构建三步骤 1. 编写dockerfile文件 2. docker build命令构建镜像 3. docker run依镜像运…...

斯坦福大学医学院教授:几年内ChatGPT之类的AI将纳入日常医学实践
注意:本信息仅供参考,分享此内容旨在传递更多信息之目的,并不意味着赞同其观点或证实其说法。 在一项新研究中,斯坦福大学研究人员发现,ChatGPT在复杂临床护理考试题中可以胜过一、二年级的医学生。此项研究显示&#…...
)
golang 命令行 command line (flag,os,arg,args)
目录 1. golang 命令行 command line1.1. Introduction1.2. Parsing Arguments from the command line (os package)1.2.1. Get the number of args1.2.2. Iterate over all arguments 1.3. Using flags package1.3.1. Parse Typed Flags1.3.2. Set flags from the script1.3.3…...

Shell语法揭秘:深入探讨常见Linux Shell之间的语法转换
深入探讨常见Linux Shell之间的语法转换 一、引言二、Linux常用Shell:Bash、Zsh、Ksh、Csh、Tcsh和Fish的简介2.1、Bash、Zsh、Ksh、Csh、Tcsh和Fish的特点和用途2.2、语法差异是常见Shell之间的主要区别 三、变量和环境设置的语法差异3.1、变量定义和使用的不同语法…...

Python3 基础语法
Python3 基础语法 编码 默认情况下,Python 3 源码文件以 UTF-8 编码,所有字符串都是 unicode 字符串。 当然你也可以为源码文件指定不同的编码: # -*- coding: cp-1252 -*- 上述定义允许在源文件中使用 Windows-1252 字符集中的字符编码&…...
spring boot分装通用的查询+分页接口
背景 在用spring bootmybatis plus实现增删改查的时候,总是免不了各种模糊查询和分页的查询。每个数据表设计一个模糊分页,这样代码就造成了冗余,且对自身的技能提升没有帮助。那么有没有办法实现一个通用的增删改查的方法呢?今天…...

【OpenCV】OpenCV环境搭建,Mac系统,C++开发环境
OpenCV环境搭建,Mac系统,C开发环境 一、步骤VSCode C环境安装运行CMake安装运行OpenCV 安装CMakeList 一、步骤 VSCode C环境安装CMake 安装OpenCV 安装CmakeList.txt VSCode C环境安装运行 访问官网 CMake安装运行 CMake官网 参考文档 OpenCV 安…...
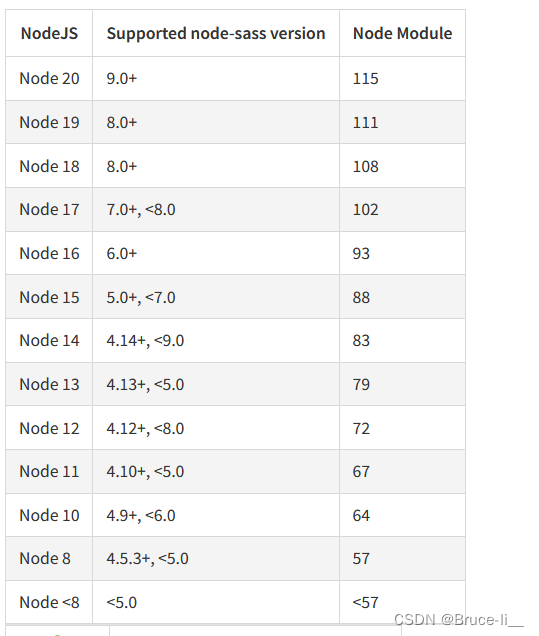
node安装node-sass依赖失败(版本不一致)
1.官网对应node版本 https://www.npmjs.com/package/node-sass2.node-sass版本对应表...

联想小新Pro 16笔记本键盘失灵处理方法
问题描述: 联想小新Pro 16新笔记本开机准备激活,到连接网络的时候就开始触控板、键盘失灵,但是有意思的是键盘的背光灯是可以调节关闭的;外接鼠标是正常可以移动的,但是只要拔掉外接鼠标再插回去的时候就不能用了&…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

ServerTrust 并非唯一
NSURLAuthenticationMethodServerTrust 只是 authenticationMethod 的冰山一角 要理解 NSURLAuthenticationMethodServerTrust, 首先要明白它只是 authenticationMethod 的选项之一, 并非唯一 1 先厘清概念 点说明authenticationMethodURLAuthenticationChallenge.protectionS…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...