使用 PyTorch 进行高效图像分割:第 1 部分
一、说明
在这个由 4 部分组成的系列中,我们将使用 PyTorch 中的深度学习技术从头开始逐步实现图像分割。我们将在本文中从图像分割所需的基本概念和想法开始本系列。

图1:宠物图像及其分割掩码(来源:牛津-IIIT宠物数据集)
图像分割是一种隔离属于图像中特定对象的像素的技术。对象像素的隔离为有趣的应用打开了大门。例如,在图 1 中,右侧的图像是与左侧黄色像素属于宠物的宠物图像对应的遮罩。一旦像素被识别出来,我们可以很容易地使宠物变大或改变图像背景。该技术广泛用于多种社交媒体应用程序中的面部过滤器功能。
在本系列文章的最后,我们的目标是让读者了解构建视觉 AI 模型并使用 PyTorch 使用不同设置运行实验所需的所有步骤。
二、本系列文章
本系列面向所有深度学习经验水平的读者。如果您想了解深度学习和视觉AI的实践以及一些扎实的理论和实践经验,那么您来对地方了!这将是一个由 4 部分组成的系列,包含以下文章:
- 概念和想法(本文)
- 基于 CNN 的模型
- 深度可分离卷积
- 基于视觉变压器的模型
三、图像分割简介
图像分割将图像划分或分割为对应于对象、背景和边界的区域。请看图 2,其中显示了城市场景。它用不同颜色的遮罩标记与汽车、摩托车、树木、建筑物、人行道和其他有趣物体相对应的区域。这些区域通过图像分割技术进行识别。
从历史上看,我们使用专门的图像处理工具和管道将图像分解为区域。然而,由于过去二十年来视觉数据的惊人增长,深度学习已成为图像分割任务的首选解决方案。它大大减少了对专家构建特定领域图像分割策略的依赖,就像过去所做的那样。如果有足够的训练数据可用于任务,深度学习从业者可以训练图像分割模型。

图 2:来自 a2d2 数据集的分割场景 (CC BY-ND 4.0)
3.1 图像分割有哪些应用?
图像分割在通信、农业、交通、医疗保健等多个领域都有应用。此外,其应用随着视觉数据的增长而增长。以下是一些示例:
- 在自动驾驶汽车中,深度学习模型不断处理来自车载摄像头的视频馈送,将场景分割成汽车、行人和交通信号灯等物体,这对于汽车安全运行至关重要。
- 在医学成像中,图像分割可帮助医生识别医学扫描中与肿瘤、病变和其他异常相对应的区域。
- 在 Zoom 视频通话中,它用于通过用虚拟场景替换背景来保护个人隐私。
- 在农业中,使用图像分割识别的杂草和作物区域的信息用于保持健康的作物产量。
您可以在v7labs的此页面上阅读有关图像分割实际应用的更多详细信息。
3.2 图像分割任务有哪些不同类型?
有许多不同类型的图像分割任务,每种任务都有其优点和缺点。两种最常见的图像分割任务类型是:
- 类或语义分割:类分割为每个图像像素分配一个语义类,例如背景、道路、汽车或人物。如果图像中有 2 辆车,则与两辆车对应的像素将被标记为汽车像素。它通常用于自动驾驶和场景理解等任务。
- 对象或实例分割:对象分割可识别对象并为图像中的每个唯一对象分配遮罩。如果图像中有 2 辆汽车,则对应于每辆车的像素将被标识为属于单独的对象。对象分割通常用于跟踪单个对象,例如编程为跟随前方特定汽车的自动驾驶汽车。

图3:对象和类分割(来源:MS Coco — 知识共享署名许可))
在本系列中,我们将重点介绍类细分。
3.3 实施高效图像分割所需的决策
高效训练模型以提高速度和准确性需要在项目的生命周期中做出许多重要决策。这包括(但不限于):
- 深度学习框架的选择
- 选择一个好的模型架构
- 选择一个有效的损失函数来优化您关心的方面
- 避免过度拟合和欠拟合
- 评估模型的准确性
在本文的其余部分,我们将更深入地探讨上述每个方面,并提供许多文章链接,这些文章可以更详细地讨论每个主题,可以在此处介绍。
四、用于高效图像分割的 PyTorch
4.1 什么是 PyTorch?
“PyTorch是一个开源深度学习框架,旨在灵活和模块化地进行研究,具有生产部署所需的稳定性和支持。PyTorch提供了一个Python包,用于高级功能,如张量计算(如NumPy),具有强大的GPU加速和TorchScript,可在渴望模式和图形模式之间轻松过渡。随着最新版本的PyTorch,该框架提供了基于图形的执行,分布式训练,移动部署和量化。(来源:PyTorch上的Meta AI页面)
PyTorch是用Python和C++编写的,这使得它易于使用和学习以及高效运行。它支持广泛的硬件平台,包括(服务器和移动)CPU、GPU 和 TPU。
4.2 为什么 PyTorch 是图像分割的不错选择?
PyTorch 是深度学习研究和开发的热门选择,因为它为创建和训练神经网络提供了灵活而强大的环境。由于以下功能,它是实现基于深度学习的图像分割的绝佳框架选择:
- 灵活性:PyTorch 是一个灵活的框架,允许您以多种方式创建和训练神经网络。您可以使用预先训练的模型,也可以非常轻松地从头开始创建自己的模型
- 后端支持:PyTorch 支持多个后端,例如 GPU/TPU 硬件
- 域库:PyTorch 拥有一组丰富的域库,使处理特定垂直数据变得非常容易。例如,对于与视觉(图像/视频)相关的AI,PyTorch提供了一个名为Torchvision的库,我们将在本系列中广泛使用。
- 易用性和社区采用:PyTorch 是一个易于使用的框架,文档齐全,拥有庞大的用户和开发人员社区。许多研究人员使用PyTorch进行实验,他们发表的论文中的结果在PyTorch中免费实现了该模型。
五、数据集的选择
我们将使用牛津IIIT Pet数据集(在CC BY-SA 4.0下授权)进行类细分。此数据集在训练集中有 3680 张图像,每个图像都有一个与之关联的分割三图。三元组是 3 个像素类之一:
- 宠物
- 背景
- 边境
我们选择这个数据集是因为它足够多样化,可以为我们提供重要的类分割任务。此外,它并没有那么复杂,以至于我们最终会花时间在处理阶级失衡等事情上......并忘记了我们想要了解和解决的主要问题;即类细分。
用于图像分割任务的其他常用数据集包括:
- Pascal VOC(视觉对象类)
- 可可女士
- 城市景观
六、使用 PyTorch 实现高效的图像分割
在本系列中,我们将从头开始训练多个用于类细分的模型。从头开始构建和训练模型时需要考虑许多注意事项。下面,我们将介绍您在这样做时需要做出的一些关键决策。
6.1 为您的任务选择正确的模型
在为图像分割选择正确的深度学习模型时,需要考虑许多因素。一些最重要的因素包括:
- 图像分割任务的类型:图像分割任务主要有两种类型:类(语义)分割和对象(实例)分割。由于我们关注的是更简单的类分割问题,因此我们将考虑相应地对问题进行建模。
- 数据集的大小和复杂性:数据集的大小和复杂性会影响我们需要使用的模型的复杂性。例如,如果我们处理的空间维度较小的图像,我们可能会使用更简单(或更浅)的模型,例如全卷积网络(FCN)。如果我们使用大型复杂的数据集,我们可能会使用更复杂(或更深入)的模型,例如U-Net。
- 预训练模型的可用性:有许多预训练模型可用于图像分割。这些模型可以用作我们自己模型的起点,也可以直接使用它们。但是,如果我们使用预先训练的模型,我们可能会受到模型输入图像的空间维度的限制。在本系列中,我们将重点介绍如何从头开始训练模型。
- 可用的计算资源:深度学习模型的训练成本可能很高。如果我们的计算资源有限,我们可能需要选择更简单的模型或更高效的模型架构。
在本系列中,我们将使用牛津 IIIT Pet 数据集,因为它足够大,我们可以训练中等大小的模型并需要使用 GPU。我们强烈建议您在 kaggle.com 上创建一个帐户,或使用Google Colab的免费GPU来运行本系列中引用的笔记本和代码。
6.2 模型体系结构
以下是一些最流行的用于图像分割的深度学习模型架构:
- U-Net:U-Net是一种卷积神经网络,通常用于图像分割任务。它使用跳过连接,这有助于更快地训练网络并提高整体准确性。如果你必须选择,U-Net总是一个优秀的默认选择!
- FCN:全卷积网络(FCN)是一个全卷积网络,但它没有U-Net那么深。深度不足主要是由于在较高的网络深度下,精度下降。这使得训练速度更快,但可能不如U-Net准确。
- SegNet:SegNet是一种类似于U-Net的流行模型架构,使用比U-Net更少的激活内存。我们将在本系列中使用SegNet。
- 视觉转换器(ViT):视觉转换器由于其简单的结构和注意力机制对文本,视觉和其他领域的适用性而最近越来越受欢迎。视觉转换器在训练和推理方面可以更有效(与CNN相比),但与卷积神经网络相比,历史上需要更多的数据来训练。我们还将在本系列中使用 ViT。

图 4:U-Net 模型架构。
这些只是可用于图像分割的众多深度学习模型中的一小部分。特定任务的最佳模型将取决于前面提到的因素、特定任务和您自己的实验。
6.3 选择正确的损失函数
图像分割任务的损失函数选择很重要,因为它会对模型的性能产生重大影响。有许多不同的损失函数可用,每个都有自己的优点和缺点。图像分割中最常用的损失函数是:
- 交叉熵损失:交叉熵损失是预测概率分布与真实概率分布之间差值的度量
- IoU 损失:IoU 损失衡量每个类的预测掩码和真实掩码之间的重叠量。IoU损失会惩罚预测或召回会受到影响的情况。定义的 IoU 是不可微分的,因此我们需要稍微调整它以将其用作损失函数
- 骰子损失:骰子损失也是预测掩码和地面真实掩码之间重叠的度量。
- 特沃斯基损失:特沃斯基损失被提议为一个鲁棒损失函数,可用于处理不平衡的数据集。
- 局灶性丧失:局灶性丧失旨在关注难以分类的示例。这有助于提高模型在具有挑战性的数据集上的性能。
特定任务的最佳损失函数将取决于任务的特定要求。例如,如果精度更重要,那么 IoU 损失或骰子损失可能是更好的选择。如果任务不平衡,那么特沃斯基损失或焦点损失可能是不错的选择。训练模型时,使用的特定损失函数可能会影响模型的收敛率。
损失函数是模型的超参数,根据我们看到的结果使用不同的损失可以让我们更快地减少损失并提高模型的准确性。
默认值:在本系列中,我们将使用交叉熵损失,因为当结果未知时,选择它始终是一个不错的默认值。
您可以使用以下资源了解有关损失函数的更多信息。
- PyTorch 损失函数:终极指南
- 火炬视觉 — 损失
- 火炬计量
让我们详细看看我们在下面定义的 IoU 损失,它是分割任务交叉熵损失的稳健替代方案。
6.4 自定义欠条损失
IoU 被定义为并集上的交集。对于图像分割任务,我们可以通过计算(对于每个类)、模型预测的该类中像素的交集和地面实况分割掩码来计算这一点。
例如,如果我们有 2 个类:
- 背景
- 人
然后,我们可以确定哪些像素被归类为人,并将其与人的地面真实像素进行比较,并计算人员类的 IoU。同样,我们可以计算后台类的 IoU。
一旦我们有了这些特定于类的 IoU 指标,我们就可以选择将它们平均为未加权或加权,然后再对它们进行平均,以解释我们在前面的例子中看到的任何类型的类不平衡。
定义的 IoU 指标要求我们为每个指标计算硬标签。这需要使用 argmax() 函数,该函数不可微分,因此我们不能将此指标用作损失函数。因此,我们没有使用硬标签,而是应用 softmax() 并使用预测的概率作为软标签来计算 IoU 指标。这会产生一个可微分的指标,然后我们可以从中计算损失。因此,有时,在损失函数的上下文中使用时,IoU 指标也称为软 IoU 指标。
如果我们有一个介于 0.0 和 1.0 之间的度量 (M),我们可以将损失 (L) 计算为:
L = 1 — M
但是,如果您的指标的值介于 0.0 和 1.0 之间,这里有另一个技巧可以用来将指标转换为损失。计算:
L = -log(M)
即计算指标的负对数。这与之前的表述有明显的不同,你可以在这里和这里阅读它。基本上,它可以为您的模型带来更好的学习。
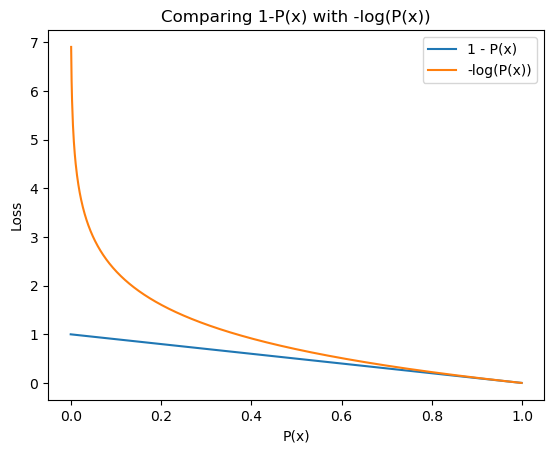
图 6:比较 1-P(x) 与 -log(P(x)) 导致的损耗。资料来源:作者。
使用IoU作为我们的损失也使损失函数更接近于捕获我们真正关心的东西。使用评估指标作为损失函数有利有弊。如果你有兴趣进一步探索这个领域,你可以从这个关于stackexchange的讨论开始。
6.5 数据增强
为了高效且有效地训练模型以获得良好的准确性,需要注意用于训练模型的训练数据的数量和类型。选择使用的训练数据将显着影响最终模型的准确性,因此,如果您希望从本系列文章中学到一件事,那么应该就是它!
通常,我们会将数据分成 3 个部分,这些部分大致按照下面提到的比例。
- 培训 (80%)
- 验证 (10%)
- 测试 (10%)
您将在训练集上训练模型,评估验证集的准确性,然后重复该过程,直到您对报告的指标感到满意。只有这样,您才会在测试集上评估模型,然后报告数字。这样做是为了防止任何类型的偏差蔓延到模型的架构和训练和评估期间使用的超参数中。通常,根据测试数据的结果调整设置的次数越多,结果的可靠性就越低。因此,我们必须将决策限制在训练和验证数据集上看到的结果。
在本系列中,我们将不使用测试数据集。相反,我们将使用测试数据集作为验证数据集,并对测试数据集应用数据增强,以便我们始终在略有不同的数据上验证模型。这可以防止我们在验证数据集上过度拟合我们的决策。这有点像黑客,我们这样做只是为了权宜之计和捷径。对于生产模型开发,您应该尝试坚持使用上述标准配方。
我们将在本系列中使用的数据集在训练集中有 3680 张图像。虽然这看起来像是大量的图像,但我们希望确保我们的模型不会过度拟合这些图像,因为我们将在多个时期训练模型。
在单个训练时期,我们在整个训练数据集上训练模型,并且我们通常会在生产中训练 60 个或更多时期的模型。在本系列中,我们将仅训练 20 个 epoch 的模型,以缩短迭代时间。为了防止过度拟合,我们将采用一种称为数据增强的技术,用于从现有输入数据生成新的输入数据。图像输入的数据增强背后的基本思想是,如果您稍微更改图像,感觉就像模型的新图像,但可以推断预期输出是否相同。以下是我们将在本系列中应用的数据增强的一些示例。
- 随机水平翻转
- 随机颜色抖动
虽然我们将使用Torchvision库来应用上述数据增强,但我们鼓励您评估Albumentations数据增强库的视觉任务。这两个库都有一组丰富的转换可用于图像数据。我们个人继续使用火炬视觉,仅仅是因为它是我们开始的。Albumentations 支持更丰富的数据增强基元,可以同时更改输入图像以及真实标注或掩码。例如,如果要调整图像大小或翻转图像,则需要对真实分割掩码进行相同的更改。Albumentations可以为您开箱即用。
从广义上讲,这两个库都支持在像素级别应用于图像或更改图像空间维度的转换。像素级变换被火炬视称为颜色变换,空间变换被火炬视称为几何变换。
下面,我们将看到Torchvision和Albumentations库应用的像素级和几何转换的一些示例。

图 7:使用相音应用于图像的像素级数据增强示例。来源:蛋白

图 8:使用 Torchvision 变换应用于图像的数据增强示例。来源:作者(笔记本)

图 9:使用蛋白转换应用的空间级别转换示例。来源:作者(笔记本)
6.6 评估模型的性能
在评估模型的性能时,您需要了解它在代表模型在实际数据上的性能质量的指标上的表现。例如,对于图像分割任务,我们想知道模型能够预测像素的正确类的准确度。因此,我们说像素精度是该模型的验证指标。
你可以使用你的评估指标作为损失函数(为什么不优化你真正关心的东西!),除了这可能并不总是可行的。
除了准确性之外,我们还将跟踪 IoU 指标(也称为 Jaccard 指数)和我们上面定义的自定义 IoU 指标。
要了解有关适用于图像分割任务的各种准确性指标的更多信息,请参阅:
- 所有细分指标 — Kaggle
- 如何评估图像分割模型
- 评估图像分割模型
6.7 使用像素精度作为性能指标的缺点
虽然准确度指标可能是衡量图像分割任务性能的不错默认选择,但它确实有其自身的缺点,根据您的具体情况,这些缺点可能很重要。
例如,考虑一个图像分割任务,以识别图片中人的眼睛,并相应地标记这些像素。因此,该模型会将每个像素分类为以下任一像素:
- 背景
- 眼睛
假设每个图像中只有 1 个人,并且 98% 的像素与眼睛不对应。在这种情况下,模型可以简单地学习将每个像素预测为背景像素,并在分割任务中实现 98% 的像素准确率。哇!

图 10:人脸图像及其眼睛的相应分割掩码。你可以看到眼睛只占整个图像的很小一部分。来源:改编自Unsplash
在这种情况下,使用 IoU 或 Dice 指标可能是一个更好的主意,因为 IoU 将捕获多少预测是正确的,并且不一定会因原始图像中每个类或类别所占区域而产生偏差。您甚至可以考虑使用每个类的 IoU 或骰子系数作为指标。这可以更好地捕获模型在手头任务中的性能。
当仅考虑像素精度时,我们要计算分割掩码的对象(上面示例中的眼睛)的精度和召回率可以捕获我们正在寻找的细节。
现在我们已经介绍了图像分割的大部分理论基础,让我们绕道而行,了解一下与实际工作负载的图像分割的推理和部署相关的考虑因素。
6.8 模型大小和推理延迟
最后但并非最不重要的一点是,我们希望确保我们的模型具有合理数量的参数,但不要太多,因为我们想要一个小而高效的模型。我们将在以后的文章中更详细地研究这一方面,这些文章与使用高效的模型架构减小模型大小有关。
就推理延迟而言,重要的是我们的模型执行的数学运算(多加法)的数量。模型大小和多个添加都可以使用火炬信息包显示。虽然多加法是确定模型延迟的一个很好的代理,但各个后端的延迟可能会有很大差异。确定模型在特定后端或设备上的性能的唯一真正方法是使用您希望在生产设置中看到的一组输入在该特定设备上对其进行分析和基准测试。
from torchinfo import summary
model = nn.Linear(1000, 500)
summary(model,input_size=(1, 1000),col_names=["kernel_size", "output_size", "num_params", "mult_adds"],col_width=15,
)输出:
====================================================================================================
Layer (type:depth-idx) Kernel Shape Output Shape Param # Mult-Adds
====================================================================================================
Linear -- [1, 500] 500,500 500,500
====================================================================================================
Total params: 500,500
Trainable params: 500,500
Non-trainable params: 0
Total mult-adds (M): 0.50
====================================================================================================
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 2.00
Estimated Total Size (MB): 2.01
====================================================================================================七、文章回顾
以下是我们到目前为止讨论的内容的快速回顾。
- 图像分割是一种将图像分割为多个片段的技术(来源:维基百科)
- 图像分割任务主要有两种类型:类(语义)分割和对象(实例)分割。类分割将图像中的每个像素分配给语义类。对象分割可识别图像中的每个单独对象,并为每个唯一对象分配一个遮罩
- 我们将使用PyTorch作为深度学习框架和牛津IIIT Pet数据集,在这一系列的高效图像分割中。
- 在为图像分割选择正确的深度学习模型时,需要考虑许多因素,包括(但不限于)图像分割任务的类型、数据集的大小和复杂性、预训练模型的可用性以及可用的计算资源。一些最流行的用于图像分割的深度学习模型架构包括U-Net,FCN,SegNet和Vision Transformer (ViT)。
- 图像分割任务的损失函数选择很重要,因为它会对模型的性能和训练效率产生重大影响。对于图像分割任务,我们可以使用交叉熵损失、IoU 损失、骰子损失或焦点损失(等等)
- 数据增强是一种有价值的技术,用于防止过度拟合以及处理训练数据不足
- 评估模型的性能对于手头的任务很重要,必须谨慎选择此指标
- 模型大小和推理延迟是开发模型时要考虑的重要指标,特别是如果您打算将其用于实时应用程序,例如人脸分割或背景噪声消除
在下一篇文章中,我们将研究一个卷积神经网络(CNN),它使用PyTorch从头开始构建,对Oxford IIIT Pet数据集执行图像分割。
相关文章:
使用 PyTorch 进行高效图像分割:第 1 部分
一、说明 在这个由 4 部分组成的系列中,我们将使用 PyTorch 中的深度学习技术从头开始逐步实现图像分割。我们将在本文中从图像分割所需的基本概念和想法开始本系列。 图1:宠物图像及其分割掩码(来源:牛津-IIIT宠物数据集) 图像分…...
vellum (Discovering Houdini VellumⅡ柔体系统)学习笔记
视频地址: https://www.bilibili.com/video/BV1ve411u7nE?p3&spm_id_frompageDriver&vd_source044ee2998086c02fedb124921a28c963(搬运) 个人笔记如有错误欢迎指正;希望可以节省你的学习时间 ~享受艺术 干杯🍻…...
最优的家电设备交互方式是什么?详解家电设备交互的演进之旅
家电,在人们的日常生活中扮演着不可或缺的角色,也是提升人们幸福感的重要组成部分,那你了解家电的发展史吗? 70年代 结婚流行“四大件”:手表、自行车、缝纫机,收音机,合成“三转一响”。 80年…...

前端面试总结心得
1.放在HTML里的哪一部分JavaScripts会在页面加载的时候被执行? A、文件头部位置;B、文件尾;C、<head>标签部分;D、<body>标签部分 (正确答案D) 2.队列和栈的区别是什么? 答案&am…...
STL---list
目录 1. list的介绍及使用 1.1 list的介绍 1.2 list的使用注意事项 2.list接口介绍及模拟实现 2.1构造编辑 2.2容量 2.3修改 3.list迭代器 4.迭代器失效 5.模拟实现 6.vector和list的区别 1. list的介绍及使用 1.1 list的介绍 list的文档介绍 1. list是可以在常…...

python判断ip所属地区 python 判断ip 网段
前言 IP地址是互联网中唯一标识一个设备的地址,有时候需要判断一个IP地址所属的地区,这就需要用到IP地址归属查询。本文将介绍Python如何通过IP地址查询所属地区并展示代码。 一、 IP地址归属查询 IP地址归属查询又称IP地址归属地查询、IP地址归属地定…...
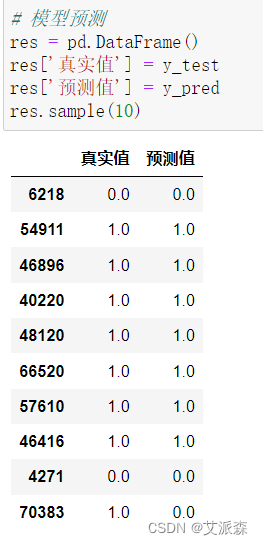
大数据分析案例-基于LightGBM算法构建糖尿病确诊预测模型
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

Mysql查询重复数据常用方法
在平常的开发工作中,我们经常需要查询数据,比如查询某个表中重复的数据,那么,具体应该怎么实现呢?常用的方法都有哪些呢? 测试表中数据: 1:查询名字重复的数据 having: …...

Go framework-GORM
目录 一、GORM 1、GORM连接数据库 2、单表的增删改查 3、结构体名和表名的映射规则 4、gorm.Model匿名字段 5、结构体标签gorm 6、多表操作 7、常用方法 8、支持原生SQL 9、Gin整合GORM 一、GORM ORM:即Object-Relational Mapping,它的作用是在…...

FirmAE 工具安装(解决克隆失败 网络问题解决)
FirmAE官方推荐使用Ubuntu 18.04系统进行安装部署,FirmAE工具的安装部署十分简单,只需要拉取工具仓库后执行安装脚本即可。 首先运行git clone --recursive https://kgithub.com/pr0v3rbs/FirmAE命令 拉取FirmAE工具仓库,因为网络的问题&…...

css实现九宫格布局
要使用CSS实现九宫格布局,可以创建一个包含九个元素的容器,并使用display: grid属性将其设置为网格布局。然后,使用grid-template-columns和grid-template-rows属性来定义网格的行和列布局。接下来,使用grid-gap属性来设置网格的行…...

linux下系统问题排查基本套路
文章目录 总结常用命令原文GC相关网络TIME_WAITCLOSE_WAIT 总结常用命令 top 查找cpu占用高的进程ps 找到对应进程的pidtop -H -p pid 查找cpu利用率较高的线程printf ‘%x\n’ pid 将线程pid转换为16进制得到 nidjstack pid |grep ‘nid’ -C5 –color 在jstack中找到对应堆栈…...
想解锁禁用的iPhone?除了可以使用电脑之外,这里还有不需要电脑的方法!
多次输入错误的密码后,iPhone将显示“iPhone已禁用”。这种情况看起来很棘手,因为你现在不能用iPhone做任何事情。对于这种情况,我们提供了几种有效的方法来帮助你在最棘手的问题中解锁禁用的iPhone。你可以选择使用或不使用电脑来解锁禁用的iPhone。 一、为什么你的iPhone…...

基于Springboot+Thymeleaf学生在线考试管理系统——LW模板
摘 要 随着当前大数据时代的飞速发展,信息技术以及数据科学不断的普及,教育界也随之更新换代。无粉尘黑板以及电子化考试都已经是在各种学校中普及使用,而且因为操作简单以及对环境没有任何影响,这也将是未来发展的重大趋势。而由…...
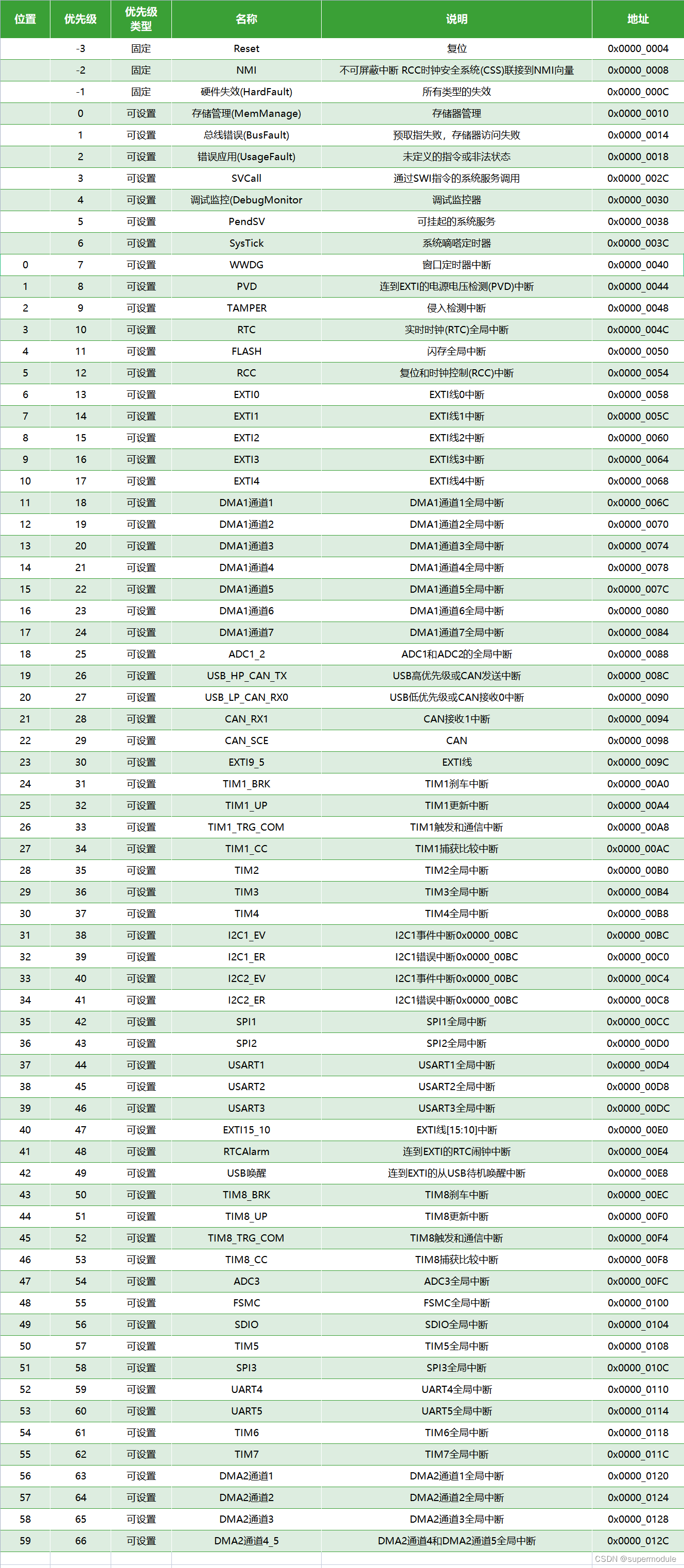
STM32f103c6t6/STM32f103c8t6寄存器开发
目录 资料 寻址区 2区 TIMx RTC WWDG IWDG SPI I2S USART I2C USB全速设备寄存器 bxCAN BKP PWR DAC ADC 编辑 EXTI 编辑 GPIO AFIO SDIO DMA CRC RCC FSMC USB_OTG ETH(以太网) 7区 配置流程 外部中断 硬件中断 例子 点灯 …...

MySQL Connection not available.
Mysql 报错 最近部署在服务器上的mysql总是报这种错。 但是在服务器上,使用命令行是可以登录进mysq的。 cursor db.cursor() File “/home/ubuntu/miniconda3/envs/chatbot_env/lib/python3.9/site-packages/mysql/connector/connection_cext.py”, line 700, in …...

PHP反序列化 字符串逃逸
前言 最近在打西电的新生赛,有道反序列化的题卡了很久,今天在NSS上刷题的时候突然想到做法,就是利用字符串逃逸去改变题目锁死的值,从而实现绕过 为了研究反序列化的字符串逃逸 我们先简单的测试下 原理 <?php class escape…...
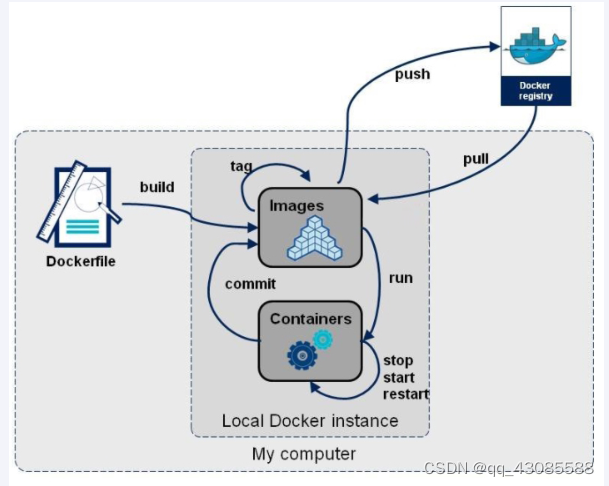
DockerFile解析
1. 是什么 Dockerfile是田来构建Docker镜像的文本文件,是由一条条构建镜像所需的指令和参数构成的脚本 1.1 概述 1.2 官网 Dockerfile reference | Docker Documentation 1.3 构建三步骤 1. 编写dockerfile文件 2. docker build命令构建镜像 3. docker run依镜像运…...

斯坦福大学医学院教授:几年内ChatGPT之类的AI将纳入日常医学实践
注意:本信息仅供参考,分享此内容旨在传递更多信息之目的,并不意味着赞同其观点或证实其说法。 在一项新研究中,斯坦福大学研究人员发现,ChatGPT在复杂临床护理考试题中可以胜过一、二年级的医学生。此项研究显示&#…...
)
golang 命令行 command line (flag,os,arg,args)
目录 1. golang 命令行 command line1.1. Introduction1.2. Parsing Arguments from the command line (os package)1.2.1. Get the number of args1.2.2. Iterate over all arguments 1.3. Using flags package1.3.1. Parse Typed Flags1.3.2. Set flags from the script1.3.3…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

区块链技术概述
区块链技术是一种去中心化、分布式账本技术,通过密码学、共识机制和智能合约等核心组件,实现数据不可篡改、透明可追溯的系统。 一、核心技术 1. 去中心化 特点:数据存储在网络中的多个节点(计算机),而非…...
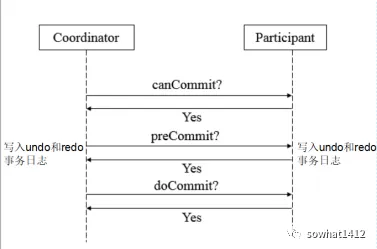
解析两阶段提交与三阶段提交的核心差异及MySQL实现方案
引言 在分布式系统的事务处理中,如何保障跨节点数据操作的一致性始终是核心挑战。经典的两阶段提交协议(2PC)通过准备阶段与提交阶段的协调机制,以同步决策模式确保事务原子性。其改进版本三阶段提交协议(3PC…...