Lnton羚通关于Optimization在【PyTorch】中的基础知识
OPTIMIZING MODEL PARAMETERS (模型参数优化)
现在我们有了模型和数据,是时候通过优化数据上的参数来训练了,验证和测试我们的模型。训练一个模型是一个迭代的过程,在每次迭代中,模型会对输出进行猜测,计算猜测数据与真实数据的误差(损失),收集误差对其参数的导数(正如前一节我们看到的那样),并使用梯度下降优化这些参数。
Prerequisite Code ( 先决代码 )
We load the code from the previous sections on
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transformstraining_data = datasets.FashionMNIST(root = "../../data/",train = True,download = True, transform = transforms.ToTensor()
)test_data = datasets.FashionMNIST(root = "../../data/",train = False,download = True, transform = transforms.ToTensor()
)train_dataloader = DataLoader(training_data, batch_size = 32, shuffle = True)
test_dataloader = DataLoader(test_data, batch_size = 32, shuffle = True)class NeuralNetwork(nn.Module):def __init__(self):super(NeuralNetwork, self).__init__()self.flatten = nn.Flatten()self.linear_relu_stack = nn.Sequential(nn.Linear(28 * 28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10) )def forward(self, x):out = self.flatten(x)out = self.linear_relu_stack(out)return outmodel = NeuralNetwork()
Hyperparameters ( 超参数 )
超参数是可调节的参数,允许控制模型优化过程,不同的超参数会影响模型的训练和收敛速度。read more
我们定义如下的超参数进行训练:
Number of Epochs: 遍历数据集的次数
Batch Size: 每一次使用的数据集大小,即每一次用于训练的样本数量
Learning Rate: 每个 batch/epoch 更新模型参数的速度,较小的值会导致较慢的学习速度,而较大的值可能会导致训练过程中不可预测的行为,例如训练抖动频繁,有可能会发散等。
learning_rate = 1e-3
batch_size = 32
epochs = 5
Optimization Loop ( 优化循环 )
我们设置完超参数后,就可以利用优化循环训练和优化模型;优化循环的每次迭代称为一个 epoch, 每个 epoch 包含两个主要部分:
The Train Loop: 遍历训练数据集并尝试收敛到最优参数。
The Validation/Test Loop: 验证/测试循环—遍历测试数据集以检查模型性能是否得到改善。
让我们简单地熟悉一下训练循环中使用的一些概念。跳转到前面以查看优化循环的完整实现。
Loss Function ( 损失函数 )
当给出一些训练数据时,我们未经训练的网络可能不会给出正确的答案。 Loss function 衡量的是得到的结果与目标值的不相似程度,是我们在训练过程中想要最小化的 Loss function。为了计算 loss ,我们使用给定数据样本的输入进行预测,并将其与真实的数据标签值进行比较。
常见的损失函数包括nn.MSELoss (均方误差)用于回归任务,nn.NLLLoss(负对数似然)用于分类神经网络。nn.CrossEntropyLoss 结合 nn.LogSoftmax 和 nn.NLLLoss 。
我们将模型的输出 logits 传递给 nn.CrossEntropyLoss ,它将规范化 logits 并计算预测误差。
# Initialize the loss function
loss_fn = nn.CrossEntropyLoss()
Optimizer ( 优化器 )
优化是在每个训练步骤中调整模型参数以减少模型误差的过程。优化算法定义了如何执行这个过程(在这个例子中,我们使用随机梯度下降)。所有优化逻辑都封装在优化器对象中。这里,我们使用 SGD 优化器; 此外,PyTorch 中还有许多不同的优化器,如 ADAM 和 RMSProp ,它们可以更好地用于不同类型的模型和数据。
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
在训练的循环中,优化分为3个步骤:
调用 optimizer.zero_grad() 重置模型参数的梯度,默认情况下,梯度是累加的。为了防止重复计算,我们在每次迭代中显式将他们归零。
通过调用 loss.backward() 反向传播预测损失, PyTorch 保存每个参数的损失梯度。
一旦我们有了梯度,我们调用 optimizer.step() 在向后传递中收集梯度调整参数。
Full Implementation (完整实现)
我们定义了遍历优化参数代码的 train loop, 以及根据测试数据定义了test loop。
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms## 数据集
training_data = datasets.FashionMNIST(root="../../data/",train=True,download=True,transform=transforms.ToTensor()
)test_data = datasets.FashionMNIST(root="../../data/",train=False,download=True,transform=transforms.ToTensor()
)## dataloader
train_dataloader = DataLoader(training_data, batch_size=32, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=32, shuffle=True)## 定义神经网络
class NeuralNetwork(nn.Module):def __init__(self):super(NeuralNetwork, self).__init__()self.flatten = nn.Flatten()self.linear_relu_stack = nn.Sequential(nn.Linear(28 * 28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10))def forward(self, x):out = self.flatten(x)out = self.linear_relu_stack(out)return out## 实例化模型
model = NeuralNetwork()## 损失函数
loss_fn = nn.CrossEntropyLoss()## 优化器
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)## 超参数
learning_rate = 1e-3
batch_size = 32
epochs = 5## 训练循环
def train_loop(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)for batch, (X, y) in enumerate(dataloader):# 计算预测和损失pred = model(X)loss = loss_fn(pred, y)## 反向传播optimizer.zero_grad()loss.backward()optimizer.step()if batch % 100 == 0:loss, current = loss.item(), batch * len(X)print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")## 测试循环
def test_loop(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)test_loss, correct = 0, 0with torch.no_grad():for X, y in dataloader:pred = model(X)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchescorrect /= sizeprint(f"Test error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f}\n")## 训练网络
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train_loop(train_dataloader, model, loss_fn, optimizer)test_loop(test_dataloader, model, loss_fn)
print("Done!")
Lnton羚通专注于音视频算法、算力、云平台的高科技人工智能企业。 公司基于视频分析技术、视频智能传输技术、远程监测技术以及智能语音融合技术等, 拥有多款可支持ONVIF、RTSP、GB/T28181等多协议、多路数的音视频智能分析服务器/云平台。

相关文章:
Lnton羚通关于Optimization在【PyTorch】中的基础知识
OPTIMIZING MODEL PARAMETERS (模型参数优化) 现在我们有了模型和数据,是时候通过优化数据上的参数来训练了,验证和测试我们的模型。训练一个模型是一个迭代的过程,在每次迭代中,模型会对输出进行猜测&…...

冒泡排序算法
//version 1 void bubblesort(vector<int>& nums){int n=nums.size();for(int i...
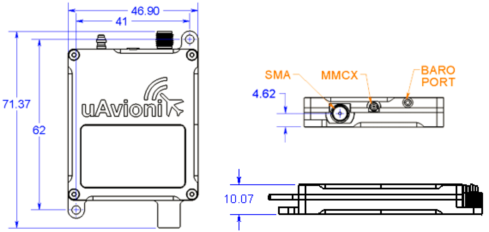
无人机航管应答机 ping200XR
产品概述 ping200XR是一个完整的系统,旨在满足航管应答器和自动相关监视广播(ADS-B)的要求,在管制空域操作无人航空系统(UAS)。该系统完全可配置为模式A,模式C,模式S转发器和扩展ADS-B发射机的任何组合。ping200XR包括一个精度超…...

oracle归档日志满了导致启动不起来解决
oracle启动不起来解决 原因:闪回归档区的空间满了 [oraclepre-oracle ~]$ sqlplus / as sysdbaSQL*Plus: Release 11.2.0.4.0 Production on Tue Aug 22 14:48:50 2023Copyright (c) 1982, 2013, Oracle. All rights reserved.Connected to: Oracle Database 11g…...

高等数学:线性代数-第二章
文章目录 第2章 矩阵及其运算2.1 线性方程组和矩阵2.2 矩阵的运算2.3 逆矩阵2.4 Cramer法则 第2章 矩阵及其运算 2.1 线性方程组和矩阵 n \bm{n} n 元线性方程组 设有 n 个未知数 m 个方程的线性方程组 { a 11 x 1 a 12 x 2 ⋯ a 1 n x n b 1 a 21 x 1 a 22 x 2 ⋯ a …...

星戈瑞分析FITC-PEG-Alkyne的荧光特性和光谱特性
欢迎来到星戈瑞荧光stargraydye!小编带您盘点: FITC-PEG-Alkyne的荧光特性和光谱特性是对其荧光性能进行分析的方面。以下是FITC-PEG-Alkyne的一些常见荧光特性和光谱特性: **1. 荧光激发波长:**FITC-PEG-Alkyne的荧光激发波长通…...

VB.NET调用VB6 Activex EXE实现PowerBasic和FreeBasic的标准DLL调用
VB6写的ActiveX EXE公共对象是外置进程,因此,尽管它是x86 32位的进程,但可以集成到 VB.NET的x64和x32程序中使用。 VS2022的VB.NET程序,调用ActiveX DLL对象我在上篇笔记中写了 VB.NET通过VB6 ActiveX DLL调用PowerBasic及FreeB…...
(下篇))
深入了解Unity的Physics类:一份详细的技术指南(七)(下篇)
接着上一篇深入了解Unity的Physics类(上篇),我们继续把Physics类剩余的属性和方法进行讲解 碰撞检测和忽略: (这些方法和属性涉及查询和处理物体之间的碰撞) Physics.CheckBox: 检查给定位置的盒子是否与任何碰撞器接触或者位于任何碰撞器内部。 Physics.CheckCapsu…...
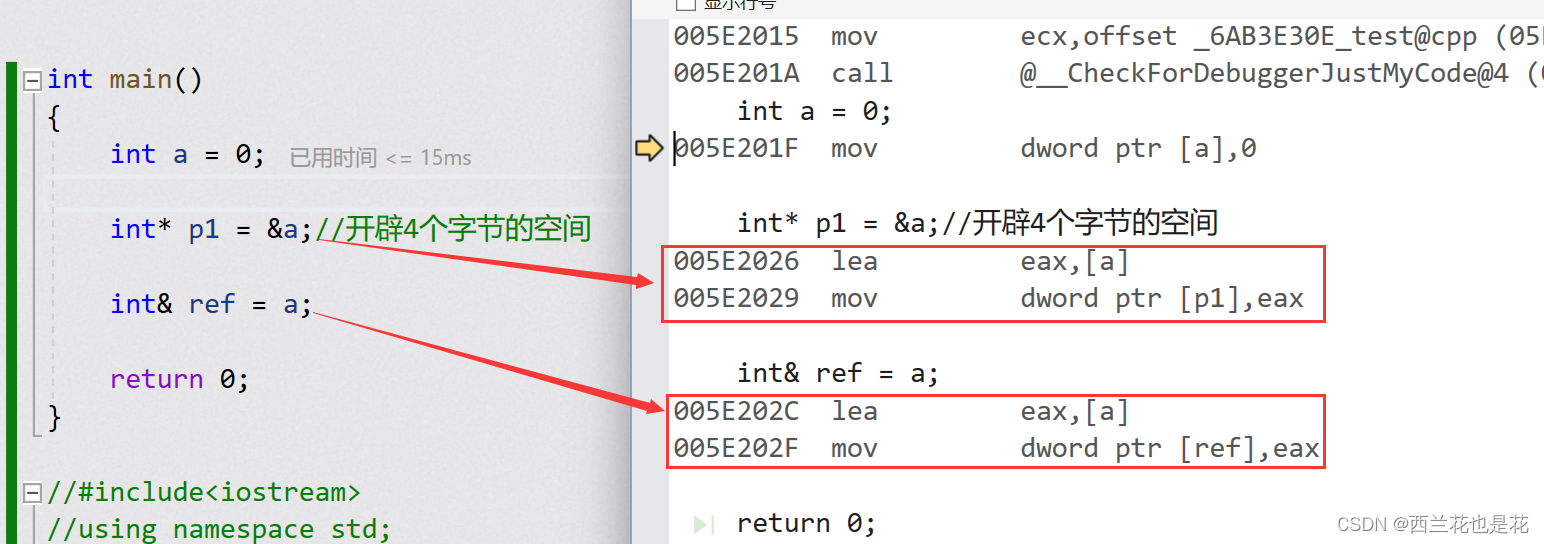
C++入门:引用是什么
目录 1.引用的概念 2.引用的特征 3.常引用 4.引用使用场景 5.传值,传引用效率比较 6.引用与指针的区别 1.引用的概念 引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空 间,它和它引用…...

2023年人工智能与自动化控制国际学术会议(AIAC 2023)
2023年人工智能与自动化控制国际学术会议(AIAC 2023) The 2023 International Conference on Artificial Intelligence and Automation Control 2023年人工智能与自动化控制国际学术会议(AIAC 2023)将于2023年10月27-29日在中…...
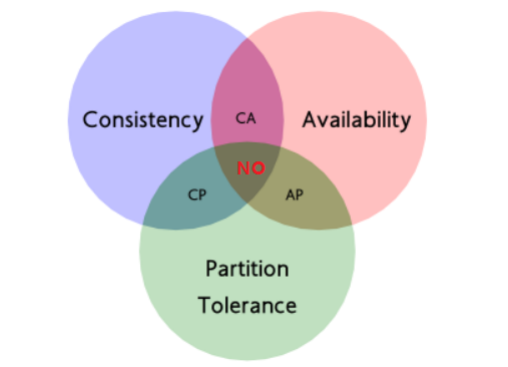
分布式核心知识以及常见微服务框架
分布式中的远程调用 在微服务架构中,通常存在多个服务之间的远程调用的需求。远程调用通常包含两个部分:序列化和通信协议。常见的序列化协议包括json、xml、 hession、 protobuf、thrift、text、 bytes等,目前主流的远程调用技术有基于HTTP…...

Unity记录4.1-存储-根据关键字加载Tile
文章首发见博客:https://mwhls.top/4810.html。 无图/格式错误/后续更新请见首发页。 更多更新请到mwhls.top查看 欢迎留言提问或批评建议,私信不回。 汇总:Unity 记录 摘要:实现完 Tilemap 地图生成后,实现根据关键字…...
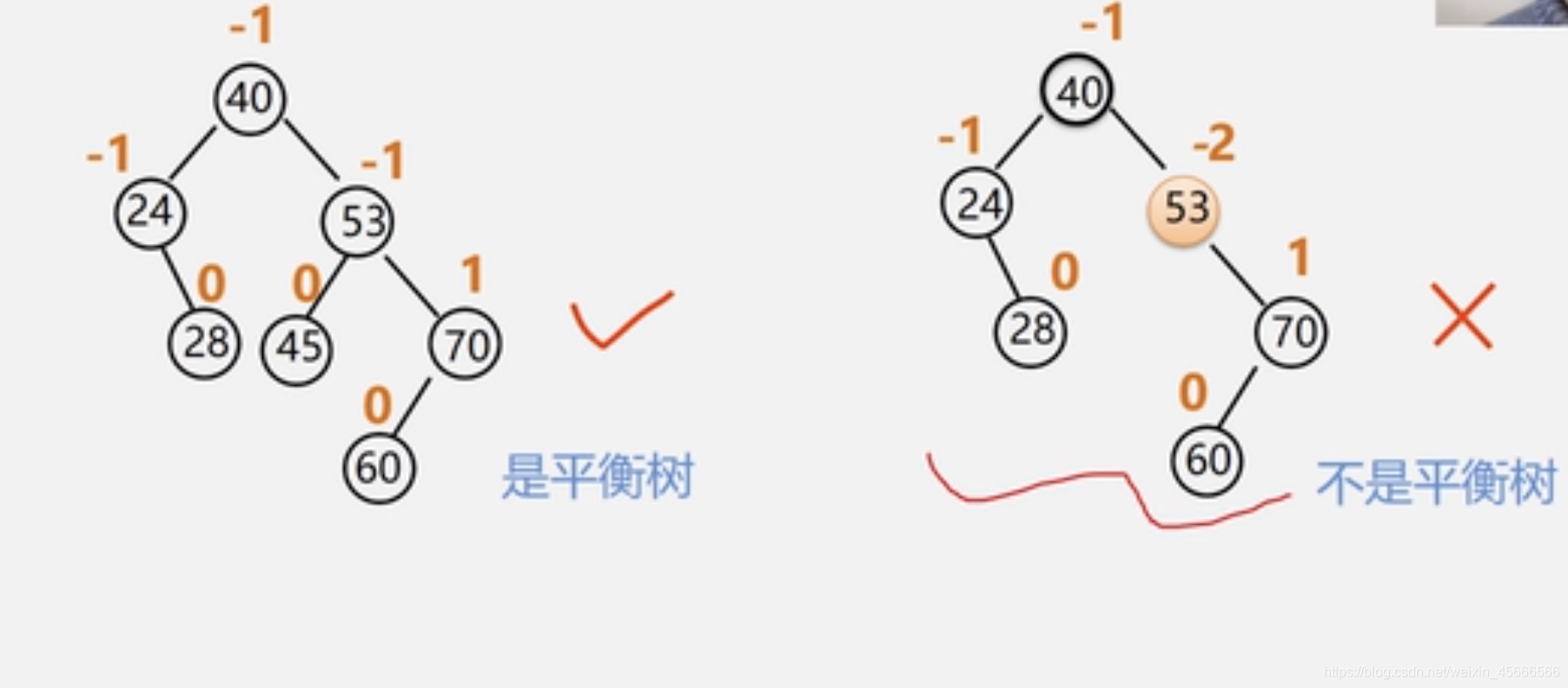
数据结构—树表的查找
7.3树表的查找 当表插入、删除操作频繁时,为维护表的有序表,需要移动表中很多记录。 改用动态查找表——几种特殊的树 表结构在查找过程中动态生成 对于给定值key 若表中存在,则成功返回; 否则࿰…...

微信小程序测试策略和注意事项?
一、测试前准备(环境搭建) 1、前端页面 微信 Web 开发者工具安装、授权测试用的微信号可预览和调试小程序 2、管理后台 配置内网测试服务器环境,通过 PC 端 Web 站点管理小程序前端的输出内容,可从开发人员获取管理账号进行测…...

VUE3封装EL-ELEMENT-PLUS input组件
VUE3封装EL-ELEMENT-PLUS input组件 完整代码 <template><div><div><div class"lable_top" v-if"label"><label :class"lable_sty">{{ label }}</label></div><el-inputv-model"inputValue&…...

RISC-V公测平台发布 · 在SG2042上配置Jupiter+Octave科学计算环境
简介 JupyterHub是一个开源的共享计算平台,它为每个用户管理一个单独的 Jupyter 环境, 可以用于学生班级、企业数据科学小组或科学研究小组。它是一个多用户中心,可以生成、管理和代理多个单用户Jupyter笔记本服务器的实例。 GNU Octave是一…...
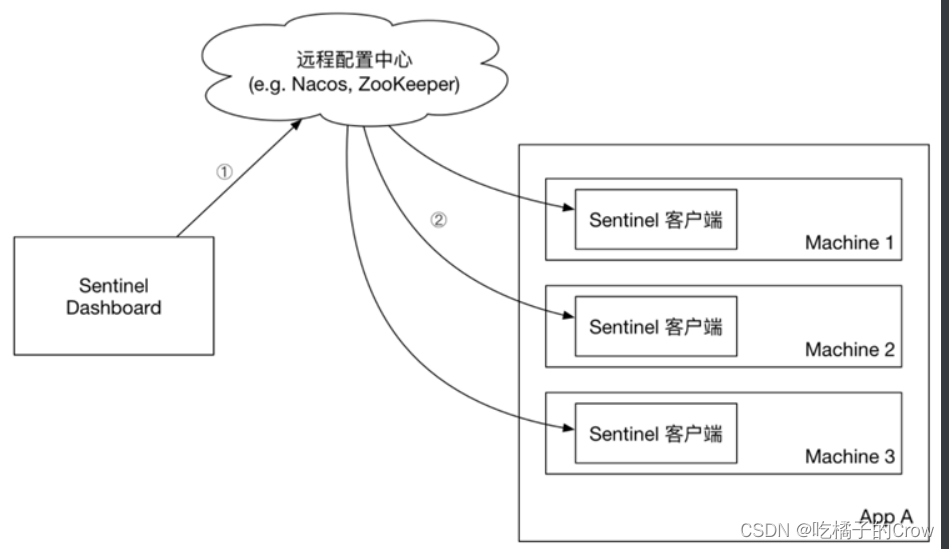
初识Sentinel
目录 1.解决雪崩的方式有4种: 1.1.2超时处理: 1.1.3仓壁模式 1.1.4.断路器 1.1.5.限流 1.1.6.总结 1.2.服务保护技术对比 1.3.Sentinel介绍和安装 1.3.1.初识Sentinel 1.3.2.安装Sentinel 1.4.微服务整合Sentinel 2.流量控制 2.1.簇点链路 …...

【官方中文文档】Mybatis-Spring #注入映射器
注入映射器 与其在数据访问对象(DAO)中手工编写使用 SqlSessionDaoSupport 或 SqlSessionTemplate 的代码,还不如让 Mybatis-Spring 为你创建一个线程安全的映射器,这样你就可以直接注入到其它的 bean 中了: <bea…...
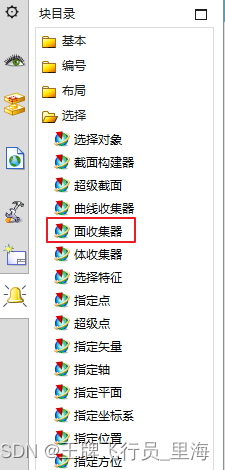
UG\NX 二次开发 相切面、相邻面的选择控件
文章作者:里海 来源网站:https://blog.csdn.net/WangPaiFeiXingYuan 简介: 有群友问“UFUN多选功能过滤面不能选择相切面或相邻面之类的吗?” 这个用Block UI的"面收集器"就可以,ufun函数是不行的。 效果: C++语言在UG二次开发中的应用及综合分析 C++ …...
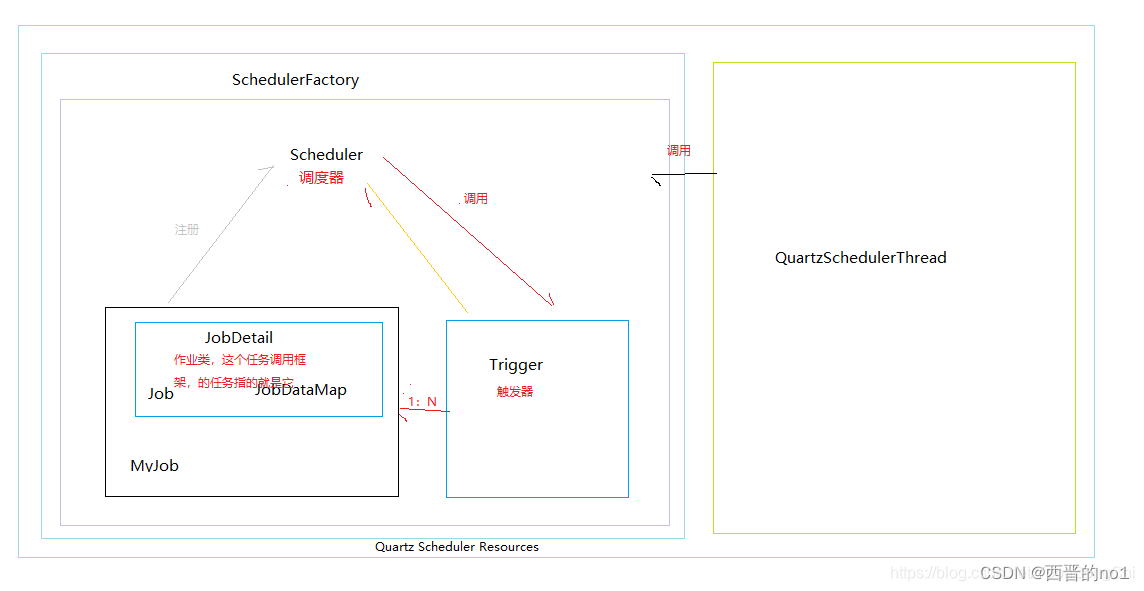
Quartz任务调度框架介绍和使用
一、Quartz介绍 Quartz [kwɔːts] 是OpenSymphony开源组织在Job scheduling领域又一个开源项目,完全由Java开发,可以用来执行定时任务,类似于java.util.Timer。但是相较于Timer, Quartz增加了很多功能: 1.持久性作业 …...

DAMO-YOLO在工地安全监管中的应用:防护装备检测系统
DAMO-YOLO在工地安全监管中的应用:防护装备检测系统 1. 工地安全监管的现实挑战 建筑工地从来都不是一个安静的场所。钢筋切割的刺耳声、塔吊运转的轰鸣、混凝土泵车的震动,这些声音背后是数百名工人同时作业的复杂场景。就在这样的环境中,…...
)
别再只用L1/L2了!用PyTorch实战图像修复的5种高阶损失函数(含VGG19感知损失代码)
超越L1/L2:PyTorch图像修复中5种高阶损失函数的工程实践 当你在深夜调试一个图像超分辨率模型时,发现生成的图片虽然PSNR值很高,但总感觉缺少那种"真实感"——边缘不够锐利,纹理略显模糊。这时候,L1/L2损失函…...

FreeRtos——24、STM32中断处理体系及软件定时器按键消抖
第一节:STM32中断处理体系结构1.中断处理路径:2.NVIC中断控制器的中断优先级:2.1 中断号:在NVIC中对于硬件产生的任何一个中断都分配了一个中断号,中断号是一个唯一的标识符,用于识别每个外设设备的中断。NVIC使用中断号来配置中断…...

ViT图像分类-中文-日常物品完整指南:4090D单卡环境配置与中文类别映射说明
ViT图像分类-中文-日常物品完整指南:4090D单卡环境配置与中文类别映射说明 想试试用AI模型来识别你手机里的照片吗?比如,拍一张桌上的水杯、键盘或者零食,让模型告诉你它是什么。今天要介绍的这个工具,就能帮你轻松实…...

如何用QtScrcpy实现跨平台Android设备高效投屏与控制
如何用QtScrcpy实现跨平台Android设备高效投屏与控制 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtScrcpy 在数字化…...

新手零基础入门CAN总线:借助快马AI生成可运行代码理解通信机制
作为一个刚接触嵌入式开发的菜鸟,最近被导师要求学习CAN总线协议。面对手册里密密麻麻的寄存器配置和报文格式说明,我一度怀疑自己是不是选错了专业方向。直到发现了InsCode(快马)平台,用它的AI生成功能快速搭建了一个可运行的CAN通信demo&am…...

深入解析AUTOSAR通信模块:从信号抽象到多路CAN配置
1. AUTOSAR通信模块的核心价值 第一次接触AUTOSAR通信模块时,我被它复杂的层级关系绕得头晕。直到在实车上调试快充CAN信号时,才真正理解这种架构设计的精妙之处。简单来说,AUTOSAR的Com模块就像个智能邮局,负责把应用层产生的各种…...

Graphormer部署教程:/etc/supervisor/conf.d/graphormer.conf配置解析
Graphormer部署教程:/etc/supervisor/conf.d/graphormer.conf配置解析 1. 项目介绍 Graphormer是一种基于纯Transformer架构的图神经网络模型,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。该模型在OGB、PCQM4M等…...

别让import.*拖慢你的Spring Boot项目!IDEA优化导入配置详解
别让import.*拖慢你的Spring Boot项目!IDEA优化导入配置详解 在微服务架构盛行的今天,Spring Boot项目的启动速度已经成为开发者关注的焦点。一个常见的性能陷阱就隐藏在那些看似无害的import.*语句中——它们会强制JVM加载整个包的类,即使你…...

5分钟搞定RetroArch缩略图:从黑屏到完美游戏封面的全攻略
5分钟搞定RetroArch缩略图:从黑屏到完美游戏封面的全攻略 【免费下载链接】RetroArch Cross-platform, sophisticated frontend for the libretro API. Licensed GPLv3. 项目地址: https://gitcode.com/GitHub_Trending/re/RetroArch 还记得打开RetroArch游戏…...