Elasticsearch(十三)搜索---搜索匹配功能④--Constant Score查询、Function Score查询
一、前言
之前我们学习了布尔查询,知道了filter查询只在乎查询条件和文档的匹配程度,但不会根据匹配程度对文档进行打分,而对于must、should这两个布尔查询会对文档进行打分,那如果我想在查询的时候同时不去在乎文档的打分(对搜索结果的排序),只想过滤文本字段是否包含这个词,除了filter查询,我们还会介绍Constant Score查询。相反,如果想干预这个分数,我们会使用Function Score查询,这些都会在后面介绍到。
二、Constant Score查询
如果不想让检索词频率TF(Term Frequency)对搜索结果排序有影响,只想过滤某个文本字段是否包含某个词,可以使用Constant Score将查询语句包装起来。
假设需要查询city字段是否包含关键词“上海”的酒店,则请求的DSL如下:
POST /hotel/_search
{"query": {"constant_score": { //满足条件即打分为1(默认值是1)"filter": {"term": { //term查询city中是上海的城市"city": "上海"}}}}
}
查询结果如下:
{..."hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "hotel","_type" : "_doc","_id" : "004","_score" : 1.0,"_source" : {"title" : "京盛集团酒店","city" : "上海","price" : "800.00","create_time" : "2021-05-29 21:35:00","amenities" : "浴池(假日需预订),室内游泳池,普通停车场/充电停车场","full_room" : true,"location" : {"lat" : 36.940243,"lon" : 120.394},"praise" : 100}},{"_index" : "hotel","_type" : "_doc","_id" : "006","_score" : 1.0,"_source" : {"title" : "京盛集团精选酒店","city" : "上海","price" : "500.00","create_time" : "2022-01-29 22:50:00","full_room" : true,"location" : {"lat" : 40.918229,"lon" : 118.422011},"praise" : 20}}]}
}
通过结果可以看到,使用Constant Score搜索时,命中的酒店文档对应的city字段都包含“上海”一词。但是不论该词在文档中出现多少次,这些文档的得分都是一样的1.0.
PS:很多人可能会把constant_score查询中的filter和布尔查询的filter搞混,constant_score中的filter可以把它想象成普通的query,它后面接的就是各种各样的查询子句。如term,terms,exists,bool等等。
比如我想同时使用must查询创建时间大于等于2022-01-29 22:50:00的hotel且不在乎打分,那么可以使用下面的DSL:
POST /hotel/_search
{"query": {"constant_score": {"filter": {"bool": {"must": [{"range": {"create_time": {"gte": "2022-01-29 22:50:00"}}}]}}}}
}
在Constant Score搜索中,参数boost可以控制命中文档的得分,默认值都是1.0,以下为更改boost参数为2.0的例子:
POST /hotel/_search
{"query": {"constant_score": {"boost":2.0,"filter": {"term": {"city": "上海"}}}}
}
查询结果如下:
{..."hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 2.0,"hits" : [{"_index" : "hotel","_type" : "_doc","_id" : "004","_score" : 2.0,"_source" : {"title" : "京盛集团酒店","city" : "上海","price" : "800.00","create_time" : "2021-05-29 21:35:00","amenities" : "浴池(假日需预订),室内游泳池,普通停车场/充电停车场","full_room" : true,"location" : {"lat" : 36.940243,"lon" : 120.394},"praise" : 100}},{"_index" : "hotel","_type" : "_doc","_id" : "006","_score" : 2.0,"_source" : {"title" : "京盛集团精选酒店","city" : "上海","price" : "500.00","create_time" : "2022-01-29 22:50:00","full_room" : true,"location" : {"lat" : 40.918229,"lon" : 118.422011},"praise" : 20}}]}
}根据搜索结果可以看到,设定Boost值为2.0后,所有的命中的文档得分都为2.0。
然后对于Constant Score的效率问题,我们拿它和上一节讲到的filter查询做一个对比:
- Constant Score查询实际上就是一个没有分值函数的查询,它会将所有匹配文档的分值设置为一个常量。这种查询不需要计算每个匹配文档的相关度,所以效率会比普通查询高。
- 但是Constant Score查询还需要执行查询本身,比如匹配查询条件、过滤文档等步骤。而filter查询仅仅过滤文档,不计算分值,所以整体效率比Constant Score查询更高。
- Constant Score查询不会像filter查询那样缓存过滤结果。因为Constant Score查询还需要计算每个匹配文档的分值,而这一步不受过滤结果缓存的影响。
- 所以总的来说,在效率方面: filter查询 > Constant Score查询 > 普通查询
在java客户端上构建Constant Score搜索时,可以使用ConstantScoreQueryBuilder类的实例进行构建,它接收一个QueryBuilder参数,即可以接收termQueryBuilder,termsQueryBuilder,boolQueryBuilder等等,和之前的DSL是一样的,那么比如我们查询一个城市是上海或者北京的酒店,代码如下:
Service层,getQueryResult()可以看往期的博客,有具体的方法实现:
public List<Hotel> constantScore(HotelDocRequest hotelDocRequest) throws IOException {//新建搜索请求String indexName = getNotNullIndexName(hotelDocRequest);SearchRequest searchRequest = new SearchRequest(indexName);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();TermQueryBuilder termQueryBuilder1 = QueryBuilders.termQuery("city", "北京");TermQueryBuilder termQueryBuilder2 = QueryBuilders.termQuery("city", "上海");BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();boolQueryBuilder.should(termQueryBuilder1).should(termQueryBuilder2);//构建ConstantScoreBuilderConstantScoreQueryBuilder constantScoreQueryBuilder = new ConstantScoreQueryBuilder(boolQueryBuilder);//设置固定分数2.0constantScoreQueryBuilder.boost(2.0f);searchSourceBuilder.query(constantScoreQueryBuilder);searchRequest.source(searchSourceBuilder);return getQueryResult(searchRequest);}
Controller层:
@PostMapping("/query/constant_score")public FoundationResponse<List<Hotel>> constantScoreQuery(@RequestBody HotelDocRequest hotelDocRequest) {try {List<Hotel> hotelList = esQueryService.constantScore(hotelDocRequest);if (CollUtil.isNotEmpty(hotelList)) {return FoundationResponse.success(hotelList);} else {return FoundationResponse.error(100,"no data");}} catch (IOException e) {log.warn("搜索发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());} catch (Exception e) {log.error("服务发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());}}
Postman实现:
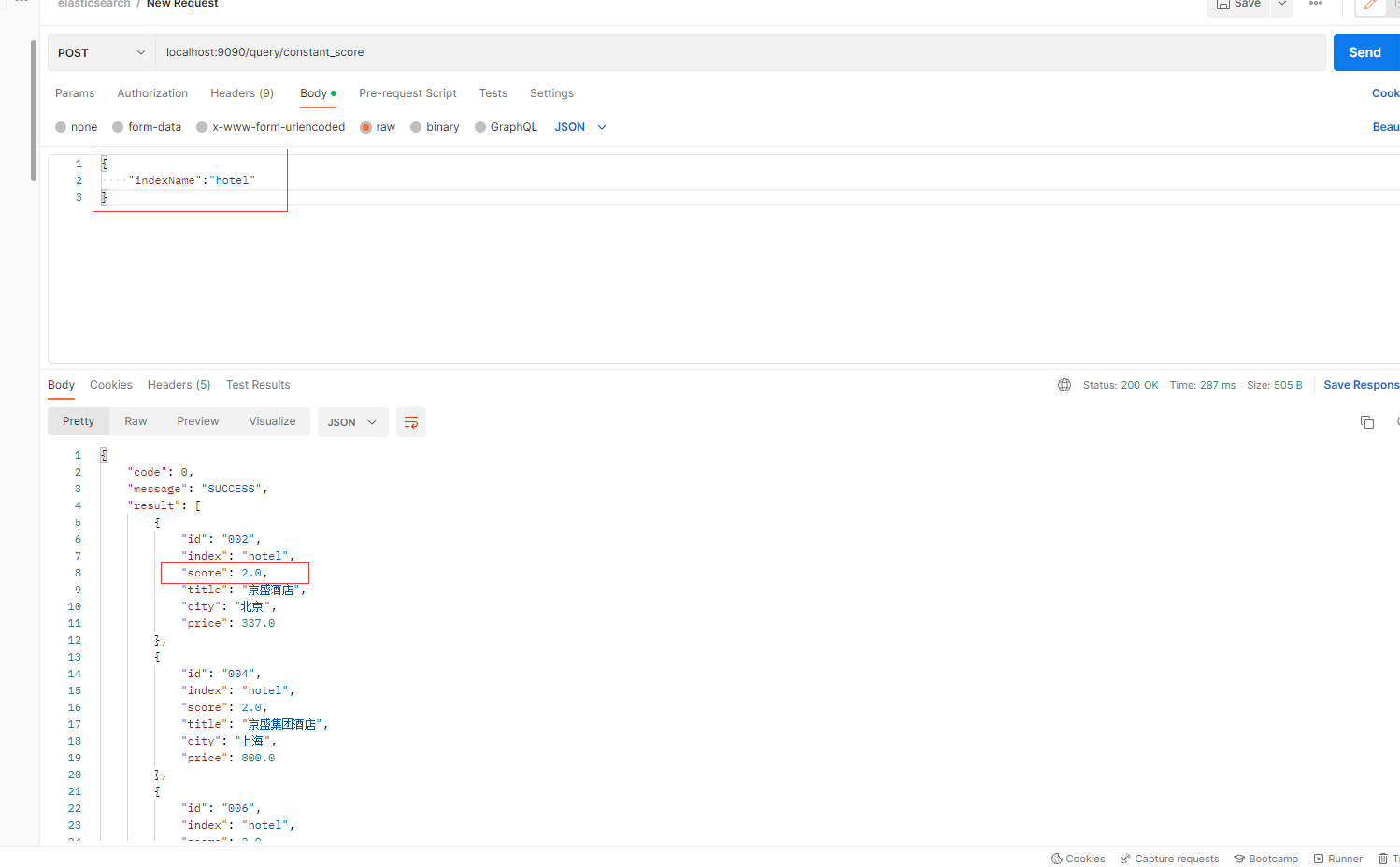
三、Function Score查询
当你使用ES进行搜索时,命中的文档默认按照相关度进行排序,有些场景下用户需要干预该“相关度”,此时就可以使用Function Score查询。使用时,用户必须定义一个查询以及一个或多个函数,这些函数为每一个文档计算一个新分数。
它允许每个主查询query匹配的文档应用加强函数,以达到改变原始查询评分_score的目的。
3.1、function_score 查询模板
function_score 查询模板可以分为两类,分别为单个加强函数的查询和多个加强函数的查询。
单个加强函数的查询模板:
{"query": {"function_score": {"query": {.....}, // 主查询,查询完后会有一个 _score 评分"field_value_factor": {...}, // 在 _score 的基础上进行强化评分"boost_mode": "multiply", // 指定用哪种方式结合 _score 和 强化 score"max_boost": 1.5 // 限制强化 score 的最高分,但是不会限制 _score}}
}
多个加强函数的查询模板:
{"query": {"function_score": {"query": {.....},"functions": [ // 可以有多个加强函数(或是 filter+加强函数),每一个加强函数会产生一个加强 score{ "field_value_factor": ... },{ "gauss": ... },{ "filter": {...}, "weight": ... }],"score_mode": "sum", // 决定加强 score 们如何整合"boost_mode": "multiply" // 决定最后的 functions 中 score 和 query score 的结合方式}}
}
3.2、function_score 参数
强化 _score 计算的函数
function_score 提供了几种内置加强 _score 计算的函数功能:
weight:设置一个简单而不被规范化的权重提升值。
weight 加强函数和 boost 参数比较类似,可以用于任何查询,不过有一点差别是 weight 不会被 Lucene 规范化(normalize)成难以理解的浮点数,而是直接被应用。
例如,当 weight 为 2 时,最终得分为 new_score = 2 * _score。
POST /hotel/_search
{"query": {"function_score": {"query": {"term": {"city": {"value": "上海"}}},"weight":2}}
}
输出后可以对比一下不加weight的默认分数,基本分数都翻了2倍
field_value_factor:指定文档中某个字段的值结合 _score 改变分数
属性如下:
field:指定字段名
factor:对字段值进行预处理,乘以(或者加,取决于boost_mode)指定的数值(默认为1)
modifier:将字段值进行加工,有以下的几个选项:
none:不处理log:计算对数log1p:先将字段值+1,再计算对数log2p:先将字段值+2,再计算对数ln:计算自然对数ln1p:先将字段值+1,再计算自然对数ln2p:先将字段值+2,再计算自然对数square:计算平方sqrt:计算平方根reciprocal:计算倒数
{"query": {"function_score": {"query": {.....},"field_value_factor": {"field": "price","modifier": "none","factor": 1.2},"boost_mode": "multiply", "max_boost": 1.5}}
}
调整后的 function 分数公式为,factor * doc['price'].value;如果boos_mode设定为sum,那么分数公式为factor + doc['price'].value;
例如我们让最终的分数以price字段进行增强,在原分数基础上*1.2
POST /hotel/_search
{"query": {"function_score": {"query": {"term": {"city": {"value": "上海"}}},"field_value_factor": {"field":"price","factor": 1.2},"boost_mode": "multiply"}}
}
再例如我想对字段值先乘1.2再+1再取对数,那么DSL如下:
POST /hotel/_search
{"query": {"function_score": {"query": {"term": {"city": {"value": "上海"}}},"field_value_factor": {"field":"price","modifier": "ln1p","missing":1.0,"factor": 1.2},"boost_mode": "multiply"}}
}
function 分数为,ln1p(1.2 * doc['view_cnt'].value),如果指定字段缺失用 missing 对应的值,至于和匹配的相关性分数 _score 如何结合需要下面的 boost_mode 参数来决定。
random_score:使用一致性随机分值计算来对每个用户采用不同的结果排序方式,对相同用户仍然使用相同的排序方式,其本质上用的是seed 种子参数,用户相关的 id 与 seed 构造映射关系,就可千人千面的效果,seed 不同排序结果也不同。具体示例如下:
①字段值相同,例如通过full_room,由上面查询结果可知,两个结果的full_room相同,此时使用random_score,两个的排序结果仍然是一致的:
POST /hotel/_search
{"query": {"function_score": {"query": {"term": {"city": {"value": "上海"}}},"random_score": {"field":"full_room","seed": 10},"boost_mode": "multiply"}}
}
如果对price进行随机加强,那么排序就会不一样:
POST /hotel/_search
{"query": {"function_score": {"query": {"term": {"city": {"value": "上海"}}},"random_score": {"field":"price","seed": 10},"boost_mode": "multiply"}}
}

我们可以调整seed,就会发现排序不一样。
衰减函数(decay function):es 内置了三种衰减函数,分别是 linear、exp 和 gauss;
三种衰减函数的差别只在于衰减曲线的形状,在 DSL 的语法上的用法完全一样;
linear : 线性函数是条直线,一旦直线与横轴0香蕉,所有其他值的评分都是0
exp : 指数函数是先剧烈衰减然后变缓
guass(最常用) : 高斯函数则是钟形的,他的衰减速率是先缓慢,然后变快,最后又放缓
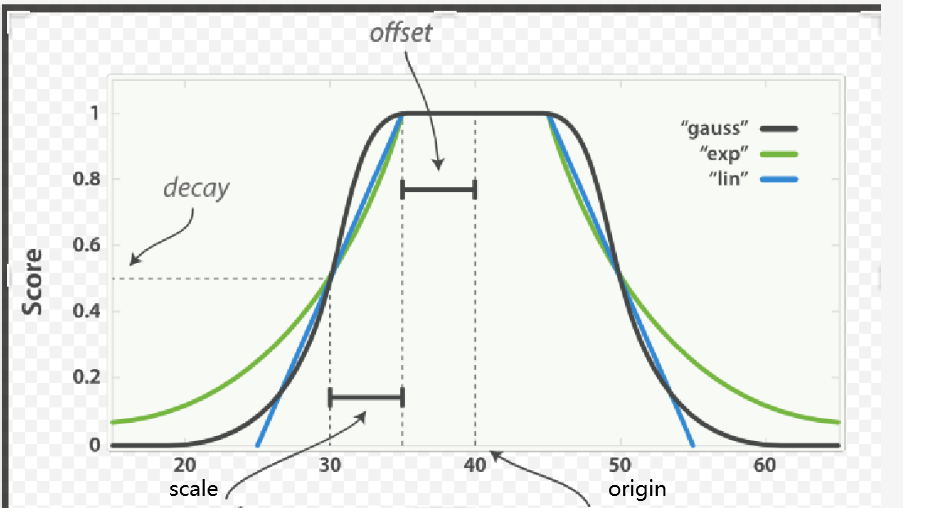
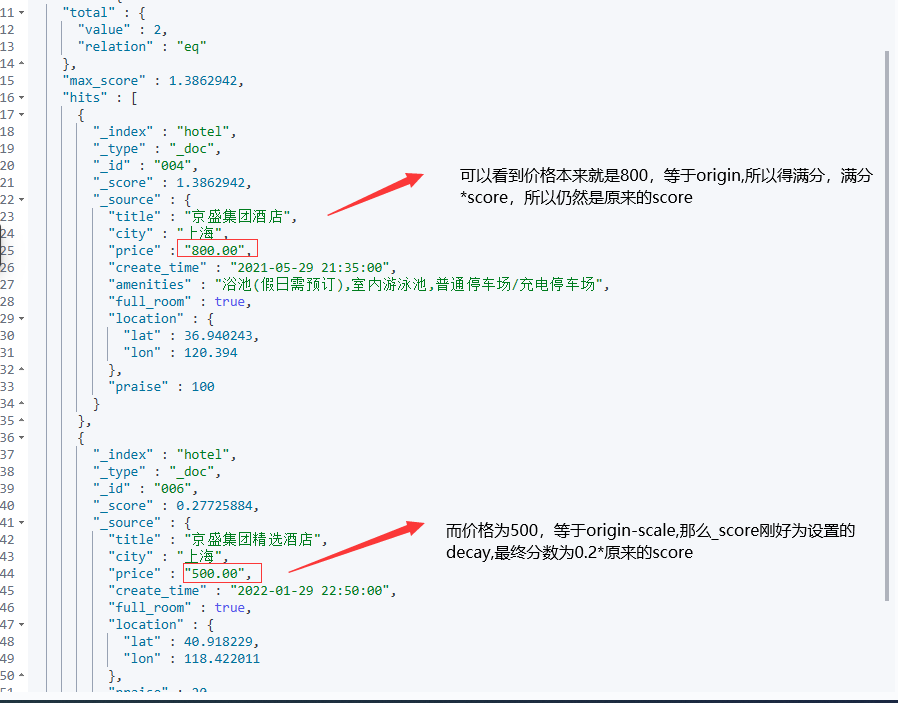
origin:中心点 或字段可能的最佳值,落在原点 origin 上的文档评分 _score 为满分 1.0 。
scale:衰减率,即一个文档从原点 origin 下落时,评分 _score 改变的速度。(例如,每 £10 欧元或每 100 米)。
decay:从原点 origin 衰减到 scale 所得的评分 _score ,默认值为 0.5 。
offset:以原点 origin 为中心点,为其设置一个非零的偏移量 offset 覆盖一个范围,而不只是单个原点。在范围 -offset <= origin <= +offset 内的所有评分 _score 都是 1.0 。不设置默认是0
POST /hotel/_search
{"query": {"function_score": {"query": {"term": {"city": {"value": "上海"}}},"gauss": {"price": {// 如果不设置offset,offset默认为0 公式 : origin-offset <= value <= origin+offset// 范围在800-0 <= value <= 800+0的文档的评分_score都是满分1.0//而在此范围之外,评分会开始衰减,衰减率由scale值(此处是300)和decay值(此处是0.2)决定// 也就是说,在origin + offset + scale或是origin - offset - scale的点上,得到的分数仅有decay分"origin": "800","scale": "300","decay": 0.2}}, "boost_mode": "multiply"}}
}
对衰减函数感兴趣的小伙伴可以浏览这篇文章,讲的很详细,尤其是最后对于用户同时对于酒店的地理位置和价格去做一个筛选。
script_score:当需求超出以上范围时,可以用自定义脚本完全控制评分计算。
3.3、其它辅助函数
boost_mode参数:决定 query 中的相关性分数和加强的函数分数的结合方式。
multiply:默认的配置,两者分数相乘,new_score = _score * boost_score;
sum:两者相加,new_score = _score + boost_score;
min:取两者最小值,new_score = min(_score, boost_score);
max:取两者最大值,new_score = max(_score, boost_score);
replace:用 boost_score 替换 _score 值。有时候我们可以通过replace看具体的函数得分是多少,便于我们排查问题
score_mode参数决定 functions 里面的强化 score 如何结合
function_score 先会执行 score_mode 的设置,即先整合所有的强化计算,再执行 boost_mode 的配置,就是将 query 相关性分数和整合强化分数的结合。
multiply:默认的配置,多个强化分数相乘;
sum:多个强化分数相加;
min:取多个强化分数最小值;
max:取多个强化分数最大值;
avg:取多个强化分数平均值;
first:使用首个函数的结果作为最终结果。
max_boost:限制加强函数的最大效果,就是限制加强 score 最大能多少,但要注意不会限制 old_score。
如果加强 score 超过了 max_boost 限制的值,会把加强 score 的值设成 max_boost 的值;
假设加强 score 是5,而 max_boost 是2,因为加强 score 超出了 max_boost 的限制,所以 max_boost 就会把加强 score 改为2。简单的说,就是 final_score = min(整合后的 score, max_boost)。
3.4、java实现
funtion_score的参数我们可以通过ScoreFunctionBuilders.xxx构筑
Service层实现:
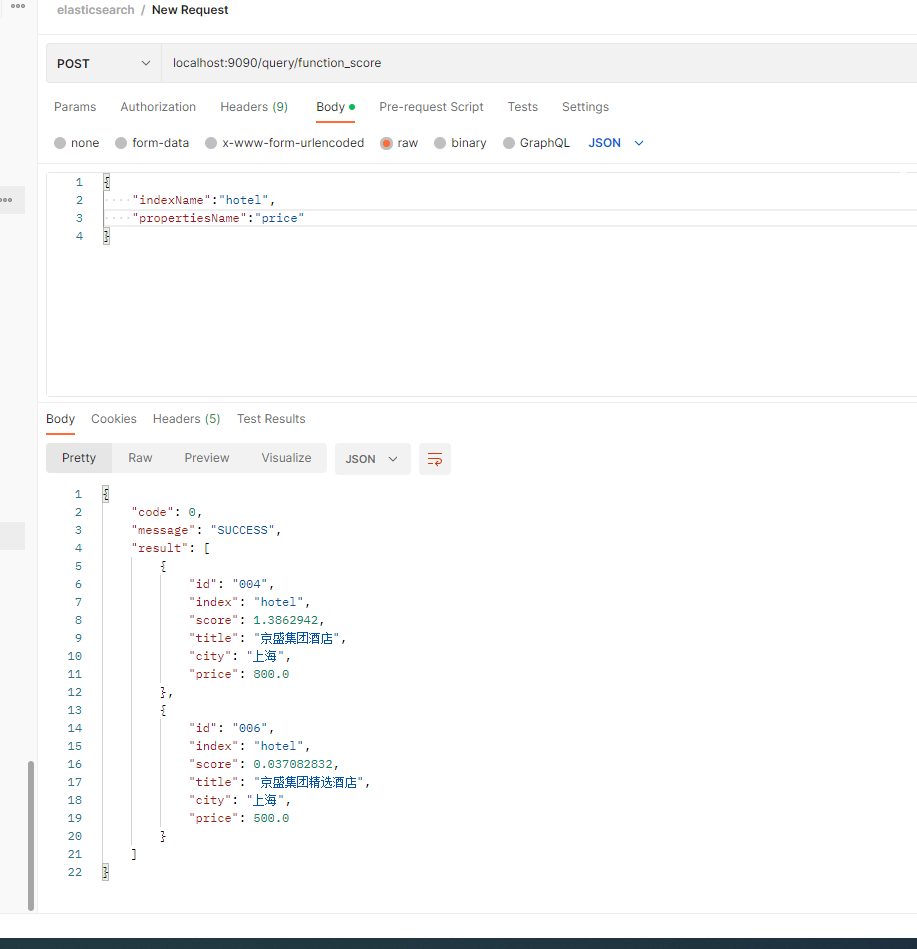
public List<Hotel> functionScoreScore(HotelDocRequest hotelDocRequest) throws IOException {//新建搜索请求String indexName = getNotNullIndexName(hotelDocRequest);SearchRequest searchRequest = new SearchRequest(indexName);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("city", "上海");//构建FunctionScoreBuilder,比如这里构筑高斯函数(衰减函数)GaussDecayFunctionBuilder gaussDecayFunctionBuilder = ScoreFunctionBuilders.gaussDecayFunction(hotelDocRequest.getPropertiesName(), 800, 200, 0, 0.2);//构建Function Score查询FunctionScoreQueryBuilder functionScoreQueryBuilder = new FunctionScoreQueryBuilder(termQueryBuilder, gaussDecayFunctionBuilder).boostMode(CombineFunction.MULTIPLY);searchSourceBuilder.query(functionScoreQueryBuilder);searchRequest.source(searchSourceBuilder);return getQueryResult(searchRequest);}
controller层实现:
@PostMapping("/query/function_score")public FoundationResponse<List<Hotel>> functionScoreQuery(@RequestBody HotelDocRequest hotelDocRequest) {try {List<Hotel> hotelList = esQueryService.functionScoreScore(hotelDocRequest);if (CollUtil.isNotEmpty(hotelList)) {return FoundationResponse.success(hotelList);} else {return FoundationResponse.error(100,"no data");}} catch (IOException e) {log.warn("搜索发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());} catch (Exception e) {log.error("服务发生异常,原因为:{}", e.getMessage());return FoundationResponse.error(100, e.getMessage());}}
postman实现截图:
相关文章:
Elasticsearch(十三)搜索---搜索匹配功能④--Constant Score查询、Function Score查询
一、前言 之前我们学习了布尔查询,知道了filter查询只在乎查询条件和文档的匹配程度,但不会根据匹配程度对文档进行打分,而对于must、should这两个布尔查询会对文档进行打分,那如果我想在查询的时候同时不去在乎文档的打分&#…...

直播系统源码协议探索篇(二):网络套接字协议WebSocket
上一篇我们分析了直播平台的会话初始化协议SIP,他关乎着直播平台的实时通信和多方互动技术的实现,今天我们来讲另一个协议,叫网络套接字协议WebSocket,WebSocket基于TCP在客户端与服务器建立双向通信的网络协议,并且可…...
Windows 11 下使用 VMWare Workstation 17 Pro 新建 CentOS Stream 9 64位 虚拟机 并配置网络
文章目录 为什么选择 CentOS Stream 9下载安装访问连接快照克隆网络配置 为什么选择 CentOS Stream 9 CentOS Linux 8: 已经过了 End-of-life (EOL)CentOS Linux 7: EOL Jun 30th, 2024CentOS Stream 8: EOL May 31st, 2024CentOS Stream 9: End of RHEL9 full support phase …...
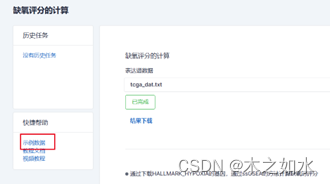
生信豆芽菜-缺氧评分的计算
网址:http://www.sxdyc.com/gradeHypoxia 1、数据准备 表达谱数据,行为基因,列为样本 2、提交后,等待运行成功即可下载 当然,如果不清楚数据是什么样的,可以选择下载我们的示例数据,也可以…...

C++:通过find/substr分割字符串
find函数可以在一个目标字符串中查找子字符串,返回值为子字符串在目标字符串中的起始位置 substr通过起始位置和长度可以截取一段字符串 将find和substr结合可以用于分割字符串 #include <iostream> #include <string> #include <tuple>using …...
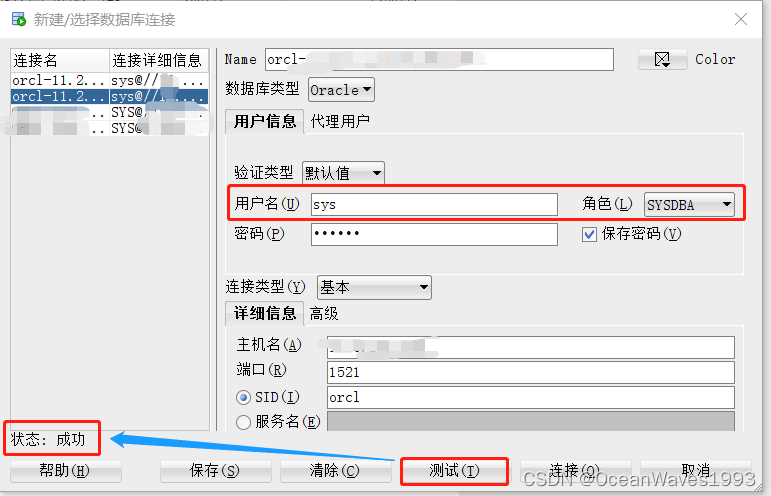
sql developer 连不上oracle数据库 报错 ORA-01031: insufficient privileges
sql developer 连不上oracle数据库 报错 ORA-01031: insufficient privileges 1、问题描述2、问题原因3、解决方法4、sql developer 连接oracle 成功 1、问题描述 使用sys账户以SYSDBA角色登录失败 报错 ORA-01031: insufficient privileges 2、问题原因 因为没有给sys账户分…...

LeetCode 面试题 01.07. 旋转矩阵
文章目录 一、题目二、C# 题解 一、题目 给你一幅由 N N 矩阵表示的图像,其中每个像素的大小为 4 字节。请你设计一种算法,将图像旋转 90 度。 不占用额外内存空间能否做到? 点击此处跳转题目。 示例 1: 给定 matrix [ [1,2,3], [4,5,6], …...
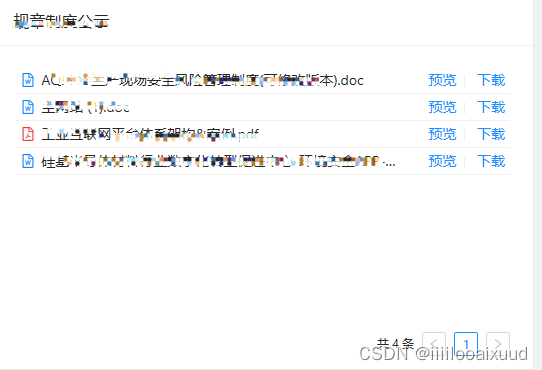
vue3 pdf、word等文件下载
效果: <div class"byLawBox"><div class"titleBox">规章制度公示</div><div class"contentBox"><TableList:loading"byLawloading"ref"byLawtablistRef":hasImport"false"…...
带你了解SpringBoot---开启Durid 监控
文章目录 数据库操作--开启Durid 监控整合Druid 到Spring-Boot官方文档基本介绍Durid 基本使用代码实现 Durid 监控功能-SQL 监控需求:SQL 监控数据SQL 监控数据-测试页面 Durid 监控功能-Web 关联监控需求:Web 关联监控配置-Web 应用、URI 监控重启项目 Durid 监控功能-SQL 防…...

matlab 点云精配准(3)——Trimmed ICP
目录 一、算法原理1、原理概述2、参考文献二、代码实现三、结果展示四、参考链接本文由CSDN点云侠原创,matlab 点云精配准(3)——Trimmed ICP。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫。 一、算法原理 1、原理概述 见论文:[1] 李鑫,莫思特,黄华,…...

nodejs开发环境搭建示例
服务与后端 {"name": "AsaiCC","private": true,"version": "1.0.0","description": "","main": "main.js","bin": "index.js","author": "&…...
网络安全(大厂)面试题
以下为网络安全各个方向涉及的面试题,星数越多代表问题出现的几率越大,祝各位都能找到满意的工作。 注:本套面试题,已整理成pdf文档,但内容还在持续更新中,因为无论如何都不可能覆盖所有的面试问题…...
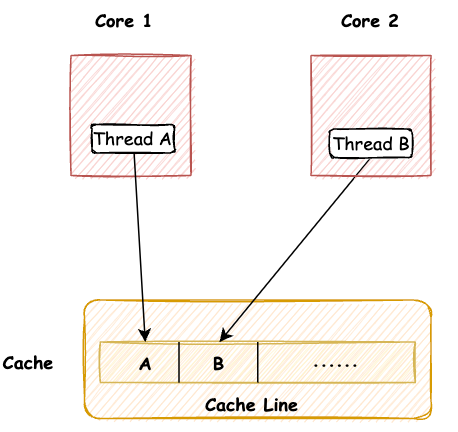
GC面临的困境,JVM是如何解决跨代引用的?
本文已收录至GitHub,推荐阅读 👉 Java随想录 微信公众号:Java随想录 原创不易,注重版权。转载请注明原作者和原文链接 文章目录 跨代引用问题记忆集卡表写屏障写屏障的伪共享问题 前面我们讲了可达性分析和根节点枚举,…...
Qt下拉菜单
1,QComboBox 2,setMenu()---设置下拉菜单 AI对话未来丨智能写作对话: setMenu()是QWidget类的一个成员函数,在Qt中用于将一个菜单作为一个控件的下拉菜单设置。具体来说,它会把相应的菜单对象与该控件关联,并在控件上…...

考研C语言进阶题库——更新41-50题
目录 41.编写程序要求输出整数a和b若a和b的平方和大于100,则输出a和b的平方和,否则输出a和b的和 42.现代数学的著名证明之一是Georg Cantor证明了有理数是可枚举的。他是用下面这一张表来证明这一命题的:第一项是1/1,第二项是是…...
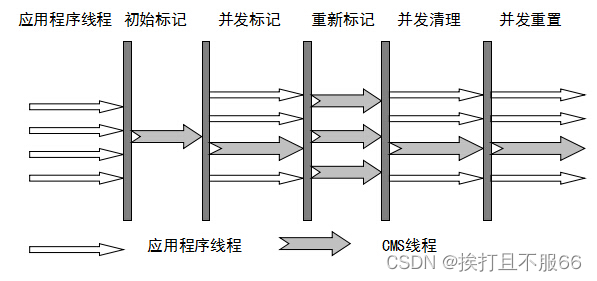
JVM——JVM 垃圾回收
文章目录 写在前面本节常见面试题本文导火索 1 揭开 JVM 内存分配与回收的神秘面纱1.1 对象优先在 eden 区分配1.2 大对象直接进入老年代1.3 长期存活的对象将进入老年代1.4 动态对象年龄判定1.5 主要进行 gc 的区域 2 对象已经死亡?2.1 引用计数法2.2 可达性分析算…...
浅析阿里云灵积(平台)模型服务
简介: DashScope灵积模型服务以模型为中心,致力于面向AI应用开发者提供品类丰富、数量众多的模型选择,并为其提供开箱即用、能力卓越、成本经济的模型服务API。DashScope灵积模型服务依托达摩院等机构的优质模型,在阿里云基础设施…...

使用 PyTorch 进行高效图像分割:第 1 部分
一、说明 在这个由 4 部分组成的系列中,我们将使用 PyTorch 中的深度学习技术从头开始逐步实现图像分割。我们将在本文中从图像分割所需的基本概念和想法开始本系列。 图1:宠物图像及其分割掩码(来源:牛津-IIIT宠物数据集) 图像分…...
vellum (Discovering Houdini VellumⅡ柔体系统)学习笔记
视频地址: https://www.bilibili.com/video/BV1ve411u7nE?p3&spm_id_frompageDriver&vd_source044ee2998086c02fedb124921a28c963(搬运) 个人笔记如有错误欢迎指正;希望可以节省你的学习时间 ~享受艺术 干杯🍻…...
最优的家电设备交互方式是什么?详解家电设备交互的演进之旅
家电,在人们的日常生活中扮演着不可或缺的角色,也是提升人们幸福感的重要组成部分,那你了解家电的发展史吗? 70年代 结婚流行“四大件”:手表、自行车、缝纫机,收音机,合成“三转一响”。 80年…...

Windows11回归Windows10操作习惯:控制台与第三方工具双方案解析
1. Windows11操作习惯调整的必要性 很多从Windows10升级到Windows11的用户都会遇到一个共同问题:新系统的操作习惯与旧版差异太大。最典型的例子就是右键菜单的改变——在Windows11中,微软将原本完整的右键菜单简化成了"显示更多选项"的二级菜…...

GTE文本向量镜像5分钟快速部署:一键启动中文NLP多任务Web应用
GTE文本向量镜像5分钟快速部署:一键启动中文NLP多任务Web应用 1. 项目简介 GTE文本向量-中文-通用领域-large应用是一个基于ModelScope平台的多功能中文文本处理解决方案。这个镜像将强大的自然语言处理能力封装成简单易用的Web服务,特别适合需要快速集…...

开发者专属:OpenClaw+Qwen3-32B实现日志分析自动化
开发者专属:OpenClawQwen3-32B实现日志分析自动化 1. 为什么开发者需要日志分析自动化? 凌晨三点,手机突然响起刺耳的警报声——这是上周我负责的线上服务又一次因为日志爆仓触发告警。强撑着睡眼登录服务器,面对GB级别的日志文…...

OFA-33M蒸馏模型轻量化效果展示:边缘设备部署实测
OFA-33M蒸馏模型轻量化效果展示:边缘设备部署实测 最近在折腾边缘设备上的AI应用,发现一个挺有意思的问题:那些效果好的大模型,动不动就几百上千亿参数,在服务器上跑起来都费劲,更别说塞进一个小盒子里了。…...

3步完成OpenClaw初始化:ollama-QwQ-32B云端体验极速版
3步完成OpenClaw初始化:ollama-QwQ-32B云端体验极速版 1. 为什么选择云端体验OpenClaw 作为一个长期折腾本地AI部署的技术爱好者,我深知在个人电脑上配置OpenClaw的痛点。从Python环境冲突到CUDA版本不匹配,再到模型权重下载超时࿰…...

3步构建专业级虚拟海洋测试环境:ASV波浪模拟器实战指南
3步构建专业级虚拟海洋测试环境:ASV波浪模拟器实战指南 【免费下载链接】asv_wave_sim This package contains plugins that support the simulation of waves and surface vessels in Gazebo. 项目地址: https://gitcode.com/gh_mirrors/as/asv_wave_sim 定…...

内容审核不求人:Qwen3Guard-Gen-8B快速部署与调用教程
内容审核不求人:Qwen3Guard-Gen-8B快速部署与调用教程 1. 为什么需要专业的内容审核模型? 在当今互联网环境中,用户生成内容(UGC)和AI生成内容(AIGC)呈爆炸式增长。无论是社交媒体、电商平台还是在线社区,每天都有海量内容需要审…...

AIGlasses_for_navigation中小企业适用:低成本GPU部署无障碍视觉系统
AIGlasses_for_navigation中小企业适用:低成本GPU部署无障碍视觉系统 让AI视觉技术不再高不可攀,用普通GPU也能搭建专业级目标分割系统 1. 项目背景与价值 想象一下,一家中小型科技公司想要开发智能导航产品,但面对动辄数十万的A…...

feed二级缓存设计day05
背景:feed流:投喂流,主动把消息发给我们,类似于朋友圈别人的消息组成了我的主页feed流与内容详情是该社区访问最多的接口,面临着以下挑战:- **高并发读压力**:首页 Feed 与热门内容详情同一时刻…...

Instruct-4DGS: Efficient Dynamic Scene Editing via 4D Gaussian-based Static-Dynamic Separation
4D高斯静态和动态分离实现高效的动态场景编辑一、核心摘要与研究动机核心问题:现有的4D动态场景编辑方法受限于 迭代数据集更新 的范式。如图1(a)所示,它们需要逐帧编辑用于场景合成的成千上万张2D图像(T个时间步 M个相机视角)&a…...