使用 PyTorch 进行高效图像分割:第 4 部分
一、说明
在这个由 4 部分组成的系列中,我们将使用 PyTorch 中的深度学习技术从头开始逐步实现图像分割。本部分将重点介绍如何实现基于视觉转换器的图像分割模型。

图 1:使用视觉转换器模型架构运行图像分割的结果。
从上到下,输入图像、地面实况分割掩码和预测分割掩码。来源:作者
二、文章大纲
在本文中,我们将参观风靡深度学习世界的变压器架构。变压器是一种多模态架构,可以对语言、视觉和音频等不同模态进行建模。
在本文中,我们将
- 了解变压器架构和所涉及的关键概念
- 了解视觉变压器架构
- 介绍从头开始编写的视觉转换器模型,以便您可以欣赏所有构建块和移动部件
- 跟踪输入到该模型的输入张量,并检查它如何改变形状
- 使用此模型对牛津 IIIT 宠物数据集执行图像分割
- 观察此分割任务的结果
- 简要介绍SegFormer,一种用于语义分割的最先进的视觉转换器
在本文中,我们将引用此笔记本中的代码和结果进行模型训练。如果要重现结果,则需要一个 GPU 来确保第一个笔记本在合理的时间内完成运行。
三、本系列文章
本系列面向所有深度学习经验水平的读者。如果您想了解深度学习和视觉AI的实践以及一些扎实的理论和实践经验,那么您来对地方了!这将是一个由 4 部分组成的系列,包含以下文章:
- 概念和想法
- 基于 CNN 的模型
- 深度可分离卷积
- 基于视觉变压器的模型(本文)
让我们从对变压器架构的介绍和直观理解开始我们的视觉变压器之旅。
四、变压器架构
我们可以将变压器架构视为交错的通信和计算层的组合。图 2 直观地描述了这一想法。变压器有N个处理单元(图3中的N为2),每个单元负责处理输入的1/N部分。为了使这些处理单元产生有意义的结果,每个处理单元都需要具有输入的全局视图。因此,系统将有关每个处理单元中的数据的信息重复传达给每个其他处理单元;使用从每个处理单元到每个其他处理单元的红色、绿色和蓝色箭头进行显示。接下来是基于此信息进行的一些计算。在充分重复此过程后,模型能够产生预期的结果。
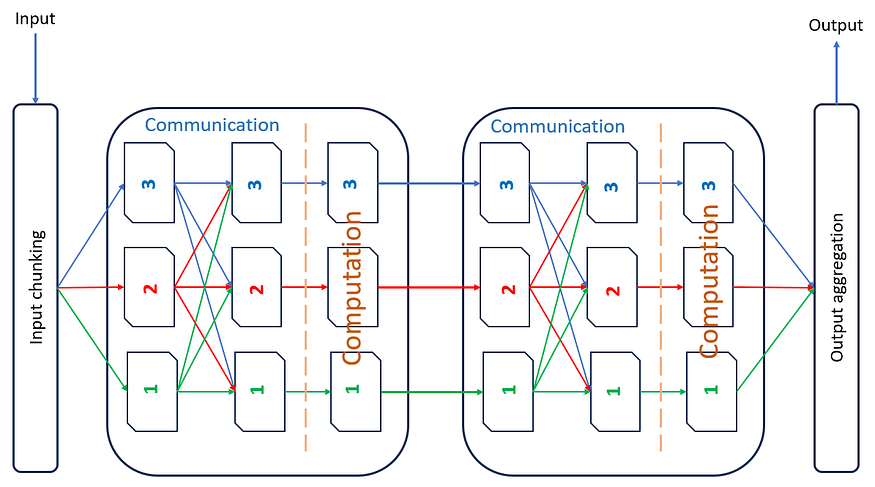
图 2:变压器中的交错通信和计算。该图像仅显示了 2 层通信和计算。
值得注意的是,大多数在线资源通常会讨论变压器的编码器和解码器,如题为“注意力是你所需要的”的论文中所述。但是,在本文中,我们将仅描述变压器的编码器部分。
让我们仔细看看变压器中的通信和计算构成。
4.1 变压器中的通信:注意
在变压器中,通信由称为注意力层的层实现。在 PyTorch 中,这被称为 MultiHeadAttention。我们稍后会谈到这个名字的原因。
文档说:
“允许模型共同关注来自不同表示子空间的信息,如论文中所述:注意力就是你所需要的。
注意力机制使用形状(批处理、长度、特征)的输入张量 x,并生成形状相似的张量 y,以便根据张量在同一实例中关注的其他输入更新每个输入的特征。因此,在大小为“长度”的实例中,长度为“特征”的每个张量的特征会根据其他每个张量进行更新。这就是注意力机制的二次成本的用武之地。
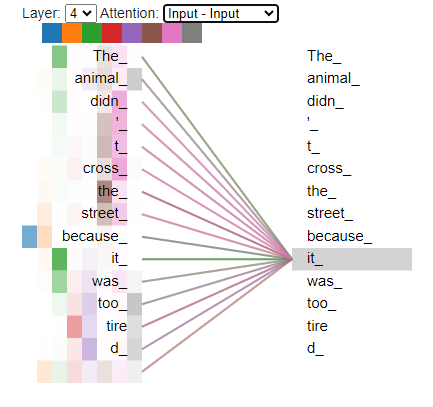
图3:相对于句子中其他单词显示的单词“it”的注意。我们可以看到,“它”是在同一句话中注意“动物”、“太”和“tire(d)”等词。
在视觉变压器的上下文中,变压器的输入是图像。假设这是一个 128 x 128(宽度、高度)的图像。我们将其分成多个较小的大小块(16 x 16)。对于 128 x 128 的图像,我们得到 64 个补丁(长度),每行 8 个补丁和 8 行补丁。
这 64 个大小为 16 x 16 像素的块中的每一个都被视为变压器模型的单独输入。在不深入细节的情况下,将此过程视为由 64 个不同的处理单元驱动就足够了,每个处理单元都在处理单个 16x16 图像补丁。
在每一轮中,每个处理单元中的注意力机制负责查看它负责的图像补丁,并查询其余 63 个处理单元中的每一个,以询问它们可能相关和有用的任何信息,以帮助它有效地处理自己的图像补丁。
通过注意力的沟通步骤之后是计算,我们接下来将研究。
4.2 变压器中的计算:多层感知器
变压器中的计算只不过是一个多层感知器(MLP)单元。该单元由 2 个线性层组成,介于两者之间具有 GeLU 非线性。也可以考虑使用其他非线性。该单元首先将输入投影到大小的 4 倍,然后将其重新投影回 1 倍,这与输入大小相同。
在我们将在笔记本中看到的代码中,此类称为多层感知器。代码如下所示。
class MultiLayerPerceptron(nn.Sequential):def __init__(self, embed_size, dropout):super().__init__(nn.Linear(embed_size, embed_size * 4),nn.GELU(),nn.Linear(embed_size * 4, embed_size),nn.Dropout(p=dropout),)# end def
# end class现在我们了解了变压器架构的高级工作原理,让我们把注意力集中在视觉转换器上,因为我们将执行图像分割。
五、视觉转换器
视觉转换器最初是由题为“图像价值16x16字:大规模图像识别的变压器”的论文介绍的。本文讨论了作者如何将原版变压器架构应用于图像分类问题。这是通过将图像拆分为大小为 16x16 的补丁,并将每个补丁视为模型的输入令牌来完成的。转换器编码器模型被馈送这些输入令牌,并被要求预测输入图像的类。
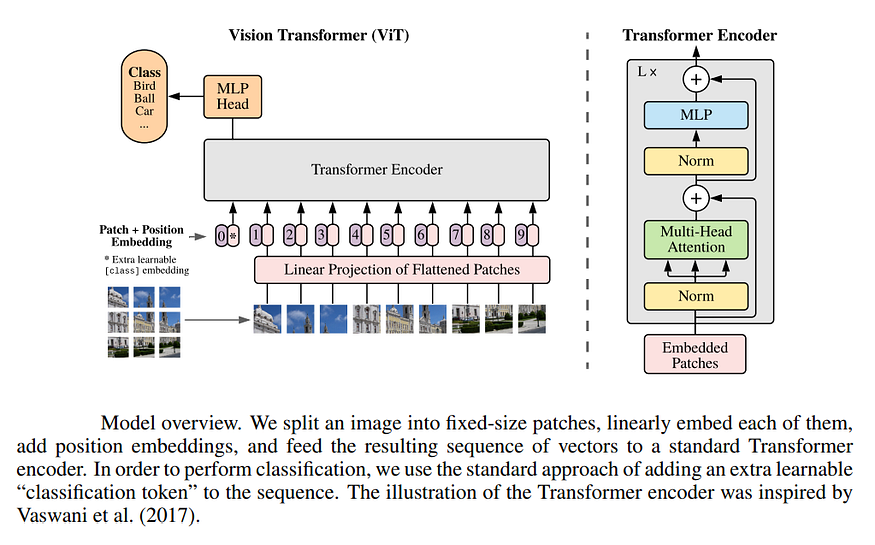
图 4:来源:用于大规模图像识别的变压器。
在我们的例子中,我们对图像分割感兴趣。我们可以将其视为像素级分类任务,因为我们打算预测每个像素的目标类。
我们对原版视觉转换器进行了一个小但重要的更改,并更换了MLP头,以便由MLP头进行像素级分类。我们在输出中有一个线性层,由每个补丁共享,其分割掩模由视觉变压器预测。此共享线性层预测作为模型输入发送的每个补丁的分割掩码。
在视觉转换器的情况下,大小为 16x16 的补丁被视为等效于特定时间步长的单个输入令牌。
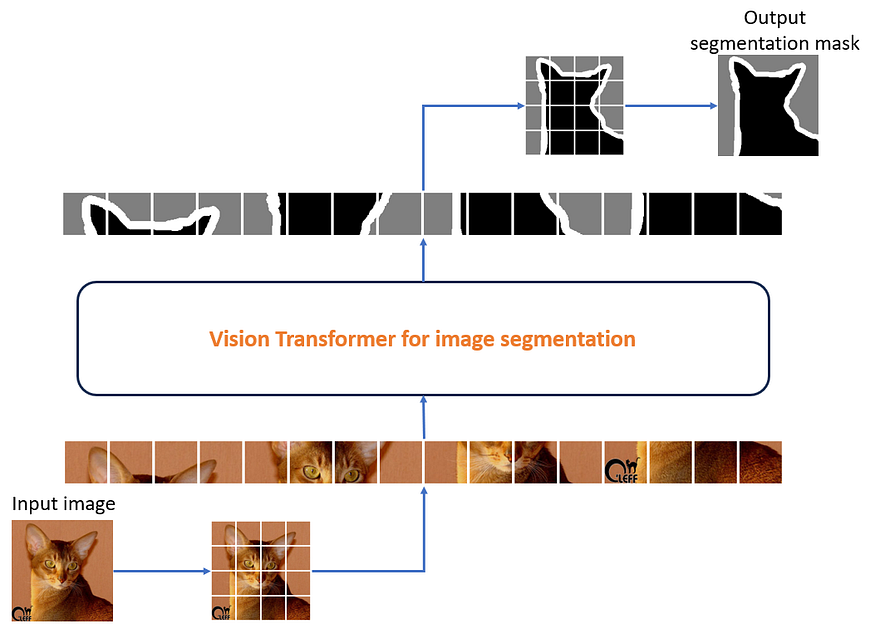
图 5:用于图像分割的视觉转换器的端到端工作。使用此笔记本生成的图像。
5.1 在视觉转换器中构建张量维度的直觉
当使用深度CNN时,我们大部分使用的张量维度是(N,C H,W),其中字母代表以下内容:
- N:批量大小
- C:通道数
- H:身高
- W:宽度
您可以看到这种格式面向 2D 图像处理,因为它闻起来非常特定于图像的特征。
另一方面,有了变压器,事情变得更加通用和领域无关。我们将在下面看到的内容适用于视觉、文本、NLP、音频或其他输入数据可以表示为序列的问题。值得注意的是,当张量流经我们的视觉转换器时,在张量的表示中几乎没有视觉特定偏差。
在使用转换器和一般情况下,我们希望张量具有以下形状:(B,T,C),其中字母代表以下内容:
- B:批量大小(与CNN相同)
- T:时间维度或序列长度。此维度有时也称为 L。在视觉变压器的情况下,每个图像块对应于这个维度。如果我们有 16 个图像补丁,那么 T 维度的值将为 16
- C:通道或嵌入大小维度。此维度有时也称为 E。处理图像时,大小为 3x16x16(通道、宽度、高度)的每个补丁通过补丁嵌入层映射到大小为 C 的嵌入。我们稍后会看到如何做到这一点。
让我们深入了解输入图像张量在预测分割掩码的过程中如何变异和处理。
5.2 视觉转换器中张量的旅程
在深度CNN中,张量的旅程看起来像这样(在UNet,SegNet或其他基于CNN的架构中)。
输入张量通常是形状为 (1, 3, 128, 128)。该张量经过一系列卷积和最大池化操作,其中其空间维度减小,通道维度增加,通常每个增加 2 倍。这称为特征编码器。在此之后,我们执行反向操作,增加空间维度并减少通道维度。这称为特征解码器。在解码过程之后,我们得到一个形状的张量(1,64,128,128)。然后将其投影到我们希望的输出通道 C 的数量中,使用 1x128 无偏差的逐点卷积作为 (128, C, 1, 1)。
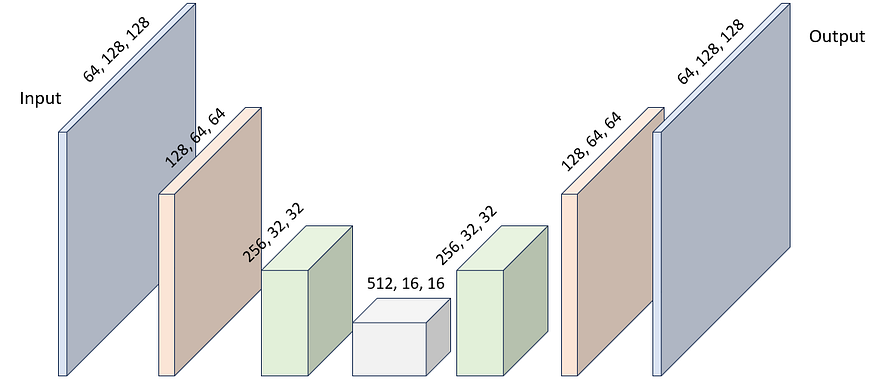
图 6:张量形状通过用于图像分割的深度 CNN 的典型进展。
使用视觉变压器时,流程要复杂得多。让我们看一下下面的一张图片,然后尝试了解张量如何在每一步中转换形状。
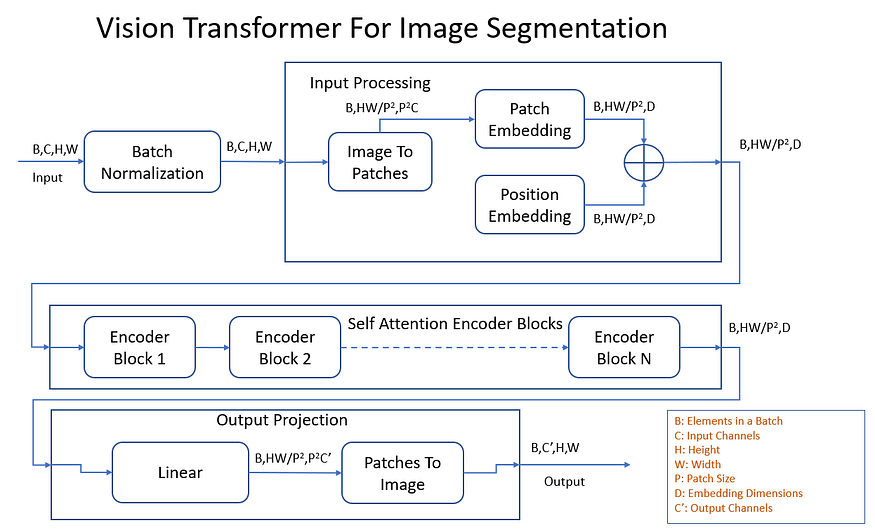
图 7:张量形状通过用于图像分割的视觉转换器的典型进展。
让我们更详细地看一下每个步骤,看看它如何更新流经视觉转换器的张量的形状。为了更好地理解这一点,让我们为张量维度取具体值。
- 批量规范化:输入和输出张量具有形状 (1, 3, 128, 128)。形状保持不变,但值归一化为零均值和单位方差。
- 图像到补丁:形状 (1, 3, 128, 128) 的输入张量被转换为 16x16 图像的堆叠块。输出张量具有形状 (1, 64, 768)。
- 补丁嵌入:补丁嵌入层将 768 个输入通道映射到 512 个嵌入通道(在本例中)。输出张量的形状为 (1, 64, 512)。补丁嵌入层基本上只是一个 nn。PyTorch 中的线性层。
- 位置嵌入:位置嵌入层没有输入张量,但有效地贡献了一个可学习的参数(PyTorch 中的可训练张量),其形状与补丁嵌入相同。这是形状(1,64,512)。
- 加:贴片和位置嵌入分段地加在一起,以产生视觉变压器编码器的输入。这个张量的形状是(1,64,512)。您会注意到,视觉变压器的主要主力,即编码器基本上保持这种张量形状不变。
- 变压器编码器:形状为(1,64,512)的输入张量流经多个变压器编码器块,每个转换器编码器块具有多个注意头(通信),后跟一个MLP层(计算)。张量形状保持不变,如 (1, 64, 512)。
- 线性输出投影:如果我们假设要将每个图像分成 10 个类,那么我们需要每个大小为 16x16 的补丁有 10 个通道。该 nn.用于输出投影的线性层现在会将 512 个嵌入通道转换为 16x16x10 = 2560 个输出通道,此张量将类似于 (1, 64, 2560)。在上图中 C' = 10。理想情况下,这将是一个多层感知器,因为“MLP 是通用函数近似器”,但我们使用单个线性层,因为这是一项教育练习
- 补丁到映像:该层将编码为 (64, 1, 64) 张量的 2560 个补丁转换回看起来像分割掩码的东西。这可以是 10 个单通道图像,或者在本例中是单个 10 通道图像,每个通道是 10 个类别之一的分割掩码。输出张量的形状为 (1, 10, 128, 128)。
就是这样 — 我们已经使用视觉转换器成功分割了输入图像!接下来,让我们看一个实验以及一些结果。
5.3 视觉变压器的实际应用
此笔记本包含此部分的所有代码。
就代码和类结构而言,它非常模仿上面的框图。上面提到的大多数概念都与此笔记本中的类名 1:1 对应。
有一些与注意力层相关的概念是我们模型的关键超参数。我们之前没有提到多头关注的细节,因为我们提到它超出了本文的范围。如果您对变压器中的注意力机制没有基本的了解,我们强烈建议您在继续之前阅读上述参考资料。
我们将以下模型参数用于视觉变压器进行分割。
- 补丁嵌入层的 768 个嵌入维度
- 12 变压器编码器块
- 每个变压器编码器块中有 8 个注意头
- 多头注意力和 MLP 中 20% 的辍学率
这种配置可以在 VisionTransformerArgs Python 数据类中看到。
@dataclass
class VisionTransformerArgs:"""Arguments to the VisionTransformerForSegmentation."""image_size: int = 128patch_size: int = 16in_channels: int = 3out_channels: int = 3embed_size: int = 768num_blocks: int = 12num_heads: int = 8dropout: float = 0.2
# end class在模型训练和验证期间使用了与以前类似的配置。配置指定如下。
- 随机水平翻转和颜色抖动数据增强应用于训练集以防止过度拟合
- 在非宽高比保留调整大小操作中将图像大小调整为 128x128 像素
- 不会对图像应用任何输入归一化,而是使用批量归一化层作为模型的第一层
- 该模型使用 LR 为 50.0 的 Adam 优化器和每 0004 个 epoch 将学习率衰减 0.8 倍的 StepLR 调度器训练 12 个 epoch
- 交叉熵损失函数用于将像素分类为属于宠物、背景或宠物边框
该模型具有 86.28M 参数,经过 85 个训练周期后,验证准确率为 89.50%。这低于深度 CNN 模型在 88 个训练周期后达到的 28.20% 的准确率。这可能是由于一些需要通过实验验证的因素。
- 最后一个输出投影图层为单个 nn。线性而非多层感知器
- 16x16 色块大小太大,无法捕获更细粒度的细节
- 训练时期不足
- 没有足够的训练数据 - 众所周知,与深度CNN模型相比,转换器模型需要更多的数据来有效训练
- 学习率太低
我们绘制了一个 gif,显示了模型如何学习预测验证集中 21 张图像的分割掩码。

图 8:显示图像分割模型的视觉转换器预测的分割掩码进程的 gif。
我们在早期训练时期注意到一些有趣的事情。预测的分割掩码有一些奇怪的阻塞伪影。我们能想到的唯一原因是,我们将图像分解为大小为 16x16 的补丁,经过很少的训练时期,模型除了一些非常粗略的信息之外,没有学到任何有用的东西关于这个 16x16 补丁通常被宠物或背景像素覆盖。

图 9:使用视觉转换器进行图像分割时,预测分割中看到的阻塞伪影会掩盖。
现在我们已经看到了一个基本的视觉转换器,让我们把注意力转向用于分割任务的最先进的视觉转换器。
5.4 SegFormer:使用转换器进行语义分割
本文于 2021 年提出了 SegFormer 架构。我们在上面看到的转换器是SegFormer 架构的简化版本。
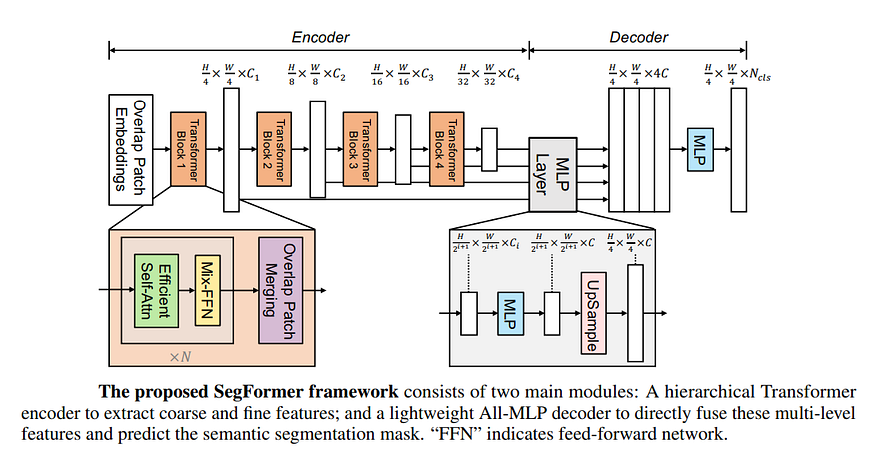
图 10:SegFormer 架构。资料来源:
最值得注意的是,SegFormer:
- 生成 4 组映像,其中包含大小为 4x4、8x8、16x16 和 32x32 的修补程序,而不是具有大小为 16x16 的修补程序的单个修补映像
- 使用 4 个变压器编码器块,而不仅仅是 1 个。这感觉就像一个模型合奏
- 在自我注意的前阶段和后期阶段使用卷积
- 不使用位置嵌入
- 每个变压器模块以空间分辨率 H/4 x W/4、H/8 x W/8、H/16 x W/16 和 H/32、W/32 处理图像
- 同样,当空间维度减小时,通道也会增加。这感觉类似于深度CNN
- 对多个空间维度的预测进行上采样,然后在解码器中合并在一起
- MLP 将所有这些预测结合起来,提供最终预测
- 最终的预测是在空间维度H/4,W/4,而不是在H,W。
六、结论
在本系列的第 4 部分中,我们特别介绍了变压器架构和视觉变压器。我们对视觉变压器的工作原理以及视觉变压器的通信和计算阶段所涉及的基本构建块有了直观的理解。我们看到了视觉转换器采用的基于补丁的独特方法,用于预测分割掩模,然后将预测组合在一起。
我们回顾了一个实验,该实验显示了视觉转换器的实际作用,并能够将结果与深度CNN方法进行比较。虽然我们的视觉转换器不是最先进的,但它能够取得相当不错的结果。我们提供了对最先进的方法的一瞥,例如SegFormer。
现在应该很清楚,与基于深度CNN的方法相比,变压器具有更多的活动部件,并且更复杂。从原始FLOP的角度来看,变压器有望提高效率。在变压器中,唯一计算繁重的实层是nn。线性。这是在大多数架构上使用优化的矩阵乘法实现的。由于这种架构的简单性,与基于深度CNN的方法相比,变压器有望更容易优化和加速。
恭喜你走到了这一步!我们很高兴您喜欢阅读有关 PyTorch 中高效图像分割的系列文章。如果您有任何问题或意见,请随时将其留在评论部分。
七、延伸阅读
注意力机制的细节超出了本文的范围。此外,您还可以参考许多高质量的资源来详细了解注意力机制。以下是我们强烈推荐的一些内容。
- 图解变压器
- 使用 PyTorch 从头开始 NanoGPT
我们将在下面提供文章的链接,这些文章提供了有关视觉转换器的更多详细信息。
- 在 PyTorch 中实现视觉转换器 (ViT):本文详细介绍了在 PyTorch 中实现用于图像分类的视觉转换器。值得注意的是,它们的实现使用 einops,我们避免这样做,因为这是一个以教育为中心的练习(我们建议学习和使用 einops 以提高代码可读性)。我们改用原生 PyTorch 运算符来排列和重新排列张量维度。此外,作者在一些地方使用 Conv2d 而不是线性图层。我们希望构建一个完全不使用卷积层的视觉转换器实现。
- 视觉转换器:AI之夏
- 在 PyTorch 中实现 SegFormer
德鲁夫·马塔尼
相关文章:
使用 PyTorch 进行高效图像分割:第 4 部分
一、说明 在这个由 4 部分组成的系列中,我们将使用 PyTorch 中的深度学习技术从头开始逐步实现图像分割。本部分将重点介绍如何实现基于视觉转换器的图像分割模型。 图 1:使用视觉转换器模型架构运行图像分割的结果。 从上到下,输入图像、地面…...

西班牙卡瓦起泡酒的风味搭配
卡瓦是一种对食物友好的西班牙起泡酒,它的制作方法和香槟一样,可以和类似的食物搭配。卡瓦食物搭配包括各种食物,从海鲜和鱼到火腿,以及不同类型的小吃,也可以将卡瓦酒与甜点、水果和奶酪搭配。 卡瓦酒是世界上最著名的…...
Java项目-苍穹外卖-Day05
文章目录 1. 新增套餐1.1 需求分析和设计1.2 代码实现1.2.1 DishController1.2.2 DishService1.2.3 DishServiceImpl1.2.4 DishMapper1.2.5 DishMapper.xml1.2.6 SetmealController1.2.7 SetmealService1.2.8 SetmealServiceImpl1.2.9 SetmealMapper1.2.10 SetmealMapper.xml1.…...

取模运算符在数组下标的应用
什么是取模运算符%? 定义: a mod b,设a、b属于正整数且b>0,如果q、r属于正整数满足aq*br,且0≤r<b,则定义: a mod b r 注意:取模运算符两侧的除数和被除数都是整数ÿ…...
Firefox(火狐),使用技巧汇总,问题处理
本文目的 说明火狐如何安装在C盘之外的盘,即定制安装路径。如何将同步功能切换到本地服务上。默认是国际服务器。安装在C盘之后如何解决,之前安装的扩展无法自动同步的问题。顺带讲解一下,火狐的一些比较好用的扩展。 安装路径定制 火狐目前…...

耐腐蚀高速数控针阀和多功能PID控制器在流量比率控制中的应用
摘要:在目前的流体比值混合控制系统中,普遍采用的是多通道闭环PID控制系统对各路流量进行准确控制后再进行混合,这种控制方式普遍存在的问题是对流量调节阀的响应速度、耐腐蚀性和线性度有很高要求。为此本文提出的第一个解决方案是采用NCNV系…...

C语言:选择+编程(每日一练Day6)
目录 编辑选择题: 题一: 题二: 题三: 题四: 题五: 编程题: 题一:至少是其他数字两倍的最大数 思路一: 思路二: 题二:两个数组的交集…...
)
微信小程序教学系列(8)
微信小程序教学系列 第八章:小程序国际化开发 欢迎来到第八章!这一次我们要谈论的是小程序国际化开发。你可能会问,什么是国际化?简单来说,国际化就是让小程序能够适应不同的语言和地区,让用户们感受到更…...

情人节定制:HTML5 Canvas全屏七夕爱心表白特效
❤️ 前言 “这个世界乱糟糟的而你干干净净可以悬在我心上做太阳和月亮。”,七夕节表白日,你要错过吗?如果你言辞不善,羞于开口的话,可以使用 html5 canvas 制作浪漫的七夕爱心表白动画特效,全屏的爱心和…...
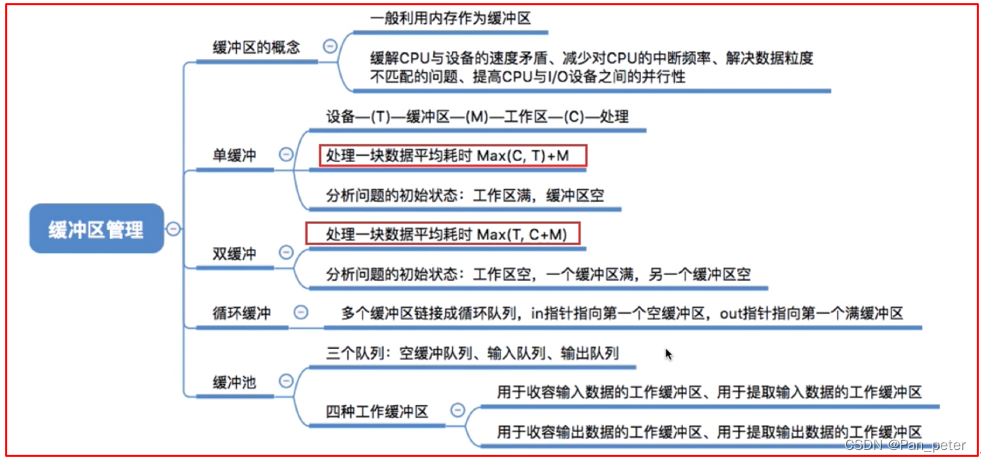
操作系统-笔记-第五章-输入输出管理
目录 五、第五章——输入输出管理 1、IO设备的概念和分类 (1)IO设备分类——使用特性 (2)IO设备分类——传输速率 (3)IO设备分类——信息交换(块、字符) 2、IO控制器 &#x…...

感觉自己效率不高吗?学习实现目标的六个关键步骤,让你做任何事都事半功倍!
概述 是否感觉自己效率不高?做任何事情都提不起来精神?开发的时候要完成的功能很多,却不知该如何下手去做?那么你通过这篇文章可以学习到六个完成工作和学习目标的关键步骤,只要简单重复这六个步骤,就可以很轻松的达到你想做到的任何目标。是不是感觉很神奇,我也是亲测…...
【高级IO】- 五种 IO 模型 | 多路转接 - select
目录 IO的基本概念 什么是高效的IO? 五种IO模型 阻塞IO 非阻塞IO 信号驱动IO IO多路转接 异步IO 同步通信VS异步通信(synchronous communication / asynchronous communication) 同步通信VS同步与互斥 阻塞VS非阻塞 其他高级IO …...

在Linux搭建GitLab私有仓库配置实现远程访问私有仓库Gitlab ——【内网穿透】
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《高效编程技巧》《cpolar》 ⛺️生活的理想,就是为了理想的生活! 文章目录 前言1. 下载Gitlab2. 安装Gitlab3. 启动Gitlab4. 安装cpolar5. 创建隧道配置访问地址6. 固定GitLab访问地址6.1 保留…...

ChatGPT应用于高职教育的四大潜在风险
目前,ChatGPT还是一种仍未成熟的技术,当其介入高职教育生态后,高职院校师生在享受ChatGPT带来的便利的同时,也应该明白ChatGPT引发的风险也会随之进入高职教育领域,如存在知识信息、伦理意识与学生主体方面的风险与挑战…...

uni-app在组件中内嵌webView,实现自定义webView的大小,并处理页面中有webview时其他元素点击事件失效的问题
uni-app在组件中内嵌webView,实现自定义webView的大小,并处理页面中有webview时其他元素点击事件失效的问题 uni-app在组件中内嵌webView,实现自定义webView的大小 setWebviewTop() {// #ifdef APP-PLUSvar currentWebview this.$scope.$g…...
档案开发:增加查询和打卡按钮
档案开发:增加查询和打卡按钮 和单据开发的不同点 没有单据类型不是右击–>特性–>单据主表/单据子表,而是右击–>特性–>选择想要的接口访问器类型是NCVO不需要映射不是项目右键–>新建–>其他–>主子表单据结点,而是…...

redis基础细心讲解,一篇了解常用的缓存技术!
今日内容 redis 1. 概念 2. 下载安装 3. 命令操作1. 数据结构 4. 持久化操作 5. 使用Java客户端操作redis 6. 在ssm项目中使用缓冲进行CRUD操作Redis 1. 概念 redis是一款高性能的NOSQL系列的非关系型数据库 1.1.什么是NOSQL NoSQL(NoSQL = Not Only SQL),意即“不仅仅…...

Three.js之几何体、高光材质、渲染器设置、gui
参考资料 阵列立方体和相机适配体验Threejs常见几何体简介…gui.js库(可视化改变三维场景) 知识点 注:基于Three.jsv0.155.0 长方体:oxGeometry球体:SphereGeometry圆柱:CylinderGeometry矩形平面:PlaneGeometry圆…...
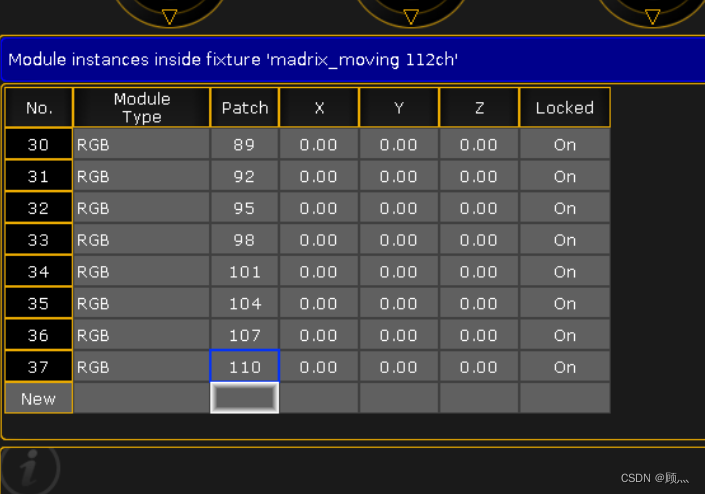
UE4如何连接dmx---摇头矩阵灯具的创建
UE4如何连接dmx---摇头矩阵灯具的创建 开始创建库! 然后我们开始创建多少个灯珠(注意了:这是矩阵灯,是看灯珠的) 那么这里我们创建6X6灯珠 下面设置灯珠的属性,灯珠有什么属性呢,只有颜色属性&…...
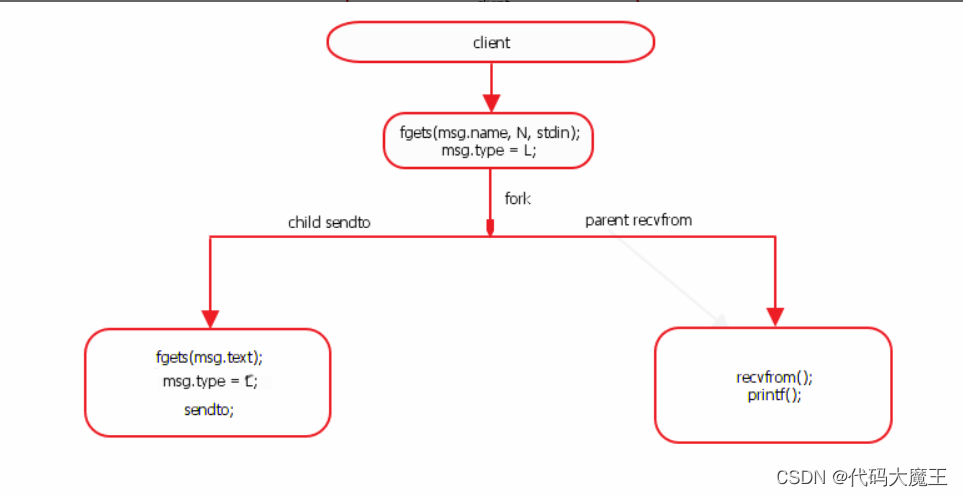
网络聊天室
一、项目要求 利用UDP协议,实现一套聊天室软件。服务器端记录客户端的地址,客户端发送消息后,服务器群发给各个客户端软件。 问题思考 客户端会不会知道其它客户端地址? UDP客户端不会直接互连,所以不会获知其它客…...

基于STM32的多参数家庭健康监测终端设计
1. 项目概述1.1 设计目标与应用场景本项目面向家庭健康监测场景,构建一套便携式、多参数、低功耗的嵌入式健康检测终端。其核心设计目标是:在无专业医疗人员介入的前提下,为普通家庭用户提供可信赖的日常生理参数采集能力,重点覆盖…...

开关电源拓扑结构全解析:从Buck到LLC的选型与设计要点
1. 电源逆变与开关变换器拓扑结构解析电源变换是电子系统能量管理的核心环节,其本质在于实现电能形式、电压等级、电流特性及电气隔离状态的可控转换。在工业控制、新能源发电、电动汽车、通信设备及消费类电子产品中,不同应用场景对效率、功率密度、动态…...

RK3566平台Android 11系统编译实战指南
1. Android系统编译:面向RK3566平台的工程化实践指南嵌入式Linux系统向Android演进的过程中,编译流程不再仅是源码到二进制的转换,而是一套覆盖引导加载、内核定制、框架集成与镜像打包的完整工程体系。本文以RK3566 SoC平台为载体࿰…...

小程序毕业设计基于微信小程序的校园快递系统weixin414
前言 传统校园快递平台系统存在信息管理难度大、容错率低、管理人员处理数据费工费时等问题。为了解决这些难题,专门开发了Spring Boot基于微信小程序的校园快递系统。该系统旨在提高校园快递平台系统信息管理问题的解决效率,优化信息处理流程࿰…...

分布式最优潮流:从理论到实践
分布式最优潮流关键词:网络划分;分布式光伏;集群电压控制;分布式优化;有功缩减 参考文档:《含分布式光伏的配电网集群划分和集群电压协调控制》 仿真平台:MATLAB 主要内容:本文以全局…...

RexUniNLU零样本实战:从电商评论到合同审核,一键搞定多领域信息抽取
RexUniNLU零样本实战:从电商评论到合同审核,一键搞定多领域信息抽取 1. 引言:零样本信息抽取的革命性突破 1.1 传统NLP落地的三大痛点 在自然语言处理领域,信息抽取一直是个"高门槛"任务。传统方案通常面临以下挑战&…...

LightOnOCR-2-1B部署教程:Linux服务器环境检查、端口冲突解决与权限配置
LightOnOCR-2-1B部署教程:Linux服务器环境检查、端口冲突解决与权限配置 想把图片里的文字快速、准确地提取出来吗?无论是扫描的文档、手机拍的照片,还是网上下载的图表,手动打字录入不仅费时费力,还容易出错。今天要…...

嵌入式设备Ping通却无法上网的四大根因与实战排查
1. 嵌入式网络调试核心问题:能 Ping 通但无法上网的系统性排查与工程化解决在嵌入式设备联网调试过程中,“能 Ping 通但无法上网”是一种高频、典型且极具迷惑性的网络异常现象。该现象广泛存在于工业网关、智能终端、边缘计算节点等基于 Linux 或 RTOS …...

dir命令详解:查看文件与文件夹
Windows命令提示符中dir命令的完整使用指南 dir命令是Windows命令提示符中最基础且最重要的命令之一,主要用于查看当前目录下的文件和子文件夹信息。下面我将详细介绍该命令的各种用法和参数。 1. dir命令的基本用法 基本查看操作 在命令提示符中直接输入dir命令…...

大数据基于java的云南旅游景点数据分析与可视化
目录数据收集与预处理数据分析与挖掘可视化实现系统架构设计技术栈选型预期成果项目技术支持可定制开发之功能创新亮点源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作数据收集与预处理 从公开数据源(如云南省旅游局官网、携程、…...